3360
就是说对于i,前面的元素j<i,如果j的值比i大,那么i可达j
对于i后面的元素j>i,如果j的值比i小,那么i可达j
如果要求i每个位置所能达到的最大值,那么前面存在比i大的值,那么i一定可以取到
所以一种情况是max(nj,j<i)
然后对于比i小的后面的数,就是看那些值,是否存在能到达的更大距离,假设这些位置是k
由于k对应的值小于i,所以i能到达前面的最大值,k也一定能取到
但是i,k之间的值,如果存在比i大的,那么I取不到,k能取到
所以如果有一个数组设为a,来维护ai表示i之前的最大值
那么i所对应的最大值就是,max(ai,ak,k为i所有可达的后面的点)
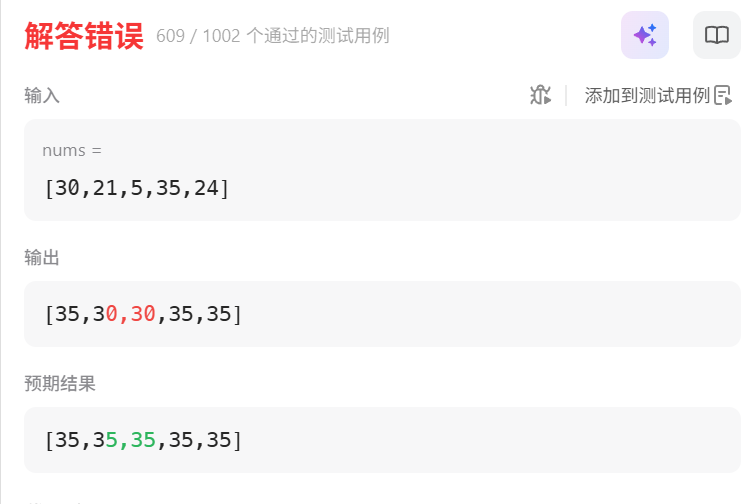
这个思路没过一些点,就是说因为能无限跳跃,之前是只考虑了右边比自己大的处理
对于左边,也可能存在它们能到但自己到不了的情况
所以取的应该是它们的res最大值
但如何证明合法性?
事实证明并不合法,不是正确的
先实现ON^2级别的
即对于每个位置i,都向后遍历去查找那些比它值小的位置,
然后进行比较
class Solution {
public:
vector<int> maxValue(vector<int>& nums) {
int n=nums.size();
if(!n){return {};}
vector<int>pre(n),res(n);
pre[0]=nums[0];
for(int i=1;i<n;i++){
pre[i]=max(pre[i-1],nums[i]);
}
int max_tmp=pre[0];
for(int i=0;i<n;i++){
res[i]=max(max_tmp,nums[i]);
for(int j=i+1;j<n;j++){
if(nums[j]<nums[i]){res[i]=max(res[i],pre[j]);}
}
max_tmp=max(max_tmp,res[i]);
//cout<<"max_tmp: "<<max_tmp<<" nums[i]: "<<nums[i]<<" i:"<<i<<endl;
}
return res;
}
};丑陋地修改后,还是有一些没过
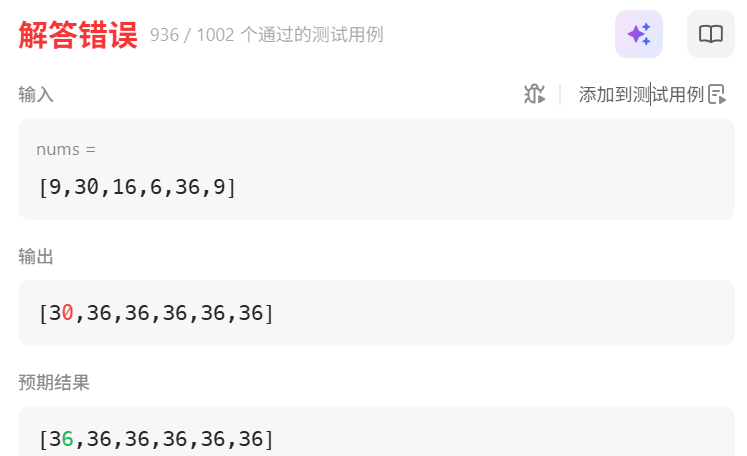
并不是第一个9到了最后一个9,然后取到了36
这个输出应该是因为,对于30,它能到最后的9,然后最后的9能到36,所以30能取到9
然后到6时,能到30,所以6也能到36
然后对于第一个9,能到6,所以也能到36
所以出错就是因为9的res确定太早了,就是前面数值的res确定可能还取决于后面的res
第一次看每个数据右侧的点,能否到达
假设当前数据i,他能到达的右侧数据点j,可以将序列分为a i, b j c
如果resA在a中,i可以直接取到
如果在b中,i取不到,但j可以取到
如果在c中,ij目前都取不到,这就是目前遗漏的情况,实际上是有可能的
假设在a中存在x,x>i;对于x,在c中存在d满足x>d且d>i>j
那么目前可进一步拆分为e x f i b j g d h
那么x可达d,进而可达i和j到不了的c中的g区域,如果g区域当中存在数据满足>d,而且还都大于前面的元素,那么就会被i所遗漏
即原来路径是i->j,到不了c
现在是i->x-,x在a中->d
这个更新,用到的不是i前的最大值,而是i前的数据所能达到的最大值
那或许不应该记录最大值,而是直接记录答案,即所能达到的最大值
不对,上面的只是其中一种反例
还可以存在i->y,y在b中->z
如果这样的话,用的就不是i前面的最好结果,而是用到了后面元素的最好结果
问题的关键在于,应当确定一个正确的res赋值顺序
它们之间显然存在依赖关系
最先被确定的应该是序列当中的最小值,也不一定
真正不依赖它值的应该是最大值
之后就可以把最大值右侧的所有答案都确定为max
那左侧的该如何处理?
我觉得应该就可以用上面的算法了,但是也不保证正确性,无法证明,相当于在原来的基础上加了个预处理
还是不行,因为没改变一种情况的路径;上面预处理没必要,因为pre就已经干了
确定了max后
先处理右侧,收集其中的值,假设为x
然后对于每个x,去找max左侧里所有比他大的值,这样x可达它,那么它也可以为max,设它为y
那么继续检测y左侧里所有比y大的值,不必要,因为y>x,如果都大于y了,那么一定也大于x,那么x肯定可达,所以左侧的情况x都处理了;
那右侧的?应当是那些比x小的值,它们x不可达,但是它们可达y
想不明白了,就算想明白了,以我现在的想法,肯定是嵌套了很多的条件判断,但我感觉正解肯定不会是这样的
如果用并查集?就是两个点之间如果能可达,就union一下,就是先构造一遍树,然后最后再输出每个节点所在树的最大值
那并查集的根应当维护的是最大值
那么在union时,就应该是判断两个节点、或者节点的根节点中的最大值来当根
没错,就是这样,联通的话就是在一个并查集下
一开始为了保证正确性,严格按照规则来,然后发现超时了
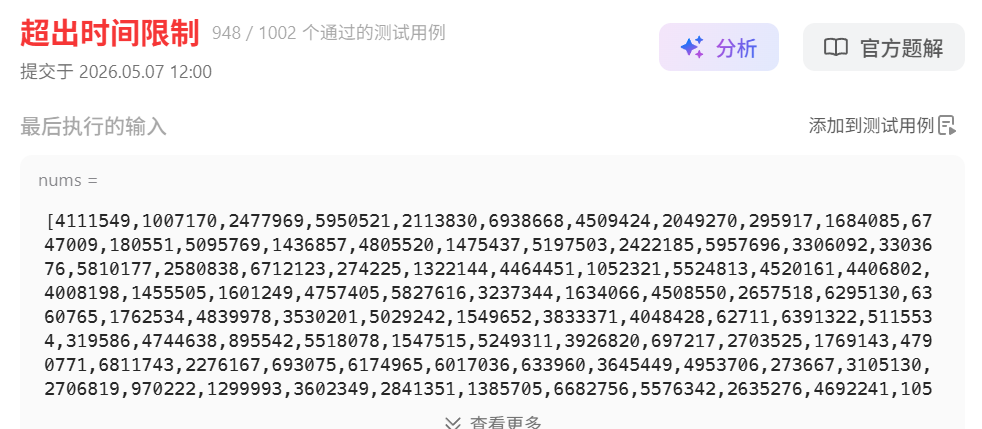
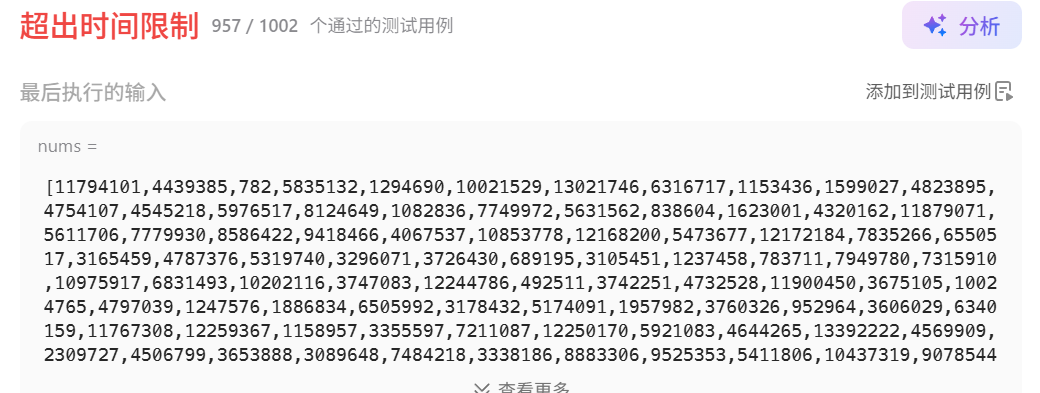
class Solution {
public:
vector<int> maxValue(vector<int>& nums) {
int n=nums.size();
if(!n){return {};}
vector<int>p(n),res(n);
//v=nums;
for(int i=0;i<n;i++){
p[i]=i;
//cout<<p[i]<<" ";
}
function<int(int)> find=[&](int x){
//cout<<x<<endl;
if(x==p[x]){return x;}
p[x]=find(p[x]);
return p[x];
};
function<void(int,int)>unite=[&](int x,int y){
int xr=find(x),yr=find(y);
if(nums[xr]>=nums[yr]){
p[yr]=xr;
}else{
p[xr]=yr;
}
};
for(int i=0;i<n;i++){
for(int j=i+1;j<n;j++){
if(nums[j]<nums[i]){unite(i,j);}
}
// for(int j=i-1;j>=0;j--){
// if(nums[j]>nums[i]){unite(i,j);}
// }
}
for(int i=0;i<n;i++){
res[i]=nums[find(i)];
}
return res;
}
};然后感觉第二条规则也没必要,因为这个点前如果存在比他小的,那么在遍历那个点时,也一定处理过,把自己纳入到它的并查集里去了
不过即使去掉它,复杂度依然是on^2,没变,
怎么优化复杂度?