TCP协议
TCP特点
-
有连接
-
面向字节流
-
可靠传输(最核心)
-
全双工
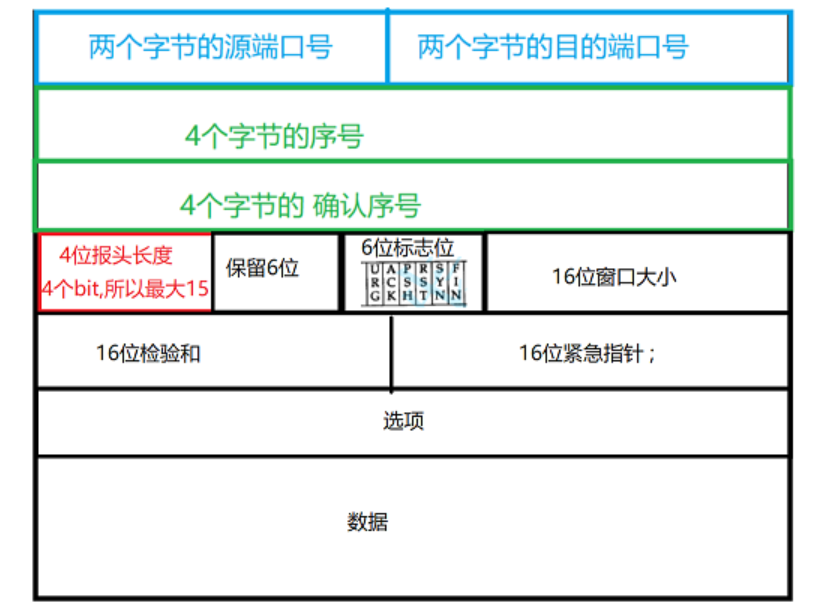
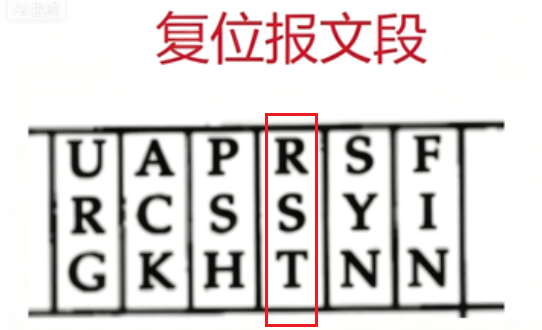
TCP报文格式
TCP的报头是不像UDP只有8个字节,TCP的报头长度是可变的 ; TCP的报文长度也没有
TCP机制
TCP可靠传输
可靠传输通过什么方法?
1.确认应答机制
发送方发送信息过去之后,接收方接收到数据会给发送方发送一个 "应答报文"
后发先至问题
网络数据传输时,会遇到的问题: 我像 张三 连续发送 两条信息: 1."hello" 2."张三" , 按正常来说, 张三应该先收到 "hello" , 然后收到 "张三" , 如果出现后发先至问题, 就会出现张三 先收到"张三 " ,再收到 "hello" ;
这个问题出现 , TCP在这里要完成两个工作
1.确保应答报文和发送的数据 能对应, 不要出现歧义;
2.确保在后发先至的情况发生时,能够让应用程序这边 仍然能够按正确的顺序来理解数据 ;
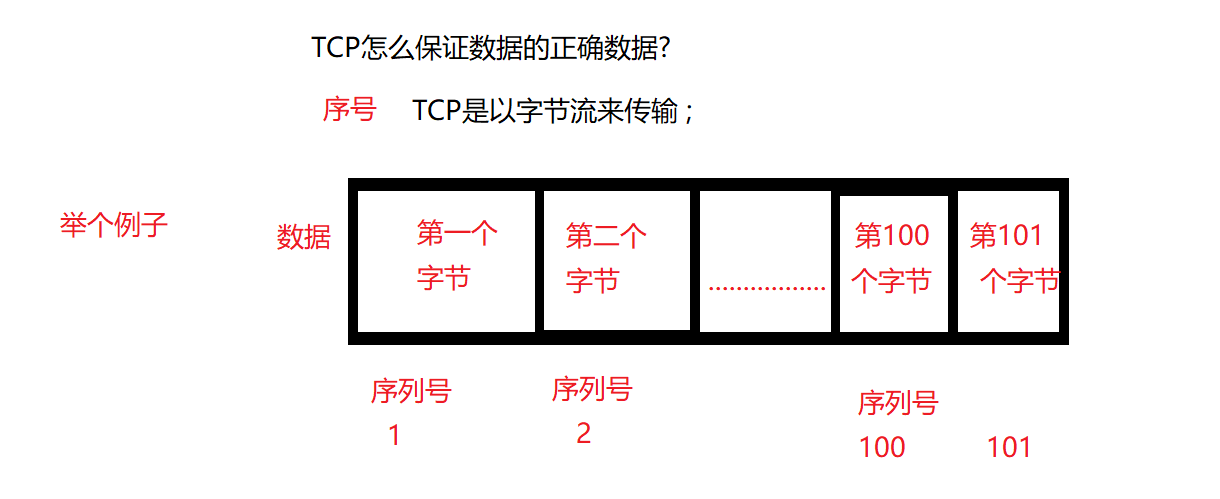
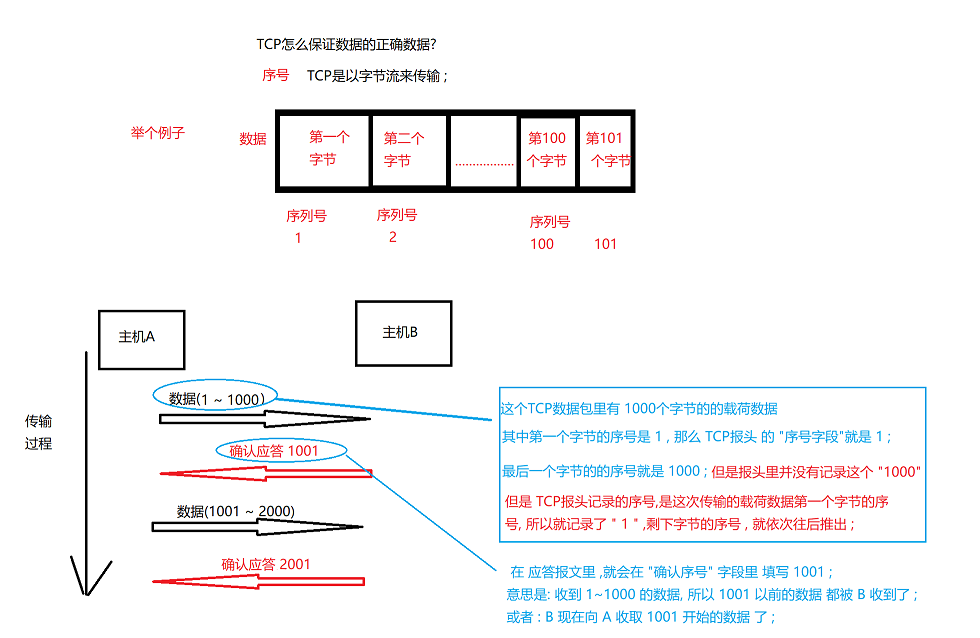
TCP如何确保发送数据的正确顺序?
序号;
例如, 一个字节给一个序号 , (
-
通过特殊的 ack 数据包 , 里的 "确认序号" 告诉发送方 ,哪些数据已经 被确认收到了 ;这时候发送方就直到了自己发送的数据到了没有 , 已达成 => 可靠传输 ;
-
TCP的初心就是为了 可靠传输 , 达成可靠传输最核心的机制 => "确认应答" ;
怎么确认这个数据是一个 "应答" ?
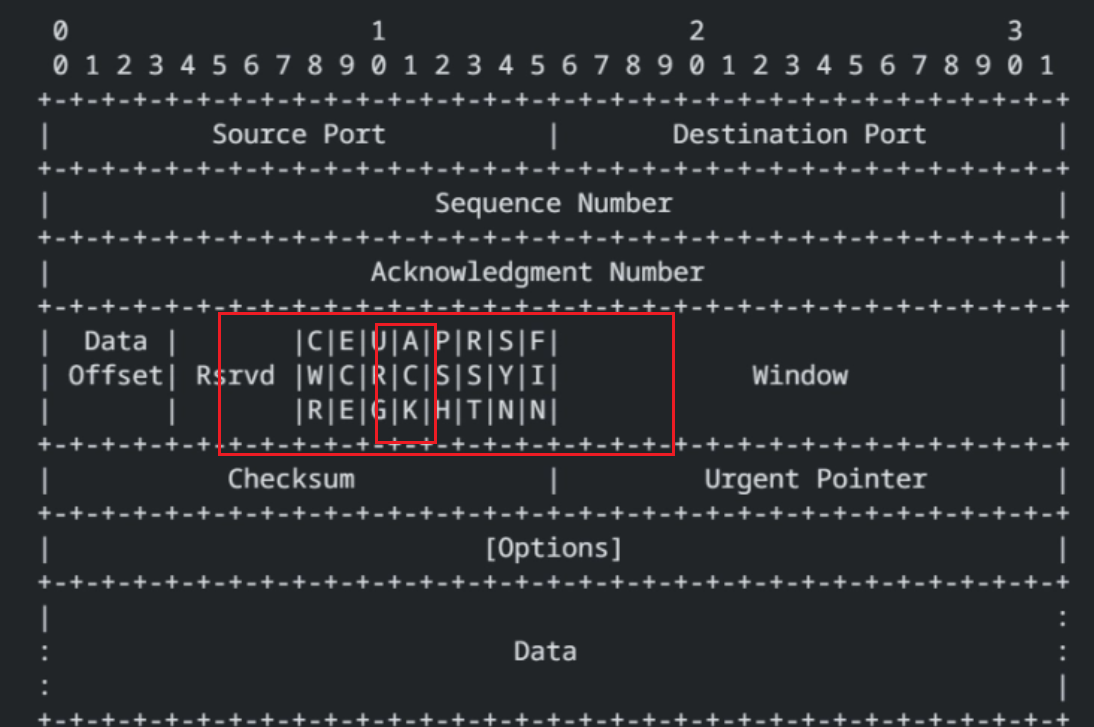
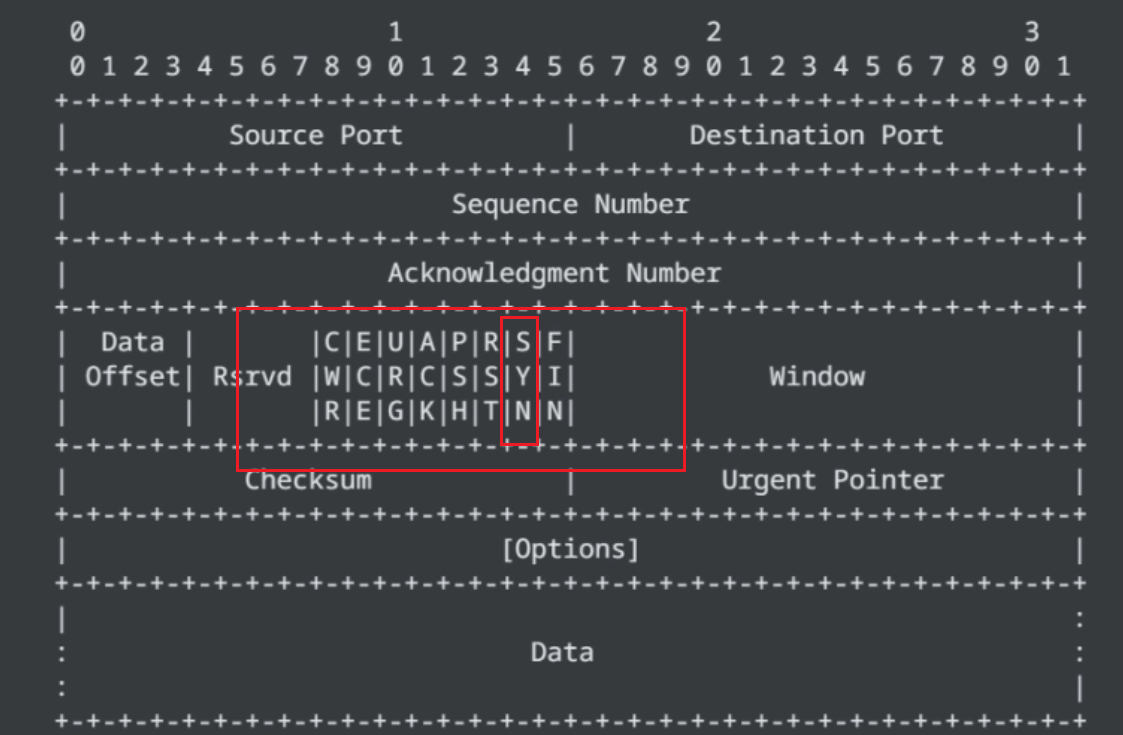
ACK: 应答报文
报头里的六位标志位里 , 如果ACK位的值 是 1 , 这个数据就是一个 "应答报文" , 是 0 就表示一个普通报文 ;
为什么确认应答的确认序号是 以 收到的最后一个字节+1 表示? (结合活动窗口理解)
总结
-
确认应答, 是TCP最核心的机制, 支持里TCP的可靠传输 ;
-
面试题: TCP是如何保证可靠传输: 已确认应答位核心,借助其他机制辅助,来完成可靠传输 ;
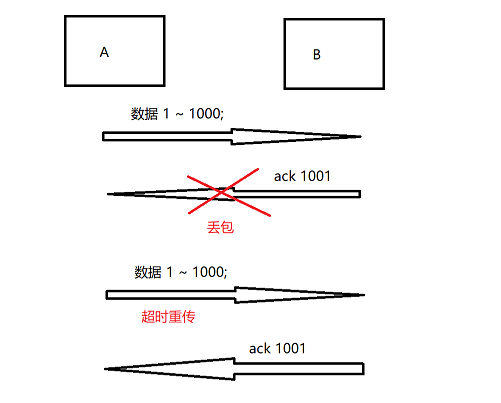
2.超时重传 机制
确认应答,是在理想条件下的,如果数据包在网络传输上,出现"丢包"了,那么 发送方就不会收到 接收方的 确认应答 ;
超时重传 机制, 就是对确认应答进行补充 ;
为什么会出现丢包?
交换机/路由器 , 在平时数据量不多的时候,问题不大 ; 但 如果数据量一下子大起来, 超过了 交换机/路由器 所能承受的极限,这是类似于 "堵车" 一样,数据都 "堵住"了 而 交换机/路由器 对于 "堵车"的处理 , 很粗暴,不会把这些积压的数据保存好, 而是会直接把其中大部分数据丢弃掉 这个数据包就在网络上消失了 ;
真是的网络环境,错综复杂,我们也不知道什么时候回出现"堵车","丢包"等随机事件
丢包是随机事件,TCP传输中就出现两种情况
传输的数据丢了
返回的ACK丢了(数据到了,但应答没有返回到)
丢包情况,在发送方是不能区分时哪个情况,所以无论哪个情况,发送方都进行"重新传输", 第一次丢了,重新传一次, 有
什么时候进行重传?
发送数据后等待一段时间,在这段时间内,ACK来了,就视为数据到达, 如果超时了,ACK还没到,就触发重传机制 ;
等待时间
初始等待的时间是可以配置的,不同系统上都可能不一样 ;
等待的时间,是动态变化的,每经历一次超时,等待时间就会变长(当然,等待时间再长也有极限)
当等待时间拉长到一定程度,还是没有能够正常传输,就认为数据怎么重传都没有用了,就放弃TCP连接(触发TCP重置连接操作); (按前面的丢包率10%,那么多次传输的成功率一个是非常大的,这时候都没有成功,就说明出现了巨大的问题)
重传问题
当 A 给 B 发了一份数据, B给A返回应答时, 出现丢包 , A 没有收到 B的 应答 , A 又重新给B发了一份数据 ;
这是 B 收到 了 两份 一样的数据 , 这会不会有什么问题;
有非常严重的问题 ;(如果是转账?)
接收缓冲区
上面的问题,TCP已经帮我们解决好了,TCP会有一个"接收缓冲区",的内存空间,来保存当前已经接收的数据,和序号 ,如果 接收方发现,收到的数据,已经在接收缓冲区有了(收到重复数据 ) 那么接收方就会把这个后来的数据给丢弃掉,确保应用程序在读取的时候,只有一条数据,而不会有两条重复的数据
接受缓冲区,不仅仅是能 去重 ,还能进行重新排序,确保发送的顺序 , 和应用程序读取的顺序一致;
3.连接管理 机制
建立连接 + 断开连接
三次握手 四次挥手
握手/挥手(handshake)
handshake :打个招呼,没有什么实际意义,比较简短,只是为了引起对方的注意 ;
TCP这里的
(握手操作,不是TCP独有,在很多计算机操作都会涉及)
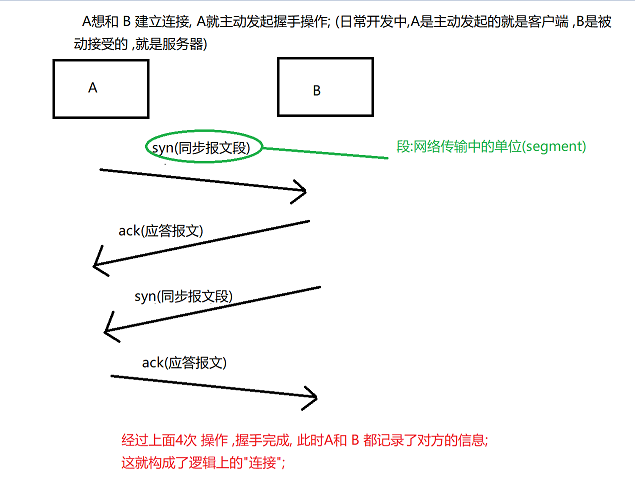
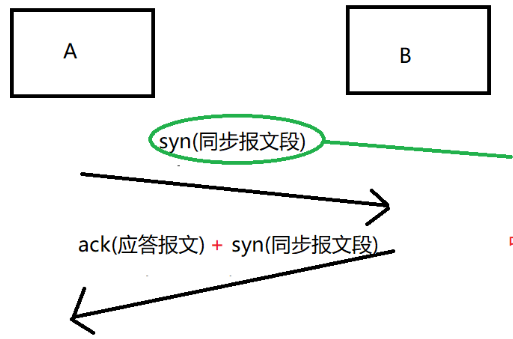
建立连接,TCP的三次握手
TCP在建立过程中,需要通信双方一共 打"三次招呼" ,才能完成建立 ;
连接建立过程
syn同步报文段
是一个特殊的 TCP数据包 , 没有载荷(不携带业务数据);
怎么区分syn , 一样在 标志位里有,当SYN里的是 1, 就是一个同步报文段,是0就不是 ;
网络传输的单位
段 segment 包 packet 报 datagram 帧 frame
三次握手
建立连接的过程,需要通信双方都给对方发起syn , 都给对方返回 ack, 一共是 4 次握手, 但中间两次 刚刚好就可以 合并在一起 ;
但中间 B 给 A 发送 ack 和 发送 syn 这两个操作 可以合并在一起 ;
syn: 同步报文段
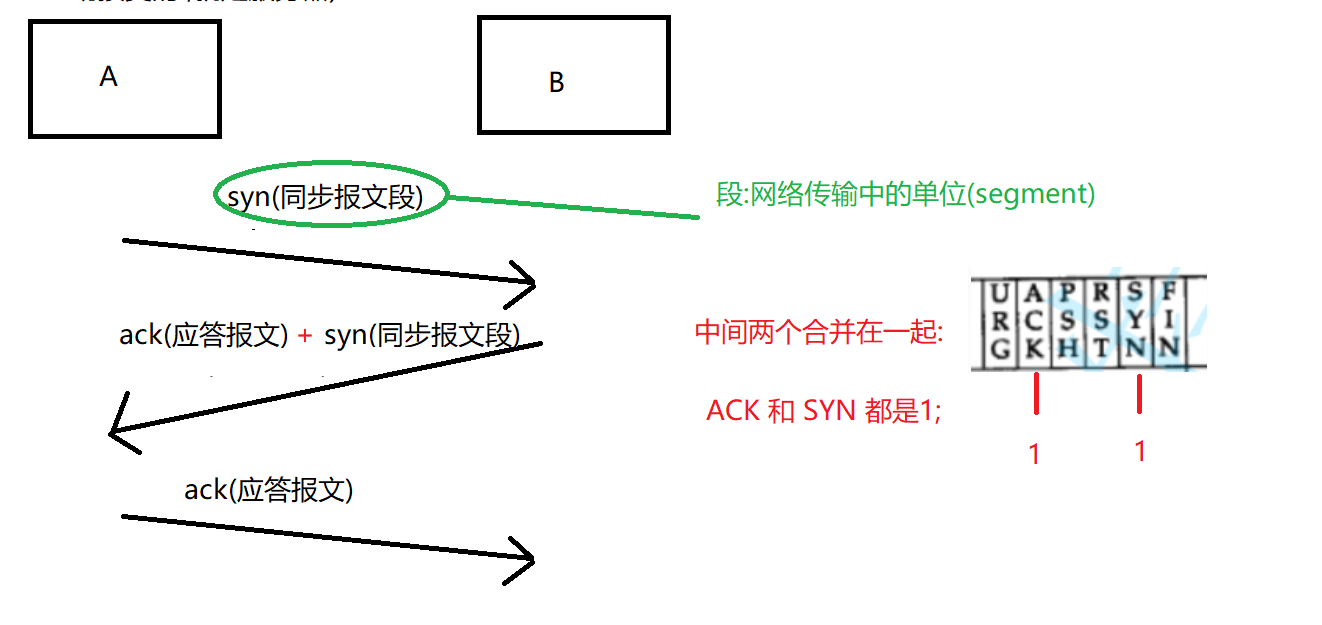
这样就是刚好 "三次握手" ;
为什么要三次握手?通过四次握手,两次握手是否可行?
TCP是为了实现可靠传输, "确认应答" 和 "超时重传"的 有一个前提, 就是当前网络是基本可用的,通畅的;如果当前网络出现重大问题,这还怎么可靠传输 ;
所以三次握手解决的问题,三次握手的作用
-
投石问路,确认当前网络是否是通畅的 (如果当前网络环境连我发的一个不带业务数据的syn或ack都不能够正常传输,那还怎么完成可靠传输)
-
要 发送方 和 接收方 都能确认自己的 发送能力和接受能力都是 正常的 ;(刚开始双方都不知道自己的情况怎么样,三次握手后就知道自己的发送和接收 正常吗)
-
让通信双方,在握手的过程中,对一些重要参数,进行协商 ;(像手机充电一样, 手机支持100w充电 , 充电器支持 65w 充电, 手机和充电器协商 , 手机:支持100w功率 ,充电器:支持65w功率 , 手机: 那我们就用65w功率);
这里握手协商的信息,有好几个, 例如: TCP通信中的 序号 是从 几 开始 , 就是 握手协商出来的(反正一般不是1开始),每次建立连接,都会协商出一个 比较大的值 , 和上一个 大不相同的值 ;(为了避免"前朝的剑,斩本朝的官" , 有时候,网络不好,客户端和服务器端口连接, 重新建立连接 ,这是,建立好新的连接了, 旧连接的数据过来了,对于这种迟到的数据,应该直接丢弃,不用这个旧连接的数据影响我们新连接的操作) (怎么确定这个数据是旧连接的, 就可以通过上述序号的设定规定来区分,如果发现接收的序号和当前正常序号差异很大,就可以直接丢弃掉)
四次握手可行?
可行,但没必要,把中间的两个数据给合并了,就不用发这么多次了,节省开销;
两次握手可行?
不可行, A 和 B 建立 连接, 两次 握手, A 可以知道 自己是否可以正确发送 和 接收 , 而 B 只知道 自己可以正确 接收, 不知道自己的发送 正常吗 ;
TCP的状态
在服务器和客户端建立连接时或其他时候, 服务器和 客户端都会有状态(像线程一样,有各种状态)
- LISTEN(listen)
服务器端的状态,服务器这边的socket建立好了,并且把端口号绑定好了,
- ESTABLISHED(established)
客户端和服务端 都有的状态 , 连接已经建立好了, 可以正常通信了
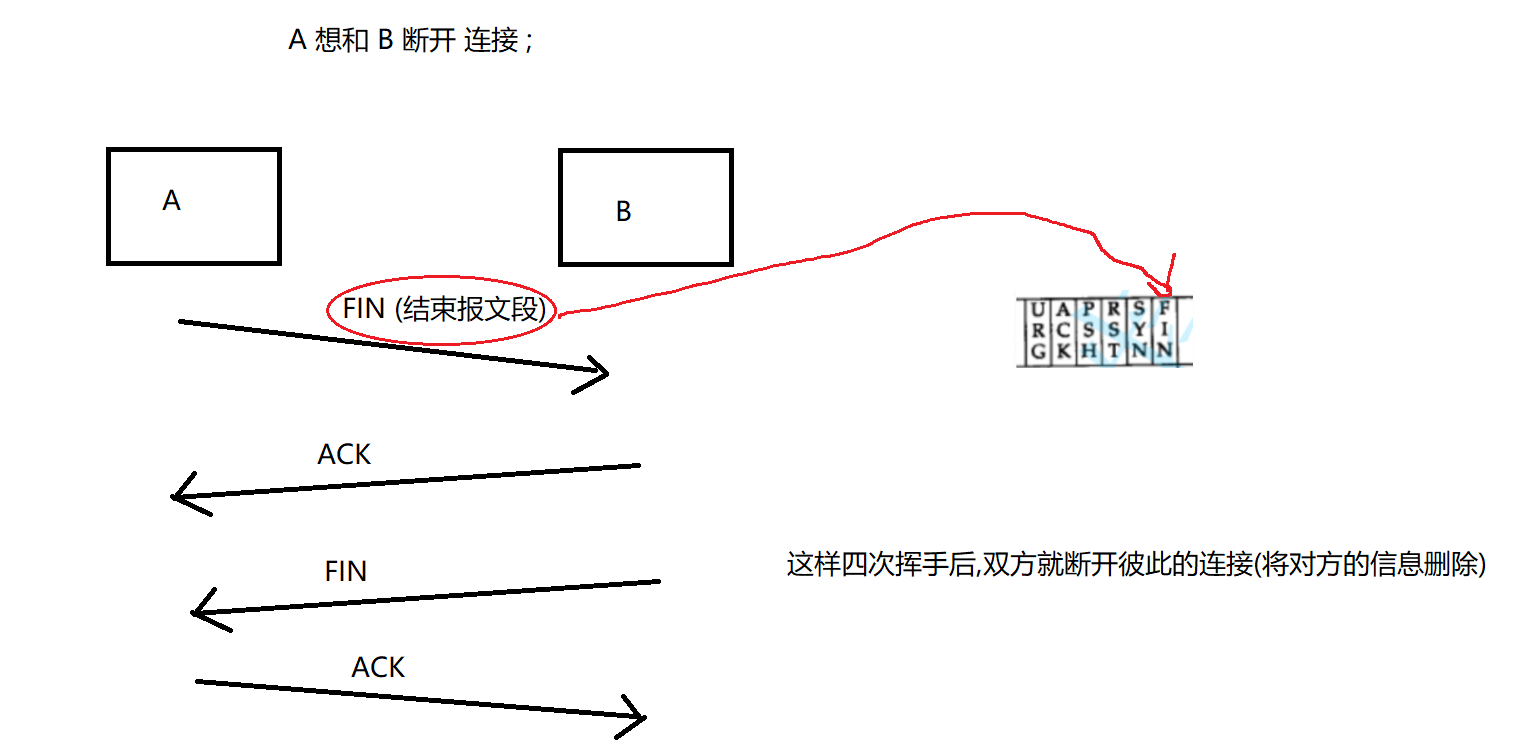
断开连接, TCP的四次挥手
建立连接,一般是 客户端向服务器发起的 , 而断开连接, 就是 双方都可以 发起 ;
FIN: 结束报文段 ;
为什么"握手时" 中间的 ACK和syn可以合并, 而 "挥手时" ACK和FIN只能分开来?
因为 ACK 和 FIN 触发的时机 是不同的 ; 不能确保 ACK 和 FIN 是同时触发;
-
ACK 是由 内核 响应的 , A 发 FIN给 B , B 收到 FIN 内核就立刻返回 ACK ;
-
FIN 是由 应用程序的 代码触发, B 这边 调用 close ()方法, 才会触发 FIN ;
FIN 会在 socket 对象 被 close 时 发起;
而 close()什么时候执行,就看代码是怎么样的 , 可能 手动执行,可能等进程结束,例如 我们这里 等 执行到 if()里的break , 就执行 close();
但是, 日常开发中,close() 什么时候执行就不确定了, close()前面还有完成什么操作就不确定了, 可能要完成一系列工作才会执行close();

前面的三次握手,ACK和 SYN 都是内核触发的 , 是同一个时机就是 可以合并 ;
这里的四次挥手 , ACK 是内核触发, 而 FIN 是程序执行close() 是触发, 时机不同, 所以不能合并
如果一直没有执行到close,就发不出第二个FIN(也是有可能的)
正常四次挥手,就正常断开连接, 如果不正常挥手(没有挥完四次),异常的流程断开连接(也是有可能的)
延时应答 机制
能够拖延 ACK 回应 时间, 这样 就有机会 和 FIN 合并 ;
TCP的状态
发送断开连接时,也有各种状态
-
CLOSED : 连接已经彻底断开了 ;
-
TIME_WAIT: 哪一步主动断开连接, 哪一方就会 进入 TIME_WAIT;
TIME_WAIT状态的作用: 为了防止 最后一个 ACK 丢失, 留下的后手;
正常情况
- A 向 B 发送 FIN , B 返回 ack 后
- B 向 A 发送 FIN , 这是, A 接收到了 返回ACK给 B (同时 A 进入TIME_WAIT状态)
- B 收到 ACK 后 就 closed ,然后 A也closed , 都断开连接 ;
不正常情况
- 如果此时 A 发完 ACK, 没有TIME_WAIT 就进入 closed 状态, 删除了 B 的信息 , 就不会处理 B 发送的 FIN 了 ;
- 所以 让 A 进入 TIME_WAIT等待状态 , 等待这个时间,就是为了处理 B 重新发送的 FIN ,这是 如果B重传 FIN ,就可以处理 ,返回ACK
- 等待时间结束都没有重传,A这边就可以放心的 closed ;
TIME_WAIT等待时间
假设 网络上 两个节点通信 最大消耗时间 : MSL (可配置的参数) ; 那么 这里的 TIME_WAIT 的等待时间就是 :
前面三个机制,都是为了TCP的可靠性(安全性是加密,即使被黑客截获也不怕)
4.滑动窗口 机制
滑动窗口是提高效率; 可靠传输 终究是影响效率的(多出了ACK等待),活动窗口的"效率机制" ,让 可靠传输的影响更小一点 ;
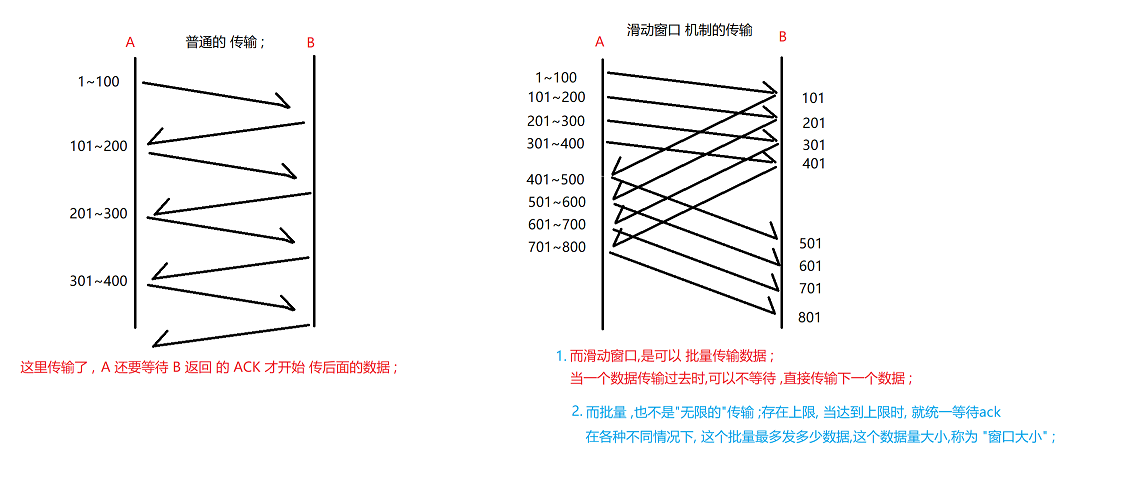
普通传输,要一个一个等待ack
批量传输, 就可以 在一个数据传输过去时不等待 ,直接 传下一个, 等超上限了 , 就一起等ack; (这里传了301~400了,到上限了,就不继续传了,等ack(101) 返回了, 就继续传 401~500的数据 )

接收到一个ack,就继续发一个数据, 而不是等待窗口里的都收到ack;
所以窗口也大, 等待的ack越多 ,效率也越快 ;
并且 TCP是为了 可靠传输, 而 滑动窗口中 , 不影响 确认应答 ;
但出现丢包了,怎么办?
滑动窗口丢包
A 给B发数据 , 丢包分两种 , 1. 丢的是 B 给 A 发的ACK ; 2 .丢的是 A 给 B 发的数据包;
1. ACK丢了
不需要重传ack,没事, 这就是 确认序号的作用 ; 确认序号: 这个序号之前的数据已经确认收到了, 开始接受这个序号开始的数据 ;
所以 如果 ack 101 丢了 , 收到了 ack 201 , 101丢了也没事 , 201到了, 确认201之前的数据已经到了 , 201 覆盖了 101 ;
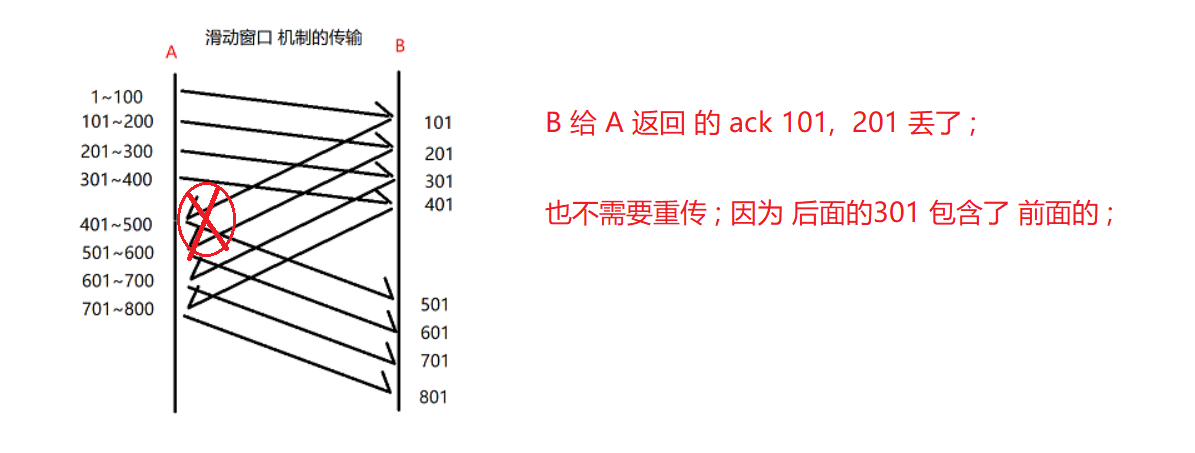
2. 数据包丢了
A 给 B 发数据 ,当 B 发现 有数据报丢了, 就一直发这个 丢了的数据包 ack序号, 给 A 知道了, A 就可以补 发这个 丢的数据包 ;
1.丢了 201~300的数据包,就 要告诉 A , 数据包丢失
2.一直发 201 ack , 当A 连续接收到3个 重复的 应答 , 就知道201 数据包丢了 ;
3.重新 发送丢失的数据包
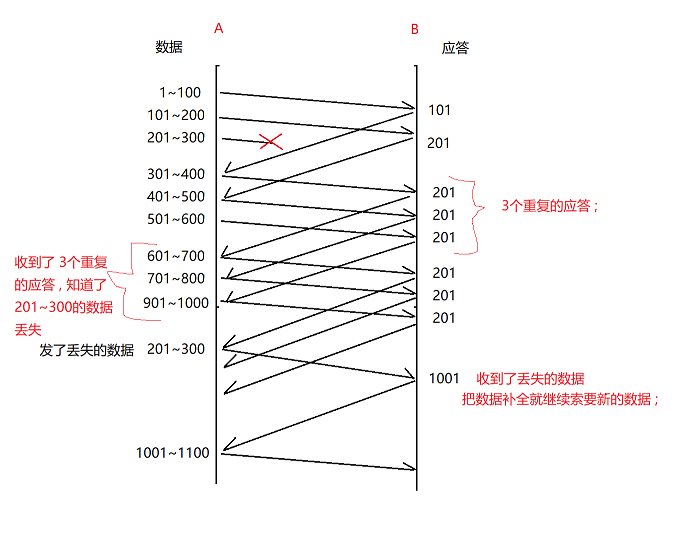
4.当接收到丢失的数据时, 就可以索要新的数据,A也可以发送新的数据(原来A 给 B 发的那些数据,是在接收缓冲区里的,不会丢,所以当补全了丢失的数据,就可以直接要新的数据了)
快速重传
上面的重传过程,没有什么冗余操作,哪个数据丢了,就重传哪个数据,没有丢的不需要重传, 所以这个过程都比较快速
这个 重传是基于 滑动窗口 下的 , 是 超时重传的变种 ;
总结
1.如果通信双方, 传输数据量小,也不频繁,那么就是普通的确认应答,和普通的超时重传
2.如果通信双方,传输数据量大,比较频繁, 那么就是 进入到 滑动窗口模式, 使用 快速重传处理
通过滑动窗口的方式传输,效率会 提升 很多, 窗口 越大, 传输效率越 高(一份等待时间, 等待的 ack多了,总的等待时间就少了)
但窗口不是越大越好, 传输的速度 快了,可能会导致接收方接收不过来, 接收方也会 出现丢包,(TCP是为了可靠传输的,提高效率的不能影响可靠性)
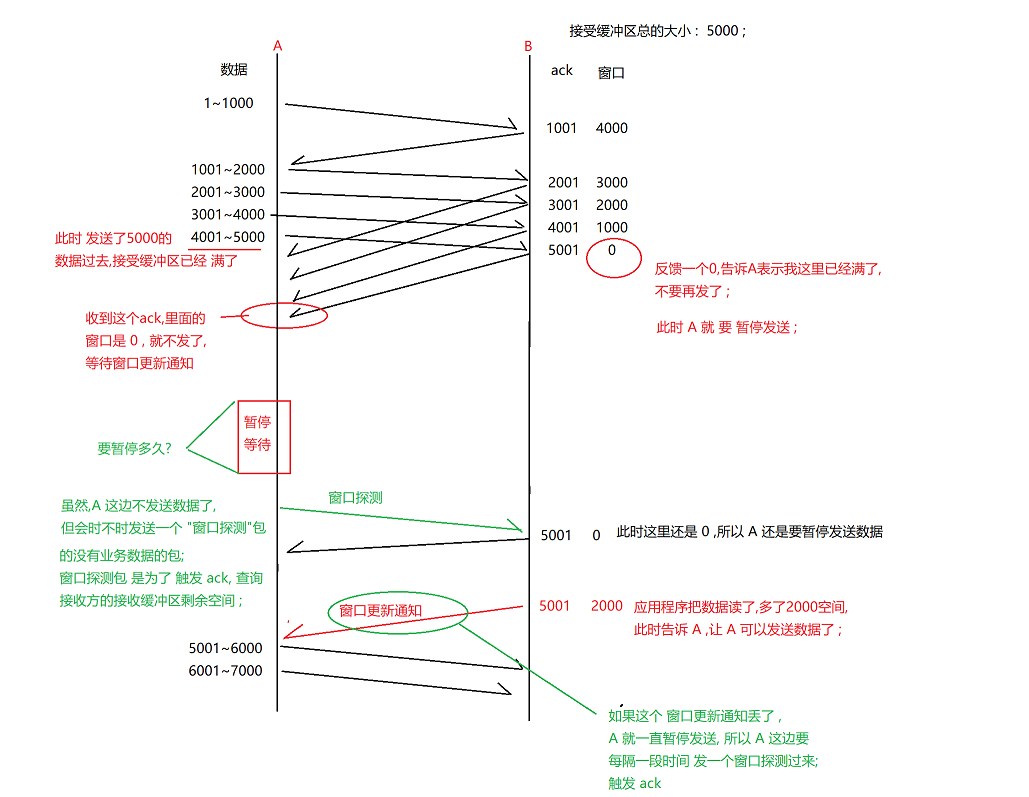
5.流量控制 机制
**接收方:**单方面的制约发送方的 传输速率 ;(正常来说,发送方的发送速率,不应该超过接收方的处理能力)
处理能力主要还是 看 应用程序的 代码怎么样,如果代码没有什么复杂操作,就读的快;
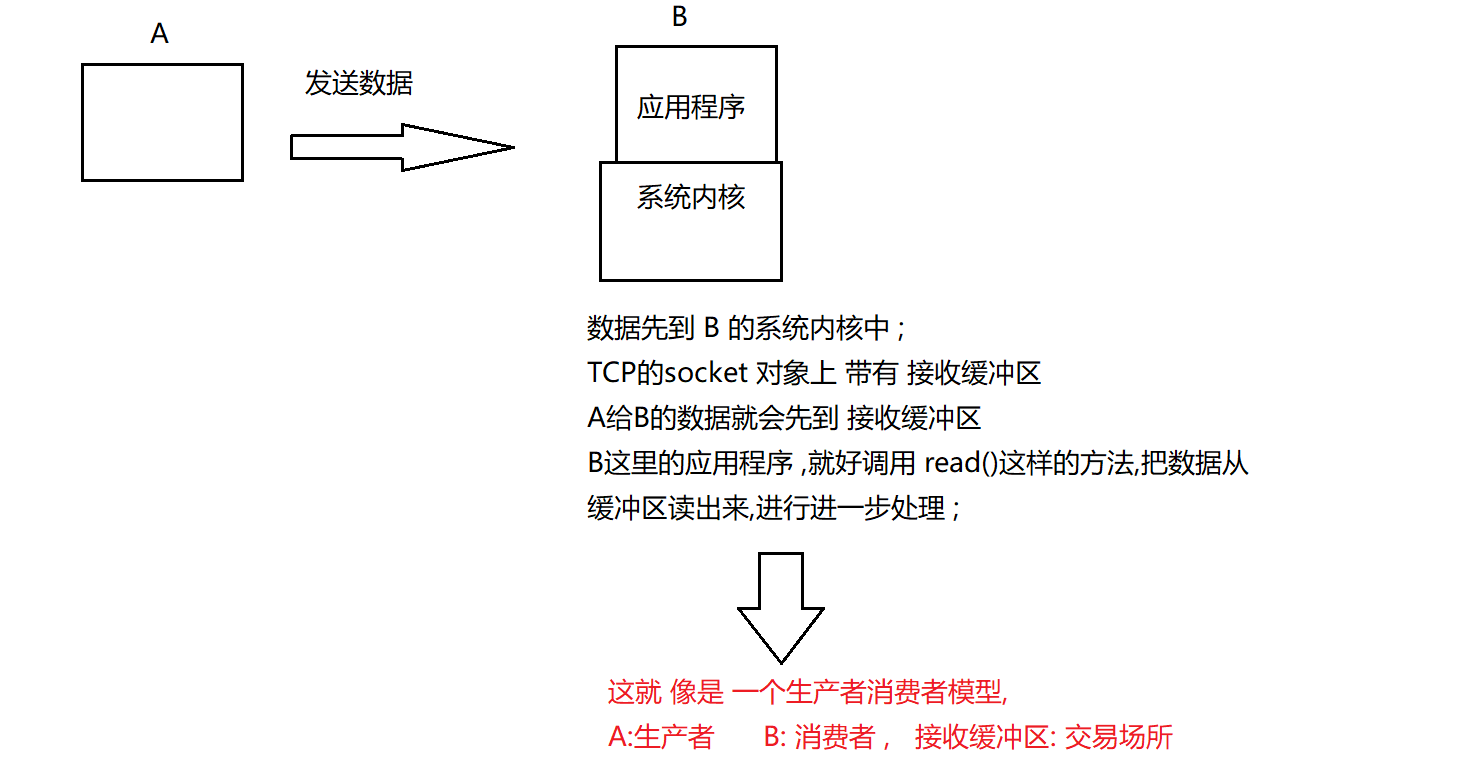
像是 数学题, A 这边在进水 , B 这边在排水, 水池什么时候装满? ;
如何衡量接收方处理能力
通过接收方 的 接收缓冲区 剩余空间的 大小, 作为衡量处理能力 的指标 ;
-
如果 接收缓冲区的剩余 空间 越多 , 意味着 消费速度越快,
-
如果 接收缓冲区的剩余 空间 越小 , 意味着 消费速度 越 慢 ;
接收方 ,每次 收到数据之后,就会 把接收缓冲区 缓冲区剩余 大小 通过 ack 发给发送方, 发送方就会 按它调整下一轮的速度 ;
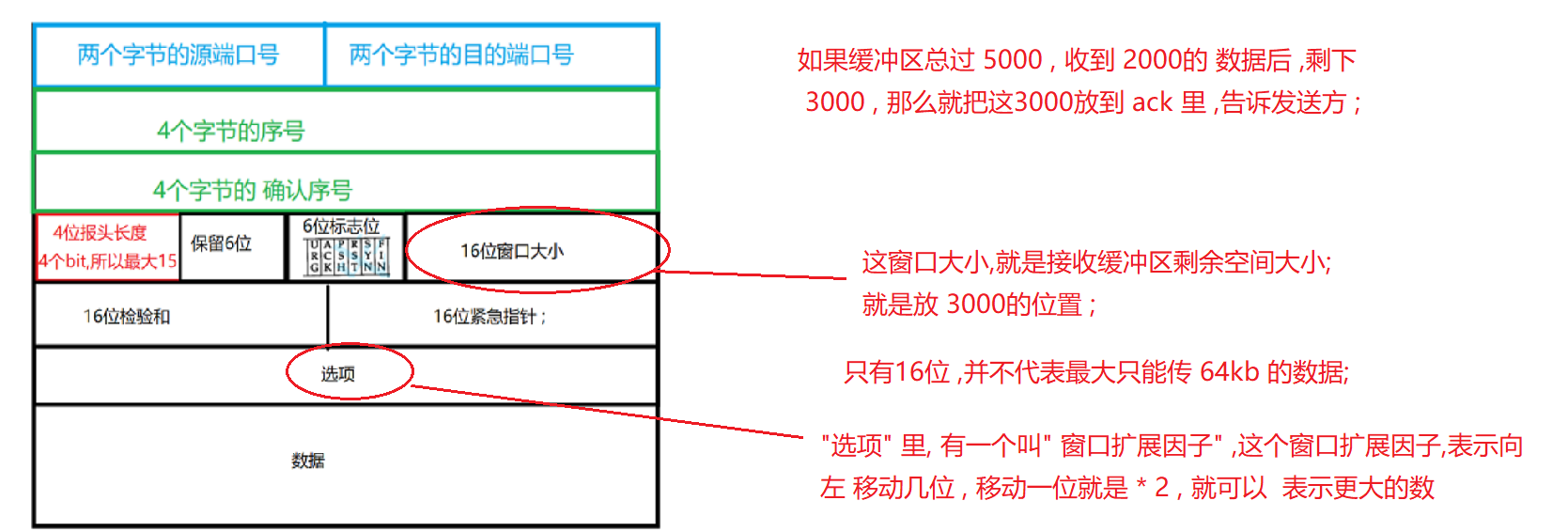
TCP报文
16位窗口大小 : 接收 缓冲区剩余大小 ; (虽然16位 ,但是TCP报头里的"选项" 里, 有一个叫" 窗口扩展因子" , 通过窗口扩展因子,就可以 表示更大的数)
流量控制流程
A 给 B 发送 数据 , 每发一个数据 , B就给A 发ack 告诉 A 此时还剩 多少空间 ;
如果 空间 满了 , A 就 暂停 发送数据 ;
"窗口探测"包 (不带业务数据的包,为了触发ack) , A每隔段时间就给 B 发去,触发 ack ,用来查询 B 的剩余空间 ;
B 如果有剩余空间了 ,就会 给 A 发送 窗口更新通知, 如果 这个通知丢了 , A 就一直 不知道 B 怎么样了, 所以 A需要隔段时间给 B 发一个 窗口探测包;
6.拥塞控制 机制
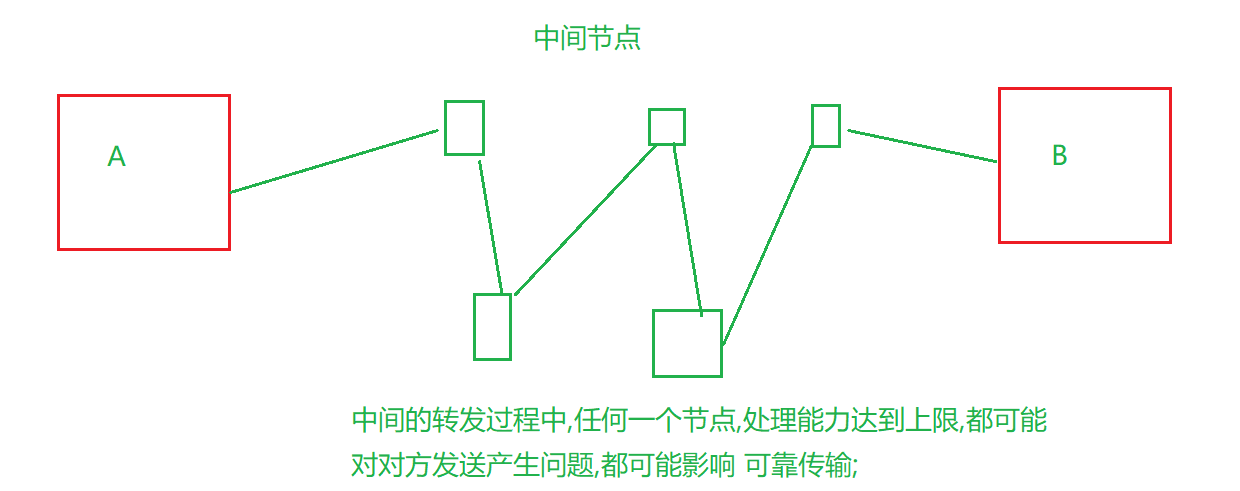
如果说 流量控制 是 考虑接收方的处理能力,(通信过程中,不仅仅是接收方,还有整个通信路径) 那么
拥塞控制,就是考虑 衡量 通信
关键问题
-
流量控制,可以按接收方的处理能力来进行量化衡量
-
而中间节点,结构复杂,难以量化; 因此 使用 "实验",来找到适合的值
实验
A 先 按比较低的速度来发送数据(小的窗口), 如果传输的顺利,没有丢包,就尝试用大点的窗口(一点一点变大)
当窗口不停变大到一定程度,中间节点出现问题 , 出现丢包, 发送方 发现丢包了,就把窗口缩小,如果还是丢包,就继续缩小,如果不丢包了,就继续尝试变大 ;
整个过程中, 发送方不断调整窗口大小,逐渐达到 "动态平衡"
这就相当于把 整个 中间节点,都 看作一个整体, 用 "实验" 的方法,来找到中间节点的 极限在哪里
拥塞控制的具体流程
刚开始,"慢启动"(刚开始很慢), 由指数增长,增长的很快,到达初始阈值, 降低一下增长速度,变成线性增长,此时速度很快
到达极限,网络拥塞了,从1开始,设置新的阈值(新的阈值就比前面的阈值要小),继续重复刚才的步骤, 慢启动->指数增长->线性增长 ;
最后达到 一个"平衡"
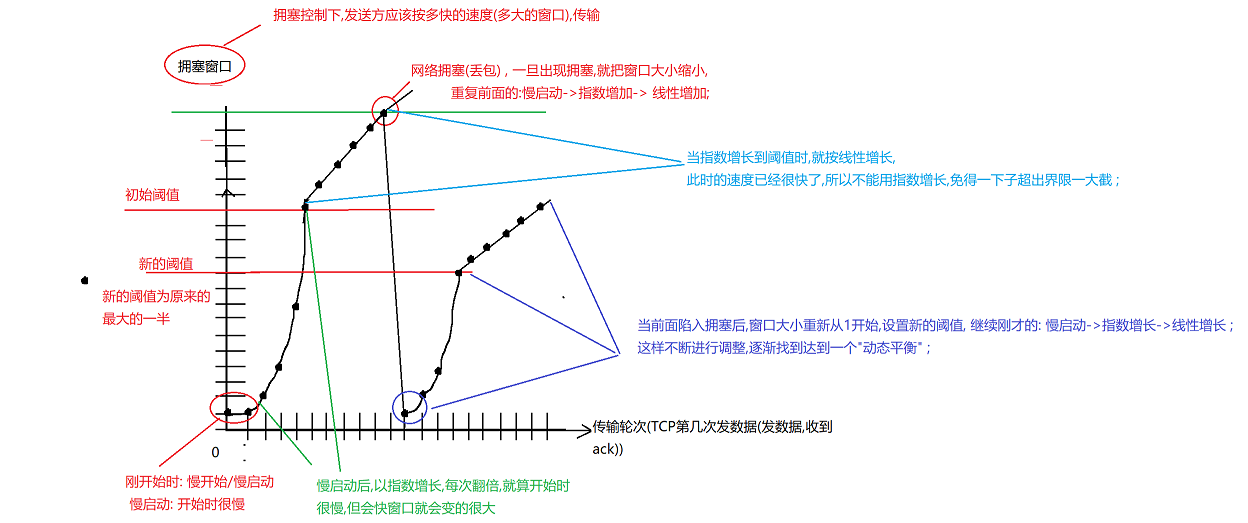
(这里的是一个 "经典版本" 的拥塞控制) TCP后面的改进版本: 到拥塞后不直接降到1 , 而是 从 新的阈值开始 ,继续线性增长 ;
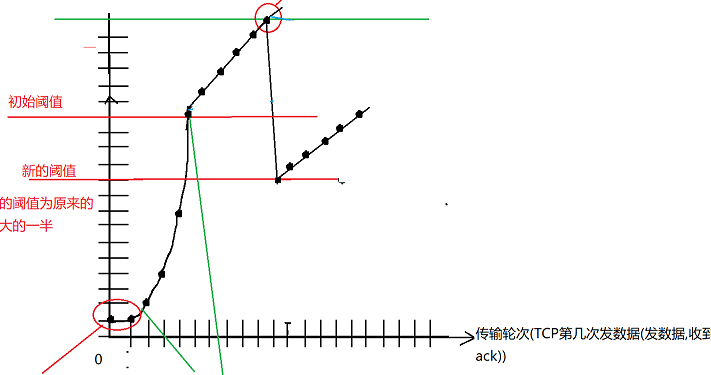
直接降到 1 ,就 浪费 前面这么久到的速度(毕竟要从1开始慢启动,效率还是一般般) ,
改进版本: 就 直接 降到 新的阈值里,在新的阈值里 "线性增长" ;
流量控制和拥塞控制都是为了限制发送方的发送速度, 最终的窗口大小就 取 流量控制和拥塞控制的 较小值 ;
7.延时应答 机制
A 把数据 发给 B , B 马上返回 ack 给 A (正常的确认应答)
A 把数据 发给 B , B 等一会 才 把 ack 返回 给 A (延时应答)
作用
大体
传输效率的关键 , 是 发送方窗口的大小
流量控制 这里, 是 根据 接收缓冲区的剩余空间大小 ,来控制 发送速率的 , 如果有方法,能让 流量控制得到的窗口 更大,发送速率就更快(因为窗口再大也要在,接收方能处理的范围 ,所以就有延时应答)
延时应答: 延时返回 ack, 给接收方更多时间, 来从 接收缓冲区 读取数据, 当读取了数据后 ,接收缓冲区的剩余空间就大了,返回的窗口大小也就更大了,传输效率就快了 ;
例子: 如果一个 接收缓冲区只剩下 20kb了, 立即返回ack的话, 发送方得到的窗口大小就是 20kb ,但是延时200ms ,再返回ack ,这200ms里 , 应用程序 读取了 3 kb 的数据, 此时 返回 ack ,就有 23kb 的窗口了 ;
(当然,这200ms里,能处理多少数据,还是看应用程序怎么处理,这样就 又能 提高效率, 有在 接收方合适范围之内) ;
延时应答 : 也能促成 四次挥手,合并成 三次 ;
8.捎带应答 机制
在延时应答上,进一步提高效率 ;(是在延时应答的基础上完成的)
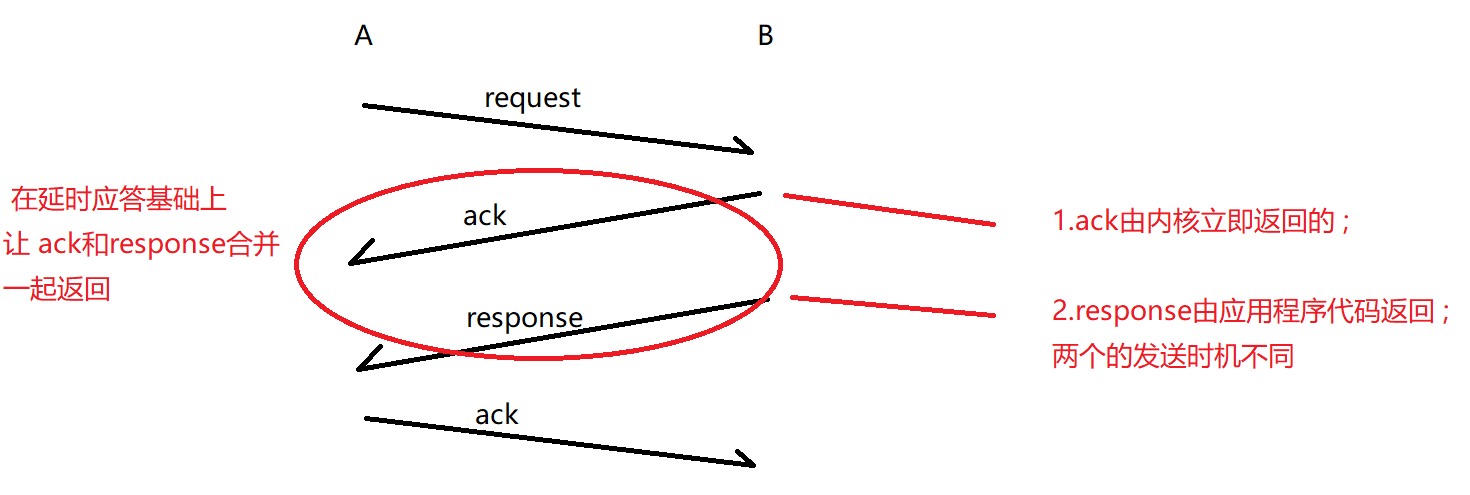
ack由内核立即返回的 ; 2.response由应用程序代码返回 ; 两个的发送时机不同
TCP引入了 "延时应答" 机制, 让 ack 不立即返回 , 而是要等一下 ; 等的过程中 response 计算好了, 要返回response ,就顺便把ack一起返回了;
这样原来要 分两次 来传输两个TCP数据包,就合并成一个;
9.面向字节流
传输灵活,传 100字节, 30字节都可以 ;
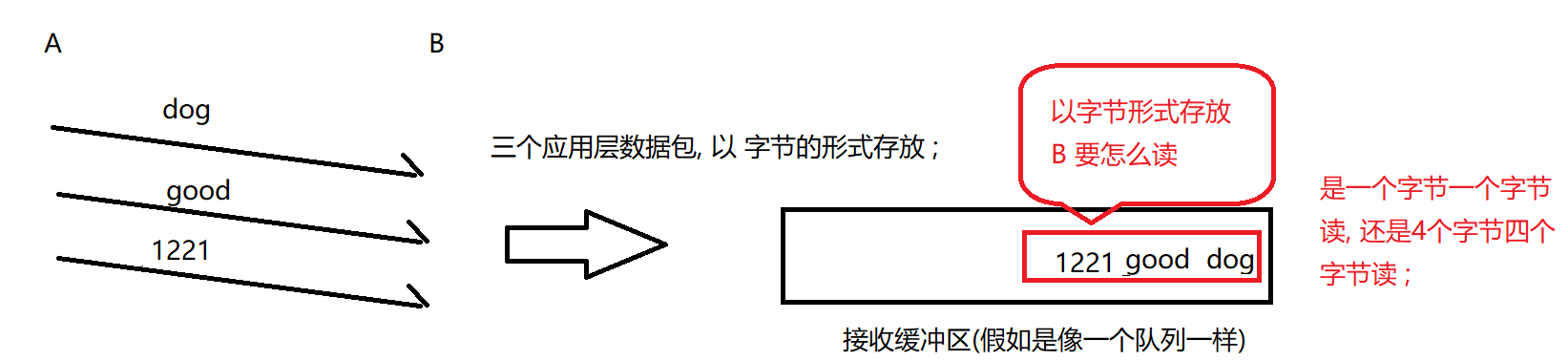
粘包问题
面向字节流机制都有的类似情节
在传输过程中 , A 给 B 发了多个数据包,这些数据包在 接收缓冲区里存在, B 在接收缓冲区里读数据时,就不知道,这个数据包是从哪里到哪里的, 哪个数据包是从哪里到哪里的 ;是一个字节一个字节读, 还是4个字节四个字节读 ;
UDP就没有这样的问题, UDP是面向数据报的, 一个单位就是一个数据报,就是一个数据,容易区分 ;
解决粘包问题
核心:
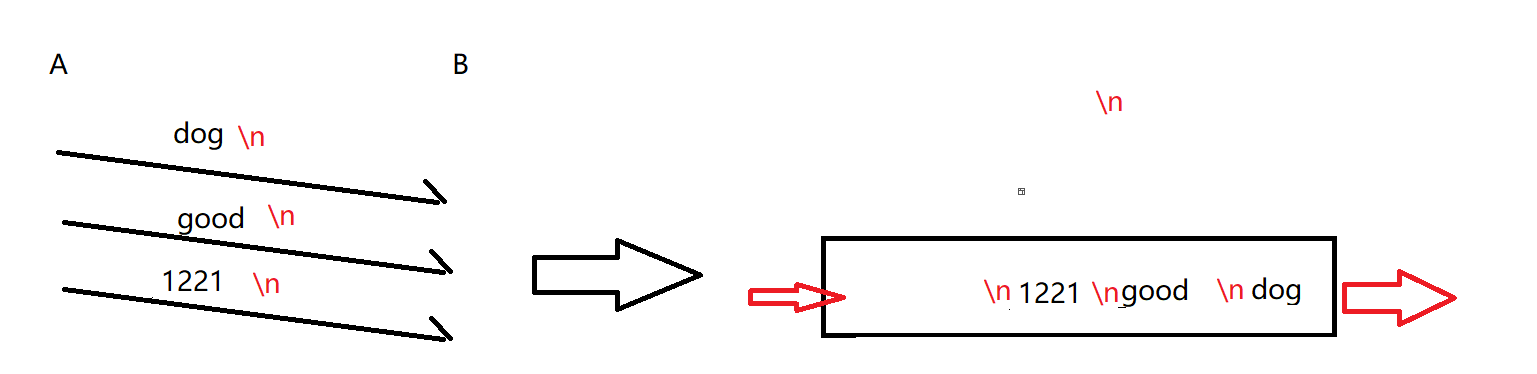
1. 引入分割符(通过分隔符分开各个数据包)
例如 \n ,读到\n就表示这个数据包结束了
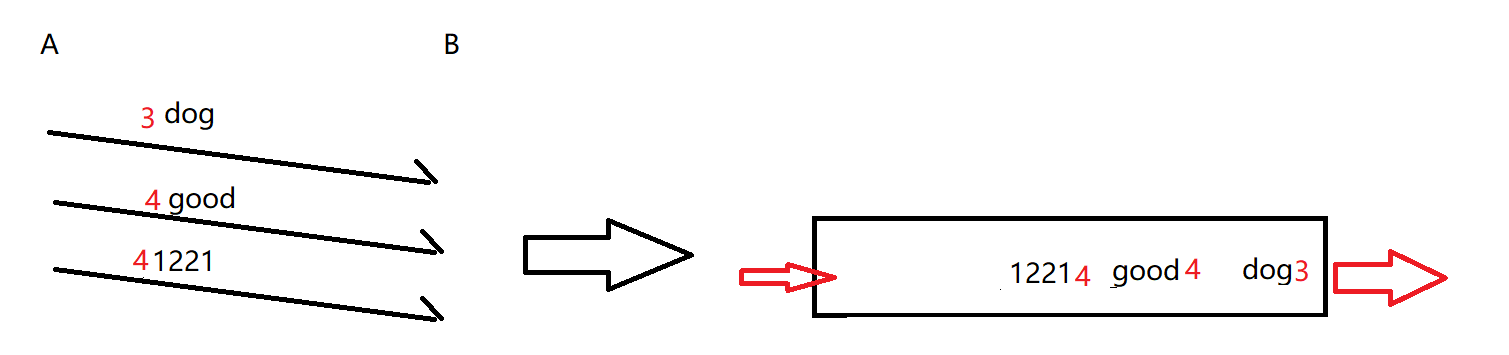
2. 引入长度(规定每个数据包的长度)
这里规定数据包前面两个字节 是 数据包的长度 ; 然后应用程序刚开始,先读 前面两个字节,就直到这个数据包有多大 ;
自定义的应用层协议 例如xml , json , protobuffer, 本身都明确了边界
10.异常情况的处理
使用TCP过程中,出现意外如何处理;
1. 进程崩溃(通信过程时,进程挂了,没了,异常终止了)
进程突然挂了,没了(资源也释放了,相当于调用了socket.close())
就会触发FIN, 对方收到了返回 ack , FIN ;这边返回 ack (还是可以正常的四次挥手流程) ;
TCP 连接 可以独立于 进程而存在 , 进程没了, TCP连接不一定也跟着没 ;所以可以正常进行四次挥手
2. 主机关机(通信过程,主机正常关机)
正常关机, 就会触发强制所有进程终止,进程终止就是上面1.进程崩溃的事情 ;
主机关机,不仅是所有进程终止了,还有整个系统也会关闭了 ;
1.在系统关闭前, 向对端发送 FIN, 对端返回ACK,FIN ,系统这边正常返回ACK, 就是正常的四次挥手
2.如果系统关闭了,对端发送的 ACK 和 FIN 迟到了, 系统这边自然是没有ACK返回的, 对端收不到ACK,就一直超时重传;
重传几次都没有得到响应, 就放弃连接(将对端的信息删除了)
主机掉电(通信过程时,主机掉电(例如台式电脑突然拔插头))
此时一下子,来不及终止进程,来不及 发送 FIN, 主机就挂了 ;
1.A 是在给 B 发送数据 ,
就触发
2. A 给 B 发数据 ,
TCP 提供了
接收方 也会 周期性的 给对方 发一个 特殊的 ,不带业务数据的数据包 , 并且期望对方给一个应答 ;
如果对方没有返回应答, 并且 发了几次心跳包都没有回应, 就默认对方 已经 挂了 ;(此时就可以单方面释放连接了)
3. 网线断开
和上面的主机掉电类似 ;
A 和 B 连接, 连接的网线直接断开了
A 给 B 发送数据
1.A 就触发 超时重传 => 重置连接 => 单方面释放连接;
2.B 触发 心跳包 => 对方没有响应 => 单方面释放连接
总结
-
TCP是可以单方面释放连接
-
TCP的心跳机制(非常重要)(后续使用的心跳机制经常是在应用程序里实现,TCP的心跳周期长)
UDP和TCP的对比
-
TCP主要优势 : 可靠传输 (绝大场景), UDP主要优势: 传输效率更高(对可靠性要求不高,对效率要求高);
-
传输较大的数据包, TCP更优先 , UDP最大只能 64kb ;
-
如果要进行 "广播传输" , 优先UDP , UDP天然支持广播 , 而TCP不支持 (需要应用程序用额外代码实现)
广播: 在同一局域网里, 把数据发送给所有的设备 ;UDP直接就发送出去, TCP就需要把可能的所有机器的ip什么的给建立一遍连接先 ;
经典面试题
怎么用UDP实现可靠传输?
其实考的是TCP
TCP怎么实现的这里就怎么实现
-
确认应答
-
引入 序号和确认序号
-
超时重传
-
滑动窗口
-
...............
TCP的Socket API 和UDP的 差别大, 但和 文件操作有密切联系 ;
Socket API类
Server Socket (给服务器的类, 用来绑定端口号)
方法 :
通过accpt() , 来获取内核中的队列里已经建立好 的连接对象
Socket (既给服务器用 , 也给客户端用)
方法:
getInputStream() getOutputStream() 用于输入和输出 ;
两个类都是 用来表示 socket 文件的 , 都是把 "网卡" 抽象出来的 ;
TCP和UDP的连接区别
UDP是无连接的,所以我们每次send 都有手动指定一下目标的ip跟端口号 , 而TCP是有连接的,不需要我们手动去指定目标 ;
逻辑: 客户端和 服务器建立连接,服务器的应用程序,不需要进行任何操作,内核就直接完成了建立连接的流程("
Socket 的方法
得到对端的信息(客户端)
getInetAddress() getPort()
得到本地的信息(服务器)
getLocalAddress() getLocalPort();
TCP数据的发送和接收
TCP传输的是字节流 , 所以用InputStream 和 OutputStream , 来进行输入和输出 ;
TCP服务器代码
java
package demo2;
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.Scanner;
public class TcpEchoServer {
private ServerSocket socket ; // 这个socket,是用来"招揽" 客户端的 ;
public TcpEchoServer(int port) throws IOException {
this.socket = new ServerSocket(port);
}
public void start() throws IOException {
System.out.println("服务器启动");
while(true){
// 1. 通过accept ,从内核中拿已经建立好的 连接对象 拿到 应用程序
// 建立连接的细节, 都是内核完成的, 无需我们手动指定
Socket clientSocket = socket.accept(); // 这里的socket,是用来后续和连接的客户端通信的 ;
processConnection(clientSocket);
}
}
// 通过这个方法 , 来处理 当前连接 ;
private void processConnection(Socket clientSocket) {
// 打印日志 , 表示有客户端连接上了
System.out.printf("[%s,%d] 客户端上线\n" , clientSocket.getInetAddress() , clientSocket.getPort());
// 输入和输出都是字节流的
//使用try 避免后面忘了close
try(InputStream inputStream = clientSocket.getInputStream() ;
OutputStream outputStream = clientSocket.getOutputStream()){
//客户端可能发送多个数据 , 使用while 来循环处理
while (true){
// 使用scanner 来配合 inputStream , 方便读取 ;
Scanner scan = new Scanner(inputStream) ;
if(!scan.hasNext()){
//如果没有数据了表示, 客户端连接断开了 ; 此时停止 ;
// 打印日志
System.out.printf("[%s,%d] 客户端下线\n" , clientSocket.getInetAddress() , clientSocket.getPort());
break;
}
// 使用next()来读取, next的读取以"空白符"结束 ,这里我们可以规定客户端以 \n ,作为结束标志
//1. 读取请求 ,并解析
String request = scan.next() ;
// 2. 计算响应 process处理请求
String response = process(request);
// 3. 把响应发送给客户端;
// OutputStream可以有两种方法,将数据写回到客户端 ;
// 可以把响应转换成字节数组,写入到OutputStream , 但是 数据最后 没有 \n
// outputStream.write(response.getBytes());
// 可以使用 PrintWriter 把 OutputStream给包裹一下,来写入字符串
PrintWriter writer = new PrintWriter(outputStream) ;
// 此时这里输出的位置就不是控制台,而是 OutputStream的流对象,就是 clientSocket
// 这样数据就发送给客户端了 ;
// 使用println,也是 让数据最后带有 \n , 这样在客户端就可以使用 scan.next()来读取 ;
writer.println(response);
// 刷新缓冲区,避免数据没有成功发送
writer.flush();
// 4. 打印日志 ,包含请求和响应;
System.out.printf("[%s,%d]request= %s , response= %s" , clientSocket.getInetAddress() ,
clientSocket.getPort() , request , response);
}
} catch (IOException e) {
e.printStackTrace();
}
}
//回显,请求就是响应
private String process(String request) {
return request ;
}
}服务器代码问题
文件资源泄露
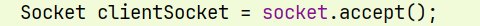
start里的 clientSocket 没有 close ;
为什么会出现文件资源泄露;
因为前面的 DatagramSocket 和 ServerSocket 两个都是在程序中只有一个对象 , 而且 都是一直要使用的 , 如果不使用了,表示程序也要结束了 , 不存在资源泄露 ;
而 这里的 clientSocket 在循环中 , 每有一个客户端连接,就会创建一个clientSocket , 一直申请,不close ;而且这个clientSocket只使用到客户端断开连接,就不使用了 , 如果有很多客户端就 会出现文件资源泄露 ;
解决方法
在处理连接方法processConnection里,加上finally, close clientSocket
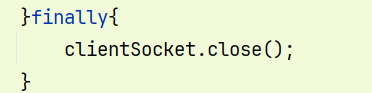
因为处理连接方法,本来就是用来处理clientSocket的,所以在处理完后,关闭掉clientSocket;
}finally{ try { clientSocket.close(); } catch (IOException e) { e.printStackTrace(); } }
不使用try()把clientSocket包裹的原因:
多个客户端问题
先看下面客户端代码
客户端
细节问题
客户端与服务器连接的问题: 虽然客户端的连接和服务器的连接,不需要我们处理,但是客户端要知道服务器的ip和端口号,才能进行连接
操作步骤
1.在控制台读取请求
2.把请求发给服务器
3.从服务器读取响应
4.把响应显示出来客户端代码
java
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.PrintWriter;
import java.net.Socket;
import java.util.Scanner;
public class TcpEchoClient {
private Socket socket = null ;
public TcpEchoClient(String serverIp , int serverPort) throws IOException {
//socket和服务器建立连接,需要告诉socket 服务器在哪里,
//具体建立连接的细节,就交由内核处理,不需要我们管
// 创建socket时,把服务器的信息给socket
this.socket = new Socket(serverIp , serverPort); // 当我们new出对象时,内核就帮我们进行连接
}
public void start(){
System.out.println("客户端启动");
Scanner scan = new Scanner(System.in) ;
try(InputStream inputStream = socket.getInputStream();
OutputStream outputStream = socket.getOutputStream()){
Scanner scanResponse = new Scanner(inputStream) ;
while (true){
//1.在控制台读取请求
System.out.println("输入请求-> ");
String request = scan.next() ;
//2. 把请求发送给服务器
PrintWriter writer = new PrintWriter(outputStream) ;
// 使用println ,为了发生的请求也带有\n换行
writer.println(request);
writer.flush();
//3. 读取响应
String response = scanResponse .next() ;
//4.打印响应
System.out.println(response);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws IOException {
TcpEchoClient client = new TcpEchoClient("127.0.0.1" , 9090);
client.start();
}
}
TCP客户端和服务器通信逻辑
客户端启动,和服务器建立连接, 服务器能感知到 (accpt 会返回,) 进一步到 processConnection里的scan.next ;
一个代码多个进程(实例)
首先将idea的类的设置更改

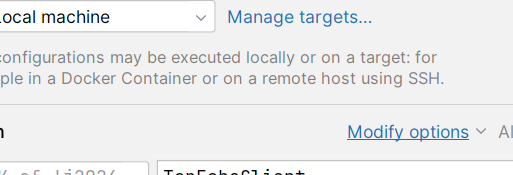
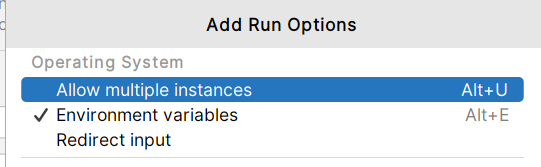
idea默认的是一个代码只能创建一个进程, 勾选第一个,让一个代码可以同时运行多个进程 ;

这时候就有多个客户端了 ;
多个客户端问题
1.有多个客户端之后, 发现服务器,并没有提示有多个客户端上线

2.第一个上线的客户端,发送请求,有响应,而第二个客户端没有响应 ;
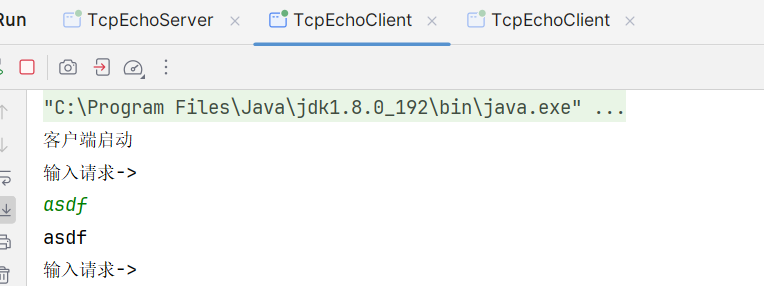
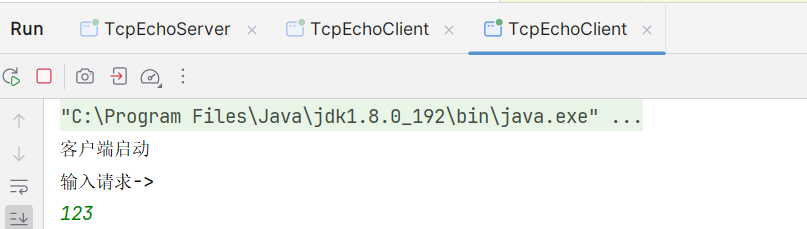
启动两个客户端,同时连接服务器,先启动的客户端,能够正常和服务器交互,但第二个客户端确没有正常工作 ;
问题出现的原因

服务器一次只能处理一个客户端,只有这个客户端下线, 才能处理其他客户端 ;
解决问题的关键
让服务器能够同时处理多个客户端, 关键就是 在处理第一个客户端时, 还能够快速执行下一个accept ; --- > 多线程
让这些客户端都能并发处理, 主线程每次 accept , 都创建新线程来处理 processConnection ; 每有一个客户端,就创建一个线程;
public void start() throws IOException { System.out.println("服务器启动"); while(true){ Socket clientSocket = socket.accept() ; // 这里不直接调用processConnection,而是创建新线程来让线程调用 // 创建线程来掉用 ; Thread thread = new Thread(()->{ processConnection(clientSocket); }); thread.start(); } }
进一步优化===> 线程池 ; 稍微降低创建销毁线程的消耗 ;
public void start() throws IOException { System.out.println("服务器启动"); ExecutorService service = Executors.newCachedThreadPool(); while(true){ Socket clientSocket = socket.accept() ; service.submit(new Runnable() { @Override public void run() { processConnection(clientSocket); } }); } }
但也只是降低一点点, 因为同一时间有上万个客户端请求, 不可能要创建出上万个线程, 如果一个程序有上万个线程,那这个主机肯定是会 挂了 ;
解决方法: IO多路复用 / IO多路转接 ; 一个线程同时处理多个客户端socket