
一、背景
这两年大家已经习惯让大模型写 CRUD、写脚本、甚至写简单前端 Demo,但真正落地到复杂 Web 场景时,问题会变得微妙:
-
一方面,大模型在代码生成这块已经相当成熟,能熟练复用 Three.js、React、Tailwind 之类的模式。
-
另一方面,真实世界的空间约束 (几何一致性、动线合理性、物体不穿模)却很容易被忽略,尤其到了 3D 任务,很多模型会出现「代码能跑,但场景完全不符合常识」的情况。linkedin
一些最新的研究也在讨论类似问题:传统 LLM 更擅长语言和代码模式,对 3D 空间关系的理解仍然薄弱,因此才会出现「物体重叠、布局自相矛盾」这类现象。arxiv+1
为了更直观地对比不同模型在代码能力 + 3D 空间感知上的综合表现,我设计了一个非常具体的任务:
让多个主流大模型,在统一约束下,用一个 HTML 文件实现 120㎡ 两室两卫的 3D 户型平面图。
二、测试任务设计:一个统一的"户型基准题"
1. Prompt 要求
html
为我创建一个120 平方的3D平面图。 确保它有2个房间、 2个卫生间, 并且是一个可用的平面图。 使用HTML、 CSS、 JS 以及 Three.JS。 只给我一个可以运行并查看这个平面图的HTML文件。所有模型收到的核心指令保持一致,关键约束包括:
-
目标场景:
-
约 120㎡ 的公寓户型
-
2 个卧室 + 2 个卫生间(两室两卫)
-
-
技术栈:
-
HTML + CSS + JavaScript + Three.js
-
只允许返回一个可以直接运行的 HTML 文件,所有代码内嵌,方便直接双击预览
-
-
视觉形态:
- 需要呈现一个3D 户型平面图,包含基本的墙体、房间、门洞和简化家具
换句话说,这是一个「前端三件套 + Three.js + 建筑常识」的综合题。
2. 参与模型名单
这次参与测试的模型包括(按字母序):
-
DeepSeek-V4-Pro
-
Gemini 3.1-Pro
-
GPT 5.5
-
Kimi 2.6
-
Mimo V2.5-Pro
-
Opus 4.6
-
Qwen 3.6-Plus
每个模型的输出我都保存成 HTML,在本地打开并截图,主要从"是否能跑"和"户型是否可信"两个层面做主观评估。
三、这个任务到底在考什么能力?
我觉得这个任务非常适合作为一个综合能力基准,它同时考察两条关键能力曲线:
1. 代码生成与工程落地能力
-
能否在「单 HTML 文件」的约束下,合理组织
<head> / <body>、样式和脚本。 -
是否能正确引入 Three.js,并创建场景、相机、光源、渲染循环等基础结构。
-
是否具备一定的工程习惯:变量命名、函数拆分、注释、交互事件处理等。
这部分更偏向传统"Code LLM"的强项,属于模式化问题 :只要学会几种常见 Three.js 场景搭建模板,就可以快速拼出一个能跑的 Demo。linkedin
2. 真实 3D 空间感知与推理能力
真正区分模型水平的,是下面这些「非语法」约束:
-
几何一致性
-
房间是否都处在统一壳体之内?
-
墙体是否连续、闭合?
-
是否存在明显穿模(门在半空、家具穿墙)?
-
-
动线与门洞合理性
-
从玄关能否走到客厅、卧室、卫生间?
-
门是否长在墙上,而不是随便贴在空间里?
-
-
功能布局合不合常识
-
两室两卫是否真的成立?
-
卧室与卫生间的关系是否合理?厨房/餐厅/客厅的组合是否能用?
-
这部分就不再是简单模板复用,而是对 3D 空间关系的理解和约束能力------很多最近的论文也在讨论如何给 LLM 加上更可靠的 3D 空间推理模块,可见这是当前模型的短板之一。
四、测试结果概览:谁能写、谁能"画对"
下面是一句话先行的整体结论:
-
真正可以「直接当方案」的只有:Mimo V2.5-Pro、GPT 5.5。
-
几何/动线有明显问题但整体还算像样的:Gemini 3.1-Pro、DeepSeek-V4-Pro、Opus 4.6。
-
空间结构严重不可信的:Kimi 2.7、Qwen 3.6-Plus。
详细来说:
1)Mimo V2.5-Pro:综合能力最平衡的第一名

-
几何正确:所有房间都在统一壳体内,墙体连续,看不到明显穿模或错层。
-
动线自然:从玄关进入客厅,再到主卧、次卧以及两个卫生间都能走得通,每个房间都有明确门洞。
-
语义清晰:Living Room、Kitchen、Dining、Master Bedroom、Bedroom 2、Master Bath、Bathroom 2 布局合理。
-
3D & UI 平衡:光照、家具体块和界面信息都在一个「适度」的水平,看起来就像一个可以给甲方看的 120㎡ 两室两卫小方案。
如果让我选一个结果改改文案、直接拿去做产品 Demo,我会首选 Mimo。
2)GPT 5.5:工程风味浓厚的"技术派"
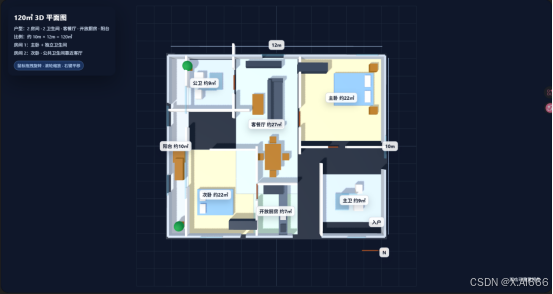
-
尺寸与布局规整:整体是 12m × 10m 的矩形户型,墙体厚度均匀,各房间尺寸都有标注。
-
动线合理:玄关、客厅、卧室、卫生间之间有清晰的门和通路,没有明显"进不去的房间"。
-
表达偏平面 CAD:3D 立体感比 Mimo 弱一些,但工程信息非常清晰。
如果你的受众是开发/工程团队,而不是终端 C 端用户,GPT 这版实际可用性非常高。
3)Gemini 3.1-Pro:结构还行,但更像教学 Demo

-
整体壳体与房间连续,没有散成几块。
-
功能分区(主卧、次卧、客卫、厨房&餐厅、客厅)通过颜色图例标注,逻辑是讲得通的。
-
家具和 3D 表达非常简化,更像教学示例,而不是正式产品界面。
适合作为「Three.js + LLM 教学」的例子,但要当设计方案的话,还得重做 UI 和细节。
4)DeepSeek-V4-Pro:视觉最好看之一,但动线有硬伤
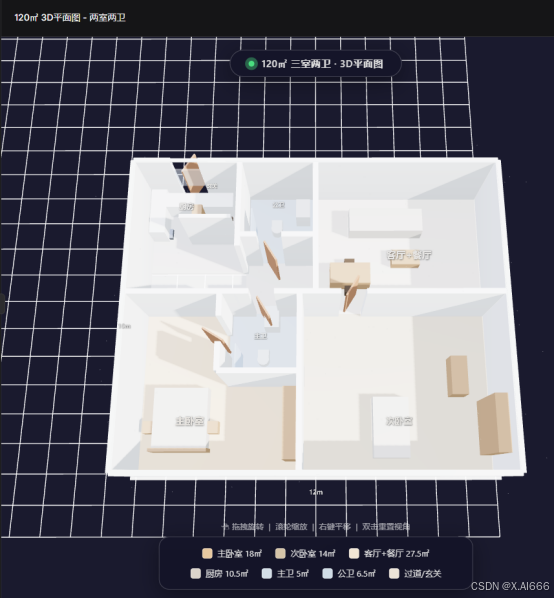
-
材质、光照、家具体块都很完整,看起来非常有「专业 3D 户型工具」的味道。
-
但在动线上有明显问题:
-
玄关开门几乎直接连到厨房,中间缺少缓冲空间。
-
次卧/客厅/餐厅从正门视角看不到清晰入口,有"只能穿墙进去"的感觉。
-
总结就是:"画得很像,但住起来不太行"。
5)Opus 4.6:UI 最强,但几何 Bug 不能忽略
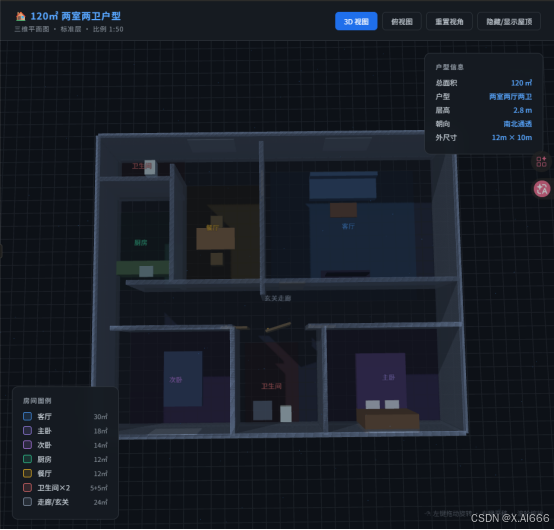
-
从产品 UI 角度看,非常完整:顶部标题、右侧户型信息卡片、左下房间面积图例、视角切换等等。
-
但仔细看细节:
-
卫生间门有悬空、未对齐墙体的情况。
-
主卧和次卧门与墙体错位,存在穿模感。
-
所以它属于「界面完成度高,但几何错误减分」的一档。
6)Kimi 2.6:块体穿模明显、整体没有统一平面
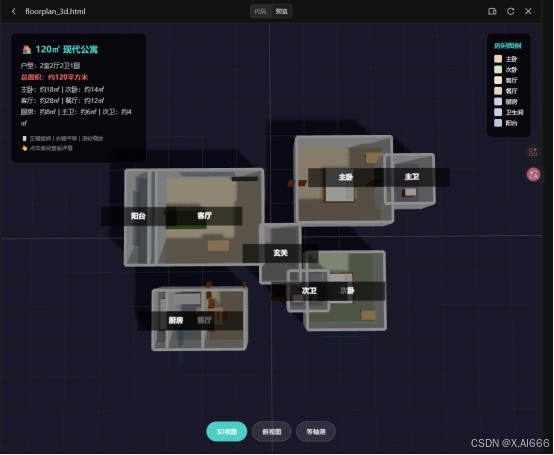
-
多个房间像"岛屿"一样分散在中心区域,通过狭窄通道连接。
-
玄关、次卧、次卫交界处穿模严重,很难看出真实边界。
-
缺少一个清晰的户型外轮廓,更像几块 3D 方块堆在一起。
从「三维可视化实验」的角度看很有意思,但离"户型方案"还有一段距离。
7)Qwen 3.6-Plus:布局与几何问题最严重
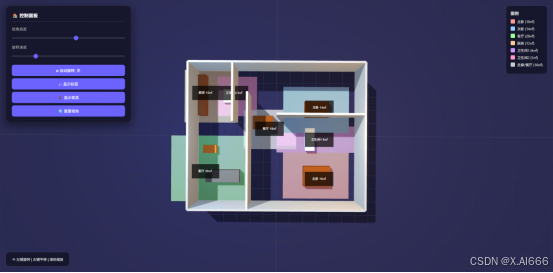
-
彩色块虽然标注了房间类型,但整体轮廓和内部墙线没有形成统一壳体。
-
几乎看不到明确门洞和动线,空间连通性难以判断。
-
家具模型极其简化,3D 表达非常薄弱。
这次测试里,它在「空间结构合理性」维度是最弱的一位。
五、最终排名与档位划分
按「可交付程度(代码可跑 + 户型可用)」来总结,本次测试的大致分档如下:
第一档:可以直接当 Demo 的
-
Mimo V2.5-Pro
-
GPT 5.5
第二档:需要容忍逻辑问题或二次改造的
-
Gemini 3.1-Pro(结构 OK,表现简陋)
-
DeepSeek-V4-Pro(视觉优秀,动线有硬伤)
-
Opus 4.6(UI 完整,门/墙几何 Bug 明显)
第三档:不推荐用于「真实户型 Demo」的
-
Kimi 2.7(块体穿模严重,无统一壳体)
-
Qwen 3.6-Plus(布局不成体系,动线不可读)
六、小结:LLM 写 3D 户型,还差一层「空间常识」
这次实验的一个直观体会是:
-
写出能跑的 Three.js 户型代码,已经不是难题;
-
真正难的是:让模型在生成代码的同时,遵守人与建筑的空间常识------门要长在墙上,房间要连在一起,动线要走得通,不要让用户"穿墙进卧室"。
从实践角度,如果以后要在产品里真正依赖大模型来生成 3D 布局,建议:
-
把空间规则(壳体闭合、门附着墙体、不允许穿模、所有房间可达等)显式写进 Prompt;
-
结合一些几何/图搜索规则,在生成后做自动检查,尽可能把「看着就不对劲」的结果挡在系统外面;
-
对于高风险场景(真实装修、建筑方案),仍然需要人类设计师做最后审核。