一、背景
在数据仓库和数据建模中,维度表的属性并不是一成不变的。随着业务的发展,常常会出现诸如产品调价、客户信息变更、组织架构调整、渠道归属变化、会员等级升级 等场景。对于这类"会变化但又需要保留历史"的数据,Slowly Changing Dimension Type 2(缓慢变化维度第二类,简称为SCD Type 2) 是最经典、最常用的处理方式之一。
SCD Type 2 的核心思想是:当维度属性发生变化时,不覆盖旧记录,而是保留历史版本,同时插入一条新的当前版本记录。这样一来,既能准确反映当前状态,又能完整追溯任意时间点的历史面貌,为后续分析提供可追溯、可审计的数据基础。
之所以在很多数据仓库场景中必须使用 SCD Type 2,通常是因为它能够很好地满足以下几类需求:
-
历史追溯与分析:支持按任意时间点还原维度状态,便于做同比、环比、留存、归因等分析
-
数据治理:通过保留版本链路,提升数据血缘、数据演变过程的可追踪性,便于问题排查和口径统一
-
合规与审计:满足金融、零售、政企等场景对数据留痕、历史可查、审计可回放的要求
-
业务决策复盘:支持回看"当时系统看到的是什么",避免因为维表覆盖更新导致分析结果失真
-
降本增效:避免为历史数据单独维护多套快照表或离线备份链路,减少重复存储和维护成本
-
易用性与标准化:统一历史管理方式,降低业务方和开发方在维度变更处理上的复杂度
使用 SCD Type 2 较多的行业包括:
- 金融与银行:
风险评估 :当客户的信用评级(Credit Rating)或收入等级发生变化时,银行需要保留变动前后的记录,以准确追溯历史贷款审批时的风险背景。
合规监管:金融监管通常要求能够回溯至任何一个历史时间点,查看当时用户的状态信息。
- 电子商务与零售:
区域销售分析 :如果一名会员从"上海"搬家到了"北京",系统需要记录搬家前后的订单分别属于哪个区域。如果直接覆盖(Type 1),会导致历史上的上海订单被错误地统计到北京名下。
定价策略:追踪产品价格、SKU分类或促销状态的变化历史,以便分析调价对销量的长期影响。
- 保险行业:
保单管理:投保人的婚姻状况、职业或健康状态随时间发生变化,保险公司需要根据事故发生时刻的投保人属性来决定理赔额度。
- 电信与公共事业:
套餐与地址管理:用户的宽带套餐升级历程或居住地变动,对分析用户流失率(Churn Rate)和长期价值(LTV)至关重要。
传统实现 SCD Type 2 时,通常会遇到不少工程上的困难:
-
变更检测依赖外部组件:需要借助 Canal、Flink CDC 等工具捕获数据变更,链路较长,开发和运维成本高
-
缺乏原生行级更新能力:很多传统数仓表只能通过分区覆盖写、全量替换或批量重算来模拟更新,效率和灵活性都不理想
-
历史快照维护繁琐:通常需要额外设计历史表、快照表或版本表,并手动管理生效时间、失效时间和当前标识
-
容易出现口径不一致:不同团队可能采用不同的历史保留方式,导致同一维度在不同报表中的解释不一致
MaxCompute 的 Delta Table 为这些问题提供了一种更简洁、更工程化的解法。Delta Table 原生支持 ACID 事务 、行级 UPDATE / DELETE / MERGE ,并内置 Time Travel 能力------每次事务提交后都会自动生成版本快照,可以通过 VERSION AS OF 或 TIMESTAMP AS OF 回溯到任意历史状态。
这意味着,原本需要依赖外部 CDC、手工快照和复杂维护逻辑才能实现的 SCD Type 2,现在可以借助 Delta Table 更自然地落地。
本文将以一个产品价格变更的场景为例,完整演示如何利用 Delta Table 的 Time Travel 能力实现 SCD Type 2。
二、方案架构
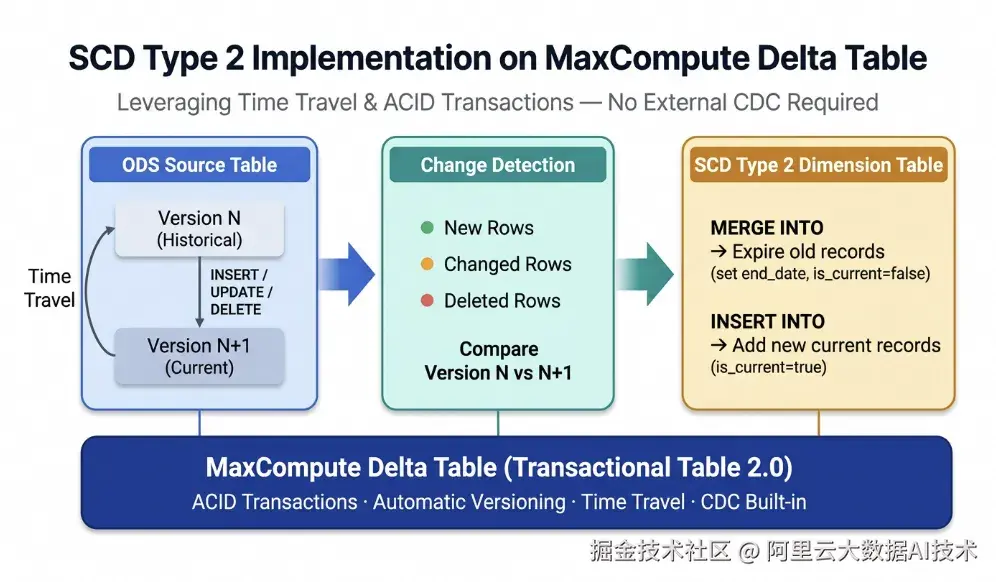
核心思路 :每次增量处理时,通过 Time Travel 将 ODS 源表的当前版本 与上一次处理时的版本进行对比,自动检测出新增、变更、删除的记录,再通过 MERGE + INSERT 完成 SCD Type 2 的更新逻辑。
三、示例数据
本文的案例模拟了一家手机零售公司的产品维度数据,初始数据如下:
| product_id | product_name | current_price |
|---|---|---|
| 100 | Nokia | 1000 |
| 200 | Apple | 5000 |
| 300 | Samsung | 9000 |
| 500 | HP | 7000 |
变更场景:Nokia 降价,价格从 1000 调整为 200。
四、完整实现步骤
Step 1:创建 ODS 源表(Delta Table)
通过 "table.format.version"="2" 将表声明为 Delta Table,开启 ACID 事务和 Time Travel 能力,且通过 "acid.cdc.build.async"="false" 将 CDC 构建模式声明为同步。
sql
CREATE TABLE IF NOT EXISTS ods_product_delta (
product_id BIGINT COMMENT '产品ID',
product_name STRING COMMENT '产品名称',
current_price BIGINT COMMENT '当前价格'
)
COMMENT 'ODS产品源表(Delta Table)'
TBLPROPERTIES ("table.format.version"="2", "acid.cdc.build.async"="false");Step 2:加载初始数据
sql
INSERT INTO TABLE ods_product_delta VALUES
(100, 'Nokia', 1000),
(200, 'Apple', 5000),
(300, 'Samsung', 9000),
(500, 'HP', 7000);验证:
sql
SELECT * FROM ods_product_delta;Step 3:记录当前版本号
执行 SHOW HISTORY 记录当前版本号,该版本号将在后续 Time Travel 对比中作为基线。
sql
SHOW HISTORY FOR ods_product_delta;记录输出中的版本号(假设初始加载后为 version 1__),后续步骤中以此为基准。
Step 4:创建 SCD Type 2 维度表
维度表在原始业务字段的基础上,增加三个 SCD Type 2 管理字段:
| 字段 | 含义 |
|---|---|
effective_start_date |
该版本记录的生效起始日期 |
effective_end_date |
该版本记录的失效日期(9999-12-31 表示当前有效) |
is_current |
是否为当前有效版本 |
sql
CREATE TABLE IF NOT EXISTS dim_product_scd2 (
product_id BIGINT COMMENT '产品ID',
product_name STRING COMMENT '产品名称',
current_price BIGINT COMMENT '价格',
effective_start_date STRING COMMENT '生效开始日期',
effective_end_date STRING COMMENT '生效结束日期',
is_current BOOLEAN COMMENT '是否当前有效记录'
)
COMMENT 'SCD Type 2 产品维度表'
TBLPROPERTIES ("table.format.version"="2");Step 5:初始化加载维度表
将 ODS 源表的初始快照全量写入维度表,所有记录标记为当前有效:
sql
INSERT INTO TABLE dim_product_scd2
SELECT
product_id,
product_name,
current_price,
'2026-04-08' AS effective_start_date,
'9999-12-31' AS effective_end_date,
true AS is_current
FROM ods_product_delta;验证:
sql
SELECT * FROM dim_product_scd2 ORDER BY product_id;预期结果:
| product_id | product_name | current_price | effective_start_date | effective_end_date | is_current |
|---|---|---|---|---|---|
| 100 | Nokia | 1000 | 2026-04-08 | 9999-12-31 | true |
| 200 | Apple | 5000 | 2026-04-08 | 9999-12-31 | true |
| 300 | Samsung | 9000 | 2026-04-08 | 9999-12-31 | true |
| 500 | HP | 7000 | 2026-04-08 | 9999-12-31 | true |
Step 6:模拟数据变更
对 ODS 源表执行行级 UPDATE,将 Nokia 的价格从 1000 改为 200:
sql
UPDATE ods_product_delta
SET current_price = 200
WHERE product_id = 100;这是 Delta Table 相对于传统 MaxCompute 表的核心优势之一------支持行级更新,无需分区覆盖写。
验证:
sql
SELECT * FROM ods_product_delta;Nokia 的价格已更新为 200,其余记录不受影响。
Step 7:Time Travel------回溯历史快照
无需任何备份机制,Delta Table 内置的 Time Travel 能力可直接查询任意历史版本:
sql
-- 方式一:按版本号回溯(推荐,精确可控)
SELECT * FROM ods_product_delta VERSION AS OF 2;
-- 方式二:按时间戳回溯
SELECT * FROM ods_product_delta
TIMESTAMP AS OF TIMESTAMP'2026-04-08 10:00:00';查询结果为 UPDATE 之前的数据快照------Nokia 价格仍为 1000。
Step 8:变更检测
将 ODS 源表的当前版本与历史版本进行 FULL OUTER JOIN,自动识别出所有新增、变更和删除的记录:
sql
WITH hist_snapshot AS (
SELECT * FROM ods_product_delta VERSION AS OF 2
)
SELECT
COALESCE(curr.product_id, hist.product_id) AS product_id,
COALESCE(curr.product_name, hist.product_name) AS product_name,
hist.current_price AS old_price,
curr.current_price AS new_price,
CASE
WHEN hist.product_id IS NULL THEN 'NEW'
WHEN curr.product_id IS NULL THEN 'DELETED'
WHEN curr.current_price <> hist.current_price THEN 'CHANGED'
ELSE 'UNCHANGED'
END AS change_type
FROM ods_product_delta curr
FULL OUTER JOIN hist_snapshot hist
ON curr.product_id = hist.product_id
WHERE curr.current_price <> hist.current_price
OR curr.product_id IS NULL
OR hist.product_id IS NULL;预期结果:
| product_id | product_name | old_price | new_price | change_type |
|---|---|---|---|---|
| 100 | Nokia | 1000 | 200 | CHANGED |
无需任何外部 CDC 组件__,仅凭 Delta Table 的 Time Travel 即可完成变更检测。
Step 9:执行 SCD Type 2 更新
SCD Type 2 的更新逻辑分为三步:关闭旧记录、插入新记录、处理删除。
a. 关闭变更记录的旧版本
对维度表中已发生变更的当前有效记录,将 is_current 置为 false,并设置失效日期:
sql
WITH hist_snapshot AS (
SELECT * FROM ods_product_delta VERSION AS OF 2
)
MERGE INTO dim_product_scd2 tgt
USING (
SELECT
curr.product_id,
curr.product_name,
curr.current_price
FROM ods_product_delta curr
INNER JOIN hist_snapshot hist
ON curr.product_id = hist.product_id
WHERE curr.current_price <> hist.current_price
OR curr.product_name <> hist.product_name -- check all tracked attributes
) src
ON tgt.product_id = src.product_id AND tgt.is_current = true
WHEN MATCHED THEN UPDATE SET
tgt.effective_end_date = '2026-04-08',
tgt.is_current = false;b. 插入变更和新增记录的当前版本
将变更后的记录和新增的记录统一写入维度表,标记为当前有效:
sql
WITH hist_snapshot AS (
SELECT * FROM ods_product_delta VERSION AS OF 2
)
INSERT INTO TABLE dim_product_scd2
SELECT
src.product_id,
src.product_name,
src.current_price,
'2026-04-08' AS effective_start_date,
'9999-12-31' AS effective_end_date,
true AS is_current
FROM (
-- Changed records
SELECT curr.*
FROM ods_product_delta curr
INNER JOIN hist_snapshot hist
ON curr.product_id = hist.product_id
WHERE curr.current_price <> hist.current_price
OR curr.product_name <> hist.product_name
UNION ALL
-- New records (exist in current version but not in previous version)
SELECT curr.*
FROM ods_product_delta curr
LEFT JOIN hist_snapshot hist
ON curr.product_id = hist.product_id
WHERE hist.product_id IS NULL
) src;c. 处理删除记录(可选)
如果 ODS 源表中有记录被删除,将维度表中对应的当前有效记录关闭:
sql
WITH hist_snapshot AS (
SELECT * FROM ods_product_delta VERSION AS OF 2
)
MERGE INTO dim_product_scd2 tgt
USING (
SELECT hist.product_id
FROM hist_snapshot hist
LEFT JOIN ods_product_delta curr
ON hist.product_id = curr.product_id
WHERE curr.product_id IS NULL
) deleted
ON tgt.product_id = deleted.product_id AND tgt.is_current = true
WHEN MATCHED THEN UPDATE SET
tgt.effective_end_date = '2026-04-08',
tgt.is_current = false;Step 10:验证结果
sql
SELECT * FROM dim_product_scd2
ORDER BY product_id, effective_start_date;预期结果:
| product_id | product_name | current_price | effective_start_date | effective_end_date | is_current |
|---|---|---|---|---|---|
| 100 | Nokia | 1000 | 2026-04-08 | 2026-04-08 | false |
| 100 | Nokia | 200 | 2026-04-08 | 9999-12-31 | true |
| 200 | Apple | 5000 | 2026-04-08 | 9999-12-31 | true |
| 300 | Samsung | 9000 | 2026-04-08 | 9999-12-31 | true |
| 500 | HP | 7000 | 2026-04-08 | 9999-12-31 | true |
Nokia(product_id = 100)现在有两条记录:
-
历史版本 :价格 1000,已失效(
is_current = false) -
当前版本 :价格 200,有效(
is_current = true)
五、查询维度表的正确方式
SCD Type 2 维度表中同一实体可能存在多条记录(历史版本 + 当前版本),下游查询时需要根据场景选择合适的过滤条件。
查询当前最新状态
sql
-- 方式一:通过 is_current 标记过滤
SELECT * FROM dim_product_scd2 WHERE is_current = true;
-- 方式二:通过 effective_end_date 过滤
SELECT * FROM dim_product_scd2 WHERE effective_end_date = '9999-12-31';建议为下游创建一个 View,封装过滤逻辑,避免每次手动添加条件:
sql
CREATE VIEW v_dim_product_current AS
SELECT product_id, product_name, current_price
FROM dim_product_scd2
WHERE is_current = true;下游直接查询该 View 即可获取最新数据,无需关心 SCD Type 2 的底层实现。
查询某个历史时间点的快照
sql
-- 查询 2026-04-07 时的产品价格(Nokia 降价之前)
SELECT *
FROM dim_product_scd2
WHERE effective_start_date <= '2026-04-07'
AND effective_end_date > '2026-04-07';查询某个产品的完整变更历史
sql
SELECT *
FROM dim_product_scd2
WHERE product_id = 100
ORDER BY effective_start_date;六、生产环境注意事项
1. 版本号管理
示例中 VERSION AS OF 2 是硬编码的。生产环境中,每次增量处理前应通过 SHOW HISTORY 获取当前版本号,并在处理完成后将该版本号持久化(写入元数据表或配置),作为下一次增量处理的基线:
sql
-- 建议维护一张元数据表,记录每次处理的版本号
CREATE TABLE IF NOT EXISTS meta_scd2_checkpoint (
table_name STRING COMMENT '表名',
last_version BIGINT COMMENT '上次处理的版本号',
process_time STRING COMMENT '处理时间'
)
TBLPROPERTIES ("table.format.version"="2");2. 日期字段类型
示例中为简化演示使用了 STRING 类型。生产环境建议使用 DATETIME 类型,并记录精确到秒的时间戳,以支持更细粒度的时间点查询。
3. 变更检测的完备性
如果维度表追踪的属性较多,建议在变更检测的 WHERE 条件中覆盖所有需要追踪的字段,或者使用 checksum / hash 来简化比较逻辑:
sql
-- 使用多字段拼接的 hash 进行变更检测
WHERE MD5(CONCAT(curr.product_name, '|', curr.current_price))
<> MD5(CONCAT(hist.product_name, '|', hist.current_price))4. Time Travel 的保留期限
Delta Table 的历史版本有保留期限(默认配置请参考 MaxCompute 文档),超过保留期的历史版本会被自动清理。增量调度频率应在保留期限内,确保 Time Travel 基线版本可用。
七、方案优势总结
7.1 与传统 MaxCompute 方案的对比
| 维度 | 传统方案 | Delta Table 方案 |
|---|---|---|
| 数据变更 | 分区覆盖写 / 全量替换 | 行级 UPDATE/DELETE,ACID 保障 |
| 变更检测 | 依赖 Canal / Flink CDC 等外部组件 | Time Travel 原生对比,零外部依赖 |
| 历史追溯 | 手动维护快照表或每日全量备份 | 内置版本管理,VERSION AS OF 即时回溯 |
| SCD2 实现 | ETL 链路长,涉及多个组件协调 | MERGE INTO + Time Travel,SQL 原生闭环 |
| 运维成本 | 高(多组件、多链路) | 低(单引擎、单 SQL 层) |
7.2 与主流云数仓平台的对比
以下将 MaxCompute Delta Table 的 SCD Type 2 实现方案与四大主流云数仓平台进行横向对比。
7.2.1 核心能力矩阵
| 能力 | MaxCompute Delta Table | Databricks (Delta Lake) | Snowflake | Google BigQuery | AWS Redshift |
|---|---|---|---|---|---|
| 表格式 | Delta Table (事务表2.0) | Delta Lake (开源) | 原生微分区表 | BigQuery 原生表 | Redshift 原生表 / Iceberg |
| MERGE INTO | 原生支持 | 原生支持 | 原生支持 | 支持 | 原生支持 |
| 行级 UPDATE/DELETE | 原生支持 | 原生支持 | 原生支持 | 支持 | 支持 |
7.2.2 CDC(变更捕获)能力 z 对比
| 维度 | MaxCompute | Databricks | Snowflake | BigQuery | Redshift |
|---|---|---|---|---|---|
| CDC 机制 | TABLE_CHANGES() 函数 |
table_changes() 函数 (Change Data Feed) |
Stream 对象 + CHANGES 子句 |
CHANGES() TVF |
无内置 CDC 函数 |
| 启用方式 | 表属性 acid.cdc.mode.enable=true |
表属性 delta.enableChangeDataFeed=true |
CREATE STREAM ON TABLE ...(独立对象) |
表属性 enable_change_history=true |
需外部工具 (DMS / Glue) |
| 查询维度 | 按版本号区间 | 按版本号区间 | Stream 偏移量自动推进 | 按时间戳区间 | N/A |
| 变更类型标识 | _change_type: insert, delete |
_change_type: insert, update_preimage, update_postimage, delete |
METADATA$ACTION (INSERT/DELETE) + METADATA$ISUPDATE (true/false) |
_CHANGE_TYPE: INSERT, UPDATE, DELETE |
N/A |
| UPDATE 语义 | 拆为 delete + insert | 提供变更前 (update_preimage) 和变更后 (update_postimage),语义最丰富 |
拆为 DELETE(ISUPDATE=true) + INSERT(ISUPDATE=true) |
拆为 DELETE + UPDATE |
N/A |
| 消费模型 | 按版本区间自由查询,可重复读 | 按版本区间自由查询,可重复读 | Stream 消费后偏移量自动推进,默认不可重复读 ;CHANGES 子句可重复读 |
按时间戳区间查询,可重复读 | N/A |
| 查询延迟 | 同步构建模式(acid.cdc.build.async=false)下无延迟 |
无延迟 | 无延迟 | 至少 10 分钟延迟 (end_timestamp 须早于当前时间 10 分钟) |
N/A |
| 外部依赖 | 无 | 无 | 无 | 无 | 有(需 AWS DMS/Glue) |
重点差异解读:
-
MaxCompute vs Databricks :功能最接近。两者都通过表属性启用 CDC,都用
TABLE_CHANGES函数按版本区间查询。区别在于 Databricks 的 CDC 语义更细------区分update_preimage(变更前镜像)和update_postimage(变更后镜像),而 MaxCompute 将 UPDATE 拆为 delete + insert。 -
MaxCompute vs Snowflake :Snowflake 用 Stream 对象 做 CDC,这是一个独立的数据库对象,有偏移量管理机制(类似 Kafka consumer)。Stream 被消费(如在 DML 事务中引用)后偏移量自动推进,默认不可重复读 。MaxCompute 的
TABLE_CHANGES按版本区间查询,任意时间可重复读,使用更灵活。 -
MaxCompute vs BigQuery :BigQuery 也提供了
CHANGES()TVF 查询行级变更,功能方向一致。但有两个实际限制:一是变更历史受限于 Time Travel 窗口(最长 7 天),二是查询有 10 分钟延迟。MaxCompute 按版本号精确查询,同步模式下无延迟,历史保留期更灵活。 -
MaxCompute vs Redshift:Redshift 没有内置 CDC 查询函数,SCD2 实现依赖外部组件(DMS/Glue),链路最长。Redshift 2025 年初推出的 History Mode 可自动追踪变更,但仅限 zero-ETL 集成场景,通用性不足。
7.2.3 Time Travel 对比
| 维度 | MaxCompute | Databricks | Snowflake | BigQuery | Redshift |
|---|---|---|---|---|---|
| 语法 | VERSION AS OF N / TIMESTAMP AS OF ts |
VERSION AS OF N / TIMESTAMP AS OF ts |
AT(OFFSET => -N) / AT(TIMESTAMP => ts) |
FOR SYSTEM_TIME AS OF ts |
Iceberg 快照查询 |
| 最大保留期 | 可配置 | 默认 30 天(可配置) | Standard 版 1 天 ;Enterprise+ 版最长 90 天 | 最长 7 天 | 取决于快照过期策略 |
| 用于变更检测 | 直接 JOIN 两个版本做 diff | 直接 JOIN 或用 CDF | 可以但通常用 Stream 替代 | 保留窗口短,生产环境受限 | 不常用 |
7.2.4 SCD Type 2 实现方式对比
| 维度 | MaxCompute | Databricks | Snowflake | BigQuery | Redshift |
|---|---|---|---|---|---|
| 典型方案 | Time Travel diff + MERGE + INSERT(纯 SQL) | APPLY CHANGES INTO 声明式自动 SCD2 / 手写 MERGE |
Streams + Tasks + MERGE(官方推荐);或 Dynamic Tables | CHANGES() TVF + MERGE / dbt snapshot |
外部 CDC → Staging → MERGE;或 History Mode(仅 zero-ETL) |
| 自动化程度 | 手写 SQL,无声明式 SCD2 | 最高 --- APPLY CHANGES INTO 一行声明式语句自动处理 SCD1/SCD2 |
中 --- Streams + Tasks 可自动调度 | 中 --- 需配合调度工具 | 低 --- 需搭建完整 pipeline |
| 代码量 | 中等(约 30-50 行 SQL) | 低(声明式约 5-10 行)或中等(手写 MERGE) | 中等(需创建 Stream → Task → MERGE,约 40-60 行) | 中等(约 30-50 行 SQL) | 高(需搭建完整 pipeline + SQL) |
| 实时性 | 手动/调度触发 | 可近实时(Structured Streaming) | Streams + Tasks 可设分钟级调度 | 受限(10 分钟延迟 + 7 天窗口) | 取决于外部 pipeline |
7.2.5 易用性与运维总结
| 评估项 | MaxCompute | Databricks | Snowflake | BigQuery | Redshift |
|---|---|---|---|---|---|
| 开箱即用 | 建表加属性即可 | 建表加属性即可 | 需额外创建 Stream/Task 对象 | 建表加属性即可 | 需搭建外部 CDC |
| 学习曲线 | 低 --- 标准 SQL,概念少 | 低~中 --- 标准 SQL 即可完成 SCD2;AUTO CDC 需理解 Lakeflow 框架 | 低~中 --- 标准 SQL,但需理解 Stream 偏移量/Task 调度等额外概念 | 低 --- 标准 SQL,但 CDC 有延迟限制需注意 | 中 --- 需理解外部 CDC 工具链 |
| 运维负担 | 低 --- Serverless 全托管 | 中 --- 需管理 Spark 集群(Serverless SQL 除外) | 低 --- Serverless | 低 --- Serverless | 中 --- 需管理集群 |
7.2.6 MaxCompute Delta Table 的差异化优势
-
概念简单,零外部依赖 :Databricks、Snowflake、MaxCompute 都支持纯 SQL 完成 SCD2,但 MaxCompute 的实现路径概念最少------建表加属性、
TABLE_CHANGES查变更、MERGE 写维度表,无需理解 Stream 偏移量(Snowflake)或 Lakeflow 框架(Databricks)。对比 Redshift 则完全不需要搭建外部 CDC pipeline。 -
按版本号精确查询,同一区间可反复查询 :
TABLE_CHANGES按版本区间查询,同一区间无论查询多少次,结果不变(对比 Snowflake Stream 消费后偏移量自动推进,已消费变更无法再次读取)。 -
无 10 分钟延迟限制 :对比 BigQuery
CHANGES()TVF 要求end_timestamp至少早于当前时间 10 分钟,MaxCompute 的TABLE_CHANGES无此限制。(注:acid.cdc.build.async=false同步构建模式下的具体延迟表现请以官方文档为准。) -
Serverless 全托管:无需管理计算集群(对比 Databricks 需管理 Spark 集群、Redshift 需管理节点),按量付费成本可控。
-
历史保留期灵活:版本保留期可配置(对比 BigQuery 最长 7 天、Snowflake Standard 版仅 1 天)。
客观说明 :Databricks 在 CDC 语义丰富度(
_update_preimage_/_update_postimage_)和 SCD2 自动化程度(*_APPLY CHANGES INTO_声明式处理)方面目前领先;Snowflake 的 Stream + Task 在自动化调度方面也有优势。三者都支持纯 SQL 实现 SCD2,MaxCompute 的核心竞争力在于* 概念简洁****(无需额外对象或框架)和****全托管 Serverless 架构。