国产化之-GoldenDB配置参数调优指南
基于分布式数据库通用架构和GoldenDB技术白皮书,整理出GoldenDB各模块的关键配置分类及代表性参数,涵盖性能调优、资源管理和高可用等核心方面。
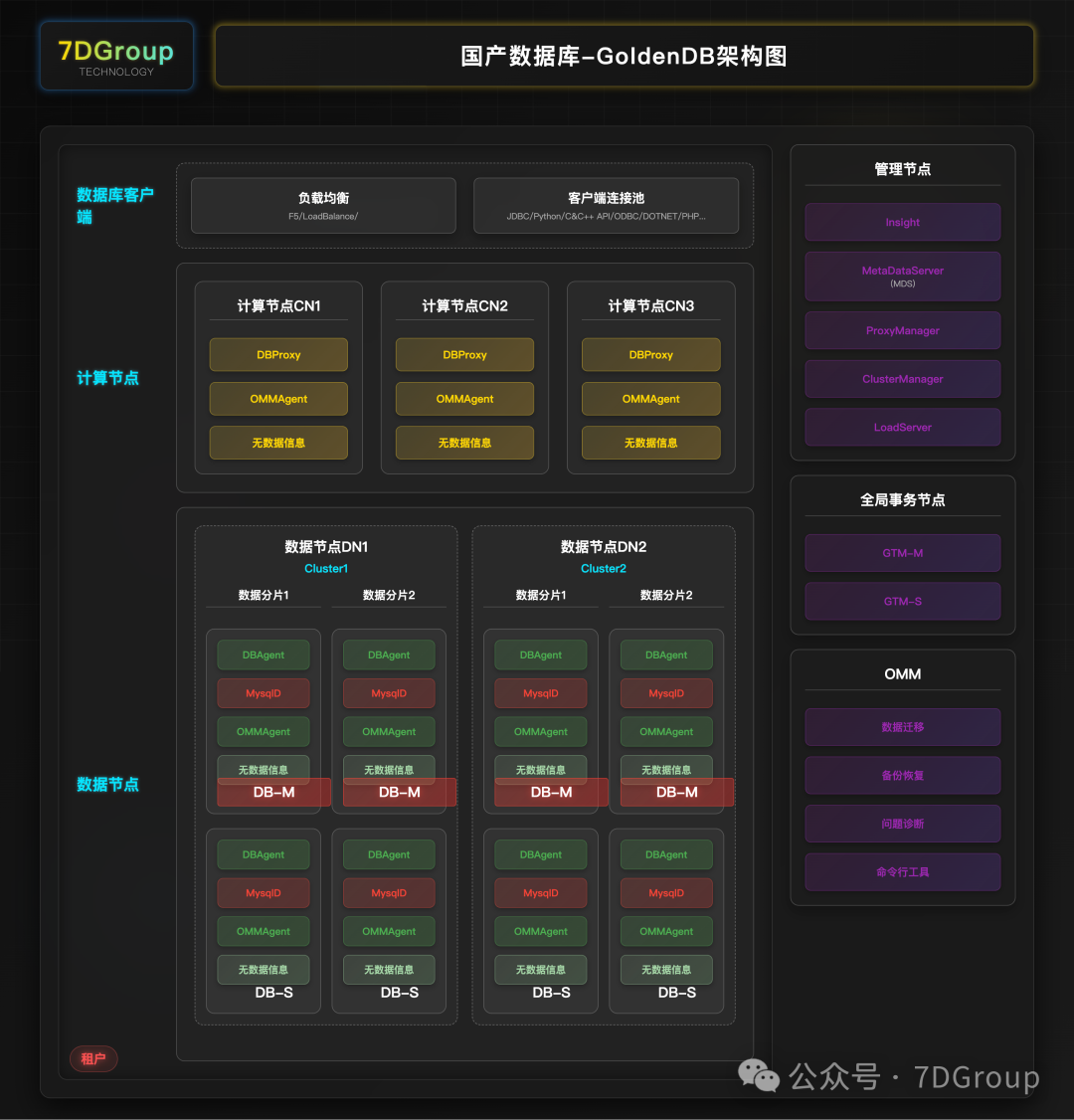
一、计算节点(CN)配置参数
1. 连接与会话管理
-
max_connections: 最大客户端连接数
-
调优方法 : 根据业务并发量设置,建议值 = (峰值QPS × 平均响应时间) / 并发系数。高并发场景建议2000-5000,监控
Threads_connected使用率,避免设置过大导致内存耗尽。计算公式:max_connections × 每连接内存(约256KB) < 可用内存的50% -
wait_timeout: 非交互连接超时时间(秒)
-
调优方法 : 默认28800秒(8小时),可根据业务空闲连接情况调整。OLTP场景建议1800-3600秒,避免长连接占用资源。监控
Threads_connected和Aborted_connects,如果空闲连接过多可适当降低 -
interactive_timeout: 交互式连接超时时间(秒)
-
调优方法: 通常与wait_timeout保持一致,交互式客户端(如mysql命令行)使用此参数。建议与wait_timeout相同,避免连接管理混乱
-
connection_pool_size: 连接池大小
-
调优方法: 客户端连接池大小,建议 = 并发线程数 × 1.5。应用层连接池(如HikariCP)建议10-50,避免连接池过小导致等待,过大导致资源浪费。公式:pool_size = (峰值TPS × 平均响应时间) / 并发度
-
max_prepared_stmt_count: 预处理语句缓存数量
-
调优方法 : 默认16382,高并发场景建议32768-65536。监控
Prepared_stmt_count使用率,如果经常达到上限会导致预处理失败。注意:每个预处理语句占用约8KB内存
2. 查询处理与优化
-
query_cache_size: 查询缓存大小(通常建议为0,依赖分布式缓存)
-
调优方法 : 分布式数据库通常禁用查询缓存,设置为0。如果启用,建议不超过256MB,监控
Qcache_hits和Qcache_lowmem_prunes,命中率低或频繁淘汰则建议关闭。注意:查询缓存锁竞争严重,高并发场景不建议使用 -
optimizer_switch: 优化器开关(索引合并等)
-
调优方法 : 根据查询特征调整,常用优化:
index_merge=on(索引合并)、index_condition_pushdown=on(索引条件下推)、derived_merge=on(派生表合并)。OLTP场景建议开启索引合并,OLAP场景可关闭部分优化减少优化器开销。通过EXPLAIN验证优化效果 -
join_buffer_size: JOIN操作缓冲区大小
-
调优方法 : 默认256KB,用于无法使用索引的JOIN操作。建议128KB-512KB,过大(>2MB)会占用过多内存。监控
Select_scan和Select_full_join,如果频繁全表扫描JOIN可适当增大,但优先优化索引 -
sort_buffer_size: 排序缓冲区大小
-
调优方法 : 默认256KB,用于ORDER BY和GROUP BY。建议256KB-2MB,每个排序操作独立分配。监控
Sort_merge_passes,如果值较大说明缓冲区不足,但注意:每个连接可能分配多个排序缓冲区,总内存 = sort_buffer_size × 连接数 × 并发排序数 -
max_execution_time: 查询最大执行时间(毫秒)
-
调优方法 : 防止慢查询长时间占用资源,OLTP场景建议5000-30000ms,OLAP场景可设置更大(300000ms)。结合
long_query_time使用,超时查询会被终止。注意:仅对SELECT语句生效
3. 内存管理
-
memory_limit: 单个CN节点内存上限
-
调优方法: 建议设置为物理内存的70-80%,预留系统和其他进程内存。例如64GB服务器建议45-50GB。监控系统内存使用率,避免OOM。注意:需要为操作系统、其他进程、临时表等预留足够内存
-
thread_cache_size: 线程缓存数量
-
调优方法 : 默认值通常为8,高并发场景建议16-32。监控
Threads_created和Connections,计算线程创建率 = Threads_created / Connections,如果>0.1说明缓存不足。公式:thread_cache_size ≈ 峰值并发连接数 × 0.1 -
table_open_cache: 表缓存数量
-
调优方法 : 默认2000,建议根据表数量设置,公式:表数量 × 1.5。高并发场景建议4000-8000。监控
Open_tables和Opened_tables,如果Opened_tables持续增长说明缓存不足。注意:每个表缓存占用约8KB内存 -
query_cache_limit: 单个查询结果缓存最大值
-
调优方法: 默认1MB,如果启用查询缓存,建议512KB-2MB。超过此大小的查询结果不会被缓存。根据业务查询结果大小调整,避免大结果集占用过多缓存空间
4. 分布式事务
-
xa_support: XA事务支持开关
-
调优方法: 分布式事务场景必须开启,但XA事务性能开销较大。如果业务不需要分布式事务(如单分片操作),可关闭提升性能。监控XA事务数量和耗时,评估是否必须使用XA
-
autocommit: 自动提交模式
-
调优方法: 默认ON,每条SQL自动提交。批量操作场景建议关闭(autocommit=0),使用显式事务减少提交次数,提升性能。注意:关闭后必须显式COMMIT或ROLLBACK,避免长事务锁等待
-
transaction_isolation: 事务隔离级别(读已提交/可重复读)
-
调优方法: 默认REPEATABLE-READ,分布式场景建议READ-COMMITTED以提升并发性能。READ-COMMITTED可减少锁等待,但可能出现不可重复读。根据业务一致性要求选择:强一致性用REPEATABLE-READ,高并发优先用READ-COMMITTED
二、数据节点(DN)配置参数
1. 存储引擎配置
-
innodb_buffer_pool_size: InnoDB缓冲池大小(通常为物理内存70-80%)
-
调优方法 : 最重要的参数,建议设置为物理内存的70-80%。例如64GB服务器建议45-50GB。监控
Innodb_buffer_pool_read_requests和Innodb_buffer_pool_reads,计算命中率 = (1 - reads/requests) × 100%,目标>99%。8.0+版本支持动态调整,可逐步增加观察效果 -
innodb_log_file_size: Redo日志文件大小
-
调优方法 : 默认48MB,建议256MB-2GB。日志文件总大小 = innodb_log_file_size × innodb_log_files_in_group(通常2个)。建议设置为1小时内写入量的1/4到1/2。过大恢复时间长,过小导致频繁checkpoint影响性能。监控
Innodb_log_waits,如果>0说明日志空间不足 -
innodb_flush_log_at_trx_commit: Redo日志刷盘策略(1/0/2)
-
调优方法: 1=每次提交刷盘(最安全,性能最低),0=每秒刷盘(性能最高,可能丢失1秒数据),2=每次提交写OS缓存(平衡)。金融场景必须=1,一般业务可用2提升性能。注意:主从复制场景主库建议=1,从库可用2
-
innodb_file_per_table: 每表独立表空间
-
调优方法: 建议ON,每表独立.ibd文件,便于管理和备份。OFF时所有表共享系统表空间,难以回收空间。生产环境必须开启,便于表空间管理和维护
-
innodb_page_size: 数据页大小(默认16KB)
-
调优方法: 默认16KB,通常不建议修改。如果表数据行很小(<100字节)且查询以单行为主,可考虑8KB减少内存占用。如果BLOB字段多,可考虑32KB或64KB。注意:修改需要重建表,且影响索引结构
2. 复制与高可用
-
replication_mode: 复制模式(异步/半同步/同步)
-
调优方法 : 异步模式性能最高但可能丢失数据,半同步保证至少一个从库收到数据,同步模式性能最低但最安全。一般业务用异步,金融核心业务用半同步。监控复制延迟
Seconds_Behind_Master,如果延迟持续增长需要优化或增加从库 -
sync_binlog: Binlog刷盘策略
-
调优方法: 0=依赖OS刷盘(性能最高),1=每次提交刷盘(最安全),N=每N次提交刷盘(平衡)。主从复制场景建议=1保证数据安全,单机场景可用0或100提升性能。注意:sync_binlog=0时服务器异常可能丢失binlog
-
gtid_mode: GTID模式开关
-
调优方法: 建议开启,便于主从切换和故障恢复。GTID模式下可以自动定位复制位置,避免手动指定binlog文件和位置。注意:开启GTID后需要重启,且从库需要重新搭建
-
slave_parallel_workers: 并行复制线程数
-
调优方法 : 默认0(串行复制),建议设置为CPU核心数的1/2到1倍。例如8核CPU建议4-8。监控
Slave_lag,如果延迟大且CPU使用率不高,可适当增加。注意:需要设置slave_parallel_type=LOGICAL_CLOCK才能生效
3. 性能调优
-
innodb_io_capacity: IOPS能力设置(SSD调高)
-
调优方法 : 默认200,SSD建议2000-4000,NVMe SSD建议4000-8000。根据实际IOPS能力设置,可通过
fio测试磁盘IOPS。监控Innodb_data_pending_reads和Innodb_data_pending_writes,如果持续>0说明IO能力不足。注意:设置过高可能导致IO过载 -
innodb_read_io_threads: 读IO线程数
-
调优方法 : 默认4,建议根据CPU核心数和IO负载调整,范围4-16。读密集型场景可适当增加,但超过16通常无效果。监控
Innodb_data_reads和IO等待时间,如果读等待时间长可增加线程数 -
innodb_write_io_threads: 写IO线程数
-
调优方法 : 默认4,建议与读IO线程数相同或略高。写密集型场景(如批量导入)可增加到8-16。监控
Innodb_data_writes和写IO等待,如果写等待时间长可增加线程数 -
innodb_buffer_pool_instances: 缓冲池实例数(减少锁竞争)
-
调优方法: 默认8,建议缓冲池每10GB对应1个实例,最大64个。例如64GB缓冲池建议8-16个实例。多个实例可以减少锁竞争,提升并发性能。注意:实例数必须是2的幂次方(1,2,4,8,16,32,64)
4. 日志配置
-
log_bin: Binlog开关
-
调优方法: 主从复制必须开启,单机场景如果不需要时间点恢复可关闭提升性能。开启后会产生binlog文件,需要定期清理。监控binlog文件大小和增长速度,评估磁盘空间需求
-
binlog_format: Binlog格式(ROW/STATEMENT/MIXED)
-
调优方法: ROW格式最安全(主从数据一致),但日志量大;STATEMENT格式日志小但可能不一致;MIXED自动选择。建议使用ROW格式,特别是涉及触发器、存储过程的场景。ROW格式下监控binlog文件大小,如果增长过快考虑优化SQL减少影响行数
-
expire_logs_days: Binlog保留天数
-
调优方法: 默认0(不自动删除),建议7-30天。根据备份策略设置,确保保留时间覆盖至少一次全量备份周期。监控binlog占用磁盘空间,如果空间紧张可适当减少,但需确保不影响备份恢复
-
slow_query_log: 慢查询日志开关
-
调优方法 : 生产环境建议开启,用于性能分析和优化。注意:开启后会产生IO开销,如果慢查询很多可能影响性能。可结合
log_queries_not_using_indexes记录未使用索引的查询 -
long_query_time: 慢查询阈值(秒)
-
调优方法: 默认10秒,OLTP场景建议0.5-2秒,OLAP场景可设置5-10秒。根据业务SLA设置,如果大部分查询都在阈值以下,可适当降低阈值捕获更多慢查询。监控慢查询日志大小和数量,定期分析优化
三、全局事务管理器(GTM)配置参数
-
gtm_host: GTM服务地址
-
调优方法: 配置主GTM地址,建议使用VIP或域名,便于故障切换。确保网络延迟低(<1ms),GTM是全局事务的瓶颈点。监控GTM连接状态和响应时间
-
gtm_port: GTM服务端口
-
调优方法: 使用默认端口,如需修改确保防火墙规则允许。建议与GTM服务配置保持一致,避免端口冲突
-
gtm_standby_host: 备GTM地址
-
调优方法: 配置备GTM实现高可用,主备GTM建议部署在不同机房。监控主备GTM同步状态,确保故障时能快速切换。建议使用GTM集群模式提升可用性
-
transaction_timeout: 全局事务超时时间
-
调优方法: 默认值通常为300秒,根据业务最长事务时间设置。建议设置为业务最长事务时间的2-3倍,避免正常事务被误杀。监控超时事务数量,如果频繁超时需要优化事务逻辑或适当增加超时时间
-
global_snapshot_interval: 全局快照生成间隔
-
调优方法: 控制全局一致性快照生成频率,默认通常为1秒。间隔越小一致性越好但GTM负载越高,间隔越大性能越好但可能影响读一致性。OLTP场景建议1-5秒,OLAP场景可设置10-30秒。监控GTM CPU使用率,如果过高可适当增加间隔
-
max_prepared_transactions: 最大预备事务数
-
调优方法: 限制两阶段提交中的预备事务数量,默认通常为100。根据业务并发事务数设置,建议 = 峰值并发事务数 × 1.5。如果达到上限会导致新事务等待,需要适当增加。注意:每个预备事务占用内存,需要平衡内存使用
四、管理节点(MAN)配置参数
1. 集群管理
-
cluster_name: 集群名称
-
调优方法: 设置唯一集群标识,便于多集群环境管理。建议使用有意义的命名规则,如:环境_业务_序号(prod_core_01)。注意:集群名称修改需要重启,且影响监控和日志标识
-
node_heartbeat_timeout: 节点心跳超时时间(秒)
-
调优方法: 默认通常为10-30秒,根据网络延迟设置。网络稳定环境可设置10-15秒,网络不稳定或跨机房可设置30-60秒。设置过小可能导致误判节点故障,设置过大故障检测延迟高。监控心跳失败次数,如果频繁失败需要检查网络或适当增加超时时间
-
auto_failover: 自动故障切换开关
-
调优方法: 生产环境建议开启,实现自动故障恢复。注意:自动切换可能导致短暂服务中断,需要评估业务容忍度。金融核心系统建议结合人工确认,避免误切换。监控failover事件和切换耗时
-
failover_timeout: 故障切换超时时间
-
调优方法: 设置故障切换的最大等待时间,默认通常为60-300秒。根据数据量和网络带宽计算,确保在超时时间内能完成数据同步和角色切换。建议 = 数据同步时间 × 2 + 缓冲时间。监控实际切换耗时,如果经常超时需要优化或增加超时时间
2. 备份恢复
-
backup_strategy: 备份策略(全量/增量)
-
调优方法: 全量备份数据完整但耗时耗空间,增量备份快速但依赖全量。建议策略:每日增量备份,每周全量备份。根据数据变更频率调整,高频变更场景可增加全量备份频率。监控备份耗时和成功率,确保在备份窗口内完成
-
backup_retention_days: 备份保留天数
-
调优方法: 根据合规要求和恢复需求设置,金融行业通常要求30-90天。建议至少保留2个全量备份周期,确保可以恢复到任意时间点。监控备份存储空间,如果空间紧张可适当减少但需满足合规要求
-
backup_compression: 备份压缩开关
-
调优方法: 建议开启,可减少50-70%存储空间,但会增加CPU开销和备份时间。根据CPU和存储情况选择,CPU充足场景建议开启。监控压缩比和备份耗时,评估压缩效果。注意:压缩备份恢复时需要解压,恢复时间可能增加
-
backup_encryption: 备份加密开关
-
调优方法: 敏感数据场景必须开启,符合数据安全要求。加密会增加CPU开销和备份时间,但提升数据安全性。建议使用AES-256加密算法,妥善保管加密密钥。监控加密备份的耗时和存储空间
3. 监控告警
-
metric_collection_interval: 指标收集间隔(秒)
-
调优方法: 默认通常为10-60秒,根据监控精度需求设置。高频监控(10-30秒)能及时发现异常但增加系统开销,低频监控(60-300秒)开销小但可能延迟发现。生产环境建议30-60秒,关键指标可单独设置更短间隔。监控指标收集对系统性能的影响,如果影响明显可适当增加间隔
-
alert_threshold_cpu: CPU告警阈值(%)
-
调优方法: 建议设置80-90%,持续超过阈值说明CPU资源不足。根据业务特点调整,OLTP场景建议80%,OLAP场景可设置90%。设置多级告警:警告(80%)、严重(90%)、紧急(95%)。监控CPU使用趋势,提前扩容避免告警
-
alert_threshold_memory: 内存告警阈值(%)
-
调优方法: 建议设置85-90%,超过阈值可能导致OOM。注意区分系统内存和数据库内存使用率,数据库内存建议单独监控。设置告警后需要立即处理,内存不足影响严重。监控内存使用趋势和swap使用情况
-
alert_threshold_disk: 磁盘使用率告警阈值(%)
-
调优方法: 建议设置80-85%,预留足够空间用于日志、临时文件等。设置多级告警:警告(80%)、严重(90%)、紧急(95%)。监控磁盘使用增长趋势,提前扩容或清理数据。注意:需要区分数据盘、日志盘、临时盘分别设置阈值
五、全局集群配置参数
1. 分布式架构
-
sharding_mode: 分片模式(范围/哈希/列表)
-
调优方法: 哈希分片适合均匀分布,范围分片适合范围查询,列表分片适合按业务分区。根据查询模式选择:点查询多用哈希,范围查询多用范围,业务隔离用列表。注意:分片模式一旦确定难以修改,需要提前规划。监控各分片数据量和负载,确保分布均匀
-
shard_number: 分片数量
-
调优方法: 建议设置为2的幂次方(4,8,16,32,64),便于扩展。分片数 = 总数据量 / 单分片容量(建议<500GB)。初始可设置较少分片,后续通过分片分裂扩展。注意:分片数过多增加管理复杂度,过少限制扩展性。监控单分片数据量和性能,如果达到瓶颈需要增加分片
-
replica_factor: 副本因子(每个分片的副本数)
-
调优方法: 通常设置为2-3,保证高可用。2副本可容忍1个节点故障,3副本可容忍2个节点故障。根据可用性要求设置,金融核心系统建议3副本。注意:副本数增加会提升可用性但增加存储和网络开销。监控副本同步延迟和健康状态
-
data_balance_strategy: 数据均衡策略(自动/手动)
-
调优方法: 自动均衡适合动态负载场景,手动均衡适合稳定场景。生产环境建议自动均衡,但需要设置均衡阈值避免频繁迁移。监控数据分布均匀度和迁移频率,如果迁移过于频繁可调整阈值或改为手动模式
2. 跨数据中心
-
dc_replication_mode: 跨数据中心复制模式
-
调优方法: 异步模式适合跨地域(延迟>10ms),同步模式适合同城(延迟<5ms)。根据网络延迟和一致性要求选择,一般跨地域用异步,同城双活可用同步。监控跨机房复制延迟,如果延迟过大影响业务可考虑异步模式
-
dc_latency_threshold: 跨机房延迟阈值(毫秒)
-
调优方法: 设置跨机房网络延迟上限,超过阈值触发告警或切换。同城建议5-10ms,跨地域建议50-100ms。根据实际网络延迟设置,设置过小可能误告警,过大可能影响业务。监控实际延迟分布,调整阈值使其在正常范围内
-
dc_failover_priority: 数据中心故障切换优先级
-
调优方法: 设置多个数据中心的故障切换优先级,优先级高的优先切换。建议主数据中心优先级最高,备用数据中心按重要性排序。注意:需要结合网络延迟、数据一致性等因素综合考虑。定期演练故障切换,验证优先级配置正确性
3. 安全配置
-
ssl_enabled: SSL加密开关
-
调优方法: 生产环境建议开启,保护数据传输安全。SSL会增加CPU开销(约5-10%)和连接建立时间,但提升安全性。内网环境如果安全可控可关闭提升性能,外网访问必须开启。监控SSL连接数和CPU使用率,评估性能影响
-
audit_log: 审计日志开关
-
调优方法: 合规要求场景必须开启,记录所有数据库操作。审计日志会产生大量IO和存储开销,需要评估存储容量。建议只审计关键操作(如DDL、DCL),减少日志量。监控审计日志大小和IO影响,定期归档清理
-
password_policy: 密码策略(复杂度要求)
-
调优方法: 设置密码复杂度要求,包括长度、字符类型等。建议:最小长度8-12位,包含大小写字母、数字、特殊字符。根据安全等级调整,金融系统建议更严格策略。注意:过于严格可能影响用户体验,需要平衡安全性和可用性
-
ip_whitelist: IP白名单
-
调优方法: 限制允许访问的IP地址,提升安全性。建议只允许应用服务器和运维管理IP访问,禁止公网直接访问。使用CIDR格式配置IP段,便于管理。注意:需要确保应用服务器IP在白名单内,避免影响业务。定期审查白名单,移除不再使用的IP
六、客户端/驱动配置参数
1. 连接配置
-
load_balance_strategy: 负载均衡策略(轮询/最小连接)
-
调优方法: 轮询策略简单均匀,最小连接策略更智能但需要维护连接状态。如果CN节点性能相近用轮询,性能差异大用最小连接。监控各CN节点连接数和负载,确保负载均衡。注意:需要结合应用层连接池配置,避免连接分布不均
-
failover_enabled: 故障转移开关
-
调优方法: 生产环境建议开启,实现自动故障转移。故障转移会导致连接重建,可能有短暂中断。设置合理的重试次数和间隔,避免频繁重试影响性能。监控故障转移事件和恢复时间,评估对业务的影响
-
connection_timeout: 连接超时时间(毫秒)
-
调优方法: 默认通常为30秒,根据网络延迟设置。内网环境建议5-10秒,跨网络环境建议30-60秒。设置过小可能导致正常连接超时,过大可能影响故障检测速度。监控连接超时次数,如果频繁超时需要检查网络或增加超时时间
-
socket_timeout: Socket超时时间(毫秒)
-
调优方法: 设置Socket读写超时,防止长时间等待。建议设置为业务最长查询时间的2-3倍,默认通常为30-60秒。OLTP场景建议10-30秒,OLAP场景可设置60-300秒。监控超时事件,如果频繁超时需要优化查询或增加超时时间
2. 读写分离
-
read_write_splitting: 读写分离开关
-
调优方法: 读多写少场景建议开启,将读请求路由到从库,减轻主库压力。注意:需要处理主从延迟导致的数据不一致问题。监控主从延迟,如果延迟过大可能影响业务一致性。对于强一致性要求的读操作,需要强制读主库
-
read_weight: 读节点权重分配
-
调优方法: 根据读节点性能分配权重,性能好的节点权重高。例如:主库权重100,从库1权重80,从库2权重60。监控各读节点负载,如果负载不均需要调整权重。注意:权重总和影响负载分配比例,建议总和为100的倍数便于计算
-
transaction_route_policy: 事务路由策略(写节点优先)
-
调优方法: 事务内的所有操作路由到写节点,保证事务一致性。这是默认且推荐策略,避免主从延迟导致的事务数据不一致。注意:即使开启读写分离,事务内的读操作也会路由到主库。监控事务数量和主库负载,如果主库压力大需要优化事务逻辑
七、运维相关配置
1. 日志管理
-
log_level: 日志级别(DEBUG/INFO/WARN/ERROR)
-
调优方法: 生产环境建议INFO或WARN,开发环境可用DEBUG。DEBUG级别日志量大影响性能,生产环境不建议使用。根据问题排查需求调整,排查问题时临时调整为DEBUG,问题解决后恢复。监控日志文件大小和IO影响,如果影响性能可提高日志级别
-
log_retention_days: 日志保留天数
-
调优方法: 建议7-30天,根据存储空间和合规要求设置。关键日志建议保留更长时间,普通日志可适当缩短。监控日志占用磁盘空间,如果空间紧张可减少保留天数或启用日志压缩。注意:需要确保保留时间满足问题排查和审计要求
-
log_rotation_size: 日志轮转大小(MB)
-
调优方法: 默认通常为100-500MB,建议100-200MB。设置过小导致频繁轮转影响性能,过大导致单个日志文件过大不便查看。监控日志轮转频率,如果过于频繁可适当增大,如果很少轮转可适当减小。注意:需要结合日志保留策略,确保总日志量在可控范围内
2. 性能采集
-
metrics_export_interval: 指标导出间隔
-
调优方法: 控制性能指标导出到监控系统的时间间隔,默认通常为10-60秒。根据监控系统需求和系统开销设置,高频导出(10-30秒)数据更实时但开销大,低频导出(60-300秒)开销小但可能遗漏短期异常。生产环境建议30-60秒。监控指标导出对系统性能的影响
-
profiling_enabled: SQL性能剖析开关
-
调优方法: 用于分析SQL执行性能,开启后记录SQL执行各阶段耗时。建议在性能优化时临时开启,问题解决后关闭,因为会产生额外开销。注意:只对当前会话生效,需要为每个会话单独开启。分析完成后及时关闭,避免长期开启影响性能
-
trace_enabled: 分布式跟踪开关
-
调优方法: 用于跟踪分布式事务和跨节点操作,帮助定位性能瓶颈。建议在排查分布式性能问题时开启,生产环境不建议长期开启。跟踪会产生大量日志和性能开销,需要评估影响。注意:可以设置采样率,只跟踪部分请求减少开销
八、GoldenDB特有参数示例
注:以下为基于技术白皮书推测的参数,实际以官方文档为准
-
global_query_cache: 全局查询缓存开关
-
调优方法: GoldenDB分布式场景下的全局查询缓存,可缓存跨分片查询结果。建议在查询重复度高且数据变更不频繁的场景开启。监控缓存命中率和内存使用,如果命中率低(<30%)建议关闭。注意:数据频繁变更的场景不建议使用,缓存失效开销大
-
cross_shard_join_limit: 跨分片JOIN限制
-
调优方法: 限制跨分片JOIN操作的分片数量,防止JOIN操作涉及过多分片导致性能下降。建议根据业务查询模式设置,OLTP场景建议2-4个分片,OLAP场景可设置更大。监控跨分片JOIN的执行时间和涉及分片数,如果性能差需要优化表结构或增加限制
-
distributed_lock_timeout: 分布式锁超时时间
-
调优方法: 设置分布式锁获取的超时时间,防止死锁长时间等待。默认通常为30-60秒,根据业务操作耗时设置。建议设置为最长操作时间的2-3倍,避免正常操作超时。监控锁超时事件,如果频繁超时需要优化锁粒度或增加超时时间
-
online_ddl_timeout: 在线DDL超时时间
-
调优方法: 在线DDL操作的最大执行时间,超过时间可能回滚或转为离线DDL。根据表大小和DDL类型设置,小表建议300-600秒,大表建议1800-3600秒。监控DDL执行时间和成功率,如果经常超时需要优化DDL策略或增加超时时间。注意:在线DDL会占用资源,建议在业务低峰期执行
-
data_rebalance_threshold: 数据重均衡阈值(%)
-
调优方法: 触发数据重均衡的数据分布不均衡阈值,默认通常为10-20%。设置过小可能导致频繁重均衡影响性能,设置过大可能导致负载不均。建议根据业务负载特点设置,稳定负载场景可设置20-30%,动态负载场景可设置10-15%。监控重均衡频率和效果,调整阈值使其在合理范围内
-
tenant_resource_quota: 租户资源配额
-
调优方法: 多租户场景下限制每个租户的资源使用(CPU、内存、IO等)。根据租户重要性和付费等级分配配额,核心租户配额高,普通租户配额低。监控各租户资源使用率,如果经常达到上限需要调整配额或优化租户业务。注意:需要预留系统资源,避免所有租户配额总和超过系统容量
-
tenant_isolation_level: 租户隔离级别
-
调优方法: 设置租户间的隔离级别,包括数据隔离、资源隔离等。金融云场景建议强隔离,确保租户间互不影响。隔离级别越高安全性越好但资源利用率越低,需要平衡。监控租户间资源竞争情况,如果存在影响需要提高隔离级别
配置管理建议
1. 配置文件层级
bash
GoldenDB/
├── cluster.conf # 集群全局配置
├── cn/
│ ├── cn_server.conf # CN服务配置
│ └── cn_router.conf # CN路由配置
├── dn/
│ ├── my.cnf # DN数据库配置
│ └── replication.conf # DN复制配置
├── gtm/
│ └── gtm.conf # GTM配置
├── man/
│ └── manager.conf # 管理节点配置
└── client/
└── jdbc.properties # 客户端连接配置2. 参数调整优先级
sql
-- 必须立即重启生效的参数
SET GLOBAL max_connections=2000; -- 需要重启
-- 动态生效参数
SET GLOBAL innodb_buffer_pool_size=128G; -- 8.0+可动态调整
SET GLOBAL thread_cache_size=32; -- 立即生效3. 监控参数生效
sql
-- 查看当前参数值
SHOW VARIABLES LIKE 'innodb_buffer_pool%';
-- 查看运行状态
SHOW GLOBAL STATUS LIKE 'Threads_connected';
-- GoldenDB特有命令(推测)
SHOW DISTRIBUTED STATUS; -- 查看分布式状态重要提醒
- 版本差异:GoldenDB不同版本(v5.x/v6.x)参数可能不同
- 环境依赖:参数值与硬件配置(CPU/内存/磁盘)强相关
- 业务适配:OLTP和OLAP场景参数优化方向不同
- 官方文档:生产环境调整前务必参考《GoldenDB参数调优指南》
- 变更管理:重要参数变更需在测试环境验证,并制定回滚方案
如果需要针对特定场景(如高并发交易、批量处理)的配置模板,可提供具体业务需求,我会进一步给出优化建议。