Scaling-Aware Data Selection for End-to-End Autonomous Driving Systems
核心信息
- 论文ID :arXiv:2604.08366 - 作者 :Tolga Dimlioglu (NYU/NVIDIA), Nadine Chang, Maying Shen, Rafid Mahmood (NVIDIA/U. Ottawa), Jose M. Alvarez (NVIDIA) - 机构 :New York University, NVIDIA, University of Ottawa - 发布时间 :2026-04-09 - 会议/期刊 :CVPR 2026 - 链接:arXiv(https://arxiv.org/abs/2604.08366) | PDF(https://arxiv.org/pdf/2604.08366)
abstract: 一句话总结
自动驾驶训练数据太多训不动?MOSAIC 把数据按场景分堆,估算每堆数据对驾驶评分的"性价比",然后专挑性价比高的数据来训练------用五分之一的数据就能训出比随机选数据更好的模型。
研究出发点与核心收益
question: 研究出发点
端到端自动驾驶系统的训练数据来自各种驾驶场景------不同城市、天气、交通密度------但不可能把所有数据都拿来训练,因为计算成本不可承受。更关键的是,不同驾驶片段对 9 项规则合规指标的贡献各不相同:某些片段对车道保持提升大,某些对碰撞避免更有效。现有数据混合方法(DoReMi, DOGE, Chameleon)要么假设数据域天然可分且同质(这在驾驶数据中不成立),要么无法处理"同一条数据影响多个相互竞争的指标"这一核心难题。
check: 核心收益
- 数据效率:用不到随机选择 20% 的数据就能达到同样好的驾驶评分------别人用 1000 条数据训出来的水平,MOSAIC 只要 150-180 条
- 绝对性能:不管给多少数据预算,MOSAIC 选出来的数据训出的模型都比其他方法好约 1 个百分点
- 方法创新:核心思路是"先分堆、再估算每堆的性价比、最后专挑性价比高的"------这个"性价比"就是 scaling law,它预测"这堆数据再加一条,模型能提升多少"
开篇总述
这篇论文要解决的问题是:自动驾驶模型训练数据太多,训不动,怎么从中挑出最有用的那一小部分?
这个问题的难点在于,自动驾驶的评估不是看一个分数,而是看 9 个分数的综合------不撞车、车道保持、舒适度、红绿灯合规等等。关键矛盾是:某段驾驶视频可能对"不撞车"很有帮助,但对"车道保持"没啥用。所以你不能简单地说"选最难的数据"或者"选最多样的数据",你得回答一个更精确的问题:在当前阶段,从哪堆场景数据里再加一条,对整体评分的提升最大?
MOSAIC 的做法分三步。第一步 ,把数据池按场景分成几堆(按城市、按场景描述、按驾驶类型都行),每堆里面按"模型在这些场景上表现多差"排序------越差的排越前面。第二步 ,对每一堆,用少量训练实验(叫 pilot run)测出一条"性价比曲线":加 100 条能提升多少?加 200 条呢?这条曲线用饱和指数函数拟合,特性是"刚开始提升快,越往后提升越慢"------很直觉,好学的先学会了,剩下的越来越难。第三步,选数据的时候,每次都从"多加一条提升最大"的那堆里取一条,取完重新算一遍各堆的性价比,再取。就这样一条一条选,直到用完预算。
实验表明这个方法有几个好性质:数据越少的时候优势越大(因为"选对数据"在资源紧张时更重要);对聚类方式不挑剔(按城市分、按语义描述分、按驾驶类型分都行);而且选出来的数据训出的模型,在 9 个子指标上不是某个特别好其他很差,而是策略性地优先提升最拖后腿的那个指标。
摘要翻译
英文摘要
Large-scale deep learning models for physical AI applications depend on diverse training data collection efforts. These models and correspondingly, the training data, must address different evaluation criteria necessary for the models to be deployable in real-world environments. Data selection policies can guide the development of the training set, but current frameworks do not account for the ambiguity in how data points affect different metrics. In this work, we propose Mixture Optimization via Scaling-Aware Iterative Collection (MOSAIC), a general data selection framework that operates by: (i) partitioning the dataset into domains; (ii) fitting neural scaling laws from each data domain to the evaluation metrics; and (iii) optimizing a data mixture by iteratively adding data from domains that maximize the change in metrics. We apply MOSAIC to autonomous driving (AD), where an End-to-End (E2E) planner model is evaluated on the Extended Predictive Driver Model Score (EPDMS), an aggregate of driving rule compliance metrics. Here, MOSAIC outperforms a diverse set of baselines on EPDMS with up to 80% less data.
中文翻译
训练物理 AI 系统需要从各种场景采集海量数据。这些系统好不好用,得看多项指标的综合表现。数据选择策略能帮我们决定"哪些数据该拿来训练",但现有方法都忽略了一个关键问题:同一条数据对不同指标的影响是不一样的------某段驾驶视频可能对"不撞车"很有帮助,但对"车道保持"没啥用。
本文提出 MOSAIC 框架来解决这个问题。它的做法分三步:第一步,把数据池按场景分成几堆(比如按城市分);第二步,对每一堆数据,用少量训练实验估算出一个"性价比曲线"------即"从这堆数据多加 N 条,模型评分能提升多少";第三步,每次挑一条数据时,都选"加了之后模型提升最大"的那堆里的下一条。把这个框架用在自动驾驶上,以驾驶规则综合评分(EPDMS)来衡量模型好坏。结果:MOSAIC 用最多 80% 更少的数据就超越了所有对比方法。
核心要点提炼
- 研究背景 :自动驾驶模型训练数据量巨大,不可能全拿来训,得选最有用的子集 - 核心难点 :一条驾驶数据可能对"不撞车"有帮助但对"车道保持"没用,现有方法都没建模这种"不同数据对不同指标影响不同"的现象 - 核心方法 :先把数据分堆 → 估算每堆的"性价比曲线"(加多少条能提升多少分) → 每次都从性价比最高的堆里选 - 主要结果 :用 15-18% 的数据就能达到随机选择 100% 数据的效果 - 研究意义:第一次把 scaling law(预测"数据量↔模型性能"关系的工具)用在多指标竞争的数据选择场景
研究背景与动机
领域现状
端到端自动驾驶系统已经从早期的 ALVINN、Dave 等原型发展到如今的 Hydra-MDP 等竞赛级规划器。这些系统直接从传感器输入映射到驾驶轨迹,采用知识蒸馏和规则合规评分来训练。NAVSIM 基准测试平台引入了 EPDMS 这一综合评估指标,它聚合了 9 项闭环规则合规指标,包括无碰撞 (NC)、可驾驶区域合规 (DAC)、可行驶方向合规 (DDC)、交通灯合规 (TLC)、自我进度 (EP)、碰撞时间 (TTC)、车道保持 (LK)、人体舒适度 (HC) 和可驾驶合规 (EC)。
与此同时,数据管理领域在 LLM 训练中已发展出成熟的数据混合优化方法(DoReMi, DOGE, RegMix 等),利用 scaling law 预测模型性能如何随数据规模和配比变化。但这些方法的假设------数据域天然可分(如数学/代码/不同语言)且同域样本重要性均匀------在驾驶数据中并不成立。
现有方法的局限性
现有方法面临三个根本性限制。第一,多指标竞争 :自动驾驶评估涉及多个可能相互冲突的指标,一条数据的添加可能改善某项指标却恶化另一项。第二,差异化影响率 :不同数据样本对指标组合的影响速率各异,例如高交通密度片段对碰撞避免提升大但对舒适度影响小。第三,数据域不可分:驾驶数据在地理位置、天气、交通条件上连续变化,不像语言数据那样天然划分为离散域。
现有数据混合方法要么仅操作域级权重而不处理域内样本差异(如 Chameleon),要么依赖特征空间覆盖度而忽视多指标结构(如 Coreset),要么用不确定性度量选取困难样本而不考虑不同场景对不同指标的贡献(如 Uncertainty)。这些方法都缺少一个关键环节:建模数据域对聚合效用的缩放行为,并据此优化数据混合。
研究动机
一个很自然的想法是:如果我们能提前知道"从某堆数据多加 100 条,模型能提升多少",就能在有限预算下把资源花在刀刃上。scaling law 就是做这件事的工具------它用一条曲线描述"数据量↔性能"的关系。但之前的 scaling law 主要用在语言模型上,那边数据天然分好了类(数学、代码、不同语言),每类里样本也差不多。自动驾驶数据可不一样:场景是连续变化的(城市→郊区→高速),一条视频里可能既有人行横道又有急弯。所以核心挑战是:怎么在不规则、连续的数据上也能用 scaling law 指导数据选择?本文的假设是:只要你把数据按某种合理方式分了堆,堆内按"模型表现多差"排好序,那每堆的 scaling 曲线就足够平滑可预测,可以用来做优化了。
方法概述
核心思想
用大白话说,MOSAIC 的思路就是:先分堆、再估算性价比、最后专挑性价比高的。
具体来说,数据池太大了不可能全选,那怎么选?与其直接在几万条数据里挑,不如先把它们按场景分成几堆,然后对每堆估算一个"性价比曲线"------从这堆里多拿 1 条数据,模型评分能涨多少?有了这个曲线之后,选数据就简单了:每次都选"性价比最高"的那堆里的下一条。随着你从某堆里拿的数据越来越多,它的性价比会下降(好学的已经学完了),这时候框架会自动切换到其他性价比更高的堆。
这种"分堆→估性价比→逐条选"的思路之所以有效,是因为:分堆让同一堆里的数据有类似的规律,估性价比才有意义;堆内排序(从最难的开始选)让性价比曲线更平滑更好预测。
整体架构
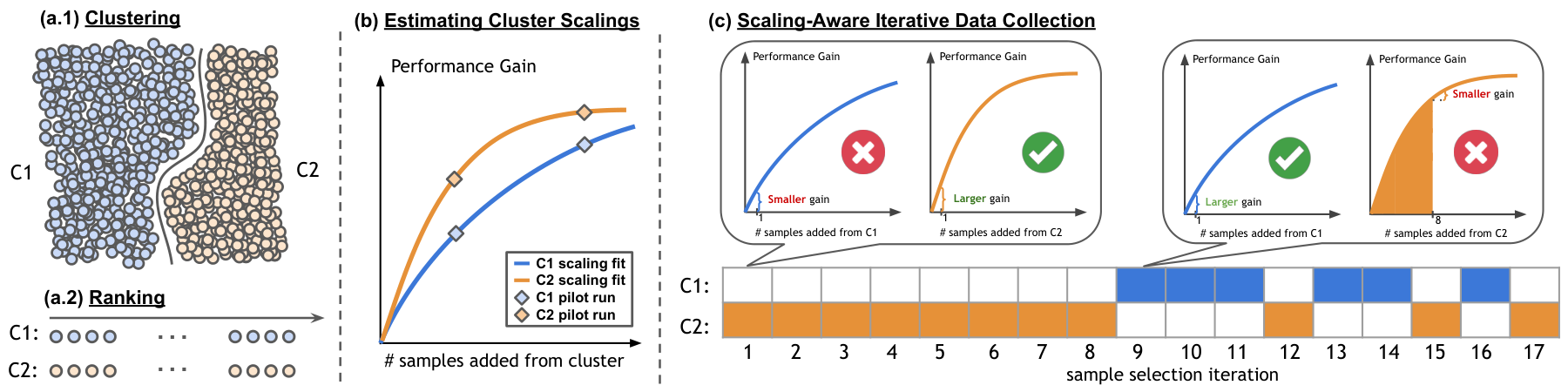
图1:MOSAIC 框架三步走。(a) 分堆+排序 :把数据池按场景聚成 MM 堆,每堆里按"模型表现多差"排序(最难的排前面)。(b) 估算每堆的性价比曲线 :对每堆做几次小规模训练实验,测出"多加 nn 条数据,模型评分能提升多少"。用 ⋆⋆ 标记的是实测点,曲线是拟合出来的。注意不同堆的曲线形状不一样------有的堆起步提升快但很快饱和,有的堆提升慢但持续时间长。(c) 逐条选数据:每次都从"多加一条提升最大"的堆里取下一条,取完重新比较各堆的性价比,循环直到用完预算。
从架构上看,MOSAIC 分为三个阶段,数据流如下:
- 输入 :初始训练集 DtrainDtrain、数据池 DpoolDpool、预算 BB 2. 聚类与排名 (阶段 a):数据池 → MM 个聚类 → 每个聚类按重要性排序 3. Scaling law 拟合 (阶段 b):每个聚类 → pilot run → 饱和指数曲线参数 (ai,τi)(ai,τi) 4. 迭代选择 (阶段 c):循环 BB 次,每次选取边际增益 δi(bi)δi(bi) 最大的聚类的下一条样本 5. 输出:选出的数据子集 DselDsel
这种三阶段设计的理由在于:聚类提供了域级别的结构化分解,使得 scaling law 的拟合有意义(同域内数据对指标的影响模式一致);排名确保了同一域内的样本按学习信号强度排列,使缩放曲线更加平滑和可预测;迭代选择则避免了全局优化所需的巨大搜索空间。
关键模块拆解
聚类与排名:将异质数据转化为结构化域
聚类是 MOSAIC 的第一步,其目标是将数据池划分为 MM 个"对指标影响模式一致"的子集。论文指出,聚类方式不需要唯一------地理信息(城市名)、VLM 生成的语义描述、甚至规则合规信号均可作为特征。关键在于聚类后每个域内的数据具有相似的 scaling 行为。
排名紧接聚类之后,对每个域内的样本按重要性分数 I(x)I(x) 排序。在自动驾驶应用中,重要性定义为模型在该样本上的效用值:
I(x):=U({Gr(f(⋅;Dtrain),x)}r=1R)I(x):=U({Gr(f(⋅;Dtrain),x)}r=1R)
即用当前模型评估该驾驶片段的聚合效用。分数越低意味着模型在该场景上表现越差,因此该样本的学习信号越强,应优先选取。这一排序策略使得 pilot run 中观测到的性能提升呈现更平滑的凹形曲线,而非无序波动的噪声模式。
Scaling Law 拟合:估算每堆数据的"性价比曲线"
这一步的目标是回答一个核心问题:从第 ii 堆数据里多拿 nn 条来训练,模型能提升多少?
论文做了一个简化假设:各堆数据对模型的影响可以独立估算,然后加起来。也就是说,不用考虑堆与堆之间的交互------从 Boston 数据堆拿了 100 条的提升,加上从 Vegas 堆拿了 50 条的提升,就近似等于总共的提升。这个假设不一定完全准确,但实验表明够用了。
在这个假设下,每堆数据各自有一条"性价比曲线",用饱和指数函数建模:
ΔU^i(n)=ai(1−e−n/τi)ΔU^i(n)=ai(1−e−n/τi)
这个公式的意思是:aiai 是天花板------这堆数据再多也最多提升这么多;τiτi 是达到天花板的速度------值越大,提升越慢但持续时间越长。为什么不用更常见的幂律 ancanc?因为幂律没有天花板,永远在增长,不现实。而饱和指数函数更符合直觉:好学的先学会了,越往后提升越小,最终趋于平缓。
怎么拟合这条曲线?不用训练完整模型。先用 10% 的基础数据训一个小模型,然后对每堆数据分别试加少量样本(比如 20 条、40 条),测一下评分涨了多少。就凭这几个点就能把曲线拟合出来。论文在补充材料里证明这种"小规模试训"已经足够准确。
迭代选择:每次都挑"性价比最高"的那条
有了每堆数据的性价比曲线之后,选数据的过程就很直观了:
假设已经从第 ii 堆拿了 bibi 条数据,那"再多拿一条能提升多少"就是:
δi(bi)=ΔUi^(bi+1)−ΔUi^(bi)δi(bi)=ΔUi(bi+1)−ΔUi(bi)
因为性价比曲线是"凹"的(越往后越平),所以从同一堆拿的数据越多,再多拿一条的提升就越小。这就是边际收益递减。
选数据的策略很简单:每轮都算一下每堆的 δiδi,谁最大就从谁那里拿一条。拿完之后这堆的 δδ 变小了,下一轮可能就该从别的堆拿了。如此循环 BB 次。
从数学上讲,因为性价比曲线都是凹的,所以这种"每次贪心选最优"的策略恰好能找到全局最优解------不存在"前面选错了导致后面更差"的问题。
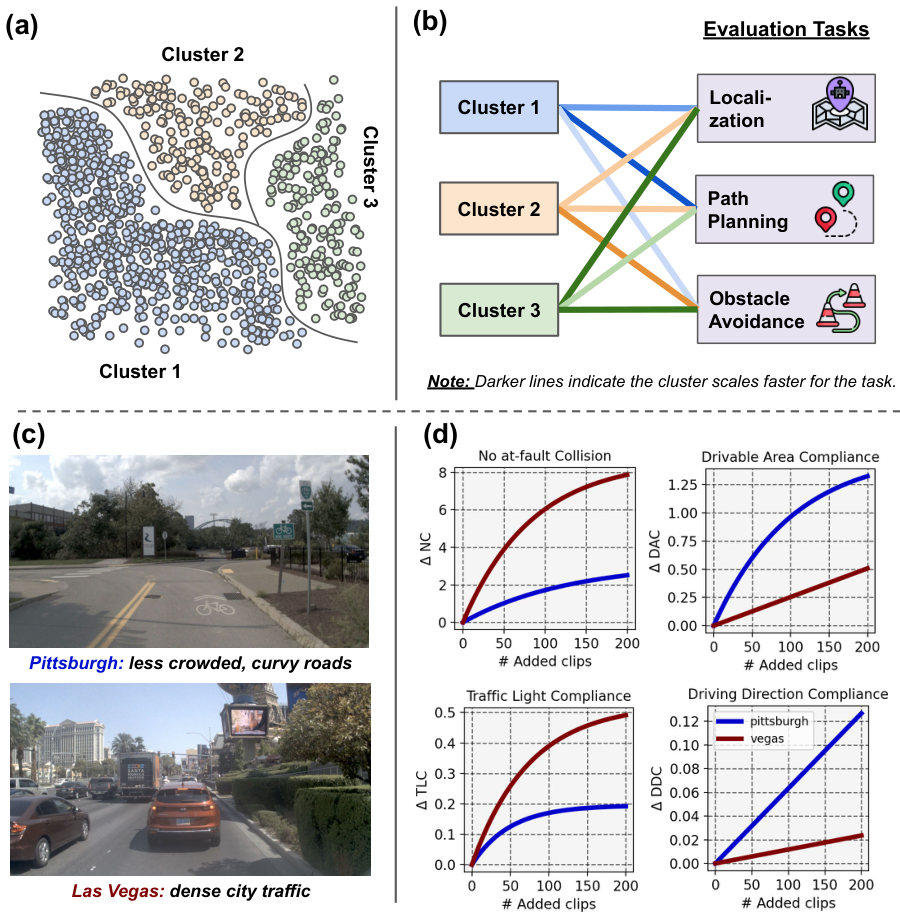
图2:展示了 MOSAIC 解决的核心问题。(a-b) 数据池被划分为多个离散域,每个域对不同的评估指标有不同的改善速率。(c-d) 自动驾驶中的具体例子:Pittsburgh(弯曲郊区道路)和 Las Vegas(密集城市交通)两个聚类,分别对不同的规则合规指标产生不同的影响。
训练/推理流程
Pilot run 阶段:先用 DtrainDtrain 的 10% 子集训练一个基础 pilot 模型。然后对每个聚类 ii,分别选取该聚类中按重要性排名最靠前的 20% 和 40% 的样本,以继续训练(而非从头训练)的方式在 pilot 模型上微调少量 epoch,记录 EPDMS 的变化。用这三个点(0, 20%, 40%)拟合饱和指数函数的参数。
最终训练阶段:选定 DselDsel 后,用完整的 Dtrain∪DselDtrain∪Dsel 从头训练 Hydra-MDP 模型。论文中所有报告的性能数字都来自这一最终训练。
实验结果
实验目标
验证 MOSAIC 在以下维度的有效性:(1)在不同数据预算下是否能持续超越现有基线;(2)数据效率提升的幅度;(3)对聚类方式的鲁棒性;(4)各组件的必要性。
数据集与实验设置
数据集统计
| 数据集 | 初始训练集 | 数据池大小 | 评估集 | 特征 |
|---|---|---|---|---|
| OpenScene | 1,000 clips | 31,539 clips | navtest | 完整 trainval 划分,约 120 小时驾驶数据 |
| Navtrain | 460 clips | 4,141 clips | navtest | 经筛选的非平凡场景,排除简单驾驶 |
每条 virtual clip 为 10 秒(20 帧,2Hz),与行业惯例一致。
基线方法
- Random :均匀随机采样,最基本的对照 - Uncertainty (Joshi et al.):用轨迹 logits 的熵排序,选最不确定的样本 - Coreset (Sener & Savarese):在特征空间中最大化覆盖多样性的子集 - Chameleon (Xie et al.):用核岭回归在模型隐空间计算域权重,是当前最强的数据混合方法之一
选择这些基线的原因:它们分别代表了随机采样、不确定性驱动、多样性驱动和数据混合优化四条技术路线。
评估指标
- EPDMS :9 项规则合规指标的聚合分数(惩罚项 NC, DAC, DDC, TLC 的乘积 × 加权平均项 EP, TTC, LK, HC, EC 的加权和),与闭环驾驶性能高度相关 - BRMR (Budget Ratio to Match Random):某方法达到随机选择同等性能所需预算与随机选择预算之比,越低越高效
主要结果
主实验结果
| 方法 | OpenScene (250 clips) | BRMR | OpenScene (1000 clips) | BRMR | OpenScene (4000 clips) | BRMR |
|---|---|---|---|---|---|---|
| Random | 72.84±1.14 | 1.00 | 75.84±0.90 | 1.00 | 80.38±0.55 | 1.00 |
| Uncertainty | 70.78±0.59 | 14.58 | 71.12±0.38 | 8.00 | 73.46±0.19 | 2.00 |
| Coreset | 76.26±0.48 | 0.20 | 80.46±0.02 | 0.22 | 83.63±0.36 | 0.25 |
| Chameleon | 72.97±1.72 | 0.86 | 79.08±0.74 | 0.49 | 82.92±0.13 | 0.39 |
| MOSAIC | 77.38±1.58 | 0.15 | 81.68±0.52 | 0.18 | 84.25±0.14 | 0.18 |
| 方法 | Navtrain (100 clips) | BRMR | Navtrain (400 clips) | BRMR | Navtrain (1600 clips) | BRMR |
|---|---|---|---|---|---|---|
| Random | 84.66±0.60 | 1.00 | 86.69±0.20 | 1.00 | 88.62±0.22 | 1.00 |
| Uncertainty | 84.50±0.48 | 1.47 | 86.07±0.75 | 2.00 | 87.75±0.37 | 1.36 |
| Coreset | 85.29±0.47 | 0.53 | 87.09±0.29 | 0.79 | 89.30±0.19 | 0.58 |
| Chameleon | 84.57±0.18 | 1.07 | 87.04±0.60 | 0.82 | 89.50±0.20 | 0.62 |
| MOSAIC | 86.29±0.43 | 0.30 | 88.21±0.03 | 0.38 | 90.18±0.25 | 0.37 |
EPDMS 子指标分解(4000 clips / OpenScene)
| 方法 | NC | DAC | DDC | TLC | EP | TTC | LK | HC | EC | EPDMS |
|---|---|---|---|---|---|---|---|---|---|---|
| Base | 94.05 | 83.9 | 96.28 | 99.6 | 85.96 | 92.95 | 93.26 | 98.25 | 81.88 | 72.0 |
| Random | 96.32 | 90.53 | 99.06 | 99.79 | 86.36 | 95.66 | 95.68 | 98.30 | 84.46 | 80.38 |
| Coreset | 97.11 | 92.93 | 99.44 | 99.82 | 86.65 | 96.42 | 96.66 | 98.16 | 85.10 | 83.63 |
| Chameleon | 96.76 | 92.32 | 99.51 | 99.77 | 86.98 | 95.91 | 96.49 | 98.32 | 85.51 | 82.92 |
| MOSAIC | 96.97 | 93.59 | 99.59 | 99.80 | 87.14 | 96.18 | 96.62 | 98.28 | 85.06 | 84.25 |
注:MOSAIC 在 DAC 上提升最大(从 Base 83.9 → 93.59,+9.69),这是对 EPDMS 影响最大的瓶颈指标。MOSAIC 在所有指标上都保持 Top-2,展现了其对多指标权衡的理解。
结果分析
最关键的对比是 MOSAIC vs Coreset。Coreset 是一致性第二好的方法,它通过特征空间覆盖度选取多样本。MOSAIC 在所有预算下都领先 Coreset 约 0.6-1.1 个 EPDMS 点,且 BRMR 更低(OpenScene 上 0.18 vs 0.25),说明 MOSAIC 不仅性能更好,数据效率也更高。
Uncertainty 基线的表现最差,甚至低于 Random,这表明仅凭模型输出的不确定性无法有效捕捉驾驶数据中的学习信号------一个场景可能因为模型不确定而有高熵,但该场景的训练价值可能很低(比如只是罕见的天气条件而非有价值的驾驶行为)。
从子指标分解来看,MOSAIC 的优势并非来自均匀提升所有指标,而是战略性优先提升对 EPDMS 影响最大的瓶颈指标(DAC),同时维持其他指标的高水平。这正是 scaling-aware 选择策略的核心价值所在。
消融实验
消融设计思路
论文通过多维度消融验证:(1)聚类+排名各自的作用;(2)不同聚类方式的鲁棒性;(3)scaling law 拟合的动态行为。
消融一:聚类与排名的必要性
论文设计了两个变体:"w/o Clustering"(仅排名,无聚类,直接按 EPDMS 排序后贪心选取)和"w/o Ranking"(有聚类+scaling law,但不排序)。
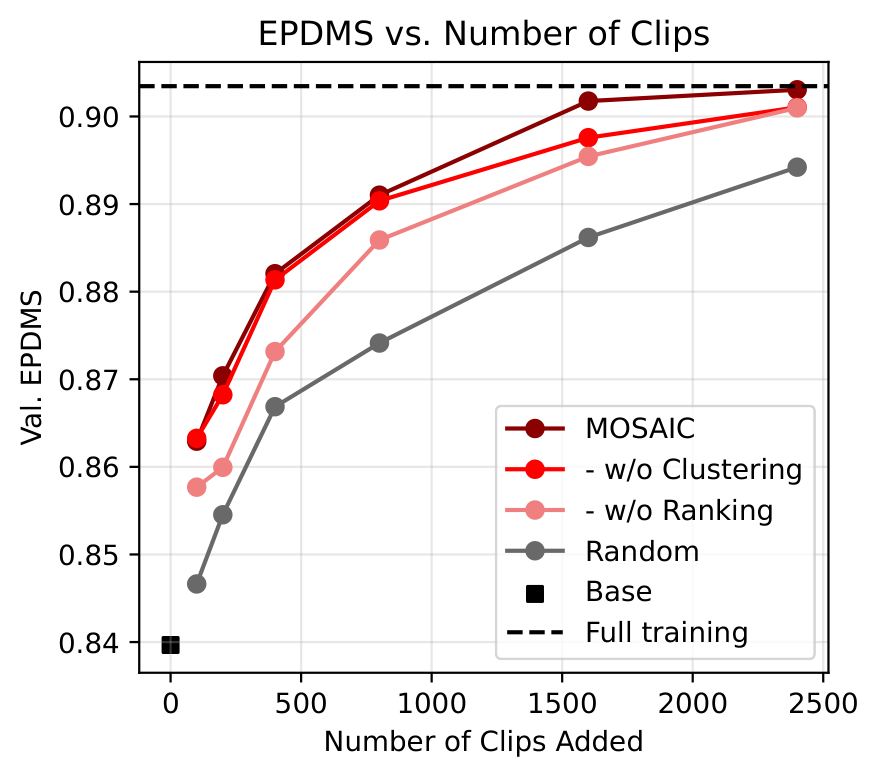
图3:各组件的贡献分析。在低数据区间(<800 clips),排名的贡献占主导------MOSAIC 和 w/o Clustering 表现接近。但在高数据区间,仅靠排名已不足以区分"哪类数据更有价值",此时聚类的 scaling law 开始发挥关键作用。
关键发现:排名在低数据区间贡献最大(此时最难样本的学习信号最强),而聚类+scaling law 在高数据区间贡献最大(此时边际收益递减使得跨域分配变得关键)。两者互补。
消融二:不同聚类机制
论文测试了三种聚类方式: - 地理信息 (Geolocation):按城市划分(Boston, Pittsburgh, Singapore, Vegas) - 语义描述 (Caption):用 Qwen-2.5-VL-32B 生成片段描述,TF-IDF 特征 + K-means - 规则合规(Rule compliance):基于 EPDMS 子指标
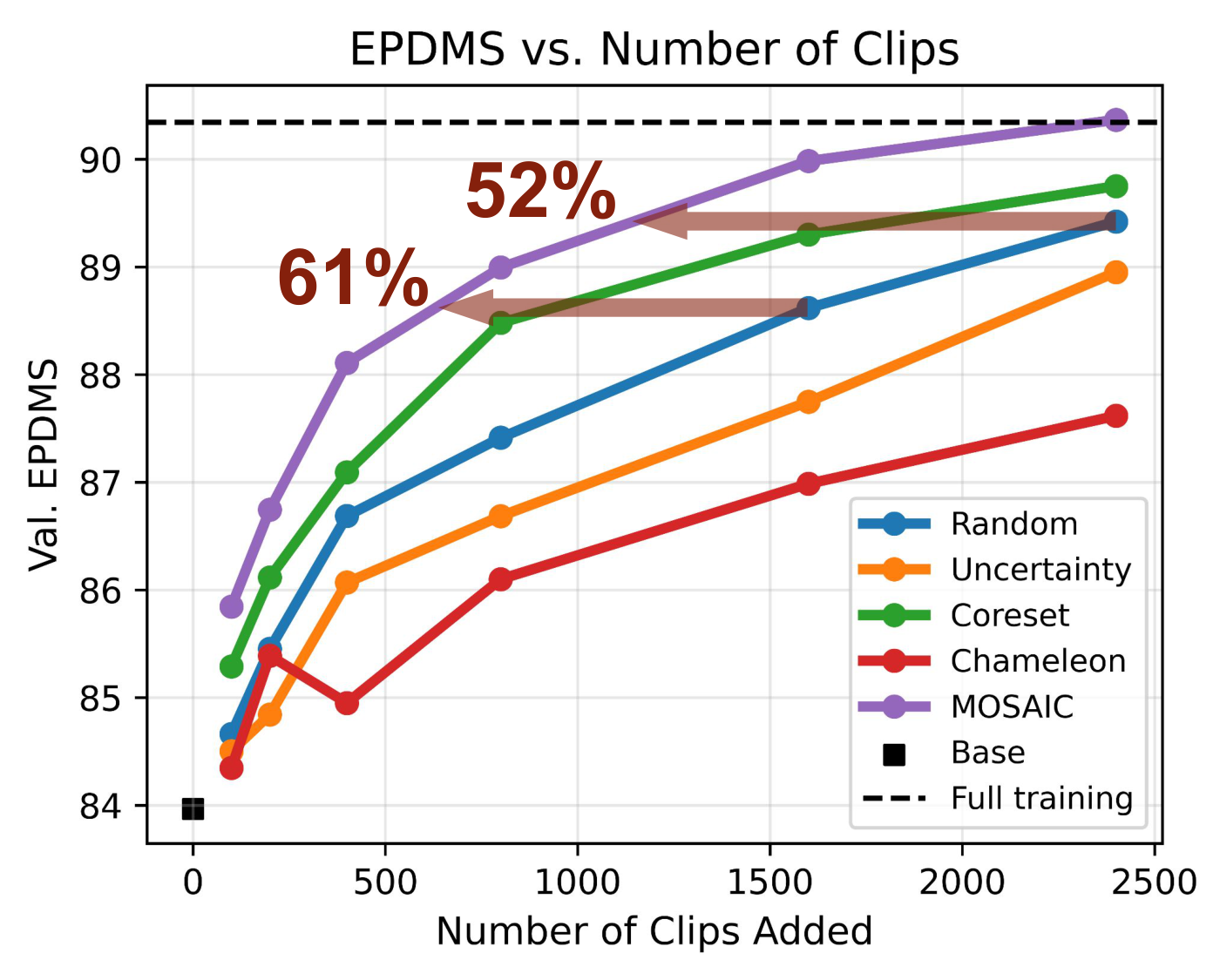
图4:使用 Caption 聚类时各方法的 EPDMS 随预算变化。MOSAIC 在 1600 和 2400 clips 时分别比 Random 少用 61% 和 52% 的数据即可达到同等性能。更重要的是,MOSAIC 仅用 2400 clips(总池 4141 条)就达到了全量训练的性能------节省 42%。
值得注意的是,Chameleon 在地理聚类下表现尚可,但在 Caption 聚类下性能显著退化,说明其核岭加权对域结构高度敏感。MOSAIC 在所有聚类方式下都保持最优。
消融三:Scaling law 的动态行为
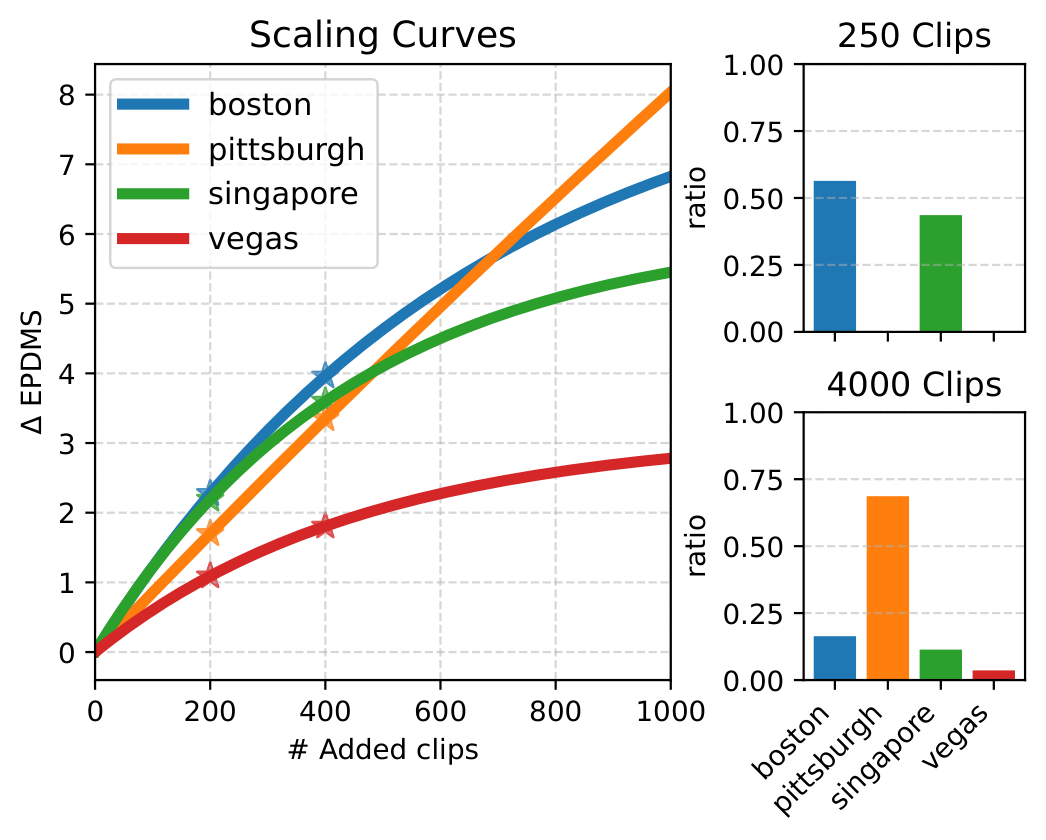
图5:(左) 四个城市聚类的 fitted scaling 曲线,⋆⋆ 标记为 pilot run 观测点。Boston 和 Singapore 在低数据区间增益最大,Pittsburgh 在高数据区间持续改善并最终超越其他域,Vegas 增益最小且早期饱和。(右) 不同预算下从各城市选取的数据比例------250 clips 时以 Boston/Singapore 为主,4000 clips 时以 Pittsburgh 为主。

图6:MOSAIC 迭代选择过程的条形码可视化。y 轴为城市名,x 轴为迭代轮次,每根竖条表示该轮从哪个城市选取样本。早期(<500 轮)以 Boston 和 Singapore 为主;中期(500-3700 轮)转向 Pittsburgh;后期 Vegas 的边际增益变得可比。
深度分析
研究价值评估
理论贡献
- 可分离近似 :将 NP-hard 的子集选择问题转化为可高效求解的凹最大化问题,这是 MOSAIC 实用性的数学基础。虽然可分离性假设(域间无交互)是一个强假设,但实验结果表明在实际场景中该近似足够好。 - 饱和指数 scaling law :相比传统幂律,饱和指数函数更好地建模了有限数据池中"边际收益递减"的真实行为------因为数据池本身是有限的,不可能像幂律那样无限增长。 - 一阶差分贪心策略:理论上保证了在凹目标函数下的全局最优性,且计算复杂度仅为 O(B⋅M)O(B⋅M)(BB 为预算,MM 为聚类数)。
实际应用价值
- 自动驾驶行业 :自动驾驶公司收集了海量驾驶数据但受限于计算预算。MOSAIC 提供了一种从大规模数据池中高效选择最有价值子集的方法论,直接降低了训练成本。 - 通用数据管理 :框架本身不依赖自动驾驶特有假设,可推广到任何"多指标评估 + 异质数据"的场景(如机器人操作、无人机导航等)。 - 持续学习:MOSAIC 的迭代选择机制天然适用于增量式数据收集场景------每次有新数据入库时,可以重新评估 scaling law 并更新选择策略。
领域影响
- 短期影响 :为 NAVSIM/OpenScene 基准上的模型训练提供了更高效的数据选择方案 - 中期影响 :可能推动工业界从"数据越多越好"转向"选择正确的数据"的数据管理范式 - 长期影响:scaling-law-based 数据选择作为一种通用的数据效率方法论,有望在更多物理 AI 领域获得应用
方法优势与局限
核心优势
MOSAIC 的核心优势在于它同时建模了三个维度:(1)数据的域级结构(通过聚类),(2)域内样本的质量差异(通过排名),以及(3)数据量与性能的缩放关系(通过 scaling law)。现有方法通常只关注其中一个维度------Coreset 关注多样性但忽视 scaling,Uncertainty 关注难度但忽视域结构,Chameleon 关注域权重但忽视域内差异。MOSAIC 通过三阶段流水线将这三个维度整合到一个统一框架中。
局限性分析
- 可分离性假设 :公式中 ΔUmix≈∑ΔUi(ni)ΔUmix≈∑ΔUi(ni) 假设域间无交互。如果聚类不当(域间高度相关),该假设可能被违反,导致次优分配。不过论文的实验表明,在合理聚类下该近似足够有效。 - Pilot run 的额外计算成本 :虽然论文声称 pilot run 可以通过继续训练和小子集来降低成本,但在拥有数百个聚类的大规模场景中,pilot run 的数量和成本仍然不可忽视。 - 聚类数量和方式的敏感性:论文虽然展示了 MOSAIC 对不同聚类方式的鲁棒性,但未系统研究聚类数量 MM 的选择如何影响性能------MM 过小可能无法区分不同的 scaling 行为,MM 过大则 pilot run 成本线性增长。
适用场景分析
- 最适合的场景 :数据池大但计算预算有限的场景,尤其是需要优化多指标聚合效用的系统。自动驾驶是典型的适用场景。 - 不太适合的场景:数据池本身较小(pilot run 的开销不成比例)或评估指标单一(此时简单的不确定性/多样性策略可能足够)的场景。
与相关论文对比
对比论文选择依据
选择以下论文的原因是它们分别代表了数据选择/混合的不同技术路线,且在自动驾驶或通用数据管理领域有代表性影响。
DoReMi - Distributing Weights for Multi-source Data
方法对比
| 对比维度 | DoReMi | MOSAIC |
|---|---|---|
| 核心思想 | 用两个 proxy 模型估计域权重 | 用 scaling law 建模域级性能增长 |
| 技术路线 | 域间 excess loss 重加权 | 聚类+排名+饱和指数缩放 |
| 多指标处理 | 无(单指标) | 原生支持(聚合效用函数) |
| 域内样本 | 均匀对待 | 按重要性排名 |
关系分析
- 关系类型 :改进/扩展 - 本文改进 :MOSAIC 将 DoReMi 的域级重加权思想推广到了多指标竞争+域内排序的设定 - 互补性:DoReMi 的 excess loss 信号可以作为 MOSAIC 的一种替代重要性度量
Chameleon - Adaptive Data Mixture via Kernel Similarity
方法对比
| 对比维度 | Chameleon | MOSAIC |
|---|---|---|
| 核心思想 | 模型隐空间核相似度分配域权重 | Scaling law 预测域级边际增益 |
| 技术路线 | 核岭回归 → 域权重 | Pilot run → 饱和指数 → 贪心选择 |
| 对域结构依赖 | 高(性能对聚类敏感) | 低(对多种聚类鲁棒) |
| 理论保证 | 无 | 凹目标下的全局最优 |
性能对比
在论文所有实验中,MOSAIC 的 EPDMS 均高于 Chameleon,且在 Caption 聚类下 Chameleon 性能显著退化而 MOSAIC 保持稳定。
关系分析
- 关系类型 :对比/改进 - 本文优势 :scaling law 提供了显式的外推能力,而非仅依赖当前训练状态的隐空间特征 - 互补性:Chameleon 的核岭权重可作为 MOSAIC 聚类阶段的辅助信号
Hydra-MDP - NAVSIM Challenge Winner
- 关系类型:应用基础 - Hydra-MDP 是论文中使用的底层规划器模型,MOSAIC 的数据选择作用于 Hydra-MDP 的训练数据。这表明 MOSAIC 是模型无关的数据管理框架,可与任何 E2E 规划器配合使用。
技术路线定位
所属技术路线
MOSAIC 属于"数据为中心的 AI (Data-centric AI)"这一技术路线,具体位于"数据选择与混合优化"子方向。该路线认为模型性能的提升不应仅靠更大的模型或更多计算,而应通过更聪明的数据管理来实现。
技术路线发展历程
Data Pruning (SemDeDup, SSE) → Data Mixtures (DoReMi, DOGE) → Scaling-law-based Mixtures (RegMix, ADO) → MOSAIC (本文:多指标+异质域+scaling-law 选择)
本文在技术路线中的位置
- 承上 :继承了 scaling law 用于数据管理的思想,以及数据混合优化的方法论框架 - 启下 :为物理 AI 领域的多指标数据选择问题提供了首个系统性解决方案,开辟了"scaling-aware selection for multi-metric systems"这一新方向 - 关键节点:首次将 scaling law 从单指标、清晰域推广到多指标、模糊域的设定
未来工作建议
作者建议的未来工作
论文在结论中提到 MOSAIC 提供了"通用且原则性的框架",暗示可扩展到其他物理 AI 场景(如机器人操作),但未具体说明。
基于分析的未来方向
- 在线自适应选择 :当前 MOSAIC 是离线的(pilot run 后一次性选择),可以扩展为在线版本------在训练过程中持续更新 scaling law 估计并动态调整数据选择策略。 2. 跨模型迁移的 scaling law :pilot run 在小模型上拟合的 scaling law 能否迁移到大模型?如果能,将进一步降低 pilot run 成本。 3. 层次化聚类:当前用单一粒度聚类,可以引入层次化结构(如先按天气分大类,再按场景复杂度细分),使 scaling law 在不同粒度上提供不同精度的指导。
我的综合评价
价值评分
总体评分
7.5/10 - 一篇方法清晰、实验扎实的工作,将 scaling law 与多指标数据选择相结合的思路具有实用价值,但方法本身的每个组件都是已有技术的组合,创新深度有限。
分项评分
| 评分维度 | 分数 | 评分理由 |
|---|---|---|
| 创新性 | 7/10 | 聚类+排名+scaling law+贪心选择的组合新颖且合理,但每个组件单独来看并非全新。核心贡献在于将这些组件系统性地整合为一个解决多指标数据选择的框架 |
| 技术质量 | 8/10 | 数学推导清晰(可分离近似、凹优化、一阶差分贪心),公式定义严谨,算法伪代码完整。可分离性假设的讨论较为诚实 |
| 实验充分性 | 7/10 | 两个数据集、多个预算水平、多种聚类方式、多维度消融。但仅有自动驾驶一个应用场景,未验证框架在其他领域的通用性。缺少与 ADO 等更近期 scaling-law 方法的对比 |
| 写作质量 | 8/10 | 论文结构清晰,动机阐述充分,图表质量高。某些方法论段落稍显冗长但总体可读性好 |
| 实用性 | 8/10 | 对工业界有直接应用价值------自动驾驶公司可以用 MOSAIC 从海量数据中高效选择训练子集。框架的模型无关性增加了实用性 |
重点关注
值得关注的技术点
- 饱和指数函数作为 scaling law 的选择:相比幂律更自然地建模了有限数据池的边际收益递减 - BRMR 指标:作为衡量数据效率的新指标,简洁且直观 - Scaling law 拟合只需 2-3 个 pilot run 点:这大大降低了 scaling-based 方法的使用门槛
需要深入理解的部分
- 可分离近似 ΔUmix≈∑ΔUiΔUmix≈∑ΔUi 的精度到底如何------论文未定量评估该近似的误差 - Pilot run 的"继续训练"策略在多大程度上影响了 scaling law 的精度
我的笔记
MOSAIC 人话版流程
这篇论文可以粗略理解为:
先把数据分堆;每堆内部把当前模型最不会的样本排前面;每堆拿一点样本试训,估计这堆数据的收益曲线;然后按"哪堆下一批数据最划算"来分配数据预算;最后用选出来的数据训练模型。
1. 对候选数据按场景分簇
先把所有候选数据池 DpoolDpool 按场景类型分成不同簇。
Cluster A:高速场景
Cluster B:复杂路口
Cluster C:连续弯道
Cluster D:红绿灯场景
Cluster E:密集交通核心目的:不把所有数据混在一起看,而是先区分"不同类型的数据"。
2. 用 base model 给每个簇内样本打分并排序
base model 是已经在初始训练集 DtrainDtrain 上训练好的当前模型。用它去跑候选数据池里的每个样本,根据模型表现打分。直观规则:
模型表现越差 → 样本越重要 → 排序越靠前
模型表现越好 → 样本越普通 → 排序越靠后每个簇内部变成一个排序列表:
Cluster A: 难例1, 难例2, 难例3, ..., 普通样本
Cluster B: 难例1, 难例2, 难例3, ..., 普通样本
Cluster C: 难例1, 难例2, 难例3, ..., 普通样本直觉:将来从某个簇里拿数据时,优先拿这个簇里当前模型最不会的样本。
3. 对每个簇取 top-k 小批量样本做 pilot runs
对每个排好序的簇,分别取前缀样本做小规模试训。然后在 DtrainDtrain + 当前簇 top-k 样本上短程 fine-tune,看验证指标提升多少:
| 簇 | top 100 提升 | top 200 提升 |
|---|---|---|
| Cluster A:弯道 | +2.0 | +2.6 |
| Cluster B:路口 | +0.8 | +1.9 |
| Cluster C:高速 | +0.4 | +0.6 |
这一步得到的是:每个簇"按排序取前 nn 条样本时,总体能带来多少收益"的几个观测点。
4. 用 pilot 点拟合每个簇的收益曲线
对每个簇拟合一条累计收益曲线 ΔUi(n)ΔUi(n):第 ii 个簇按排序取前 nn 条样本,预计可以带来多少总收益。
注意:这条曲线是累计收益曲线,不是直接的边际收益曲线。
5. 从累计收益曲线计算边际收益
真正用来决定"下一批该从哪个簇拿"的是边际收益:
gi(n)=ΔUi(n+1)−ΔUi(n)gi(n)=ΔUi(n+1)−ΔUi(n)
含义:第 ii 个簇已经取了 nn 条数据后,如果再多取一条,还能额外提升多少。
6. 基于边际收益构造最终训练数据集
MOSAIC 不是平均从每个簇取,也不是固定比例取,而是反复比较:
现在从哪个簇再拿下一条/下一批,预测收益最大?
如果当前 Cluster A 的边际收益最大,就从 A 的排序列表里继续拿。拿了一些之后 A 的边际收益下降,低于 B,就切换到 B。
伪代码:
while 还没达到总预算:
计算每个簇"再拿一点"的预测边际收益
选择边际收益最大的簇
从这个簇的排序列表中拿下一个样本/下一批样本最终可能得到:
Cluster A:选了 300 条
Cluster B:选了 900 条
Cluster C:选了 100 条
Cluster D:选了 0 条7. 用选出的数据正式训练模型
正式训练使用:Dtrain∪SDtrain∪S,其中 SS 是 MOSAIC 选出的新数据。
注意:"换簇"发生在数据选择阶段,不是正式训练阶段。不是训练时先训 Cluster A 再训 Cluster B------而是先根据 pilot 曲线选好最终数据集,再整体训练。
最短总结
MOSAIC=分簇+簇内难例排序+小规模 pilot run+收益曲线拟合+边际收益贪心选数MOSAIC=分簇+簇内难例排序+小规模 pilot run+收益曲线拟合+边际收益贪心选数
更人话一点:
把数据先分成几堆;每堆里把当前模型最不会的样本排前面;每堆拿一点样本试训,估计这堆数据的收益曲线;然后每次都从"下一批最划算"的那堆里拿数据;最后用选出来的数据训练模型。
最大风险
MOSAIC 最大的问题是:小批量 pilot run 得到的收益曲线,需要外推到更大的数据量。超出 pilot 范围后的边际收益不是实测出来的,而是拟合曲线预测出来的。
如果出现以下情况,MOSAIC 可能会选错:
- 某个簇 top-k 很有价值,但后面的样本很快变普通 2. 某个簇前期收益不明显,但大数据量后才出现收益 3. 簇内样本不够同质 4. 不同簇之间存在强交互 5. base model 表现差的样本其实是脏数据或标签噪声
所以它更像一个工程上有效的数据预算分配方法,而不是一个有严格理论保证的 scaling theorem。
相关论文
直接相关
- Chameleon - 核岭相似度数据混合,最强基线 - DoReMi - excess loss 域权重分配 - DOGE - 域特定梯度跟踪 - RegMix - 回归式混合优化 - ADO - 在线自适应数据混合
背景相关
- Hydra-MDP - NAVSIM 挑战赛获胜模型,本文使用的规划器 - NAVSIM - 自动驾驶规划基准测试平台 - Coreset - 基于多样性的主动学习基线 - SemDeDup - 语义去重,数据剪枝代表工作
后续工作
- 可扩展到机器人操作、无人机导航等物理 AI 场景 - 在线版本(训练过程中动态调整选择策略)是自然的后续方向
外部资源
- NAVSIM Benchmark(https://github.com/autonomousvision/navsim)
tip: 关键启示
选训练数据的本质不是"选难的"也不是"选多样的",而是回答"在当前阶段,加哪条数据对模型提升最大"。Scaling law 提供了一个定量工具来预测这个答案。
warning: 注意事项
- MOSAIC 的 scaling law 拟合依赖 pilot run 的质量,如果 pilot 模型与最终模型差异过大,外推可能不准确
- 可分离近似假设域间无交互,这在聚类不充分时可能被违反
- 论文仅验证了自动驾驶场景,框架在其他领域的通用性有待验证
success: 推荐指数
⭐⭐⭐⭐ 推荐关注------方法清晰实用,实验扎实,对自动驾驶数据管理有直接指导意义。适合从事自动驾驶或大规模数据管理的工程师和研究人员阅读。