Transformer 架构深度解析------从 Attention 到 BERT 的基石
标签 :深度学习 · NLP · Transformer · Self-Attention · BERT · 位置编码
摘要:本文以程序员视角,从传统序列模型的痛点出发,逐层拆解 Transformer 的核心组件------Self-Attention、Multi-Head Attention、位置编码、残差连接与归一化,最终梳理 Encoder-Decoder 的完整数据流。这是理解 BERT、GPT 等现代预训练语言模型的必备基础。
目录
- 背景:传统序列模型的局限
- [Encoder-Decoder 框架](#Encoder-Decoder 框架)
- Self-Attention:注意力机制
- [Multi-Head Attention:多头机制](#Multi-Head Attention:多头机制)
- [位置编码(Positional Encoding)](#位置编码(Positional Encoding))
- [Add & Norm:残差连接与归一化](#Add & Norm:残差连接与归一化)
- [Feed Forward 层](#Feed Forward 层)
- [Transformer 完整架构](#Transformer 完整架构)
- [Outputs (Shifted Right):解码器自回归](#Outputs (Shifted Right):解码器自回归)
- [从 Transformer 到 BERT](#从 Transformer 到 BERT)
- 总结
一、背景:传统序列模型的局限
在 Transformer 出现之前,NLP 序列建模的主力是 RNN / LSTM / GRU。然而这类模型存在两个本质缺陷:
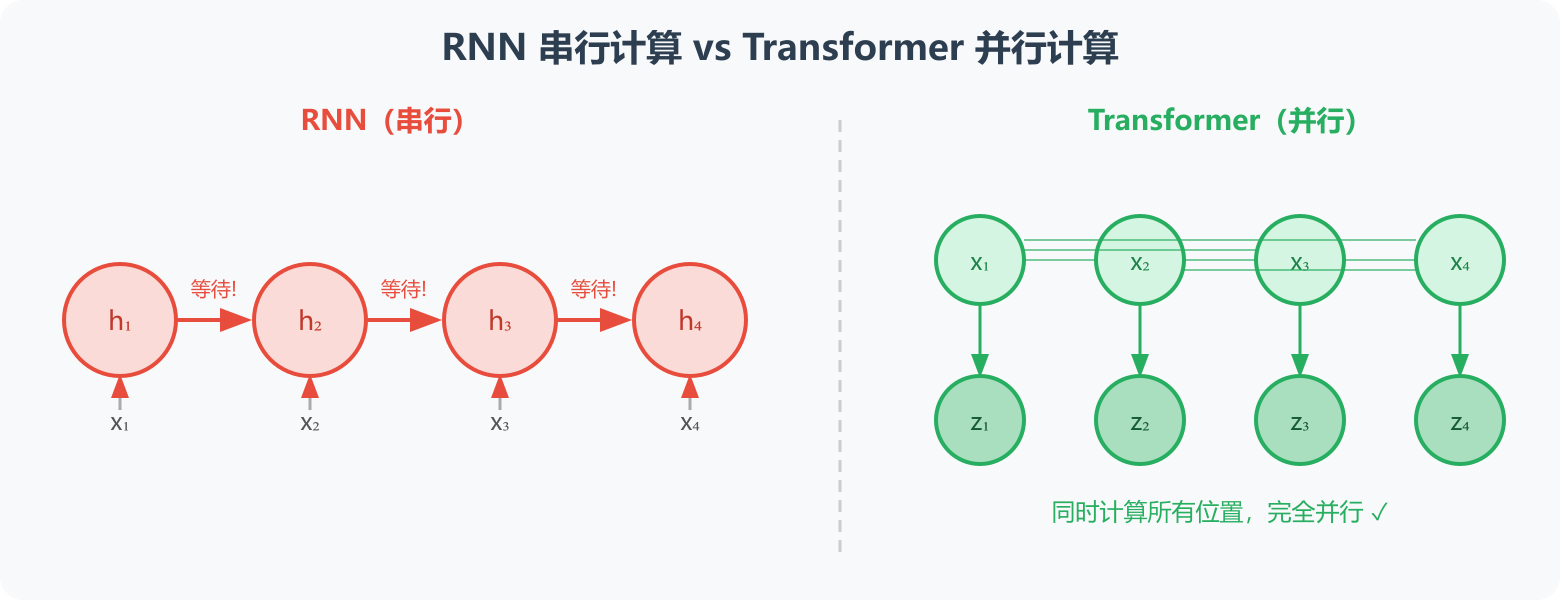
图1:RNN 串行依赖 vs Transformer 全并行------Transformer 可同时计算所有位置的特征,极大提升训练速度
1.1 串行计算,无法并行
RNN 的隐藏状态计算具有严格的时序依赖:
h1 → h2 → h3 → ... → hm必须等 h₁ 计算完才能算 h₂,无法利用 GPU 的并行计算能力,导致长序列训练耗时极长。
1.2 静态词向量:无法区分语境
传统 Word2Vec 训练完成后词向量固定不变,无法区分同词异义的情况:
a. 台湾人说"机车" → 表示"讨厌/烦人"(语气词)
b. 火车站的"机车" → 表示机械车辆(名词)两句话中的「机车」应当有不同的向量表示,而静态词向量做不到这一点。
Transformer 的核心思路 :放弃 RNN 的时序结构,完全基于 Attention 机制实现上下文感知,同时支持全并行计算。
二、Encoder-Decoder 框架
Transformer 沿用了 NLP 中经典的 **Encoder-Decoder(编码-解码)**框架,专门用于处理「序列到序列(Seq2Seq)」问题。
2.1 典型应用场景
| 任务 | 输入序列 | 输出序列 |
|---|---|---|
| 机器翻译 | 一句英文 | 对应中文 |
| 文本摘要 | 一篇文章 | 摘要段落 |
| 问答系统 | 一个问题 | 对应答案 |
2.2 核心流程
输入序列 <x1, x2, ..., xn>
↓ Encoder 编码
语义向量 C(Feature Vector)
↓ Decoder 解码
输出序列 <y1, y2, ..., ym>- Encoder :将输入序列压缩为固定维度的语义向量 C,存储了整个输入序列的信息。
- Decoder:以语义向量 C 为条件,逐步生成目标序列。
- Encoder 与 Decoder 的具体实现可任意组合(RNN/LSTM/GRU/Transformer)。
直觉理解:翻译「Bonjour」时,大脑先将其含义抽象为一个意识概念(编码),再从英语词库中找到匹配词「Hello」(解码)。这正是 Encoder-Decoder 的工作方式。
三、Self-Attention:注意力机制
Self-Attention 是 Transformer 的核心,其目标是:让模型在处理每个词时,能动态关注句子中其他词的重要程度。
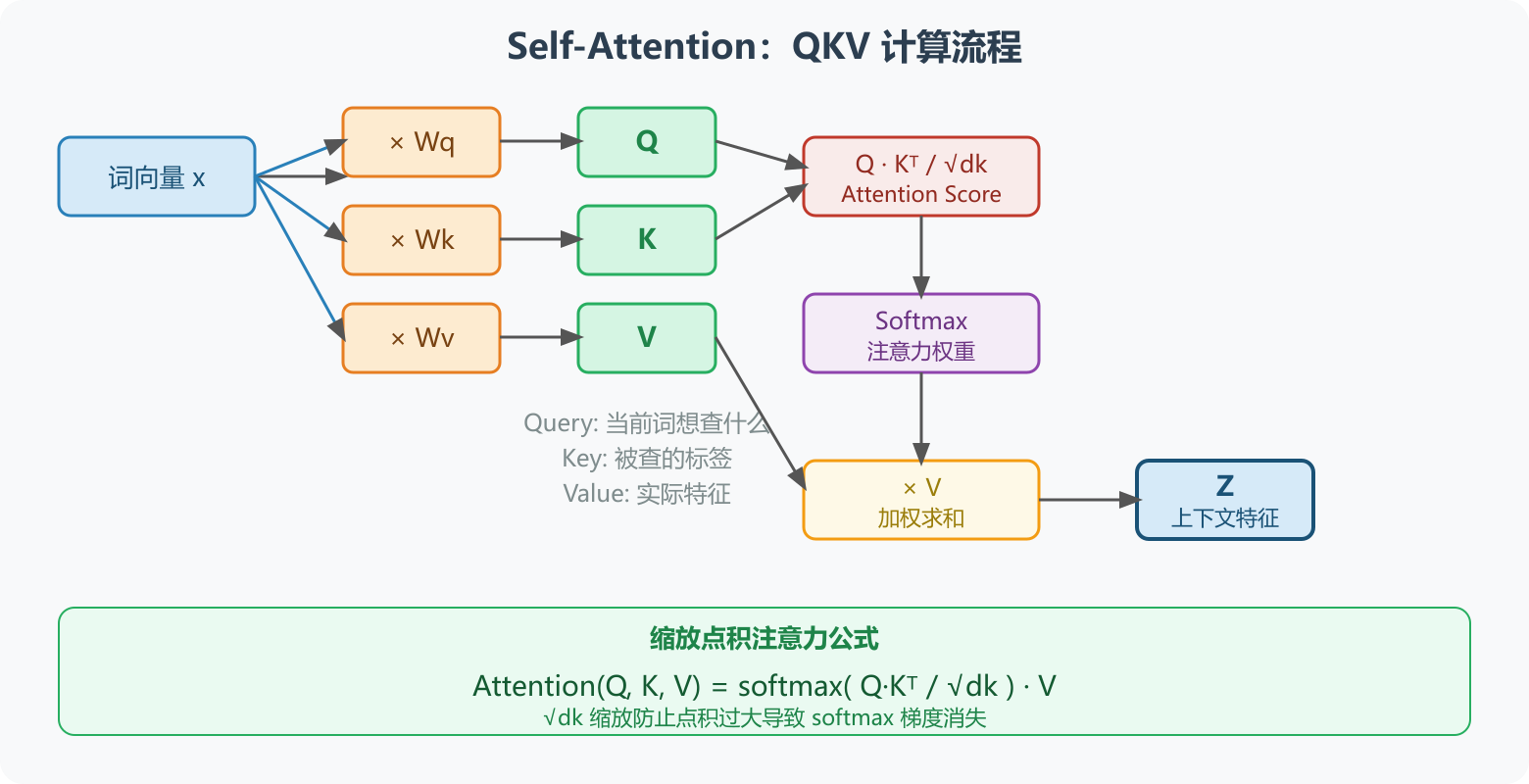
图2:Self-Attention 完整计算流程------词向量经过 Wq/Wk/Wv 投影得到 Q/K/V,再通过缩放点积注意力公式得到含上下文的特征 Z
3.1 QKV 矩阵的构建
输入词向量经过 Embedding 后,与三个可学习权重矩阵相乘,得到 Q、K、V:
词向量 x → × Wq → Q(Query,查询向量)
词向量 x → × Wk → K(Key, 被查向量)
词向量 x → × Wv → V(Value,实际特征)- Q(Query):当前词想要查询哪些信息
- K(Key):序列中每个词「等着被查」的标签
- V(Value):序列中每个词实际携带的特征信息
类比数据库:Q 相当于查询语句,K 相当于索引,V 相当于实际数据值。
3.2 Attention Score 计算
以第 1 个词(q₁)为例,计算它与序列中每个词的匹配程度:
score(q1, k1) = q1 · k1 # 第1词 与 第1词 的匹配程度
score(q1, k2) = q1 · k2 # 第1词 与 第2词 的匹配程度
score(q1, k3) = q1 · k3 # 第1词 与 第3词 的匹配程度
...3.3 缩放点积(Scaled Dot-Product Attention)
完整的 Attention 计算公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V Attention(Q,K,V)=softmax(dk QKT)V
为什么要除以 d k \sqrt{d_k} dk ?
当词向量维度 d k d_k dk 较大时, Q ⋅ K T Q \cdot K^T Q⋅KT 的数值会随维度增大而膨胀,导致 softmax 梯度趋近于 0(梯度消失)。除以 d k \sqrt{d_k} dk 起到归一化缩放作用,稳定训练。
3.4 完整计算流程
输入词向量矩阵 X
↓
Q = X·Wq K = X·Wk V = X·Wv
↓
scores = Q · Kᵀ / √dk ← 计算每对词的匹配得分
↓
weights = softmax(scores) ← 归一化为概率分布
↓
Z = weights · V ← 加权求和,得到含上下文的特征关键结论:
- 同一个词与不同词组成序列时,得到的 Z 不同(注意力分配不同)
- 整个计算过程完全可并行,不存在 RNN 的时序依赖
3.5 直觉示例
句子:Thinking Machines
z_Thinking = w(T,T)·V_Thinking + w(T,M)·V_Machines
z_Machines = w(M,T)·V_Thinking + w(M,M)·V_Machines其中 w(i,j) 是第 i 个词对第 j 个词的注意力权重。z_Thinking 就是融合了整句上下文信息后,「Thinking」的最终特征表示。
四、Multi-Head Attention:多头机制
4.1 设计动机
CNN 中使用多组卷积核,可以提取图像的多种特征(边缘、纹理、颜色......)。
同理 ,Transformer 使用多组 Q/K/V 矩阵(多个 head),让模型从多个不同角度理解词语之间的关系。
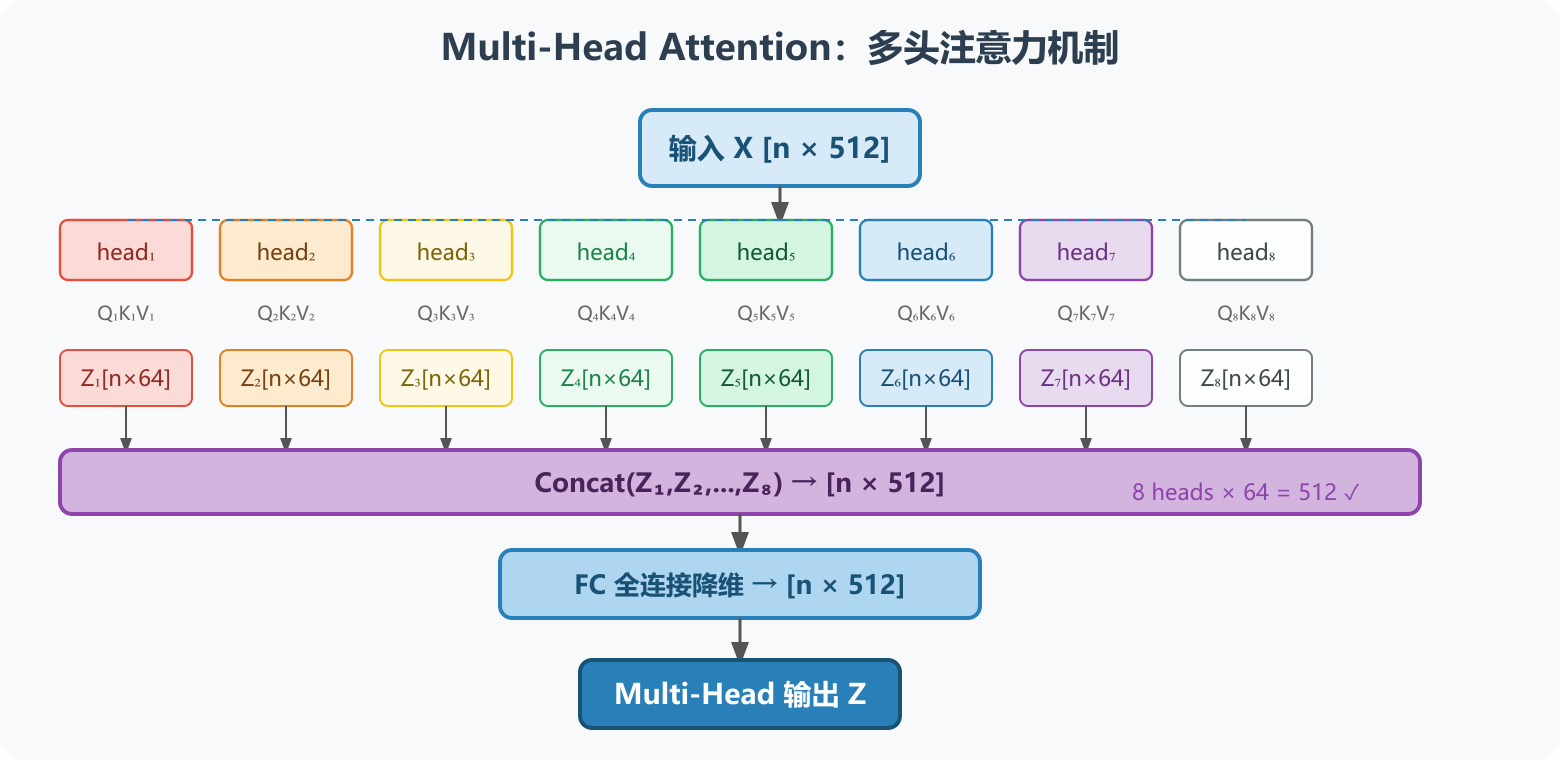
图3:Multi-Head Attention------8 组独立的 Q/K/V 分别计算注意力,得到 8 个特征矩阵后 Concat 再经 FC 降维,维度保持不变
4.2 计算流程
┌─────────────────────────────────────────────────────┐
│ Multi-Head Attention │
│ │
│ 输入 X │
│ │ │
│ ├─ head₀: Q₀K₀V₀ → Z₀ │
│ ├─ head₁: Q₁K₁V₁ → Z₁ │
│ ├─ head₂: Q₂K₂V₂ → Z₂ │
│ │ ...(共 8 个 head) │
│ └─ head₇: Q₇K₇V₇ → Z₇ │
│ │
│ Concat(Z₀, Z₁, ..., Z₇) → [Z₀|Z₁|...|Z₇] │
│ │
│ FC 全连接降维 → 最终输出 Z │
└─────────────────────────────────────────────────────┘三步操作:
- 用 8 个不同的
Wq/Wk/Wv分别计算 8 组 Attention,得到 8 个特征矩阵 Z₀~Z₇ - 将 Z₀~Z₇ 在特征维度上拼接(Concat)
- 通过全连接层(FC)降维,还原到原始维度
4.3 为什么是 8 个 head?
原论文(Attention is All You Need)中使用 h=8 个头,d_model=512,每个头的维度 d_k=d_model/h=64。这是一个经验值,实践中 BERT-Base 使用 12 头,BERT-Large 使用 16 头。
4.4 矩阵维度示意
输入 X: [seq_len, d_model] = [n, 512]
单头 Q/K/V: [seq_len, d_k] = [n, 64]
单头输出 Zᵢ: [seq_len, d_k] = [n, 64]
8头拼接后: [seq_len, 8*d_k] = [n, 512]
FC 降维后: [seq_len, d_model] = [n, 512] ← 维度不变五、位置编码(Positional Encoding)
5.1 为什么需要位置编码?
Self-Attention 本质上是在计算词与词的相关性,对词的顺序不敏感。句子「我爱你」和「你爱我」在 Attention 计算中结果相同,这显然有问题。
因此,Transformer 在词向量输入之前,需要显式地注入位置信息。
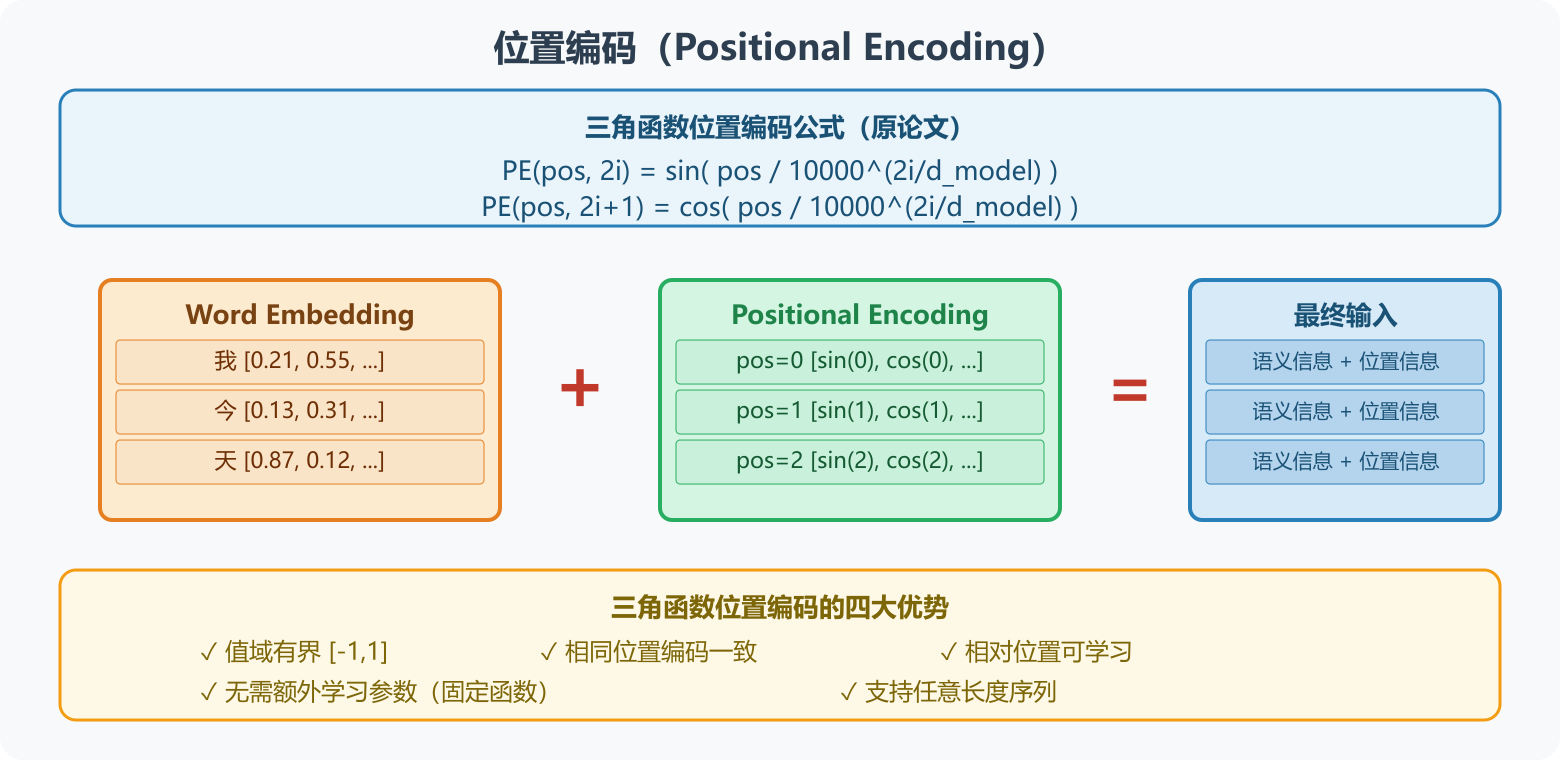
图4:位置编码------Word Embedding 与三角函数 Positional Encoding 逐元素相加,让模型同时感知语义信息与位置信息
5.2 朴素方案的缺陷
方案一:0~1 归一化
我喜欢吃洋葱 → [0, 0.16, 0.32, 0.48, 0.64, 0.80, 1]
我真的不喜欢吃洋葱 → [0, 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875, 1]问题:句子长度不同时,同一位置的编码值不同,无法比较不同句子中相同位置的词。
方案二:正整数序列
我喜欢吃洋葱 → [1, 2, 3, 4, 5, 6]问题:句子越长,后面位置的数值越大,隐含"越靠后越重要"的偏差。
5.3 Transformer 方案:三角函数位置编码
原论文采用正弦/余弦函数的组合编码:
P E ( p o s , 2 i ) = sin ( p o s 10000 2 i / d m o d e l ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)
P E ( p o s , 2 i + 1 ) = cos ( p o s 10000 2 i / d m o d e l ) PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)
参数说明:
| 参数 | 含义 |
|---|---|
pos |
词在句子中的位置(0-indexed) |
i |
词向量的维度索引,i ∈ [0, d_model/2) |
d_model |
词向量的总维度(如 512) |
2i |
偶数维度,使用 sin |
2i+1 |
奇数维度,使用 cos |
示例 :当 pos=3,d_model=128 时:
python
import numpy as np
pos = 3
d_model = 128
PE = np.zeros(d_model)
for i in range(d_model // 2):
PE[2*i] = np.sin(pos / (10000 ** (2*i / d_model))) # 偶数维度
PE[2*i+1] = np.cos(pos / (10000 ** (2*i / d_model))) # 奇数维度5.4 三角函数编码的优势
| 优点 | 说明 |
|---|---|
| 值域有界 | PE 值分布在 -1, 1,不会因位置过大而数值爆炸 |
| 相同位置一致 | 不同句子中 pos=0 的位置编码完全相同 |
| 相对位置可学 | 任意位移 k 的 PE(pos+k) 可以表示为 PE(pos) 的线性函数 |
| 无需学习 | 是固定的函数,不引入额外参数 |
5.5 位置编码的叠加方式
词向量矩阵(Word Embedding)
+
位置编码矩阵(Positional Encoding)
↓
逐元素相加(Element-wise Add)
↓
最终输入(语义信息 + 位置信息)
┌──────────────────────────────────────────────────────┐
│ Input Embedding │
│ │
│ 词: 我 今 天 去 面 试 │
│ WE: [0.2, 0.5, ...] + PE(0) │
│ [0.1, 0.3, ...] + PE(1) │
│ [0.8, 0.1, ...] + PE(2) │
│ ... │
│ ↓ Element-wise Add │
│ 最终输入 = Word Embedding + Pos Embedding │
└──────────────────────────────────────────────────────┘六、Add & Norm:残差连接与归一化
Transformer 的每个子层(Attention 层、FFN 层)后面都接有 Add & Norm 操作:
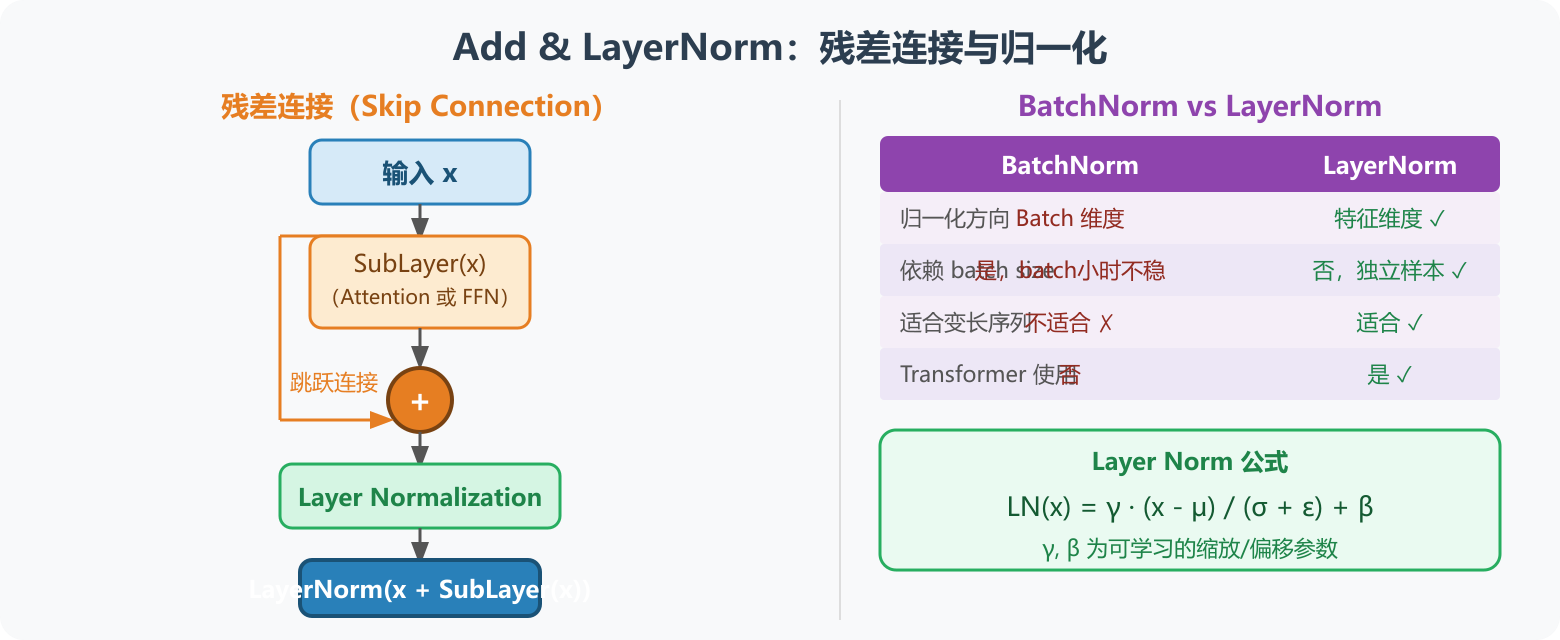
图5:Add & LayerNorm------残差连接将子层输入直接加回输出防止梯度消失,LayerNorm 在特征维度归一化优于 BatchNorm
6.1 Add:残差连接
output = LayerNorm(x + SubLayer(x))残差连接将子层的输入直接加到输出,解决深层网络梯度消失问题(与 ResNet 同理):
x (原始输入)
│
├─────────────┐
│ │
SubLayer(x) │ (跳跃连接)
│ │
└─────────────┘
↓
x + SubLayer(x)
↓
LayerNorm6.2 Normalize:层归一化
使用 Layer Normalization(而非 Batch Normalization)对每个样本的特征维度进行归一化:
L N ( x ) = γ ⋅ x − μ σ + ϵ + β LN(x) = \gamma \cdot \frac{x - \mu}{\sigma + \epsilon} + \beta LN(x)=γ⋅σ+ϵx−μ+β
- Layer Norm 在特征维度上归一化,不依赖 batch size,适合变长序列
- Batch Norm 在batch 维度上归一化,不适合 NLP(序列长度不一)
七、Feed Forward 层
每个 Encoder/Decoder 块中,Attention 子层之后跟着一个 Position-wise Feed-Forward Network(FFN):
python
# 两层全连接 + ReLU
FFN(x) = max(0, x·W₁ + b₁)·W₂ + b₂- 第一层 :将维度从
d_model=512升至d_ff=2048(扩展 4 倍) - 激活函数:ReLU(原论文)或 GELU(BERT 使用)
- 第二层 :将维度从
d_ff=2048降回d_model=512
FFN 对序列中每个位置独立地做相同变换(Position-wise),不跨位置混合信息------跨位置的信息交互已由 Attention 层完成。
八、Transformer 完整架构
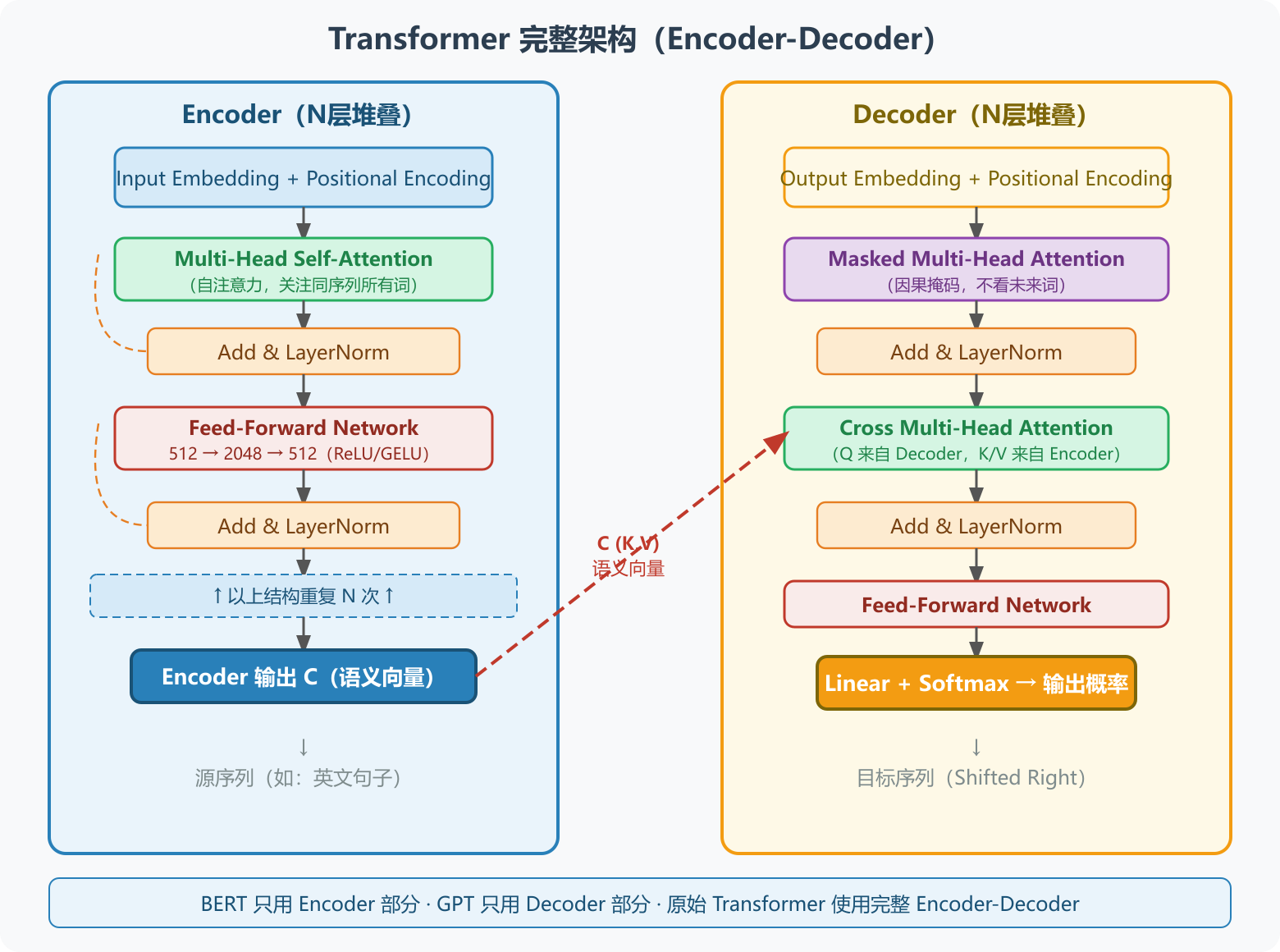
图6:Transformer 完整架构------左侧 Encoder 处理源序列,右侧 Decoder 处理目标序列并通过 Cross-Attention 接收 Encoder 的语义向量 C
8.1 Encoder 单层结构
输入 X(Word Embedding + Positional Encoding)
↓
┌─────────────────────────────┐
│ Multi-Head Attention │
│ (Self-Attention) │
└─────────────────────────────┘
↓
Add & LayerNorm
↓
┌─────────────────────────────┐
│ Feed-Forward Network │
│ (两层 FC + ReLU/GELU) │
└─────────────────────────────┘
↓
Add & LayerNorm
↓
Encoder 单层输出8.2 Decoder 单层结构
目标序列输入(Shifted Right)
↓
┌─────────────────────────────┐
│ Masked Multi-Head Attention│ ← 遮蔽未来词(因果掩码)
└─────────────────────────────┘
↓
Add & LayerNorm
↓
┌─────────────────────────────┐
│ Cross Multi-Head Attention │ ← Q 来自 Decoder,K/V 来自 Encoder
└─────────────────────────────┘
↓
Add & LayerNorm
↓
┌─────────────────────────────┐
│ Feed-Forward Network │
└─────────────────────────────┘
↓
Add & LayerNorm
↓
Decoder 单层输出8.3 整体架构图(N 层堆叠)
┌──────────────────────────────────────────────────────────────┐
│ Transformer │
│ │
│ Input Output (Shifted Right) │
│ │ │ │
│ [Embedding + PE] [Embedding + PE] │
│ │ │ │
│ ┌──┴──────────────┐ ┌────────┴──────────┐ │
│ │ Encoder × N │ │ Decoder × N │ │
│ │ │ │ │ │
│ │ ┌────────────┐ │ ──── C ──→ │ ┌───────────────┐ │ │
│ │ │MH Attention│ │ │ │Masked MH Attn │ │ │
│ │ └────────────┘ │ │ └───────────────┘ │ │
│ │ ┌────────────┐ │ │ ┌───────────────┐ │ │
│ │ │ Add&Norm │ │ │ │ Cross MH Attn│ │ │
│ │ └────────────┘ │ │ └───────────────┘ │ │
│ │ ┌────────────┐ │ │ ┌───────────────┐ │ │
│ │ │ FFN │ │ │ │ FFN │ │ │
│ │ └────────────┘ │ │ └───────────────┘ │ │
│ │ ┌────────────┐ │ │ ┌───────────────┐ │ │
│ │ │ Add&Norm │ │ │ │ Add&Norm │ │ │
│ │ └────────────┘ │ │ └───────────────┘ │ │
│ └─────────────────┘ └───────────────────┘ │
│ │ │
│ Linear + Softmax │
│ │ │
│ Output Probabilities │
└──────────────────────────────────────────────────────────────┘BERT 只使用 Encoder 部分 ,GPT 只使用 Decoder 部分,原始 Transformer 则是完整的 Encoder-Decoder。
九、Outputs (Shifted Right):解码器自回归
9.1 概念
"Shifted Right"是解码器的训练机制:将目标序列整体右移一位 ,并在最左端插入起始符 <sos>,作为解码器的输入。
9.2 以翻译为例
任务:将「我爱中国」翻译为「I love China」
| 时间步 | 解码器输入 | 预测目标 |
|---|---|---|
| t=1 | <sos> |
I |
| t=2 | <sos> I |
love |
| t=3 | <sos> I love |
China |
| t=4 | <sos> I love China |
<eos> |
目标序列: I love China <eos>
↑ ↑ ↑ ↑
解码器输入: <sos> I love China ← 右移一位9.3 Masked Attention 的作用
在训练时,解码器能看到完整的目标序列(Teacher Forcing),但为了防止「作弊」(提前看到未来词),使用 Causal Mask(下三角掩码) 遮住未来位置:
时间步 t=2,只能看 <sos> 和 I,不能看 love、China十、从 Transformer 到 BERT
10.1 BERT 的核心改进
BERT(Bidirectional Encoder Representations from Transformers)在 Transformer Encoder 基础上引入了两个预训练任务:
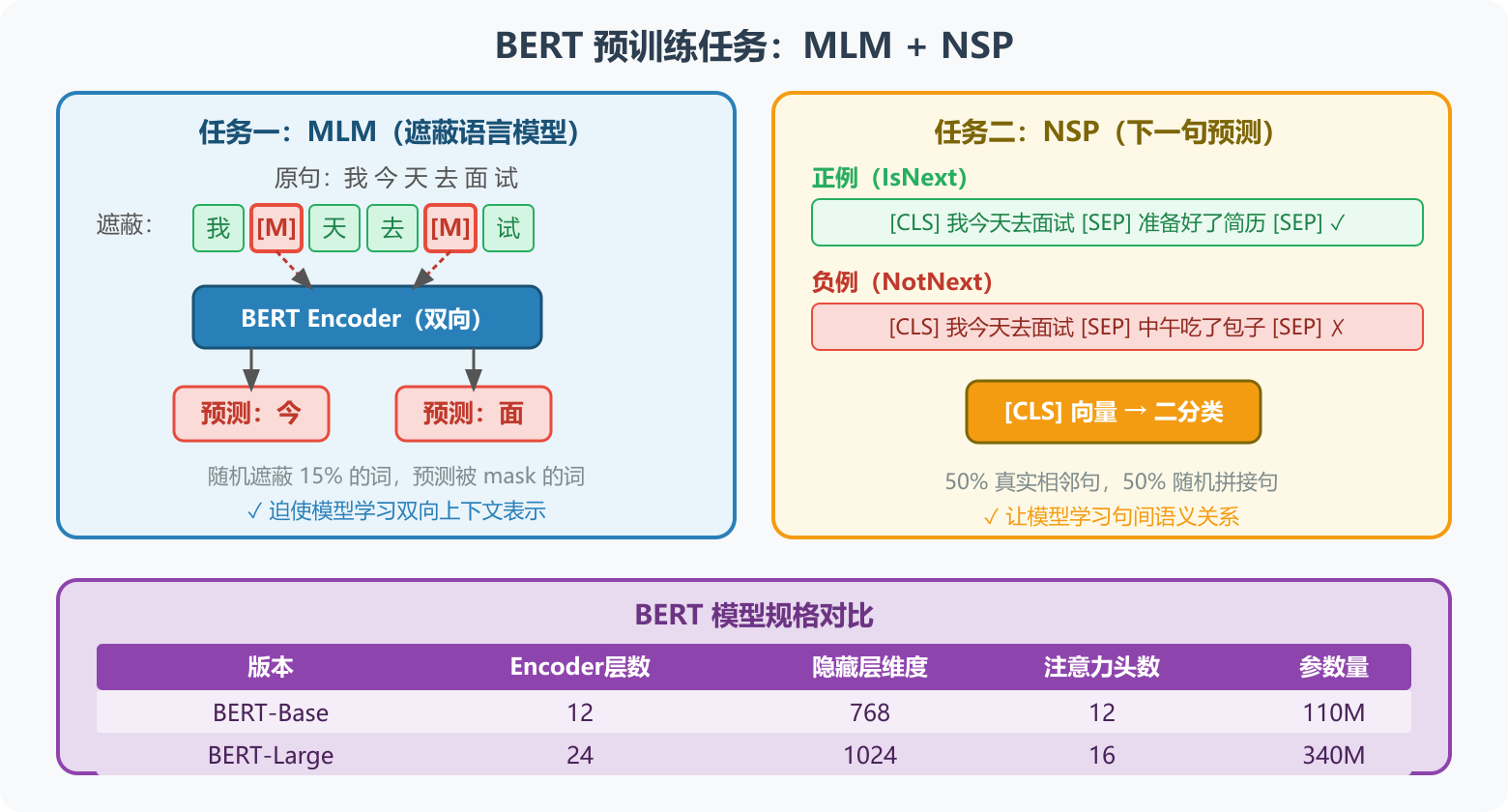
图7:BERT 两大预训练任务------MLM 随机遮蔽 15% 的词让模型学习双向上下文,NSP 让模型学习句间语义关系
任务一:Masked Language Model(MLM,遮蔽语言模型)
随机遮蔽输入序列中 15% 的词,让模型预测被遮蔽的词:
原句: 我 今 天 去 面 试
遮蔽: 我 [M] 天 去 [M] 试 ← 今 和 面 被 mask 掉
预测: 今 面 ← 模型预测 mask 位置的词实践中通常 mask 单个字而非词组,因为词组候选集过大(今天、明天、后天......),训练收敛困难。
任务二:Next Sentence Prediction(NSP,下一句预测)
判断两个句子是否语义上连续:
[CLS] 我 今 天 去 面 试 [SEP] 准 备 好 了 简 历 [SEP] → 标签: YES(连续)
[CLS] 我 今 天 去 面 试 [SEP] 中 午 吃 了 包 子 [SEP] → 标签: NO(不连续)特殊 Token 说明:
| Token | 作用 |
|---|---|
[CLS] |
位于序列开头,其最终向量用于分类任务(如 NSP) |
[SEP] |
分隔符,标记每个句子的结束 |
10.2 BERT 的双向性
| 模型 | 方向 | 训练目标 |
|---|---|---|
| GPT | 单向(从左到右) | 预测下一个词 |
| ELMo | 双向(两个单向 LSTM 拼接) | 语言模型 |
| BERT | 真正双向(Transformer Encoder) | MLM + NSP |
BERT 在预测一个词时,同时考虑该词前后的所有上下文,因此特征更丰富。
10.3 BERT 的模型规格
| 版本 | Encoder 层数 (L) | 隐藏层维度 (H) | 注意力头数 (A) | 参数量 |
|---|---|---|---|---|
| BERT-Base | 12 | 768 | 12 | 110M |
| BERT-Large | 24 | 1024 | 16 | 340M |
10.4 下游任务微调(Fine-tuning)
BERT 预训练完成后,可通过微调适配各类 NLP 下游任务:
┌────────────────────────────────────────────────────┐
│ BERT 微调策略 │
│ │
│ 文本分类 → 取 [CLS] 向量 + 分类头 │
│ 序列标注 → 取每个 token 的向量 + 标注头 │
│ 问答系统 → 取答案 span 的起止位置向量 │
│ 句子相似度 → 取 [CLS] 向量 + 相似度计算 │
└────────────────────────────────────────────────────┘十一、总结
核心模块速查表
| 组件 | 作用 | 关键公式/参数 |
|---|---|---|
| Input Embedding | 词 ID → 稠密向量 | d_model = 512 |
| Positional Encoding | 注入位置信息 | sin/cos 三角函数 |
| Self-Attention | 计算词间相关性 | softmax ( Q K T / d k ) V \text{softmax}(QK^T/\sqrt{d_k})V softmax(QKT/dk )V |
| Multi-Head Attention | 多角度特征提取 | h=8 头,各 d_k=64 |
| Add & LayerNorm | 残差 + 归一化 | 防梯度消失,稳定训练 |
| Feed-Forward Network | 非线性变换 | 512 → 2048 → 512 |
| Masked Attention | 解码器防作弊 | 下三角 Causal Mask |
Transformer 的革命性意义
传统 RNN/LSTM
✗ 串行计算,无法并行
✗ 长距离依赖梯度消失
✗ 静态词向量,语境无关
Transformer
✓ 全并行计算,训练速度大幅提升
✓ Self-Attention 直接建立任意距离词对的依赖
✓ 动态上下文词向量,同词异义
✓ 可扩展堆叠,催生 BERT / GPT / T5 等大模型Transformer 是现代大语言模型(LLM)的基础架构。理解 Transformer,就是理解 ChatGPT、LLaMA、BERT 等一切现代 NLP 模型的核心。
参考文献
- Vaswani A. et al. Attention Is All You Need. NeurIPS 2017.
- Devlin J. et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019.
- The Illustrated Transformer -- Jay Alammar
- Hugging Face BERT 文档