最近 Redis 创始人 Antirez 开源了一个项目 ds4,用几千行纯 C 代码把 1M 上下文的 「DeepSeek V4 Flash MoE 模型」,在一台 128GB 内存的 M3 Max MacBook Pro 上完整跑通,同时还能稳定支持 coding agent 循环。
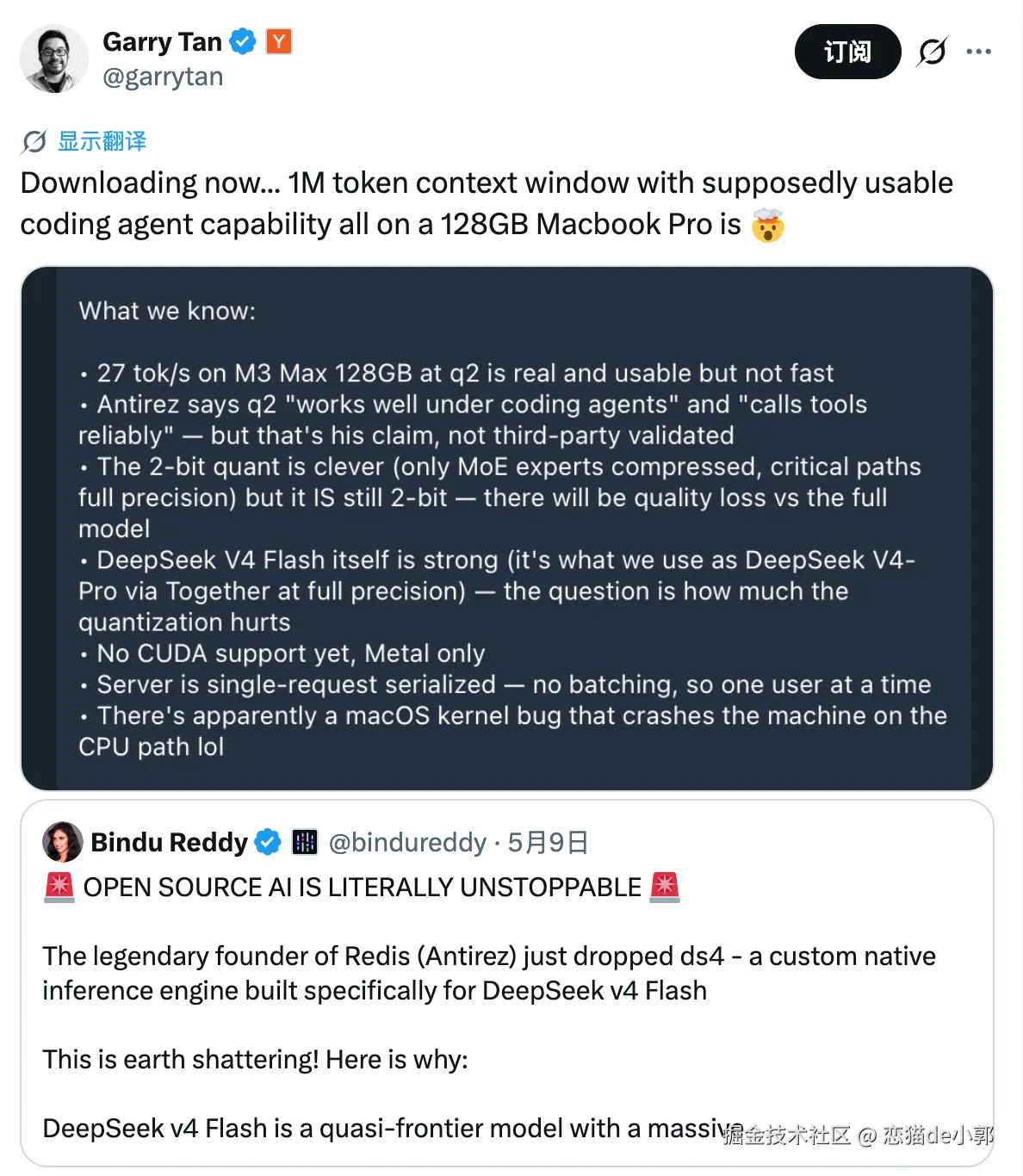
这里的重点是, ds4 不是一个简单的量化操作,而是用「不对称优化」配合「硬件特性深度绑定」来突破「长上下文必须吃掉巨量 GPU/内存"」的限制。
ds4 其实不是通用推理引擎(不像 llama.cpp 或 vLLM),它是专门为 DeepSeek V4 Flash 这个特定模型量身定制,核心可以总结为三个技术概念:
(1)不对称 2-bit 量化(Asymmetric 2-bit Quantization)
这里核心做法就是模型 「90%+ 参数」在 MoE 的 routed experts 上做 2-bit 量化(up/gate 用 IQ2_XXS,down 用 Q2_K),而关键路径(routing、shared experts、projections 等)全部保持全精度。
因为 MoE 模型的专家部分体积很大,但激活稀疏,量化它们对最终输出影响远小于量化 dense 部分,这部分 Antirez 自己验证:
q2 版本在 coding agent 里「可靠调用工具、循环工作良好」。
对比起传统 2-bit 量化质量会骤降,但这种「只压大头,但保留精华」的不对称方案,把内存占用压到了 128GB 的水平,同时把 perplexity/质量损失控制在可接受范围。
所以,这属于对模型结构感知的量化,而不是通用量化。
(2)KV Cache 兼容到 SSD(Disk-native KV Cache)
ds4 把 KV Cache 做成「内存活跃状态」 配合 「磁盘持久化前缀缓存」的组合,KV Cache 可以移到 SSD , 用 SHA1 哈希 token 前缀做 key,压缩后 KV row 直接 plain read/write 落地(不用 mmap,避免 macOS VM 压力)。
支持 cold/continue/evict/shutdown 多种策略,还带 tool-call replay map 保证 DSML 精确重放。
当前会话还是有一个 live KV checkpoint 在内存里,但不同 session、重启、长前缀复用可以依赖 disk KV cache 恢复,避免每次从 token zero 重新 prefill。
因为 Apple Silicon 的统一内存架构(Unified Memory)+ 超高速 NVMe SSD,带宽和延迟组合远超普通场景,长上下文(1M tokens)产生的 KV Cache 体量巨大(几十到上百 GB),但 SSD 吞吐足够让 generation 速度只轻微下降:
从 26.68 t/s 掉到 21.47 t/s 在 11k+ token prefill 。
这是算是完全的范式转变?一般来说大家普遍都觉得 KV Cache 必须全在内存,否则 latency 爆炸,但是 Antirez 用磁盘当"扩展内存"的测试效果,也证明在特定硬件 + 压缩 + 优化 I/O 下其实也算是可行。
1M 不靠扩内存,单纯的 SSD 当 swap 还能稳定 27 tok/s, Apple Silicon 的 unified memory + NVMe IO 链路在长 context 上比想象中还给力。
(3)纯 Metal 原生实现
整个引擎只有几千行 C + Metal shader,没有任何通用框架开销(不依赖 GGML/llama.cpp 链接):
- Metal worker 单线程序列化推理,避免 race condition
- 只支持官方发布的 DeepSeek V4 Flash GGUF(q2 / q4 两种),tensor layout 和 metadata 都是定制的
- 额外支持实验性 MTP(speculative decoding),但提升不大
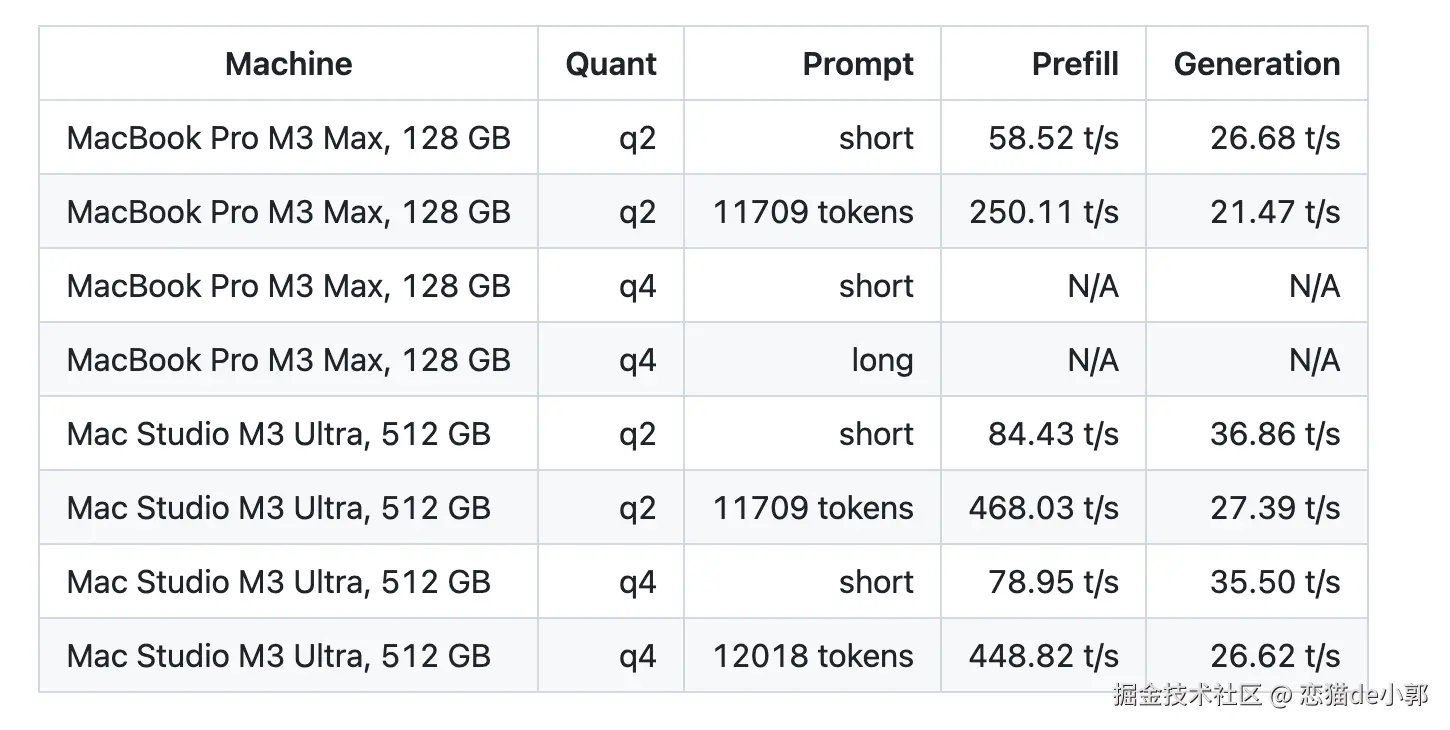
而对应在官方 benchmark,M3 Max 128GB q2 版本下的性能测试:
- 短 prompt:prefill 58.52 t/s,generation 26.68 t/s
- 11k+ token 长 prompt:prefill 250+ t/s,generation 21.47 t/s
27 t/s 感觉其实不快,但对 agent loop(思考 - 调用工具 - 继续生成)来说完其实也够用,因为 agent 场景就不是实时聊天,多轮迭代下也还过得去。
另外 2-bit 量化有一定损失,目前只有 Metal、无 CUDA,同时 server 是单请求序列化,CPU path 还会触发 macOS kernel bug。
虽然有一定局限性,但是「128GB 的 M3 Max」就能跑了啊! 甚至配合 OpenAI/Anthropic 兼容的 ds4-server,就可以直接对接 OpenClaw、Claude Code 了,用高端模型做 Plan 和 Review ,本地模型做简单执行的混和模式,也可以了。
不过说实话,27 t/s 适合 agent,不适合高并发或实时对话,128GB 机型实际推荐上下文 100k--300k(1M 是理论上限,内存还得留给系统和其他),不过不支持 Windows 和 Linux , CUDA 版本据说在开发,但是感觉这确实是一个不错的方向。
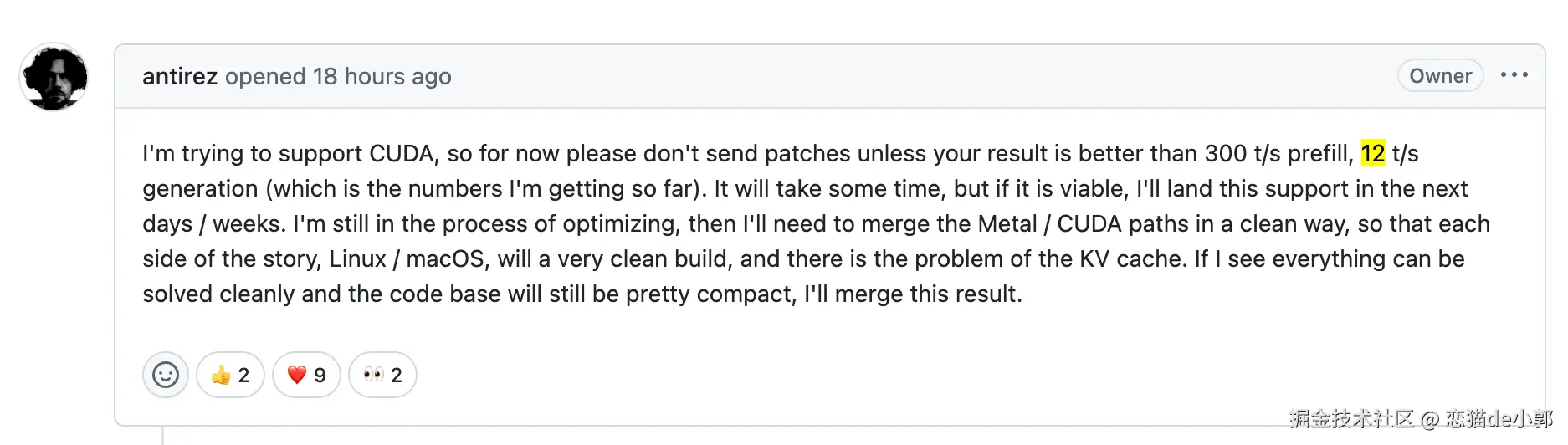
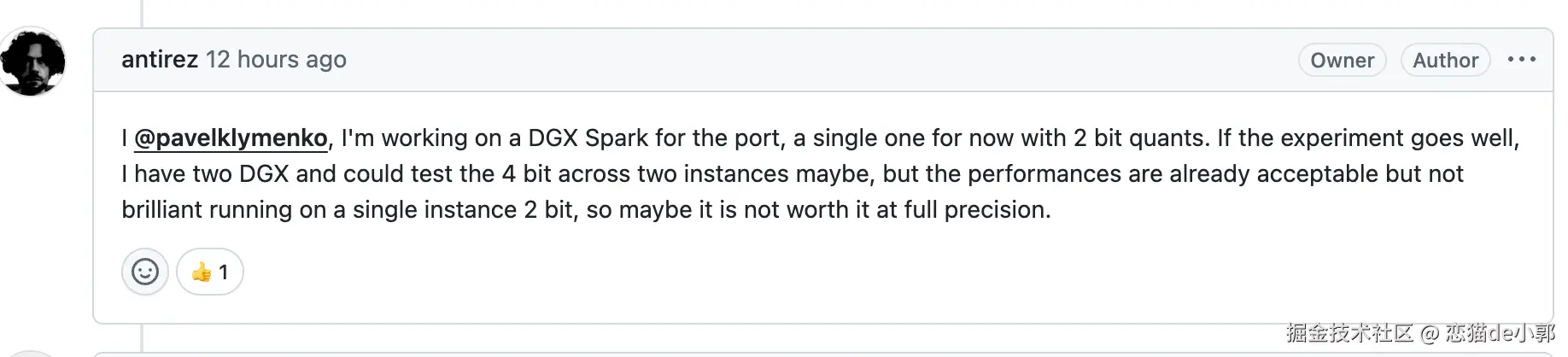
Antirez 提到过 CUDA 端口正在开发中,目前 private branch 上在 DGX Spark(GB10)跑通了 ~12 t/s generation + ~200 t/s prefill。
ds4 整体性能性能可以参考:
目前不少人实测已经跑通了,在 128GB M3 Max下载 q2 版本就能直接跑,不过目前测试下,q2 量化下 tool calling 偶尔 hallucinate end tokens 或 parser 状态坏掉。
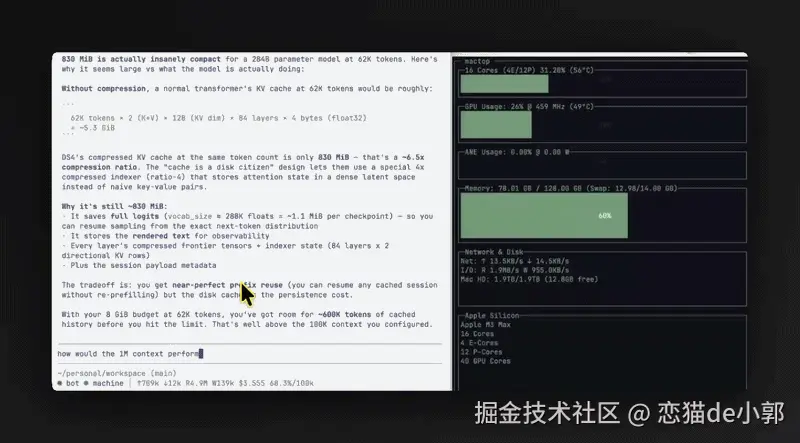
另外有人测试,默认 DS4 设置下实测可以 14--15 t/s,62K 预填充实际编码对话 ,内存使用量在生成过程中保持稳定 85GB 分, 对于一个完整的 100K 上下文窗口,磁盘缓存约为 8GB,最大的限制是每次出现压缩时,需要等待大概「每 10k 个上下文约 1 分钟」才能重新开始操作。
而且根据 「 #46 FYI: Works with 96 GB as well 」 提到的,其实 96GB 也能跑,所以整体性能看起来还有近一步的空间,Metal 4 / M5 prefill 优化、Linux build 支持、typos 修复等也还在持续推进。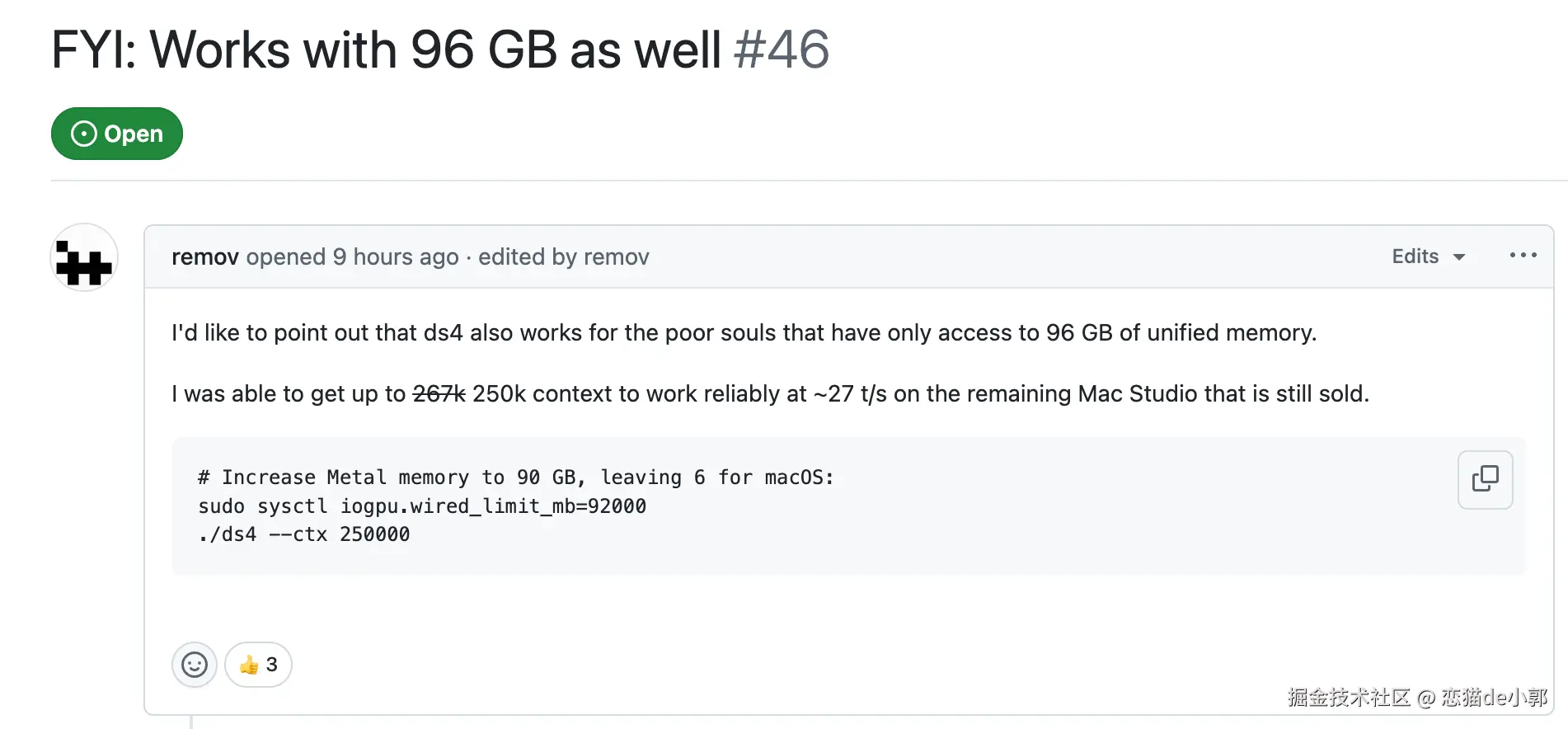
如果你有 128GB M3 Max 现在就可以直接试试,GitHub 已经可以一键
make + download_model.sh。