1. 背景知识
1.1 Milvus简介
**1)作用上:**开源向量数据库,专门存AI向量、做相似度检索(图片 / 文本 / RAG)。
-
单机版:自己玩、测试
-
分布式版:企业生产用、拆成很多组件
**2)语言上:**使用 Go 和 C++ 编写,并使用了cpu/gpu加速。
3)架构上: 原生K8s支持,水平扩展。
4)开源协议上: Apache 2.0许可证。
**5)性能上:**在大多数情况下,Milvus 的性能是其他向量数据库的 2-5 倍(自说)
Milvus分布式本身就是微服务架构,它不是单体程序,而是由很多独立组件组成,且每个组件独立运行。
1.2 Milvus和 K8s关系
1)Milvus:分布式向量数据库,用来存储向量、做检索。
2)K8s(Kubernetes):容器编排平台,负责运行、管理、维护Milvus。
可以理解为:Milvus是一家公司,K8s是写字楼 + 物业 + 后勤总管
K8s给Milvus提供:
-
在哪台机器运行
-
挂了自动重启
-
不够用自动扩容
-
升级不停服
-
网络、存储统一管理
示例:跑一个Milvus分布式集群,不是直接双击运行,而是:
-
把Milvus打包成容器镜像
-
交给K8s
-
K8s自动在多台服务器上把Milvus跑起来
小结:生产环境的Milvus集群,几乎都跑在 K8s 上。
1.3 K8s和Pod关系
Pod是K8s管理的最小单位
一个Pod里面跑一个服务,比如Milvus的查询节点、MySQL、Redis等。
K8s负责:
-
创建Pod
-
销毁Pod
-
把Pod调度到服务器
-
监控Pod健康
示例:K8s相当于学校,Pod相当于班级,一个班级在同一时间只干一件事。
问:为什么在K8s上运行Milvus时,需要自动创建一堆Pod(etcd、Pulsar等)?
因为Milvus是分布式系统,本身就拆成了很多组件,每个组件必须单独运行,所以每个组件对应一个Pod。
1.4 K8s如何扩缩容
在K8s上对Milvus组件进行扩缩容,可以通过修改对应组件的 replicas(副本数),K8s会自动创建 / 删除对应Pod,Milvus自动将其加入集群 / 下线。
扩容 QueryNode示例:
bash
### 方式A: Helm(最常用)
helm upgrade my-release milvus/milvus \
--setqueryNode.replicas=5 \
--reuse-values
```{insert\_element\_1\_}
#### 方式B:kubectl scale(直接改 Deployment)
```
bashkubectl scale deployment my-release-milvus-querynode --replicas=5会看到 新的 querynode Pod 自动创建、Running、加入集群。
问:哪些组件能扩,哪些不能扩?
-
可扩缩:QueryNode、DataNode、IndexNode、Proxy
-
一般不扩:Coord 类(RootCoord/QueryCoord/DataCoord),用于高可用,通常固定 1 或 3 副本
1.5 Pod存储变更
两种存储:
1)云盘(网络存储 / 远程PVC)
-
StorageClass 如:cbs/ebs/gp3/nfs
-
跨节点可用、高可用、可迁移
-
适合:etcd、MinIO、Pulsar、持久化数据
2)本地盘(LocalPV / HostPath / EmptyDir)
-
StorageClass 如:local-path/local-storage
-
只能绑在某一台 Node、性能极高
-
适合:QueryNode 热数据缓存、临时 Segment
CSI时K8s的存储驱动标准,云厂商本地存储、分布式存储都靠CSI驱动提供PV / PVC能力。
问:什么是PV?什么是PVC?二者有什么区别?
1)**PV:**一块真实可用的存储空间,可以是云厂商的云盘(EBS/CBS/ 云硬盘),也可以是服务器本地盘(SSD/NVMe)等。它属于K8s里的资源,就像CPU、内存一样。
2)PVC: 申请磁盘,即向K8s提交一个申请,告诉K8s需要多大(100G)、什么类型(云盘 / 本地盘),读写模式等,K8s会自动找一个匹配的PV绑上去(自动创建,或自动购买云盘)。
注:Pod只跟PVC绑定,不关心磁盘在哪。即使Pod删了、重建了、漂移了,数据还在。
2. Milvus架构
Milvus 2.6是一个云原生、分布式向量数据库,采用分层解耦的架构设计,将请求接入、集群调度、数据处理与持久化分离,实现高可用、高并发与弹性扩展。
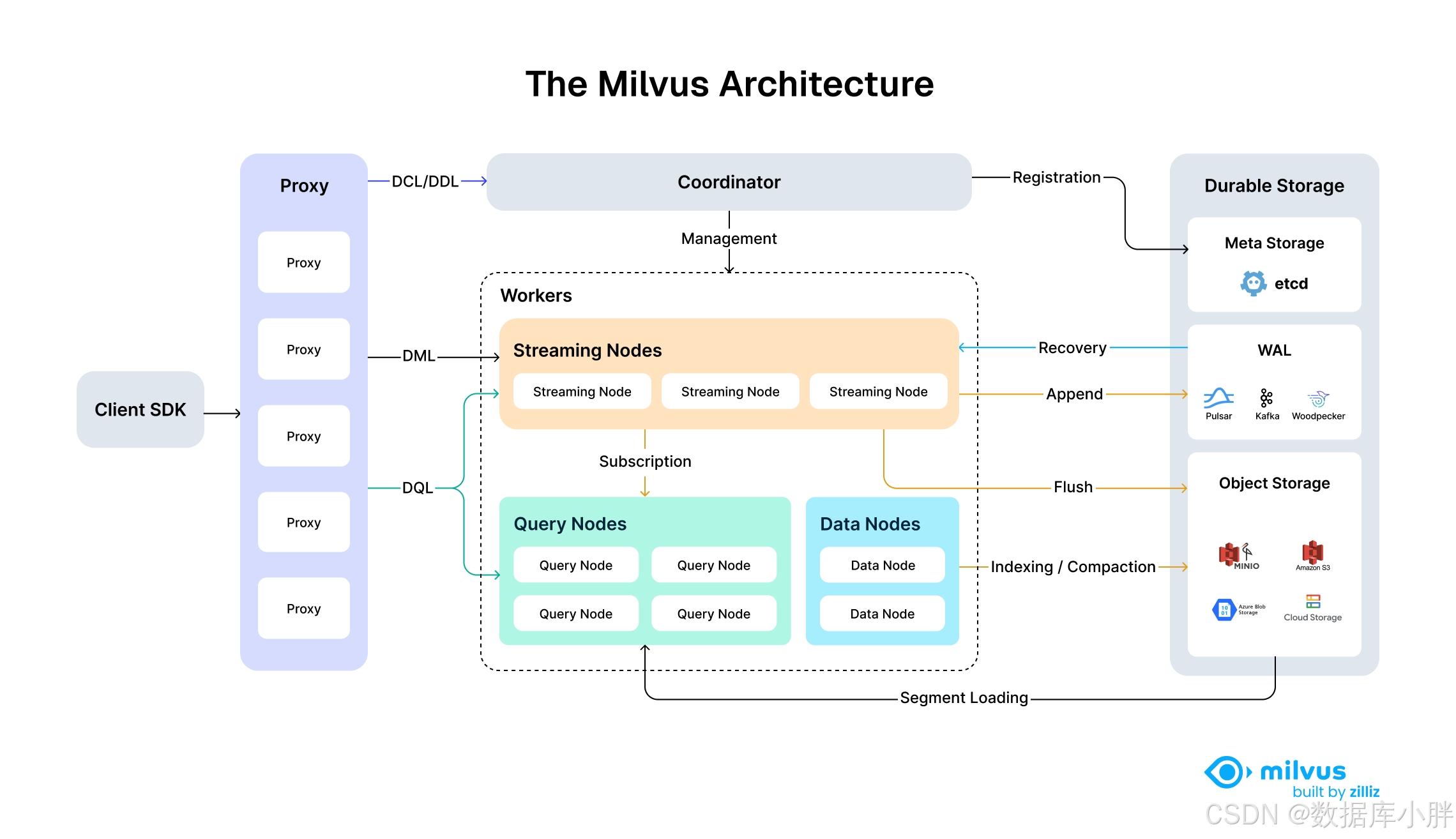
3. 模块功能详解
Milvus 2.6 架构可分为五大核心模块:Client SDK 接入层 、Proxy 代理层 、Coordinator 协调层 、Workers 工作节点层 、Durable Storage 持久化存储层。
3.1 Client SDK
1)**功能定位:**用户与 Milvus 集群交互的入口,提供多语言 SDK(Python/Java/Go 等),封装向量写入、查询、索引创建等操作。
2)核心职责:
-
提供声明式 API,屏蔽底层分布式细节
-
负责请求序列化、结果反序列化,以及与 Proxy 节点的通信
-
支持连接池、负载均衡配置,适配不同业务场景
3.2 Proxy(代理层)
1)**功能定位:**集群的统一接入网关,无状态的横向扩展组件,负责请求的路由与分发。
2)核心职责:
-
请求路由:区分请求类型(DCL/DDL、DML、DQL),转发至对应模块
-
请求预处理:校验数据格式、权限,解析向量与标量字段
-
结果聚合:将多个 Query Node 的查询结果合并、排序,返回给客户端
-
负载均衡:基于一致性哈希将请求分发至不同节点,避免单点压力
3.3 Coordinator(协调层,MixCoord)
1)功能定位: 集群的 "大脑",Milvus 2.6 将原 RootCoord/QueryCoord/DataCoord 整合为单一 MixCoord,负责集群元数据管理与任务调度。
2)核心职责:
-
元数据管理:维护集合、分区、索引、用户权限等元数据,持久化至 etcd
-
集群拓扑管理:监控所有节点(Proxy/Streaming/Query/Data)的健康状态,处理节点上下线
-
任务调度:分配数据分片、索引构建、Compaction 等任务至对应工作节点
-
一致性保证:维护集群级别的时间戳(TSO),保证分布式操作的全局有序性
**具体示例:**当执行create_collection()时,Proxy 会把 DDL 请求发给 Coordinator,由它决定分配哪些节点来承载这个集合。
3.4 Workers(工作节点层)
Milvus 2.6 将数据处理拆分为三类专用节点,实现流批分离:
Streaming Nodes(流节点)
1)功能定位: 处理实时写入与增量数据,替代旧版本中分散在 Proxy/DataNode 的流处理逻辑。
2)核心职责:
-
接收 Proxy 转发的 DML 请求,写入 WAL(消息队列,如 Pulsar/Kafka/Woodpecker)
-
消费 WAL 数据,构建增量 Segment(内存中的 Growing Segment),当达到一定阈值(大小或时间)后,它会被封存为 Sealed Segment 并落盘到对象存储;此时 MixCoord 会调度 DataNode 来对这些 Sealed Segment 进行后台处理
-
向 Query Nodes 发布数据订阅,推送最新增量数据
-
故障恢复:从 WAL 中重放数据,恢复内存中的增量 Segment
问1:什么叫消费WAL数据?
批量插入 100 万条向量,Proxy 把请求发给 Streaming Node,这100万条向量先被写入 WAL 日志,后台程序去读WAL,然后把这100万条向量分发给下游节点(即消费WAL)。
问2:构建增量Segment是什么意思?
把刚才从WAL读出来的数据,在内存里拼接成一个临时数据块(Segment),一边攒数据一边更新,这个块就叫Growing Segment(生长中的数据块)。
为了避免频繁写磁盘(性能差),先把实时增量数据在内存中组织成有序、可查询的结构;这个内存中动态增长、未落盘的Segment就是增量Growing Segment。
问3:什么叫向Query Nodes发布数据订阅,推送最新增量数据?
订阅发布机制:告诉所有需要读数据的查询节点,我这有新数据了。
推送最新增量数据:把刚写到内存里的增量Segment,实时发给Query Nodes,让它们立刻能查到最新数据。即Query Nodes不用轮询、不用等待,实时拿到最新数据。
完整流程:
bash
【插入数据】:把数据写入 WAL 日志
【消费 WAL 数据】:后台线程读取 WAL 里的新记录
【构建增量 Segment】:把新记录拼成内存中的 Growing Segment
【发布数据订阅,推送增量数据】:把这个内存块推给所有Query Nodes
【Query Nodes】:立刻能查到刚写入的热数据Query Nodes(查询节点)
1)功能定位: 处理向量查询请求,负责数据的加载、索引查询与结果计算。
2)核心职责:
-
从对象存储加载历史 Segment(已落盘的静态数据)
-
订阅 Streaming Nodes 的增量数据,加载 Growing Segment 和 Sealed Segment
-
执行向量相似度检索(如 HNSW/IVF 索引查询)与标量过滤
-
将查询结果返回给 Proxy,支持分布式查询的并行处理
具体示例: 调用 client.search() 时,Proxy 把请求发给 Query Node,它在内存 / 磁盘索引中执行向量最近邻搜索。
Data Nodes(数据节点)
1)功能定位: 处理离线数据任务,替代旧版本的 DataNode + IndexNode,负责数据持久化与索引构建。
2)核心职责:
-
写入原始数据(消费Sealed Segment),DataNode 会立即将 Sealed Segment 的原始向量和标量数据以binlog格式写入对象存储。(确保数据的持久性和安全性)
-
数据压缩(Compaction),DataNode 会将多个零散的 Sealed Segment 合并成更大的 Segment,优化查询性能(减少需要扫描的 Segment 数量)和回收存储空间
-
构建向量索引,为 Sealed Segment 构建向量索引(如 HNSW/IVF_SQ8),索引构建完成后,也会被写入对象存储,供查询时加速检索
-
清理过期数据,维护对象存储中的 Segment 生命周期
3.5 Durable Storage(持久化存储层)
Milvus 采用分层存储设计,不同类型数据对应不同存储组件:
|----------------|-------------------------|---------------------|-----------------------|
| 存储组件 | 对应服务 | 存储内容 | 核心作用 |
| Meta Storage | etcd | 集群元数据、节点状态、Schema信息 | 分布式一致性存储,保证元数据高可用 |
| WAL | Pulsar/Kafka/Woodpecker | 写入操作日志、增量数据 | 实现数据持久化与故障恢复,作为流数据的枢纽 |
| Object Storage | MinIO/S3/云存储 | 静态 Segment、索引文件 | 低成本存储海量向量数据,支持冷热分层 |
Milvus中多shard和多副本的区别是什么?
1)Shard主要是解决水平扩展写入能力,通过将数据分散到多个分片,让多个节点可以并行处理写入请求。(原理:创建Collection时,可以指定num_shards的数量,Milvus会根据主键ID的哈希值,决定每条数据应该若在哪个Shard上;Collection一旦创建,分片数量就不能再更改)
2)Replica主要用于提高读取吞吐量和系统可用性,通过在节点上创建相同的数据副本,让多个节点可以并行处理读取请求。(原理:当你通过
collection.load(replica_number=2) 加载数据时,Milvus 会为同一个 Shard 在两个不同的 Query Node 上各加载一份完整的数据;提升查询吞吐量和保障系统高可用)
4. 模块协同工作
4.1 数据写入流程(向量插入)
假设用户通过 Client SDK 向 Milvus 写入一批向量数据,流程如下:
1)Client SDK → Proxy:SDK 将数据发送至 Proxy,Proxy 校验数据格式、权限,根据分片规则将数据路由至对应 Streaming Node。
2)Proxy → Streaming Node:Proxy 将 DML 请求转发至 Streaming Node,Streaming Node 将数据写入 WAL(如 Pulsar),同时在内存中构建 Growing Segment。
3)Streaming Node → Data Node:Data Node 消费 WAL 中的数据,当 Growing Segment 达到阈值(如大小 / 时间),执行 Flush 操作,将数据写入对象存储,生成静态 Segment。
4)Data Node → Coordinator:Data Node 将新生成的 Segment 元数据上报给 Coordinator,Coordinator 更新元数据并通知 Query Nodes 加载新 Segment。
5)Streaming Node → Query Node:Streaming Node 通过订阅机制,向 Query Nodes 推送增量数据,Query Nodes 加载 Growing Segment,确保写入的数据可被实时查询。
4.2 向量查询流程(相似度检索)
用户发送向量查询请求,获取与目标向量最相似的 TopK 结果,流程如下:
1)Client SDK → Proxy:SDK 发送查询请求,Proxy 解析查询参数(如 TopK、向量字段、过滤条件),根据分片路由将请求转发至多个 Query Nodes。
2)Proxy → Query Nodes:Query Nodes 同时查询两类数据:
-
增量数据:从内存中的 Growing Segment 实时检索
-
历史数据:从对象存储加载的静态 Segment 中,通过预构建的索引快速检索
3)Query Nodes → Proxy:每个 Query Node 完成本地查询后,将结果返回给 Proxy,Proxy 合并所有节点的结果,按相似度排序并去重。
4)Proxy → Client SDK:Proxy 将最终结果返回给 SDK,SDK 序列化后呈现给用户。
5. Milvus 2.6 架构优化点
1)流批分离:Streaming Node 专注实时写入与增量查询,Data Node 专注离线 Compaction 与索引构建,避免流批任务相互干扰。
2)组件简化:Coordinator 合并为 MixCoord,IndexNode 与 DataNode 合并,降低运维复杂度。
3)弹性扩展:Proxy/Streaming/Query/Data 节点均可横向扩展,适配不同的写入 / 查询并发。
4)分层存储:内存层(增量数据)、对象存储(历史数据)、WAL(日志数据)分离,兼顾性能与成本。
6. 支持搜索类型
Milvus 支持各种类型的搜索功能,以满足不同用例的需求:
-
ANN 搜索:查找最接近查询向量的前 K 个向量。
-
过滤搜索:在指定的过滤条件下执行 ANN 搜索。
-
范围搜索:查找查询向量指定半径范围内的向量。
-
混合搜索:基于多个向量场进行 ANN 搜索。
-
全文搜索:基于 BM25 的全文搜索。
-
Rerankers:根据附加标准或辅助算法调整搜索结果顺序,完善初始 ANN 搜索结果。
-
获取:根据主键检索数据。
-
查询:使用特定表达式检索数据。