特征工程在建模里面是一个特别灵活的部分。它的方法相对来说是比较多的部分。建模的方法都是相对固定的,从线性回归开始就有介绍过,建模的步骤都是那 5 步,了解它的核心思想就可以了。但是在特征工程里面,可以理解为数据清洗的高级版本。它的作用就是在建模之前,再次去进行一些处理,为了让模型的性能更好。进行了数据处理之后,才能去进行建模。比如在招聘市场里,这里的数据可能有,工作地点,经验要求,学历,年龄,岗位职责,薪资,行业等等一些字段。比如我们预测的目标列为薪资,数据有经验、地点、学历。这个时候很明显,薪资和地点肯定有很强的关系,普遍来说,同样的岗位,一线城市薪资会高一些,而小城市薪资就会低一些。这个时候,地点这个字段肯定是要保留,建模的本质就是机器训练得到公式,全部都是数字才能去参与建模和计算,而地点字段存放的所有数据都是文本类型,这时候就需要进行文本数值化处理。不是一种方法来处理,具体使用哪一种需要尝试,基于经验来使用。特征工程的处理是多种多样的,灵活性也是非常强的。处理好了,这个模型的性能会很好,如果处理不好,可能模型的性能就会变得很差。接下来介绍特征工程的具体操作。
目标:
- 能够理解缺失值的各种计算方式
- 能够掌握数值型的幅度变换
- 能够掌握类别型的数据:有序特征、无序特征
什么是特征工程
特征是用于描述数据中的各种属性、变量或维度的信息,它们是模型用来做出预测或分类的输入。特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。良好的特征工程可以显著提高模型的性能,而糟糕的特征选择或构建可能导致模型性能下降。
意义:会直接影响机器学习的效果
特征工程的主要目标包括:
- 特征选择:选择最相关的特征,以减少维度和噪声,提高模型的泛化能力。这可以通过统计方法、领域知识、特征重要性评估等方式来完成。
- 特征构建:创建新的特征,以提供更多的信息或改善模型的性能。这可能包括将原始特征组合、进行数学变换、提取时间序列特征等操作。
- 特征缩放:确保特征具有相似的尺度,以避免某些特征对模型的权重产生不适当的影响。常见的缩放方法包括标准化和归一化。
- 处理缺失数据:处理缺失值,可以使用插补方法来填充缺失值,或者考虑是否删除包含缺失值的样本。
- 处理分类特征:将分类特征进行编码,例如独热编码(One-Hot Encoding)或标签编码(Label Encoding),以使其适用于机器学习模型。
- 特征交叉:将不同特征之间的关联性考虑在内,通过创建特征交叉来提供更多信息。
- 特征选择和降维:使用降维技术(如主成分分析PCA)来减少特征的数量,以提高模型的效率和可解释性。
基本预处理
基本预处理:缺失值处理
- 删除属性或者删除样本:如果大部分样本该属性都缺失,这个属性能提供的信息有限,可以选择放弃使用该维属性
- 统计填充:对于缺失值的属性,尤其是数值类型的属性,根据所有样本关于这维属性的统计值对其进行填充,如使用平均数、中位数、众数、最大值、最小值等,具体选择哪种统计值需要具体问题具体分析。
- 统一填充:常用的统一填充值有:"空"、"0"、"正无穷"、"负无穷"等。
- 预测/模型填充:可以通过预测模型利用不存在缺失值的属性来预测缺失值,也就是先用预测模型把数据填充后再做进一步的工作,如统计、学习等。虽然这种方法比较复杂,但是最后得到的结果比较好。
pandas库:fiilna
sklearn库:Imputer
数据集介绍
使用的是泰坦尼克号数据集的训练集部分,它包含了891名乘客的基本信息、船票详情以及他们在泰坦尼克号沉没事件中的生存情况。每一行都是一名乘客的信息。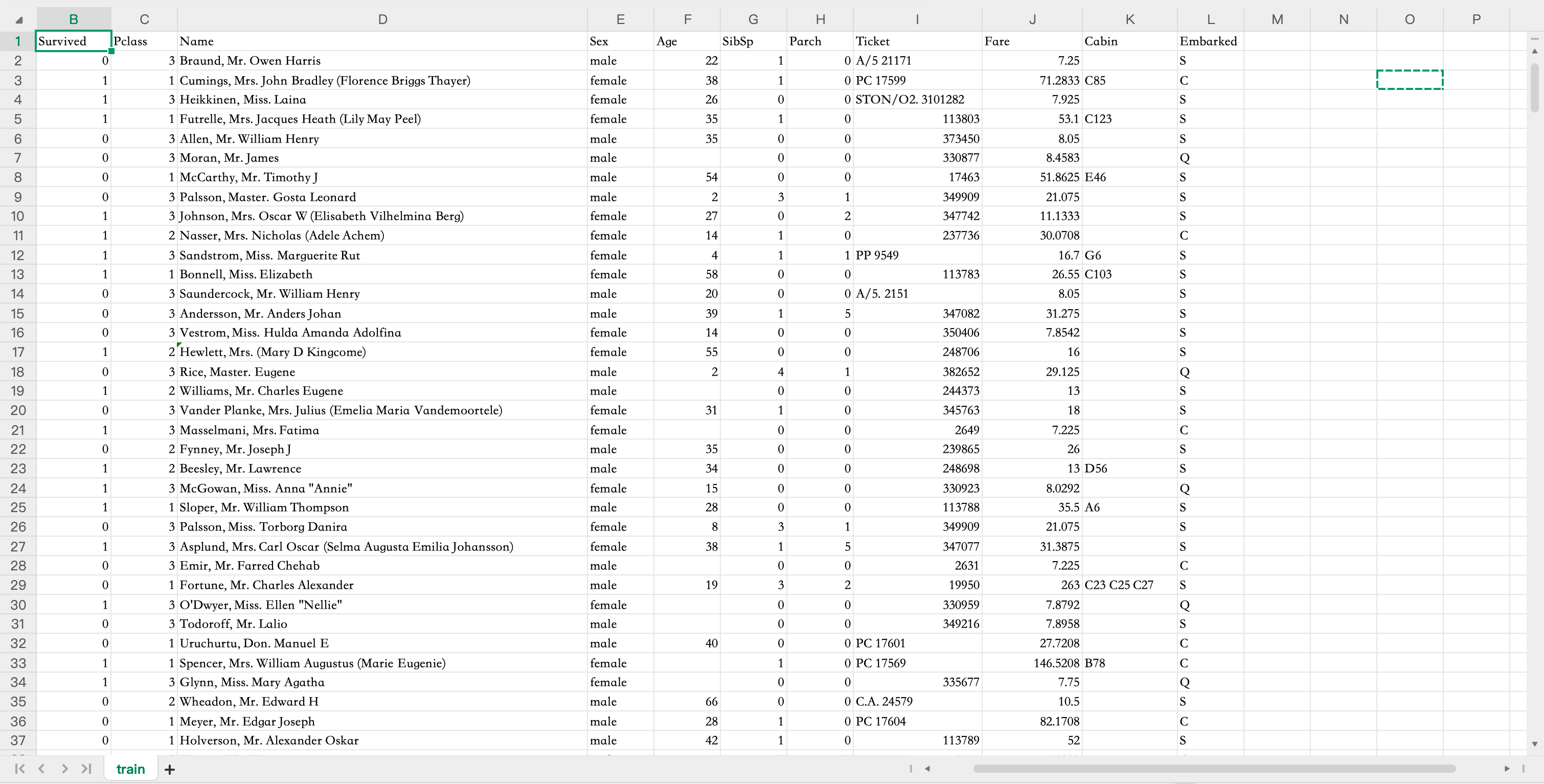
数据集共有12个字段,具体含义如下:
PassengerId:乘客唯一编号,无预测意义,仅用于标识(ID)。
Survived(目标标签):0遇难,1存活,模型最终需要预测的值。
Pclass:客舱等级(1头等舱/2二等舱/3三等舱),代表社会阶层,头等舱存活率远高于三等舱。
Name:乘客姓名。
Sex:性别(male/female),极强特征,女性存活率极高。
Age:乘客年龄,存在约20%缺失值;孩童存活率更高。
SibSp:同船配偶、兄弟姐妹人数。
Parch:同船父母、子女人数。
Ticket:船票编号,一般无太大使用价值。
Fare:船票价格,和舱位等级强关联。
Cabin:船舱编号,缺失率77%以上,大多直接舍弃。
Embarked:登船港口(S南安普顿/C瑟堡/Q昆士顿),仅2个缺失值。
缺失值处理
回到 jupyter 当中。第一步,把要用到的包全部导入进去。
python
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
接下来,将数据读取出来。起个变量名来保存读取到的数据。然后打印出来看一看。
python
# 读取数据
df_train=pd.read_csv('train.csv')
df_train
如果遇到数据量较大的数据集,也可以只查看前 10 行的数据,然后用函数来查看有多少行。
python
# 读取数据
df_train=pd.read_csv('train.csv')
df_train.head(10)
# 查看行数
df_train.shape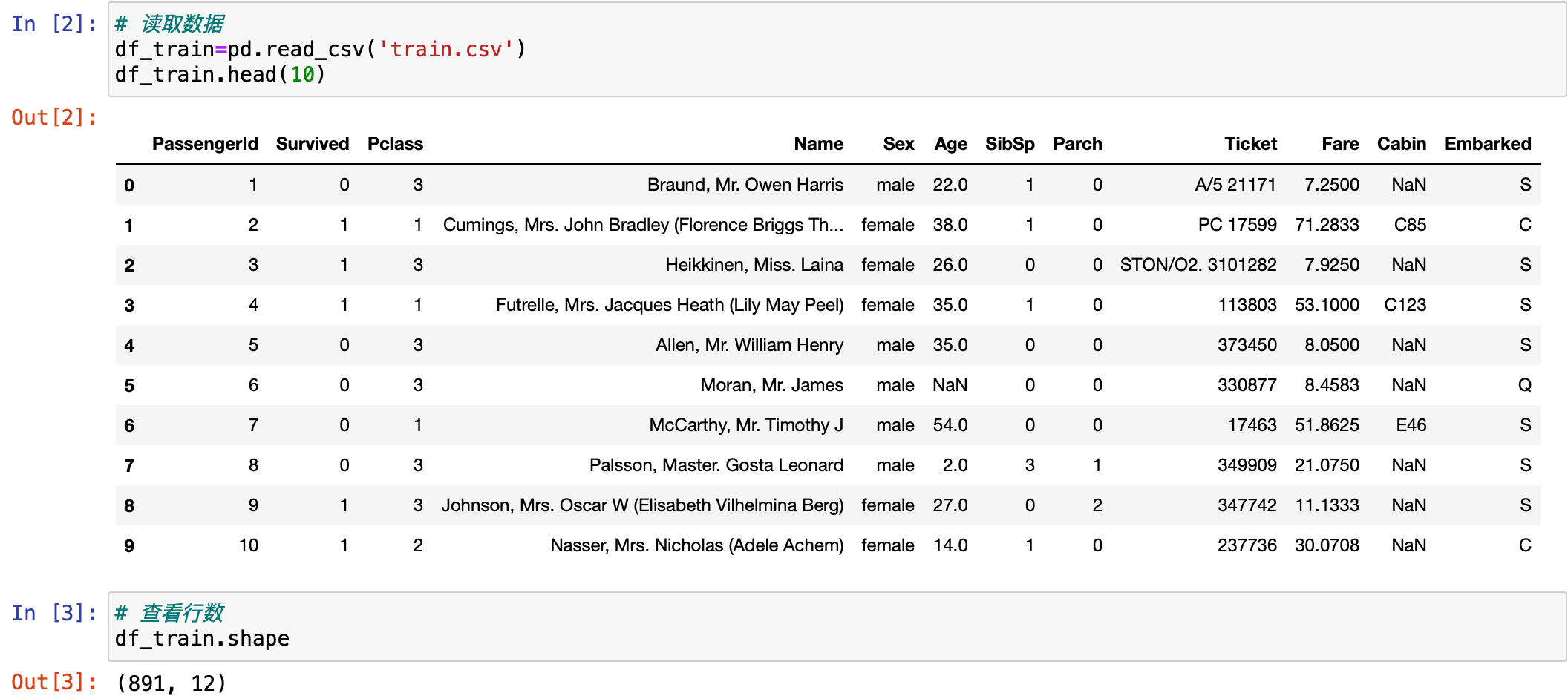
可以看到这个数据一共 891 行,12 列。这个就是通过 shape 查看出来的。接下来,查看数据类型,通过 info() 来直接查看。运行一下。
python
# 查看数据类型
df_train.info()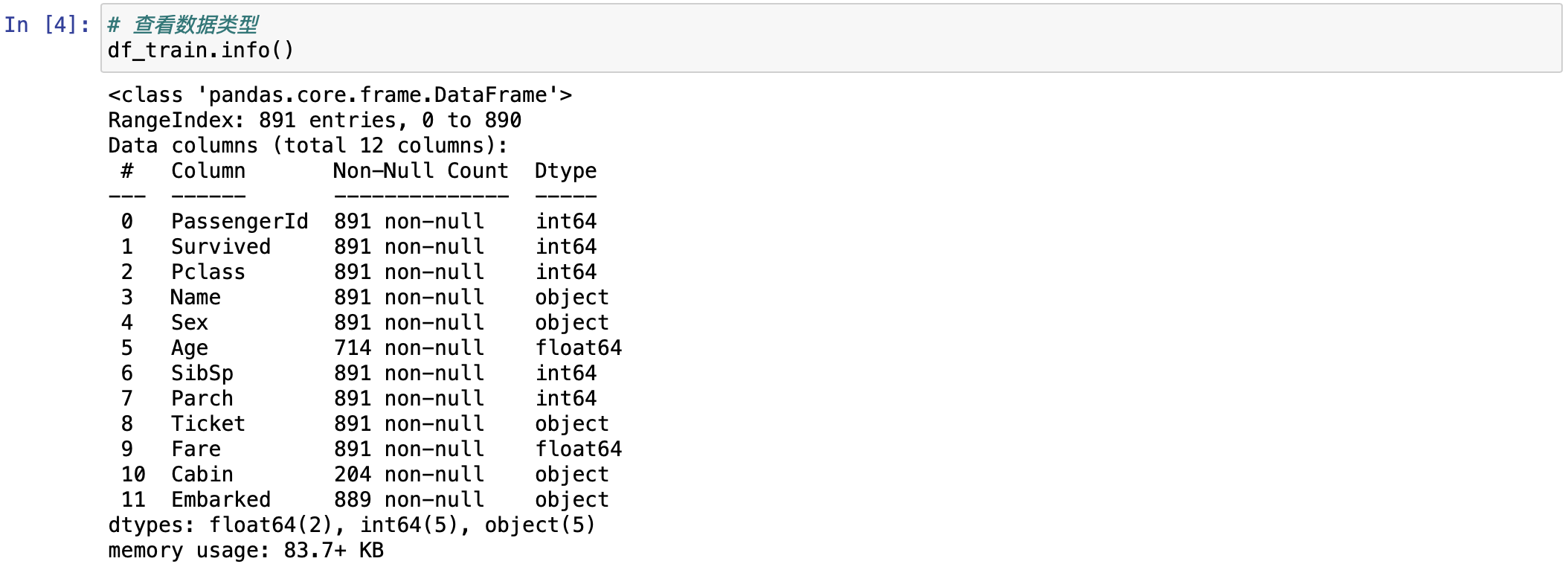
这里可以看到前三个字段都是 int64(整型)的数据。还有一些情况是,看起来是数字的,但实际类型是字符串的,比如 Age 和 Fare。所以用 info() 来打印确认一下是很有必要的。而且 Name 和 Sex 都是 object 类型的。在 Pandas 里面,都会给它展示成 object。object 这种类型产生是有两种情况的,某一列存在多种数据类型的时候,会变成 object。还有一种是 string 类型,字符串类型,它也会认为是 object 类型的。还可以看一下,Cabin 客舱号,它也是 object 类型的。还可以发现,通过 info() 还可以打印出它的缺失值。可以发现,客舱号的 Non_Null Count 是 204,有值的一共 204,剩下都是缺失值,所以客舱号的缺失值是比较多的,确实了 600 多条数据。还有 Age,也有缺失。还有最后 Embarked 字段,也有一丢丢缺失。用 info(),即可以看数据类型,又可以看到缺失值。
看完数据类型之后,还想看一看,数据是否存在极值的情况。看数据分布是否是相对均匀的状态。使用 describe() 就可以查看。
python
# 查看数据异常值
df_train.describe()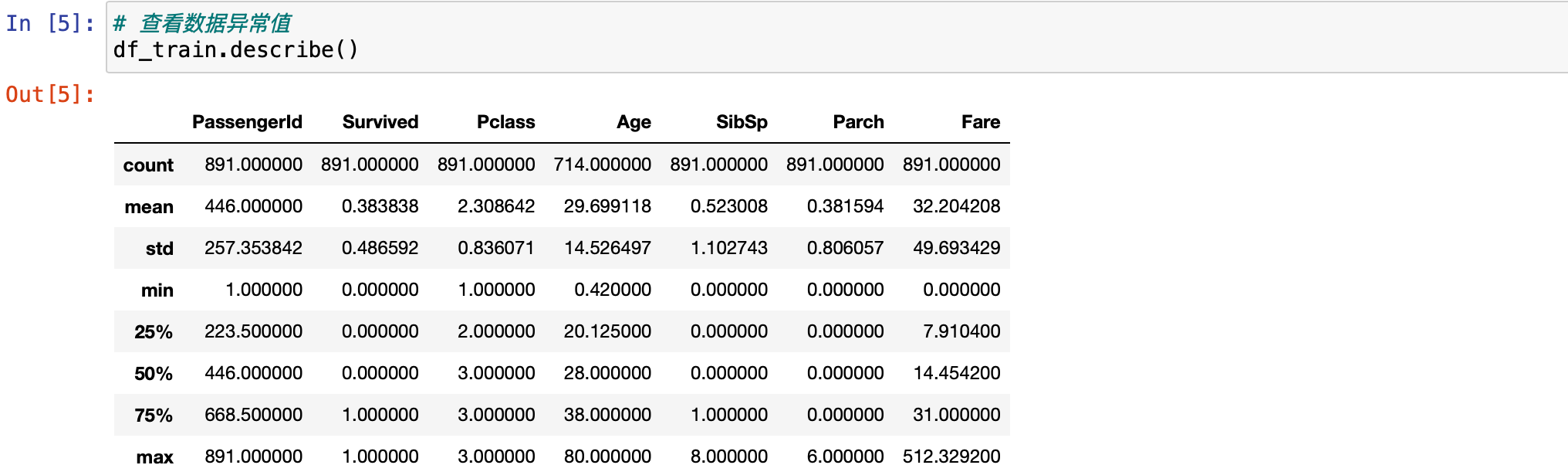
然后发现这个数据有点儿小问题,它只会默认显示数值字段。把鼠标光标放在函数上方,然后按住键盘的 shift + tab 键,就可以查看这个函数的具体情况。这里有一个参数 percentiles。
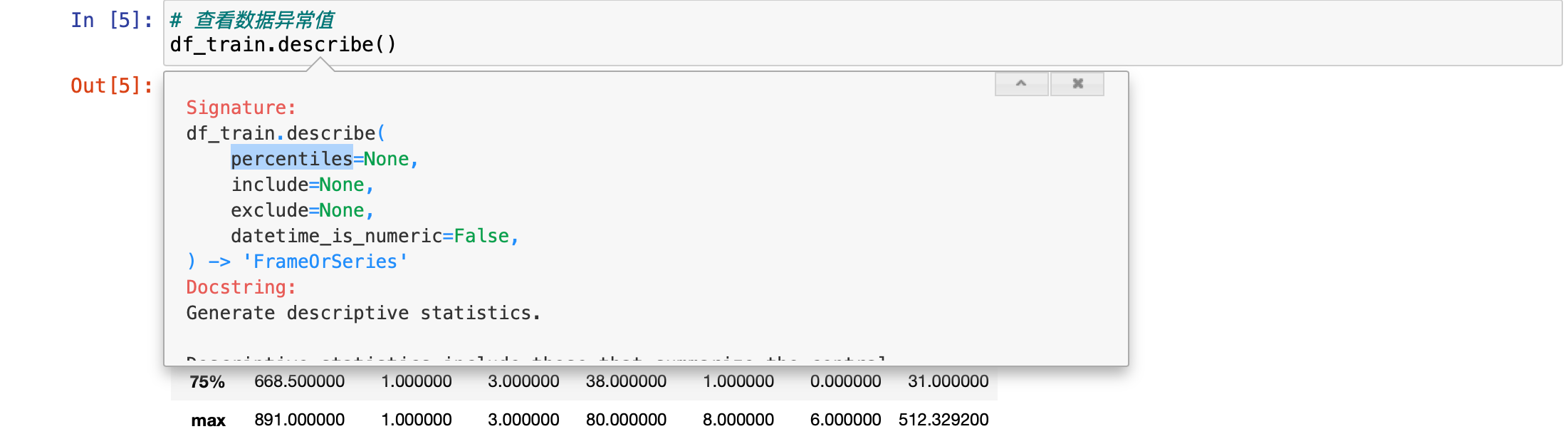
这个参数可以改四分位数的数值,所以它不是固定的四分位数。也就是对应这个地方 25%,50%,75% 这三个四分位数不是固定的,可以通过设置参数 percentiles 进行更改。
还有一个参数,include。include 对应有很多参数可以选择。
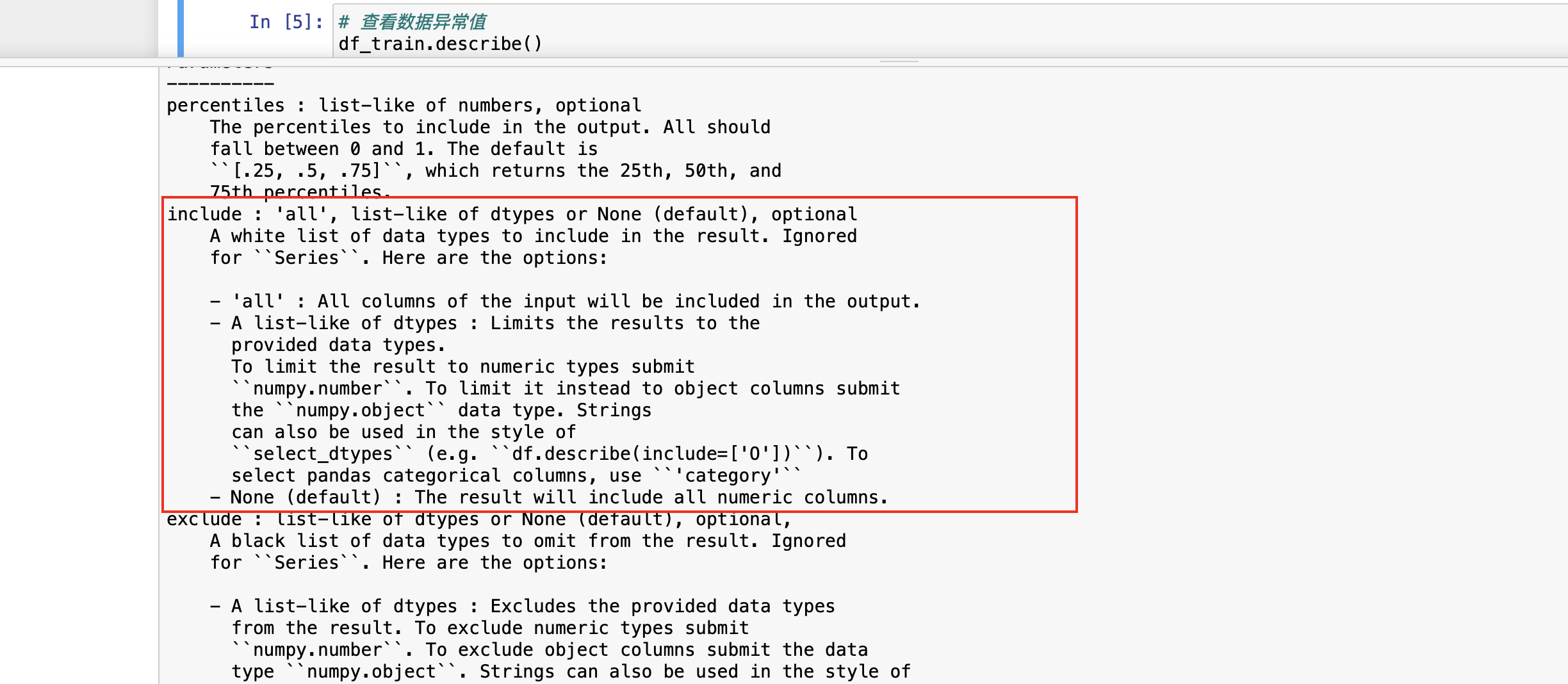
这里有个 all,就是把所有的详细内容都展示出来。如果用 all,文本类型的内容就也可以展示出来了。这种情况下去展示数据就没有太大的意义了,在什么时候有意义?比如在展示日期的时候,想快速看一下是否存在 3030 年这样的数据,这种数据一般属于异常数据,就可以通过设置 include='all' 这种方式去查看。因为不涉及到文本字段,也不涉及到日期,所以这里就不去设置 include 参数了。
还可以看到 Survived 字段只有两种情况,0 和 1,0 是遇难,1 是存活。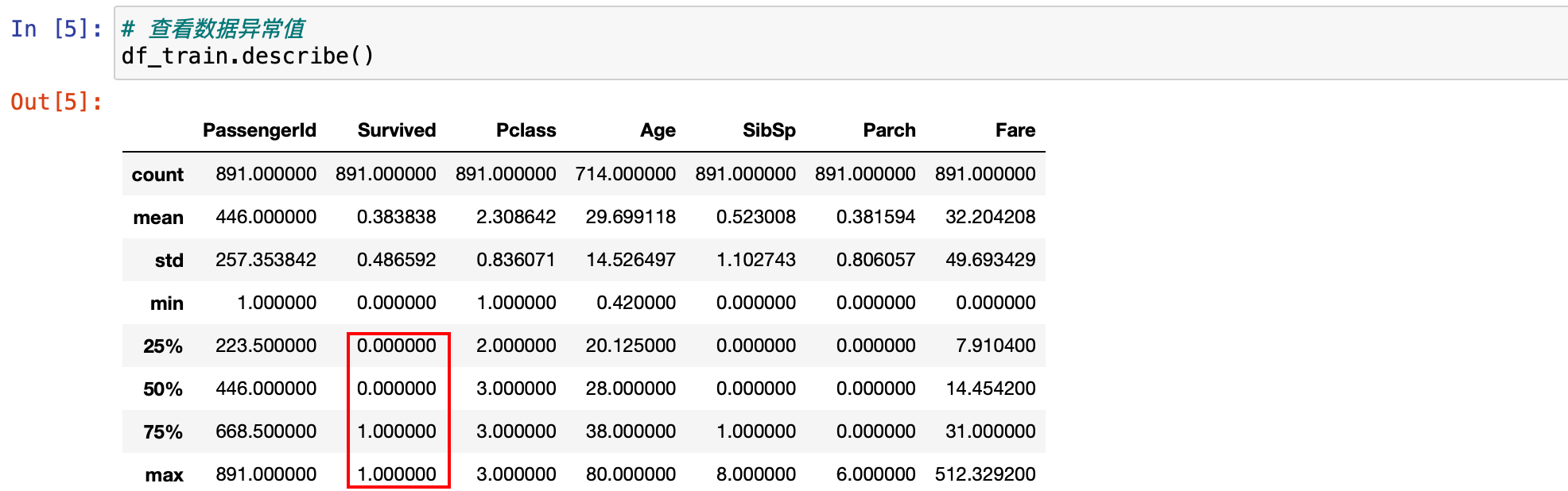
接下来看一看它是否有重复行,统计一下重复行个数。使用 .duplicated().sum(),发现返回的是 0,所以没有重复行。
python
# 统计重复行
df_train.duplicated().sum()
如果想看数据缺失值的百分比。使用 .isnull().mean()。发现有缺失值的情况,接下来要对这些缺失值进行处理。
python
# 查看缺失值百分比
df_train.isnull().mean()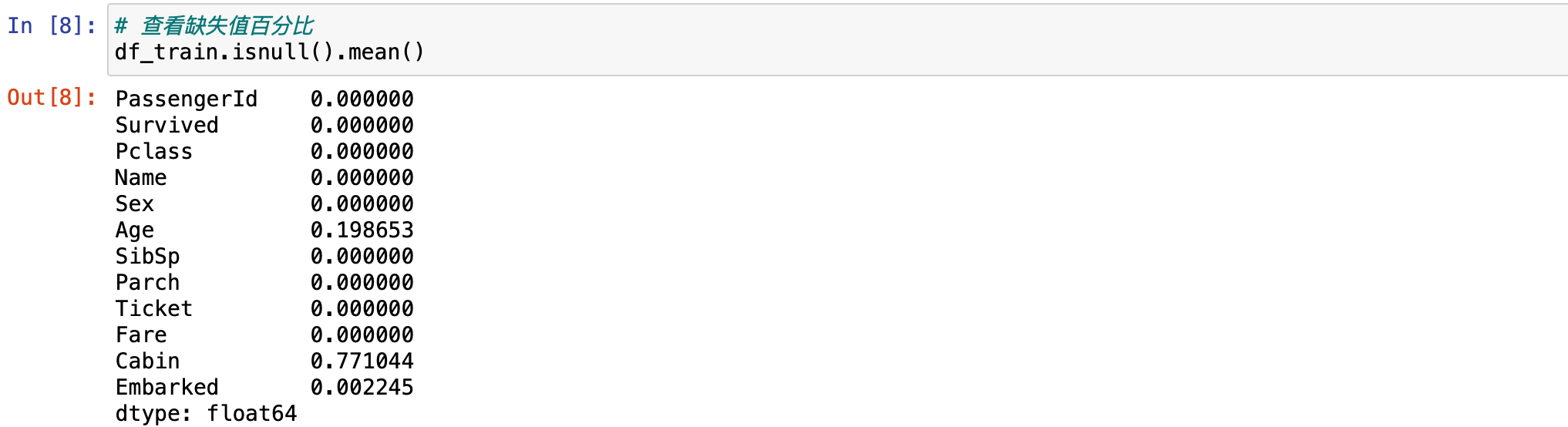
常用有两个处理方式,一个是删除,一个是填充。如果想删除缺失值,使用 dropna。如果不想删除,想填充,使用 fillna。
刚刚看了,Age 有缺失值,先对 Age 进行处理。使用填充对它进行处理,这里可以使用平均年龄进行填充。把年龄拿过来,然后点上 mean 就拿到平均值了。
python
# 缺失值处理
# 删除缺失值 dropna
# 填充 fillna()
df_train['Age'].fillna(value=df_train['Age'].mean(), inplace=True)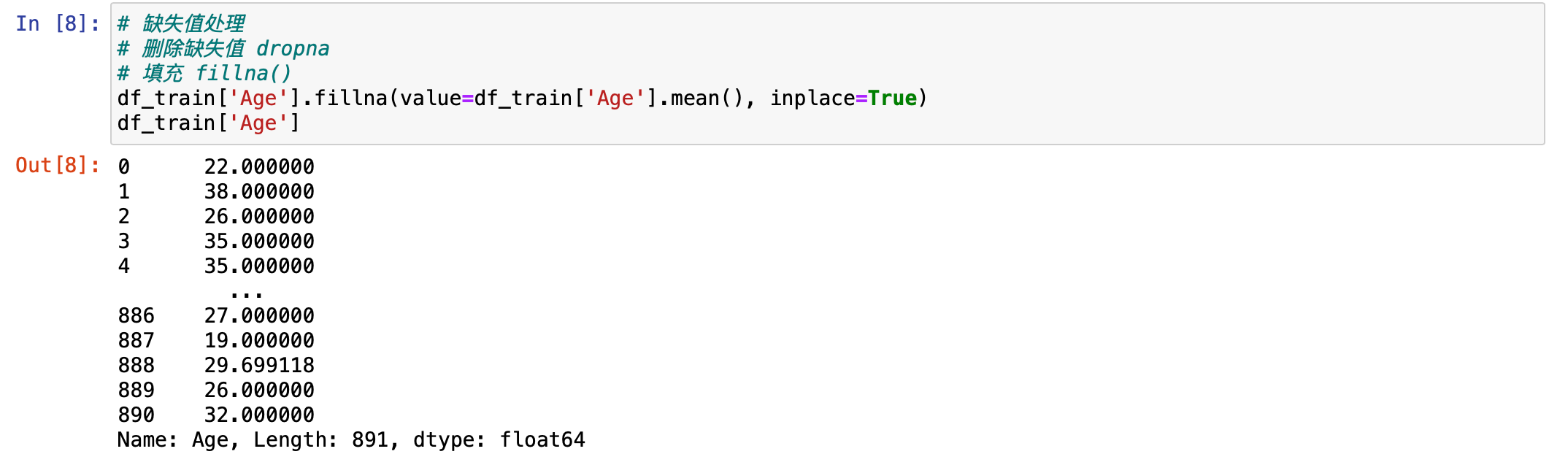
注意,在填充的时候也不是随便用一个数来填充都可以的,要看一下填充的是否合理。基本上年龄填充都是用平均值来填充。在实际当中它也是非常合理的,符合现实情况。所以这里选择用平均值来填充。
还有一种填充方式,使用 scikit 包,SimpleImputer。这个模块是专门用来处理缺失值数据的类。使用它的时候,先导入一下这个包。注意,如果 sklearn 的版本过低,导入的语句就是 "from sklearn.impute import Imputer",如果 sklearn 的版本大于 0.9,导入的语句就是 "from sklearn.impute import SimpleImputer"。
python
# 方法二 scikit SimpleImputer 这个模块是专门处理缺失值数据的类
from sklearn.impute import SimpleImputer导入之后就可以使用了。先获取年龄。这里要注意一下,使用这个类的时候数据一定是二维数组。一维的会报错,所以在去用它的时候,数据一定要加上两个中括号表示二维数组。参数是填充方式,仍然选择平均。然后用建模方式去操作,对 Age 做处理,最后打印一下 info() 看看结果。
python
imp=SimpleImputer(strategy='mean')
df_train[['Age']]=imp.fit(df_train[['Age']].values)
df_train.info()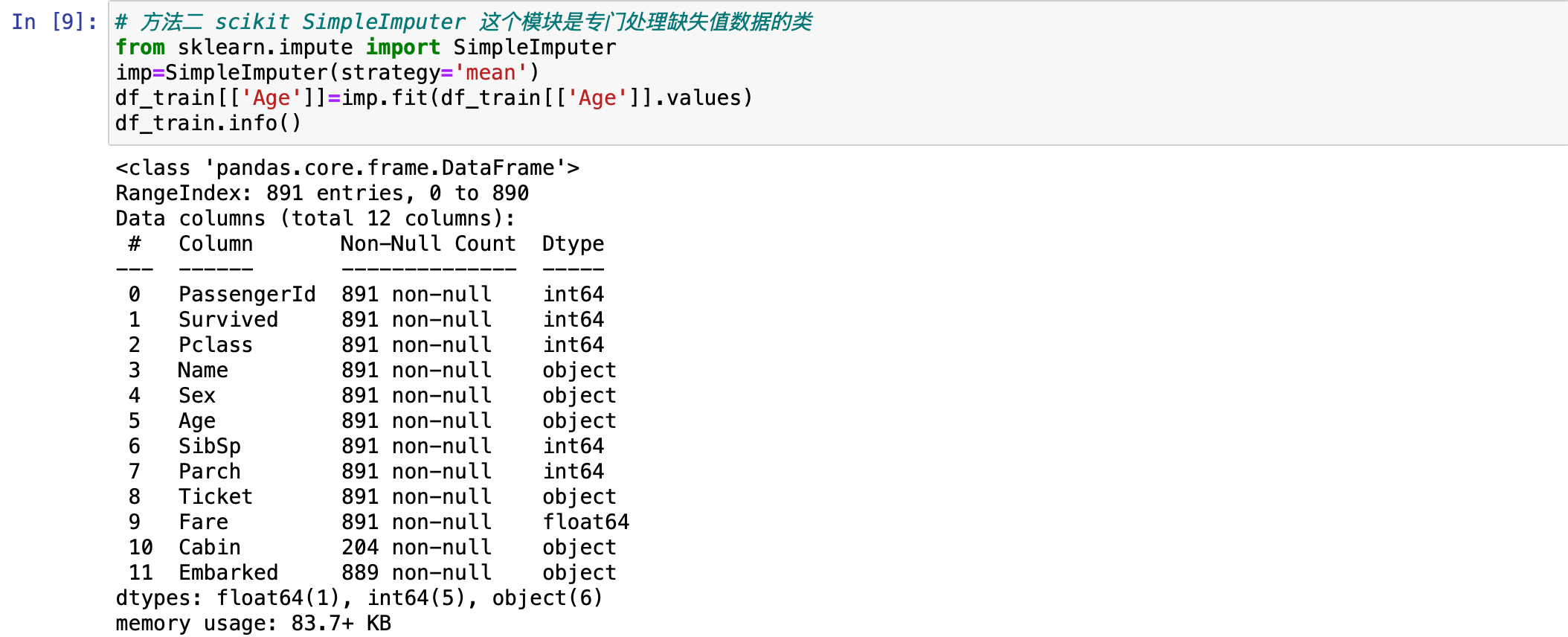
现在可以看到 Age 有 891 个数据,没有缺失值了。这种方式比较适用于机器学习任务的时候,比第一种方式更复杂一点。这里作为了解即可。具体用什么方式看个人习惯。特征工程里面的方式很灵活,没有标准答案,只要处理成目标效果,就是正确的。
接下来,对 Cabin 进行处理。Cabin 的缺失值非常滴多。
对于缺失值,可以画一个图,横轴是缺失比例,纵轴是重要程度。在二象限,选择填充的方式进行处理。也就是重要程度高的话,都不会选择删除的。在第一象限,这个字段很重要,缺失的比例又非常高,就单独给字段进行划分,划分为 NO类别,单独起一个名字,相当于新建了一个不知道的类别。在第四象限里,也就是既不重要,缺失的比例又比较多,这种时候一般会选择删除字段。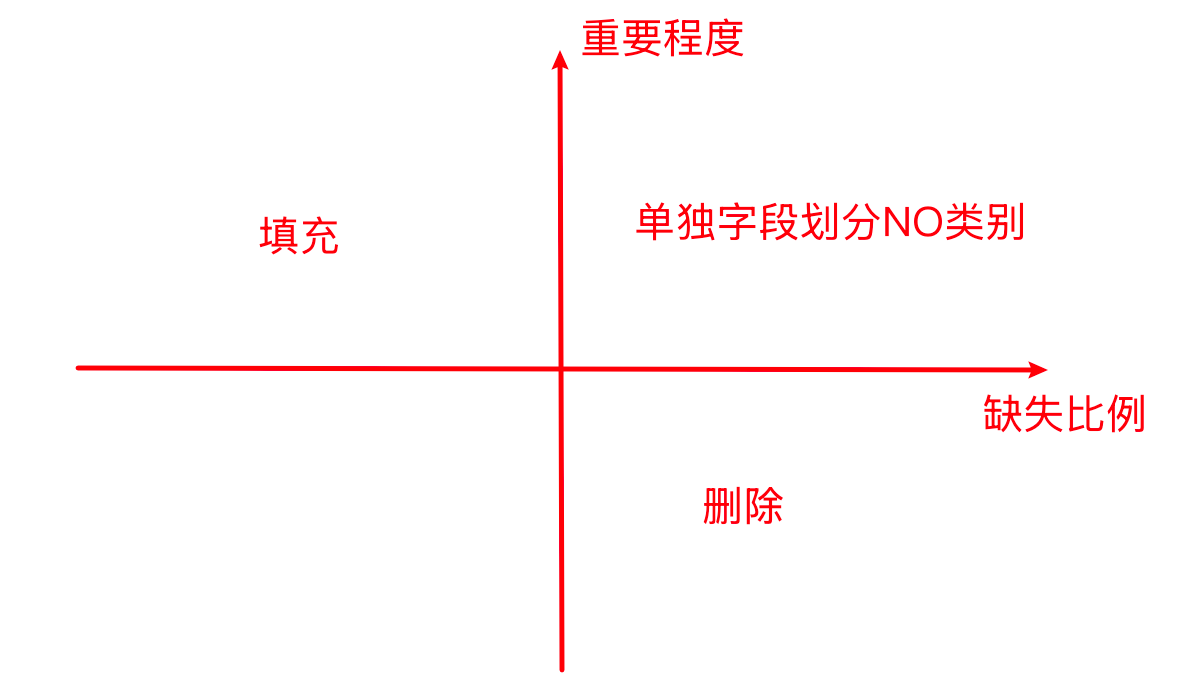
大部分时候,在不确定的情况下,能做填充尽量做填充。除非百分百确定这个字段一定不会在后面建模的时候能使用到,有没有这个字段都毫无影响,这时候就可以把它删除。如果没有百分百的把握,在这个时候都要选择填充。
对于 Cabin,这个客舱来说,不确定后面会不会用到,尽量使用填充来进行处理。这里直接用 0 来填充就可以了。打印出来看看。
python
## Cabin 缺失值处理
df_train['Cabin']=df_train['Cabin'].fillna(0)
df_train.info()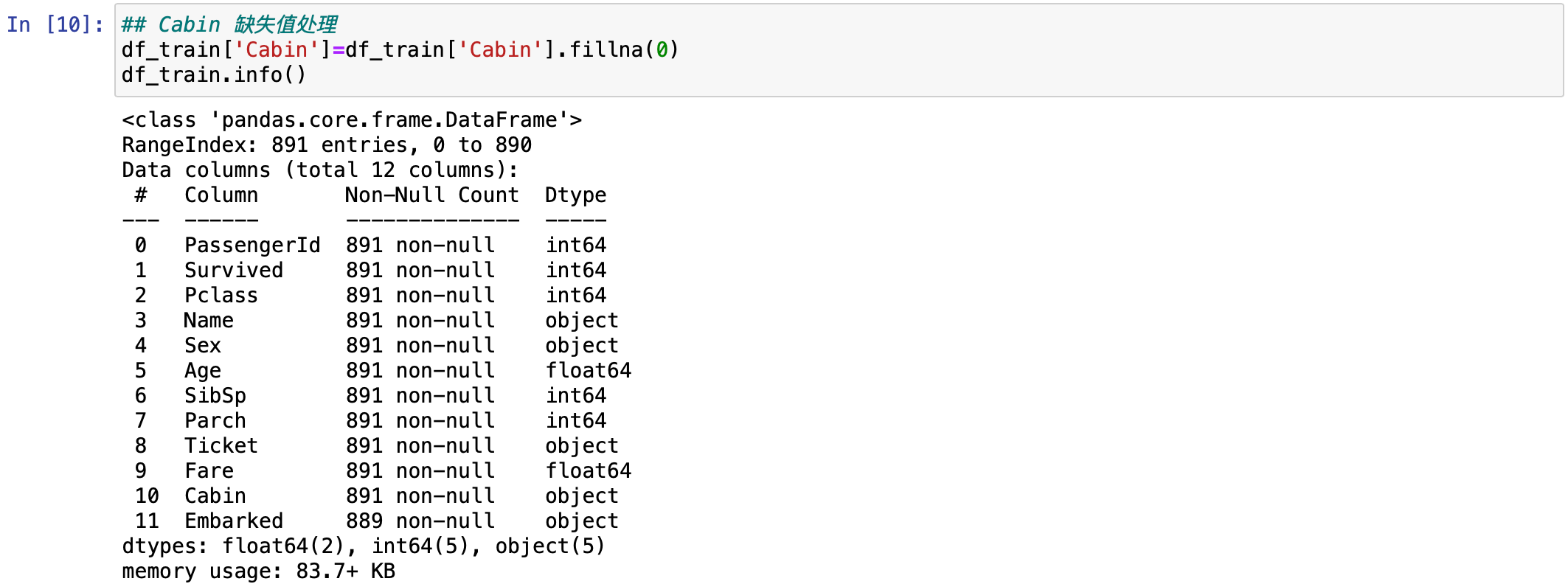
可以看到 Cabin 也变成了 891 条数据。所有的缺失值全部用 0 填充完毕。
处理完两个字段,还有一个字段有缺失值。是最后一个字段,Embarked(登船港口:C=瑟堡,Q=皇后镇,S=南安普顿)。这个字段也要对它进行处理。它只有两个空值。这个地方就不能用平均值来填充了。因为这个字段是文本类型的。这里就可以用众数进行填充。mode() 是Pandas中用于计算众数的方法,即计算数据中出现次数最多的值。df_train'Embarked'.mode() 会返回 "Embarked" 列数据的众数,由于可能存在多个众数(即多个值出现的次数并列最多),它返回的是一个Series对象。0:因为我们一般只需要使用第一个众数(当存在多个众数时,通常取第一个)来填充缺失值,所以使用 0 从上述返回的 Series 对象中取出第一个众数。
python
# Embarked 众数填充
df_train['Embarked'].fillna(value=df_train['Embarked'].mode()[0], inplace=True)
df_train.info()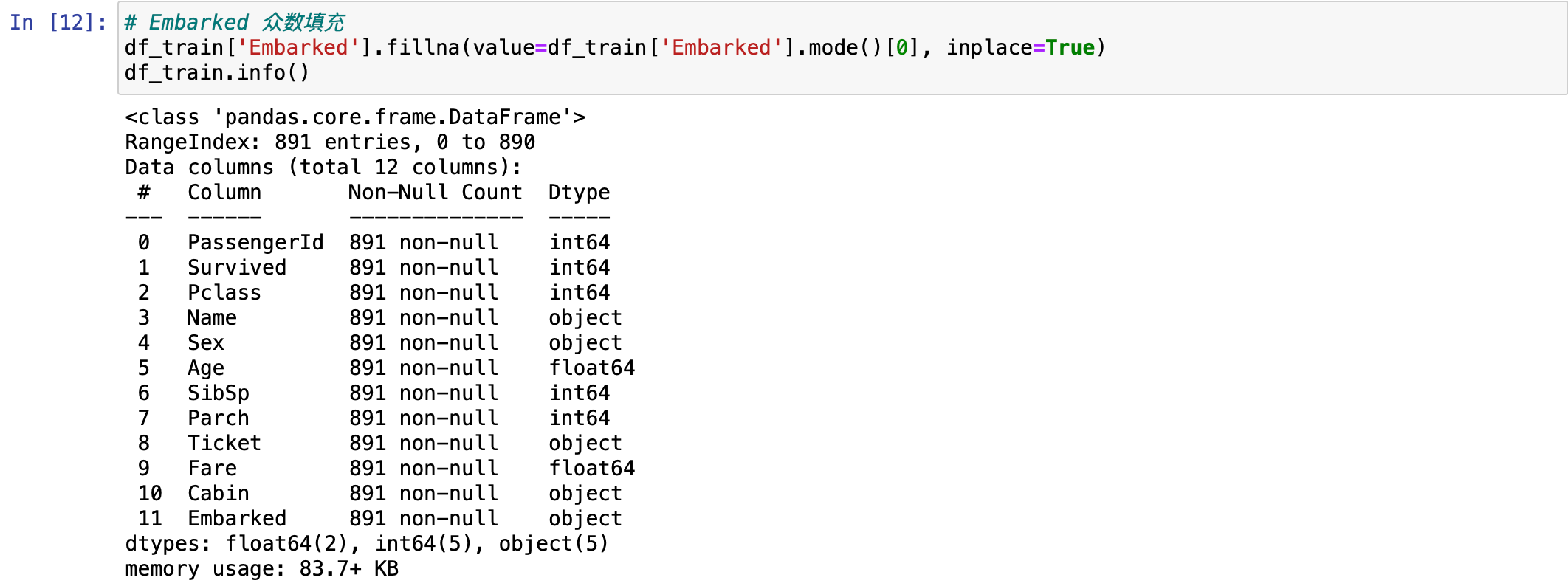
现在,缺失值都已经处理完成了。接下来看一下数值型特征的处理。
数值型特征
数值型的幅度变换:
log 变换、多项式变换
幅度缩放(数据预处理):MinMaxScaler、 StandardScaler
统计数值:Max、Min、 AVG...
四则运算:+ - * /
其中 min 是样本中最⼩值, max 是样本中最⼤值。
log 变换
回到数据集处理一下。先了解数据分布情况。第一步导入需要的包。这次要画核密度图,要画存活和死亡的图形形状。存活,看一下年龄的分布,再给一下对应的标签。死亡的也是一样的。
python
# 先了解数据分布的情况
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
fig,ax=plt.subplots(figsize=(12,4))
sns.kdeplot(df_train[df_train['Survived']==1]['Age'],label='Survived',shade=True,ax=ax) # kdeplot核密度图 shade=Ture:阴影部分面积
sns.kdeplot(df_train[df_train['Survived']==0]['Age'],label='Not Survived',shade=True,ax=ax)
plt.legend()
ax.set_xlim(0,df_train['Age'].max())
plt.show()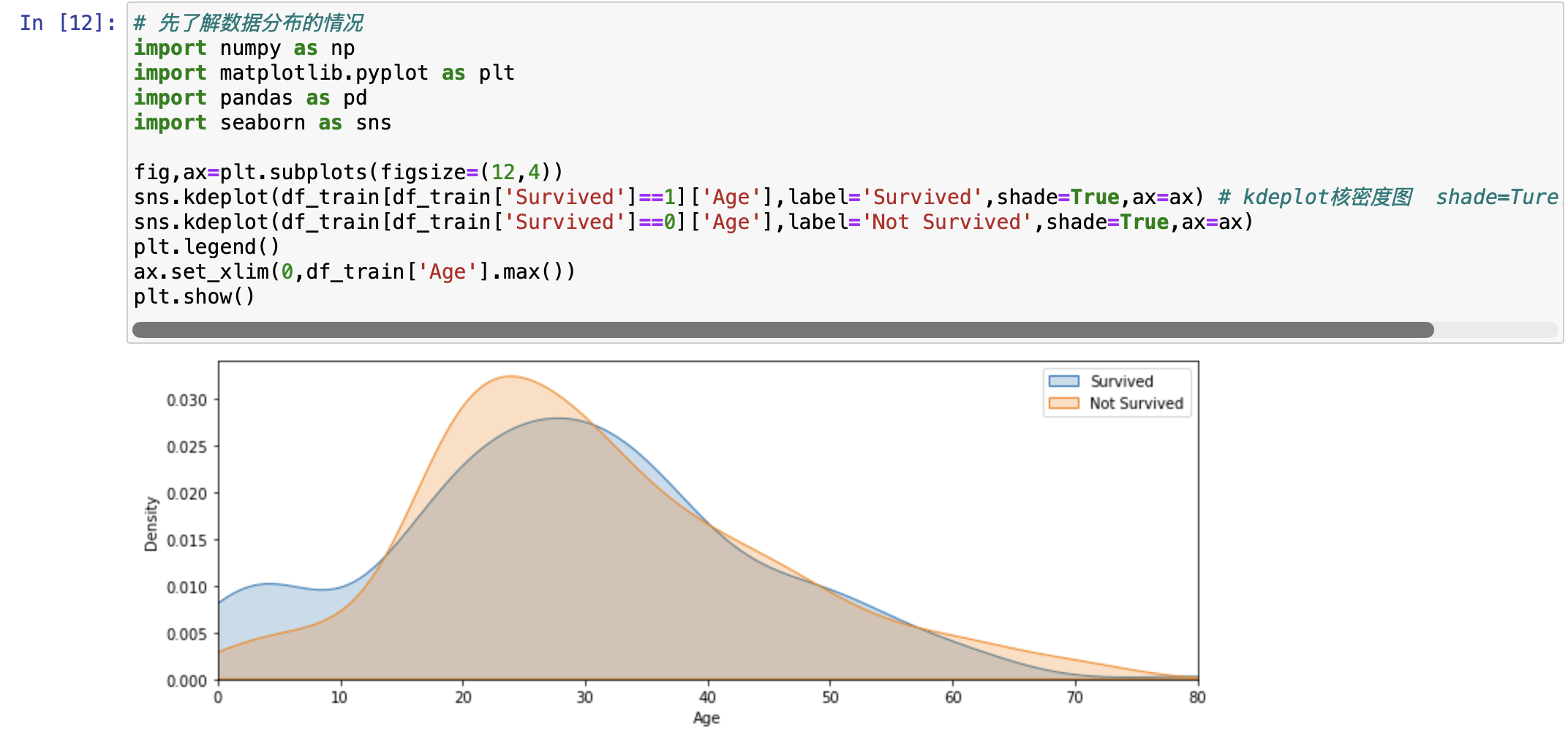
然后我们对年龄进行 log 变换。这里注意,使用 log 变换的时候,数据一定得是个大于 0 的数。这里还没有进行 log 变换,只是先看一下数据的分布情况。通过这个分布情况也可以发现,这些全部都是大于 0 的数。不管是以什么为底,都是要大于 0 的。
现在很明显可以看到,前提条件已经满足了,这时候就可以用对数转换了。把年龄进行 log 变换,然后打印出来看看。
python
# 对数变换
df_train['log_age']=df_train['Age'].apply(lambda x:np.log(x))
df_train我们可以发现,原本的年龄差距比较大,但是经过对数转换之后,这些差距变小了。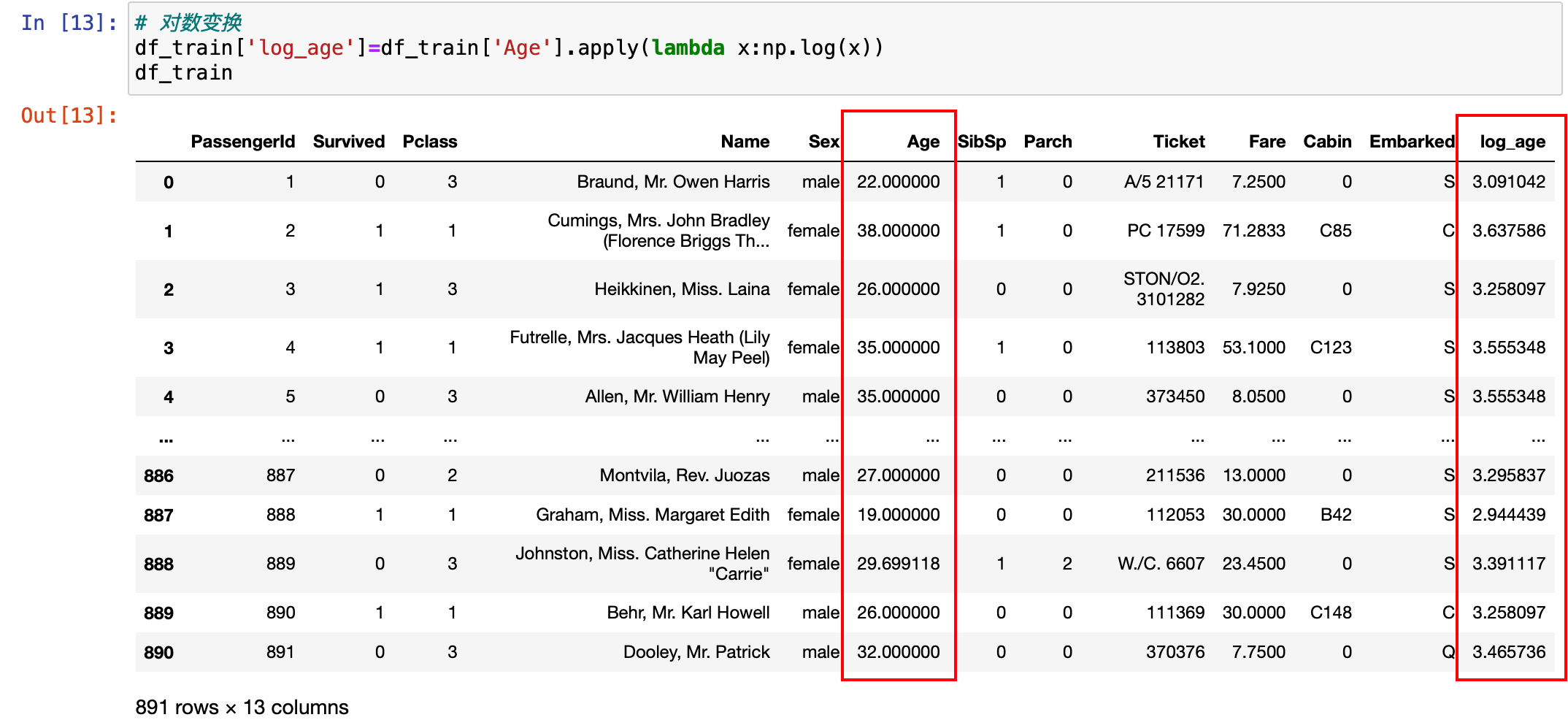
基本上都是 3.几,差别变小了。接下来是最大最小归一化处理。
MinMaxScaler() 归一化处理
MinMaxScaler 是一种常见的数据归一化方法,用于将数据特征缩放到指定的范围内,在数据预处理阶段,它可以将原始数据转换为具有统一尺度的数据,这对许多机器学习算法很重要。
原理:MinMaxScaler 将数据特征缩放到一个指定的范围内,通常是一个预定义的最小值和最大值之间,其缩放公式为:
在 Python 的 sklearn 库中,可以通过 preprocessing 模块的 MinMaxScaler 类来使用。导入所需的库和模块:from sklearn.preprocessing import MinMaxScaler。创建一个 MinMaxScaler 对象,可以选择指定缩放的范围,0, 1:scaler = MinMaxScaler(feature_range = (0, 1))。使用 fit_transform 方法来对数据进行归一化处理:x_transformed = scaler.fit_transform(x)。
这个处理方法其实有一个弊端,它受极值的影响是比较大的。这个公式要用到最大值和最小值的,如果有几个离群点,影响是非常严重的,就不适用这种处理方式。就是最终归一化的时候,模型的性能不一定很好。一般数据,不知道用最大最小化处理合不合适的时候,一般用本篇接下来会提到的标准化来处理。
回到 jupyter 上,对 Fare(船票价格)进行最大最小化处理。先把需要用到的包全部导入进去。注意,在做最大最小化处理的时候,需要二维数组,所以要两个中括号。最后打印一下看看结果。
python
# 最大最小化处理
from sklearn.preprocessing import MinMaxScaler
mm_scaler=MinMaxScaler()
fare_trans=mm_scaler.fit_transform(df_train[['Fare']])
fare_trans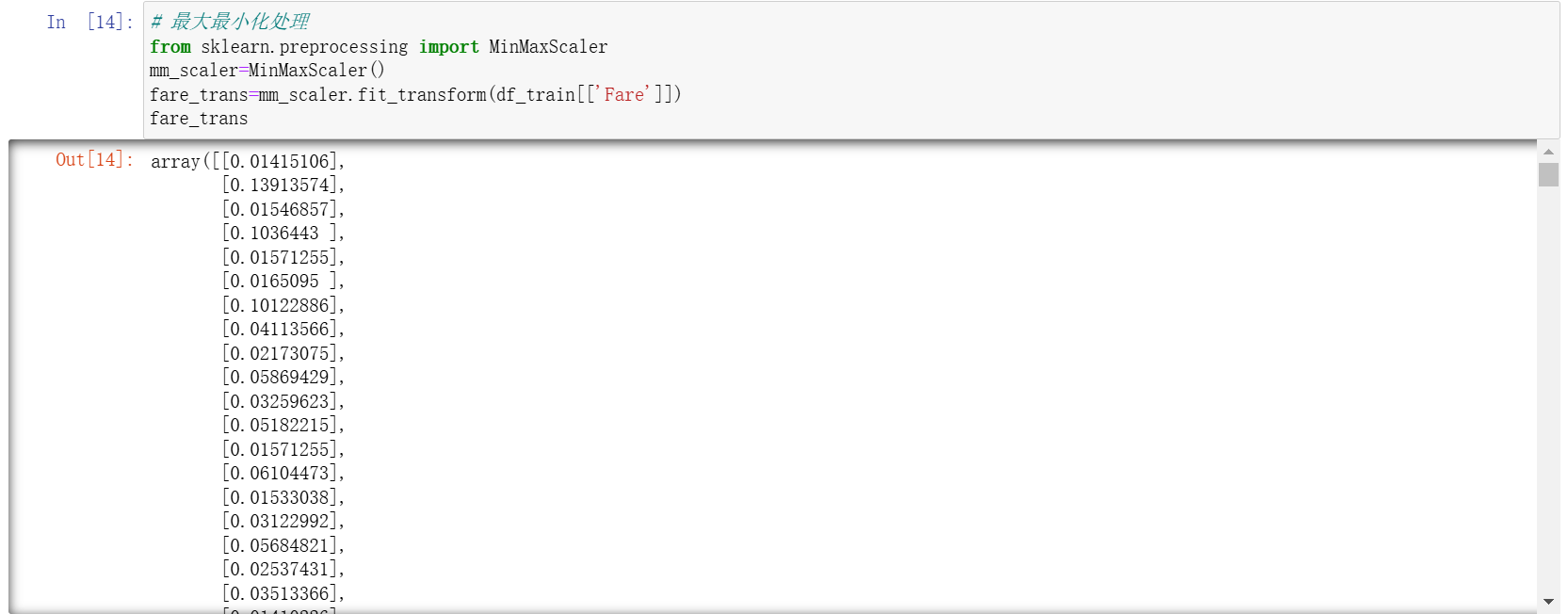
可以看到,对应的结果已经出来了。可以观察一下这个数据,通过最大最小化处理之后,船票的价格都归到了指定的 0 到 1 之间。
还有一个标准化处理,如果离群点太多,最大最小化处理容易受极值的影响,这个时候就采用标准化处理来处理数据。
标准化处理
标准化处理 =
:代表数据集中某一个原始数据点
核心作用如下:
- 消除量纲差异:能把不同单位、不同尺度的数据转换到统一的尺度下,比如将身高(cm)、体重(kg)、收入(元)这类不同量纲的数据放到同一标准下对比分析。
- 适配算法需求:对于支持向量机(SVM)、K近邻(KNN)、线性回归、逻辑回归等对数据分布敏感的算法,标准化可以加快模型收敛速度,提升模型准确性。
- 异常值检测:标准化后的数据中,若某个数据点的绝对值大于3,通常可将其判定为异常值。
处理特点如下:
- 标准化后的数据会呈现均值为0,标准差为1的特征,且不会改变原始数据的分布形态,只是对数据做了线性变换。
- 对异常值不敏感,就算数据中存在极端值,也不会像Min-Max标准化那样被过度影响。
适用场景:
- 数据集的不同特征单位不同,且会对模型结果产生影响时,比如同时包含身高、体重、收入的用户数据集。
- 大部分机器学习算法,尤其是基于距离计算、梯度下降优化的算法,比如KNN、SVM、线性回归等。
- 需要对数据进行异常值检测的场景。
还是处理船票数据。仍然是先导包,把需要用到的包全部导入进去。fit_transform 是 StandardScaler 类的一个方法,它执行了两个步骤:fit(拟合):std_scaler.fit(df_train\['Fare']) 会计算 df_train 数据集中"Fare"列的均值和标准差等统计信息,这些统计信息将用于后续的数据转换。例如,它会计算出"Fare"列的平均值 𝜇 和标准差 𝜎。transform(转换):在计算出统计信息后,transform 方法会根据这些信息对"Fare"列的数据进行转换,将每个原始的"Fare"值 𝑥 按照公式 (𝑥−𝜇) / 𝜎 进行计算,得到标准化后的值。最终,标准化后的 "Fare" 列数据被赋值给fare_std_trans。最后打印出来看一下。
python
# 标准化处理
from sklearn.preprocessing import StandardScaler
std_scaler=StandardScaler()
fare_std_trans=std_scaler.fit_transform(df_train[['Fare']])
fare_std_trans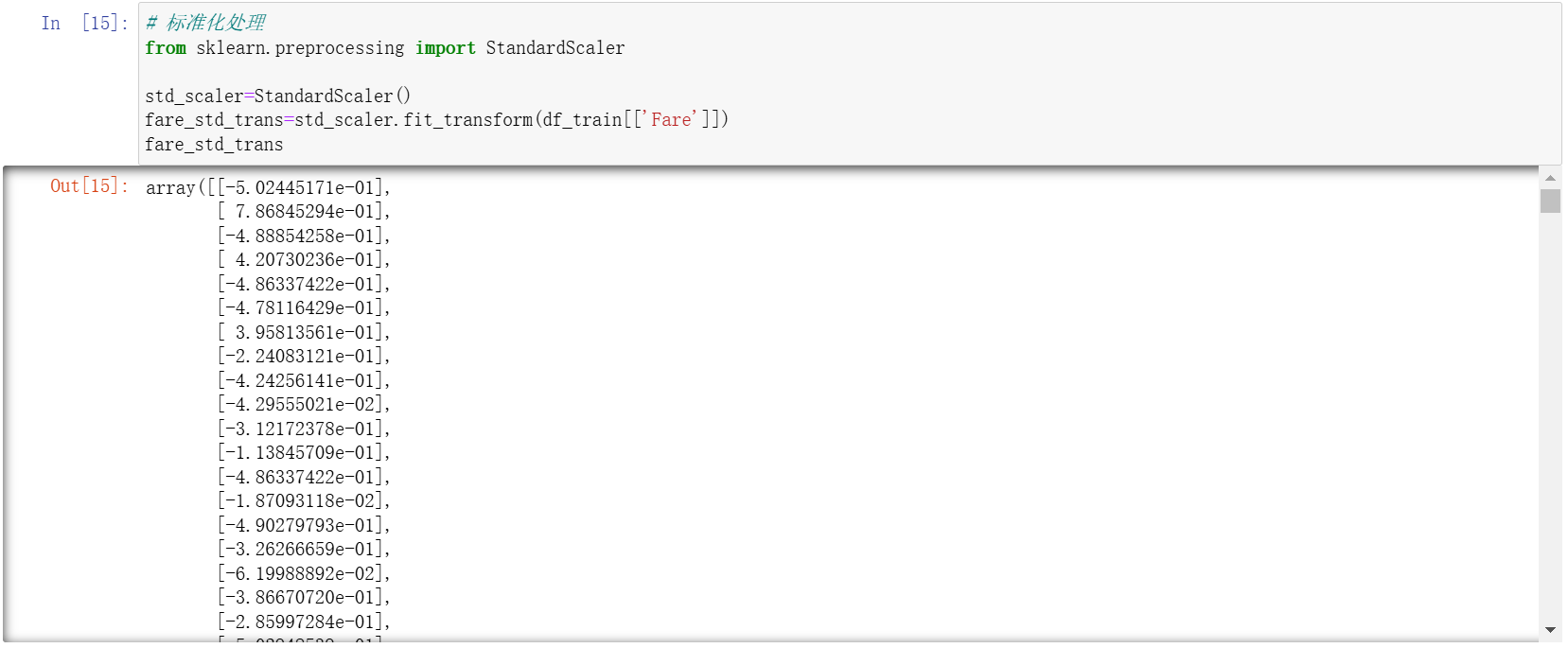
观察后可以发现,它的范围就不在 0 和 1 之间了,它是什么样的数字都有。两个都是用来缩小量纲的(即对数据量纲进行缩放处理以消除量纲影响)。这两个方式用哪一种都行,根据实际情况来。一般一个字段使用一种方法处理就可以了。
描述统计分析
这种东西一般在电商里面会用到。
最大最小值、分位数
统计年龄最大最小值,以及分位数。分位数其实就是箱型图。箱型图上限和下限经常会多出来一些数据点。这些多出来的数据点就是异常值。通过把大于上限的数据点进行筛选,把小于下限的数据点也进行筛选,这样就把异常值给筛选出来了。中间的部分是 IQR = Q3 - Q1。上面的部分是 Q3 +1.5IQR,下面部分就是 Q1 - 1.5IQR。这样就可以计算出来具体的值,就可以筛选出来异常值。
python
# 最⼤最⼩值
max_age = df_train['Age'].max()
min_age = df_train['Age'].min()
print(max_age)
print(min_age)
# 分位数
# 1/4分位数
age_quarter_1 = df_train['Age'].quantile(0.25)
# 3/4分位数
age_quarter_3 = df_train['Age'].quantile(0.75)
print(age_quarter_1)
print(age_quarter_3)高次特征与交叉特征
preprocessing.PolynomialFeatures。这个在统计学里面用的比较多。用来捕捉非线性关系。
PolynomialFeatures 变换用于在机器学习中创建多项式特征,它的主要目的是扩展特征空间,使模型能够更好地拟合非线性关系。这种变换通常用于线性回归、逻辑回归、支持向量机(SVM)等模型,特别是当原始特征与目标之间存在复杂的非线性关系时,多项式特征变换可以提高模型的性能。
使用方法:对于给定的输入特征,例如一个特征向量 x1, x2, x3,PolynomialFeatures 将其转换为多项式的形式,包括原始特征的各种幂和交叉项。例如,对于二次多项式,它会生成 x1, x2, x3, x1\^2, x2\^2, x3\^2, x1x2, x1x3, x2x3。
什么时候用:
-
非线性关系:当你有理由相信目标变量与特征之间存在非线性关系时,多项式特征变换可以用来更好地捕捉这些非线性关系。
-
特定特征之间的交互效应:如果你怀疑某些特征之间的交互效应对目标变量有影响,你可以使用多项式特征变换来引入这些交互项,以改善模型性能。
-
特征工程:在一些情况下,多项式特征变换是特征工程的一部分,用于改进模型的性能。
-
高次特征:如果你认为某些特征具有高次项的影响,例如 x^2, x^3, 等等,你可以使用多项式特征变换来引入这些高次项,以更好地描述数据的复杂性。
-
用于支持向量机 (SVM):在支持向量机中,多项式特征变换可以将数据映射到高维空间,从而使支持向量机能够更好地分隔不同类别的数据。
回到 jupyter 当中实操一下。使用的两个字段分别是 SibSp(同船配偶、兄弟姐妹人数)和 Parch(同船父母、子女人数)来作为高次特征项。打印一下这两项的原始结果。
python
df_train[['SibSp', 'Parch']]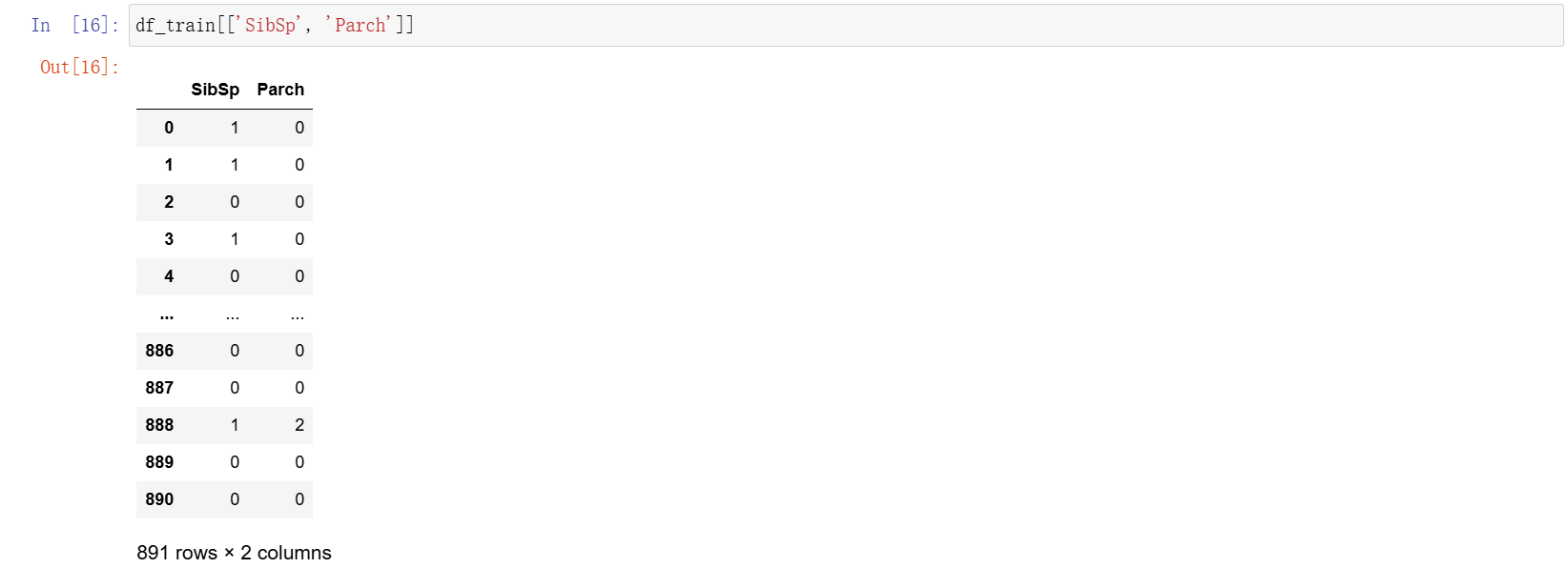
现在开始处理。先导入高次特征需要用到的包。然后实例化,这里涉及到一个参数 degree,这个参数的作用是指定最高次幂是多少次幂的。本次设置为 2,意思就是最高次幂是二次幂。打印一下看看。
python
from sklearn.preprocessing import PolynomialFeatures
poly=PolynomialFeatures(degree=2) # degree设置最高的次幂是哪个次幂 2次幂
poly_fea=poly.fit_transform(df_train[['SibSp','Parch']])
poly_fea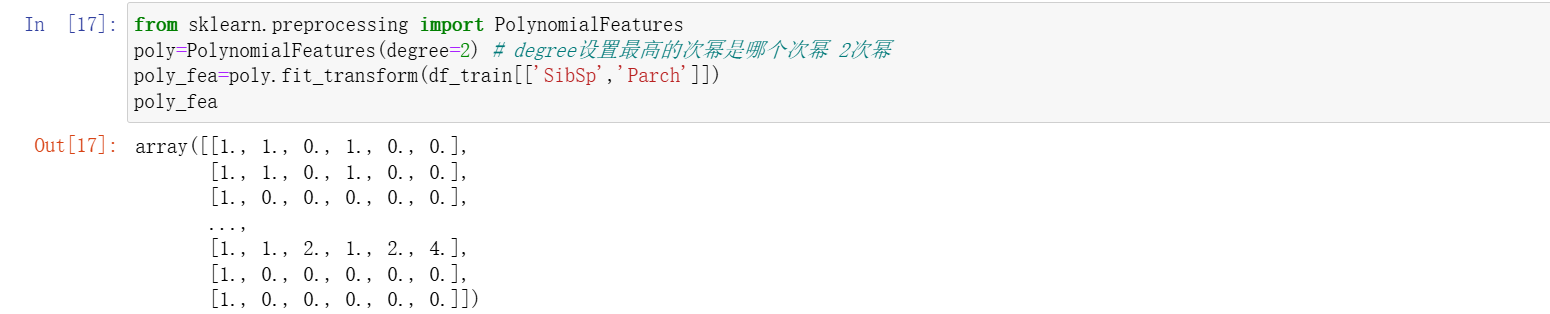
打印出来的都是 0 1 2 4 什么的这些东西。这的怎么去看?可以用获取特征的方式来看。
python
# 获取特征
poly.get_feature_names_out(input_features=['SibSp','Parch'])
这里打印出来 6 个,和上面对应,上面每一行也是 6 个。相当于把这两个字段进行了组合,因为前面指定了最高次幂是 2,所以打印出来的结果就有两个带 2 的,二次幂。就把原来的两列变成了 6 列,给它去增加了非线性的关系,帮助提升模型的性能,然后就可以把这个数据给拼接到原来的数据里,为了最终的建模。
最后说明一下这 6 个值是怎么来的。这6个值是通过 PolynomialFeatures 对输入特征'SibSp','Parch' 进行多项式特征生成得到的,具体来源如下:
- 1:当 include_bias 参数为默认的 True 时,会自动添加一个全为 1 的偏置项特征,它代表常数项。也就是零次幂的项,任何数的零次幂都是 1。
- SibSp:原始输入特征之一,属于一次项。
- Parch:原始输入特征之一,属于一次项。
- SibSp^2:是原始特征 SibSp 的二次幂项,因为设置了 degree=2,所以会产生原始特征的二次幂形式的新特征。
- SibSp Parch:这是两个原始特征 SibSp 和 Parch 的交叉项,在多项式特征生成中,当 degree 足够时,会生成不同特征之间的乘积形式的特征。
- Parch^2:是原始特征 Parch 的二次幂项 ,同样是由于 degree=2,产生了该特征的二次幂形式的新特征。
PolynomialFeatures 在 degree=2 的设定下,对原始的两个特征 'SibSp','Parch' ,生成了包含常数项、原始一次项、原始特征的二次幂项以及原始特征交叉项在内的新特征组合。
字符型特征
最后是字符型特征如何来处理。一共有三种方式。
- 类别型:
- pandas get_dummies/哑变量
- OneHotEncoder()/独热向量编码
- 标签编码LabelEncoder()
get_dummies()是pandas库中的一个函数,用于将分类数据转换为虚拟(二进制)变量。
python
pandas.get_dummies(data, columns=None, prefix=None, prefix_sep='_', drop_first=False, dummy_na=False, sparse=False, dtype=None)参数说明:
- data: 要进行虚拟编码的数据,可以是一个DataFrame或Series。
- columns(可选): 一个用于指定要编码的列名的列表。如果不指定,函数将尝试对数据中的所有非数值列进行编码。
- prefix(可选): 一个字符串或字符串列表,用于指定生成的虚拟列的前缀。如果提供了多个前缀,它们将与列名一一对应。默认情况下,生成的虚拟列的名称将与原始分类值相同。
- prefix_sep(可选): 用于分隔前缀和列名的字符串。默认为下划线"_"。
- drop_first(可选): 如果设置为True,则将删除每个虚拟列中的第一个级别,以避免多重共线性。默认为False。
- dummy_na(可选): 如果设置为True,将为缺失值创建虚拟列,表示原始列中的缺失值。默认为False。
- sparse(可选): 如果设置为True,则生成稀疏矩阵,否则生成密集矩阵。稀疏矩阵在具有大量零值的情况下可以节省内存。默认为False。
- dtype(可选): 用于指定生成虚拟列的数据类型。默认为None,会自动根据数据类型选择。
回到 jupyter,我们对客舱等级进行处理。所有的这些函数需要的参数都是二维数组。
python
# 哑变量处理客舱等级
pd.get_dummies(df_train[['Embarked']])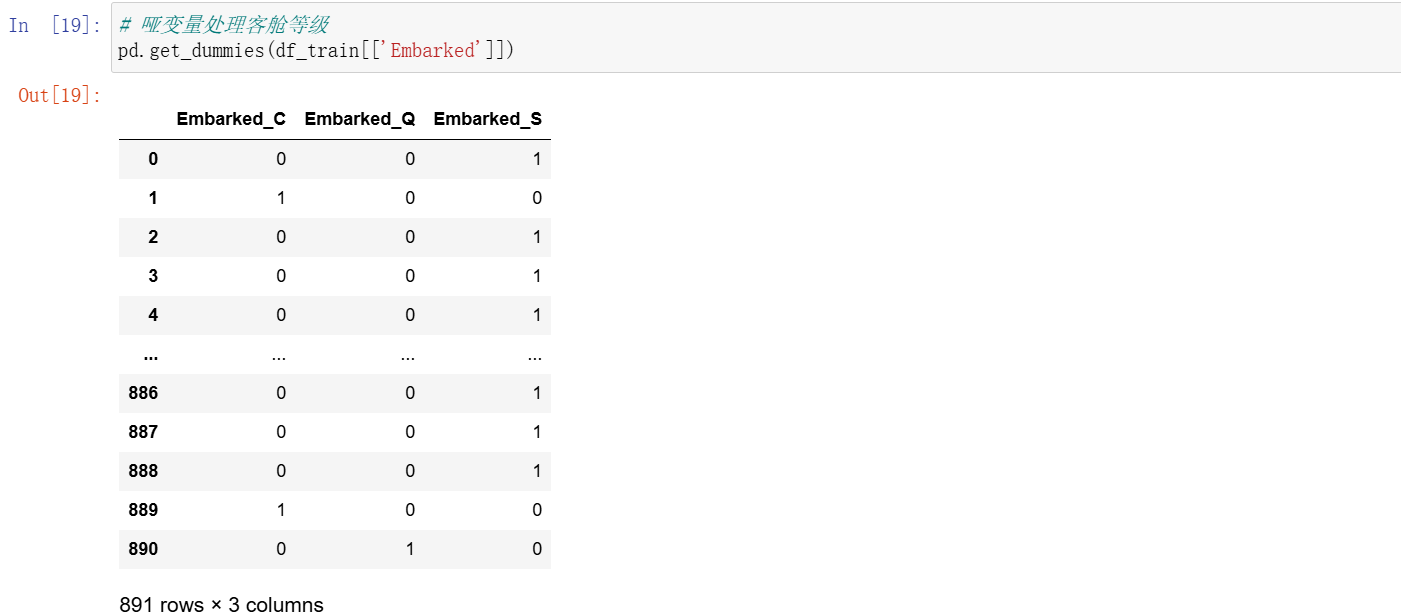
可以看到,都变成了 0101 这样子。就是 true 和 false,true 就是 1,false 就是 0。它们是一一对应的,可以摘过来放一起看一下。比如蓝色画笔画的客舱 S,对应的就是 ture 也就是 1,对应到其他两个客舱就是 false 也就是 0。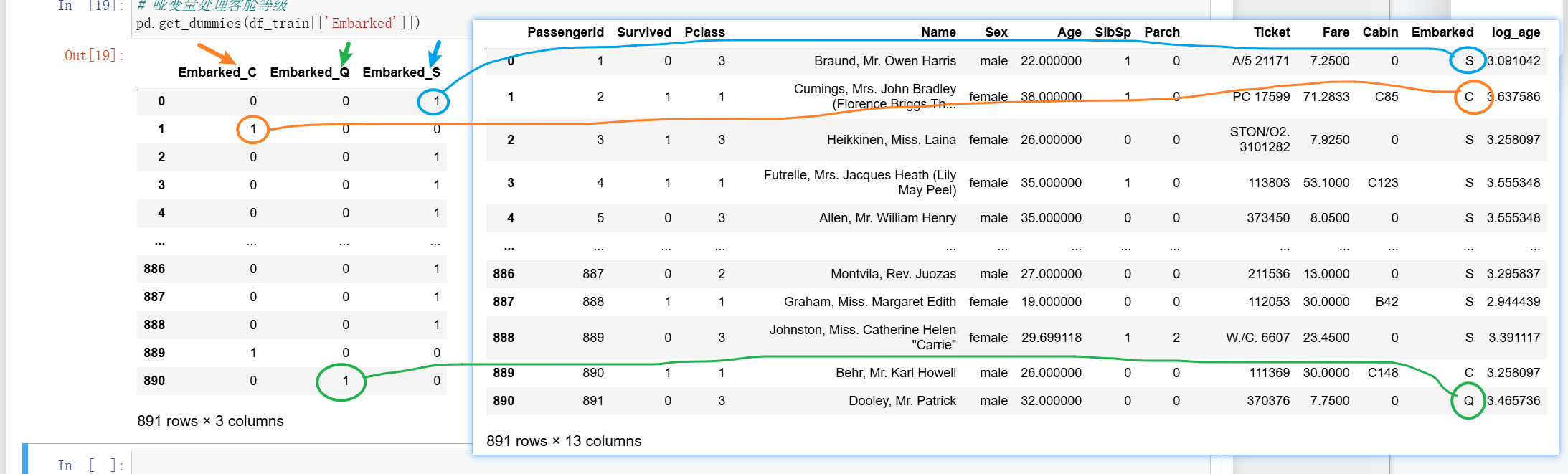
数据量比较小的时候直接用哑变量就可以了。
本篇完整代码
python
# 缺失值处理
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
# 读取数据
df_train=pd.read_csv('train.csv')
df_train.head(10)
# 查看行数
df_train.shape
# 查看数据类型
df_train.info()
# 查看数据异常值
df_train.describe()
# 统计重复行
df_train.duplicated().sum()
# 查看缺失值百分比
df_train.isnull().mean()
# 缺失值处理
# 删除缺失值 dropna
# 填充 fillna()
df_train['Age'].fillna(value=df_train['Age'].mean(), inplace=True)
# # 方法二 scikit SimpleImputer 这个模块是专门处理缺失值数据的类
# from sklearn.impute import SimpleImputer
# imp=SimpleImputer(strategy='mean')
# df_train[['Age']]=imp.fit(df_train[['Age']].values)
# df_train.info()
## Cabin 缺失值处理
df_train['Cabin']=df_train['Cabin'].fillna(0)
df_train.info()
# Embarked 众数填充
df_train['Embarked'].fillna(value=df_train['Embarked'].mode()[0], inplace=True)
df_train.info()
# log变换
# 先了解数据分布的情况
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
fig,ax=plt.subplots(figsize=(12,4))
sns.kdeplot(df_train[df_train['Survived']==1]['Age'],label='Survived',shade=True,ax=ax) # kdeplot核密度图 shade=Ture:阴影部分面积
sns.kdeplot(df_train[df_train['Survived']==0]['Age'],label='Not Survived',shade=True,ax=ax)
plt.legend()
ax.set_xlim(0,df_train['Age'].max())
plt.show()
# 对数变换
df_train['log_age']=df_train['Age'].apply(lambda x:np.log(x))
df_train
# MinMaxScaler() 归一化处理
# 最大最小化处理
from sklearn.preprocessing import MinMaxScaler
mm_scaler=MinMaxScaler()
fare_trans=mm_scaler.fit_transform(df_train[['Fare']])
fare_trans
# 标准化处理
from sklearn.preprocessing import StandardScaler
std_scaler=StandardScaler()
fare_std_trans=std_scaler.fit_transform(df_train[['Fare']])
fare_std_trans
# 高次特征与交叉特征
df_train[['SibSp', 'Parch']]
from sklearn.preprocessing import PolynomialFeatures
poly=PolynomialFeatures(degree=2) # degree设置最高的次幂是哪个次幂 2次幂
poly_fea=poly.fit_transform(df_train[['SibSp','Parch']])
poly_fea
# 获取特征
poly.get_feature_names_out(input_features=['SibSp','Parch'])
# 哑变量处理客舱等级
pd.get_dummies(df_train[['Embarked']])