在日常业务开发中,我们经常会遇到逻辑极其复杂的报表需求。为了在一个 SQL 里算出结果,开发人员往往会写出嵌套了三四层 SELECT 的"子查询地狱"。这种 SQL 当时能跑通,但一个月后连作者自己都看不懂,一旦业务逻辑变更,修改起来极易引发线上故障。
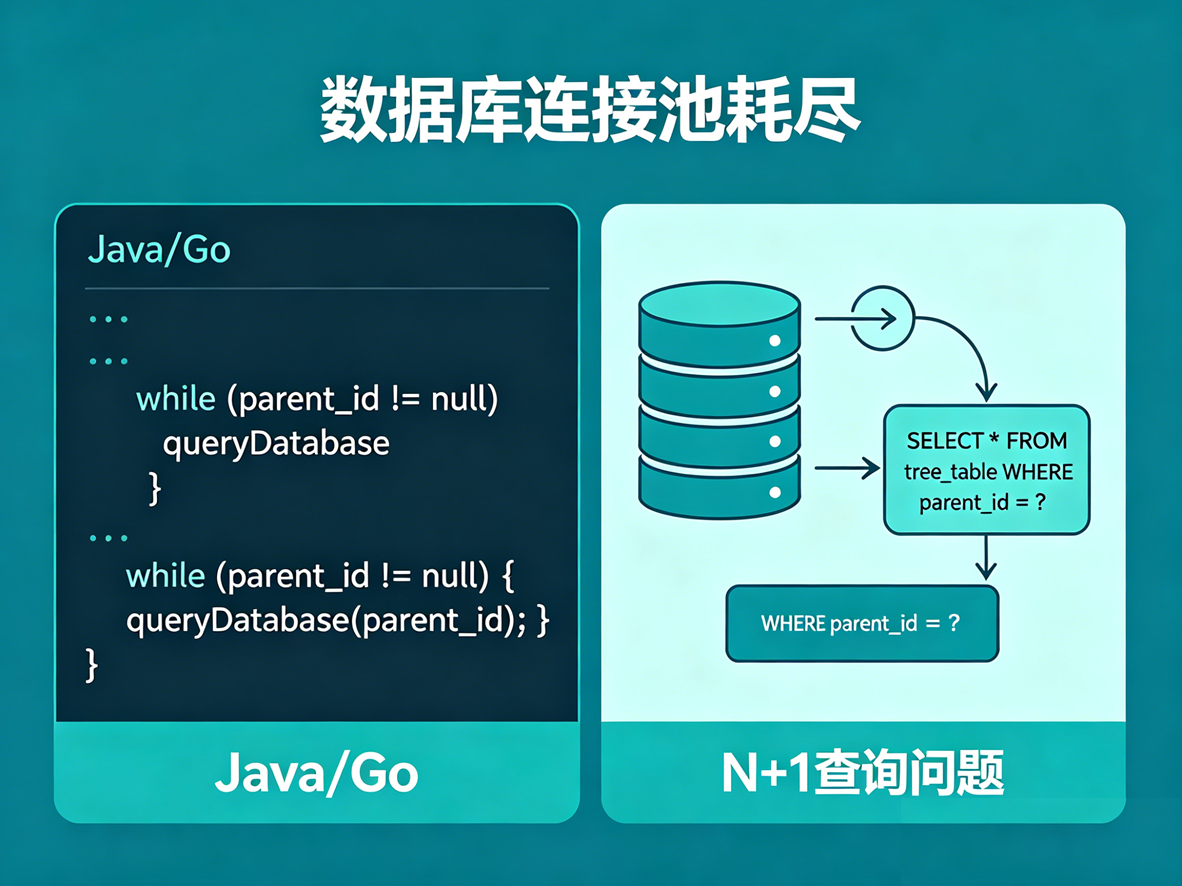
另一方面,面对"省-市-区"或"部门-子部门"这种无限层级的树形结构,很多人的做法是在 Java/Go 代码里写 while 循环,根据 parent_id 不断向数据库发起查询。这会引发严重的"N+1 查询问题",瞬间耗尽数据库的连接池。
其实,利用现代关系型数据库的公用表表达式(CTE,Common Table Expressions) ,这两个痛点都可以被优雅地解决。本文将直接演示如何使用 WITH 语句来重构 SQL。
一、 什么是 CTE?
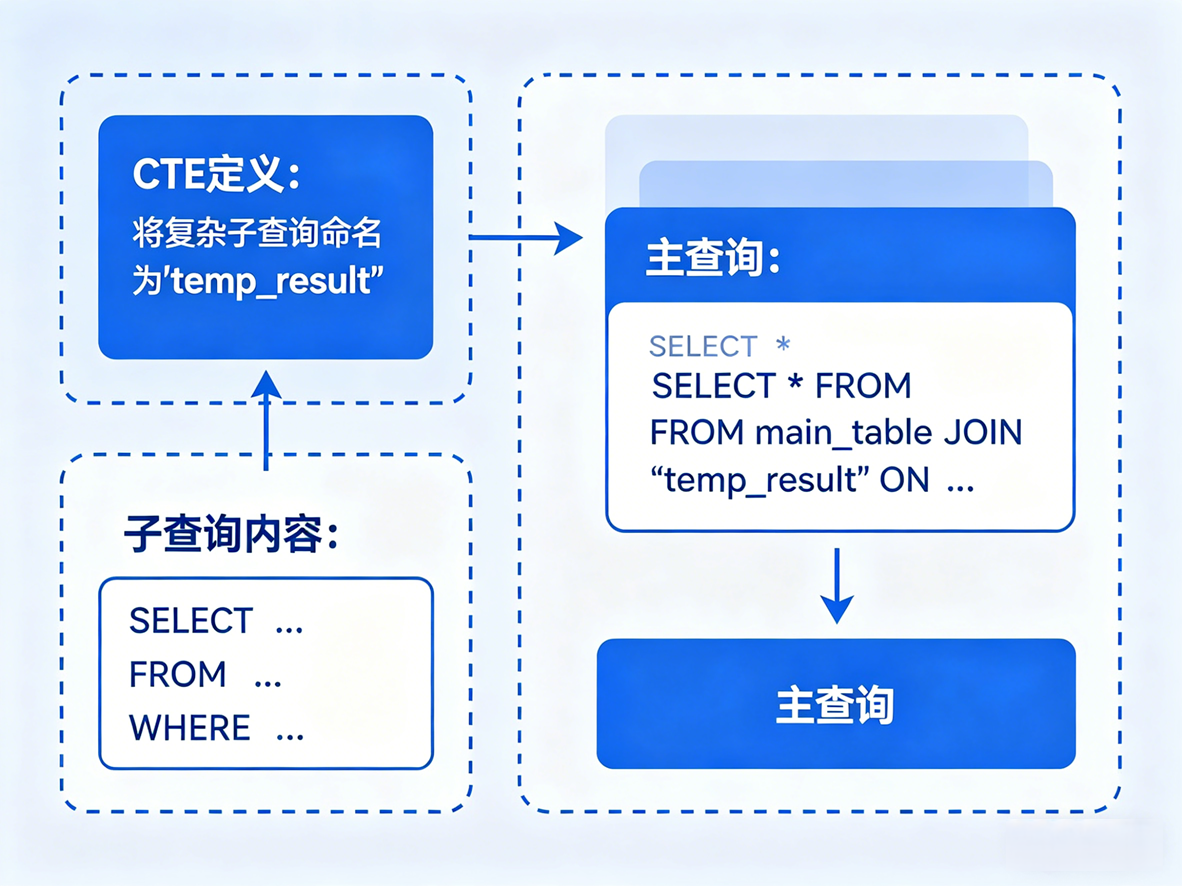
CTE 可以被看作是一个临时的、只在当前查询中生效的视图 。 在编程语言中,如果一段逻辑太复杂,我们会把它抽离成一个方法,或者赋值给一个局部变量。CTE 在 SQL 中的作用完全一样:它允许你将复杂的子查询定义为一个具名的临时结果集,然后在主查询中像查普通表一样去 JOIN 它。
二、 实战场景 1:用普通 CTE 展平嵌套子查询
需求说明: 查询出 employee 表中,平均薪资高于全公司平均薪资的部门及其具体平均薪资。
表结构参考: employee (id, emp_name, department_id, salary)
传统解法(子查询嵌套): 这段逻辑读起来非常反直觉,因为阅读顺序是从内向外的。
SELECT
department_id,
AVG(salary) AS dept_avg_salary
FROM employee
GROUP BY department_id
HAVING AVG(salary) > (
SELECT AVG(salary) FROM employee -- 嵌套子查询:全公司平均薪资
);使用 CTE 解法: 使用 WITH 关键字,我们可以将计算过程拆解为从上到下的线性逻辑。
WITH
-- 步骤 1:计算全公司的平均薪资,存入临时表 company_avg
company_avg AS (
SELECT AVG(salary) AS global_avg FROM employee
),
-- 步骤 2:计算每个部门的平均薪资,存入临时表 dept_avg
dept_avg AS (
SELECT department_id, AVG(salary) AS dept_avg_salary
FROM employee
GROUP BY department_id
)
-- 主查询:将两个临时表关联过滤
SELECT
d.department_id,
d.dept_avg_salary
FROM dept_avg d
JOIN company_avg c ON d.dept_avg_salary > c.global_avg;工程价值: 虽然对于这个简单的例子,子查询也能应付。但当你的报表需要汇总订单、库存、财务三张底表的数据时,CTE 能让你的 SQL 像结构化代码一样,模块清晰,极大地降低了后期的维护成本。
三、 实战场景 2:用递归 CTE 一次性拉取树形结构
需求说明: 有一张员工组织架构表,每个员工都有一个上级(manager_id)。现在要求查出"张三(ID=100)"的所有下属,包括直接下属、下属的下属,一直到底。
表结构参考: org_structure (emp_id, emp_name, manager_id)
传统解法的灾难: 应用层先 SELECT * WHERE manager_id = 100 查出第一层,然后在 Java 里遍历这批 ID,再发起几十个 SELECT 去查第二层。网络 I/O 开销极大。
使用 WITH RECURSIVE 解法: 只需向数据库发送一次请求,利用递归 CTE,让数据库引擎在底层完成树的遍历。
WITH RECURSIVE sub_employees AS (
-- 1. 锚点成员(Base Case):先查出递归的起点(张三本人)
SELECT
emp_id,
emp_name,
manager_id,
1 AS level -- 标记层级
FROM org_structure
WHERE emp_id = 100
UNION ALL
-- 2. 递归成员(Recursive Step):用起点去查下一层,循环往复
SELECT
o.emp_id,
o.emp_name,
o.manager_id,
c.level + 1 -- 层级递增
FROM org_structure o
INNER JOIN sub_employees c ON o.manager_id = c.emp_id -- 注意:这里 JOIN 了 CTE 自身
)
-- 3. 主查询:输出完整的树形结果集
SELECT * FROM sub_employees;原理解析: 递归 CTE 包含两部分,由 UNION ALL 连接。
-
数据库首先执行锚点部分,查出顶级节点。
-
然后,数据库将锚点的结果代入递归部分 ,通过
INNER JOIN找到所有的子节点。 -
接着,把刚找到的子节点再次代入递归部分,寻找孙子节点。一直重复,直到再也 JOIN 不出新数据为止,递归结束。
四、 总结
抛弃难以阅读的嵌套子查询,停止在业务代码里写低效的数据库轮询。
-
对于复杂报表: 用标准 CTE(
WITH)把大 SQL 切割成具有业务语义的小模块。 -
对于树形结构(菜单栏、组织架构、评论盖楼): 用递归 CTE(
WITH RECURSIVE)代替应用层的for循环,彻底根除 N+1 查询问题。
执行前置条件: 与窗口函数一样,CTE 属于较新的 SQL 规范。请确保生产环境为 MySQL 8.0+ 或 PostgreSQL。对于旧版数据库,树形结构查询依然需要依赖自建路径字段(Path Enumeration)或左右值编码(Nested Sets)等复杂的表结构设计来绕过。