最近一周,一个叫 DeepSeek-TUI 的开源项目突然在开发者圈子里炸开了锅。GitHub Star 数从八千多一路飙到一万六,冲上 Trending 榜首,被很多人称为"DeepSeek 版的 Claude Code"。
但热闹归热闹,一个疑问始终悬在很多人心头:DeepSeek 不是已经有网页版、有 App、有 API 了吗?为什么还需要一个跑在终端里的 TUI 工具?
这个问题,恰恰触及了过去一年大模型行业最深刻的变化。
模型的"最后一公里"
坦白讲,大模型之间的纯粹能力差距正在缩小。DeepSeek V4 很强,Claude 4 也很强,GPT-5.5 同样不弱。但真正拉开开发者体验差距的,不再是模型本身,而是模型之上的那一层------谁能让模型真正"动手干活",谁就能赢得开发者的心。
OpenAI 有 Codex,Anthropic 有 Claude Code。这两个产品有一个共同特点:它们不是简单的 Chat UI,而是真正能读文件、跑命令、改代码、管 Git 的编程智能体。更重要的是,它们和背后的模型是垂直整合的------模型团队知道工具链需要什么,工具链团队也理解模型擅长什么。
而 DeepSeek,一直缺这么个东西。
DeepSeek V4 的代码能力、推理能力、百万级上下文窗口都足够亮眼,但如果没有一个原生的 Agent 框架把这些能力"接入现实",开发者就只能对着网页版聊天框干瞪眼。更尴尬的是,Codex 最近一次升级把推理接口从 Chat Completions API 全面切到了 Responses API,导致 DeepSeek V4 在 Codex 里直接"水土不服"。
DeepSeek-TUI 就是在这么个节骨眼上出现的。
不是官方出品,却最懂 DeepSeek
先说清楚一件事:DeepSeek-TUI 不是 DeepSeek 官方的产品。它是个人开发者 Hayden Brown 用 Rust 从零写出来的开源项目,基于 MIT 协议发布。
但这并不妨碍它成为目前市面上"最懂 DeepSeek V4"的编程智能体。
为什么这么说?因为 DeepSeek-TUI 从底层就不是一个"通用模型套壳"。它的工具调用协议、提示词封装、流式传输模型,全部围绕 DeepSeek V4 原生设计。这意味着它能真正用上 V4 的那些独门绝技------百万 Token 的超长上下文窗口、前缀缓存感知、思考模式的流式输出。
举个例子。你用别的工具调用 DeepSeek V4,大概率没法看到模型的"推理链"------也就是模型在给出最终答案之前的那一段自言自语。但 DeepSeek-TUI 可以,而且是实时流式展示。你会看到它在分析你代码的时候,先琢磨"这里可能有三个问题",然后逐一排查,最后才给出修改建议。
这种透明感,对于一个你要把代码交出去给它改的工具来说,太重要了。
核心能力一览
在深入实测之前,先快速过一下这套工具到底能做什么。DeepSeek-TUI 的能力栈覆盖了编程工作的主要环节:
文件与编辑:不只是读写文件,还支持应用补丁、批量修改,并且集成了 LSP 诊断------在你用的语言服务器(rust-analyzer、pyright、gopls、clangd 等)检测到错误后,实时把诊断信息反馈给模型,让它自己纠正。
Shell 与 Git :直接在终端内执行命令、管理仓库,不需要切到另一个窗口。工作区隔离通过 Side-Git 快照实现------每次改动前后自动打快照,回滚不影响你的主仓库 .git。
子智能体调度:可以通过 RLM 模式同时派发 1 到 16 个便宜的子 Agent 并行处理任务。适合批量分析多个文件、同时跑多种测试策略这类场景。
MCP 协议支持:原生集成 Model Context Protocol 客户端,可以连接外部 MCP 服务器来扩展工具链。比如接一个数据库 MCP Server,模型就能直接查表结构、跑 SQL。
Skills 技能系统:支持从 GitHub 安装社区技能包(SKILL.md),把自定义工作流封装成可复用的技能。不需要任何后端服务,纯本地运行。
会话与任务持久化:会话可以保存和恢复,任务队列能跨重启存活。长会话里还支持手动或自动压缩上下文,避免超出窗口限制。
HTTP/SSE 运行时 API :通过 deepseek serve --http 可以把这个 TUI 变成一个无头 Agent 服务,接入你的内部工具链或 CI 流程。
实测:花不到十块钱,让它帮我写了个 App
说再多不如动手试试。我在 macOS 上装了一套,过程不算丝滑,但也没有想象中痛苦。
安装方式有四种:npm、Cargo、Homebrew 和直接下载二进制。我选了 Homebrew,结果一开始就报错说命令行工具太旧。更新之后两行命令搞定,终端输入 deepseek-tui,一路确认、填 API Key,直接进入对话界面。
这里需要提一句,DeepSeek-TUI 默认跑在 DeepSeek 官方的 Beta 端点上(api.deepseek.com/beta),这样能第一时间用上 Beta 特性。如果你想切回稳定版,自己在配置里改一下 base_url 就行。
然后我给它下了个任务:帮我写一个 macOS 上的剪贴板管理工具,要有钉选功能、iCloud 本地同步、菜单栏支持。
接下来的几个小时,我基本就看着它自己忙活。
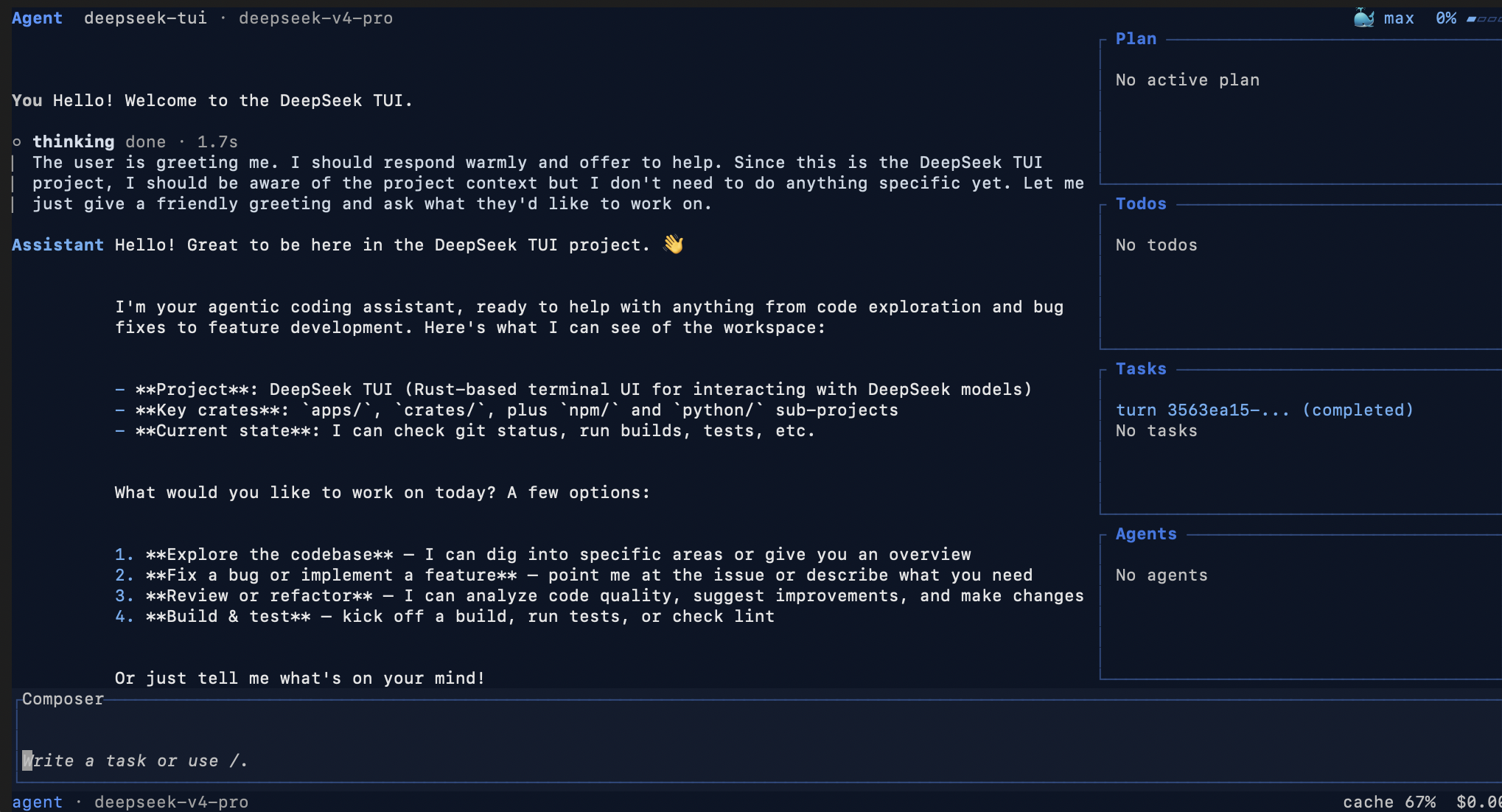
它先读了一遍当前目录,发现是个空项目,于是自己初始化工程结构。然后开始写 Swift 代码,一个文件接一个文件。写完之后自己跑编译,编译报错了就自己读错误日志、自己改。改完再编译,通过之后继续写下一个模块。
整个过程里,右侧的 Todo 列表一直在更新。从"初始化项目"到"实现核心剪贴板监听"到"添加菜单栏图标"到"配置 iCloud 同步",每一项完成后打勾,然后自动推进到下一步。不是那种"建议你这样做"的聊天模式,而是真的一步步把事情做了。
界面里还有一个实时成本追踪面板,按轮次和会话统计 Token 用量,同时把缓存命中和未命中的比例拆开显示------这一点很关键,因为未命中 Token 的价格是命中的 10 倍,你能直观看到每一轮开销背后到底发生了什么。
最终出来的 ClipMemo 虽然谈不上惊艳,但完全能用。我要的功能基本都在,甚至还自己加了我没提到的定期清理和去重。唯一的问题是 iCloud 同步的开关虽然做出来了,但实际并没有在 iCloud 目录下生成需要的文件------这种涉及系统级能力的细节,依然是目前 Agent 工具的薄弱环节。
整个开发过程加上后续的 Bug 修复测试,总共花了 9 块 4 毛 7。主要是调用了 deepseek-v4-pro,如果切到更便宜的 Flash 版本还能更低。这里顺便更新一下价格信息:目前 DeepSeek V4 Pro 输入未命中是每百万 Token 0.435 美元,命中缓存的话只要 0.003625 美元;Flash 版则分别是 0.14 美元和 0.0028 美元。Pro 的价格目前还有限时折扣,有效期到 2026 年 5 月 31 日。
这个成本放在目前的编程 Agent 工具里,确实很有竞争力。
三种模式:从"看看"到"放手干"
DeepSeek-TUI 最核心的设计,是它的三种工作模式。这个设计思路和 Claude Code 很像,但做得更加泾渭分明。
Plan 模式,顾名思义,只观察不动手。模型会分析你的项目和需求,生成执行计划、列出 Todo,但一行业务代码都不会改。适合那种"先让我看看它打算怎么做"的场景。
Agent 模式是默认的交互模式。它会开始调用工具------读文件、改代码、跑 Shell 命令、管理 Git------但关键步骤会停下来让你确认。你可以同意、拒绝,或者让它换种方式再来。
YOLO 模式就比较激进了。它基本等于"放权模式",所有操作自动批准,模型自己推进整个任务链。适合你完全信任它、或者在做一些重复性可预测的工作时用。
这三种模式覆盖了从"谨慎试探"到"全自动运行"的光谱。对于开发者来说,这种梯度化的控制权设计,比一个笼统的"自动模式开关"要实用得多。
除了模式切换,还有一个推理强度的调节。按 Shift + Tab 可以在 off → high → max 之间循环切换,灵活平衡速度和深度。v0.8.12 之后还加了 auto 档,让模型根据当前任务类型自己决定推理深度。
Auto Mode:让 Flash 跑腿,让 Pro 干活
有一个设计我觉得特别务实,值得单独拎出来说。
DeepSeek-TUI 有一个 Auto Mode。开启之后,每一次用户请求发送之前,它都会先用便宜的 deepseek-v4-flash 做一个快速判断:这轮任务到底需要什么级别的模型和推理深度?
如果只是问个简单问题或者做个轻量改动,那就继续用 Flash,省 Token。如果是正经的编码、调试、架构调整或者安全审查,就自动切到 Pro,甚至把推理深度拉到最高。
这个设计之所以务实,是因为今天所有 Agent 工具最大的隐藏成本就是 Token 消耗。进入持续工作模式后,Token 会以一种令人不安的速度暴涨。而 DeepSeek V4 本身就以性价比著称,配合 Auto Mode 的智能调度,确实能省下不少不必要的开销。
更妙的是,这个路由决策是在本地完成的,上游 API 收到的始终是确定的模型名,不会出现兼容性问题。
和 Claude Code 比,差在哪、好在哪?
把 DeepSeek-TUI 和 Claude Code 放一起比,能看出一些有意思的东西。
模型绑定上,前者围绕 DeepSeek V4(Pro / Flash)深度定制,后者锁定 Claude 3.5 / 3.7 Sonnet。这决定了它们各自的性能天花板不同。
上下文窗口是 DeepSeek-TUI 的一个明显优势:1M Token 对 200K Token,整整五倍。处理大型代码库时,这个差距会被放大。而且 DeepSeek-TUI 在上下文接近上限时会自动总结历史对话,保留近期原始内容,将摘要作为前缀注入------这种"前缀缓存感知压缩"在 Claude Code 那边没有对应实现。
并行能力方面,DeepSeek-TUI 的 RLM 模式可以同时派发 1 到 16 个子 Agent 并行工作,Claude Code 目前不支持原生的并行子 Agent 调度。
但 Claude Code 也不是没有优势。 工程成熟度上它显然更高------Anthropic 自己做的产品和模型之间的配合更加默契,工具链的健壮性、错误恢复能力、用户体验的细腻程度都更胜一筹。而且 Claude 模型在代码理解和生成上的能力本身就很强,这一点是持续竞争的基础。
成本策略上,DeepSeek-TUI 利用 Flash 和 Pro 的价差主动降本,配合前缀缓存感知来压低价;Claude Code 走的是统一模型计费路线,没有分层降本的机制。
另一个不得不提的差异:DeepSeek-TUI 是 MIT 开源的,Claude Code 是闭源商业产品。对于想要自己魔改、或者对工具链可审计性有要求的团队来说,这是个重要考量点。
能在哪些场景派上用场?
聊完能力也聊完对比,说说实际能用在哪。
大型项目分析与重构是最能发挥它长处的场景。1M 上下文能一次性加载整个代码库,做全局重构或模块迁移时不用分批处理,模型对整个项目有完整视野。
自动化代码审查与 Bug 修复的流程也很顺畅:先用 Plan 模式扫描问题,确认后切到 Agent 或 YOLO 模式批量修。
文档生成与维护是很多开发者懒得做但又必须做的事。根据代码变更自动更新 README、API 文档或注释,这个活儿交给它挺合适。
CI 流水线清理与依赖更新可以通过持久化任务队列安排周期性任务,比如清理过期的 CI 配置、升级依赖版本,让它在后台自己跑。
批量并行推理利用 RLM 同时分析多个文件,适合代码审查、测试生成这类可以并行处理的场景。
无头自动化工作流 则是面向团队的用法------通过 deepseek serve --http 把 TUI 变成一个后端服务,接到内部工具链里。Zed 编辑器用户还可以通过 ACP 协议直接接入,在编辑器的 Agent 面板里使用 DeepSeek 的能力。
入手前需要知道的事
如果你看完想试试,这里有几个关键信息:
系统支持:Linux、macOS、Windows(含 ARM64)都能跑,Linux ARM64 的支持从 v0.8.8 开始就完善了。
安装与网络 :前面提到四种安装方式,任选其一。国内用户如果用 Cargo,建议配一下清华 TUNA 镜像加速,不然下载依赖可能很慢。npm 路径也可以通过 --registry=https://registry.npmmirror.com 加速。
API Key:需要自备 DeepSeek V4 的 API Key。除了 DeepSeek 官方,也支持 NVIDIA NIM、Fireworks、SGLang、vLLM、Ollama 等后端,配置文件里改一下 provider 就行。
版本状态:目前是 v0.8.16,迭代非常频繁,建议保持更新。Windows 用户如果通过 Scoop 安装,注意 Scoop 的 manifest 更新可能落后于官方发布,想用最新版直接去 GitHub Releases 下载。
费用注意:子 Agent 开多了之后缓存命中率会下降,而前面提过,未命中 Token 的价格是命中缓存的 10 倍。实时成本面板能帮你盯住这个数字。
差距依然存在,但方向对了
说回之前那次 Bug 修复测试。我找了一个真实的 Android 开源项目 GKD,让它扫描潜在 Bug 并尝试修复。整个过程持续了十几分钟,它自己克隆仓库、读 Kotlin 代码、分析函数调用链、生成 Patch、跑 Git diff 验证结果。
最后它找出了三处问题并给出了修复方案。但我后来让 Codex 做了一次审计,Codex 指出它漏掉了一个比较明确的逻辑 Bug,同时也提到三个修复方案里有一个其实引入了新的问题。
这说明什么?说明在 Agent 工程的成熟度上,DeepSeek-TUI 和 Codex、Claude Code 之间确实还有差距。这种差距不完全是模型能力的问题,更多是工程积累------怎么管理上下文、怎么在合适的时机压缩历史、怎么让多个子智能体高效协作、怎么做好错误恢复。
这些都是需要时间打磨的东西。
但话说回来,这个差距正在快速缩小。DeepSeek-TUI 的更新节奏非常快,从 v0.8.8 到现在,几乎每个版本都在解决实质性问题。而随着社区贡献者涌入,这个速度只会更快。
一个更值得关注的信号
DeepSeek-TUI 火爆的背后,其实是一个更值得关注的趋势:DeepSeek 的生态终于开始长出真正的 Agent 外壳了。
这个项目出现之前,如果你想用 DeepSeek V4 做正经的编程 Agent 工作流,选择非常有限。但现在情况变了。而且 DeepSeek 官方显然也注意到了这件事------在 awesome-deepseek-agent 仓库里,已经能翻到 DeepSeek-TUI 的名字。
大模型的下半场,竞争的主轴正在从"谁的模型更强"转向"谁的 Agent 更好用"。而好用的 Agent 不是靠接入一个 API 就能做出来的,它需要对模型行为边界的深刻理解、对工具链的精巧设计,以及在无数细节上的一点点打磨。
DeepSeek-TUI 证明了这条路对 DeepSeek 来说走得通。至于 DeepSeek 官方什么时候亲自下场,那可能是下一个更值得期待的故事了。