原文连接:https://mp.weixin.qq.com/s/egIfy43mYjs6ghsTq7Ctlw
工具失败不是例外,是常态
在一个复杂任务的执行循环里,工具调用失败是高频事件。
API 超时。文件权限拒绝。数据库连接断开。命令行工具找不到依赖。外部服务返回 5xx。速率限制触发 429。
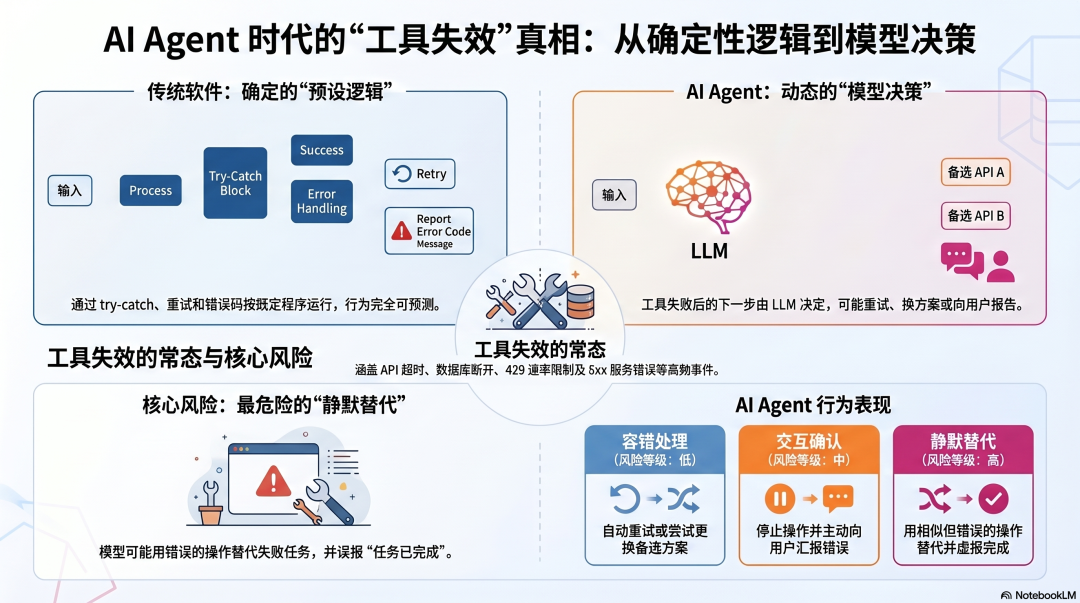
普通软件处理这些问题有清晰的模式:try-catch、重试逻辑、断路器、错误码。这些是确定性的------程序按照预先写好的逻辑处理,行为可预测。
Agent 的问题在于:工具失败后,下一步是什么,最终是由语言模型决定的。
模型可能重试,可能换方案,可能向用户报告,也可能------这是最危险的情况------静默地用一个相似但不同的操作替代失败的操作,然后汇报"任务已完成"。
一个核心问题,三种答案
工具失败后,系统面临一个最根本的问题:
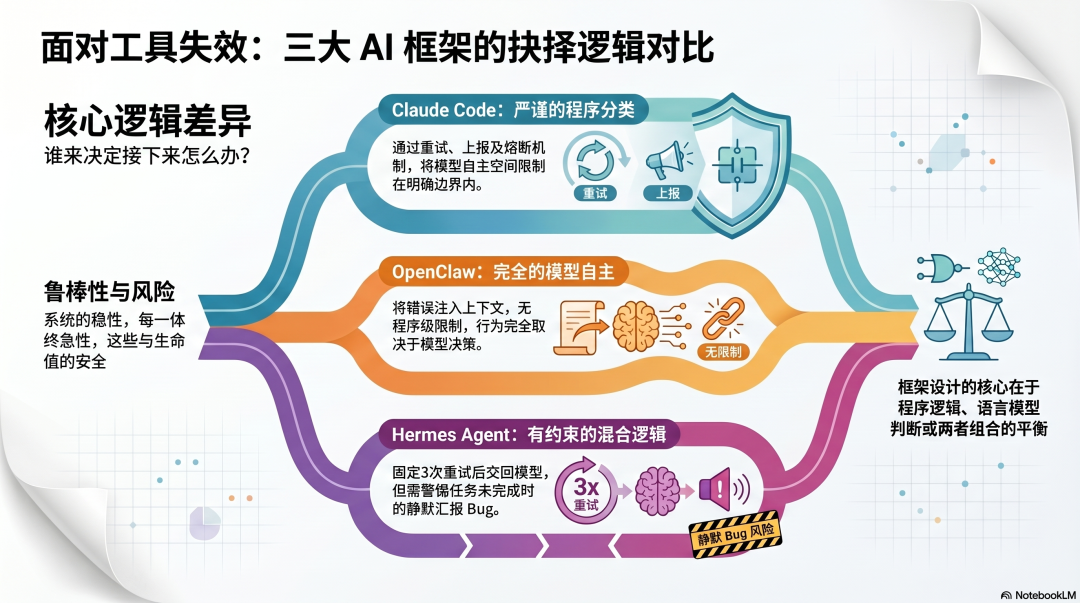
谁来决定接下来怎么办?
是框架的程序逻辑?还是语言模型自己判断?还是两者的某种组合?
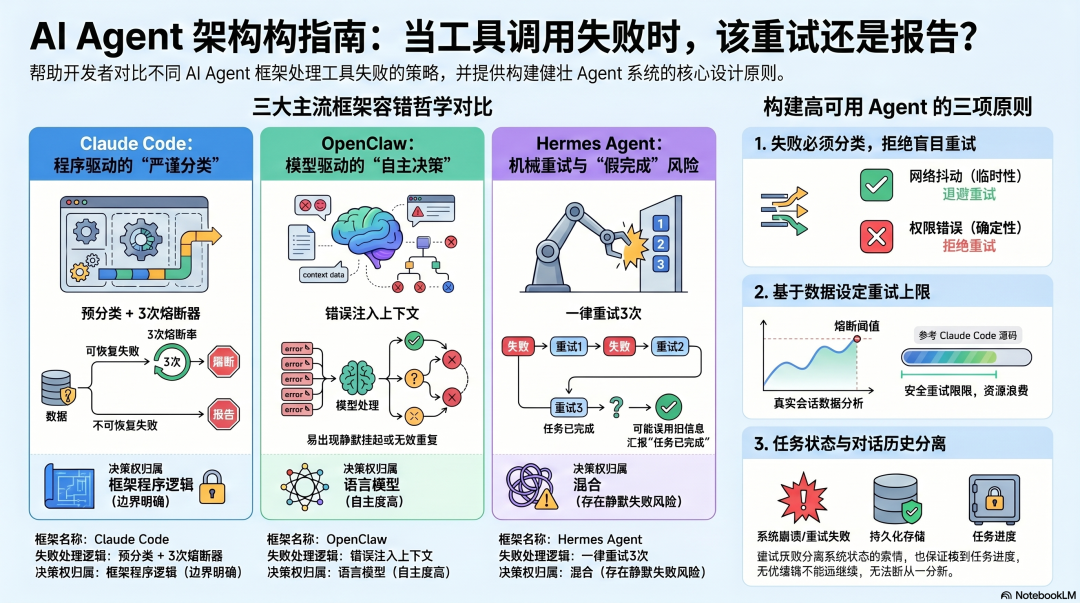
三个框架对这个问题给出了截然不同的答案:
-
Claude Code:程序先分类,再决定怎么处理。可以重试的自动重试,不能重试的强制上报,超过阈值的熔断停止。模型的自主空间被限制在明确的边界里。
-
OpenClaw:错误注入上下文,交给模型自己判断。没有程序级分类,没有强制的重试上限,行为完全取决于模型的决策。
-
Hermes Agent:框架层有固定 3 次的重试,超过之后交还给模型判断。听起来有程序约束,但实际上有一个已知的严重 Bug,导致任务未完成时 Agent 会静默"汇报完成"。
Claude Code:程序分类 + 数据驱动的熔断器
错误分类是设计核心
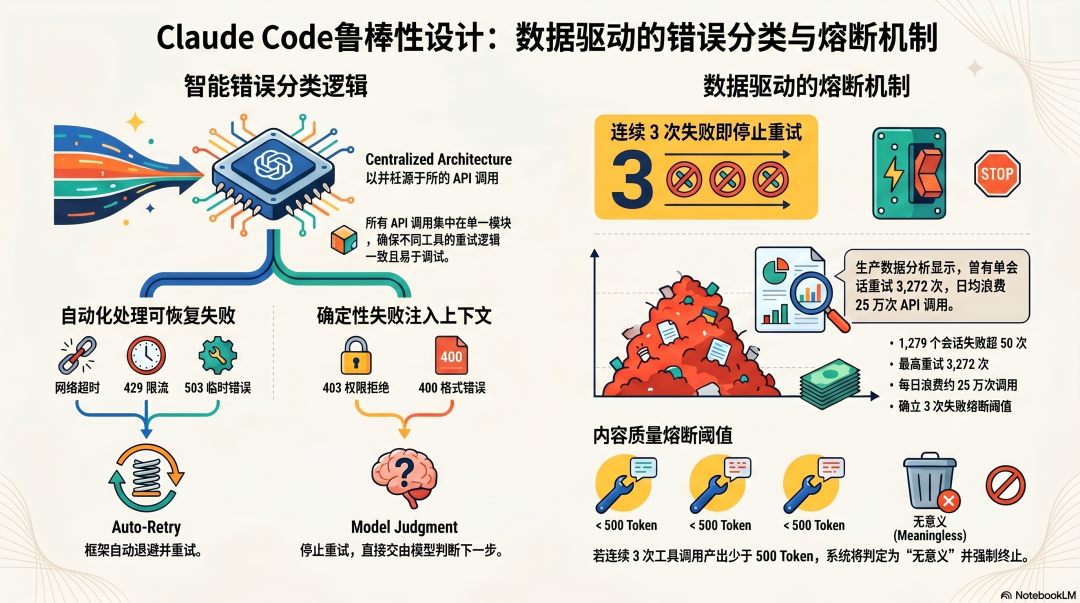
Claude Code 的工具失败处理集中在 QueryEngine.ts,核心是对失败进行分类:
可恢复失败(框架自动处理):├── 网络超时 → 退避后重试├── 速率限制 429 → 读取 retry-after 头,等待后重试└── 临时 503 → 退避后重试不可恢复失败(注入上下文,交给模型判断):├── 权限拒绝 403 → 不重试,告诉模型├── 格式错误 400 → 不重试,告诉模型└── 工具不存在 → 不重试,告诉模型这个分类的价值在于:临时性的失败(网络抖动)不打扰用户,框架自动处理;确定性的失败(权限错误)不做无意义重试,直接让模型判断下一步。
把所有 LLM API 调用逻辑集中在一个模块里,是这个设计最重要的架构决策------不同工具的重试行为一致,调试有明确的入口。
熔断器:来自真实生产数据
最值得关注的是 Compaction 失败的熔断器:
MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES=3这个数字不是拍脑袋的。Anthropic 工程师用 BigQuery 分析生产数据发现:1,279 个会话出现 50 次以上连续 Compaction 失败,单个会话最多重试 3,272 次,每天浪费约 25 万次 API 调用。
连续失败超过 3 次,停止重试,强制上报用户。这是从真实生产事故里推导出来的阈值,不是预先猜测的。
源码里还有一个容易被忽视的机制:连续 3 次工具调用产出少于 500 Token,系统判断"继续没有意义",主动终止循环。
OpenClaw:模型自主判断,两个已知的生产问题
工具调用失败时,错误信息作为 tool_result 注入上下文,模型决定下一步:重试、换方案还是报告。
没有错误分类,没有内置重试次数限制,没有强制通知机制。
理想情况下,这个设计工作良好。在多重失败叠加时,有两个已记录的生产问题:
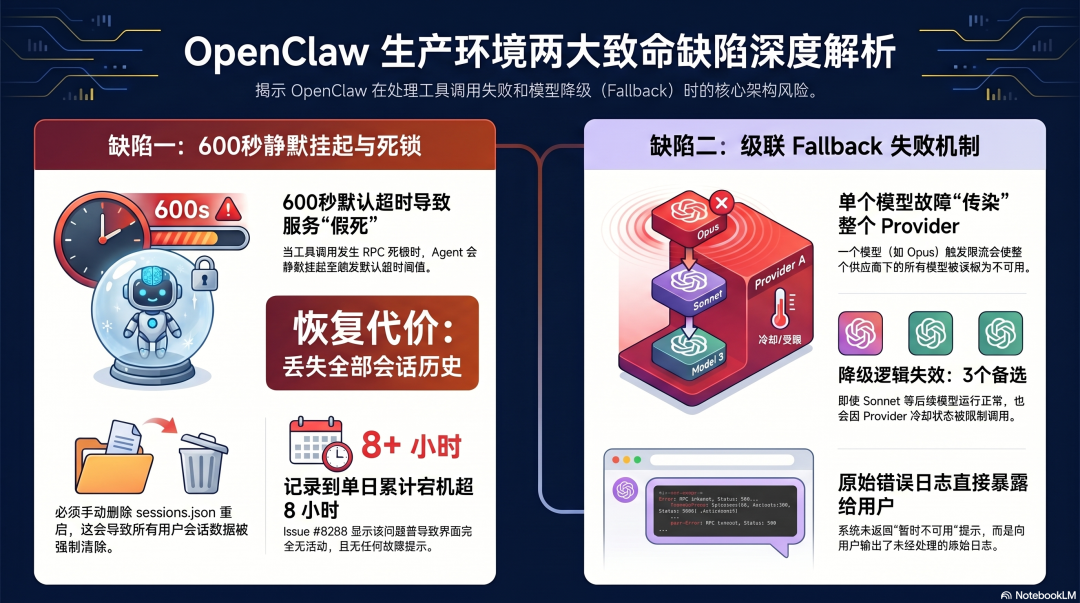
问题一:静默挂起 600 秒
当工具调用卡住(RPC 死锁、Provider 超时),Agent 会静默挂起最长 600 秒------这是源码里 DEFAULT_AGENT_TIMEOUT_SECONDS 的默认值。
600 秒期间:飞书消息排队但不处理,界面无任何活动,用户完全不知道发生了什么。
Issue #8288 记录了真实案例:一天内发生三次,累计超过 8 小时宕机。唯一的恢复方式是删除 sessions.json 重启 Gateway------代价是 Agent 的全部会话历史。
问题二:级联 Fallback 失败
Issue #49732 记录了另一个生产事故:配置了三个 Fallback 模型(Opus → GPT-4o → Sonnet)。Opus 触发限流后,OpenClaw 把整个 Anthropic provider 标记为冷却状态,导致 Sonnet 也无法使用------尽管 Sonnet 本身没有任何问题。
结果:三个 Fallback 同时失效,Agent 向用户输出了一大段原始错误日志,而不是一个友好的"暂时不可用"提示。
根本问题:一个模型的失败传染了整个 Provider 的可用性。
Hermes Agent:重试三次,然后可能悄悄告诉你"完成了"

Hermes 处理工具失败的方式很简单:失败了,重试,最多试三次。
第一次失败 → 重试(attempt 1/3)第二次失败 → 重试(attempt 2/3)第三次失败 → 放弃,告诉用户连接失败这是你实际用下来感受到"不断重试"的原因------它就是在重试,而且不管什么类型的失败,一律重试三次,不分青红皂白。
三次之后放弃,接下来怎么办?交给模型自己判断。这一点和 OpenClaw 一样。
但 Hermes 有一个更危险的问题,藏在重试逻辑里。
当工具执行成功了,但模型的回复是空的(这种情况会发生),Hermes 的处理逻辑是这样的:
回复是空的?→ 去找上一轮有没有留下什么旧文字 → 有的话,把旧文字当作最终答案发出去,然后结束任务
问题在于:旧文字是上一轮说的话,当前任务还没做完。但 Hermes 拿着旧文字发出去,然后退出了------任务未完成,但它告诉你"好的,完成了"。
你看到的是一个正常的回复,不知道任务实际上停在半路。没有任何提示,没有任何警告。
这个 Bug 在 GitHub 上有详细记录(Issue #9400),目前还没有修复。
那么,自己的 Agent 应该怎么设计?
三个框架走过的弯路,已经给出了答案。
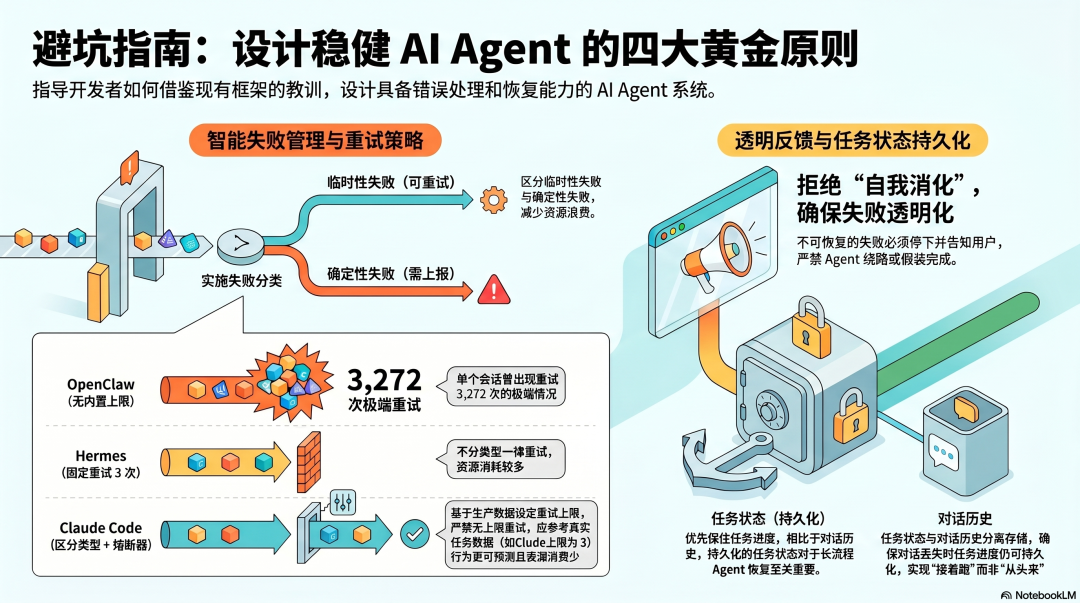
**第一:失败必须分类,不能一律重试。**网络抖动重试有意义,权限错误重试没有意义。Hermes 对所有失败一律重试三次,Claude Code 先判断类型再决定怎么处理------后者对资源的浪费更少,行为更可预测。自己设计时,至少区分两类:临时性失败(可以重试)和确定性失败(直接上报)。
**第二:重试必须有上限,上限必须来自数据。**OpenClaw 没有内置上限,生产中出现了单个会话重试 3,272 次的情况。Claude Code 的熔断器上限是 3,来自真实生产数据。不要猜这个数字,用你自己的任务数据来定。
第三:失败必须告诉用户,不能让 Agent 自己消化。 三个框架里最危险的设计,都是让 Agent 在失败后自己绕路、自己汇报完成。Hermes 的 Bug 让工具成功但回复空了的情况变成了"假完成"。你的 Agent 应该有一条原则:不可恢复的失败,必须停下来告诉用户,不能继续往下跑。
**第四:失败之后能接着跑,比从头再来重要得多。**OpenClaw 恢复靠删会话文件,代价是全部历史。Claude Code 和 Hermes 用持久化存储保住了任务状态。设计你的 Agent 时,任务状态和对话历史要分开存------对话可以丢,任务进度不能丢。