机器人行业一直是一个高度确定性的领域。它要求高精度、强同步能力,以及通常运行在千赫兹频率上的控制循环。AI 当然也曾经参与到机器人系统中,但更多时候只是作为一个附加模块存在。过去的典型做法,往往依赖手工调试的感知算法、脆弱的状态机,以及只能在严格受控环境下工作的运动脚本。
但一旦进入真实世界,这套方式很快就会暴露问题。
这正是 Physical AI 受到关注的原因:我们需要的是能够从数据中学习、融合感知与动作,并且以足够快的速度闭环运行的系统。机器人开发的重心,正在从"手写机器人行为逻辑",转向"构建能够持续训练、持续适应、持续部署的工作流"。因为任务会变化,环境会变化,真实世界的约束也会变化。
这也是 Physical AI Studio 的价值所在。
Physical AI Studio是一个端到端框架,旨在通过人类演示和模仿学习来训练机器人。它同时提供 GUI 应用、Python API 和 CLI 接口,并覆盖从演示数据录制到机器人部署的完整流程。其应用文档涵盖了机器人与摄像头设置、数据集采集、模型训练以及面向部署的工作流。

在这系列第一篇文章中,我们不会一上来就讨论数据集或者策略模型名称。因为这并不是大多数开发者真正开始的地方。当你第一次坐在机器人机械臂前,最直接的问题其实是:
我该如何把机器人、摄像头和平台正确连接起来,从而开始采集可用于训练的演示数据?
这正是本文要解决的问题。
下面的流程参考了应用指南中基于 SO-101 的遥操作路径:创建项目、设置机械臂、添加摄像头、定义环境,然后采集演示数据。
Step 1 :启动 Physical AI Studio
在进行标定或遥操作之前,第一步是把应用跑起来。
Physical AI Studio 提供了两种便捷的启动方式。对于希望最快运行完整应用的开发者,可以按照应用README 中推荐的 Docker 方式启动。如果你希望更贴近代码进行开发,也可以使用原生开发模式:后端通过 uv 运行,前端通过 Node.js 构建。
用户指南中也提供了更详细的硬件要求说明,包括如何在搭载 Intel® Core™ Ultra 的系统上利用内置 GPU 加速,或者在配备独立 Intel® Arc™ 显卡的平台上运行 Physical AI Studio。整体设置体验保持一致。
如果你希望最快启动完整应用,可以从 Docker 开始:
git clone https://github.com/open-edge-platform/physical-ai-studio.gitcd physical-ai-studio/application/dockercp .env.example .envdocker compose --profile xpu up可用的 profile 包括:
--profile xpu--profile cuda--profile cpu启动后,Docker 模式下的应用运行在:
http://localhost:7860如果你希望以原生开发模式运行,需要先启动后端,再启动前端 UI:
cd application/backenduv sync --extra xpu # or --extra cpu / --extra cuda./run.sh然后在另一个终端中启动 UI:
cd application/uinvm usenpm installnpm run build:api:downloadnpm run build:apinpm run start在原生开发模式下,后端运行在:
http://localhost:7860前端 UI 运行在:
http://localhost:3000这一步看起来只是基础环境启动,但它比表面上更重要。Physical AI Studio 的一个核心优势,就是为早期机器人 AI 工作流提供了统一的应用入口。你不需要在彼此割裂的脚本和工具之间来回切换,而是可以从同一个地方开始,一步一步推进整个流程。
这会让后续所有步骤都更容易。
Step 2 :在操作机器人之前,先创建一个项目
应用启动后,下一步是创建一个 Project。
Physical AI Studio 会把机器人问题组织成项目。每个项目都对应某个具体问题,并包含该问题相关的数据集和模型。这看似是一个小设计,但非常重要。它会促使你在一开始就定义任务边界,而不是从第一天起就把演示数据随意散落在各种临时文件夹中。
在实际使用中,一个项目可以代表:
- 桌面 pick-and-place 任务
- 两个盒子之间的物体转移任务
- 简单的物体分类或分拣任务
关键在于,这个项目会成为后续所有内容的容器:环境配置、录制的演示数据,以及后续训练出的策略模型。
这让整个工作流从一开始就有了清晰的中心。

Step 3 :设置机械臂 ------ 这才是真正动手实践的开始
对于开发者来说,这一步才是真正的开始。
不是数据采集。
不是模型训练。
也不是 benchmark 测试。
第一个真正动手的环节,是让机器人机械臂在平台中被正确识别、标定并验证。
应用指南之所以从机器人设置开始,是有原因的。在录制数据集和训练模型之前,你首先需要搭建环境,而这个环境由机械臂和摄像头组成。以 SO-101 为例,推荐的流程是:先添加 follower 机械臂,分配电机 ID,完成机械臂标定,验证运动是否正确,保存机器人配置,然后对 SO-101 leader 机械臂重复同样流程。
3.1 添加 follower 机械臂
应用流程从 follower 机械臂开始。根据指南,你需要为机器人命名,选择机器人类型为 SO101 Follower,选择正确的串口设备。如果你不确定哪个 serial ID 对应哪台机器人,可以使用 identify 功能。该功能会通过打开和关闭夹爪来帮助你确认设备。
这个小小的 identify 功能值得特别强调。在真实硬件工作流中,哪怕只是连接设备的歧义,也很容易浪费大量时间。一个好的上手体验,应该尽量减少这种摩擦,而这正是一个很实际的例子。
3.2 分配电机 ID
对于 SO-101,下一步是电机设置。
SO101 的舵机采用串联方式连接,因此每个舵机都需要分配对应的 ID。这样系统才能知道每个电机属于哪个关节。整体模式很简单:将某一个指定舵机连接到控制板,为它分配 ID;然后对每一个电机重复这个过程;最后重新连接所有电机,并在继续之前完成验证。
这并不是机器人 AI 中最"酷"的部分,但却是最重要的部分之一。
如果一篇技术文章跳过电机映射这类步骤,它就会变成一篇"看起来很美"的宣传文章,而不是一篇真正可操作的教程。Physical AI Studio 展示的是实际工作流,而不仅仅是被包装过的漂亮部分。
3.3 标定机械臂
标定,是硬件设置真正变得可信的地方。
SO-101 的标定流程要求机器人了解其根位置以及舵机运动范围。UI 引导的步骤包括:将机械臂移动到显示的运动范围中心位置,应用 homing offsets,依次移动每个关节通过其完整运动范围,然后完成记录。
这是物理机器人和数字表示开始对齐的时刻。
这种对齐的重要性远超"设置"本身。在机器人模仿学习中,今天糟糕的标定,会变成明天糟糕的数据。
3.4 继续之前,先完成验证
标定完成后,需要仔细验证运动是否正确。
用户需要移动机器人关节通过完整运动范围,并确认 UI 中显示的运动与物理机械臂的实际运动一致。如果显示结果与真实运动不一致,就需要回到标定步骤重新处理,然后再保存机器人配置。
完成 follower 机械臂后,需要对 SO101 Leader 机械臂重复相同流程。
这个验证步骤值得在文章中特别强调,因为它不只是一个 checklist 项。
它是整个流水线中的第一个质量门。
一次糟糕的标定不会停留在标定阶段。它会继续影响遥操作质量、演示数据质量,并最终影响模型质量。
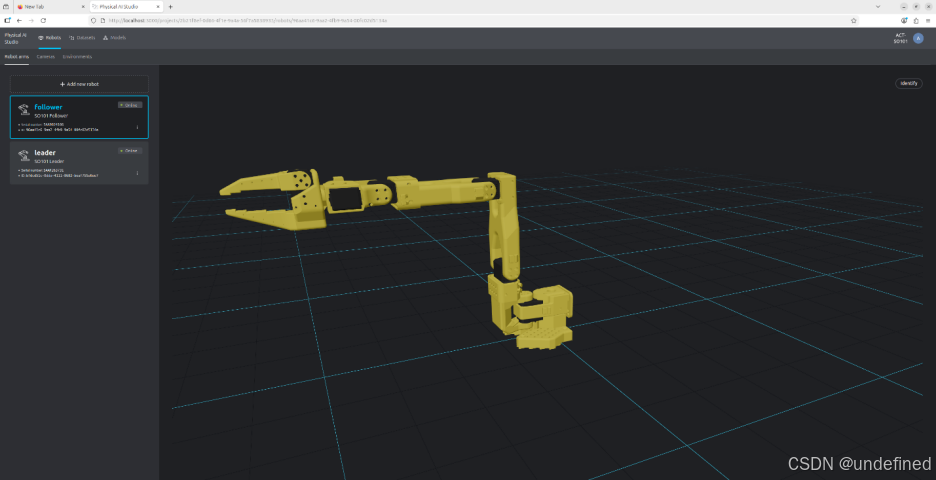
Step 4 :添加后续策略模型会依赖的摄像头
机械臂设置完成后,下一步是感知。
应用指南中的摄像头设置非常直接:添加一个新的 USB 摄像头,为其命名,选择设备,设置分辨率和 FPS,预览视频流,然后添加摄像头。对于机器人需要的所有视角,都重复这个过程。
这里的重点并不是追求某种"完美通用"的摄像头布局,而是选择那些在后续训练和调试策略模型时依然有意义的视角。
对于许多桌面操作任务来说,这通常意味着:
-
一个更宽的场景视角,用于观察任务整体上下文
-
另一个角度,用于理解运动过程
-
有时还需要一个更局部的视角,用于观察精细操作
在我们的案例中,我们在场景中使用了三个 USB 摄像头。第一个摄像头安装在桌面上方,用于提供整个桌面工作区的全局视角;第二个摄像头安装在 follower 机械臂上,用于捕捉物体和夹爪交互过程中的近距离视角;第三个摄像头放置在桌面上,用于观察 pick-and-place 过程中机械臂相对于桌面的高度,这可以帮助捕捉那些仅靠俯视视角难以看到的运动细节。
因此,摄像头设置并不是一个附属步骤。
它已经是模型设计的一部分。
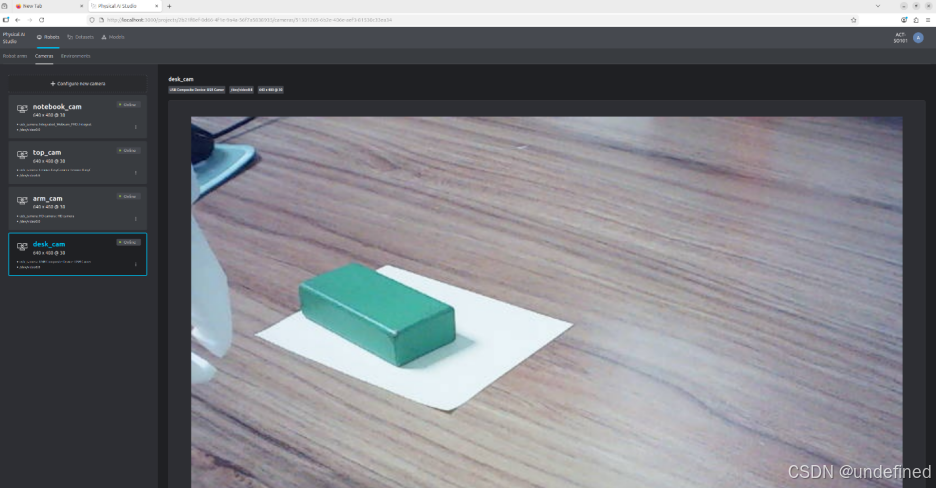
Step 5 :定义把所有组件连接起来的环境
到目前为止,你已经分别配置了:
-
follower 机械臂
-
leader 机械臂
-
摄像头视频流
现在,需要把它们绑定成一个真正可用的工作设置。
这就是 Environment 的作用。
Environment 会定义机器人和摄像头,并且会在数据集中用于确定模型的输入特征。其工作流包括:创建新的 environment,选择 follower,选择 leader,添加摄像头,预览设置,实时验证机器人,然后添加 environment。
这一点非常关键。Environment 不只是应用中的一个方便配置项。它会成为数据和模型之间契约的一部分。换句话说,你现在如何定义 environment,会直接决定数据集中包含什么,以及后续模型会期待什么样的输入。
这一步也会让系统不再抽象。在此之前,你配置的是一个个独立组件。而在这里,你定义的是后续数据采集所依赖的完整遥操作组合。
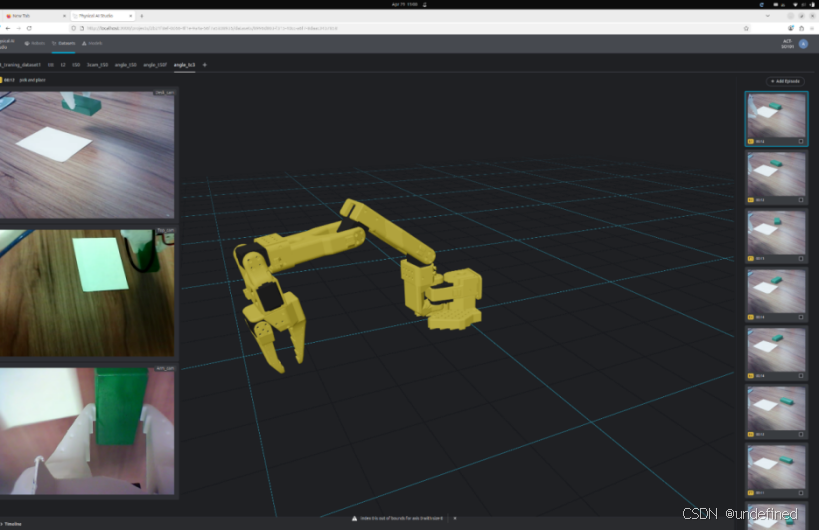
Step 6 :录制第一批演示片段
直到现在,才真正到了采集数据的时刻。
这个顺序很重要。
一篇文章如果一上来就说"录制数据集",就会跳过开发者必须先完成的真实工作。但当应用已经启动,机器人已经标定,摄像头已经在线,environment 已经定义好,那么数据采集就是顺理成章的下一步。
应用会把这个过程分成三部分:创建新的数据集并选择 environment,为任务开始录制,然后启动一个 episode。文档中也提到,所选择的 environment 会决定数据集特征;如果多个 environment 具有相同特征,也可以一起使用。
对于每个 episode,推荐流程包括:验证 leader 运动,检查场景光照,重置环境,启动 episode,执行动作,然后接受或丢弃该次演示。
一个干净的初始数据集,是通过一次次经过判断的演示片段建立起来的。
即使是在第一次数据采集阶段,也有一个原则值得记住:
不要只录制成功。要录制变化。
仓库文档本身没有明确写出这句话,但这是任何基于真实场景演示数据的模仿学习工作流中非常自然的实践结论。如果每个 episode 中物体都处在同一个位置、同一种光照、同一种运动模式下,策略模型可能很快学会,但在真实环境中仍然很脆弱。
物体方向、位置以及场景条件中的小变化,才会让模型有机会学习到更好的泛化能力。
这是从整个工作流中得到的实践推断,而不是对仓库文档的直接引用。
总结
这就是我们在第一篇文章中想要分享的内容,因为它遵循的是开发者进入机器人 AI 的真实路径。
你不是从模型导出开始。
你不是从 benchmark 开始。
你也不是从抽象意义上的"数据采集"开始。
你是从启动应用、创建项目、标定机器人、验证系统、添加摄像头、定义 environment,然后录制第一批被接受的演示数据开始。
这个顺序,正是把一个"看起来很有意思的机器人框架",变成一个"开发者真的可以用起来的工具"的关键。
一旦你拥有了:
-
已完成标定的 leader 和 follower 机械臂
-
已验证的视频流
-
已定义好的 environment
-
以及第一批被接受的演示 episode
下一个问题就自然出现了:
我们如何把这些演示数据转化成一个可训练的策略模型,并为真实推理做好准备?
这就是下一篇博客要开始的地方。敬请关注------在下一篇文章中,我们会把工作流从录制好的 episode 推进到策略模型训练,并进一步走向真实部署。
更多资源