校对通更新!告别反复转格式 PDF图文/扫描件一键校对
编辑们大概都有过这样的经历:收到一份图文并茂的PDF,正文要校对,图片里的文字、画面、标注、说明也得逐一核查。偏偏很多办公软件不支持直接校对,流程就变成了------先截图或扫描保存成其他格式,运气不好的话转换后会破坏原有排版,还得人工调整、粘贴图片然后重新核对。校对通本次更新,上线三大实用功能,不用转格式、不用拆文件,只需上传就能完成校对。
一、PDF图文混合校对:文件上传即校、无需转换格式
无需转换格式,无需额外步骤,直接上传,系统即可对PDF中的文字与图片同步完成校对。目前这一功能暂不扣除图片权益,编辑可以放心使用。
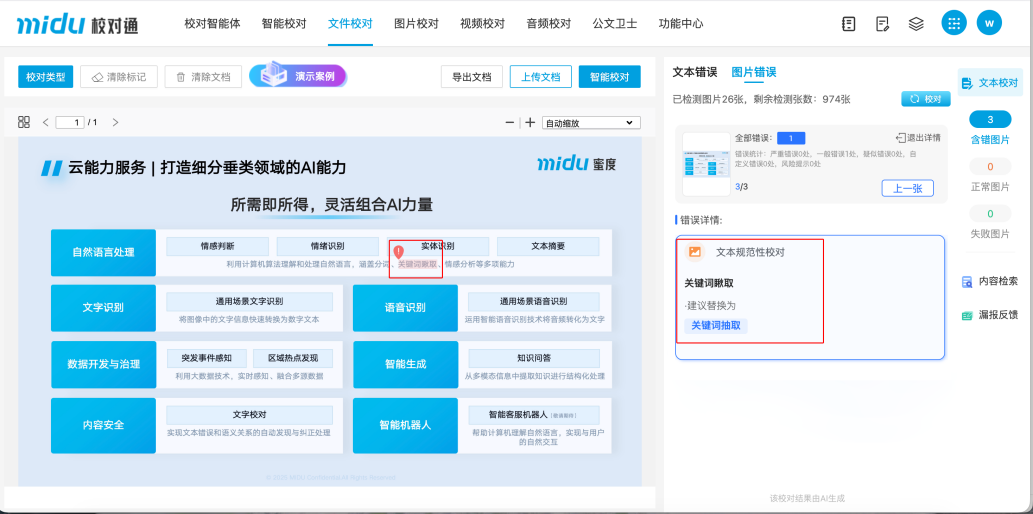
(校对通PDF图文混校)
这一能力为编辑的实际工作场景提供了切实支持:如新媒体运营人员在处理图文混合的专题稿件时,可以直接上传原始PDF进行校对,导出勘误表即可,无需再逐张导出图片分别处理;出版编辑在校对含有大量图表的书稿时,也能直接以原始版式为底稿进行审核,省去因格式转换带来的大量修复工作;新闻媒体从业者在处理带图新闻稿时,同样可以一步到位完成校对。
对于长期需要处理图文混合文档的编辑来说,这个功能解决的是一个很具体的问题:以前必须借助插件或额外操作才能完成的工作,现在在网页端点点鼠标就能搞定,省略了中间那些"先转成Word、再排版、再检查格式"的繁琐动作。
二、PDF扫描件直接校对:拍照、扫描的纯图片文件也能校
在实际工作中,很多PDF不是直接Word生成的,而是扫描书稿、拍照存档后导出的,相当于纯图片,一些系统识别不到文本,也就没办法直接校对。
现在,校对通支持对扫描件进行识别并校对。即使是老旧书籍、打印版或拍照保存的文件,也能精准识别,还支持导出勘误表。
以企业为例,打印版文件以往都需要人工逐页核对,现在上传扫描件即可校对,内容中的问题逐页标出,校对结果清晰呈现、一目了然。
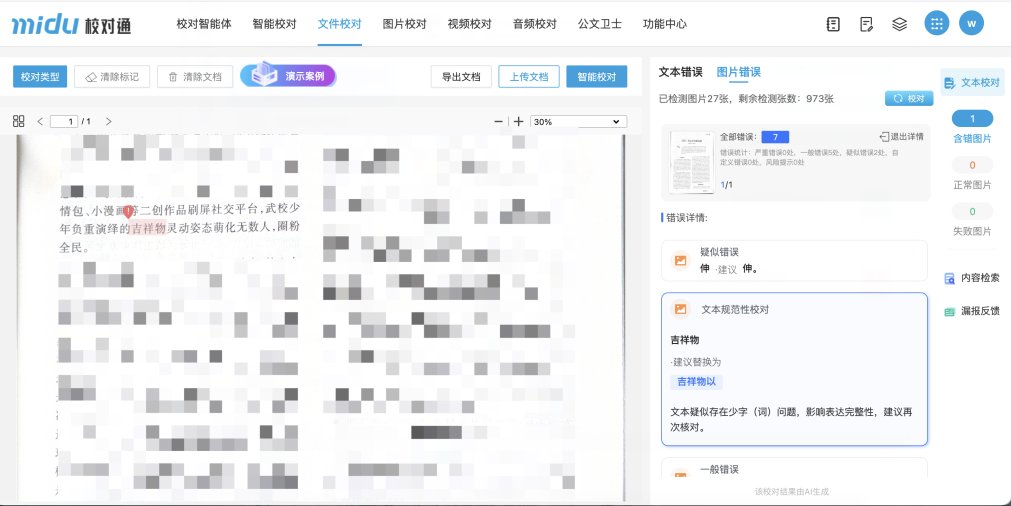
(PDF扫描件校对)
三、自定义人物图片识别:人名、职务等信息智能核验
在重要报道、宣传物料的发布前审核中,画面里的人物与姓名等信息是必须严格检查核验的一项。传统的做法需要人工对照、逐一确认,当素材量大的时候,这一步既耗时又容易疏漏。
现在,用户可预先上传人物相关信息,校对通在处理图片或视频时,会自动检测画面中是否出现该人物,并对人物姓名、职务等信息作出核验提示。这项能力适用于新闻图片、活动现场图、宣传海报等多种场景,主要帮助用户解决"发布前快速核验"这个需求。
以媒体报道为例,在发布活动的图文报道前,经常需要逐一核实画面中人物的姓名、单位与职务信息。通过自定义素材库,校对通可以在审核环节帮助用户完成这一核查,大幅减轻人工核对的负担。
四、智能体升级+能力接口开放内容校对更轻松
智能体模块升级为默认全开全量校对能力,不受其他模块配置影响,同时新增图文共校能力,可自动输出勘误表与校对批注稿,减少了编辑手动整理的工作量。对于论文写作与图书出版等需要保留完整审稿记录的场景,这一功能尤为实用。
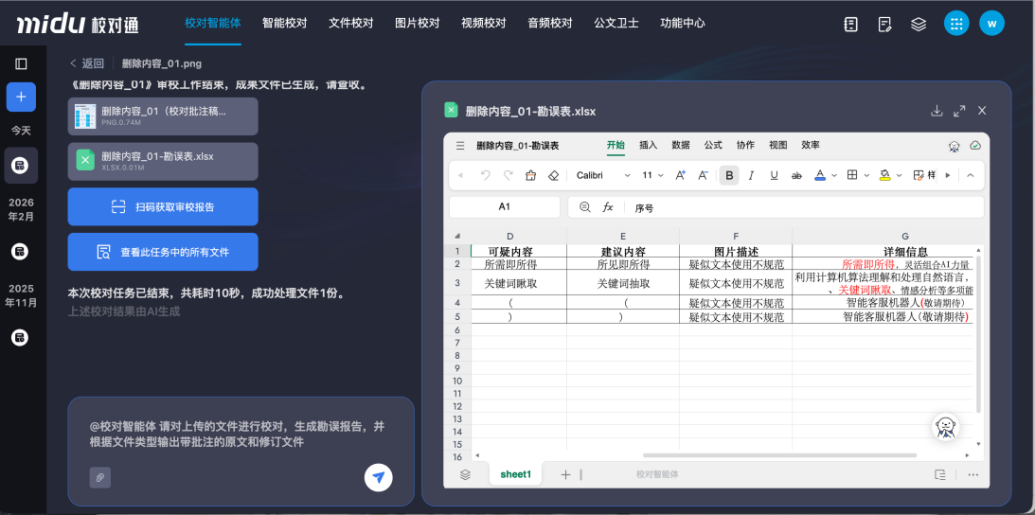
(校对智能体自动输出勘误表)
此外,校对通本次同步新增了能力接口,支持文档、图片、音视频类文件快速调用校对服务。这意味着企业用户可以将校对能力集成到自有办公系统中,实现更灵活的工作流适配。后续,平台还将陆续上线面向更多垂直场景的AI能力调用服务,其中就包括智能校对的深度定制能力。