1.开f12失败
但是关闭f12请求成功
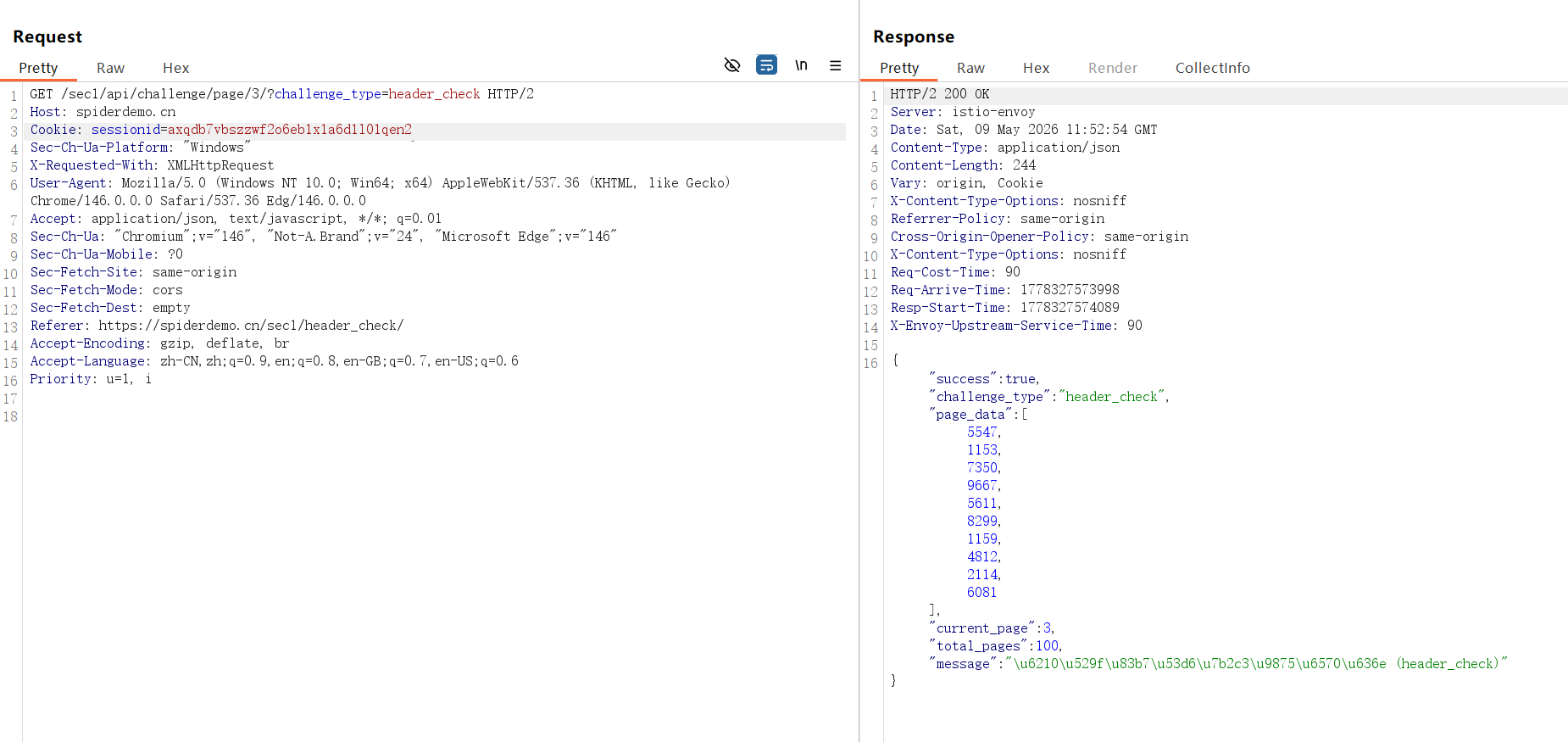
2.我们使用抓包工具来对比两次请求包,看看f12的请求包有什么不一样
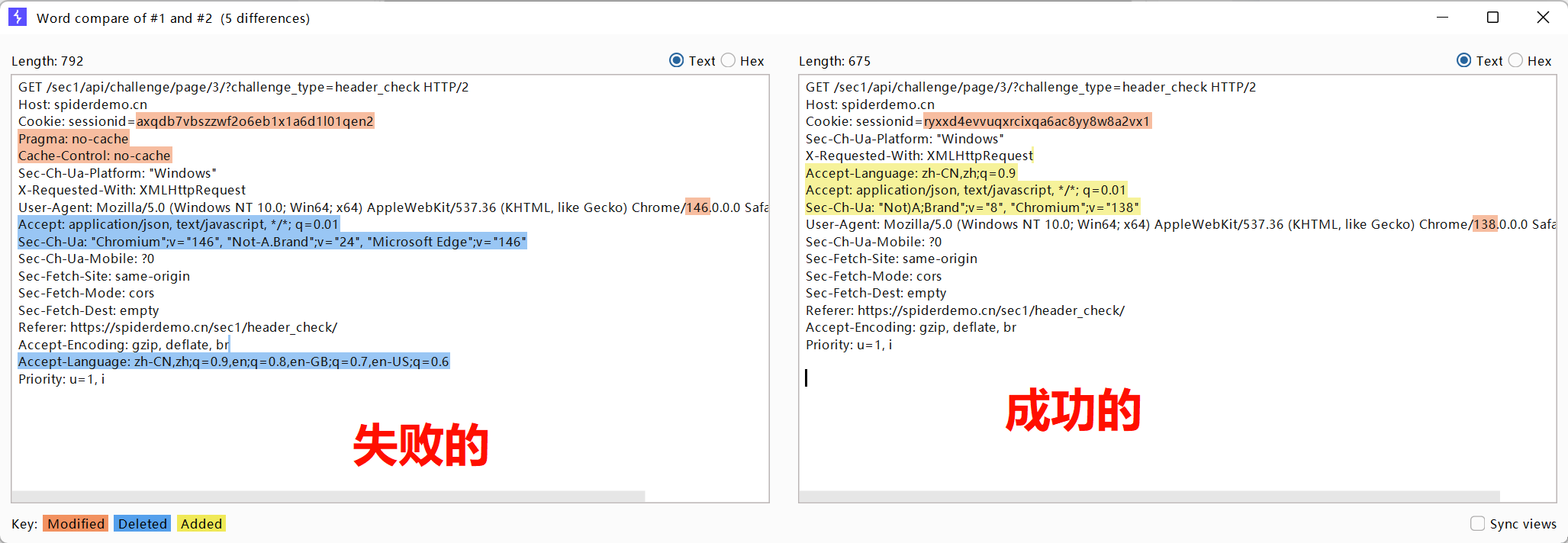
然后测试这个失败的包,
发现删除
Pragma: no-cache
Cache-Control: no-cache
这两个字段后就可以正常获取数据了
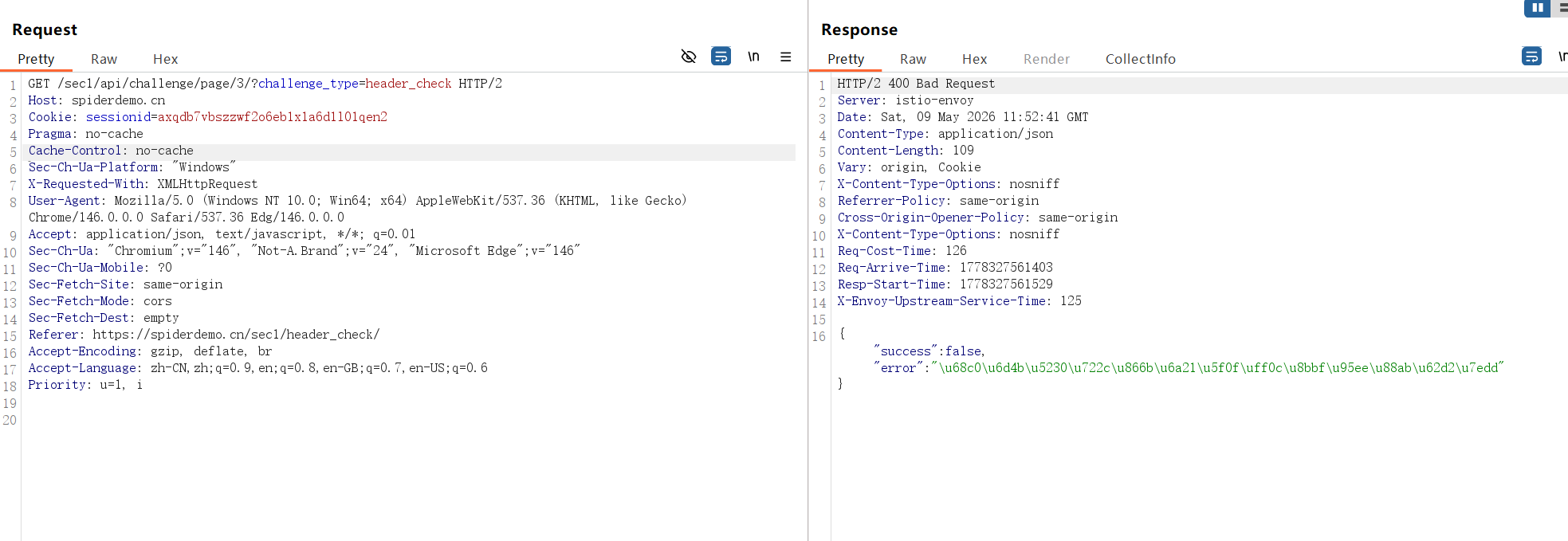
那么为什么开了f12会有这两个字段,原来是因为选择了这两个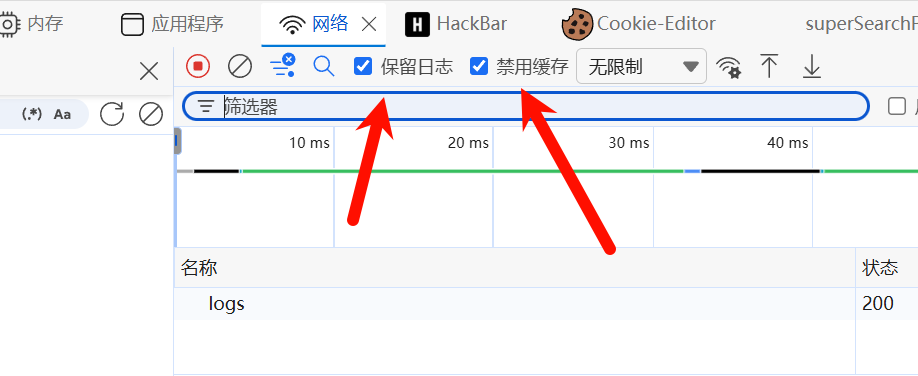
2.抓取包
现在关闭了这两个字段之后,f12就可以正常抓取包了
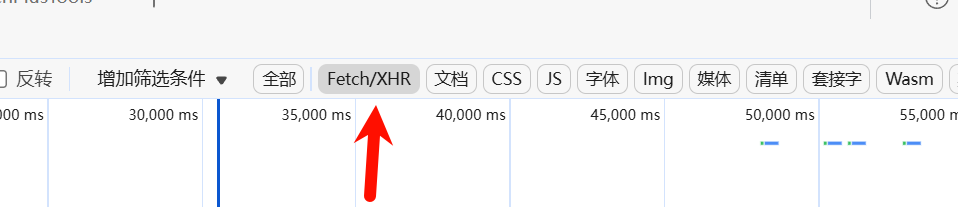
技巧一:
因为在爬虫中,获得的数据更多是动态数据,所以我们在筛选包的时候,可以只选择Fetch/XHR:
然后我们复制bash,生成爬虫代码,具体可看博主写的《人民的爬虫》
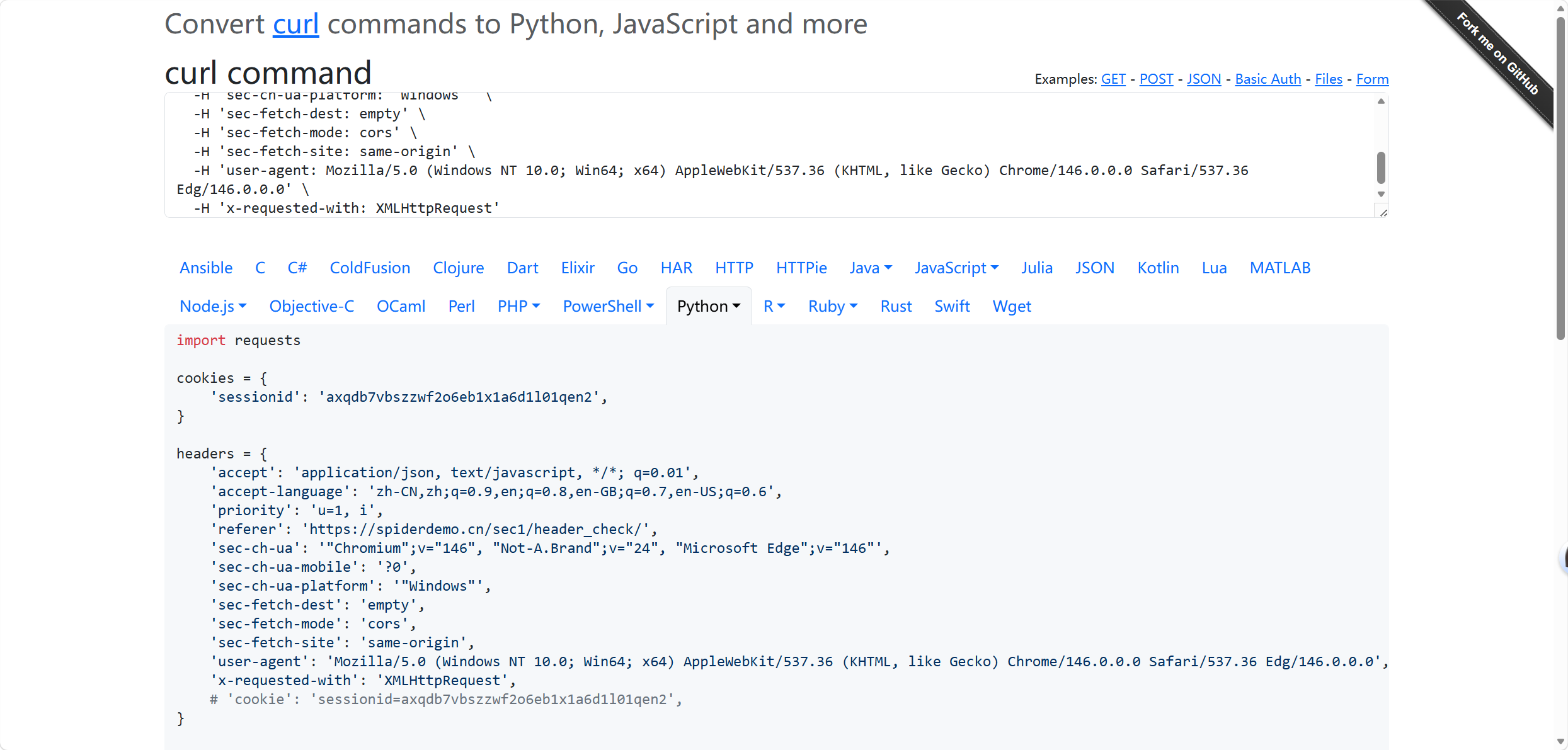
技巧二:
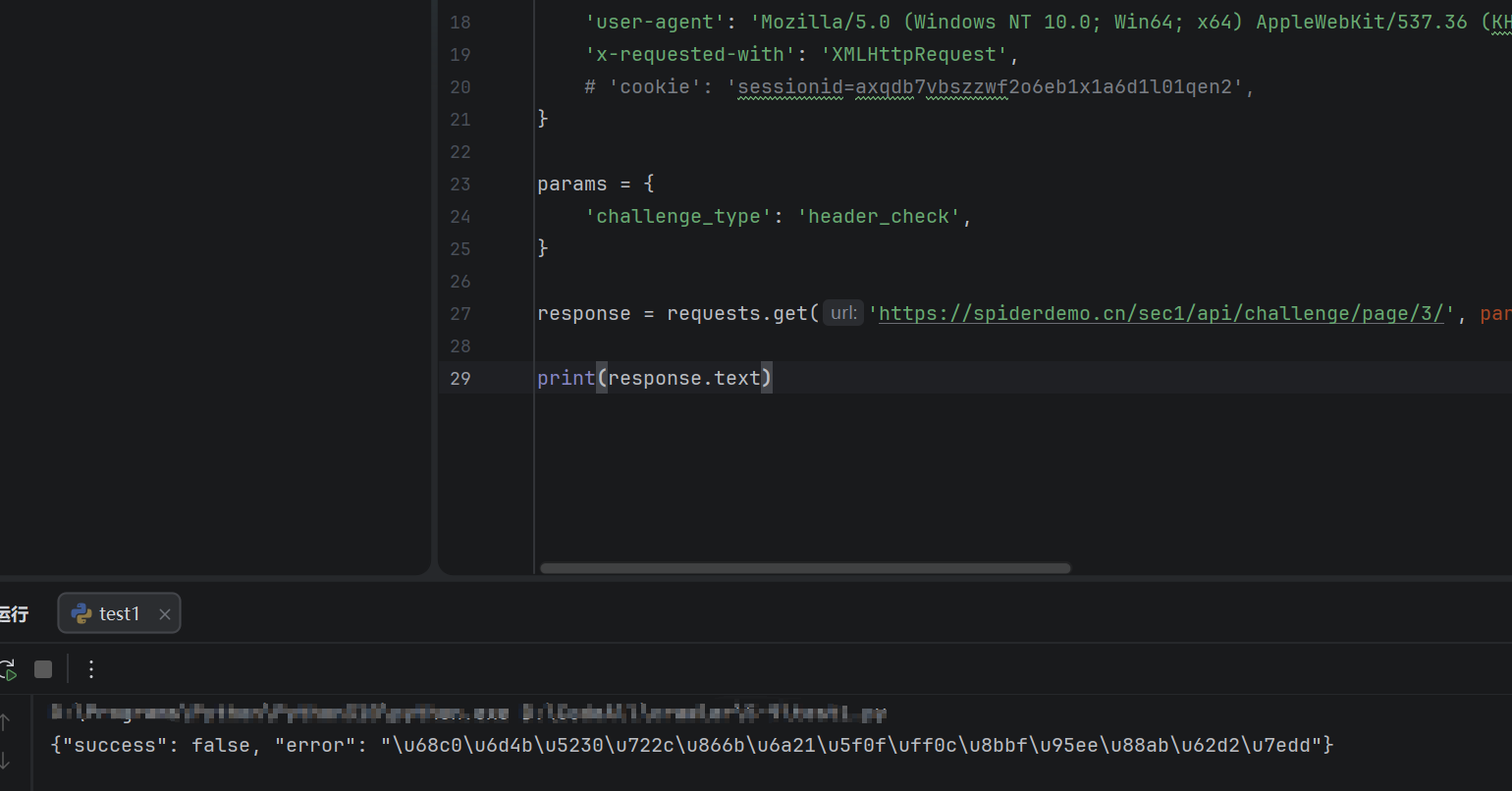
但是是失败的,这里我们有一个看结果的技巧,我们发现结果是unicode编码,而且是json格式,我们就可以看到编码后的汉字了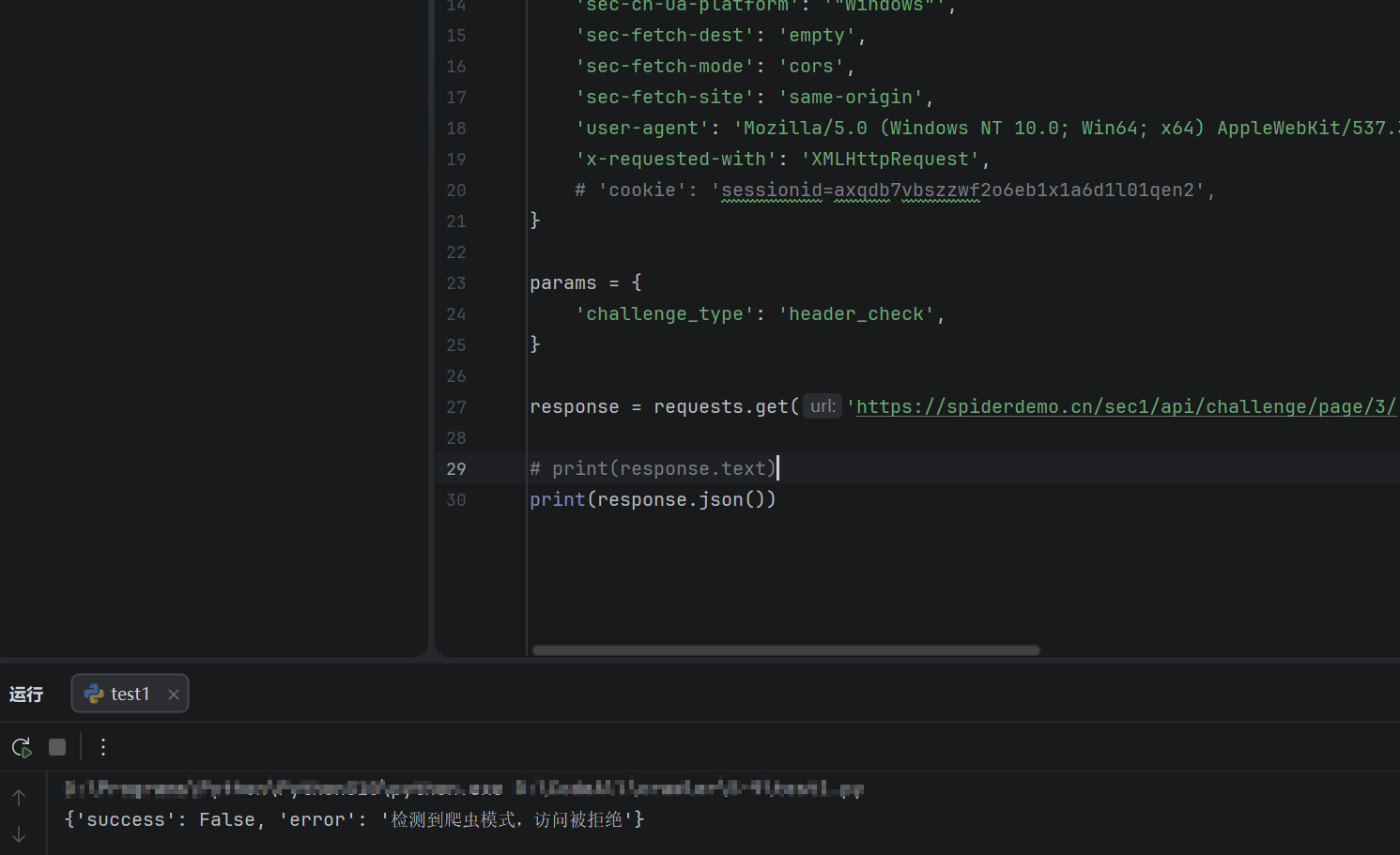
原理:
- response.text - 原始文本
返回服务器响应的原始字符串内容
如果服务器返回的是 Unicode 转义序列(如 \u68c0\u6d4b),它会原样显示
这是 JSON 格式的字符串表示,还没有被解析
- response.json() - 解析后的 Python 对象
使用 json 模块解析响应内容
自动将 Unicode 转义序列(\uXXXX)解码为对应的中文字符
返回 Python 字典/列表等数据结构
扩展:response.text 和 response.json () 区别 & 使用场景
一、对比表格
| 方式 | 返回类型 | 原理 | 适用场景 | 优缺点 |
|---|---|---|---|---|
response.text |
字符串 str |
把响应原始报文按编码解码成普通文本 | 1. 返回 HTML 网页2. 返回纯文本 / 普通字符串3. 不确定返回格式,只想看原始内容4. 接口不是标准 JSON | 通用不报错,不能直接点键取值,要自己字符串处理 |
response.json() |
Python 字典dict/ 列表list |
自动把响应文本loads 反序列化成 JSON 对象 | 1. 接口明确返回 标准 JSON 2. 需要读取里面字段:success/error/data 等 |
直接取值方便;非 JSON 会直接抛解析异常 |
二、一句话总结
只要接口返回标准 JSON、需要拿里面字段,就用 response.json();返回网页 HTML、纯文本,或者不确定格式怕报错,就用 response.text。
3.让代码成功运行
为什么浏览器可以正常运行,但是之前管用的爬虫现在也报错了
原因:因为这样子的cookie的传递和浏览器有区别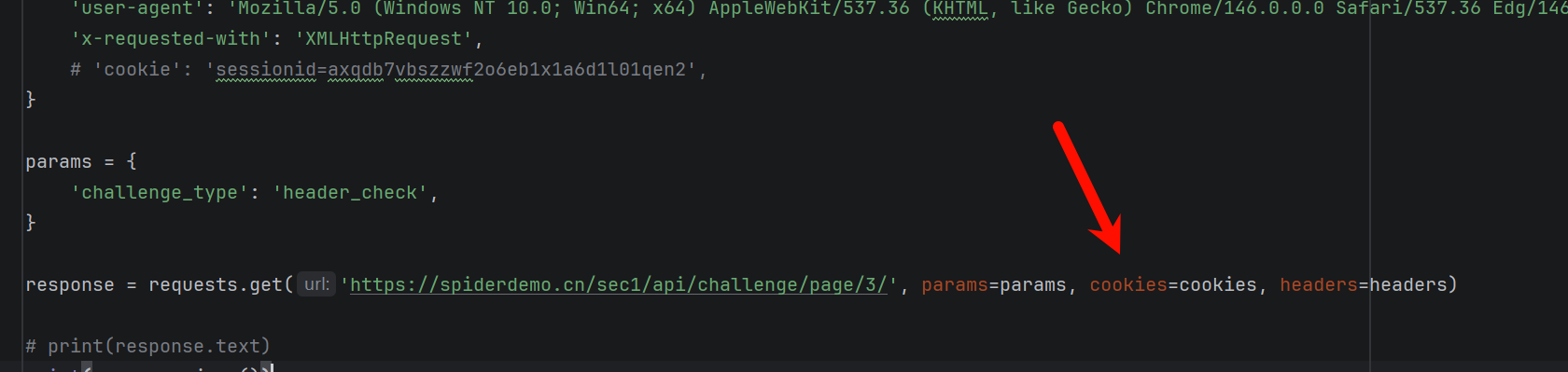
解决方法1:

添加,并在调用时候调用session
python
session = requests.Session()
session.headers.clear() # 清空默认头解决方法2:
修改requests库:
python
from curl_cffi import requests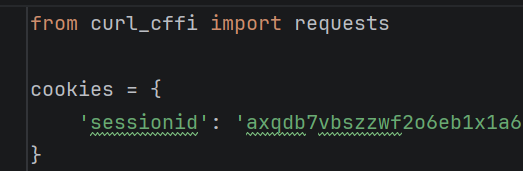
其他都不修改,即可成功
4.循环获取100个数字
python
from curl_cffi import requests
cookies = {
'sessionid': 'axqdb7vbszzwf2o6eb1x1a6d1l01qen2',
}
headers = {
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'priority': 'u=1, i',
'referer': 'https://spiderdemo.cn/sec1/header_check/',
'sec-ch-ua': '"Chromium";v="146", "Not-A.Brand";v="24", "Microsoft Edge";v="146"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/146.0.0.0 Safari/537.36 Edg/146.0.0.0',
'x-requested-with': 'XMLHttpRequest',
# 'cookie': 'sessionid=axqdb7vbszzwf2o6eb1x1a6d1l01qen2',
}
params = {
'challenge_type': 'header_check',
}
all_page_data = []
for page_num in range(1, 101):
url = f'https://spiderdemo.cn/sec1/api/challenge/page/{page_num}/'
response = requests.get(url, params=params, cookies=cookies, headers=headers)
response_data = response.json()
page_data = response_data.get('page_data', [])
all_page_data.extend(page_data)
print(f"第 {page_num} 页: 提取到 {len(page_data)} 条数据")
print(f"\n总共提取到 {len(all_page_data)} 条数据")
print("\n所有提取的数据:")
a=0
for i, data in enumerate(all_page_data, 1):
print(f"{i}. {data}")
a=a+data
print(a)