你必须非常努力,才能看起来毫不费力!
微信搜索公众号 AGIPlayer ,一起From Zero To Hero !
Anthropic 在 Code with Claude 大会上推出了 Dreaming------一个让 Agent 在 Session 间隙自动审查过往经历、提取模式、重组记忆的机制。它不是噱头,而是解决 Agent 长期运行中记忆退化问题的系统性方案。
5 月 6 号,Anthropic 在旧金山办了场开发者大会叫 Code with Claude。没什么新模型,没什么大新闻,但有一个功能让我盯了半天------Dreaming。
说实话,第一次看到这个名字我还以为是个营销噱头。AI 在做梦?这什么鬼?
但仔细看完文档和 API 设计之后,我觉得这个功能比名字听起来要严肃得多。它解决的是我过去大半年一直在头疼的问题:Agent 跑得越久,记忆越烂。
 图片来源:x.com/claudeai/st...
图片来源:x.com/claudeai/st...
一、问题:Agent 的记忆是个垃圾堆
先说说问题本身。
如果你做过长时间运行的 Agent,你一定遇到过这个场景:Agent 第 1 次跑的时候,它学到了一些东西------比如"这个项目的测试要用 pnpm test 不是 npm test"、"这个 API 的 id 字段是字符串不是整数"。这些经验被写进了 Memory,挺好。
但第 10 次跑的时候,Memory 里已经有了七八条关于测试命令的记录,其中三条说的是同一件事但措辞不同,两条互相矛盾(因为项目中间改过构建工具),还有一条已经完全过时了。
官方文档的描述非常精确:
"Agents write to their memory stores as they work, but these writes are local and incremental: over many sessions a memory store accumulates duplicates, contradictions, and stale entries."
这就是问题所在。Agent 的 Memory 写入是局部的、增量的。每一次写入在当时都是合理的,但累积起来就是一团乱麻。
这跟人类的情况其实很像。你每天经历的事情,不会自动变成有条理的知识。白天接收的信息是碎片化的、重复的、有时候还自相矛盾的。人类靠什么把这些碎片整理成知识?靠睡眠。
 图片来源:claude.com/blog/new-in...
图片来源:claude.com/blog/new-in...
二、Dreaming 的核心机制:Agent 的睡眠巩固
神经科学里有个概念叫"记忆巩固"(Memory Consolidation)。大脑在睡眠期间会做三件事:重放白天的经历、修剪冗余连接、把短期记忆转化为长期记忆。这不是被动存储,是主动重构。
Anthropic 给这个功能取名叫 Dreaming,灵感就是从这来的。
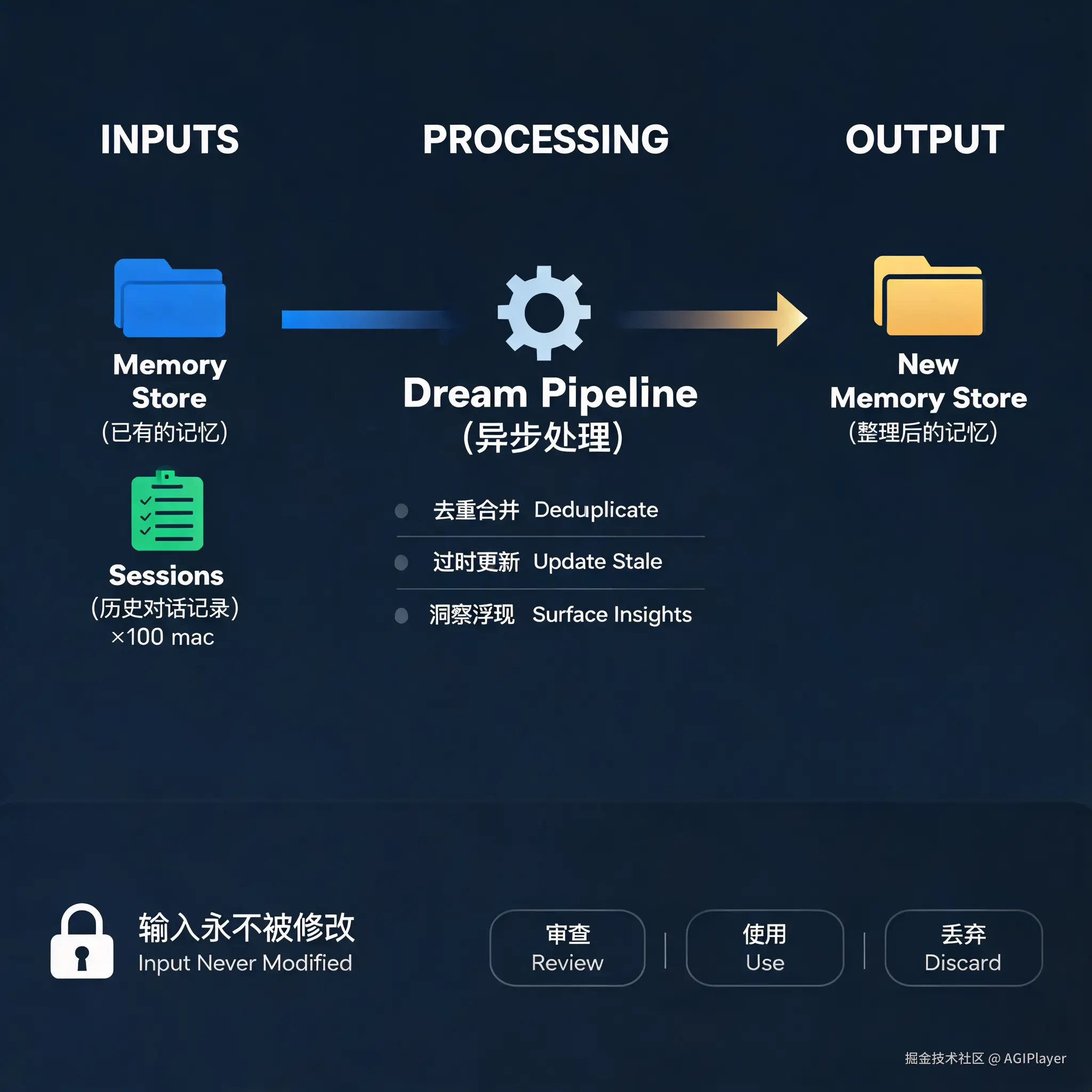
Agent 在"清醒"时工作,把学到的东西写入 Memory Store。在"做梦"时,它离线审查这些积累的记忆,做三件事:
去重合并 ------多个 Session 写入的重复记忆,合并成一条。 过时更新 ------被新信息矛盾的旧条目,替换成最新值。 洞察浮现------跨 Session 挖掘单个 Agent 看不到的模式。
第三点特别关键。单个 Agent 只能看到自己那一次 Session 的经历,但 Dreaming 能看到所有 Session 的全貌。它能发现那些反复出现的错误、Agent 们趋同的工作流、团队共享的偏好------这些是任何单个 Agent 无法察觉的。
官方的说法更简洁:
"Dreaming surfaces patterns that a single agent cannot see on its own, including recurring mistakes, workflows that agents converge on, and preferences shared across a team."
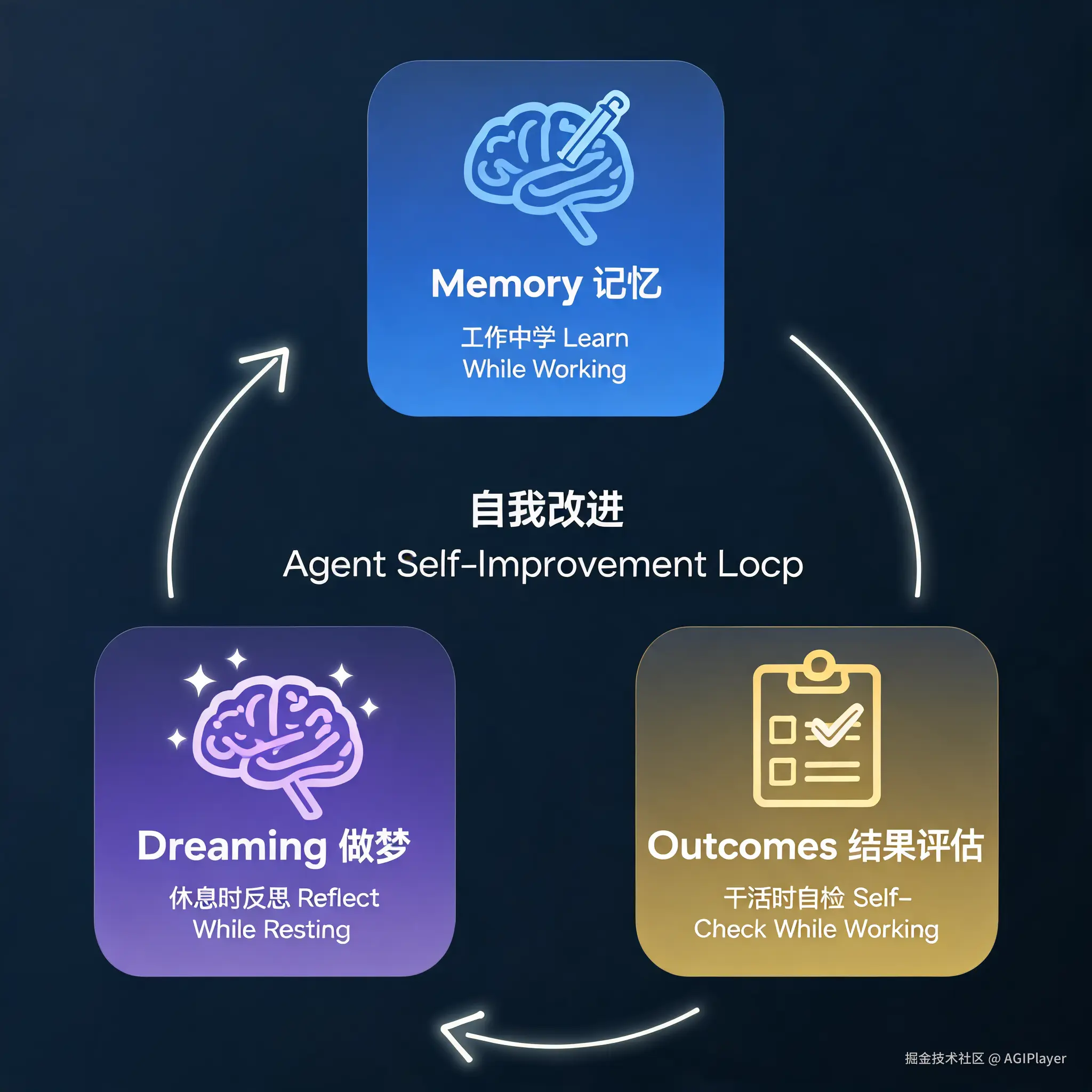
Memory 让 Agent 在工作时学习,Dreaming 让 Agent 在休息时反思。两者组合,才是一个完整的自我改进系统。
三、技术架构:一个异步 Job 而已
Dreaming 的技术实现比我预想的要简洁。它本质上就是一个异步 Job。
一个 Dream 的输入有两部分:
- 一个已有的 Memory Store(必须)------这是 Claude 要审查和整理的对象
- 最多 100 个 Sessions(可选)------过去的对话记录,Claude 从中挖掘模式和洞察
输出是一个全新的 Memory Store。注意,输入的 Memory Store 永远不会被修改。你拿到输出后,可以审查,满意就用,不满意就扔掉。
这设计我觉得挺讲究的。不可变性给了开发者安全感------你永远不会因为一次 Dreaming 把辛苦积累的 Memory 搞坏。
看一个最简的创建 Dream 的代码:
python
dream = client.beta.dreams.create(
inputs=[
{"type": "memory_store", "memory_store_id": store_id},
{"type": "sessions", "session_ids": [session_a, session_b]},
],
model="claude-opus-4-7",
instructions="Focus on coding-style preferences; ignore one-off debugging notes.",
)
print(dream.id) # drm_01...instructions 参数很有意思------你可以给 Dreaming 过程加引导。比如上面这个例子,告诉它只关注编码风格偏好,忽略一次性的调试笔记。这相当于你在告诉 Agent "做梦的时候重点想什么",限制最多 4096 字符。
Dream 的生命周期很标准:
arduino
pending → running → completed
→ failed
→ canceled运行过程中,usage 字段会实时更新 token 消耗。Dream 底层跑的是一个 Managed Agent Session,你可以通过 session_id 字段流式观察它具体在读写什么。
目前只支持 claude-opus-4-7 和 claude-sonnet-4-6 两个模型。Dreaming 需要 Beta headers:managed-agents-2026-04-01 和 dreaming-2026-04-21。
四、Memory Store:Dreaming 操作的对象
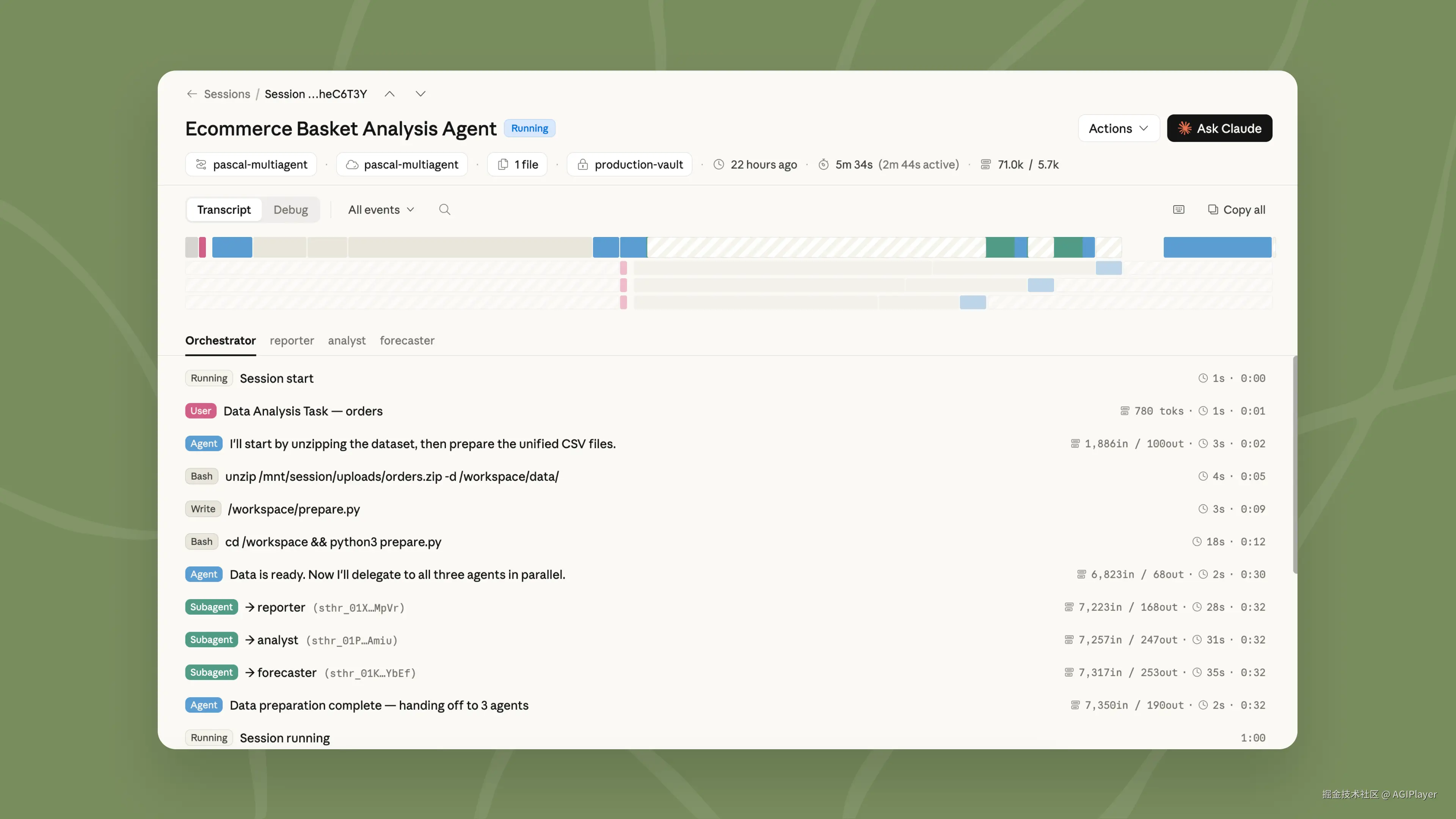
要理解 Dreaming,得先搞懂它操作的对象------Memory Store。
Memory Store 是 Workspace 级别的文本文档集合,专门为 Claude 优化。当它被挂载到 Session 时,Agent 在容器里看到的是一个目录:/mnt/memory/。Agent 用和操作文件系统一样的工具来读写它。
几个关键参数:
- 每次 Session 最多挂载 8 个 Memory Store
- 单个 Memory 最大 100KB(约 25K tokens)
- 支持读写和只读两种模式
- 每次修改都会生成不可变的 Memory Version,保留 30 天审计记录
这里有个设计我很欣赏:Memory Store 可以设置只读。官方文档专门提醒了安全风险------如果 Agent 处理了不受信任的输入(用户 Prompt、网页内容、第三方工具输出),一次成功的 Prompt Injection 可能往 Memory 里写入恶意内容,后续 Session 会把这些内容当作可信记忆来读。
所以最佳实践是:参考材料用只读 Store,Agent 自己的运行时记忆用读写 Store,分开管理。
 图片来源:claude.com/blog/new-in...
图片来源:claude.com/blog/new-in...
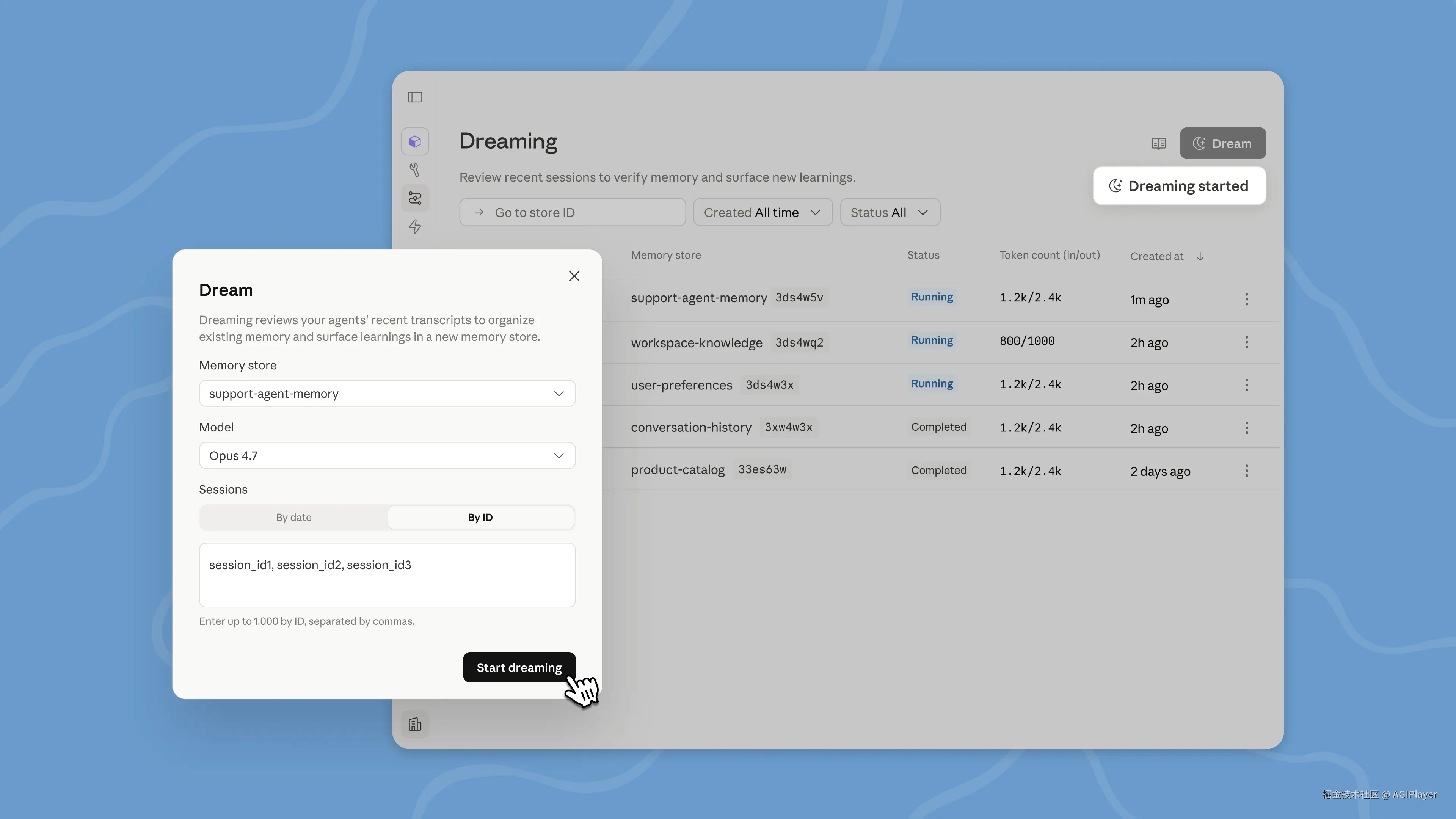
五、Dreaming 的输出:审查、使用、丢弃
Dream 完成后,outputs[] 里会有一个全新的 Memory Store ID。你可以:
直接使用------把它挂载到后续的 Session 中,替换或补充原来的 Memory Store
审查后使用------在 Console 里对比输入和输出的 Diff,确认没问题再用
直接丢弃------删掉或归档输出 Store,一切回到原样
在 Code with Claude 的演示中,Dreaming 跑了一晚上,审查了过去多个 Session,最终生成了一个 descent-playbook.md------一个整合了过往经验的操作手册。这个 Demo 虽然简单,但把核心价值讲清楚了:Dreaming 能从碎片化的经历中提炼出结构化的知识。
Wisedocs 的案例更实际。他们用 Managed Agents 做 50,000+ 份医疗文档的质量审查,Memory 用来维护 Agent 之间的共享问题清单和边缘案例。跑了一段时间后,Memory 里堆满了各种格式不一致、互相覆盖的条目。有了 Dreaming,这些条目可以被自动整理------去重、更新、归档。
六、不是孤例:为什么整个行业都在走向"离线反思"
Dreaming 不是 Anthropic 一家的想法。整个 Agent 工程领域都在往一个方向走:让 Agent 不只是执行,还能反思。
Anthropic 自己的工程博客其实一直在铺垫这个思路。
2025 年 11 月的《Effective Harnesses for Long-Running Agents》提出了 Initializer Agent + Coding Agent 的模式------用结构化文件(claude-progress.txt、feature_list.json)来在不同 Session 之间传递上下文。这本质上是用文件系统做 Memory,用人工设计做 Dreaming。
2026 年 3 月的《Harness Design for Long-Running Application Development》引入了 GAN 启发的 Generator-Evaluator 模式------生成器干活,评估器审查。关键发现是:Agent 自我评估根本不靠谱。官方原话是 "when asked to evaluate their own work, agents tend to respond by confidently praising the work---even when, to a human observer, the quality is obviously mediocre." 所以必须把生成和评估拆开。
2026 年 4 月的《Scaling Managed Agents: Decoupling the Brain from the Hands》提出了更底层的架构------Session 作为上下文对象存在于 Context Window 之外,通过 getEvents() 接口按位置切片查询。这为 Dreaming 铺了路:如果 Session 的完整历史可以被独立访问,那就可以在不影响运行时的情况下做离线分析。
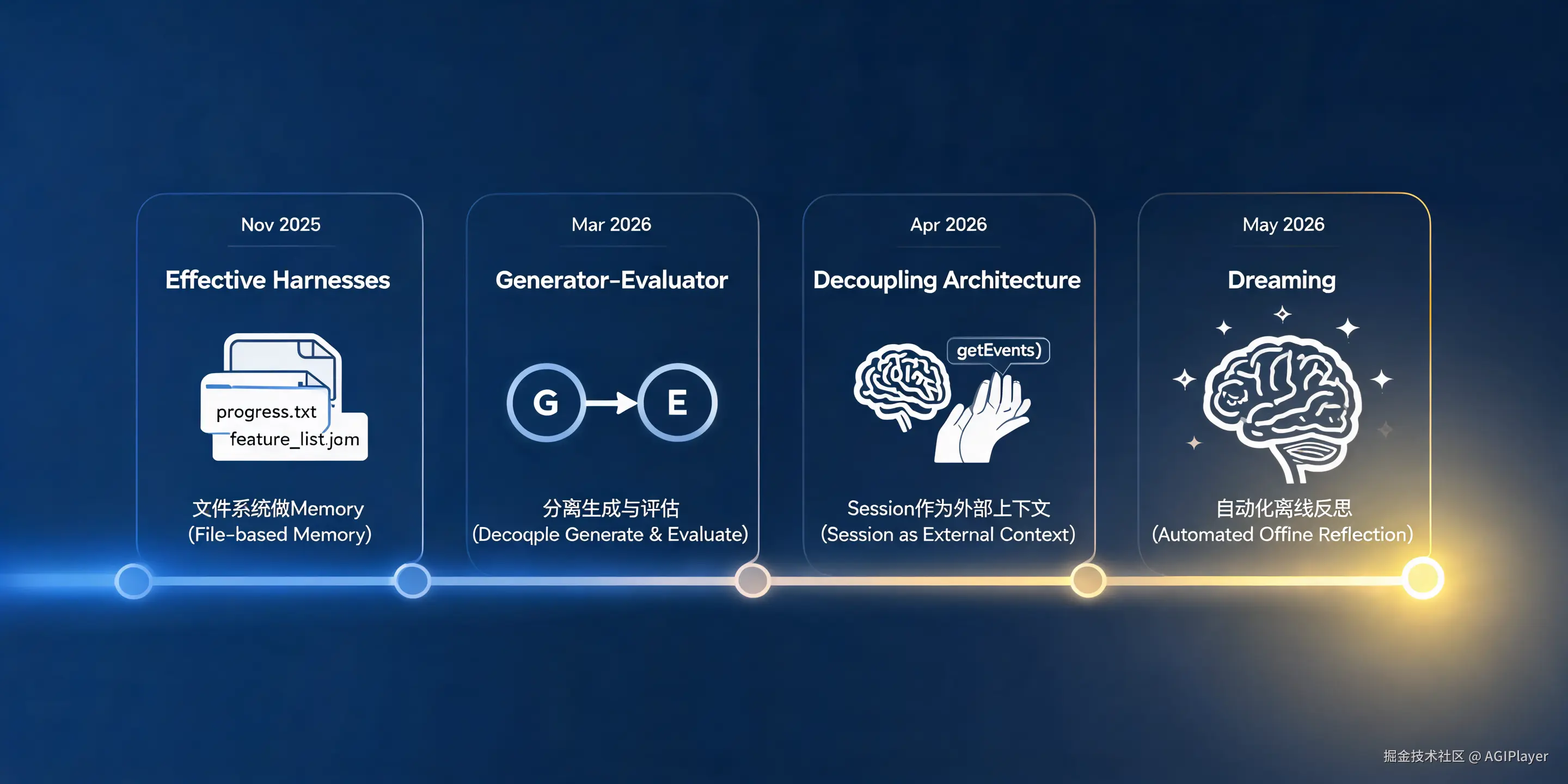
这三篇文章的演进逻辑是清晰的:从人工传递上下文 → 分离生成和评估 → 架构层面解耦上下文存储 → 自动化的离线反思。Dreaming 是这条线的自然终点。
同时期发布的 Outcomes 功能也体现了同样的哲学------让 Agent 有自我改进的能力。Outcomes 让你定义"成功是什么样子",一个独立的 Grader 在自己的 Context Window 里评估 Agent 的输出,不受 Agent 推理的影响。不符合标准就再来一轮。测试中,Outcomes 让任务成功率最高提升了 10 个百分点。
Memory + Dreaming + Outcomes,三个功能组合在一起,构成了一个闭环:工作中学 → 休息时反思 → 干活时自检。
七、客户案例:谁在用,效果如何
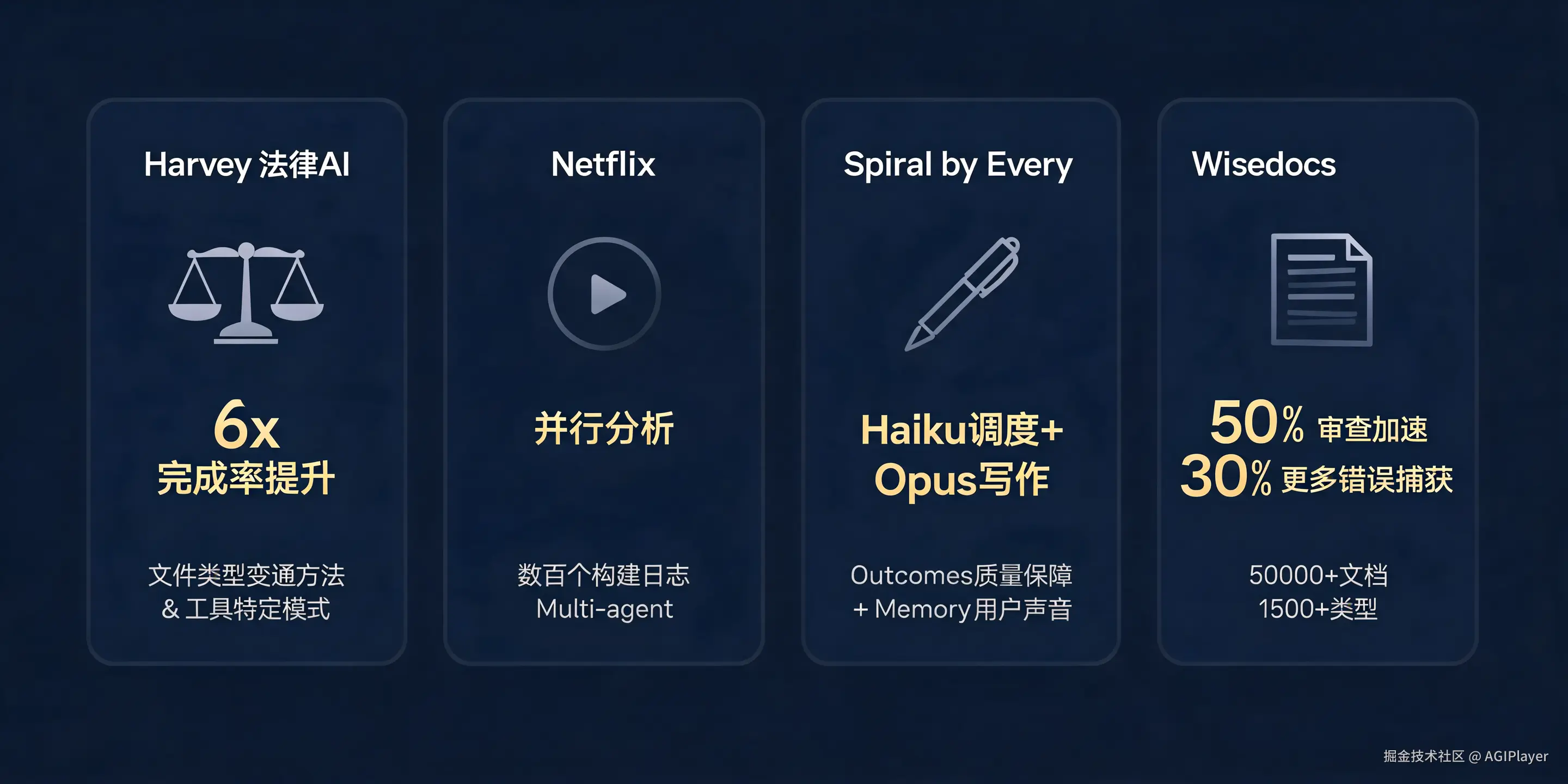
官方给了四个客户案例,但 Dreaming 相关的数据只有 Harvey 的比较具体。
Harvey (法律 AI):使用 Dreaming 后,Agent 记住了 Session 间学到的东西,包括文件类型的变通方法和工具特定的模式。完成率提升约 6 倍。这个数字挺惊人的,但说实话我有点想知道具体是什么任务上的 6 倍,官方没有给更多细节。
Netflix:平台团队构建了分析 Agent,处理数百个构建的日志。这个案例更多是 Multi-agent Orchestration 的场景------Agent 并行分析批次,浮现跨构建的模式。Dreaming 在其中的作用没有单独拎出来说。
Spiral (by Every):写作 Agent,Lead Agent 跑在 Haiku 上做调度,Subagent 跑在 Opus 上做写作。用 Outcomes 来保证写作质量,用 Memory 来存储编辑原则和用户声音。Dreaming 帮助维护 Memory 的质量。
Wisedocs :文档质量审查,用 Managed Agents + Memory + Outcomes。审查速度提升 50% ,多抓 30% 的错误。但他们的博客文章里没有提到 Dreaming,可能还没用上。
坦率讲,目前 Dreaming 的真实使用数据还很少。毕竟这功能 5 月 6 号才发布,还是 Research Preview 阶段,需要单独申请才能用。这些案例更像是早期内测的结果,而不是大规模验证。
八、局限与隐忧
我觉得有必要聊聊 Dreaming 目前的局限,而不是一味吹捧。
首先是访问限制。 Dreaming 是 Research Preview,不是 Public Beta。你得填表申请才能用。Simon Willison 在现场博客里还专门吐槽了这一点,说他也不太确定 Research Preview 和 Public Beta 到底有什么区别。
其次是成本。 Dream 按 API Token 标准费率计费,成本大致和输入 Session 的数量与长度线性相关。如果你有 100 个长 Session 要审查,一次 Dream 的费用不会便宜。官方的建议是从小批次开始,确认整理质量后再扩大规模。
第三是可控性。 Dreaming 的输出是另一个 Memory Store,你可以审查,但审查本身也有成本。如果你的 Memory Store 里有几百个文件,Diff 审查就不是一件轻松的事。目前没有看到自动化的审查流程或质量指标。
第四是安全风险。 Memory Store 如果被污染(通过 Prompt Injection),Dreaming 可能会把恶意内容"巩固"进新的 Memory。只读 Store 能缓解部分风险,但不能完全消除。这个问题在官方文档里有提示,但没有给出系统性解决方案。
第五是模型限制。 目前只支持 Opus 4.7 和 Sonnet 4.6。如果你还在用其他模型,等一等吧。
最后是哲学问题。 Dreaming 到底在多大程度上能提取出"真知识"而不是"统计噪声"?100 个 Session 的模式,有多少是真正的最佳实践,有多少只是巧合的重复?这个问题的答案,可能要等更多实战数据出来才知道。
九、API 全景:Dreaming 的完整接口
把 Dreaming 的 API 梳理一下,给准备上手的同学一个参考。
| 端点 | 方法 | 用途 |
|---|---|---|
/v1/dreams |
POST | 创建 Dream |
/v1/dreams/{id} |
GET | 查询 Dream 状态 |
/v1/dreams/{id}/cancel |
POST | 取消 Dream |
/v1/dreams/{id}/archive |
POST | 归档已完成的 Dream |
/v1/dreams |
GET | 列出所有 Dream |
创建 Dream 的完整参数:
python
dream = client.beta.dreams.create(
inputs=[
# 必需:要审查整理的 Memory Store
{"type": "memory_store", "memory_store_id": store_id},
# 可选:最多100个 Session 的历史记录
{"type": "sessions", "session_ids": [s1, s2, s3]},
],
# 指定运行 Dreaming 的模型
model="claude-opus-4-7",
# 可选:引导 Dreaming 方向的指令
instructions="Focus on coding-style preferences; ignore one-off debugging notes.",
)轮询等待结果:
python
while dream.status in ("pending", "running"):
time.sleep(10)
dream = client.beta.dreams.retrieve(dream.id)
print(f"status={dream.status} input_tokens={dream.usage.input_tokens}")使用输出:
python
# 拿到输出 Memory Store 的 ID
output_store_id = next(
output.memory_store_id for output in dream.outputs if output.type == "memory_store"
)
# 挂载到新的 Session
session = client.beta.sessions.create(
agent=agent_id,
environment_id=environment_id,
resources=[
{"type": "memory_store", "memory_store_id": output_store_id},
],
)错误类型也值得了解:
| 错误类型 | 触发条件 |
|---|---|
timeout |
Pipeline 超出运行时间预算 |
internal_error |
未分类的 Pipeline 故障 |
memory_store_org_limit_exceeded |
组织 Memory Store 数量达到上限 |
input_memory_store_too_large |
输入 Store 超过大小限制 |
input_memory_store_unavailable |
输入 Store 在运行期间被归档或删除 |
input_session_unavailable |
输入 Session 在运行期间被归档或删除 |
如果 Dream 失败或被取消,输出 Store 会保留已写入的部分内容,你可以检查它然后决定清理还是保留。
十、Managed Agents 的更宏观视角
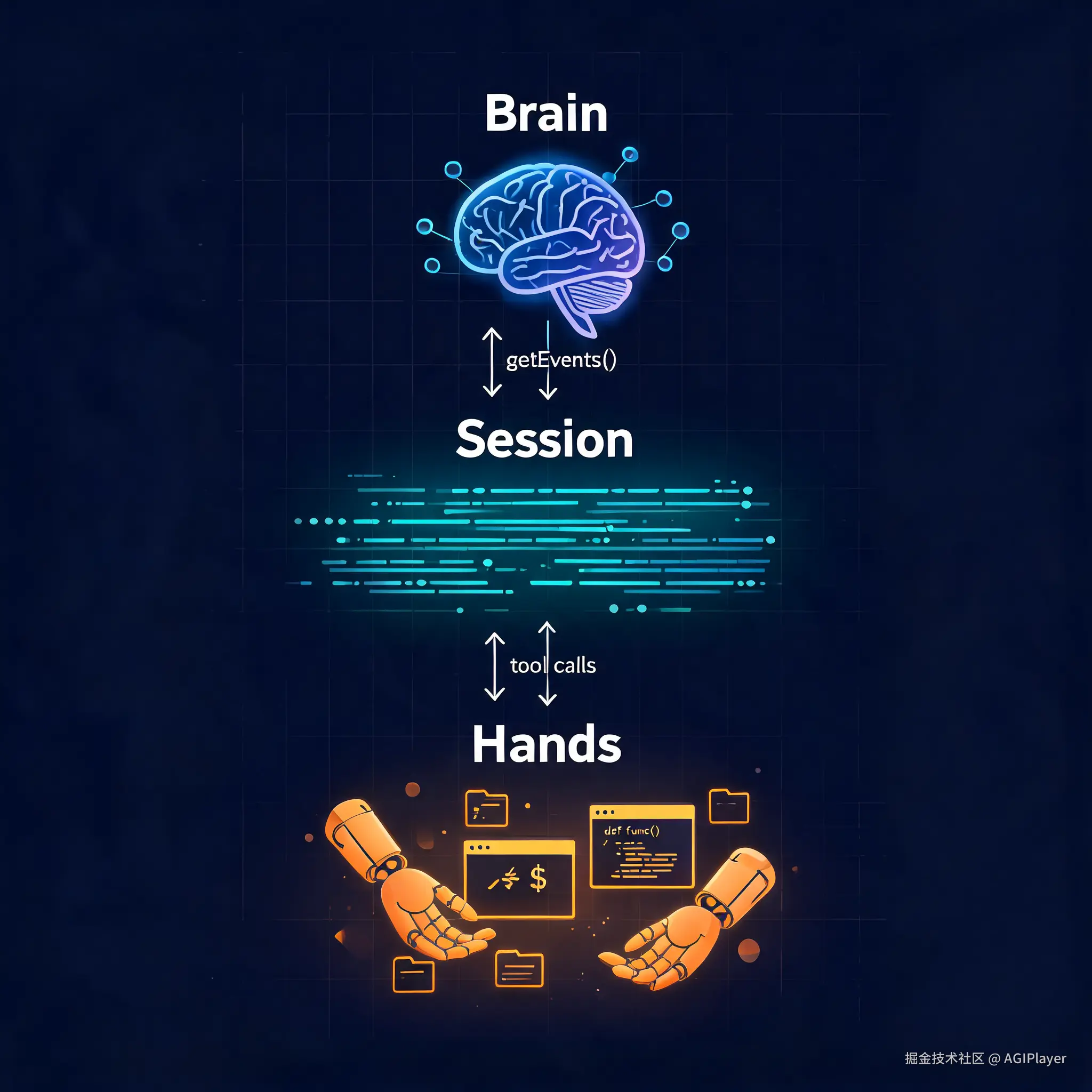
Dreaming 不是孤立的功能,它是 Claude Managed Agents 平台的一部分。不理解 Managed Agents 的整体架构,很难理解 Dreaming 为什么这样设计。
Managed Agents 的核心哲学是"解耦大脑与双手"。Session 是所有事件的追加日志,Harness 是调用 Claude 并路由工具调用的循环,Sandbox 是执行环境。三者通过少量接口连接,各自可以独立替换。
这个架构的一个直接收益是性能:p50 TTFT 下降约 60%,p95 下降超过 90%。因为容器不再需要在 Agent 启动前就准备好------Brain 可以先跑,等需要执行代码时再 Provision 容器。
Dreaming 依赖的正是这种架构。Session 的完整事件流被持久化存储在 Session Log 中,可以通过 getEvents() 接口按位置切片查询。这为离线分析提供了基础------Dreaming 不需要 Agent 正在运行,它只需要访问 Session 的历史记录。
安全边界也是关键设计。在 Managed Agents 的架构中,凭证永远无法从 Agent 运行代码的 Sandbox 中访问。OAuth Token 存储在安全保管库中,Agent 通过专用代理调用工具。这个设计同样保护了 Dreaming 过程------即使 Dream 的底层 Session 能访问工具,也不会泄露凭证。
十一、回到开头:这事儿到底意味着什么
说回来,Dreaming 这个功能为什么让我觉得有意思?
不是因为它技术多复杂------本质上就是个异步 Job,读一堆 Session 和 Memory,写出一个新的 Memory Store。技术上没什么黑魔法。
让我觉得有意思的是它背后的认知:Agent 的记忆需要主动维护,不能只靠被动累积。
这跟人类认知的规律是完全一致的。你的大脑不会把每天经历的所有事情原样存储,它会在睡眠中筛选、压缩、重组。丢失细节,保留结构。这不是 Bug,是 Feature------如果你把所有细节都留着,你根本找不到重要的东西。
Agent 也是一样。Memory Store 里堆积的重复、矛盾、过时条目,不只是"不整洁"的问题------它会直接影响 Agent 的行为质量。一个记了一堆互相矛盾指令的 Agent,比一个什么都不记的 Agent 还糟糕。
Dreaming 的价值在于:它把"记忆维护"从开发者的手动工作变成了自动化流程。你不需要写脚本去清理 Memory,不需要人工审查每一条记忆是否还准确。Agent 自己在"做梦"的时候就把这事干了。
当然,目前这个功能还很早期。Research Preview 意味着 API 可能会变,效果还没有被大规模验证,成本也需要更多实测数据。但方向我觉得是对的------Agent 的自我改进不能只靠更好的 Prompt,还需要系统化的记忆管理。
Anthropic 的产品负责人 Dianne Na Penn 在大会上说了句话我觉得挺好:"Design for the next model。" 意思是,按下一个模型的水平来设计你的系统,那些现在勉强失败的方案,等模型升级后就能跑通。
Dreaming 可能就是这样一个设计。今天它的效果可能还不完美------提炼出来的洞察可能不够准,去重可能不够干净,成本可能偏高。但随着底层模型变强,这个自动化的记忆维护流程会越来越可靠。
到那时候,Agent 真的能在"梦里"学会做事。
参考资料
- New in Claude Managed Agents: dreaming, outcomes, and multiagent orchestration --- Anthropic 官方博客
- Dreams API 文档 --- Claude Platform 官方文档
- Using Agent Memory 文档 --- Claude Platform 官方文档
- Scaling Managed Agents: Decoupling the Brain from the Hands --- Anthropic 工程博客 (2026.4.8)
- Harness Design for Long-Running Application Development --- Anthropic 工程博客 (2026.3.24)
- Effective Harnesses for Long-Running Agents --- Anthropic 工程博客 (2025.11.26)
- Simon Willison: Code w/ Claude 2026 现场博客
- Claude 官方 X 发布 --- @claudeai
- Wisedocs: Agentic Document Verification with Claude Managed Agents
- Agents for Financial Services --- Anthropic 官方博客
- Managed Agents Overview --- Claude Platform 文档
话题标签:#Claude #ManagedAgents #Dreaming #AIAgent #Anthropic #Agent架构 #记忆系统