目录
[11.5 主分量作为特征描述符(Principal Components As Feature Descriptors)](#11.5 主分量作为特征描述符(Principal Components As Feature Descriptors))
[11.6 全图像特征(Whole-Image Features)](#11.6 全图像特征(Whole-Image Features))
[11.6.1 Harris-Stephens角点检测子(The Harris-Stephens Corner Detector)](#11.6.1 Harris-Stephens角点检测子(The Harris-Stephens Corner Detector))
[11.6.2 最大稳定极值区域(MSERs)( Maximally Stable Extremal Regions (MSERs))](#11.6.2 最大稳定极值区域(MSERs)( Maximally Stable Extremal Regions (MSERs)))
[11.7 缩放不变性特征变换(Scale-Invariant Feature Transform (SIFT))](#11.7 缩放不变性特征变换(Scale-Invariant Feature Transform (SIFT)))
[11.7.1 缩放空间(Scale Space)](#11.7.1 缩放空间(Scale Space))
[11.7.2 检测局部极值(Detecting Local Extrema)](#11.7.2 检测局部极值(Detecting Local Extrema))
[11.7.2.1 求得初始关键点(Finding the Initial Keypoints)](#11.7.2.1 求得初始关键点(Finding the Initial Keypoints))
[11.7.2.2 提高关键点定位的准确性(Improving the Accuracy of Keypoint Locations)](#11.7.2.2 提高关键点定位的准确性(Improving the Accuracy of Keypoint Locations))
[11.7.2.3 消除边缘响应(Eliminating Edge Responses)](#11.7.2.3 消除边缘响应(Eliminating Edge Responses))
[11.7.3 关键点方向(Keypoint Orientation)](#11.7.3 关键点方向(Keypoint Orientation))
[11.7.4 关键点描述符(Keypoint Descriptors)](#11.7.4 关键点描述符(Keypoint Descriptors))
[11.7.5 SIFT算法概要(Summary of the SIFT Algorithm)](#11.7.5 SIFT算法概要(Summary of the SIFT Algorithm))
11.5 主分量作为特征描述符( Principal Components As Feature Descriptors**)**
本节内容适用于边界和区域。它与我们之前的讨论有所不同,因为特征是基于多幅图像的。假设我们给定一幅彩色图像的三个分量图像。这三幅图像可以作为一个整体来处理,方法是将每一组三个对应的像素表示为一个向量,如第 11.1 节所述。如果我们总共有 n 幅配准图像 ,那么所有图像中相同空间位置的对应像素可以排列成一个 n 维向量:
(11-46)
在整个本节中,我们都假设,所有向量都是列向量( 即 ,n × 1 矩阵 )。我们可以利用转置将其写一行的形式,即 ,其中, 表示转置(transpose)。
我们可以像构建强度直方图时那样,将这些向量视为随机变量。唯一的区别在于,我们现在讨论的是均值向量和协方差矩阵,而不是随机变量的均值和方差。总体(population)均值向量定义为
(11-47)
其中,E { x } 是 x 的期望值,下标表示 m 与 x 向量的总体关联。回顾一下,向量或矩阵的期望值是通过对每一个元素取期望值得到的。
向量总体的协方差矩阵定义为
(11-48)
因为 x 是维的,因此, 是一个 n × n 矩阵。
的元素
是
的方差,即总体中 x 向量的第 i 个分量,而
的元素
是这些向量的元素
和
之间的协方差。矩阵
是实对称的。若元素
和
是不相关的,则其协方差是0 ,因此
, 从而导致了一个对角协方差矩阵。
因为 是一个实对称阵,因此,求得一个 n 个正交特征向量集总是可能的( Noble 和Daniel 1988))。 令
和
(i = 1 , 2 , ... , n ) 分别为
的特征向量和其相应的特征值,(注:根据定义,一个 n × n 矩阵 C 满足方程
),排降序排列(出于方便),使得
( j = 1 , 2 , ... , n -- 1 ) ,令 A 为一个其行由
的特征向量构成的矩阵,且向量元素按其特征值降序值排列,因此,A 的第一行是与最 大特征值对应的特征向量。
假设我们将A 当作一个变换矩阵,其将 x 映射到 y ,即
(11-49)
这个表达式称为 Hotelling 变换,你很快将会看到,它有一些非常有趣且实用的属生。
不难证明(见问题 11.25),从这个变换导出的 y 向量之均值为 0 ;即
(11-50)
根据基本矩阵论可以推出,y 的协方差矩阵可根据 A 和 求得,即
(11-51)
此外,由于 A 的构成方式, 是一个对角矩阵,其沿主对角线上的元素是
的特征值;即
(11-52)
该协方差矩阵的非对角线元素均为 0,因此 y 向量的元素之间不相关。谨记, 是
的特征值,而沿一个对角矩阵的主对角线的元素是其特征值( Noble 和 Daniel 1988 )。因此,
和
具有相同的特征值。
Hotelling 变换的另一个重要属性处理基于 y 重建 x 。因为 A 的行是正交向量,因此可推断出 ,而任一向量 x 都可以根据其相应的 y 恢复,公式为
(11-53)
但假设,我们不使用 的所有特征向量, 而是使用与 k 个最大的特征向值对应的特征向量构成一个矩阵
, 即 k × n 变换矩阵。y 向量将变为k 维,公式 (11-53) 给出的重建将不再精确( 这与我们在第 11.3 节中用几个Fourier系数描述边界的过程有些类似 )。
使用 的向量重建公式是
(11-54)
可以证明, x 和 之间的均方误差计算公式为
(11-55)
公式 (11-55) 表明 ,若 k = n ( 即变换中所有的特征向量都使用 ),则错误是零。因为 λj 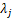 是单调递减的。公式 (11-55) 还表明,通过选择与最大特征值相关的 k 个特征向量,可以最小化误差。因此,Hotelling变换是最优的,因为它最小化了向量 x 与其近似值
是单调递减的。公式 (11-55) 还表明,通过选择与最大特征值相关的 k 个特征向量,可以最小化误差。因此,Hotelling变换是最优的,因为它最小化了向量 x 与其近似值 之间的均方误差。
由于使用了对应于最大特征值的特征向量,Hotelling变换也被称为主成分变换。
例子 11.16 :利用主分量分析进行图像表征 。
图 11.38 显示了六幅多光谱卫星图像,分别对应六个光谱波段:可见蓝光波段(450--520 nm)、可见绿光波段(520--600 nm)、可见红光波段(630--690 nm)、近红外波段(760--900 nm)、中红外波段(1550--1750 nm)和热红外波段(10400--12500 nm)。本示例旨在说明如何使用主分量作为图像特征。
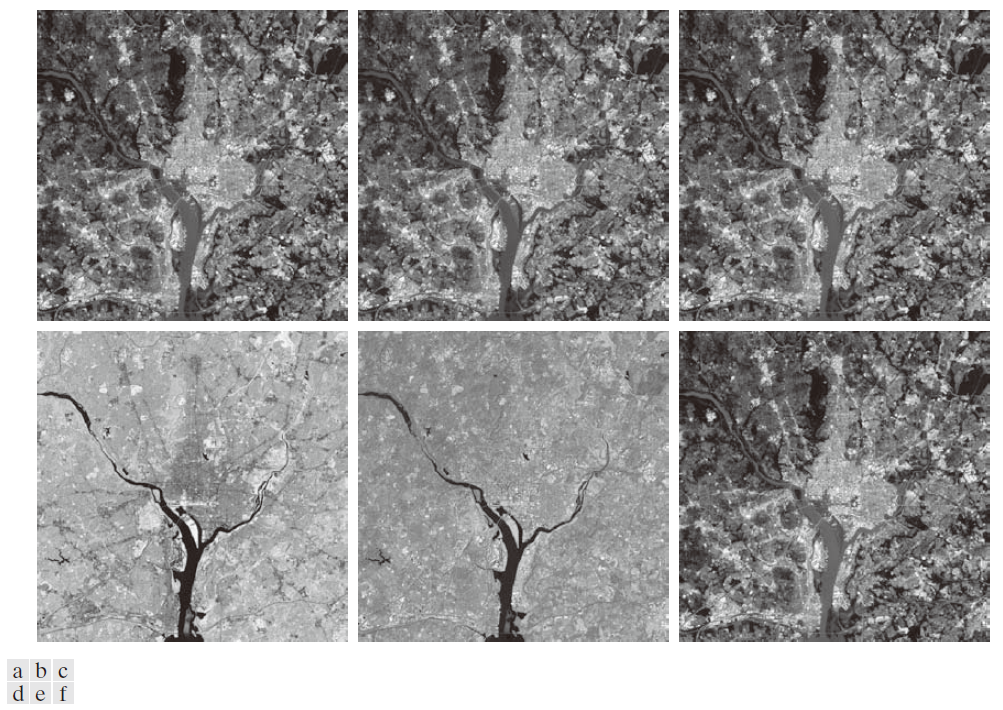
----------------------图 11.38:(a) 可见光蓝光波段、(b) 可见光绿光波段、(c)可见光红光波段、(d) 近红外波段、(e) 中红外波段和 ( f ) 热红外波段的多光谱图像。(图片由NASA提供。)-------------------------------------------------------------
如图 11.39 所示,图像的排列方式使得每组对应像素构成一个六元向量 x ,如本节前面所述。本例中的图像大小为 564 × 564 像素,因此总体由 个向量组成,从中计算均值向量、协方差矩阵以及相应的特征值和特征向量。然后,将特征向量用作矩阵 A 的行,并使用公式 (11-49) 得到一组 y 向量。类似地,我们使用公式 (11-51) 得到
。表 11.6 显示了该矩阵的特征值。请注意前两个特征值的主导地位。
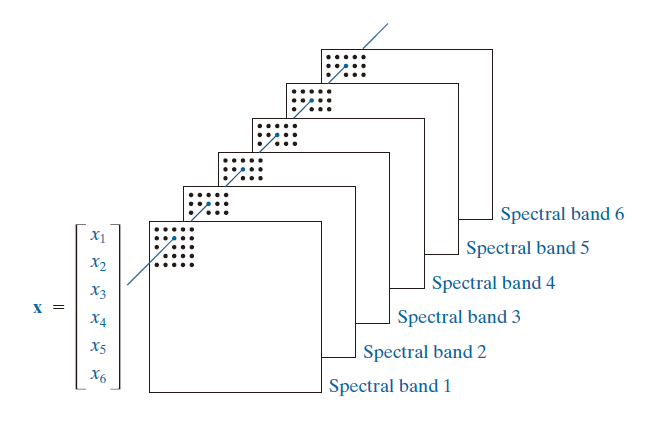
----------------图 11.39:利用六幅图像中对应像素形成特征向量。----------------

-----------------表 11.6:从图11.38中的图像获得的 的特征值--------------
利用上一段提到的y 向量生成了一组主分量图像(图像是通过反向应用图11.39中的向量构建而成的)。图11.40展示了结果。图11.40(a)由318,096个y 向量的第一主分量构成,图11.40(b)由这些向量的第二主成分构成,依此类推,因此这些图像与图11.38中的原图像大小相同。主分量图像最显著的特征是,大部分对比度细节集中在前两幅图像中,之后迅速减少。这可以通过观察特征值来解释。如表11.6所示,前两个特征值远大于其他特征值。由于特征值是 y 向量元素的方差,而方差是强度对比度的度量,因此由对应于最大特征值的向量分量构成的图像具有最高的对比度也就不足为奇了。事实上,图 11.40 中的前两幅图像就占了总方差的约 89% 。其余四幅图像对比度较低,因为它们仅占剩余的 11% 。
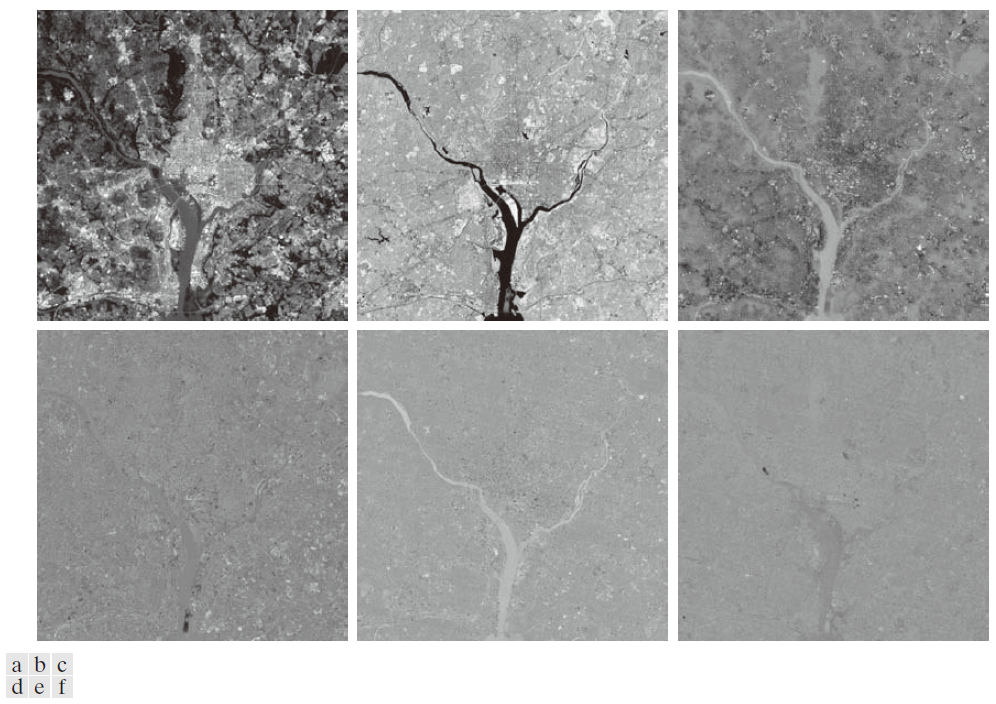
---------------------图 11.40:利用公式(11-49)计算得到的向量,得到六个主分量图像。向量通过反向应用图11.39转换为图像。------------------------------------
根据公式 (11-54) 和 (11-55),如果我们使用矩阵 A 中的所有特征向量,就可以从主分量图像重建原图像,且原图像与重建图像之间的误差为零(即,图像完全相同)。如果目标是存储和/或传输主分量图像和变换矩阵,以便后续重建原图像,则存储和/或传输所有主分量图像是没有意义的,因为这样做没有任何好处。然而,假设我们只保留和/或传输两个主分量图像,那么就可以显著节省存储和/或传输空间(矩阵 A 的大小将为 2 × 6,因此其影响可以忽略不计)。
图 11.41 显示了利用对应于最大特征值的两个主分量图像重建六幅多光谱图像的结果。前五幅图像的外观与图 11.38 中的原图像非常接近,但第六幅图像并非如此。原因是原第六幅图像实际上是模糊的,而用于重建的两个主分量图像是清晰的,因此模糊的"细节"丢失了。图 11.42 显示了原图像和重建图像之间的差异。图 11.42 中的图像经过增强处理,以突出显示它们之间的差异。如果不进行增强处理,前五幅图像几乎全黑,而第六幅(差异)图像则显示出最大的变化。
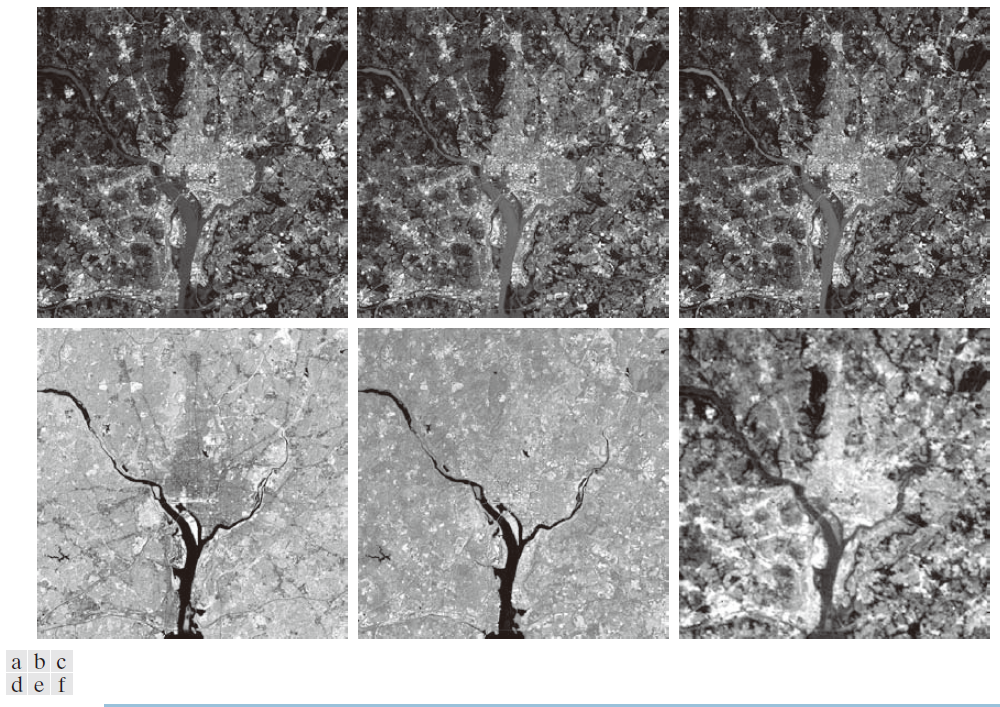
----------------------图 11.41:仅使用对应于两个最大特征值主分量向量的两个主分量图像重建多光谱图像。将这些图像与图 11.38 中的原图像进行比较。--------------
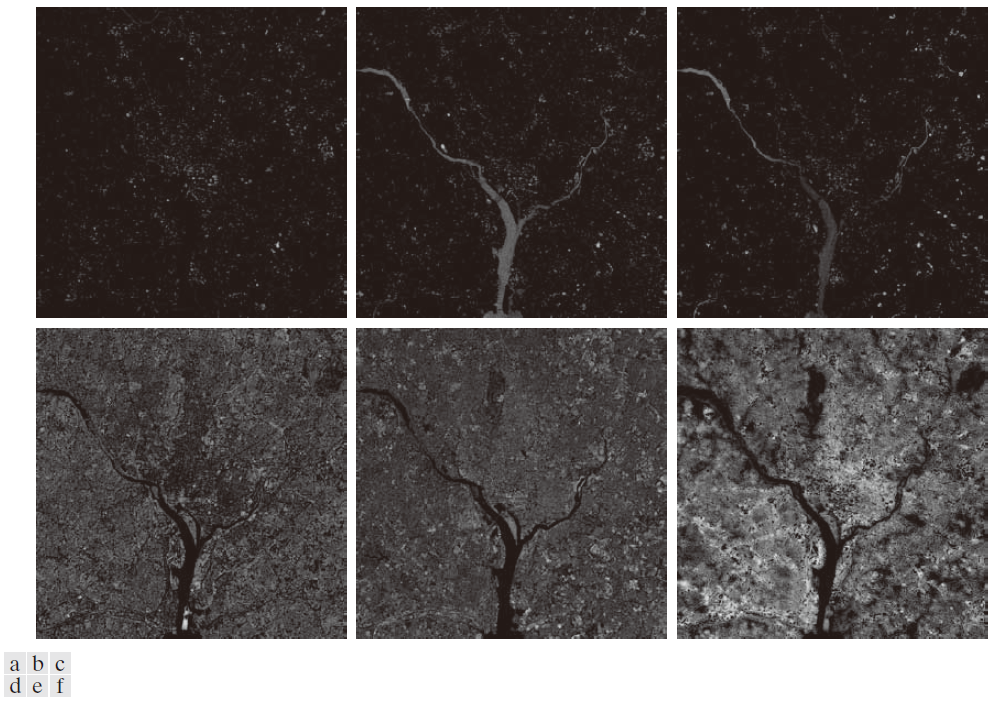
----------------------图 11.42:原图像与重建图像之间的差异。所有图像均已缩放至完整的 0, 255 范围,以便于进行视觉分析。----------------------------------
例子 11.17 :利用主分量分析进行图像表征 。
正如本章前面提到的,特征描述符应尽可能不受尺寸、平移和旋转变化的影响。主分量分析提供了一种便捷的方法来对边界和/或区域进行归一化,以消除这三个变量变化的影响。考虑图 11.43 中的物体,并假设其尺寸、位置和方向(旋转)是任意的。区域中(或其边界上的)点可以视为二维向量 ,其中,
和
是任意目标点的坐标。区域中或边界上的所有点构成一个二维向量总体,其可用于计算协方差矩阵
和均值向量
。
的一个特征向量指向总体最大方差(数据离散程度)的方向,而第二个特征向量与第一个特征向量垂直,如图 11.43(b) 所示。就本文讨论而言,公式 (11-49) 中的主成分变换实现了两个目标:(1) 它将变换后的坐标系中心建立为总体的质心(均值),因为每一个 x 都减去了
;(2) 它生成的 y 坐标(向量)是 x 坐标的旋转版本,从而使数据与特征向量对齐。如果我们定义一个
坐标系,使得
沿第一个特征向量方向,
沿第二个特征向量方向,那么得到的几何形状如图 11.43(c) 所示。即,主要数据方向与新的坐标系对齐。无论物体的大小、平移或旋转如何,只要区域或边界内的所有点都经历相同的变换,就能得到相同的结果。如果我们希望对变换后的数据进行尺寸归一化,则需要将坐标除以相应的特征值。
如图 11.43(c) 所示,y 轴坐标系中的点可以有正值也可以有负值。要将所有坐标转换为正值,我们只需从所有 y 向量中减去向量 。为了将所得点位移,使它们全部大于 0,如图 11.43(d) 所示,我们将一个向量
( 其中,a ,b 均大于 0 ) 加入到其上。
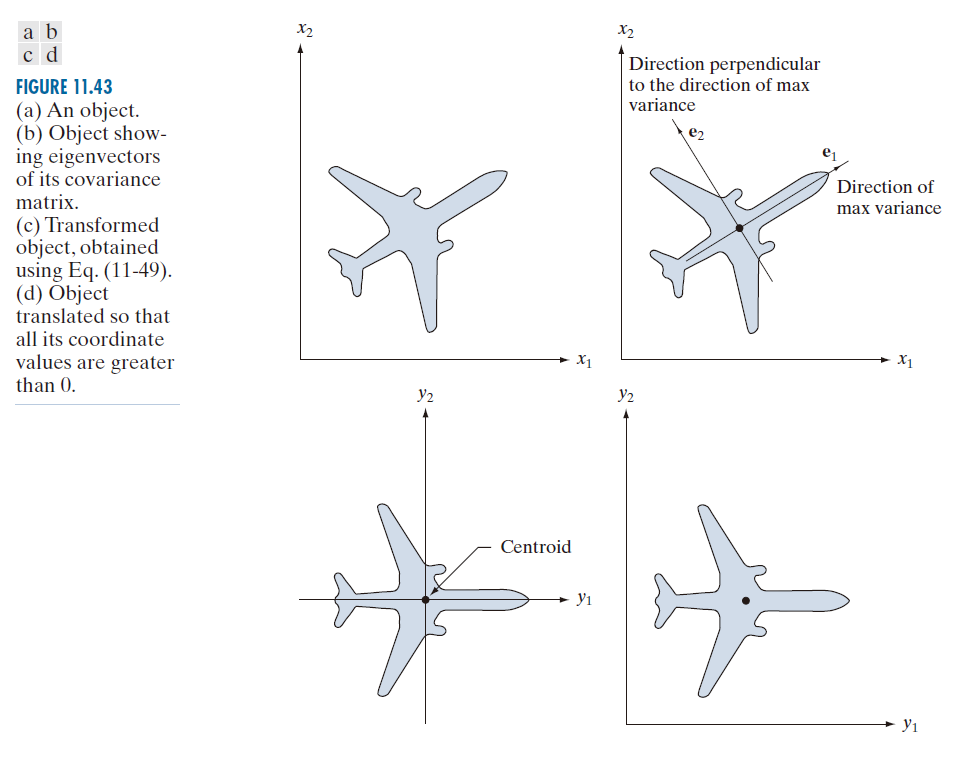
---------------------图 11.43:(a) 一个物体。(b) 显示该物体协方差矩阵特征向量的物体。(c) 使用公式(11-49)变换后的物体。(d) 经过平移后,使其所有坐标值均大于0的物体。--------------------------------------------------------------------
尽管前面的讨论在原理上很简单,但具体操作却常常令人困惑。因此,我们用一个简单的手动图示来结束这个例子。图 11.44(a) 显示了四个点,坐标分别为 (1, 1),(2, 4),(4, 2) 和 (5, 5)。该总体的均值向量、协方差矩阵和归一化(单位长度)特征向量分别为:
,
和
,
相应的特征值是 。图 1.44(b) 展示了叠加在数据上的特征向量。根据公式 (11-49),变换点 (y ) 是
,和
。 这些点绘制在图 11.44(c) 中。请注意,它们与 y 轴对齐,并且具有小数值。在处理图像时,坐标值通常是整数,因此需要将所有值四舍五入到最接近的整数。图 11.44(d) 显示了四舍五入到最接近整数的点,并且它们的位置也进行了平移,使得所有坐标值都像原图一样是大于 0 的整数。
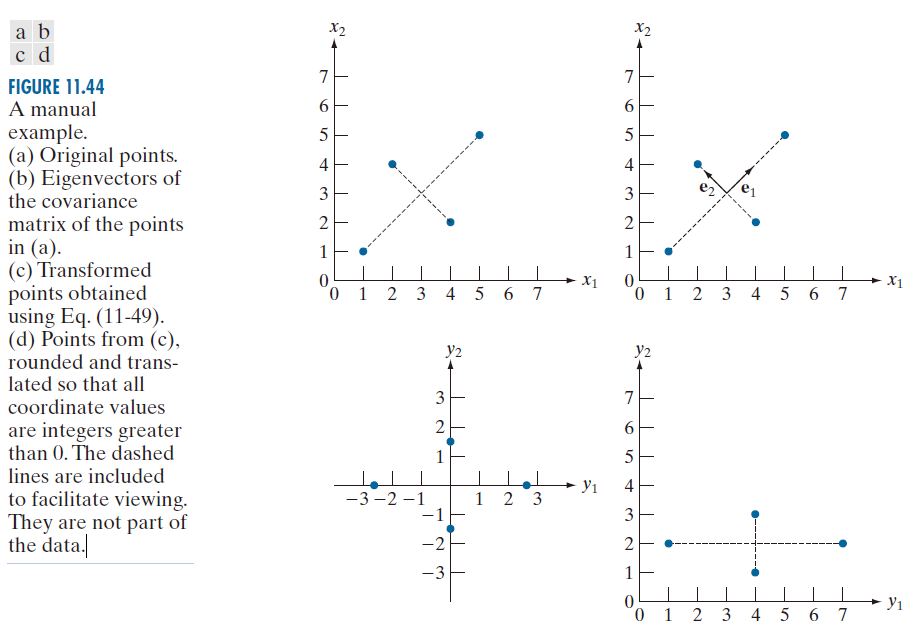
-------------图 11.44:手动示例。(a) 原始点。(b) (a) 中点的协方差矩阵的特征向量。(c) 使用公式 (11-49) 得到的变换点。(d) (c) 中的点,经过四舍五入和平移,使所有坐标值均为大于 0 的整数。虚线仅用于便于观察,并非数据的一部分。--------------
11.6 全图像特征( Whole-Image Features**)**
第 11.2 节至 11.4 节介绍的描述符非常适用于某些应用(例如工业检测),在这些应用中,可以使用诸如第 10 章和第 11 章讨论的方法可靠地分割各个区域。除了示例 11.17 中的应用外,第 11.5 节中的主分量特征向量与前面的内容有所不同,因为它们基于多幅图像。但即使是这些描述符也仅限于一组对应的像素。在某些应用中,例如在图像数据库中搜索匹配项(例如人脸识别),图像之间的差异非常大,以至于第 10 章和第 11 章中的方法不再适用。
**图像处理领域的现状是,随着任务复杂性的增加,适用于这些任务的技术数量反而减少。**当处理适用于整幅图像(这些图像属于一个大型图像族)的特征描述符时,这种情况尤为突出。本节将讨论目前用于此目的的两种主要特征检测方法。一种方法基于角点检测,另一种方法则针对图像中的整个区域。然后,在 11.7 节中,我们将介绍一种专门针对此类特征而设计的特征检测和描述方法。
11.6.1 Harris-Stephens角点检测子 ( The Harris-Stephens Corner Detector**)**
在直观上,我们认为拐角是曲线中方向的快速改变。拐角是非常有效的特征,因为它们特征鲜明且对视角具有较强的不变性。由于这些特性,拐角常用于匹配图像特征,应用于自主导航的跟踪、立体视觉算法和图像数据库查询等应用中。
本节讨论Harris和Stephens 1988提出的角点检测算法。Harris-Stephens (HS)角点检测子的基本思想如图11.45所示。其基本方法是:通过在图像上滑动一个小窗口来检测角点,这与我们在第3章中对空间滤波所做的类似。检测子窗口旨在计算强度变化。我们关注三种情况:(1) 所有方向上强度变化为零(或很小(的区域,这种情况发生在窗口位于恒定(或近似恒定)区域时,如图11.45中的A位置所示;(2) 一个方向上强度变化较大,而垂直方向上强度变化为零(或很小)的区域,这种情况发生在窗口跨越两个区域的边界时,如图B位置所示;(3) 所有方向上强度变化显著的区域,这种情况发生在窗口包含角点(或孤点)时,如图C位置所示。HS角点检测子是一个数学模型,旨在区分这三种情况。
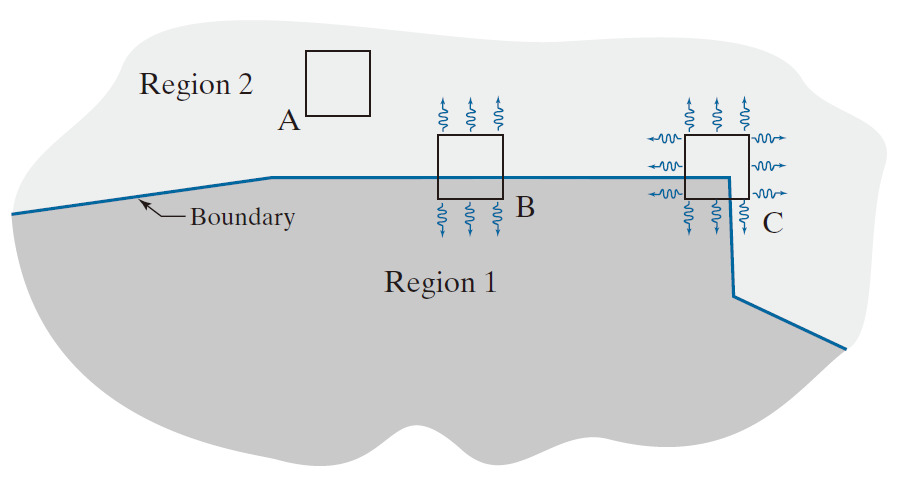
----------------------图 11.45:图示展示了Harris-Stephens角点检测子在三种子区域( A(平面)、B(边缘)和C(角点))中的工作原理。波浪形箭头以图形方式表示检测子在所示三个区域中移动时的方向响应。---------------------------------------------
令 f 表示一幅图像,令 f ( s , t ) 表示由 ( s , t ) 值定义的图像块 (patch)。大小相同但平移了 ( x , y ),用 f ( s + x ,t + y) 表示。则这两个图像块之间的差平方之权重和为
(11-56)
其中,w ( s , t) 是即将讨论的权重函数。平移图像块可以用一个Taylor 展开式的线性项近似表示,即
(11-57)
其中, 和
,二者均在 ( s , t) 处进行计算。则我们可将公式 (11-56) 写成
(11-58)
这个公式可以按矩阵形式写成
(11-59)
其中,
(11-60)
和
(11-61)
矩阵 M 有时称为Harris矩阵。需要注意的是,其各项均在 ( s , t ) 处求值。如果 w ( s , t ) 是各向同性的,则 M 是对称的,因为 A 是对称的。HS 检测子中使用的加权函数 w ( s , t) 通常有两种形式:(1) 在区域内为 1,在其他区域为 0( 即,其形状类似于箱式低通滤波器核 ),或者 (2) 是如下形式的指数函数:
(11-62)
当计算速度至关重要且噪声水平较低时,使用箱式模型。当数据平滑至关重要时,使用指数模型。
如图 11.45 所示,拐角区域在两个空间方向上都具有较大的值。然而,当图像块跨越边界时,也会在一个方向上产生响应。问题是:我们如何区分这两种情况?正如我们在 11.5 节(参见例 11.17)中所讨论的,实对称矩阵( 例如上文中的 M )的特征向量指向数据最大分布的方向,相应的特征值与数据沿特征向量方向的分布量成正比。实际上,特征向量是拟合数据的椭圆的长轴,而特征值的大小则是椭圆中心到其与长轴相交点的距离。图 11.46 展示了如何利用这些性质来区分我们感兴趣的三种情况。
图 11.46(a) 至 (c) 中的小图像块分别代表图 11.45 中的区域 A,B 和 C 。在图 11.46(d) 中,我们展示使用导数核 和
( 记住,我们使用的是图 2.19 中定义的坐标系统) 计算所得的
的值。由于我们计算的是图像块中每一个点的导数,噪声引起的变化会导致数值分散,分散程度与噪声水平及其特性直接相关。正如预期的那样,平坦区域的导数形成一个近乎圆形的簇,其特征值几乎相同,从而得到一个近乎圆形的拟合曲线(相对于其他两个图,我们将这些特征值标记为"小")。图 11.46(e) 显示了包含边缘的图像块的导数。此处,沿 x 轴的分散程度更大,而沿y 轴的分散程度与图 11.46(a) 大致相同。特征向量
是 "大的" 而
是"小的"。因此,拟合数据的椭圆在 x方向上被拉长。最后,图 11.46( f ) 显示了包含角点的区域的导数。此处,数据沿两个方向扩散,导致两个较大的特征值和一个更大且接近圆形的拟合椭圆。由此我们可以得出以下结论:(1) 两个较小的特征值表示强度几乎恒定;(2) 一个较小和一个较大的特征值意味着存在垂直或水平边界;(3) 两个较大的特征值意味着存在角点或(遗憾的是)孤立的亮点。
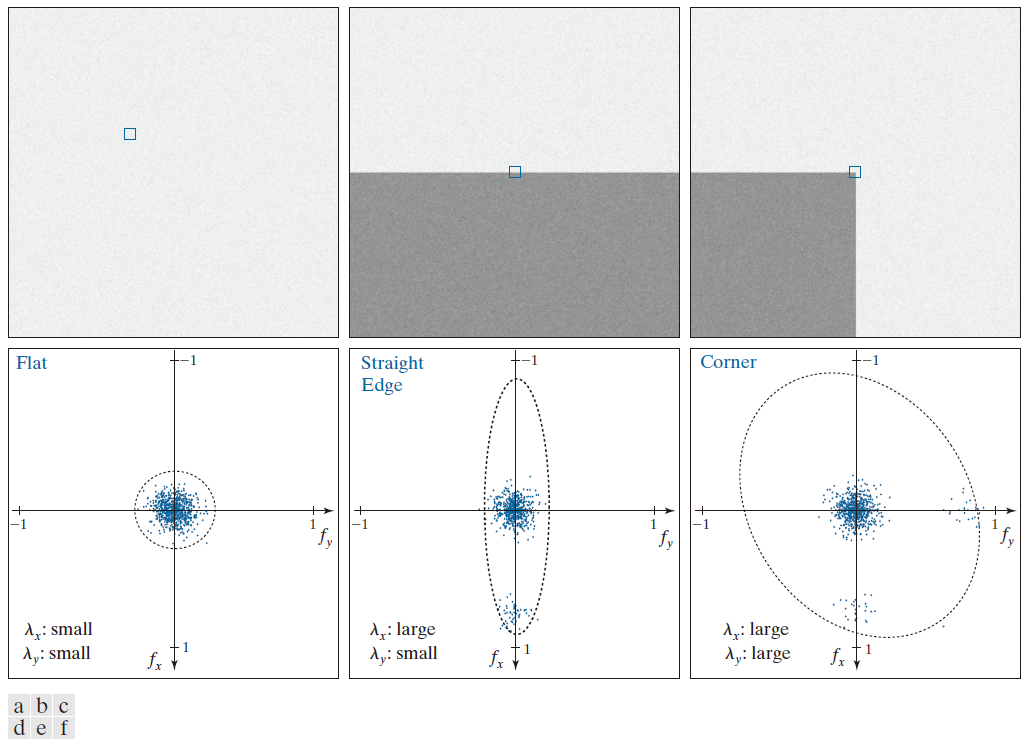
-------------------图 11.46:(a)--(c) 噪声图像和图像块(patches)(小方块),其内容与图 11.45 中的图像区域相似。( d )--( f ) 值对 图,展示了 M 的特征值特征,这些特征值可用于检测图像块中是否存在角点。----------------------------
因此,我们可以看到,由图像块中导数构成的矩阵的特征值可以用来区分三种感兴趣的场景。然而,HS检测子并没有使用计算成本高昂的特征值,而是利用了一种基于角点响应的度量方法。该方法基于以下事实:方阵的迹等于其特征值之和 ,行列式等于其特征值的乘积。此度量定义为
(11-63)
其中,k 是即将解释的一个常量。当两个特征值都很大时,度量 R 具有较大的正值,表明存在角点 ;当一个特征值很大而另一个特征值很小时,度量 R 具有较大的负值,表明存在边点 ;当两个特征值都很小时,其绝对值也很小,这表明所考虑的图像块是平坦的。
常数 k 是通过经验确定的,其取值范围取决于具体的实现方式。例如,MATLAB 图像处理工具箱使用的 k 值范围为 0 < k < 0.25。你可以将 k 理解为"灵敏度因子";k 值越小,检测子找到角点的可能性就越大。通常,R 与阈值 T 一起使用。只有当图像中某一位置的 R > T 时,我们才认为在该位置检测到了角点。
例子 11.17 :应用 HS角点检测子 。
图 11.47(a) 显示了一幅含噪图像,图 11.47(b) 是使用 HS 角点检测器,k = 0.04,T = 0.01(我们实现中的默认值)的结果。所有正方形的角点都被正确检测到,但误检数量过多(注意所有错误都发生在图像的右侧,那里正方形之间的强度差异较小)。图 11.47(c) 显示了将 k 增加到 0.1 而 T 保持为 0.01 的结果。此时,所有角点都被正确检测到。如图 11.47(d) 所示,将阈值增加到T = 0.1 也得到了相同的结果。事实上,如图 11.47(e) 所示,使用 k 的默认值并将T 保持为 0.1 也产生了相同的结果。这一切的关键在于k 和T 值之间的相互作用具有相当大的灵活性。图11.47(f)展示了使用k 的默认值和T = 0.3.得到的结果。正如预期的那样,增加阈值会消除一些角点,在本例中只保留强度差异较大的正方形的角点。将k 值增加到0.1并将T 设置为其默认值,以及使用k = 0.1.和T = 0.3.得到相同的结果,这再次表明了这两个参数取值的灵活性。然而,随着噪声水平的增加,可能取值的范围会变窄,如下一段的结果所示。

-------------------图 11.47:(a) 一幅 600 × 600 像素的图像,其数值范围为 0,1,并添加了均值为 0、方差为 0.006 的加性Gauss噪声。(b) 应用 HS 角点检测子,k = 0.04,T = 0.01(默认值)的结果。可以看到一些错误。(c) 使用 k = 0.1 和 T = 0.01 的结果。(d) 使用 k = 0.1 和 T = 0.1 的结果。(e) 使用 k = 0.04 和 T = 0.1 的结果。(f) 使用k = 0.04 和 T= 0.3 的结果(仅检测到左侧最强的角点)。-------------------
图 11.48(a) 显示了受更高水平加性 Gauss噪声干扰的棋盘格图案(参见图注)。尽管该图像与图 11.47(a) 看起来差别不大,但使用 k 和 T 的默认值得到的结果却比之前差得多。即使在图像左侧强度差异更大的区域,也检测到了错误的角点。图 11.48(c) 显示了在保持T 为默认值的情况下,将 k 值增加到接近我们实现中的最大值 (2.5) 的结果。此时,仅靠 k 值无法克服更高的噪声水平。另一方面,如图 11.48(d) 所示,将k 值降低到默认值并将T值增加到 0.15 则产生了完美的结果。

-------------------图 11.48:(a) 与图 11.47(a) 相同,但添加了均值为 0、方差为 0.01 的Gauss噪声。(b) 使用 k = 0.04 和 T = 0.01 的 HS 检测器的结果与图 11.47(b) 比较。(c) k = 0.249(接近我们实现中的最大值)和 T = 0.01 的结果。(d) 使用 k = 0.04 和 T = 0.15 的结果。--------------------------------------------
图 11.49(a) 显示了一幅更为复杂的图像,其中包含大量嵌入在不同强度范围内的角点。图 11.49(b) 是使用 k 和 T 的默认值得到的结果。如图所示,出现了许多检测错误( 例如,建筑物右边缘的大量错误角点检测 )。单独增加 k 值对过度检测角点的影响甚微,直到 k 接近其最大值。使用与图 11.48(c) 相同的值得到了图 11.49(c),该图像显示错误角点的数量有所减少,但代价是遗漏了建筑物前方的许多重要角点。如图 11.49(d) 所示,将k 减小到 0.17 并将 T 增大到 0.05 效果显著。参数 k 对建筑物图像的角点检测影响不大。事实上,图 11.49(b) 和图 11.49(c) 中 k 和 T 的值与角点检测结果基本一致。 11.49(e) 和 (f) 显示,将 k 降低到默认值 0.04,并分别使用 T = 0.05 和 T = 0.07,所获得的性能水平基本相同。

-----------------图 11.49:(a) 建筑物的 600 × 600 图像。(b) 应用 HS 角点检测器,k = 0.04,T = 0.01(我们实现中的默认值)的结果。检测到大量无关角点。(c) 使用 k = 0.249 和默认值 T 的结果。(d) 使用 k = 0.17 和 T = 0.05 的结果。(e) 使用默认值 k 和 T = 0.05 的结果。( f )使用默认值k 和 T = 0.07 的结果。---------------
最后,图 11.50 展示了旋转图像上的角点检测结果。图 11.50(b) 的结果是使用与图 11.49(f) 相同的参数获得的,这表明该方法对旋转的敏感性相对较低。图 11.49(f) 和 11.50(b) 显示,图像中每个主要结构特征(例如前门、所有窗户以及构成立面顶点的角点)都至少检测到了一个角点。就匹配而言,这些结果非常出色。

-----------------------图 11.50:(a) 图像旋转 5°。(b) 使用获得图 11.49( f )的参数检测角点。--------------------------------------------------------------
11.6.2 最大稳定极值区 域( MSERs**)** ( Maximally Stable Extremal Regions (MSERs))
前一节讨论的Harris - Stephens 角点检测子适用于强度变化剧烈的应用场景 ,例如直线边缘的交点,这些交点会在图像中形成类似角点的特征。相反,Matas等人2002提出的最大稳定极值区域(MSER)更侧重于"斑点"特征。与HS角点检测器类似,MSER旨在提取整幅图像的特征,以便建立两幅或多幅图像之间的对应关系。
从图 2.18 可知,一幅灰度图像可以看作是一幅地形图(topographic),其中 xy 轴代表空间坐标,z 轴代表强度。假设我们开始对一幅 8 位灰度图像进行阈值处理,每次调整一个强度级别。每次阈值处理的结果都是一幅二值图像,其中阈值以上或等于阈值的像素显示为白色,阈值以下的像素显示为黑色。当阈值T 为 0 时,结果为白色图像(所有像素值均大于或等于 0)。随着 T 以一个强度级别的增量递增,我们将开始在生成的二值图像中看到黑色分量。这些黑色分量对应于图像地形图中的局部最小值。这些黑色区域可能会开始扩大和合并,但它们的大小不会在图像之间缩小。最终,当 T达到 255 时,结果图像将变为黑色(没有像素值高于此级别)。由于阈值分割的每个阶段都会生成二值图像,因此每幅图像中都会存在一个或多个由白色像素组成的连通区域。所有阈值分割后得到的此类连通区域的集合即为极值区域集合。在一定阈值范围内大小(像素数)变化不显著的极值区域称为最大稳定极值区域。
正如你稍后将看到的那样,刚才讨论的过程可以表示为一颗有根连通树,称为一颗分量树,其中树的每一层对应于上一段讨论的阈值。该树的每一个节点代表一个极值区域 R ,定义为
(11-64)
其中 I 是所考虑的图像,p 和 q 是图像上的点。该方程表明,极值区域 R 是 I 的一个区域,其性质是区域内任意一点的强度都高于区域边界上任意一点的强度。通常,我们假设图像强度为整数,从 0 (黑色)到最大强度( 例如,8 位图像的 255 ),最大强度用白色表示。
MSER 是通过分析分量树的节点来找到的。对于树中的每一个连通区域,我们计算一个稳定性度量 ψ ,其定义为
(11-65)
其中,|R | 连通区域 R 的面积(像素数)的大小,T 是的阈值,T ,而 ΔT 是一个阈值增量。区域
,
,
分别是在阈值等级 T + ( n - 1) ΔT ,T + n ΔT ,T + ( n + 1) ΔT 处获得。根据分量树,区域
和
分别是 区域
的父和子 。因为 T + ( n - 1) ΔT < T + ( n + 1) ΔT ,我们确保
。然后,根据公式 (11-65) 可推导出 ψ ≥ 0 。最大稳定区域(MSRE)是指树中对应于节点的区域,这些节点的稳定性值是包含该区域的树路径上的局部最小值 。实际上,这意味着最大稳定区域是指在两个相邻的 2ΔT 阈值图像中,其大小变化不大的区域。
图 11.51 展示了刚才介绍的概念。顶部的灰度图像由一些强度恒定的简单区域组成,其值范围为 0, 255。根据公式 (11-64) 和 (11-65) 的解释,我们使用了阈值 T = 10,其值范围为 。选择 T = 50 可以分割图像的所有不同区域。左侧的二值图像列包含了使用所示阈值对灰度图像进行阈值分割的结果。右侧是生成的分量树。请注意,该树是"根在上(root up)"显示的,这是通常的编程方式。
灰度图像中的所有正方形大小(面积)都相同;因此,无论图像大小如何,我们都可以将每一个正方形的大小归一化为 1 。例如,如果图像大小为 400 × 400 像素,则每一个正方形的大小为 像素。将大小归一化为 1 意味着大小 1 对应于
像素(一个正方形),大小 2 对应于
像素(两个正方形),依此类推。你可以通过注意到公式 (11-65) 中的比例消除了公因子
来得出相同的结论。
图 11.51 中的分量树很好地概括了 MSER 算法的工作原理。第一层是使用阈值 T + 2ΔT = 60 对图像 I 进行阈值处理的结果。左侧的阈值处理图像中只有一个连通分量(白色像素)。该连通分量的大小为 11 个归一化单位 。如上所述,组件树中的每一个节点(用下标 R 表示)都包含一个由白色像素组成的连通分量。树的下一层是由使用阈值 T + ΔT = 110 对图像 I 进行阈值处理得到的二值图像中的区域构成的。如左侧所示,该图像有三个连通分量,因此我们在阈值处理图像的分量树层级创建三个节点。类似地,使用阈值 T + 3ΔT = 160 对图像 I 进行阈值处理得到的二值图像有两个连通分量,因此我们在该层级创建两个节点。这两个连通分量是上一层连通分量的子节点,因此我们将新节点放置在与其各自父节点相同的路径上。树的下一层也用同样的方法解释。注意,上一层的中心节点没有子节点,因此该路径终止于第二层。
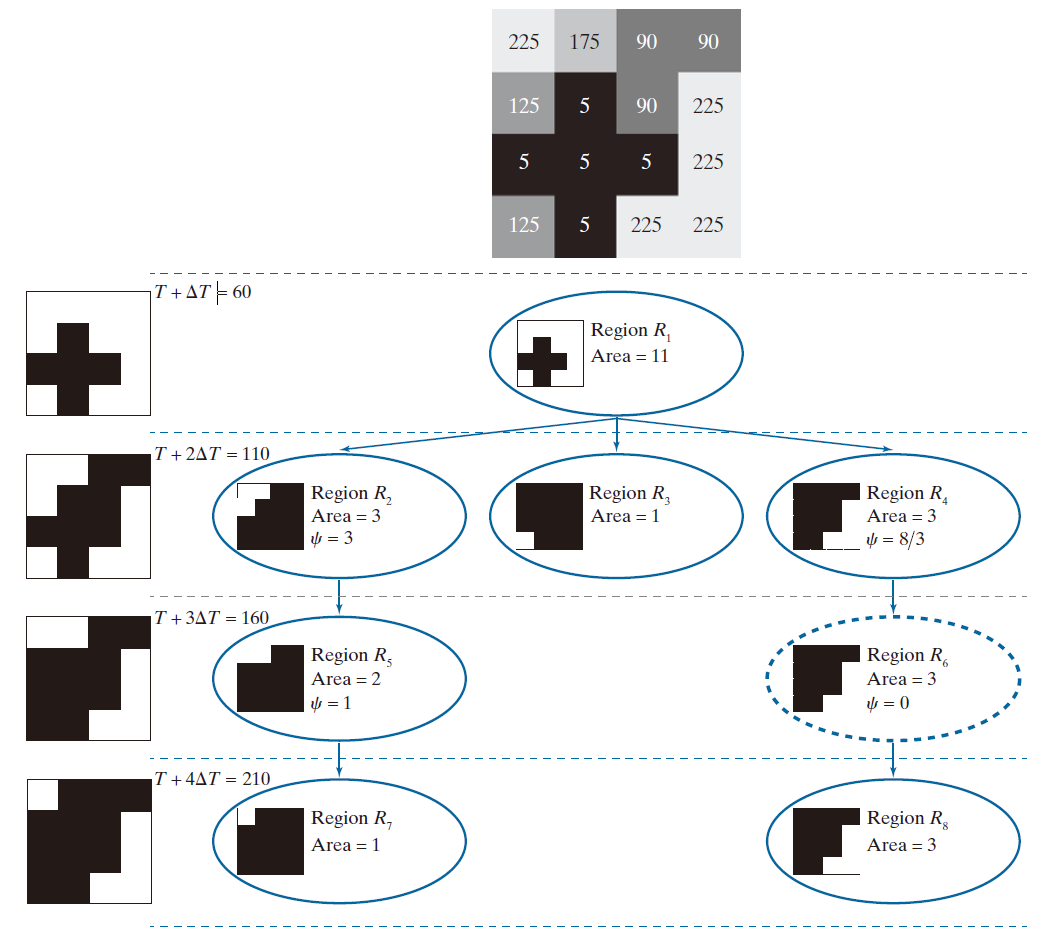
----------------图 11.51:检测 MSER。上图:灰度图像。左图:阈值化图像(阈值分别为T = 10 和 T = 50)。右图:分量树,显示各个区域。仅检测到一个 MSER(参见树最右侧分支上的虚线节点)。树的每一层均由左侧相同层级的阈值化图像构成。树的每一个节点包含一个极值区域(连通分量),以白色显示,并用下标 R 表示。----------------
由于我们需要检查父区域和子区域之间的大小差异来确定稳定性,因此本例中只有中间两个区域(分别对应阈值 110 和 160)是相关的。正如你在分量树中看到的那样,只有 的父区域和子区域大小相似(在本例中大小相同)。因此,区域
是本例中检测到的唯一 MSER 。请注意,如果我们使用单一的全局阈值来检测最亮的区域,区域
也会被检测到(在本例中,这是一个不理想的结果)。因此,我们看到,尽管 MSER 基于强度,但它们也取决于区域周围背景的性质。在本例中,
周围的背景比
更暗,并且较暗的背景在树中更早地阈值化,使得
的大小在检测为 MSER 所需的两个 2T 相邻范围内保持不变。
在我们的示例中,很容易检测到 MSER ,因为它是唯一大小不变的区域,因此稳定性因子为 0。值为零自动意味着已找到 MSER,因为父区域和子区域大小相同。处理更复杂的图像时,稳定性因子的值很少为零,因为光照、视角和噪声等变量会导致强度变化。前面提到的局部最小值概念,简单来说就是 MSER 是极值区域,它们的大小在 2ΔT 阈值范围内会发生显著变化。"显著"变化的定义取决于具体应用。
检测到大量 MSER 并不罕见,其中许多可能由于其尺寸过大而没有实际意义。控制检测到的区域数量的一种方法是通过选择合适的 ΔT 值。另一种方法是将尺寸不在指定范围内的任何区域标记为不重要。我们在示例 11.19 中对此进行了说明。
Matas 等人 2002 指出 MSER 具有仿射协变性(参见第 11.1 节)。这直接源于面积比在仿射变换下保持不变这一事实,进而意味着对于某个仿射变换,原始区域和变换后的区域之间存在该变换的关系。我们在图 11.54 和图 11.55 中展示了这一性质。
最后,需要注意的是,前面提到的MSER公式旨在检测周围环境较暗的明亮区域。将相同的公式应用于图像的负片(定义见3.2节),则会检测周围环境较亮的暗区域。如果目标是同时检测这两种类型的区域,则需要将两组MSER结果合并。
例子 11.19 :从灰度图像中提取 MSER**。**
图 11.52(a) 显示了人头部 CT 扫描的切片图像,图 11.52(b) 显示了使用 15 × 15 元素大小的盒状核对图 11.52(a) 进行平滑处理的结果。当 T 值相对较小时,平滑处理通常用作预处理步骤。在本例中,我们使用了T = 0 和 T = 10。这个增量足够小,需要进行平滑处理才能正确检测 MSER。此外,我们还使用了"尺寸过滤器",即 MSER 的尺寸(面积)必须介于 10,262 像素和 34,200 像素之间;这些尺寸限制分别是图像尺寸的 3% 和 10%。
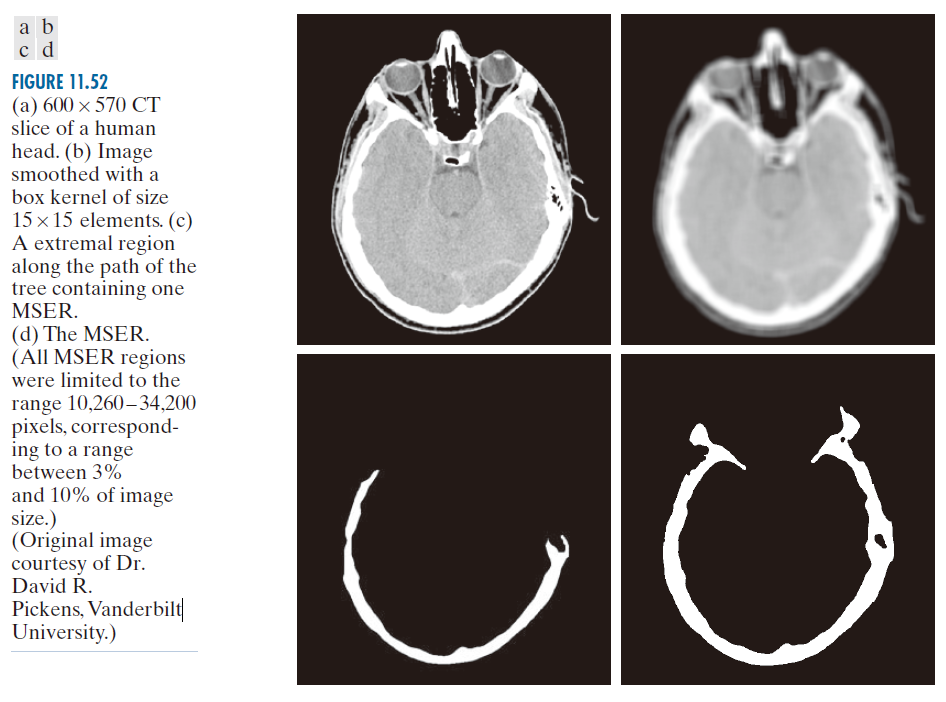
--------------------图 11.52:(a) 人头600 × 570像素的CT分片。(b) 使用15 × 15像素大小的盒状核进行平滑处理的图像。(c) 沿树状图路径包含一个MSER的极值区域。(d) MSER 。(所有MSER区域均限制在10,260至34,200像素范围内,相当于图像大小的3%至10%。)(原图像由Vanderbilt大学的David R. Pickens博士提供。)-----------
图 11.53 展示了在更复杂的图像上进行 MSER 检测的结果。由于该图像细节更丰富,我们使用了较少的模糊处理( 5 × 5 的盒状核) 。我们使用了与图 11.52 相同的T 和 T值,以及在 10,000 到 30,000 像素范围内的有效 MSER 尺寸,分别约为图像尺寸的 3% 和 8%。使用这些参数检测到了两个 MSER,如图 11.53(c) 和 (d) 所示。合成的 MSER ( 如图 11.53(e) 所示 )很好地代表了建筑物的正面。

----------------------图 11.53:(a) 尺寸为 600 × 600 像素的建筑物图像。(b) 使用 5 × 5 方框核平滑后的图像。(c) 和 (d)分别使用 T = 0 和T = 10 检测到的 MSER ,MSER 尺寸范围在 10,000 到 30,000 像素之间,分别对应于图像面积的约 3% 和 8%。(e)合成图像。--------------------------------------------------------
图 11.54 展示了图 11.53 中检测到的 MSER 在旋转后的行为。图 11.54(a) 是将建筑物图像逆时针旋转 5° 后的结果。旋转后对图像进行了裁剪,以消除由此产生的黑色区域(参见图 2.41),这些黑色区域会改变图像数据的性质,从而影响结果。图 11.54(b) 是执行与图 11.53 相同的平滑处理后的结果,图 11.54(c) 是使用与图 11.53(e) 相同的参数检测到的复合 MSER 。可以看出,旋转图像的复合 MSER 与图 11.53(e) 中的 MSER 非常接近。

--------------------------11.54: (a) 建筑图像逆时针旋转 5°。(b) 使用与图 11.53(b) 相同的卷积核进行平滑处理的图像。(c) 使用与图 11.53(e) 相同的参数检测到的复合 MSER 。原图像和旋转图像的 MSER 值几乎相同。-------------------------
最后,图 11.55 展示了 MSER 检测器在尺度变化下的性能。图 11.55(a) 是将建筑物图像缩放至其原始尺寸的 0.5 倍,图 11.55(b) 则展示了使用相应更小的 3 × 3 尺寸的盒状核进行平滑处理后的图像。由于图像区域现在只有原始区域的四分之一,因此我们将有效的 MSER 范围缩小了四分之一,至 2500 至 7500 像素。除这些变化外,我们使用了与图 11.53 相同的参数。图 11.55(c) 展示了最终的 MSER 结果。可以看出,该结果与图 11.53(e) 中的全尺寸结果非常接近。

--------------------图 11.55:(a) 缩小至一半大小的建筑物图像。(b) 使用 3 × 3 方框核平滑的图像。(c) 使用与图 11.53(e) 相同的参数获得的复合 MSER,但使用了 2,500 至 7,500 像素的有效 MSER 区域大小范围。--------------------------------
11.7 缩放不变性特征变换( Scale-Invariant Feature Transform (SIFT))
SIFT 是 Lowe 2004 开发的一种用于从图像中提取不变特征的算法。之所以称之为变换,是因为它将图像数据变换到相对于局部图像特征的缩放不变坐标系中。SIFT 是本章讨论的所有特征检测和描述方法中最复杂的一种。
在阅读本节的过程中,你会注意到大量实验确定的参数的使用。因此,与我们迄今为止讨论的大多数单一方法的公式化不同,SIFT 具有很强的启发式性质。这是因为我们目前的知识不足以告诉我们如何将一组相对成熟的单一方法组合成一个"系统",从而解决任何单一已知方法都无法单独解决的问题。因此,我们不得不通过实验来确定控制更复杂系统性能的各种参数之间的相互作用。
当图像性质相似(相同尺度、相似方向等)时,角点检测和 MSER 可作为整幅图像的特征。然而,当存在缩放变化、旋转、光照变化和视角变化等变量时,我们就不得不使用 SIFT 等方法。
SIFT 特征 (称为关键点 (keypoints))对图像缩放和旋转具有不变性,并且对各种仿射畸变、三维视角变化、噪声和光照变化都具有健壮性 。SIFT 的输入是一幅图像,其输出是一个 n 维特征向量,向量的元素是不变的特征描述符。我们首先分析 SIFT 如何实现尺度不变性。
11.7.1 缩放空间 ( Scale Space**)**
SIFT算法的第一阶段是寻找对缩放变化保持不变的图像位置。这通过在所有可能的尺度上搜索稳定特征来实现,所用到的缩放函数称为缩放空间。缩放空间是一种多缩放表示方法,能够以一致的方式处理不同缩放下的图像结构。其核心思想是建立一种公式化方法,用于处理非约束场景中物体会因图像缩放不同而呈现不同形态这一事实。由于这些缩放可能事先未知,因此一种合理的方法是同时处理所有相关的缩放。缩放空间将图像表示为一个单参数平滑图像族,其目的是模拟图像它们缩放减小时细节的损失。控制平滑程度的参数称为缩放参数。
在SIFT算法中,使用Gauss核来实现平滑,因此缩放参数是标准差。使用Gauss核的原因基于Lindberg 1994 的工作,他证明唯一满足一系列重要约束(例如线性和平移不变性)的平滑核是Gauss低通核。基于此,灰度图像f ( x , y ) 的缩放空间L ( x , y ,σ )是通过将f 与可变缩放Gauss核G ( x , y ,σ )进行卷积而生成的(注:Lowe 2004 报告的实验结果表明,使用Gauss核( σ = 0.5 )平滑原图像,然后通过线性(最近邻)插值将其尺寸加倍,可以提高 SIFT 检测到的稳定特征的数量。这一预处理步骤是算法不可或缺的一部分。图像的取值范围假定为 0,1):
(11-66)
其中,缩放由 σ 控制 ,而 G 的形式为
(11-67)
输入图像 f ( x , y ) 与标准差分别为 的 Gauss 核进行连续卷积,生成由常数因子 k 分隔的Gauss滤波(平滑)图像的"栈",如图 11.56 左下角所示。
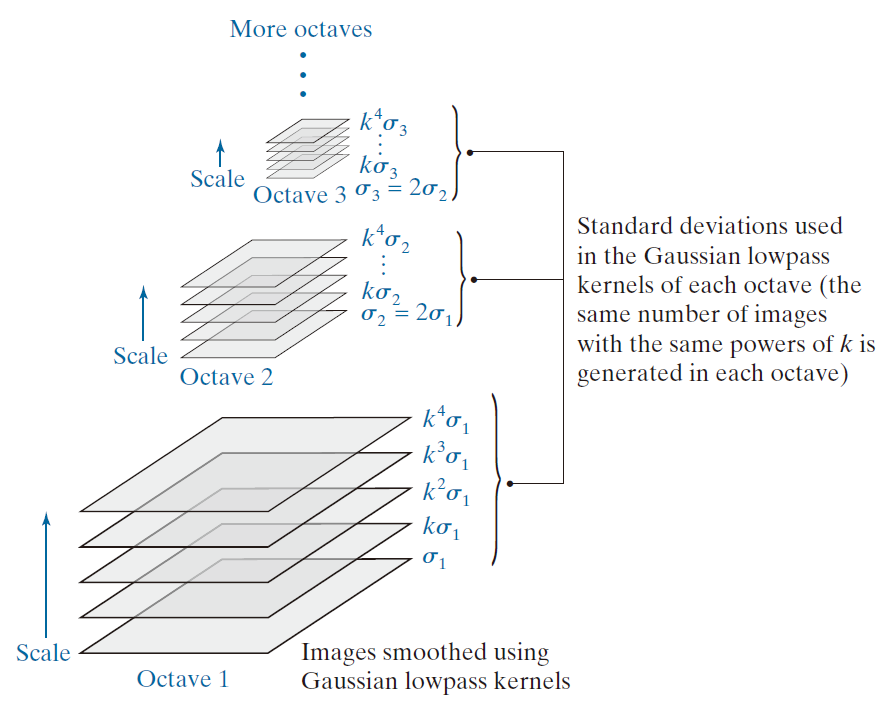
--------------图 11.56:缩放空间,显示三个倍频程。由于本例中 s = 2,每一个倍频程都有五个平滑图像。平滑处理使用了Gauss核,因此空间参数为 σ。---------------
SIFT 将缩放空间细分为倍频程 (octaves),每一个倍频程对应于 σ 的两倍,正如音乐理论中一个八度对应于声音信号频率的两倍一样。SIFT 进一步将每一个倍频程细分为整数个 s 区间 ,因此,长度为 1 的间隔由两个图像组成,长度为 2 的间隔由三个图像组成,依此类推。则可以推断出生成与一个倍频程相对应的图像的Gauss 核中所使用的值是 ,这意味着
。例如,对于 s = 2 ,
,输入图像是使用标准偏差 σ ,
,
,因此,序列中的第三幅图像 (即 s = 2 倍频程图像) 使用了具有标准偏差 ,
的 Gauss 核进行了滤波。
前面的讨论表明,在一个倍频程内生成的平滑图像数量为 s + 1 。然而,正如你将在下一节中看到的,缩放空间中的平滑图像用于计算Gauss差分 参见公式 (10-32)。为了覆盖一个完整的倍频程,这意味着在倍频程图像之后还需要两个额外的图像,总共需要 s + 3 个图像。由于倍频程图像始终是图像栈中的第 ( s + 1 ) 个图像(从底部计数),因此该图像是扩展后的 s + 3 个图像序列中从顶部数起的第三个图像。图 11.56 中的每一个倍频程包含五个图像,表明在这种情况下使用了 s = 2 。
第二个倍频程中的第一幅图像是通过对原图像进行下采样(跳过每隔一行和一列)得到的,然后使用标准偏差是第一个倍频程中两倍的核进行平滑处理 ( 即 ) 。该倍频程中的后续图像使用
进行平滑处理,k 值序列与第一个倍频程相同(如图 11.56 中的点所示)。然后,对后续倍频程重复相同的基本过程。即,新倍频程的第一幅图像是通过以下方式形成的:(1) 对原图像进行足够多次的下采样,使其大小达到前一个倍频程图像的一半;(2) 使用标准差是前一个倍频程标准差两倍的新标准差对下采样后的图像进行平滑处理。新倍频程中的其余图像是通过将下采样图像与新的标准差乘以与之前相同的 k 值序列进行平滑处理而获得的。
当 时,我们可以直接获得新倍频程的第一幅图像,而无需对下采样后的图像进行平滑处理。这是因为,对于此 k 值,用于平滑每一个倍频程第一幅图像的核与用于平滑前一个倍频程倒数第三幅图像的核相同。因此,新倍频程的第一幅图像可以直接通过将前一个倍频程的第三幅图像下采样 2 倍来获得。结果相同 (参见问题 11.36)。任何倍频程倒数第三幅图像称为倍频程图像,因为用于平滑该图像的标准差是用于平滑该倍频程第一幅图像的标准差的两倍( 即
) 。
图 11.57 使用灰度图像进一步说明了 SIFT 中缩放空间的构建方式。由于每个倍频程由五幅图像组成,因此我们再次使用 s = 2。在本例中,我们选择 和
,以便这些数值能够得到熟悉的倍数。与图 11.56 类似,缩放空间中图像的模糊化是通过使用标准差逐渐增大的 Gauss核来实现的,并且第二个及后续倍频程的第一幅图像是通过将前一个倍频程的图像下采样 2 倍得到的。正如你所看到的,随着缩放和倍频程的增加,图像变得越来越模糊(因此丢失了更多细节)。第三个八度音阶中的图像显示的细节明显减少,但它们的整体外观与前一个倍频程中的图像结构完全相同。

------------图 11.57:图示使用了SIFT中的缩放空间的前三个倍频程的图像。表格中的项为每一个倍频程的每一个缩放中标准偏差值值。例如,第1个倍频程在第二个缩放中的标准偏差 等于1.0。(为了适应图形空间,1倍频程的图像略有重叠。)---------
11.7.2 检测局部极值 ( Detecting Local Extrema**)**
SIFT 首先使用Gauss滤波图像求得关键点的位置,然后通过两个处理步骤来改进这些关键点的位置和有效性。
11.7.2.1 求得初始关键点 ( Finding the Initial Keypoints**)**
SIFT算法首先通过检测相邻两个缩放空间图像的Gauss差值的极值来寻找缩放空间中的关键点位置,这两个图像位于同一倍频程内,并与对应于该八度音程的输入图像进行卷积。例如,要求得缩放空间中与第一倍频程的前两个层级相关的关键点位置,我们求解以下函数中的极值:
(11-68)
根据公式 (11-66) 可推导出
(11-69)
换言之,要求得函数 D ( x , y ,σ ) ,我们只需将1 倍频程的前两个图像相减即可。回顾 Marr-Hildreth 边缘检测子的讨论(第 10.2 节),Gauss差分是Gauss的 Laplace算子 (LoG) 的近似。因此,公式 (11-69) 只是公式 (10-30) 的近似。关键区别在于,SIFT 寻找的是 D ( x , y ,σ) 的极值,而 Marr-Hildreth 检测子求解的是该函数的过零点(zero crossing)。
Lindberg 1994 证明,缩放空间中的真正缩放不变性要求将 LoG 用 进行归一化(即,使用了
)。可以证明( 见问题 11.34 )
(11-70)
因此,DoG 已经"内置"了必要的缩放变换。因子 ( k - 1 ) 在所有缩放上都是常数,因此它不会影响在缩放空间中定位极值点的过程。虽然公式 (11-68) 和 (11-69) 适用于第一倍频程的前两幅图像,但只要使用适当的下采样图像,并且 DoG 由该倍频程中相邻的两幅图像计算得出,这些公式的相同形式也适用于任何倍频程中的任意两幅图像。
图 11.58 以图 11.57 中的建筑图像为例,阐释了刚才讨论的概念。在每个倍频程中,由该倍频程内所有相邻的高斯滤波图像对生成总共 s + 2 个差分函数 D ( x , y ,σ)。这些差分函数可以视为图像,图 11.58 中展示了三个倍频程中每个倍频程的一个此类图像样本。正如你从图 11.57 的结果中所预期的那样,随着缩放空间的增大,这些图像的细节程度逐渐降低。
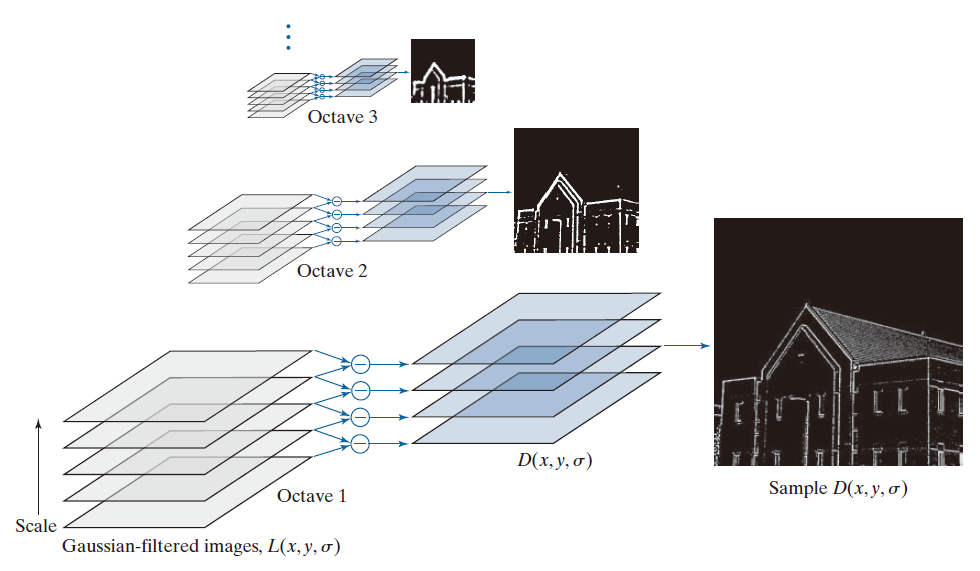
-------------图 11.58:公式 (11-69) 在缩放空间中的实现方式如下。每一个倍频程中有 s + 3 个 L ( x , y , s ) 图像和 s + 2 个对应的 D ( x , y ,σ) 图像。------------
图 11.59 展示了 SIFT 算法在 D ( x , y ,σ ) 图像中寻找极值点的过程。D ( x , y ,σ) 图像的每一个位置(图中黑色部分),该位置像素的值会与其在当前图像中的八个邻域像素值以及其在上下两幅图像中的九个邻域像素值进行比较。如果该点的值大于其所有邻域像素值,或小于其所有邻域像素值,则该点选为极值点(最大值或最小值)。由于倍频程的第一(最后一个)缩放没有相同大小的下(上)缩放图像,因此无法检测到极值点。
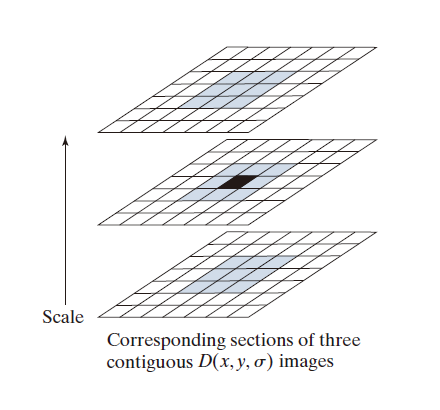
-----------------------------图 11.59:通过将当前和相邻缩放图像中 3 × 3 区域中的像素(显示为黑色)与其 26 个邻域(显示为阴影)进行比较,以检测倍频程中 D ( x , y ,σ) 图像的极值(最大值或最小值)。------------------------------------------
11.7.2.2 提高关键点定位的准确性 ( Improving the Accuracy of Keypoint Locations**)**
当对连续函数进行采样时,其真实最大值或最小值实际上可能位于采样点之间。为了更接近真实极值(达到亚像素精度),通常的做法是在数字函数中求得的每一个极值点处拟合一个插值函数,然后在插值函数中寻找更精确的极值位置。SIFT 使用 D ( x , y ,σ) 的Taylor级数展开式的线性项和二次项,并将原点平移到正在分析的采样点。按这种形式,表达式是
(11-71)
其中,D 及其导数在采样点进行计算, 是距离那个点的偏移,▽ 是我们熟悉的梯度算子
(11-72)
而 H 上 Hesse 矩阵( 译注:Ludwig Otto Hesse (1811年4月22日-1874年8月4日) ,德国数学家 )
(11-73)
取公式 (11-71) 关于 x 的导数并置为 0 ,即可求得极值的位置 ,即( 见问题 11.37 )
(11-74)
如第 10.2 节所述,我们使用相邻点的差分来近似计算 D 的 Hesse 矩阵和梯度。由此得到的 3 × 3 线性方程组很容易通过计算求解。如果偏移量 在其三个维度中的任意一个维度上大于 0.5,则我们得出结论:极值点更靠近另一个采样点,在这种情况下,我们将更改采样点,并围绕该点进行插值。最终的偏移量
加到其采样点的位置,即可得到极值点位置的插值估计。
SIFT 使用极值处的函数值 来剔除对比度低的不稳定极值,其中,
可通过将公式 (11-74) 代入 公式 (11-71) 而求得,即( 见问题 11.37 )
(11-75)
Lowe 2004 报告的实验结果中,基于所有图像值均在 0, 1 范围内,任何 小于 0.03 的极值点都被剔除。这消除了对比度低和/或定位不佳的关键点。
11.7.2.3 消除边缘响应 ( Eliminating Edge Responses**)**
回顾第 10.2 节,Gauss差分可以提取图像中的边缘。但 SIFT 算法关注的是"角状(corner-like)"特征,这些特征的局部性更强。因此,由边缘引起的强度变化会被消除。为了量化边缘和角状特征之间的差异,我们可以考察局部曲率。边缘的特征是在一个方向上具有高曲率,而在垂直方向上具有低曲率。图像中某一点的曲率可以通过计算该点处的 2 × 2 Hesse 矩阵来估计。因此,为了估计标量空间中任意层级的Gauss差分的局部曲率,我们计算该层级的 Hesse矩阵:
(11-76)
其中右侧的形式使用了与Harris矩阵的A项公式(11-61)相同的符号(但请注意主对角线不同)。H的特征值与D的曲率成正比。正如我们在讨论Harris-Stephens角点检测器时所解释的,我们可以通过基于H的迹和行列式构建检验来避免直接计算特征值,因为它们分别等于特征值的和与积。为了使用与HS讨论不同的符号,令α 和 β分别为H的最大和最小特征值。利用H的特征值与其迹和行列式之间的关系,我们有 (记住,H 是对称的,且大小为2 × 2 ) :
(11-77)
如果行列式为负,则曲率符号不同,所讨论的关键点不可能是极值点,因此将其舍弃。令 r 表示最大特征值与最小特征值之比。则 α = rβ且
(11-78)
这取决于特征值之比,而不是其单个值。当特征值相等时, 之比最小,其随着 r 的增长而递增。因此,为了检验主曲率比是否低于某个阈值 r,我们只需要检验
(11-79)
这是一个简单的计算。在 Lowe 2004 报告的实验结果中,使用了 r = 10 的值,这意味着曲率比大于 10 的关键点被剔除。
图 11.60 显示了使用本节讨论的方法在建筑物图像中检测到的 SIFT 关键点。公式 (11-75) 中 小于 0.03 的关键点被舍弃,不满足公式 (11-79) 且 r = 10 的关键点也被舍弃。

-----------------------图 11.60:在建筑物图像中检测到SIFT关键点。这些点已被略微放大以便于观察。-----------------------------------------------------------
11.7.3 关键点方向 ( Keypoint Orientation**)**
至此,我们已经计算出SIFT认为稳定的关键点。由于我们知道每个关键点在缩放空间中的位置,因此实现了缩放无关性。下一步是基于局部图像属性为每一个关键点分配一个一致的方向。这使我们能够根据关键点的方向来表示它,从而实现对图像旋转的不变性。SIFT采用了一种直接的方法来实现这一点。关键点的缩放用于选择最接近该缩放的Gauss平滑图像L 。这样,所有方向计算都以缩放不变的方式进行。然后,对于该缩放下的每一个图像样本L ( x , y ),我们使用像素差值计算梯度幅值M ( x , y ) 和方向角 θ ( x ,y):
(11-80)
和
(11-81)
方向直方图由每个关键点邻域内样本点的梯度方向构成。该直方图包含 36 个区间,覆盖图像平面上 360° 的方向范围。添加到直方图中的每个样本都根据其梯度幅值以及标准差为关键点尺度 1.5 倍的圆形高斯函数进行加权。
直方图中的峰值对应于局部梯度的主要方向。检测到直方图中的最高峰值后,任何其他与最高峰值相差在 80% 以内的局部峰值也用于创建具有相同方向的另一个关键点。因此,对于具有多个幅度相近峰值的位置,将创建多个位于相同位置和缩放但方向不同的关键点。SIFT 仅对约 15% 具有多个方向的点分配多个方向,但这些点对图像匹配贡献显著(将在后面和第 12 章中讨论)。最后,对每个峰值最接近的三个直方图值拟合抛物线,以插值峰值位置,从而提高精度。
图 11.61 显示了与图 11.60 相同的关键点,这些关键点叠加在图像上,并用箭头标示了关键点的方向。请注意图像中相似关键点集的方向一致性。例如,观察建筑物右侧垂直角上的关键点。箭头的长度会根据光照和图像内容而变化,但它们的方向始终保持一致。**关键点方向图通常比较杂乱,不适合人眼直接解读。关键点方向的价值在于图像匹配,**我们将在后面的讨论中对此进行阐述。

-------------------------图 11.61:图 11.60 中的关键点叠加在原始图像上。箭头指示关键点的方向。---------------------------------------------------------------
11.7.4 关键点描述符 ( Keypoint Descriptors**)**
到目前为止讨论的步骤用于为每个关键点分配图像位置、缩放和方向,从而使这三个变量保持不变。下一步是计算每个关键点周围局部区域的描述符,该描述符既要具有高度区分性,又要尽可能地对缩放、方向、光照和图像视角的变化保持不变。其目的是利用这些描述符来识别两幅或多幅图像中局部区域之间的匹配项(相似性)。
SIFT 计算描述符的方法基于实验结果,这些结果表明局部图像梯度似乎执行着类似于人类视觉从不同视角匹配和识别三维物体的功能(Lowe 2004)。图 11.62 总结了 SIFT 生成与每个关键点关联的描述符的过程。以关键点为中心,创建一个 16 × 16 像素大小的区域,并使用像素差计算该区域内每个点的梯度幅值和方向。这些梯度幅值和方向在图的左上角以随机方向的箭头表示。然后,使用标准差等于区域大小一半的高斯加权函数,为每个点分配一个权重,该权重乘以梯度幅值。高斯加权函数在图中显示为一个圆,但实际上它是一个钟形曲面,其值(权重)随着与中心距离的增加而减小。该函数的目的是减少描述符因函数位置的微小变化而产生的突变。
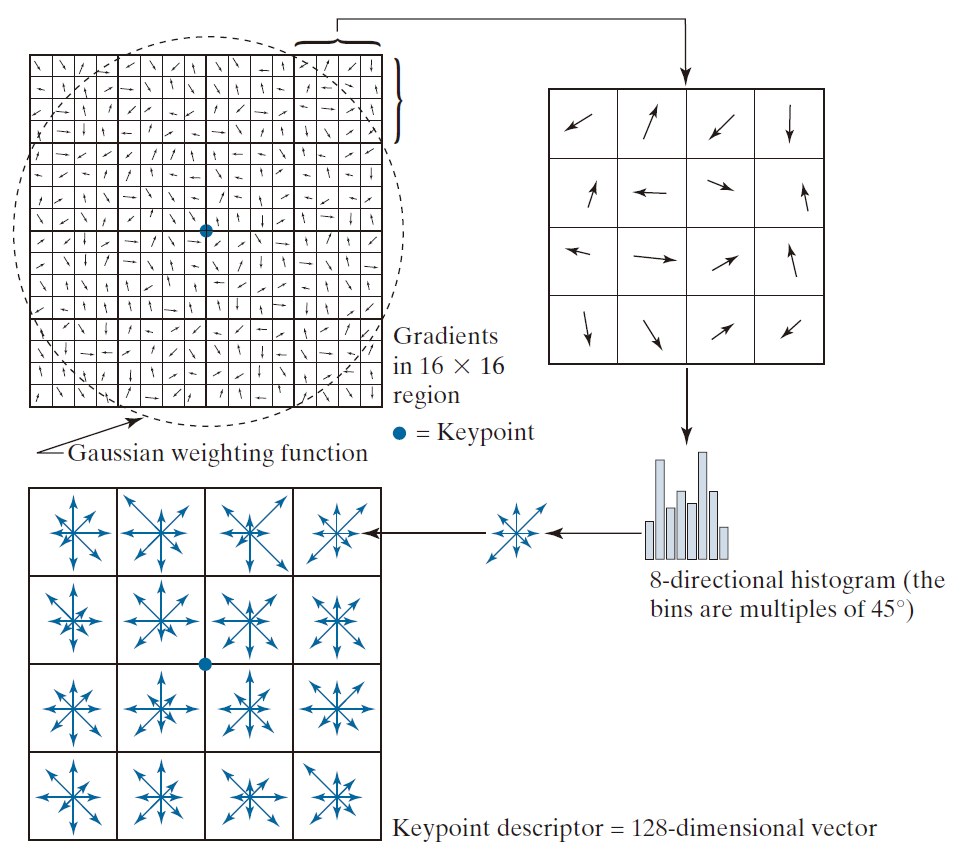
--------------------图 11.62:用于计算关键点描述符的方法。---------------------
由于关键点周围区域中的每个点都需要进行一次梯度计算,因此每个关键点需要处理 162 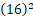 个梯度方向。每个 4 × 4 子区域内有 16 个方向。图中放大显示了最右上角的子区域,以便于解释下一步:将 4 × 4 子区域内的所有梯度方向量化为八个方向,每个方向相差 45°。SIFT 算法并非将方向值直接赋值给距离其最近的桶(bin),而是根据该值到每个桶中心的距离,按比例将直方图条目分配到所有桶中。这是通过将每个值乘以一个权重 1 - d 来实现的,其中 d 是该值到直方图区间中心的最短距离,单位为直方图间距,因此最大可能距离为 1 。例如,第一个区间的中心位于 45°/2 = 22.5°,下一个区间的中心位于 22.5°+ 45° = 67.5°,依此类推。假设某个方向值为 22.5°,该值到第一个直方图区间中心的距离为 0,因此我们将该区间分配一个完整的值(即计数为 1)。到下一个区间中心的距离大于 0,因此我们将该区间分配一个完整值的一部分,即 1 * (1 -- d),以此类推,直至所有区间。这样,每个箱子都会获得一定比例的计数,从而避免了"边界"效应,即描述符会因为方向的微小变化而突然改变,从而从一个箱子被分配到另一个箱子。
个梯度方向。每个 4 × 4 子区域内有 16 个方向。图中放大显示了最右上角的子区域,以便于解释下一步:将 4 × 4 子区域内的所有梯度方向量化为八个方向,每个方向相差 45°。SIFT 算法并非将方向值直接赋值给距离其最近的桶(bin),而是根据该值到每个桶中心的距离,按比例将直方图条目分配到所有桶中。这是通过将每个值乘以一个权重 1 - d 来实现的,其中 d 是该值到直方图区间中心的最短距离,单位为直方图间距,因此最大可能距离为 1 。例如,第一个区间的中心位于 45°/2 = 22.5°,下一个区间的中心位于 22.5°+ 45° = 67.5°,依此类推。假设某个方向值为 22.5°,该值到第一个直方图区间中心的距离为 0,因此我们将该区间分配一个完整的值(即计数为 1)。到下一个区间中心的距离大于 0,因此我们将该区间分配一个完整值的一部分,即 1 * (1 -- d),以此类推,直至所有区间。这样,每个箱子都会获得一定比例的计数,从而避免了"边界"效应,即描述符会因为方向的微小变化而突然改变,从而从一个箱子被分配到另一个箱子。
图 11.62 展示了直方图的八个方向,它们表示为一小簇向量,每个向量的长度等于其对应直方图区间的值。计算了十六个直方图,每个直方图对应于围绕关键点的 16 × 16 区域中的 4 × 4 子区域。描述符(如图左下角所示)由一个 4 × 4 数组构成,每个数组包含八个方向值。在 SIFT 算法中,该描述符数据被组织成一个 128 维向量。
为了实现方向不变性,描述符的坐标和梯度方向相对于关键点方向进行旋转。为了减少光照的影响,特征向量分两步进行归一化。首先,通过将每个分量除以向量范数,将向量归一化为单位长度。由于每个像素值乘以一个常数,图像对比度的变化也会使梯度乘以相同的常数,因此对比度的变化会被第一次归一化抵消。由于每个像素值加上一个常数,亮度变化不会影响梯度值,因为梯度值是由像素差值计算得到的。因此,描述符对光照的仿射变化是不变的。然而,非线性光照变化(例如由相机饱和引起的变化)也可能发生。这类变化会导致某些梯度的相对幅度发生较大变化,但不太可能影响梯度方向。 SIFT 通过对归一化特征向量的值进行阈值处理,使所有分量都低于实验确定的 0.2 值,从而降低大梯度幅度的影响。阈值处理后,特征向量被重新归一化为单位长度。
11.7.5 SIFT算法概要( Summary of the SIFT Algorithm**)**
如前几节所述,SIFT 是一个复杂的过程,包含许多部分和经验确定的常数。以下是该方法的逐步概述。
(1) 构建缩放空间。 这是按照图 11.56 和 11.57 中概述的步骤完成的。需要指定的参数是σ ,s ( k 由 s 计算得出)和倍频程数。建议值为 σ = 1.6 ,s = 2 和三个倍频程。
(2) 求得初始关键点。 如图 11.58 和公式 (11-69) 所示,计算缩放空间中平滑图像的Gauss 差分 D ( x , y ,σ ) 。使用图 11.59 中描述的方法,求得每个 D ( x , y ,σ) 图像中的极值点。这些极值点即为初始关键点。
(3) 提高关键点定位的准确性。 利用Taylor展开式对D ( x , y ,σ) 的值进行插值。改进后的关键点位置由式(11-74)给出。
(4) 删除不合适的关键点。 消除对比度低和/或定位不佳的关键点。这可以通过使用公式 (11-75) 在改进后的位置计算步骤 (3) 中的 D 值来实现。所有 D 值低于阈值的关键点都将被删除。建议的阈值为 0.03。与边缘相关的关键点也将使用公式 (11-79) 进行删除。建议 r 值为 10。
(5) **计算关键点的方向。**使用公式(11-80)和(11-81)来计算每个关键点的大小和方向,这些值采用与这些公式相关的基于直方图的程序进行计算。
(6) **计算关键点描述符。**使用图 11.62 中所示的方法计算每一个关键点的特征(描述符)向量。如果使用每一个关键点周围 16 × 16 大小的区域,则每个关键点将得到一个 128 维的特征向量。
以下示例说明了该算法的强大之处。
例子 11.20:使用 SIFT进行图像匹配。
我们通过使用 SIFT 算法来展示其性能,该算法用于求得建筑物图像与其右下角边缘提取部分所形成的子图像之间的匹配数量。我们还展示了图像和子图像旋转和缩小版本的结果。这种处理方法可用于图像配准等应用,例如查找两幅图像之间的对应关系,以及在图像数据库中查找图像实例。
图 11.63(a) 显示了建筑物图像(与图 11.61 相同)的关键点,以及子图像的关键点,子图像是一张独立的、小得多的图像。每个图像的关键点均使用 SIFT 算法独立计算。建筑物图像有 643 个关键点,子图像有 54 个关键点。图 11.63(b) 显示了 SIFT 算法在图像和子图像之间求得的匹配项;共找到 36 个关键点匹配项,如图所示,其中只有 3 个匹配错误。考虑到初始关键点的数量众多,可以看出关键点描述符在建立图像之间的对应关系方面具有很高的准确性。

-----------图 11.63:(a) 建筑图像及其右下角子图像的关键点及其方向(以灰色箭头表示)。子图像是单独的图像,并已进行单独处理。(b) 建筑图像与子图像之间的对应关键点(图中直线连接匹配的点对)。在求得的36个匹配点中,只有3个是错误的。---------
图 11.64(a) 显示了建筑物图像逆时针旋转 5° 后的关键点,以及从其右下角提取的子图像的关键点。旋转后的图像比原图小,因为为了去除旋转产生的恒定区域(见图 2.41),图像进行了裁剪。SIFT 算法为建筑物找到了 547 个关键点,为子图像找到了 49 个关键点。总共找到了 26 个匹配点,如图 11.64(b) 所示,其中只有两个匹配错误。

-------------------------图 11.64:(a) 旋转 5°后的建筑物图像及其右下角局部区域的关键点。子图像是单独的图像,并已单独处理。(b) 角落与建筑物之间的对应关键点。在找到的 26 个匹配点中,只有两个是错误的。------------------------------------
图 11.65 显示了使用 SIFT 算法对建筑物图像进行处理的结果,该图像在两个空间方向上的尺寸均缩小了一半。当 SIFT 应用于降采样图像及其对应的子图像时,未找到匹配项。通过调整强度Γ值略微提高缩小后的图像亮度,解决了这个问题。子图像是从该图像中提取出来的。尽管 SIFT 能够处理一定程度的强度变化,但此示例表明,在处理之前增强图像对比度可以提高性能。当处理图像数据库时,直方图规范(参见第 3 章)是使用待查询图像的特征对所有图像的强度进行归一化的绝佳工具。SIFT 为半尺寸图像找到了 195 个关键点,为对应的子图像找到了 24 个关键点。两幅图像之间共找到了 7 个匹配项,其中只有一个是错误的。

-----------------图 11.65:(a) 半尺寸建筑物及其右侧角落部分的关键点。(b)角落与建筑物之间的对应关键点。在找到的七个匹配项中,只有一个是错误的。-------------
前两幅图展示了SIFT对旋转和缩放变化的不敏感性,但它们并非理想的测试方法,因为寻求对这些变量的不敏感性的根本原因在于,我们并非总是能够预先知道图像是在不同的条件下以及几何构型下采集的。更实用的测试方法是计算原型图像的特征,并将其与未知样本进行比较。图11.66展示了此类测试的结果。图11.66(a)是原建筑图像,其SIFT特征向量已计算得出(参见图11.63)。SIFT用于将图11.64(a)中的旋转子图像与原始的未旋转图像进行比较。如图11.66(a)所示,找到了10个匹配项,其中两个是错误的。考虑到子图像相对较小且经过旋转,这些结果非常出色。图 11.66(b) 显示了将半尺寸子图像与原图像进行匹配的结果。共找到 11 个匹配项,其中 4 个错误。考虑到子图像在旋转或缩小尺寸时丢失了大量细节,这些结果仍然令人满意。如果在两种情况下都询问:仅基于 SIFT 找到的匹配项,这两个子图像分别来自建筑物的哪个部分?显而易见的答案是,子图像来自建筑物的右下角。前两个测试表明 SIFT 对旋转和缩放变化具有良好的适应性。
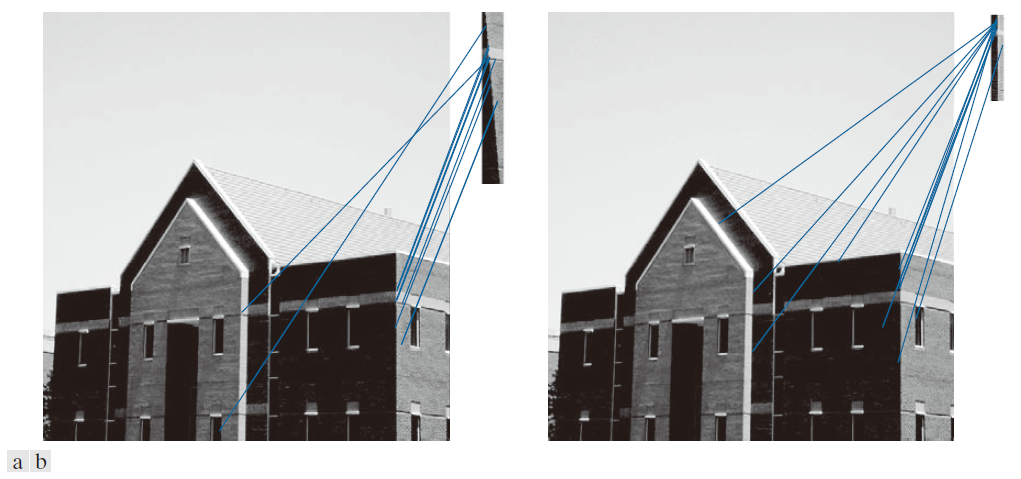
---------------------------图 11.66:(a) 原建筑图像与其右下角旋转图像的匹配项。共找到 10 个匹配项,其中 2 个错误。(b) 原图像与其右下角半缩放图像的匹配项。共找到 11 个匹配项,其中 4 个错误。----------------------------------------------