问题描述
五一假期最后一天收到客户发来的复制延迟告警,需要进行处理 。

分析过程
获取告警对应的监控指标
现场用的是kingbase_expor探针监控服务,告警对应的监控指标对应的SQL如下:kingbase_sys_stat_replication_wal_lsn_diff_bytes{type='replay_delay'}/1024/1024/1024,阈值超过100MB告警。对应的SQL为:
SELECT
client_addr, client_port, state, sys_wal_lsn_diff(sys_current_wal_lsn(), sent_lsn) AS sent_delay, sys_wal_lsn_diff(sys_current_wal_lsn(), write_lsn) AS write_delay, sys_wal_lsn_diff(sys_current_wal_lsn(), flush_lsn) AS flush_delay, sys_wal_lsn_diff(sys_current_wal_lsn(), replay_lsn) AS replay_delay
FROM
sys_stat_replication
第三条记录的lsn一直再增长。复制延迟问题主要集中在 ip后缀是.107 这个备库的几个连接上,且延迟数值差异很大。sys_wal_lsn_diff 函数计算的是两个 LSN 之间的字节差,这个值可以理解为主库产生、但备库还未处理到的数据量。 同一个备库(*.*.*.107),有的连接完全健康,有的却出现了高达 6.4GB 的延迟。
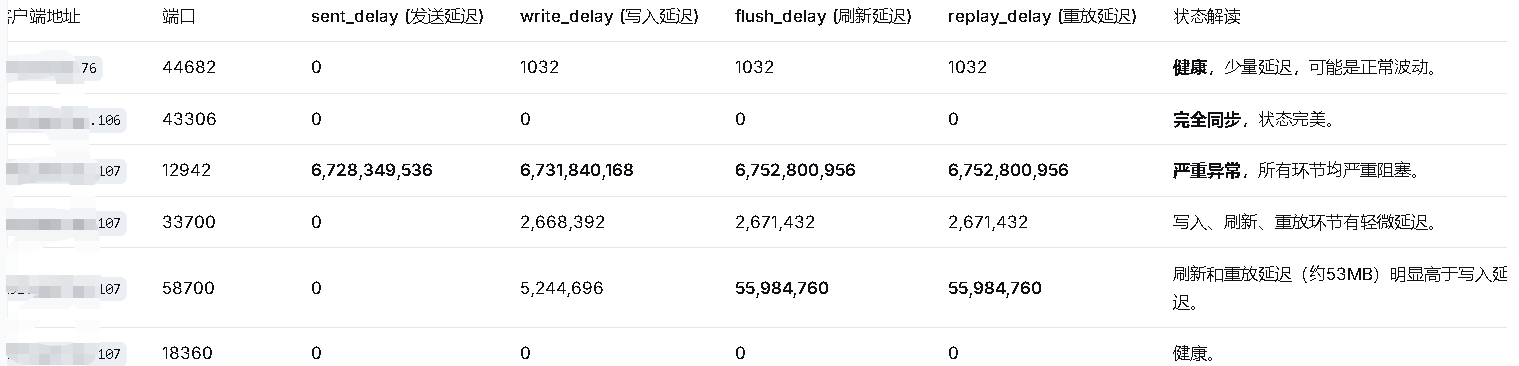
kingbase_sys_stat_replication_wal_lsn_diff_bytes告警指标说明:
名称:kingbase_sys_stat_replication_wal_lsn_diff_bytes
说明:流复制预写位置差别
单位:字节
字段:
- client_addr: 连接WAL发送进程客户端IP地址。 如果这个域为空,表示该客户端通过 服务器机器上的一个Unix套接字连接
- client_port: 客户端用来与WAL发送进程通讯的TCP端口号,如果使用Unix套接字则 为-1
- state: 当前的WAL发送进程状态
-
startup: WAL发送器正在启动
-
catchup: WAL发送器连接的后备机正在追赶主服务器
-
streaming: WAL发送器在它连接的后备服务器追上主服务器之后用流传送更改
-
backup: WAL发送器正在发送一个备份
-
stopping: WAL发送器正在停止
- backend_start: 进程开始时间,即客户端是何时连接到这个WAL发送进程的
- now: 当前时间戳
- type:
-
send_latency: 发送最后一个预写式日志延迟
-
slave_latency: 被重放后备服务器数据库中最后一个预写式日志延迟
-
flush_latency: 后备服务器刷入到磁盘最后一个预写式日志延迟
查看服务器负载
磁盘IO、CPU、内存消耗均不高
# 检查磁盘I/O,关注 %iowait 是否异常(如超过10%)
iostat -x 1 5
# 检查内存使用情况
free -h
# 检查CPU负载
top查看是否有长会话
前两条会话是KFS反向链路的,不影响。
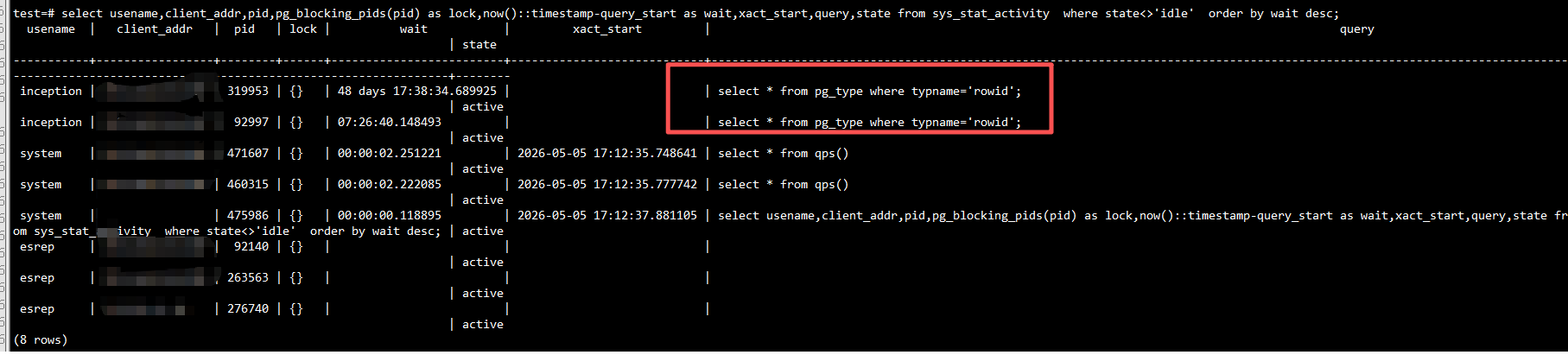
KFS的工作机制和金仓数据库的特性:select * from pg_type where typname='rowid'; 解释:
- KFS的高效同步原理 :KFS(金仓异构数据同步软件)为了实现低延迟、低侵扰的数据同步,采用了基于数据库物理日志(WAL)解析的技术。使用一种最高效、最可靠的方式捕获和定位底层数据变更。这
- 需要一个"稳定"的行定位器 :在进行增量同步、冲突处理或断点续传时,KFS需要一种稳定、唯一且永久的方式来标识数据表中的每一行记录。
-
- 原生PostgreSQL的
ctid(物理行号)会因VACUUM等操作而改变,不能作为永久标识。 - 业务主键并非所有表都有,依赖它不够通用。
- KFS在工作前会进行"握手"检查 ,通过查询
pg_type来确认目标库是否已经开启了对 ROWID****类型的支持。
- 原生PostgreSQL的
- ROWID****就是解决方案 :金仓数据库的
ROWID正是为此而生的。它是一个由数据库自动维护的逻辑唯一标识,具有以下完美特性:
-
- 全局唯一:一旦生成,在数据库全局内唯一。
- 永久不变 :无论数据如何被
VACUUM、整理或移动,其ROWID永不改变。 - 自动索引:启用后会自动创建唯一索引,查询性能极高。
- 对用户透明:默认是隐藏列,不影响现有业务逻辑。
- ROWID,这是一种专为内部机制(如同步、定位)设计的稳定行标识,比依赖业务主键或物理 ctid 更通用、更可靠。
如果查询返回了结果,说明目标库支持 ROWID,KFS就可以利用这一特性,采用最优化的策略进行数据同步。如果无结果,KFS可能需要回退到其他同步机制,以保证兼容性。
KFS为保障数据同步的效率、稳定性和数据库兼容性而自动执行的健康检查步骤之一,属于完全正常的现象。
查看集群数据库状态
LSN_Lag列:表示主备流复制差距,值越大说明主备数据之间的差异越大。当前0说明无差异。
repmgr cluster show all
或
repmgr cluster show all -v
查看复制槽信息
3条物理复制记录,2条逻辑复制记录

查看复制情况
每一个 WAL 发送进程一行,显示有关到该发送进程连接的后备服务器的复制的统计信息。
输出6条记录,比复制槽多一条记录,最后一条记录异常。
select * from sys_stat_replications;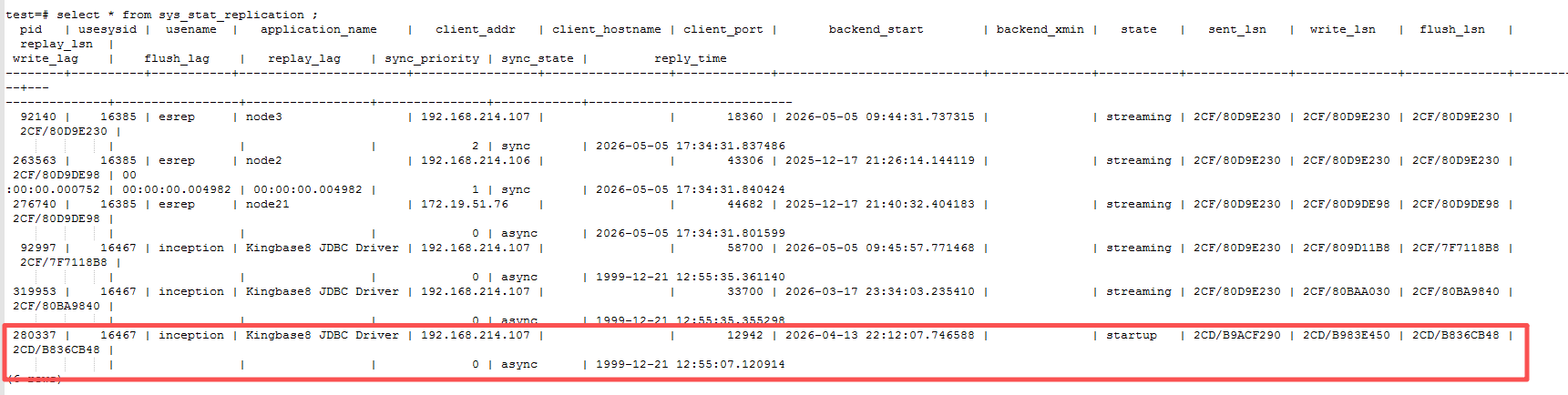

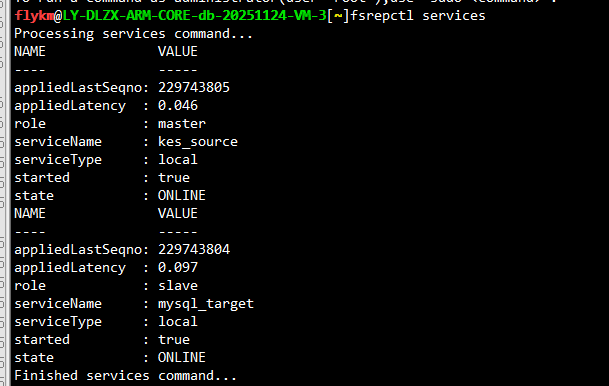
查看KFS链路是否延迟
总共有2套KFS反向链路,同步服务都正常且无延迟
fsrepctl services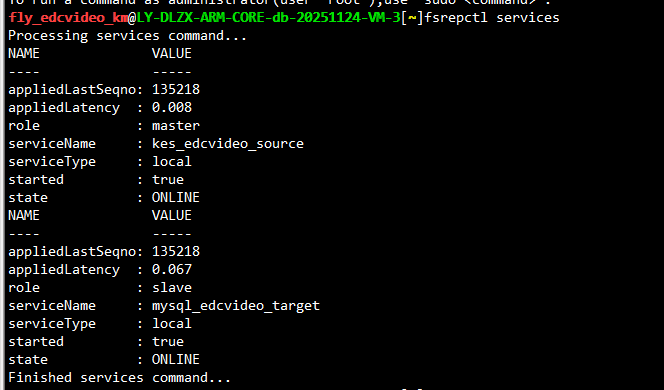
解决办法
重启KFS同步服务
分别对2条KFS反向链路同步服务进行重启,重启后告警自动消除,复制槽条目数和复制表条目数一致
查看复制槽信息
3条物理复制记录,2条逻辑复制记录
查看复制情况
已经和复制槽记录数保持一致,异常的那条记录消失

再次获取告警对应的监控指标
现场用的是kingbase_expor探针监控服务,告警对应的监控指标对应的SQL如下:kingbase_sys_stat_replication_wal_lsn_diff_bytes{type='replay_delay'}/1024/1024/1024,对应的SQL为:
SELECT
client_addr, client_port, state, sys_wal_lsn_diff(sys_current_wal_lsn(), sent_lsn) AS sent_delay, sys_wal_lsn_diff(sys_current_wal_lsn(), write_lsn) AS write_delay, sys_wal_lsn_diff(sys_current_wal_lsn(), flush_lsn) AS flush_delay, sys_wal_lsn_diff(sys_current_wal_lsn(), replay_lsn) AS replay_delay
FROM
sys_stat_replication

总结
推测是该会话可能处于"僵尸"状态,无法处理数据,但TCP连接还保持着,该应用进程本身已经挂起。
完成紧急处理后,建议长期将 sys_stat_replication 视图纳入监控系统,并为 write_delay 或 replay_delay 设置阈值告警(例如超过100MB或200MB),以便在问题累积前就及时介入。