
🦌云深麋鹿
专栏 :C++ | 用C语言学数据结构 | Java

回顾:上一篇我们结束了 二叉搜索树,接下来这篇文章让我们进入到 map&set 的使用学习,体会新的设计思路吧~
放个目录
- [一 序列式容器和关联式容器](#一 序列式容器和关联式容器)
-
- [1.1 介绍](#1.1 介绍)
-
- [1.1.1 序列式容器](#1.1.1 序列式容器)
- [1.1.2 关联式容器](#1.1.2 关联式容器)
- [1.2 给各容器分类](#1.2 给各容器分类)
- [1.3 前言](#1.3 前言)
- [二 set系列的使用](#二 set系列的使用)
-
- [2.1 构造](#2.1 构造)
-
- [2.1.1 无参默认构造](#2.1.1 无参默认构造)
- [2.1.2 迭代器区间构造](#2.1.2 迭代器区间构造)
-
- [(1)用一个 vector对象 初始化](#(1)用一个 vector对象 初始化)
- [(2)用一个 istream_iterator对象 初始化](#(2)用一个 istream_iterator对象 初始化)
- [2.1.3 initializer_list 初始化](#2.1.3 initializer_list 初始化)
- [2.2 增删查](#2.2 增删查)
-
- [2.2.1 insert](#2.2.1 insert)
- [2.2.2 erase](#2.2.2 erase)
- [2.2.3 find](#2.2.3 find)
- [2.3 其他接口](#2.3 其他接口)
-
- [2.3.1 count](#2.3.1 count)
- [2.3.2 lower_bound/upper_bound](#2.3.2 lower_bound/upper_bound)
- [2.4 multiset和set的差异](#2.4 multiset和set的差异)
-
- [2.4.1 不去重](#2.4.1 不去重)
- [2.4.2 find](#2.4.2 find)
- [2.4.3 count](#2.4.3 count)
- [2.4.4 erase](#2.4.4 erase)
- [2.5 题目](#2.5 题目)
-
- [2.4.1 142. 环形链表 II - 力扣(LeetCode)(https://leetcode.cn/problems/linked-list-cycle-ii/description/)](#2.4.1 142. 环形链表 II - 力扣(LeetCode))
- [2.4.2 349. 两个数组的交集 - 力扣(LeetCode)(https://leetcode.cn/problems/intersection-of-two-arrays/description/)](#2.4.2 349. 两个数组的交集 - 力扣(LeetCode))
- 2.4.3(拓展题型)
-
- (1)同样用set存储数据
- [(2)找 交/差 集](#(2)找 交/差 集)
- [三 map系列的使用](#三 map系列的使用)
-
- [3.1 pair的介绍](#3.1 pair的介绍)
- [3.2 insert](#3.2 insert)
-
- [3.2.1 写一个pair有名对象再插入](#3.2.1 写一个pair有名对象再插入)
- [3.2.2 插入一个pair匿名对象](#3.2.2 插入一个pair匿名对象)
- [3.2.3 隐式类型转换:直接插入值](#3.2.3 隐式类型转换:直接插入值)
- [3.2.4 make_pair构造pair](#3.2.4 make_pair构造pair)
- [3.2.5 返回值](#3.2.5 返回值)
- [3.3 遍历](#3.3 遍历)
-
- [3.3.1 迭代器遍历](#3.3.1 迭代器遍历)
- [3.3.2 范围for](#3.3.2 范围for)
- [3.4 删查改](#3.4 删查改)
-
- [3.4.1 erase](#3.4.1 erase)
- [3.4.2 find](#3.4.2 find)
- [3.4.3 通过迭代器修改](#3.4.3 通过迭代器修改)
- [3.5 应用实例](#3.5 应用实例)
- [3.6 迭代器和 ](#3.6 迭代器和[ ])
- [3.7 题目](#3.7 题目)
-
- [3.7.1 138. 随机链表的复制 - 力扣(LeetCode)(https://leetcode.cn/problems/copy-list-with-random-pointer/description/)](#3.7.1 138. 随机链表的复制 - 力扣(LeetCode))
- [3.7.2 692. 前K个高频单词 - 力扣(LeetCode)(https://leetcode.cn/problems/top-k-frequent-words/description/)](#3.7.2 692. 前K个高频单词 - 力扣(LeetCode))
- [3.8 multimap](#3.8 multimap)
一 序列式容器和关联式容器
1.1 介绍
1.1.1 序列式容器
- 逻辑结构为线性。
- 两个存储位置之间没有紧密的关联关系。
1.1.2 关联式容器
- 逻辑结构为非线性。
- 两个存储位置之间有紧密的关联关系。
1.2 给各容器分类
- 序列式容器:string、vector、list、deque、array、forward_list。
- 关联式容器:map/set系列和unordered_map/unordered_set系列。
1.3 前言
- 我们接下来介绍的map/set底层是红黑树,红黑树是⼀颗平衡二叉搜索树。
- set是key搜索场景的结构,map是key/value搜索场景的结构。
二 set系列的使用
该容器适用场景:去重+排序。

- T就是set底层关键字的类型。
- Compare(一般保持默认即可):默认要求T⽀持小于比较。
- Alloc(一般保持默认即可):底层存储数据的内存是从空间配置器申请的。
2.1 构造
我们这里研究C++11的构造。
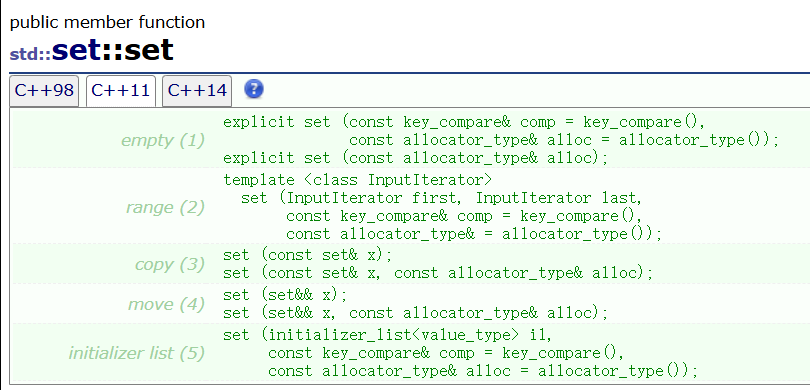
2.1.1 无参默认构造

- key_compare 是比较函数对象的类型,默认为 std::less< Key >。
- allocator_type 是内存分配器类型,默认为 std::allocator< Key >。

cpp
set<int> s;调试:

- 迭代器是双向迭代器。
2.1.2 迭代器区间构造

- InputIterator 为输入迭代器类型。

遍历迭代区间中的元素,把非重复元素插入set中。
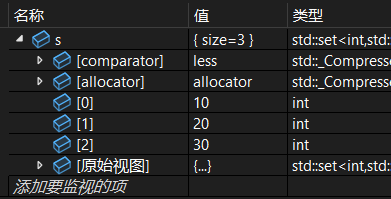
(1)用一个 vector对象 初始化
cpp
vector<int> v = { 10, 20, 30, 20, 10 };
set<int> s(v.begin(), v.end());调试:
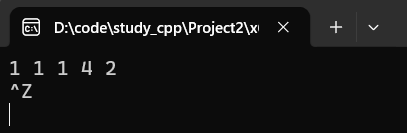
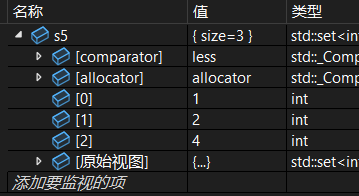
(2)用一个 istream_iterator对象 初始化
从输入中读取值初始化:
cpp
istream_iterator<int> eos;
istream_iterator<int> iit(cin);
set<int> s5(iit, eos);运行:
调试:
2.1.3 initializer_list 初始化

- initializer_list 是C++11 新增的特性,接受 花括号 {} 包围的元素列表。

cpp
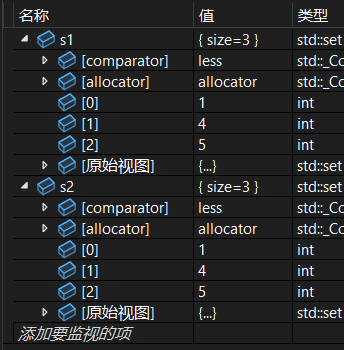
set<int> s1 = { 1, 5, 5, 4 };
set<int> s2{ 1, 5, 5, 4 };调试:
2.2 增删查
set不支持修改数据,这会破坏底层红黑树结构。
2.2.1 insert
(1)插入单个元素

- 返回值类型为一个 pair<iterator, bool>。
pair类的定义如下:

Ⅰ pair 中 iterator成员 指向已存在元素或新插入元素的迭代器。
Ⅱ pair 中 bool成员 存储是否成功插入信息。 - const value_type& val:接受左值(有名字的变量)。
- value_type&& val:接受右值(临时对象、std::move 转换的值)。
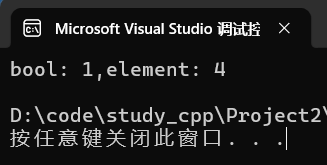
①常见用法
cpp
set<int> s{ 1, 2, 3 };
auto result = s.insert(4);
cout << "bool: " << result.second;
cout << ",element: " << *result.first << endl;运行:
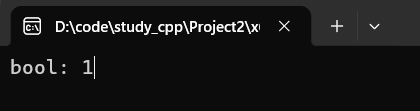
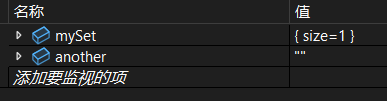
②插入 std::move 转换的值
cpp
set<string> mySet;
string another = "Temp";
auto result = mySet.insert(move(another));
cout << "bool: " << result.second;运行:
调试:
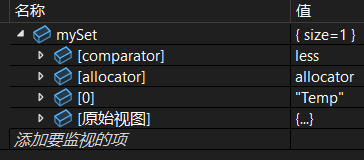
- mySet 中的元素现在拥有 "Temp" 的内存。
- another 不再拥有任何字符串内存(通常变为空)。
std::move 不是移动数据本身,而是授予"窃取资源"的权限,让目标对象可以高效地接管资源所有权。
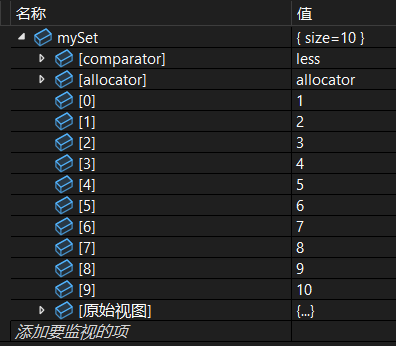
(2)指定位置插入

position: 一个提示位置的迭代器,将在此位置附近插入。
cpp
set<int> mySet;
vector<int> data = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
auto hint = mySet.end();
for (int x : data) {
hint = mySet.insert(hint, x);
}- 批量插入,插入序列有序,使用提示插入。
- 插入操作时间复杂度 O(1)。
调试:
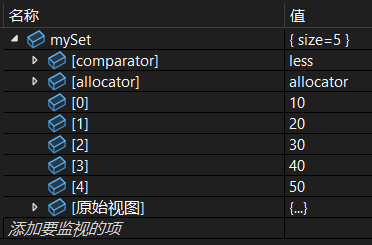
(3)插入一段区间

函数效果等价于:
cpp
while (first != last) {
insert(*first);
++first;
}上代码测试:
cpp
set<int> mySet;
vector<int> vec = { 10, 20, 30, 40, 50, 10 };
mySet.insert(vec.begin(), vec.end());调试:
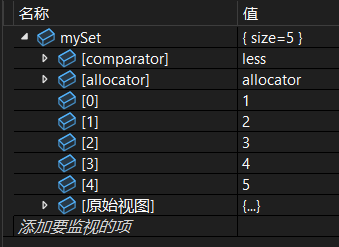
(4)插入一段 initializer_list

函数效果等价于:
cpp
for (const auto& elem : il) {
insert(elem);
}上代码测试:
cpp
set<int> mySet;
mySet.insert({ 1, 2, 3, 4, 5 });调试:
2.2.2 erase
(1)删除指定位置元素

① position: 一个 const_iterator(只能读取元素,不能修改),指向要删除的元素的位置。
② 该迭代器必须指向容器内的有效元素。
cpp
set<int> s{ 1, 2, 3 };
s.erase(s.end());否则程序奔溃: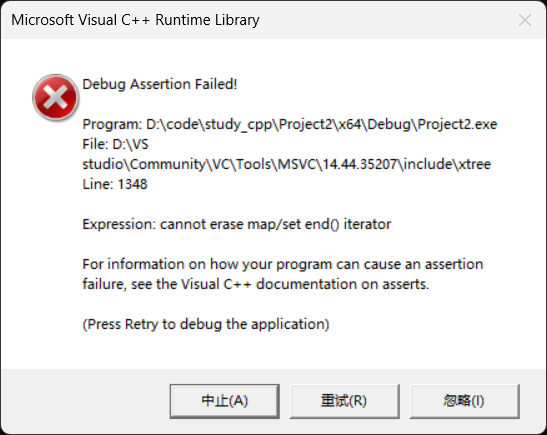
③ 返回值类型为 iterator,指向被删除元素的下一个元素。
- 若删除的是最后一个元素,则返回 end()。
- 为什么返回值类型不是 const_iterator ?
cpp
typedef const int* iterator;
typedef const int* const_iterator;Ⅰ iterator 和 const_iterator 都不能修改元素本身,底层类型可能都是一样的:
Ⅱ 可以把 const_iterator 理解为只读容器(不能erase)的迭代器。
Ⅲ erase 返回 iterator(可变容器的迭代器) 保持了它原来的特性,可继续借助返回值(赋值给定义的it遍历迭代器)连续erase。
cpp
set<int> s{ 1, 2, 3 };
for (auto it = s.begin(); it != s.end(); ) {
it = s.erase(it);
}-
为什么参数类型不是 iterator 而是 const_iterator?
Ⅰ 遵循最小权限原则:对于参数,函数只要求它真正的权限。参数类型为 const_iterator 就是函数 erase 要 求的最小权限。
Ⅱ 最大灵活性:函数接受更广泛的参数类型。我们传参 iterator (iterator 可以隐式转换成 const_iterator, 反之不可),erase 函数也接受。
删除set中的min值。
根据 set 底层是红黑树的特性:
cpp
set<int> s{ 1, 2, 3 };
s.erase(s.begin());直接传begin。
调试:

(2)删除指定值元素

1.返回值类型为 size_t ,表示已删除元素个数。
2.由于 set 元素唯一,可通过返回值判断删除是否成功。
- 返回值为0,元素不存在。
- 返回值为1,删除成功。
测试:
cpp
set<int> s{ 1, 2, 3 };
size_t n1 = s.erase(2);
cout << "test1: " << n1 << endl;
size_t n2 = s.erase(2);
cout << "test2: " << n2 << endl;运行:
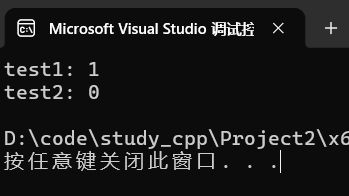
(3)删除一个区间

- 返回值指向最后一个被删除元素之后的迭代器。
- 删除范围是 [first, last) :参数 first 指向要删除的第一个元素的迭代器,last 指向要删除的最后一个元素之后的迭代器。
测试:
cpp
set<int> s{ 1, 2, 3 };
auto it = s.erase(s.begin(),--s.end());
cout << "remaining number: " << *it << endl;运行:
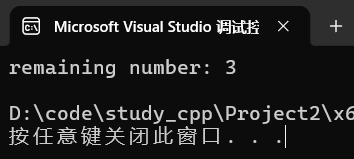
2.2.3 find

- 俩函数返回值不同,可以看出来,一个是const容器的 find,一个是可变容器的 find。
- 没找到返回set::end(如下面的代码)。
cpp
set<int> s{ 1, 2, 3 };
cout << (s.find(4) == s.end()) << endl;运行:
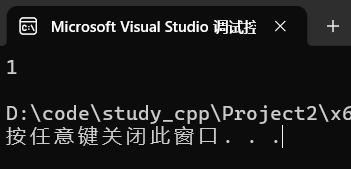
另外:
- 算法库的find是暴力查找,时间复杂度是O(N)。
- set的find效率更高,时间复杂度是O(logN)。
2.3 其他接口
2.3.1 count
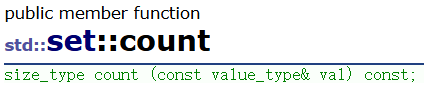
返回元素在容器里的个数。
也可以用来判断元素是否在容器里:
cpp
set<int> s{ 1, 2, 3 };
cout << s.count(4) << endl;运行:
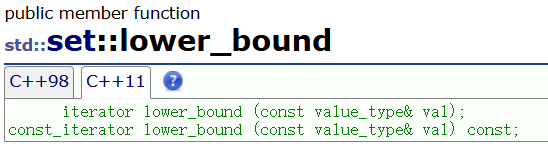
2.3.2 lower_bound/upper_bound
- lower_bound 返回大于等于val的元素的迭代器。
- upper_bound 返回大于val的元素的迭代器。
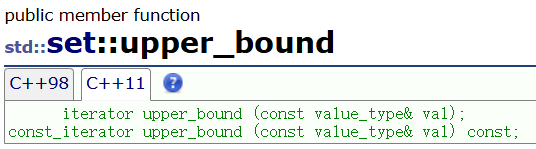
- 这俩配合起来,方便找左闭右开的区间。
删除这段区间的元素:
cpp
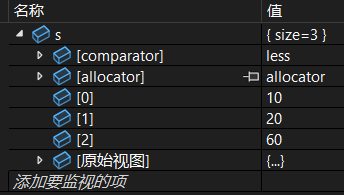
set<int> s = { 10, 20, 30, 40, 50, 60 };
auto first = s.lower_bound(25);
auto last = s.upper_bound(55);
s.erase(first, last);调试:
算法库里也有这俩函数,但是要求容器内元素有序。
2.4 multiset和set的差异
包在里了:
2.4.1 不去重
- 插入的值可以相同,所以insert操作永远不会失败。
- 这里第一个 insert 插入单个元素,返回值就不是一个pair了。
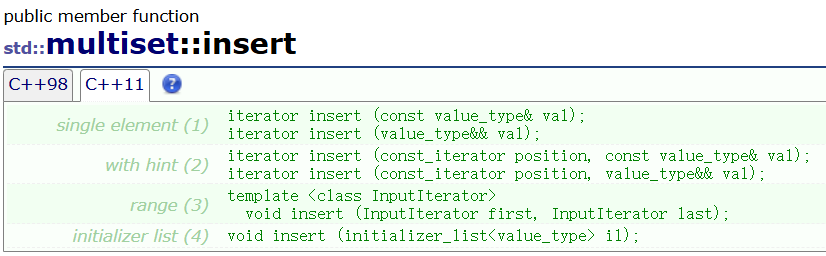
set 里元素唯一,可能会insert失败,所以返回值为一个pair(带有是否insert成功判断)。
测试:
cpp
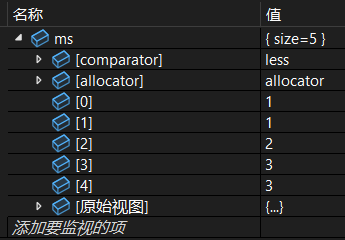
multiset<int> ms{1,1,3,3};
auto it = ms.insert(2);
cout << *it << endl;insert 返回值指向新插入元素的迭代器。
运行:
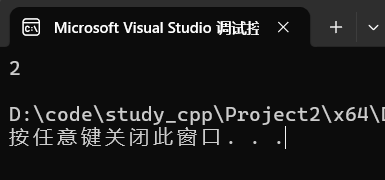
调试:
2.4.2 find

- find 找到的是中序遍历到的第一个。
- 寻找过程:找左子树有没有val,没有就取前一个找到了的val。
- 跟set的一样没找到就返回end。
测试:
cpp
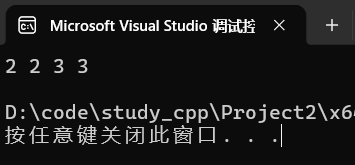
multiset<int> ms{ 1,1,2,2,3,3 };
auto it = ms.find(2);
while(it != ms.end()){
cout << *it << " ";
++it;
}
cout << endl;运行:
2.4.3 count

- 返回值为 参数val 在容器中出现的个数,可能取值为0~n。
set中元素唯一,所以count的返回值取值只可能为0或1。
测试:
cpp
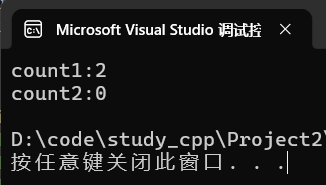
multiset<int> ms{ 1,1,2,2,3,3 };
size_t count1 = ms.count(2);
size_t count2 = ms.count(4);
cout << "count1:" << count1 << endl;
cout << "count2:" << count2 << endl;运行:
2.4.4 erase

(1)给迭代器删除一个
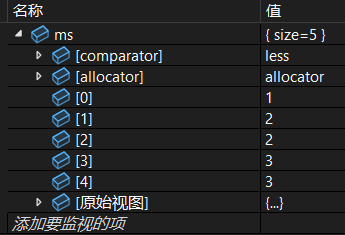
cpp
multiset<int> ms{ 1,1,2,2,3,3 };
ms.erase(ms.begin());调试:
(2)给值删除所有
cpp
multiset<int> ms{ 1,1,2,2,3,3 };
ms.erase(1);调试:
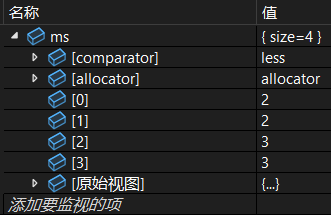
(3)迭代区间
就不上代码了。
2.5 题目
来两道题练练手。
2.4.1 142. 环形链表 II - 力扣(LeetCode)
cpp
ListNode *detectCycle(ListNode *head) {
set<ListNode*> s;
ListNode* node = head;
while(node){
if(!s.insert(node).second){
return node;
}
node = node -> next;
}
return nullptr;
}胜在代码简单。
2.4.2 349. 两个数组的交集 - 力扣(LeetCode)
(1)先去重
①算法库
算法库里有个unique函数,但是我们不用这个。
②用set存储数据
迭代器区间构造。
(2)再插入
把重叠数据插入vector,该vector作为返回值。
(3)代码
cpp
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
vector<int> v;
set<int> s1(nums1.begin(),nums1.end());
set<int> s2(nums2.begin(),nums2.end());
for(auto e:s2){
if(!s1.insert(e).second){
v.push_back(e);
}
}
return v;
}2.4.3(拓展题型)
(1)同样用set存储数据
(2)找 交/差 集
应用场景:同步算法。
①交集
- 依次比较。
- 让值小的++。
- 值相等的就是交集,后同时++。
- 其中一个结束就结束。
代码:
cpp
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
vector<int> v;
set<int> s1(nums1.begin(), nums1.end());
set<int> s2(nums2.begin(), nums2.end());
auto it1 = s1.begin();
auto it2 = s2.begin();
while(it1 != s1.end() && it2 != s2.end()){
if (*it1 == *it2) {
v.push_back(*it1);
++it1;
++it2;
}else if(*it1 < *it2) {
++it1;
}else {
++it2;
}
}
return v;
}②差集
- 依次比较。
- 值小的就是差集,小的++。
- 值相等就同时++。
- 其中一个结束就结束。
- 另一个剩下的都是差集。
代码:
cpp
vector<int> difference(vector<int>& nums1, vector<int>& nums2) {
vector<int> v;
set<int> s1(nums1.begin(), nums1.end());
set<int> s2(nums2.begin(), nums2.end());
auto it1 = s1.begin();
auto it2 = s2.begin();
while (it1 != s1.end() && it2 != s2.end()) {
if (*it1 == *it2) {
++it1;
++it2;
}
else if (*it1 < *it2) {
v.push_back(*it1);
++it1;
}
else {
v.push_back(*it2);
++it2;
}
}
if (!s1.empty()) {
while (it1 != s1.end()) {
v.push_back(*it1);
++it1;
}
}else if (!s2.empty()) {
while (it2 != s2.end()) {
v.push_back(*it2);
++it2;
}
}
return v;
}三 map系列的使用
3.1 pair的介绍
前面有提到过:

pair有键值对的意思,map中的一个元素就是一个pair。
在容器map中:
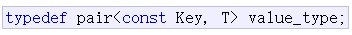
3.2 insert

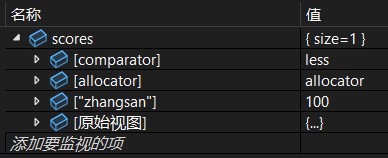
3.2.1 写一个pair有名对象再插入
cpp
map<string, int> scores;
pair<string,int> pair("zhangsan", 100);
scores.insert(pair);调试:
3.2.2 插入一个pair匿名对象
方便一些。
cpp
map<string, int> scores;
scores.insert(pair<string,int>("zhangsan", 100));3.2.3 隐式类型转换:直接插入值
最方便。
cpp
map<string, int> scores;
scores.insert({ "zhangsan", 100 });3.2.4 make_pair构造pair

上代码:
cpp
map<string, int> scores;
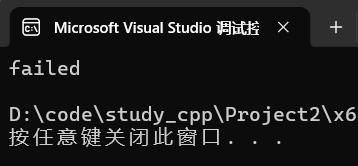
scores.insert(make_pair("zhangsan", 100));3.2.5 返回值
cpp
pair<iterator,bool>若返回pair第二个成员为true,则没有相同值;
若为false,则有相同值。
cpp
map<string, int> scores;
scores.insert({ "zhangsan", 100 });
auto result = scores.insert({ "zhangsan", 80 });
if (result.second) {
cout << "success" << endl;
}
else {
cout << "failed" << endl;
}键相同则插入失败。
运行:
3.3 遍历
插入代码放这里:
cpp
map<string, int> scores;
scores.insert({ "zhangsan", 100 });
scores.insert({ "lisi", 80 });3.3.1 迭代器遍历
- pair不支持直接输入输出,要取first/second。
cpp
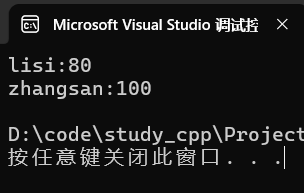
auto it = scores.begin();
while (it != scores.end()) {
cout << it->first << ":" << it->second << endl;
++it;
}运行:
3.3.2 范围for
支持迭代器,就能用范围for。
记得加引用。
cpp
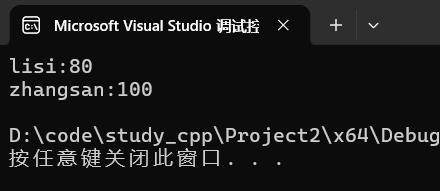
for (auto& e:scores) {
cout << e.first << ":" << e.second << endl;
}运行:
3.4 删查改
初始map:
cpp
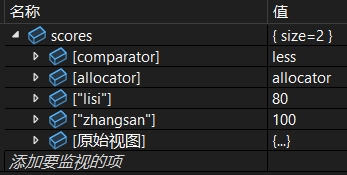
map<string, int> scores = { { "zhangsan", 100 }, { "lisi", 80 } };调试如图:
3.4.1 erase

跟set类似。
(1)用迭代器删除
cpp
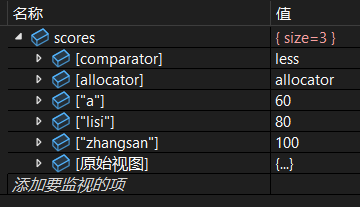
scores.insert({ "a", 60 });
scores.erase(scores.begin());调试:
继续:
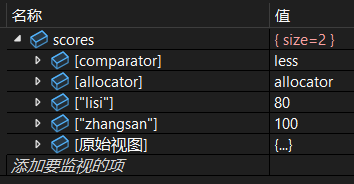
(2)用键删除
cpp
scores.insert({ "a", 60 });
scores.erase("a");调试:

继续:

(3)用迭代区间删除
cpp
scores.erase(scores.begin(), scores.end());调试:
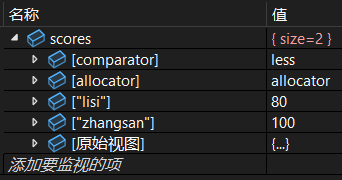
继续:
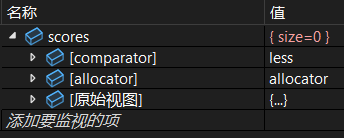
3.4.2 find
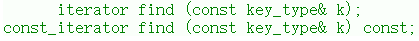
也是跟set类似。
cpp
auto it = scores.find("lisi");
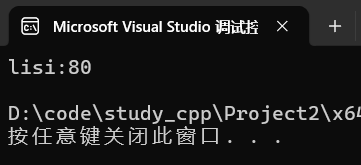
cout << it->first << ":" << it->second << endl;运行:
3.4.3 通过迭代器修改
借助find返回的迭代器修改值:
cpp
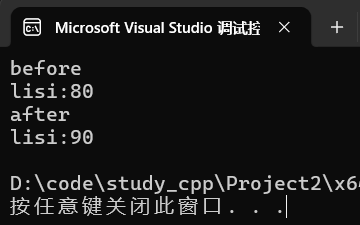
auto it = scores.find("lisi");
cout << "before" << endl;
cout << it->first << ":" << it->second << endl;
it->second = 90;
cout << "after" << endl;
cout << it->first << ":" << it->second << endl;运行:
3.5 应用实例
实现一个简单字典。
输出字典所有内容:
cpp
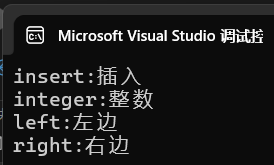
map<string, string> dict = { {"left", "左边"}, {"right", "右边"}
, {"insert", "插入"}, {"integer","整数"}};
auto it = dict.begin();
while (it != dict.end()){
cout << it->first << ":" << it->second << endl;
++it;
}
cout << endl;运行:
简单输入,匹配输出:
cpp
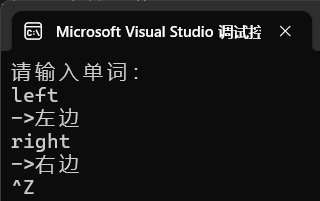
cout << "请输入单词:" << endl;
string str;
while (cin >> str){
auto ret = dict.find(str);
if (ret != dict.end()){
cout << "->" << ret->second << endl;
}else{
cout << "无此单词,请重新输入" << endl;
}
}运行:
3.6 迭代器和
场景:统计水果出现的次数。
cpp
string arr[] = { "苹果","西瓜","苹果","西瓜"
,"苹果","苹果","西瓜","苹果","香蕉","苹果","香蕉" };
map<string, int> countMap;3.6.1 迭代器代码
cpp
for (const auto& str : arr){
auto ret = countMap.find(str);
if (ret == countMap.end()){
countMap.insert({ str, 1 });
}else{
ret->second++;
}
}- 遍历arr。
- 如果ret在countMap里,它的值(即second)就++。
- ret不在countMap里,就新增这个键。
输出:
cpp
for (const auto& e : countMap){
cout << e.first << ":" << e.second << endl;
}运行:
3.6.2 代码
(1)使用场景1
更为方便就能替代上一串代码。
cpp
for (const auto& str : arr) {
++countMap[str];
}- 虽然循环体里只有一句。
- 实际逻辑:没有当前key就插入后++,有就直接++。
(2)使用场景2
修改:
cpp
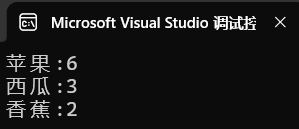
countMap["香蕉"] = 0;运行输出:
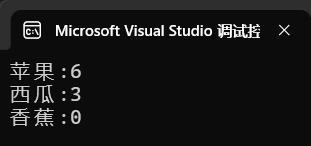
3.7 题目
3.7.1 138. 随机链表的复制 - 力扣(LeetCode)
(1)思路
- 定义一个map,键为旧结点,值为新结点。
- 先把新节点一个一个(根据旧结点的值)创建出来,再跟map里的旧结点一一对应。
- 再来个循环,把原结点的 next 和 random 映射到新结点之间。
(2)上代码
cpp
Node* copyRandomList(Node* head) {
map<Node*,Node*> m;
for(Node* p = head;p != nullptr;p = p->next){
Node* newNode = new Node(p->val);
m[p] = newNode;
}
for(Node* p = head;p != nullptr;p = p->next){
m[p]->next = m[p->next];
m[p]->random = m[p->random];
}
return m[head];
}3.7.2 692. 前K个高频单词 - 力扣(LeetCode)
cpp
vector<string> topKFrequent(vector<string>& words, int k) {}(1) 遍历words,用一个map统计每个word出现次数。
cpp
map<string, int> countMap;
for (auto& word : words) {
countMap[word]++;
}(2) 用一个vector存储map统计结果,便于使用 stable_sort 来排序。
cpp
vector<pair<string, int>> v(countMap.begin(),countMap.end());
stable_sort(v.begin(), v.end(), Compare());- stable_sort 是 < algorithm > 里的函数:

Ⅰ 原来map中是按字典序排的,符合题目条件之一。
Ⅱ 因此不能破坏原本(针对出现次数相同的string)的相对顺序,要用stable_sort。 - 这里的Compare需要自己定义一下:
cpp
struct Compare {
bool operator()(const pair<string, int>& a, const pair<string, int>& b) {
return a.second > b.second;
}
};意思就是次数多的往前排。
(3) 把前k个拎出来放到一个vector里,就是我们要返回的vector。
cpp
vector<string> ret;
for (int i = 0;i < k;++i) {
ret.push_back(v[i].first);
}
return ret;3.8 multimap
- 和map相比的区别:支持关键值key重复插入。
multimap的使用跟map差不多,不再赘述,重点介绍特殊的函数。
equal_range函数
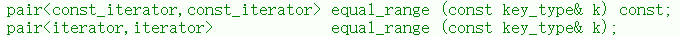
- 两个版本分别对应 const容器 和 可变容器。
- 返回值为一个pair,包含两个迭代器。
- 第一个迭代器,指向第一个不小于 k 的元素(相当于lower_bound(k) )。
- 第二个迭代器,指向第一个大于 k 的元素(相当于 upper_bound(k) )。
- 所以这两个迭代器构造出来的区间,包含所有键等于 k 的元素。
测试一下:
cpp
multimap<int, std::string> mm = {
{1, "apple"}, {2, "banana"}, {2, "blueberry"},
{2, "blackberry"}, {3, "cherry"}
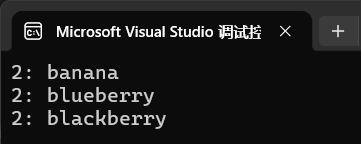
};找键为2的元素:
cpp
auto range = mm.equal_range(2);
for (auto it = range.first; it != range.second; ++it) {
std::cout << it->first << ": " << it->second << std::endl;
}运行:
map&set使用 的学习就到这里,下一篇我们上新的树 AVLTree ,今天会更出来~

