网上说"RAG 过时了",这个说法有点夸张。更准确地说是:传统"切块 + 向量库 + 相似度召回"的粗糙 RAG 正在被升级 ,而不是 RAG 消失了。现在流行的 Markdown、llms.txt、llms-full.txt、Wiki,本质上还是在做"让 AI 更容易拿到正确上下文",只是数据组织方式更轻、更结构化、更适合 Agent 读取。下面会拿ebay外挂客服的一个方案举例
先区分几个概念
RAG 是什么
RAG = Retrieval-Augmented Generation,意思是:
用户提问 → 系统先检索相关资料 → 把资料塞给大模型 → 大模型基于资料回答。
LangChain 现在仍然把 retrieval 到 RAG 作为主流方案:检索让 LLM 在运行时拿到相关上下文,而 RAG 是把检索结果和生成结合起来,产出有依据的回答。(LangChain 文档)
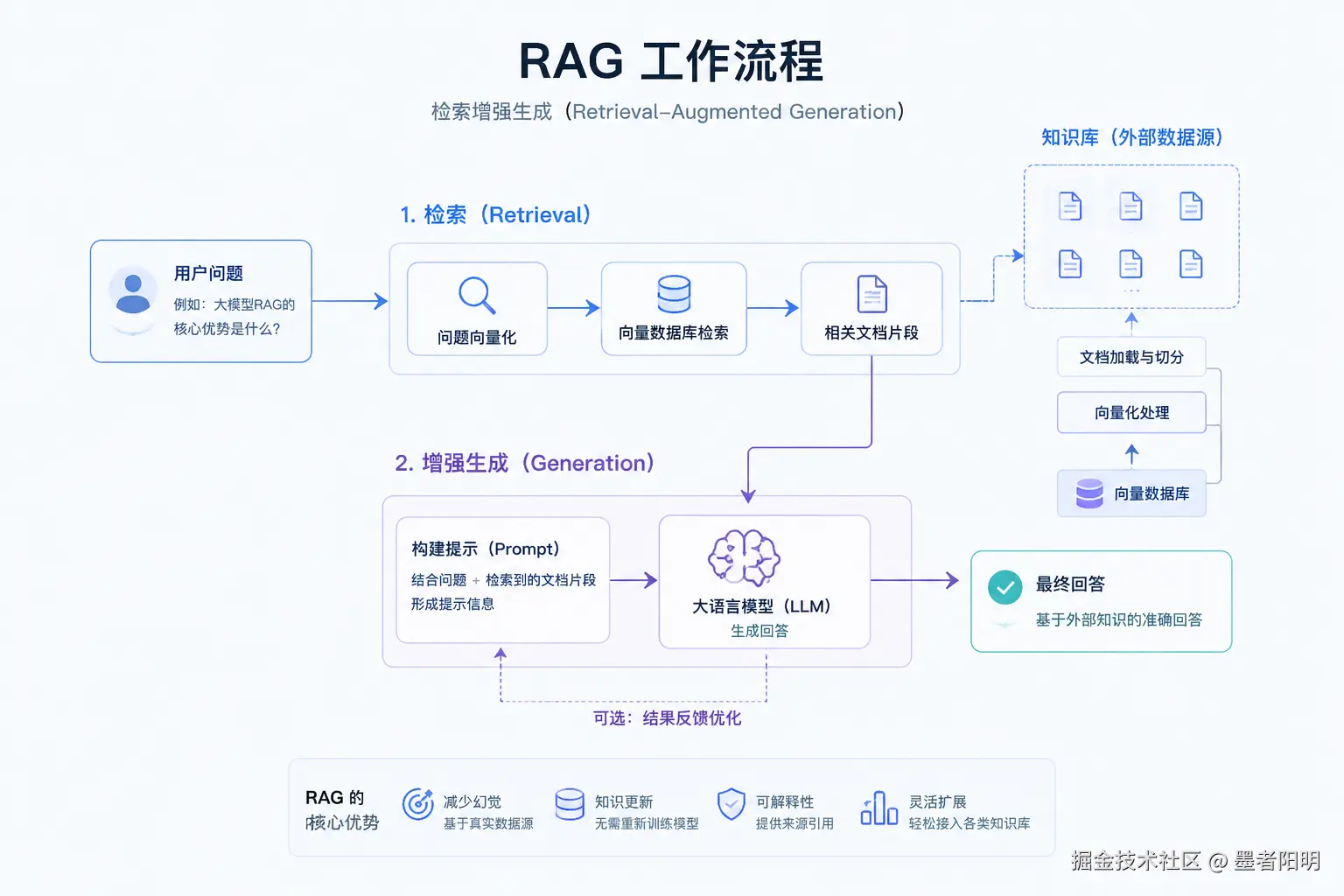
所以 RAG 没过时,过时的是这种低质量做法:
ini
把所有 Word/PDF/网页乱切成 500 字
全部丢进向量库
用户一问就 topK=5
然后让模型硬答这种容易出现:召回错、上下文碎、重复内容多、答案幻觉、成本高。
Markdown 检索为什么火了?
Markdown 的优势是:天然结构化。
比如一篇知识文档:
shell
# 退款规则
## 买家未付款
如果买家未付款,卖家可以在 4 天后取消订单。
## 买家已付款
如果买家已付款,需要走退款流程。这比 HTML、PDF、Word 更适合 AI,因为它有:
标题层级
列表
代码块
表格
链接
引用Mintlify 也提到,Markdown 可以绕开复杂 HTML、广告、JavaScript、导航栏等噪音,让 LLM 更容易消费干净内容。(Mintlify)
所以现在很多 AI 知识库会先做:
perl
网页 / Word / PDF
↓
清洗成 Markdown
↓
按标题结构切块
↓
grep / 全文检索 / 向量检索 / Agent 读取grep Markdown 文件怎么做 AI 检索?
最简单的方式不是向量库,而是直接用 grep 或更推荐的 ripgrep,命令是 rg。
假设你的知识库目录是这样
csharp
knowledge-base/
ebay/
shipping.md
refund.md
listing-title.md
tech/
rag.md
docker-postgresql.md
wow/
patch-12.0.7.md用户问:
eBay 买家未付款怎么处理?最简单可以直接搜索关键词:
csharp
rg "未付款|取消订单|buyer did not pay|unpaid" knowledge-base/返回:
bash
knowledge-base/ebay/refund.md
12: 如果买家未付款,卖家可以在 4 天后取消订单。然后 AI 读取这个文件附近内容,再回答。
grep 检索的具体操作流程
第一步:把所有知识文档转成 .md
比如:
css
原始资料:
PDF、Word、HTML、飞书文档、Notion、Wiki、网页
转换后:
xxx.mdMarkdown 文件建议统一格式:
yaml
---
title: eBay 退款规则
category: ebay
updated: 2026-05-01
source: internal
---
# eBay 退款规则
## 买家未付款
具体规则......
## 买家已付款
具体规则......前面的 --- 是元信息,叫 frontmatter,方便后面过滤。
第二步:用 rg 做全文检索
安装:
bash
# Windows,使用 winget
winget install BurntSushi.ripgrep.MSVC
# macOS
brew install ripgrep
# Ubuntu
sudo apt install ripgrep常用命令:
csharp
# 搜索关键词
rg "退款" knowledge-base/
# 忽略大小写
rg -i "refund" knowledge-base/
# 显示上下文,前后各 3 行
rg -C 3 "未付款" knowledge-base/
# 只搜 Markdown 文件
rg "未付款" knowledge-base/ -g "*.md"
# 搜多个词
rg "未付款|退款|取消订单" knowledge-base/
# 显示文件名和行号
rg -n "SpeedPAK" knowledge-base/第三步:让 AI 根据 grep 结果读取相关文件
一个简单的 AI 检索流程可以是:
markdown
用户问题:
"SpeedPAK 显示 out for delivery 很久没更新怎么办?"
系统操作:
1. 从问题中提取关键词:
SpeedPAK、out for delivery、last-mile、物流、派送
2. 执行:
rg -C 5 "SpeedPAK|out for delivery|last-mile|派送|尾程" knowledge-base/
3. 找到相关 Markdown 文件:
ebay/shipping-speedpak.md
4. 读取相关段落
5. 让模型基于这些段落回答伪代码:
javascript
import { execSync } from "node:child_process";
import fs from "node:fs";
function searchMarkdown(query) {
const cmd = `rg -n -C 5 "${query}" ./knowledge-base -g "*.md"`;
return execSync(cmd, { encoding: "utf-8" });
}
const result = searchMarkdown("SpeedPAK|out for delivery|last-mile|派送");
console.log(result);grep Markdown 适合什么场景?
适合:
文档数量不大:几十篇、几百篇、几千篇
关键词比较明确
文档结构比较清楚
技术文档、FAQ、规则文档、客服知识库
需要低成本、可控、透明不适合:
用户问题和文档关键词差异很大
需要语义理解
文档非常多
问题很抽象
需要跨多个文档综合推理举个例子。
用户问:
买家拍下后一直没付款,我能不能取消?grep 可以搜:
csharp
rg "未付款|取消" knowledge-base/但如果用户问:
订单卡住了,我现在怎么降低损失?这就不一定能直接命中关键词,需要语义检索或规则推理。
llms.txt 是什么?
llms.txt 是一个放在网站根目录的 Markdown 文件,比如:
arduino
https://example.com/llms.txt它的作用类似"给 AI 看的站点导航"。官方提案说明,/llms.txt 是一种标准化方式,用来帮助 LLM 在推理时使用网站信息。(llms-txt)
典型格式:
markdown
# My Docs
> This documentation explains how to use our API.
## Getting Started
- [Quickstart](https://example.com/docs/quickstart.md)
- [Authentication](https://example.com/docs/auth.md)
## API Reference
- [Create Order](https://example.com/docs/api/create-order.md)
- [Refund Order](https://example.com/docs/api/refund-order.md)它不是直接回答问题,而是告诉 AI:
这个网站有哪些重要文档
每个文档大概是什么
应该先看哪里很多文档平台已经支持自动生成 llms.txt 和 llms-full.txt。Mintlify 文档说它可以自动生成这两类文件,让 ChatGPT、Claude 等工具索引和理解文档。(Mintlify) Fern 也说明 llms.txt 和 llms-full.txt 是为了让 AI 工具发现和索引文档,单页还可以直接获取 Markdown。(Fern)
llms.txt 和 llms-full.txt 的区别
llms.txt
更像目录:
markdown
# eBay Seller Knowledge Base
> Internal knowledge base for eBay seller operations.
## Shipping
- [SpeedPAK delivery issues](./shipping/speedpak.md)
- [Packaging standards](./shipping/packaging.md)
## Listing
- [Title writing guide](./listing/title-guide.md)
- [Product condition description](./listing/condition.md)
## Buyer Messages
- [Offer negotiation templates](./messages/offers.md)
- [Shipping delay templates](./messages/shipping-delay.md)特点:
短
结构清楚
适合 Agent 先看目录,再决定读哪个文件llms-full.txt
更像把所有文档合并成一个大 Markdown:
shell
# eBay Seller Knowledge Base
## SpeedPAK delivery issues
完整内容......
## Packaging standards
完整内容......
## Offer negotiation templates
完整内容......X 的开发者文档也把 llms-full.txt 描述为"完整文档的单个 Markdown 文件",用于给 AI 工具完整上下文。(X Developer Platform)
特点:
内容完整
适合小型文档站
适合直接喂给长上下文模型
但太大时会浪费 tokenWiki 检索是怎么做的?
这里的 Wiki 可以分两类。
第一类:Git Wiki / Markdown Wiki
比如:
csharp
docs/
wiki/
knowledge-base/里面全是 .md 文件。
这种最简单,直接:
arduino
rg "退款|未付款|取消订单" wiki/或者加一个 llms.txt:
markdown
# Company Wiki
> Internal company knowledge base.
## eBay
- [Shipping](./ebay/shipping.md)
- [Refund](./ebay/refund.md)
- [Listing](./ebay/listing.md)
## AI Project
- [RAG Architecture](./ai/rag.md)
- [Agent Context Compression](./ai/context-compression.md)AI 操作流程:
markdown
1. 先读取 llms.txt
2. 判断问题属于哪个目录
3. rg 搜索相关 Markdown
4. 读取相关段落
5. 回答第二类:Confluence / Notion / MediaWiki 这种在线 Wiki
这种一般要先导出或同步:
arduino
Confluence / Notion / 飞书 / 语雀 / Wiki
↓
API 拉取页面
↓
转成 Markdown
↓
保存到本地 / Git / 对象存储
↓
建立 llms.txt
↓
grep / full-text / vector search操作架构:
css
定时任务
↓
拉取 Wiki 页面
↓
HTML 清洗
↓
转 Markdown
↓
按 page_id 保存
↓
生成目录 llms.txt
↓
提供给 AI 检索文件可以保存成:
markdown
wiki-md/
confluence/
refund-policy.md
shipping-rules.md
sdk-design.md
llms.txt
llms-full.txtgrep Markdown、Wiki、RAG 怎么组合?
最推荐的是混合方案,不要二选一。
小型知识库:grep + Markdown 就够了
适合你现在"几百篇以前的知识文档"的情况。
用户问题
↓
关键词提取
↓
rg 搜 Markdown
↓
读取命中文件附近内容
↓
AI 回答优点:
简单
便宜
可解释
不用向量库
不用复杂部署缺点:
同义词弱
语义理解弱
跨文档总结弱中型知识库:Markdown + PostgreSQL 全文检索
你之前问过 PostgreSQL,这里可以这样做:
sql
Markdown 文件
↓
入库 PostgreSQL
↓
使用 full-text search
↓
按关键词、标题、分类、更新时间检索表结构示例:
vbnet
CREATE TABLE docs (
id SERIAL PRIMARY KEY,
title TEXT,
path TEXT,
category TEXT,
content TEXT,
updated_at TIMESTAMP
);查询:
scss
SELECT title, path, content
FROM docs
WHERE to_tsvector('simple', content) @@ plainto_tsquery('simple', 'SpeedPAK delivery')
LIMIT 10;适合:
文档几千篇
需要权限控制
需要 Web 管理后台
需要按分类、时间、部门过滤大型知识库:全文检索 + 向量检索 + rerank
这才是比较完整的新式 RAG。
erlang
用户问题
↓
query rewrite 查询改写
↓
关键词检索:BM25 / PostgreSQL FTS / Elasticsearch
↓
向量检索:pgvector / Milvus / Qdrant
↓
结果合并
↓
rerank 重新排序
↓
上下文压缩
↓
模型回答这不是 RAG 过时,而是 RAG 变成了:
结构化知识库 + 多路检索 + 上下文工程 + Agent 工具调用## 一个适合你的落地方案你现在有几百篇知识文档,我建议别一上来就搞复杂向量库。可以这样做:
阶段 1:全部转 Markdown
目录:
markdown
kb/
ebay/
shipping/
listing/
buyer-message/
ai/
rag/
sdk/
tech/
docker/
frontend/
llms.txt
llms-full.txt每篇文档前面加元信息:
yaml
---
title: SpeedPAK 派送异常处理
category: ebay/shipping
updated: 2026-05-02
tags: [SpeedPAK, out for delivery, last-mile, eBay]
---
# SpeedPAK 派送异常处理
## 场景
当物流显示 out for delivery 但长时间未更新......
## 处理方式
建议买家联系当地尾程派送商......阶段 2:生成 llms.txt
markdown
# Robin Knowledge Base
> Personal knowledge base for eBay selling, AI projects, programming, and content writing.
## eBay Seller
- [SpeedPAK 派送异常处理](./ebay/shipping/speedpak.md)
- [eBay 标题写法](./ebay/listing/title-guide.md)
- [买家议价回复模板](./ebay/buyer-message/offer-template.md)
## AI Project
- [RAG 知识库方案](./ai/rag/rag-architecture.md)
- [Agent 上下文压缩](./ai/agent/context-compression.md)
## Programming
- [Docker 安装 PostgreSQL](./tech/docker/postgresql.md)
- [Git Submodule 使用](./tech/git/submodule.md)阶段 3:本地 grep 检索
arduino
rg -n -C 4 "SpeedPAK|out for delivery|尾程|派送" kb/阶段 4:做一个简单 Node.js 检索服务
javascript
import { execFileSync } from "node:child_process";
function searchKb(query) {
const result = execFileSync(
"rg",
["-n", "-C", "4", query, "./kb", "-g", "*.md"],
{ encoding: "utf-8" }
);
return result;
}
const question = "SpeedPAK 显示 out for delivery 一直没更新怎么办?";
const keywords = "SpeedPAK|out for delivery|尾程|派送|物流";
const context = searchKb(keywords);
console.log(context);然后把 context 拼进 prompt:
markdown
你是知识库问答助手。只能基于下面资料回答。
用户问题:
SpeedPAK 显示 out for delivery 一直没更新怎么办?
检索资料:
{context}
请回答:
1. 原因
2. 建议处理方式
3. 可发送给买家的英文模板## Markdown / llms.txt / Wiki / RAG 对比| 方案 | 本质 | 优点 | 缺点 | 适合你吗 |
|---|---|---|---|---|
| grep Markdown | 关键词搜索本地 md 文件 | 简单、便宜、透明 | 语义弱 | 很适合起步 |
| llms.txt | 给 AI 的文档目录 | 结构清晰,适合 Agent | 不是检索引擎 | 建议做 |
| llms-full.txt | 全量 Markdown 合并 | 适合长上下文模型 | 大文档会浪费 token | 小知识库可用 |
| Wiki | 知识管理系统 | 人能维护,AI 能同步 | 需要导出/清洗 | 适合团队 |
| 传统 RAG | 向量检索 + 生成 | 能处理语义问题 | 容易召回错,成本高 | 后期再做 |
| 新式 RAG | 全文 + 向量 + rerank + 压缩 | 效果最好 | 架构复杂 | 文档变多后做 |
## 我的建议你可以按这个路线走:
sql
第一步:所有资料 Markdown 化
第二步:建立 kb/ 目录和 llms.txt
第三步:先用 rg 做关键词检索
第四步:接入 AI,让 AI 根据 grep 结果回答
第五步:文档超过几千篇后,再加 PostgreSQL full-text search
第六步:最后再加 pgvector 做语义检索也就是:
perl
不要一开始就重 RAG
先做 Markdown 知识库 + llms.txt + grep
再逐步升级成混合检索 RAG一句话总结:
RAG 没过时,过时的是"只靠向量库乱搜"的 RAG。现在更好的方式是先把知识整理成 Markdown/Wiki/llms.txt,再用 grep、全文检索、向量检索组合起来。