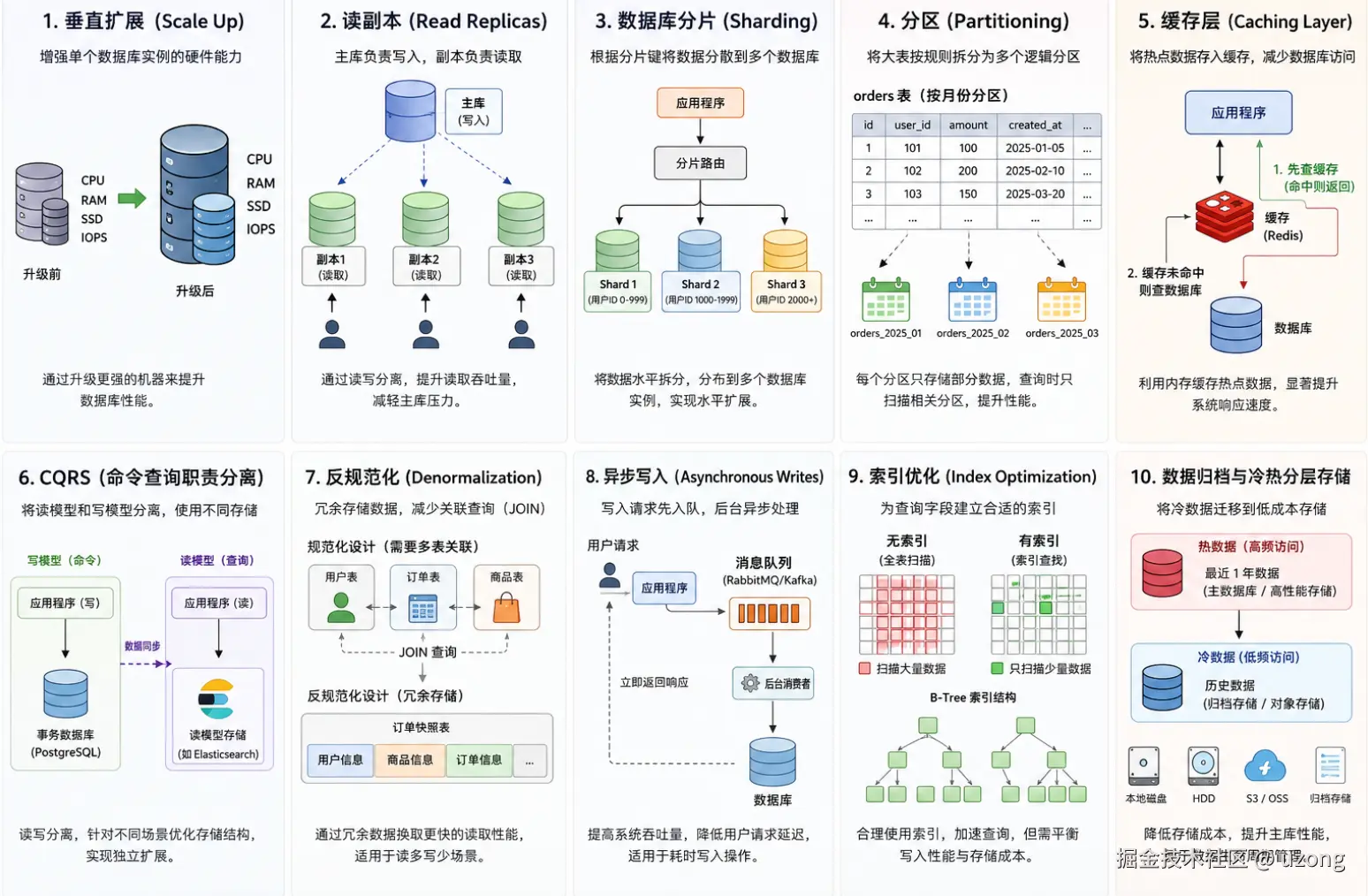
每位工程师都必须掌握的十大数据库扩容策略
现代系统崩溃,往往不是因为SELECT *这类拙劣的SQL写法,而是源于一夜之间暴涨十倍的流量、营销活动的上线、大型企业客户的签约合作,或是数据增速远超所有人预期。
绝大多数数据库故障,本质都是扩容架构失效,而非业务逻辑漏洞。
即便你写出完美的业务代码、遵循整洁架构设计,倘若数据库架构无法随业务负载同步迭代,生产环境依旧会崩盘。
本文深度拆解十大核心数据库扩容策略,结合真实业务场景、架构取舍利弊与落地适用场景。只要你负责设计需要扛住真实生产流量的系统,这些概念都是必修课。
正文开始
1. 垂直扩容(向上扩容)

垂直扩容指提升单台数据库实例的硬件资源:
- 增加CPU核心
- 扩容内存
- 更换高速固态硬盘
- 提升IOPS读写性能
- 升级云服务器实例规格
无需改动架构,只需把单台服务器配置升级即可。
团队首选该方案的原因
入门最简单、改造成本最低。
若业务体量小、流量平稳增长,只需:
升级服务器配置、加大内存做缓存、更换高性能存储,无需修改任何代码。
真实业务场景
某SaaS初创公司用户从5万增长至30万,数据库查询延迟持续走高。
优化方案:内存8GB升级至64GB,普通磁盘更换为NVMe高速固态,系统性能立刻显著提升。
局限性
- 硬件配置存在物理上限
- 成本呈非线性暴涨
- 依旧存在单点故障风险
- 无法提升系统高可用能力
垂直扩容只是短期过渡方案,只能争取缓冲时间,绝非长期架构解决方案。
2. 读写分离(读副本)
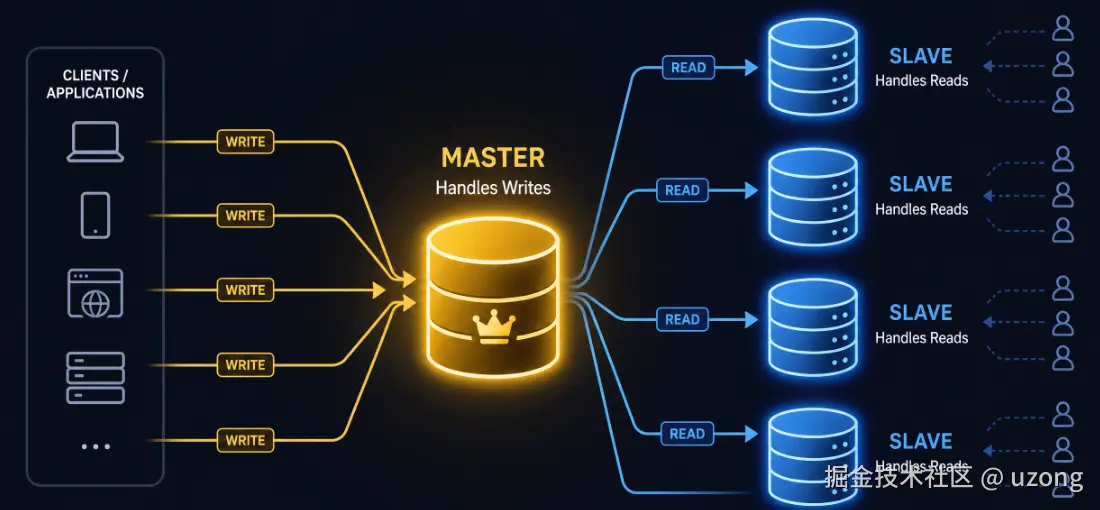
为主库数据库创建多个从库副本:
- 主库负责处理写请求
- 从库负责承载读请求
数据从主库异步同步至各个从库。
核心价值
绝大多数业务都是读多写少 场景:电商商品浏览、社交信息流、数据看板、统计报表等。
若90%流量都是查询读请求,没必要全部压在主库上。
真实业务场景
某在线教育平台:95%流量为学生浏览课程内容,仅5%为课程内容更新。
流量路由规则:读请求全部分发至从库,写请求统一走主库。
最终效果:查询吞吐量实现横向扩容,主库负载大幅下降。
核心取舍:复制延迟
多数数据库的主从复制为异步模式 。
会出现这种场景:用户刚更新个人资料,立刻刷新页面,却看到旧数据,这就是最终一致性 。
如果业务要求写后立读强一致性,则需要定制流量路由逻辑。
读写分离实用性极强,但必须充分理解数据一致性模型。
3. 数据库分库分片
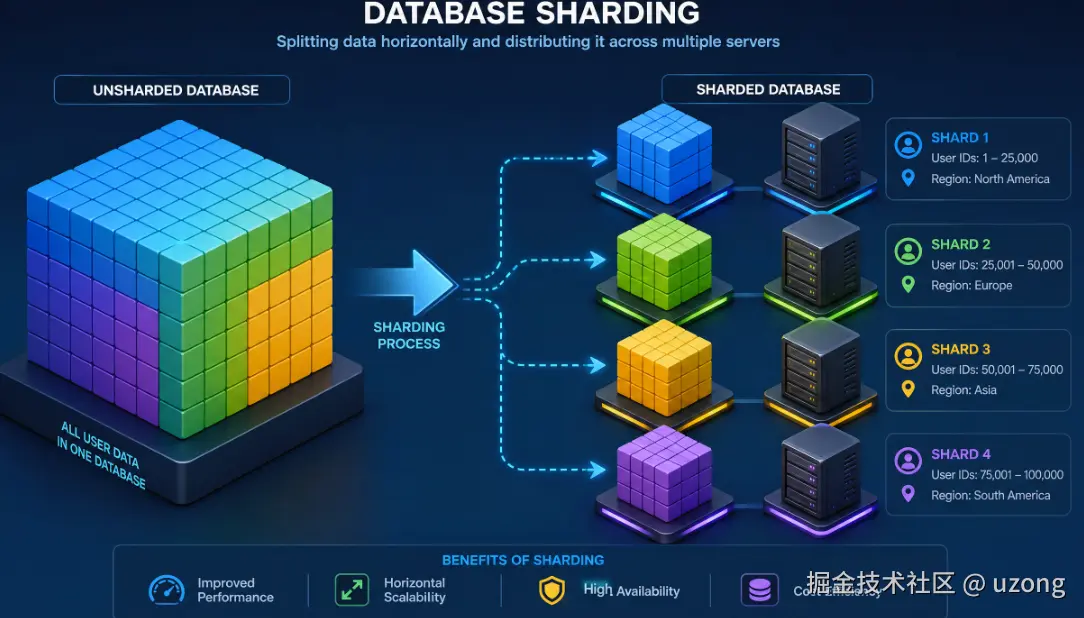
不再使用单一数据库,按分片键将数据拆分到多个独立数据库 。
分片键常用:用户ID、地域、租户ID、客户ID。
核心优势
真正实现数据库横向无限扩容 。
从单库承载全部数据,变为多台独立数据库协同分担流量,每个分片只负责一部分业务数据。
真实业务场景
多租户SaaS平台:
租户A → 分片1
租户B → 分片2
租户C → 分片3
每个分片拥有独立计算资源、独立存储,可按需单独扩容。
复杂度痛点
- 跨分片联表查询难度极大
- 全局分布式事务实现复杂
- 分片数据重新均衡运维成本极高
分片不是临时微调,而是架构级的长期决策。但对于超大规模系统,分片是绕不开的必经之路。
4. 表分区
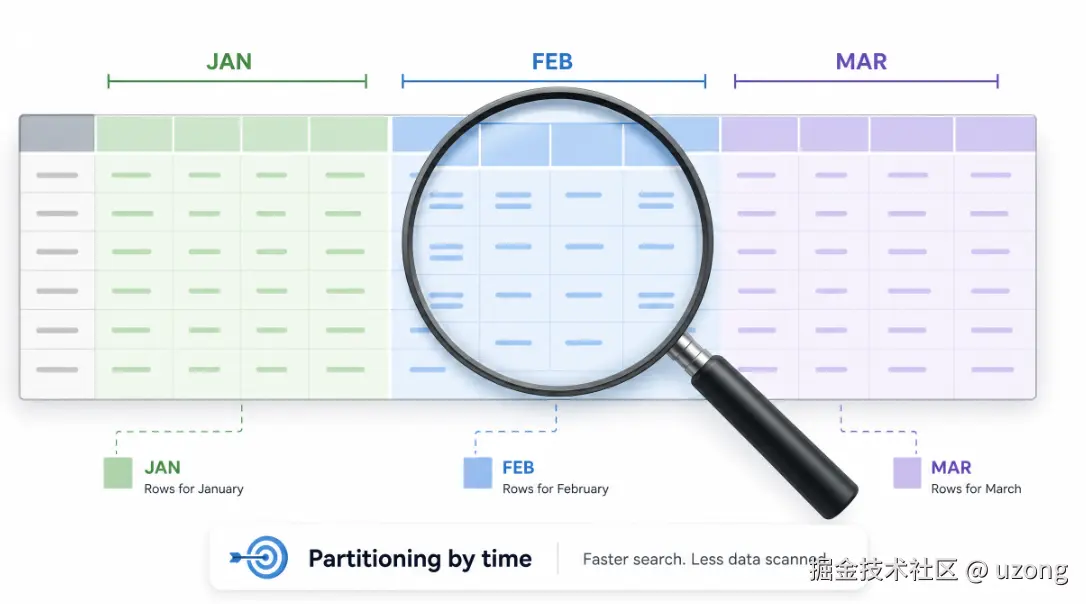
将一张大表拆分为多个逻辑小分区,常用分区方式:
范围分区(按时间日期)、哈希分区、列表分区。
示例
订单表按月份分区:
orders_2025_01、orders_2025_02、orders_2025_03
查询2月数据时,仅扫描对应单个分区即可。
核心价值
- 查询速度大幅提升
- 索引扫描效率更高
- 历史数据归档更便捷
- 数据库运维维护更轻松
真实业务场景
日志事件系统年数据量达20亿行,业务查询基本按时间范围筛选。
按日期做表分区后:近期查询仅扫描小范围分区,老旧历史分区可直接归档下线。
表分区无需引入分片的复杂架构,就能显著提升大数据量表的查询性能。
5. 缓存层

不再频繁直连数据库查询,将高频访问数据存入内存缓存 。
常用中间件:Redis、Memcached。
核心优势
内存访问速度比磁盘读写快成千上万倍。
例如商品详情页单日被访问5万次,无需重复查询数据库5万次。
主流缓存设计模式
旁路缓存、直写缓存、延后写缓存。
真实业务场景
电商秒杀场景:百万用户同时抢购同一款商品。
无缓存:数据库瞬间压垮崩溃;
加缓存:请求拦截在缓存层,数据库平稳承压。
最大难点:缓存失效
业内两大公认难题:命名规范、缓存失效。
一旦缓存与数据库数据不一致,用户就会看到过期旧数据。
缓存能极大削减数据库负载,但必须配套完善的数据一致性策略。
6. CQRS 读写职责分离
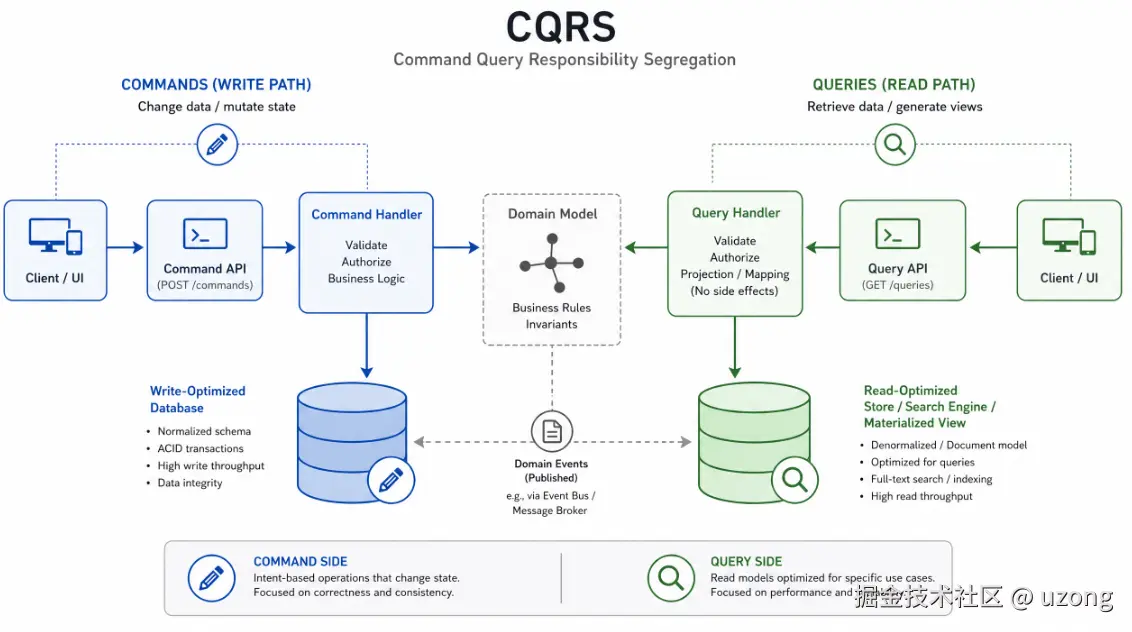
将读模型与写模型彻底拆分 。
摒弃单一数据库承载所有读写请求,分别搭建:
专属写库模型、专属读库模型,甚至可采用完全不同的数据库类型。
设计逻辑
读写业务的诉求完全不同:
写业务:优先保证数据一致性、事务完整性;
读业务:优先追求查询速度、聚合统计、非范式化视图。
真实业务场景
数据分析型平台:
写操作采用PostgreSQL事务型数据库;
读操作采用预计算物化视图,甚至接入Elasticsearch实现极速检索。
架构拆分后,读写两端可独立扩容、独立迭代。
取舍弊端
- 架构复杂度显著提升
- 多库之间数据同步存在挑战
CQRS 极其适合查询复杂、读流量庞大的业务系统。
7. 反范式设计
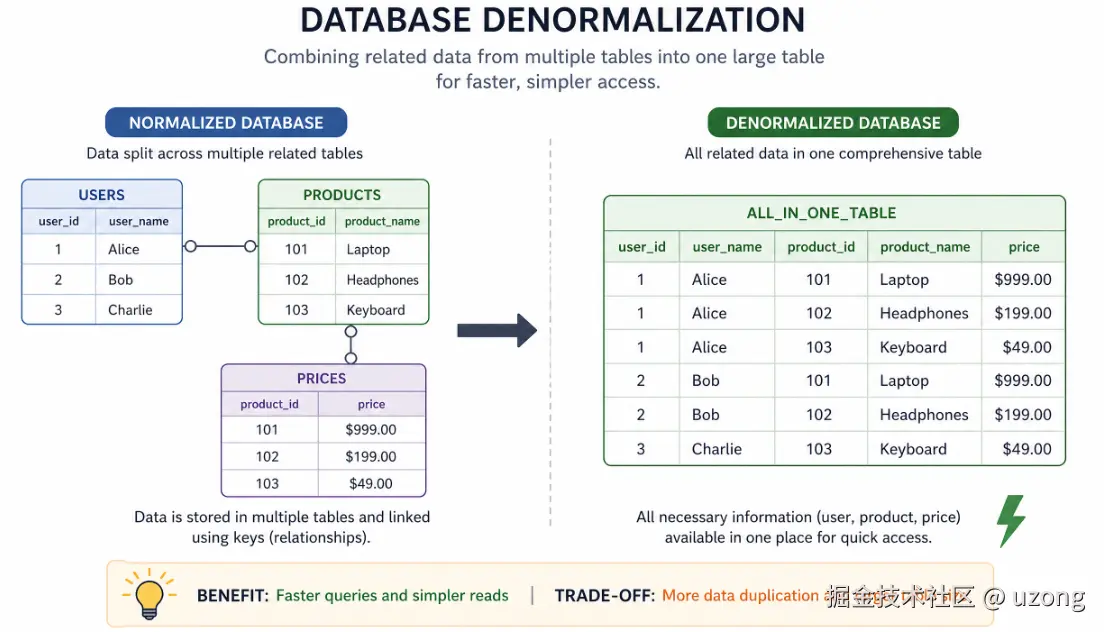
主动冗余存储部分数据,减少联表查询 。
不再做多表联表关联,而是将聚合数据、嵌套数据直接存入单表。
示例
订单表直接冗余存储:用户名、商品名称、下单时快照价格,即便用户表、商品表已单独存在。
设计原因
高并发场景下,多表联表查询性能损耗极高。
真实业务场景
社交动态信息流系统:
不再关联用户表、评论表、点赞表、发帖表做多表联查,
而是直接存储组装完成的信息流结构化数据,大幅提升读取速度。
取舍弊端
- 数据更新逻辑变得复杂
- 冗余数据易出现版本不一致
反范式设计牺牲范式规范,换取极致的查询读取性能。
8. 异步写入
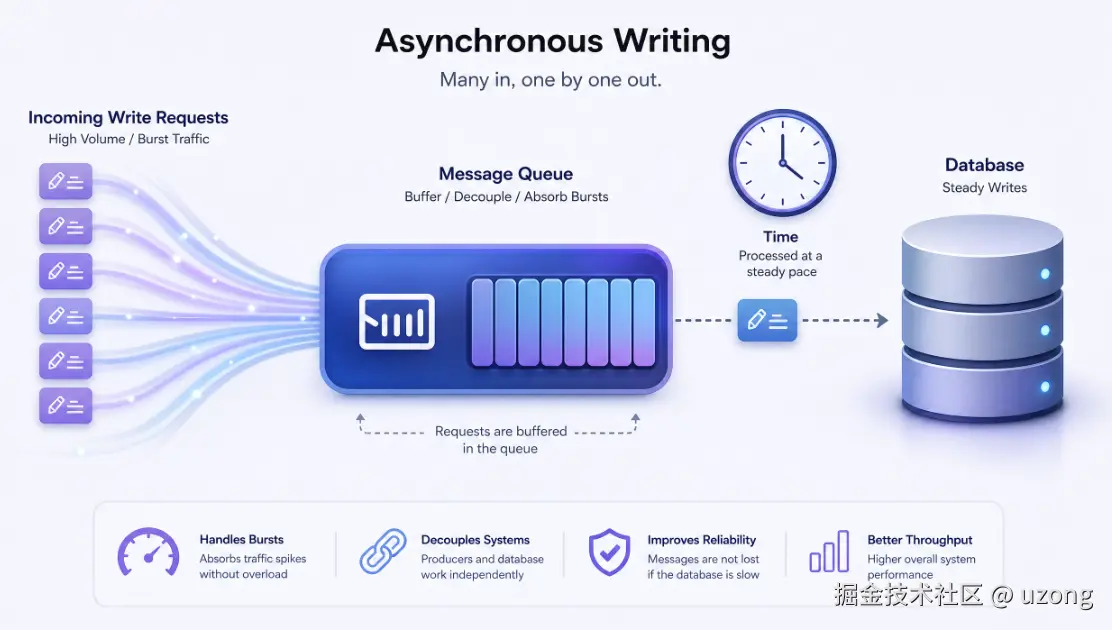
用户请求流程中,不直接同步写入数据库 :
接收用户请求 → 消息队列存入事件 → 后台异步消费完成数据库写入。
核心价值
大幅降低用户感知延迟,用户无需等待数据库繁重的写入处理流程。
真实业务场景
用户上传视频、提交大额订单、上报行为埋点等场景:
不再阻塞接口等待数据库完整写入,而是将事件送入队列,后台异步处理。
取舍弊端
- 丧失即时数据一致性
- 需要完善的失败重试机制
- 必须保证接口幂等性
异步写入能提升系统整体吞吐能力,但依赖可靠的消息队列架构支撑。
9. 索引优化

索引是实现快速检索的数据结构,常见类型:B树索引、哈希索引、复合联合索引。
核心价值
无索引:全表扫描遍历整表数据;
有索引:对数级快速定位数据。
常见开发误区
工程师盲目新建索引。
索引过多会导致:写入性能变慢、存储空间占用增加、数据库清理与运维耗时变长。
索引设计必须贴合实际业务查询语句、执行计划、生产流量特征 。
系统扩容不仅依赖架构升级,精细化的底层优化同样至关重要。
10. 数据归档与分层存储

将低频冷数据迁移至低成本存储介质。
- 热数据:近期交易数据、高频查询业务数据;
- 冷数据:历史日志、合规归档记录、低频老旧数据。
核心价值
超大数据表会拖慢查询效率、加重索引负担、拉高存储成本。
数据归档后:活跃业务数据集体量变小、索引更轻量化、整体性能自然提升。
真实业务场景
金融科技平台:主数据库仅保留近一年交易数据,更早的历史数据迁移至冷存储归档,保障热数据查询极速响应。
数据归档是最容易被忽视、性价比最高的扩容手段之一。
为何数据库扩容策略至关重要
多数系统扩容崩盘,根源都在于:
- 团队默认业务流量线性增长
- 数据库架构一成不变
- 扩容策略落地时机过晚
- 刻意忽略架构取舍利弊
早期选错扩容方案,会带来诸多隐患:
- 后续只能付出高昂成本做架构迁移
- 被迫停机维护、业务中断
- 限制业务长期发展
不存在万能的最优扩容方案,选型取决于:
读写流量比例、数据一致性要求、数据增长速度、流量突发峰值、预算成本、团队技术成熟度。
结语
数据库扩容不是单纯堆砌硬件资源,
核心是读懂业务负载特征、一致性取舍、业务增长趋势、运维复杂度。
架构演进循序渐进:
初期先做垂直扩容、新增读副本、优化索引;
业务规模壮大后,再引入缓存、合理做表分区、评估分片、拆分读写架构。
优秀的工程师从不会等到生产故障发生后才去学习扩容策略,
而是提前为业务规模设计好扩容架构。
这正是普通系统在业务暴涨中崩盘、成熟系统从容扛住流量增长的根本差距。