动⼿实现⼀个LLaMA2⼤模型
LLaMA2 模型结构如图:
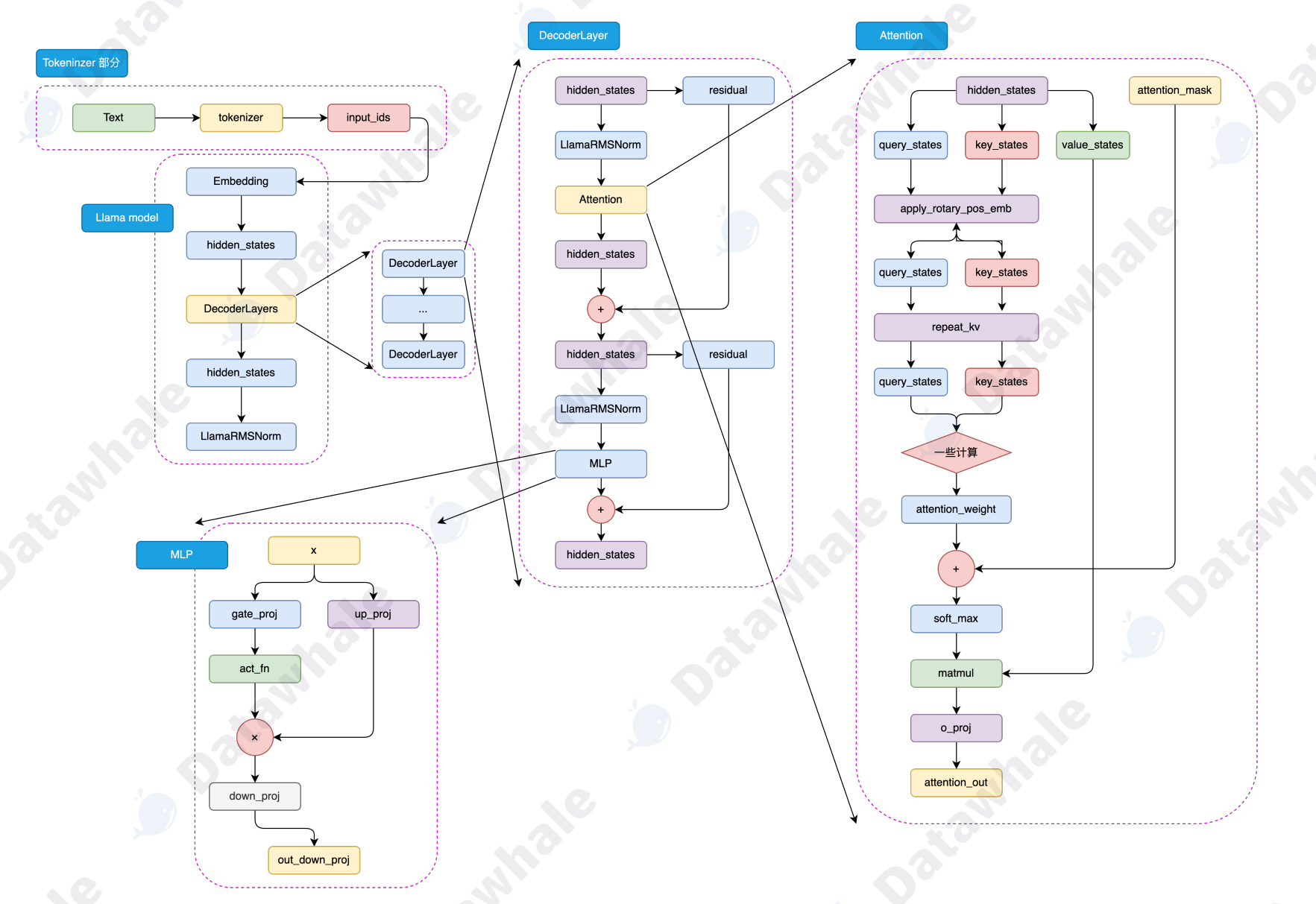
LLaMA2 大模型
├─ 词嵌入层(把单词变成向量)
├─ 堆叠 N 个 Decoder 层(核心计算层)
│ ├─ RMSNorm(归一化)
│ ├─ LLaMA2 Attention(注意力:含RoPE + GQA + repeat_kv)
│ ├─ RMSNorm(归一化)
│ └─ LLaMA2 MLP(前馈网络)
├─ 最终 RMSNorm
└─ LM 输出头(输出下一个词概率)
模块结构介绍
1. RMSNorm
-
结构:只有缩放权重,无偏置
-
公式:
x / sqrt(mean(x²) + eps) * weight -
作用:归一化特征,防止梯度爆炸
2. RoPE 旋转位置编码
-
结构:对 Q、K 分别按位置旋转复数角度
-
作用:让模型知道 "词的顺序"
3. repeat_kv
-
结构:把 KV 头重复 N 次,与 Q 头数对齐
-
作用:GQA 分组注意力,减少计算量
4. LLaMA2 Attention
-
结构:QKV 线性层 + RoPE + repeat_kv + 掩码注意力
-
作用:建模上下文依赖
5. LLaMA2 MLP
-
结构:3 个线性层 + SiLU 激活(SwiGLU)
-
公式:
silu(w1(x)) * w3(x) → w2(...) -
作用:非线性特征变换
6. DecoderLayer
-
结构:Pre-Norm 结构
-
流程:
x → norm → attention → 残差 → norm → MLP → 残差
7. LLaMA2 模型
-
结构:嵌入层 + N 个 Decoder + 归一化 + 输出头
-
任务:自回归语言模型(预测下一个词)
代码
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
# ===================== 超参数 =====================
class LLaMA2Config:
dim: int = 128
n_layers: int = 2
n_heads: int = 8
n_kv_heads: int = 2
vocab_size: int = 1024
multiple_of: int = 256
norm_eps: float = 1e-5
max_seq_len: int = 64
# ===================== RMSNorm =====================
class RMSNorm(nn.Module):
def __init__(self, dim, eps):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def forward(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps) * self.weight
# ===================== RoPE 旋转位置编码 =====================
def precompute_rope_freqs_cis(dim, end, theta=10000.0):
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2).float() / dim))
freqs = torch.outer(torch.arange(end), freqs)
return torch.polar(torch.ones_like(freqs), freqs)
def apply_rope(x, freqs_cis):
x_complex = torch.view_as_complex(x.float().reshape(*x.shape[:-1], -1, 2))
freqs_cis = freqs_cis.view(1, x.shape[1], 1, x.shape[-1]//2)
return torch.view_as_real(x_complex * freqs_cis).flatten(-2).type_as(x)
# ===================== repeat_kv 分组注意力 =====================
def repeat_kv(x, n_rep):
if n_rep == 1: return x
return x[:, :, None, :, :].expand(x.shape[0], x.shape[1], n_rep, x.shape[2], x.shape[3]).reshape(
x.shape[0], x.shape[1]*n_rep, x.shape[2], x.shape[3])
# ===================== LLaMA2 Attention =====================
class LLaMA2Attention(nn.Module):
def __init__(self, config):
super().__init__()
self.dim = config.dim
self.n_heads = config.n_heads
self.n_kv_heads = config.n_kv_heads
self.head_dim = config.dim // config.n_heads
self.n_rep = config.n_heads // config.n_kv_heads
self.wq = nn.Linear(config.dim, config.n_heads * self.head_dim, bias=False)
self.wk = nn.Linear(config.dim, self.n_kv_heads * self.head_dim, bias=False)
self.wv = nn.Linear(config.dim, self.n_kv_heads * self.head_dim, bias=False)
self.wo = nn.Linear(config.n_heads * self.head_dim, config.dim, bias=False)
self.freqs_cis = precompute_rope_freqs_cis(self.head_dim, config.max_seq_len*2)
def forward(self, x):
bs, seq_len, _ = x.shape
q = self.wq(x).view(bs, seq_len, self.n_heads, self.head_dim).transpose(1,2)
k = self.wk(x).view(bs, seq_len, self.n_kv_heads, self.head_dim).transpose(1,2)
v = self.wv(x).view(bs, seq_len, self.n_kv_heads, self.head_dim).transpose(1,2)
q = apply_rope(q, self.freqs_cis[:seq_len])
k = apply_rope(k, self.freqs_cis[:seq_len])
k = repeat_kv(k, self.n_rep)
v = repeat_kv(v, self.n_rep)
mask = torch.tril(torch.ones(seq_len, seq_len, device=x.device)) == 0
scores = torch.matmul(q, k.transpose(-2,-1)) / math.sqrt(self.head_dim)
scores = scores.masked_fill(mask, float('-inf'))
attn = F.softmax(scores, dim=-1)
out = torch.matmul(attn, v).transpose(1,2).reshape(bs, seq_len, -1)
return self.wo(out)
# ===================== LLaMA2 MLP =====================
class LLaMA2MLP(nn.Module):
def __init__(self, config):
super().__init__()
hidden_dim = int(2 * 4 * config.dim / 3)
hidden_dim = config.multiple_of * ((hidden_dim + config.multiple_of -1) // config.multiple_of)
self.w1 = nn.Linear(config.dim, hidden_dim, bias=False)
self.w2 = nn.Linear(hidden_dim, config.dim, bias=False)
self.w3 = nn.Linear(config.dim, hidden_dim, bias=False)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
# ===================== Decoder Layer =====================
class LLaMA2DecoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.attention_norm = RMSNorm(config.dim, config.norm_eps)
self.attention = LLaMA2Attention(config)
self.ffn_norm = RMSNorm(config.dim, config.norm_eps)
self.mlp = LLaMA2MLP(config)
def forward(self, x):
x = x + self.attention(self.attention_norm(x))
x = x + self.mlp(self.ffn_norm(x))
return x
# ===================== LLaMA2 完整模型 =====================
class LLaMA2(nn.Module):
def __init__(self, config):
super().__init__()
self.tok_embeddings = nn.Embedding(config.vocab_size, config.dim)
self.layers = nn.ModuleList([LLaMA2DecoderLayer(config) for _ in range(config.n_layers)])
self.norm = RMSNorm(config.dim, config.norm_eps)
self.lm_head = nn.Linear(config.dim, config.vocab_size, bias=False)
def forward(self, tokens):
h = self.tok_embeddings(tokens)
for layer in self.layers:
h = layer(h)
h = self.norm(h)
return self.lm_head(h)
# ===================== 测试 =====================
if __name__ == "__main__":
config = LLaMA2Config()
model = LLaMA2(config)
x = torch.randint(0, config.vocab_size, (2, 10))
logits = model(x)
print("输入形状:", x.shape)
print("输出形状:", logits.shape)