LangSmith 实操指南(含国内替代方案Langfuse)
LangSmith 是 LangChain 生态下的生产级 LLM 应用开发平台,核心作用是对LLM调用、Agent执行等全链路进行可观测、可追踪、可评估;
简单来说:我们可以将LLM应用的执行数据(输入、输出、耗时、错误信息等)上报到LangSmith平台,直观展示执行过程、排查问题、优化性能,是LLM应用落地的关键工具。
先通过平台界面直观了解LangSmith的核心功能(以下为实操界面截图):
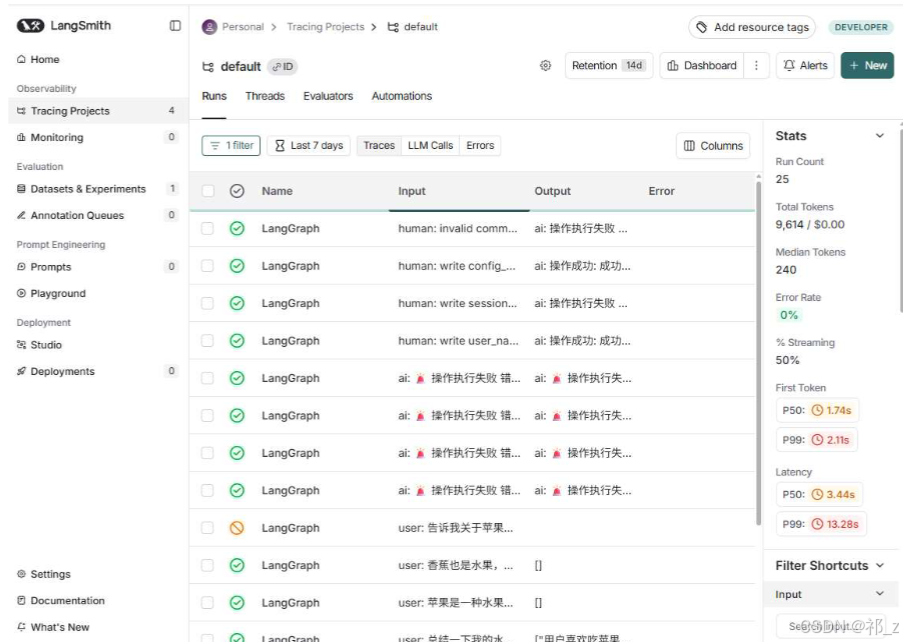
截图说明:LangSmith的Runs页面,可查看所有LLM调用、LangGraph执行记录,包含输入输出、Token消耗、错误信息、延迟等关键数据,支持按时间、类型过滤筛选。
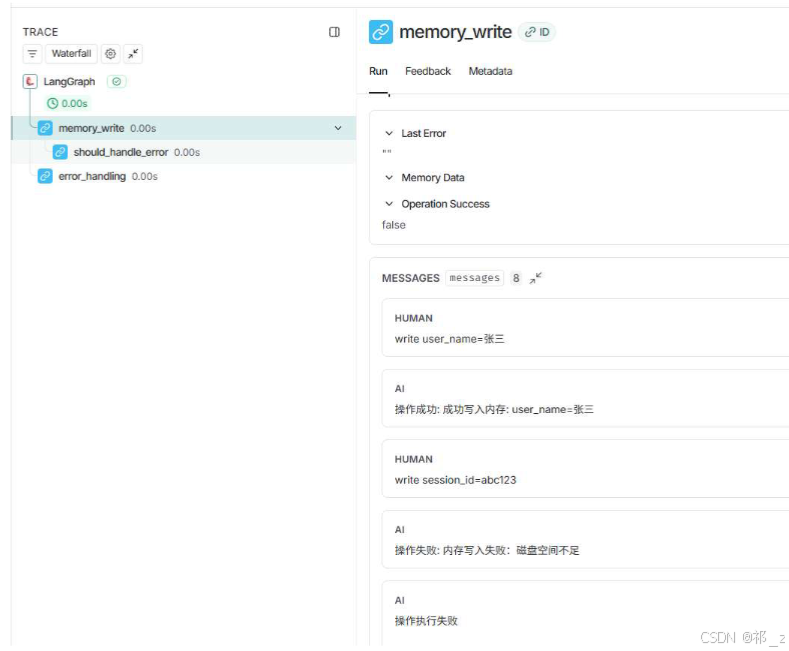
截图说明:LangSmith的链路追踪(Waterfall)页面,可查看Agent执行的全流程耗时分布,比如load_knowledge、agent调用、Prompt渲染等步骤的具体耗时,便于定位性能瓶颈。
一、国内使用LangSmith的痛点
LangSmith 服务器部署在国外,国内普通网络环境无法直接访问;同时其私有部署版本费用较高,对于个人开发者和中小团队来说,使用成本很高。
推荐国内替代方案:Langfuse(开源自托管)
核心优势:可私有部署、完全免费、功能与LangSmith高度对齐,是国内开发者最常用的LLM可观测性工具;关键是LangSmith的代码可直接平移到Langfuse,几乎无需改动,界面布局也基本一致,学习成本极低。
二、LangSmith核心配置(外网可访问场景)
使用LangSmith前,需先配置环境变量,开启追踪功能,具体配置如下(复制可直接使用):
bash
export LANGSMITH_TRACING=true # 开启LLM调用追踪(必须开启,需外网访问)
export LANGSMITH_API_KEY=<your-api-key> # 从LangSmith平台获取的API Key
export LANGSMITH_PROJECT=default # 项目名称,用于区分多个LLM应用项目三、LangSmith登录与API Key获取
-
访问LangSmith官方登录/注册地址:https://smith.langchain.com/onboarding?organizationId=23e9c879-0e89-4070-a2f9-a4216dfc91b3
-
注册/登录方式:支持Google、Github、Discord账号快捷登录,也可通过邮箱密码注册登录(首次登录需选择数据区域,一旦选择无法修改)。
-
获取API Key:登录后,进入平台「Settings」(设置)页面,找到「API Keys」选项,创建并复制个人API Key,替换上述配置中的<your-api-key>即可。
四、LangSmith追踪实操(自动上报数据)
LangSmith支持两种核心追踪场景:单独追踪LLM调用 、全链路追踪(整个函数/方法执行),实操代码如下(结合OpenAI示例,复制可直接运行):
1. 单独追踪LLM调用
python
from openai import OpenAI
from langsmith.wrappers import wrap_openai # 核心包
# 包装 OpenAI 客户端,开启 LangSmith 追踪
openai_client = wrap_openai(OpenAI(api_key="你的OpenAI API Key"))
# 后续调用 OpenAI,数据会自动上报到 LangSmith
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "苹果是一种水果吗?"}]
)2. 全链路追踪(追踪整个函数/方法)
通过@traceable装饰器,可追踪整个函数的执行过程,包括函数内的LLM调用、工具调用等,实操代码如下:
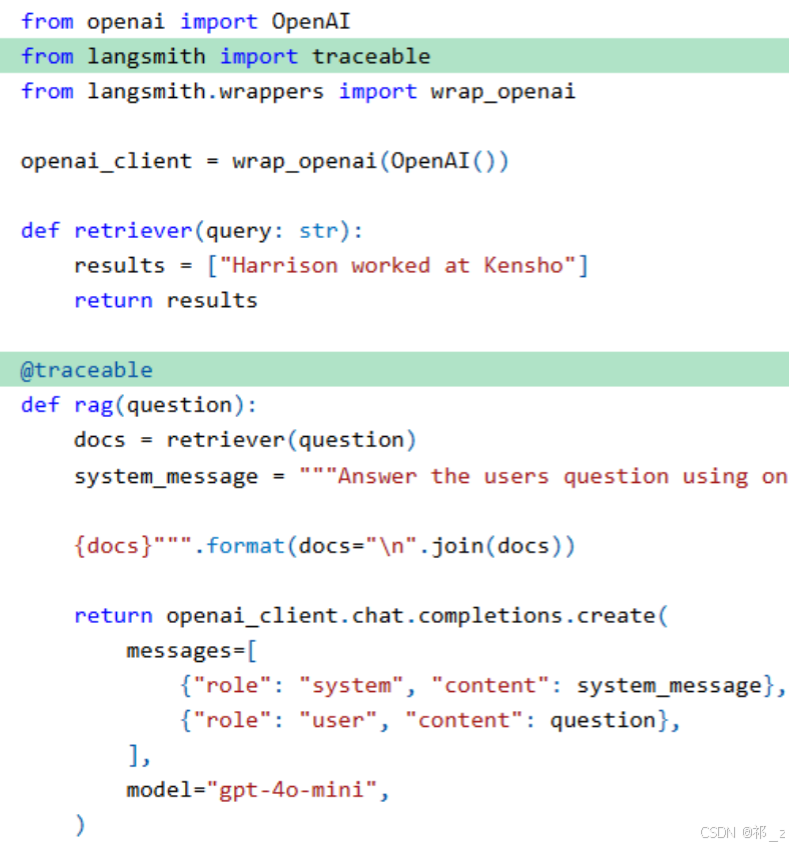
python
from openai import OpenAI
from langsmith import traceable
openai = OpenAI(api_key="你的OpenAI API Key")
def retriever(query: str):
results = ["Harrison worked at Kensho"]
return results
@traceable # 装饰器已覆盖全链路,包括内部LLM调用
def rag(question):
docs = retriever(question)
system_message = """Answer the user's question using only the provided documents:
{docs}""".format(docs="\n".join(docs))
return openai.chat.completions.create(
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": question}
],
model="gpt-4o-mini"
)
rag("Where did Harrison work?")五、LangSmith可观测性实用技巧
在 LLM 应用执行时,通过 config 中的 metadata 和 tags 添加额外信息,可大幅提升追踪、过滤、分析的效率,两者的区别与用法如下:
-
tags :字符串列表(Liststr),侧重于分类和标记,适合用于区分应用版本、功能模块、场景类型等。
-
metadata :字典(Dictstr, Any),适合存储结构化补充信息,比如用户ID、环境(开发/生产)、请求ID等,便于精准定位问题。
三种打标签的实操示例:
python
# 1、调用时传入 config
app = ChatOpenAI(model="gpt-4o-mini")
app.invoke(
"介绍langsmith可观测性的技巧",
config={
"metadata": {"user_id": user_name, "env": "production", "request_id": "abc123"},
"tags": ["agent_ReACT", "v3.1", "observability"],
}
)
--------------
# 2、给整个方法函数加上标签,每次调用都会带。
from langchain_core.runnables import RunnableLambda
# 给 chain 绑定固定 tags + metadata
app = ChatOpenAI(model="gpt-4o-mini")
app = app.with_tags(["rag_chain", "production"]) # tags
app = app.with_metadata({"version": "v3.1", "owner": "dev-team"}) # metadata
# 之后直接调用,自动带标签
app.invoke("介绍langsmith可观测性的技巧")
-------------
# 3、直接给函数打标签(最常用)。
from langsmith import traceable
@traceable(
tags=["rag", "agent_demo"],
metadata={"env": "test", "model": "gpt-4o-mini"}
)
def my_rag_chain(question):
# 你的逻辑
pass添加后,可在LangSmith平台通过tags筛选特定版本、特定模块的执行记录,也可通过metadata查询某个用户、某个请求的完整执行链路,排查问题更高效。
六、补充说明
-
若国内网络无法访问LangSmith,直接替换为Langfuse即可,代码无需大幅修改,仅需调整环境变量和导入包,后续可单独补充Langfuse的配置与实操。
-
LangSmith的核心价值的是"可观测性",无论是调试LLM应用的错误、优化Prompt、还是监控生产环境的性能,都能通过平台直观看到执行细节,是LLM应用从开发到落地的必备工具。