流程控制型
提示词链、路由|任务分解与智能分发
效率提升型
并行化、资源感知优化|速度与成本优化
质量保障型
反思、评估与监控|质量与安全
协同管理型
多智能体协作、人类在环|人机协作
知识处理型
RAG、记忆管理|信息检索与上下文
推理决策型
推理技术、目标监控、优先级管理|智能决策
错误处理型
异常处理与恢复、学习与适应|容错与改进
通信协作型
智能体间通信|分布式协同
高级模式
规划、工具使用、探索与发现|综合能力
一、流程控制型模式
1. 提示词链(Prompt Chaining)
将复杂任务分解为多个小步骤,按顺序逐一执行,每步验证前一步结果后再传递给下一步
流程:
用户输入 → 任务分解 → 执行任务1 → 验证输出1 → 执行任务2 → 验证输出2 → ... → 结果合并- 每一步都
验证前序结果的正确性 - 失败时会持续重试直到通过
- 可
回溯整个流程定位问题 模块化设计,可替换链中任意环节
场景:
- 文档处理、ETL数据流
- 代码生成
- 内容创作流程
- 数据清洗与标准化(如处理脏数据)
优点:
- 在问题发生前多次捕获失败
- 模块化程度高
缺点:
上下文爆炸:链式过长时将所有上下文带到后续步骤,导致成本飙升和幻觉风险- 错误传播 :链中每个环节会
继承最初错误 - 延迟增加(多模型推理点)
实践 :3-5步的链式结构已足够完成验证,超过此范围边际效益递减。
2. 路由(Routing)
接收请求后分析意图,根据需求将请求路由到对应的专家智能体,如同智能接待员分诊台。
工作流程:
用户请求 → AI分析意图 → 置信度评估 → 路由到专业智能体 → 返回结果- 当置信度不足时应回溯请求澄清
- 置信度可以是LLM生成的数值评分(如十分制)
- 需要添加确定性机制防止幻觉导致的误判
- 可设置管理智能体评估初始路由决策
场景:
- 多领域客户服务(技术、销售、账户管理)
- 企业自动化工作流
- 医疗分诊系统
- 防止智能体误用工具
优点:专业化、可扩展性、高效率
缺点:
- 存在路由到错误路径的可能
- 边缘情况处理复杂
- 需要隔离机制和人工介入环节
二、效率提升型模式
3. 并行化处理(Parallelization)
将大任务拆分为多个独立子任务,由多个工作者智能体同时处理,最后汇总结果。
类比:10人同时阅读一本书的不同章节,最后整合所有摘要。
工作流程:
原始输入 → 分析任务 → 拆分为独立子任务 → 生成多个并行工作者 → 各工作者执行 → 结果统一格式 → 合并输出 → 生成摘要- 每个工作者被视为独立"员工智能体"
- 失败时会持续重试直到完成
- 需要统一输出格式(苹果、橘子、菠萝→统一为某种格式)
- 可溯源结果来源,便于定位失败点
场景:
- 大规模数据处理
- 时间敏感操作
- 网络爬虫(多步骤并行)
- 文档处理、数据增强、研究自动化、测试框架
优点:
- 专业化能力强
- 可线性扩展(无需融资即可增加更多资源)
缺点:
- 复杂性随规模增加
- 统一所有工作者输出的挑战
- 需引入管理机制(类似公司HR)
4. 资源感知优化(Resource-Aware Optimization)
根据任务复杂度动态选择合适的模型------简单任务用廉价快速模型,复杂任务用强大但昂贵的模型。
类比:根据距离和紧急程度选择步行、公交或出租车。
工作流程:
任务输入 → 复杂度评估(预算限制/令牌限制) → 路由智能体分类(简单/中等/复杂) → 路由到对应模型 → 执行并监控资源 → 结果输出复杂度判定方式:
- 简单任务 → 小模型
- 中等复杂度 → 标准模型
- 复杂任务 → 推理模型(如GPT-o1、Claude的extended thinking)
- 未知情况 → 运行快速测试判定
监控指标:
- 令牌消耗
- 响应时间
- API成本
优化技术:
- 削减提示中的上下文
- 提示缓存(Prompt Caching):LLM物理缓存结果最多1小时,持续引用无需重复发送所有上下文
- 回退到更便宜的模型
场景:
- 成本敏感操作
- 高吞吐量处理
- 预算受限的企业级SaaS平台
优点:显著降低运营成本(GPT-o5争议的核心)
缺点:
- 复杂度高、调优挑战大
- 边界情况多
- 需要非常严谨可靠的评判标准
三、质量保障型模式
5. 反思(Reflection)
生成初稿后,由评审智能体根据质量标准打分修改,反复打磨直到达标。
写论文让老师审阅,不断改进直到通过。
工作流程:
初始请求 → 生成初稿 → 评审智能体检查 → 质量评分 → 通过? → 接受输出 / 未通过 → 生成结构化反馈 → 返还给原始智能体 → 循环调整- 需制定明确的评估标准和质量评分表
- 预设单元测试处理边缘情况
- 设置最大循环次数(如循环3次)避免无限循环
适用场景:
- 严格质量控制流程
- 复杂推理任务
- 创造性任务
- 内容生成(亚马逊FBA店铺数千产品描述需要避免机械化)
- 法律文书、学术写作、产品描述
优点:专注于质量输出
缺点:
- 成本问题显著
- API限流风险(1万产品同时运行请求可能导致超时)
- 需要大量前期规划
6. 评估与监控(Evaluation & Monitoring)
部署前设置质量门和黄金测试,运行时持续监控准确性、性能、成本和模型漂移(drift)。
工厂质量控制系统,每个阶段检查产品。
工作流程:
部署前:定义质量门 → 设置标准(准确率、SLA合规性、用户体验) → 创建测试套件(单元测试、契约测试、集成测试、关键路径测试)
部署后:监控准确性、性能、成本、漂移 → 检测异常 → 识别趋势 → 触发阈值 → 警报/调查 → 人机协同处理 → 定期审计- 模型漂移:同一模型输出相同响应,但随时间推移响应逐渐变差或更不可预测
- 回归:均值不再是均值,出现两个标准差外的异常预期结果
场景:
- 企业级SaaS系统
- 医疗领域
- 金融行业
- 大规模电商
优点:极高的系统可靠性
缺点:
- 告警疲劳风险
- 需要足够稳健的系统处理大规模审查
- 性能影响
7. 护栏和安全(Guardrails & Safety)
检查所有输入内容是否存在有害信息、个人隐私或注入攻击,是整个基础设施的顶层防护。
机场安检,多重检查点要求护照和登机牌。
工作流程:
输入接收 → 内容清洗 → 检测PII(个人可识别信息) → 检测注入攻击 → 风险分类(低/中/高) → 处理策略处理策略:
- PII处理:删除、哈希处理或用星号替换(如社保号)
- 注入检测:过滤或完全阻止(如SQL注入攻击)
- 高风险(90%)→ 引入人类在环流程
- 低到中风险 → 正常处理或附加约束
输出审查:
- 检查政策、道德准则、合规性、品牌安全
- 生成安全评分
- 超过阈值 → 限制工具使用或放入沙箱
最佳实践:
- 面向客户的系统使用预提示策略(预设响应,用户只能点击选择而非开放文本框)
- 越早发现上游问题,系统其余部分越安全
适用场景:
- 面向公众的大系统
- 政府相关系统
- PR风险敏感场景
优点:大幅降低风险、增强合规性和品牌保护
缺点:可能产生误报、增加用户摩擦
四、协同管理型模式
8. 多智能体协作(Multi-Agent Collaboration)
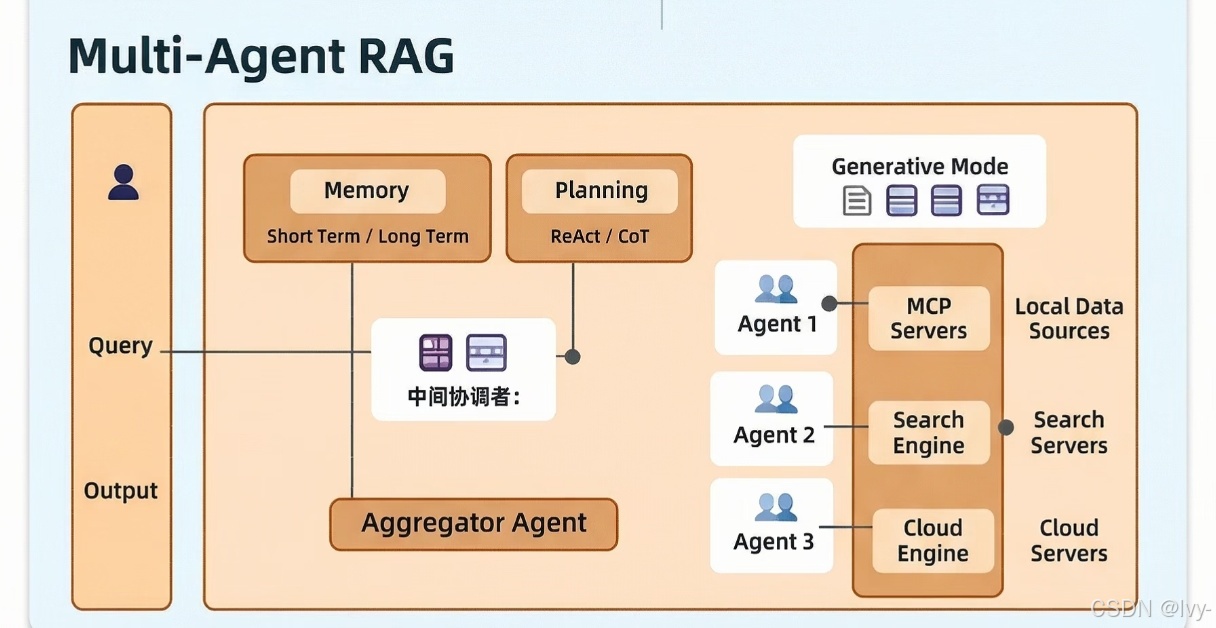
多个专业智能体在中央协调者管理下合作完成复杂任务,共享共同记忆。
类比:电影团队,导演协调摄影、声音、灯光专家各司其职,共享剧本和时间线。
工作流程:
复杂任务 → 定义专业规则 → 协调者决定使用哪些智能体 → 分配任务(工单系统) → 各智能体执行 → 契约验证(检查验收标准) → 整体验收测试 → 通过继续 / 失败回溯- 共享记忆存储(需结构良好防止记忆重叠)
- 依赖
关系图管理 - 契约机制(每个工单有标准、验收标准,满足才进入下一阶段)
- 最大重试次数避免无限循环
适用场景:
- AI产品开发(迭代优化)
- 涉及多阶段的通用产品开发
- 软件开发、产品开发、财务分析、内容创作、研究项目
优点:同时具备专业化能力和并行处理能力
缺点:
- 持续设置和测试需求
- 语言模型随时间演进和漂移的维护成本
9. 人类在环(Human in the Loop)
在低至高风险场景中引入人类参与,特别是在边缘情况下需要审核或介入。
智能体处理 → 决策点(需审核/需用户输入凭证) → 创建审核队列 → 优先级排序 → 人类介入接管 → 完成后交还控制权用户端体验:
- 显示完整上下文
- 展示差异
- 设置计时器
- 人类可选择拒绝、接管或批准
适用场景:
- 高风险决策需要监管合规
- 不能依赖LLM幻觉的场景
- 内容审核、医疗诊断
- 登录凭证输入等需要用户验证的环节
优点:
- 系统更具可信度
- 确切知道故障点位置和人类下一步操作
缺点:
- 增加系统延迟(人类介入可能需要等待)
- 缓冲时间增加
五、知识与信息处理模式
10. RAG(检索增强生成)- 知识检索
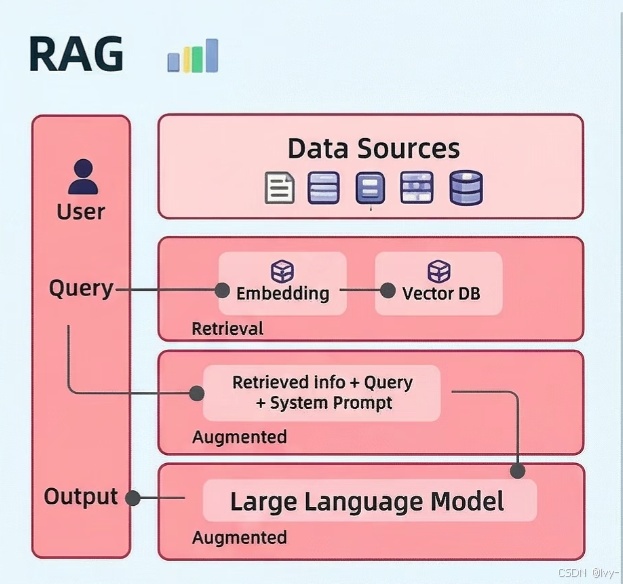
通过解析、分块和创建可搜索的嵌入来索引文档,需要时检索相关内容辅助生成。
拥有图书管理员分类和索引信息
工作流程:
用户查询 + 已摄入文档源 → 解析文档 → 分块(固定大小/语义边界/上下文感知) → 生成嵌入向量 → 存储向量数据库
查询时:获取查询 → 必要时重写查询优化匹配 → 检索Top-K最相关匹配 → 重排序(评分优化) → 测试验证 → 交付回答 → 评分指标(精确率/召回率)- Top-K:可设置为5或10个匹配项
- 注意:添加匹配项越多,LLM可选和虚构的内容越多
适用场景:
- 企业搜索
- 客户支持
- 研究协助
- 任何需要拆分和使用的文档场景
优点:提升系统准确性和可扩展性
缺点:
- 需要搭建和维护基础设施
- 持续维护随时间积累的向量数据
11. 记忆管理(Memory Management)
将信息分类为短期对话记忆和长期知识,根据实效性、相关性妥善存储和检索。
大脑短暂记录信息 vs 永久知识
用户交互 → 捕获信息 → 判断记忆类型(长期/短期/事件性/会话级) → 上下文窗口满? → 压缩当前记忆 / 继续 → 索引存储(添加元数据:实效性评分、创建频率、主题标签) → 检索时:查询记忆库 → 按角色/时间/主题过滤 → 挑选使用 → 处理隐私问题 → 更新记忆继续交互- 记忆管理因具体目标而异
- 没有完美方案,需根据构建内容决定需要记住什么
适用场景:
- 对话连续性(如Claude与ChatGPT的上下文保持)
- 个性化体验(客服、个人助理)
- 教育辅助/学习平台(识别用户对概念A的困难,详细解释依赖概念A的概念B)
优点:长期保持上下文
缺点:
- 存储记忆时确保不损害安全
- 不要过度存储
- 需有清理过时记忆的方式
六、推理与决策模式
12. 推理技术(Reasoning Techniques)
根据问题特点选择合适的推理方法,包括链式思维、树状思维、自我一致性、对抗性辩论等
| 方法 | 描述 |
|---|---|
| 链式思维(Chain-of-Thought) | 将问题拆分为步骤,按顺序推理执行,类似提示词链 |
| 树状思维(Tree-of-Thought) | 生成多个思维分支,探索每条路径,评估可行性,进行剪枝(切断无用分支) |
| 自我一致性 | 生成多个解决方案,评估打分 |
| 对抗性辩论 | 支持方智能体vs反对方智能体来回辩论,直到一方获胜 |
工作流程:
面对复杂问题 → 选择推理方法 → 执行所有方法 → 对所有解决方案评分 → 测试验证逻辑 → 根据评判标准选出最佳方案 → 可整合多种方法- 数学推理
- 大规模战略规划
- 法律分析(最有趣的潜在应用之一)
- 医疗诊断(问题复杂且需要创造性拆解)
优点:过程非常全面且稳健
缺点:
- Token消耗大、成本高
- 复杂度高
- 语言模型过度思考问题
- 增加延迟、飙升成本、组合问题
提示:
- 这是谱系中较先进的技术,90%的情况下不需要使用
- 高度实验性,需要充足时间和资源
13. 目标设定和监控(Goal & Monitoring)
定义具体的可衡量的目标(SMART目标),持续监控进度并在偏离时重新调整。
GPS设定目的地,监控进度,偏离路线时重新计算
SMART目标要素:
-
Specific(具体)
-
Measurable(可衡量)
-
Achievable(可实现)
-
Realistic(现实性)
-
Time-bound(时间限制)
定义目标 → 创建SMART目标 → 设置约束条件(时间、资源、预算) → 定义KPI → 质量观察卡确认 → 开始执行 → 持续监控(进度跟踪、检查点、状态事件) → 与目标比较 → 偏离? → 分析原因 → 调整计划/资源/范围 → 通过检查继续执行 → 达成目标
复杂项目,高度自主操作,战略执行,销售pipeline管道,非常复杂的OKR系统,成本管理...
优点:尽量高效利用资源
缺点:
- 系统中可能存在目标冲突
- 约束优化问题
- 需多次运行捕捉边缘情况
- 各种输入变量导致的僵化问题
14. 优先级管理(Prioritization)
根据价值、风险、努力程度和紧急程度对任务评分,构建依赖图确保按正确顺序执行。
急诊室分诊系统,先处理最紧急病例,确保所有人都能被看到。
工作流程:
任务列表 → 构建依赖图 → 评分因素(依赖项数量、时间敏感度、所需努力、风险等级、商业价值) → 计算优先级得分(公式:价值×紧急程度/努力程度×风险等级) → 排序任务 → 应用调度策略(负载均衡/任务老化/应用配额) → 执行最顶端任务 → 检查优先级变化 → 重新计算 → 继续动态调整 :
原计划:去健身房 → 回家吃饭 → 上班
变化:离开健身房后发现高速事故,晚了一小时
调整:跳过回家吃饭,直接在路上餐厅解决
→ 执行第一个动作引发了新的环境状态,需要重新评估
适用场景:任务管理系统,客户服务,制造业,医疗领域,DevOps
优点:适应性和透明度高
缺点:
- 上下文切换成本高(使用生成式AI时每次需重新评估)
- 缺乏确定性方式判断是否偏离原计划
- 边缘情况和变量多的动态环境最难处理
七、错误处理与恢复模式
15. 异常处理和恢复(Exception Handling & Recovery)
在智能体工作流中捕获错误,评估分类后采取相应恢复措施。
系统中的try-catch机制。
工作流程:
执行操作 → 安全检查/调用服务/工具 → 评估是否成功 → 失败? → 捕获错误 → 评估分类
├── 永久性错误(无法自行解决)→ 使用备用计划
├── 临时性错误 → 退避重试(指数退避:等待后重试,如API超时)→ 限制重试次数
└── 前端关键响应 → 启动应急响应(保存当前工作、通知团队、判断安全、继续执行)→ 继续直到恢复备用方案选项:使用简化方法,使用保存数据,使用默认答案,引入人类在环协助
适用场景:实际生产系统,质量保障,成本管理,需要考虑关键错误的场景
优点:
- 更清晰的性能可见性
- 精确知道哪些环节出错、为何出错
- 自然提升用户信任度
缺点:
- 需要大量基础设施和复杂度
- 可能触发大量误报
- 需避免告警疲劳(类似狼来了的故事)
16. 学习与适应(Learning & Adaptation)
收集用户修正、评分和反馈,清理验证后用于更新提示、策略或模型。
根据顾客反馈调整食谱。
工作流程:
系统操作 → 收集反馈(用户修正、质量评分、自动化评估、任务结果) → 质量检查 → 清理数据(去除噪音/恶意内容) → 决定学习方式
├── 更新提示词
├── 更新策略/示例
├── 更新工具
└── 微调模型(最后选项,很少需要)
→ A/B测试 → 监控性能表现- 可能学到错误的东西(如恶意虚假反馈)
- 需要防范措施确保学到正确内容
适用场景:
- 需要反馈循环和刺激输入的系统
- 提供个性化服务的地方
- 客户和虚拟形象交互场景
优点:持续改进能力
缺点:
- 训练成本
- 组合成本问题(添加更多检查和反馈循环)
- 可能学到错误内容
八、智能体通信与协作模式
17. 智能体间通信(Agent Inter-Agent Communication)
通过结构化消息系统和定义好的协议让智能体相互通信
办公室邮件系统,带有安全权限和防群发过滤器
| 类型 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 集中式 | 单一总管管理所有智能体 | 单一故障点,所有内容报告 | 依赖性强 |
| 分布式 | 所有智能体平等 | 民主化 | 幻觉和误发风险高 |
消息机制:
消息包含:追踪ID、过期时间、安全检查
消息规则:编号、过期设置、重要消息标记挑战:
- 可能陷入无限循环(需终止机制)
- 智能体卡住处理(不断返回某点)
- 消息冗长导致上下文过载
- 需要标记重要消息避免混乱
关键安全机制:
- 验证智能体身份
- 检查智能体能/不能做什么
- 根据权限允许/禁止通信
现实评估:
- 从未见过任何公司完全实现此模式
- 不适合作为实际生产系统
- 用这段时间做更确定性、更可靠的事情更实用
适用场景:
- 企业级部署(需要大量资源、工程师和规范的生产流程)
- 智慧城市系统(典型场景)
优点:故障隔离,可追溯所有问题根源
缺点:
- 复杂度极高
- 调试工作量大
- 需要查看所有智能体在特定时间点的状态
- 确保对话上下文不被过载
九、高级模式
18. 规划(Planning)
设定大目标后创建分步骤计划,设置检查点监控进度,必要时调整路线。
类比:规划公路旅行,设置检查点,监控路况,必要时调整路线。
工作流程:
目标输入 → 分解为里程碑 → 创建依赖关系图 → 检查约束条件(数据可用性、授权、预算、截止日期) → 生成分步骤计划 → 分配智能体和工具 → 按步骤执行 → 跟踪进度 → 验收测试 → 通过结束 / 失败 → 分析原因 → 评估是否有新信息 → 边缘情况需人工介入 / 升级问题处理异常关键特点:
- 不一定把前一步的输出传递给下一步
- 按顺序执行直到第N步(可能是6步、10步)
- 需要备用机制应对失败
实际应用建议(作者使用Cursor/Claude的方式):
- 不会让AI直接花40-50分钟写代码
- 反复规划直到准备好执行
- 知道接下来会发生什么,然后让系统运行
适用场景:
- 目标导向工作流程
- 雄心勃勃需要分解子步骤的项目
- 项目管理
- 软件开发
- 研究项目
优点:
- 非常战略性的执行方式
- 工作流程更灵活,能适应新变量和新环境
缺点:
- 设置和复杂性高
- 协调所有智能体的挑战(确保正确的工具、正确的系统提示、适当的后备机制)
19. 工具使用(Tool Use)
当AI需要外部信息或操作时,发现可用工具,检查权限,调用合适工具并传递正确参数。
厨师需要食材,先查看厨房有什么,确认可用性,取出并真正用在食谱中。
用户请求 → 分析需求 → 发现可用工具(网络搜索API、数据库查询、计算器、文件系统、其他API) → 选择工具 → 安全检查 → 准备工具调用 → 执行调用
→ 失败? → 添加重试逻辑/循环 → 解析工具输出 → 规范化处理 → 备用方案
→ 成功 → 继续流程常见问题处理:
- 调用失败:添加重试逻辑
- 使用了错误工具:拒绝使用,记录原因,优化工作流结构
- 工具返回成功但实际失败:错误会贯穿整个流程(类似数学题第一步除法算错,后续全错)
适用场景:任何涉及多步骤的场景,研究协助,数据分析,客户服务,内容管理
优点:提升质量,减少错误
缺点:
- 如果工具调用出错,错误会贯穿整个流程
- 选择正确工具的挑战(取决于使用的生成式AI、是否采用推理模型等)
20. 探索与发现(Exploration & Discovery)
从论文、数据和专家来源广泛探索知识领域,识别模式并聚类为主题,找出值得深入研究的方向。
侦探从各处收集线索,发现模式后聚焦最有潜力的线索
工作流程:
研究目标 → 探索来源(领域专家、数据集、学术论文) → 汇总信息 → 绘制知识空间 → 识别关键兴趣领域 → 主题聚类(收敛数据点进行同类比较,发现模式)
→ 评估模式(筛选标准:新颖性评分、潜在影响、知识缺口、可行性) → 确定深入探索方向 → 类似研究智能体深入调查
→ 提取成果(概念模型、专家资源、整理好的数据集、文献目录) → 综合见解 → 提取关键洞察、添加开放性问题、生成假设 → 循环直到结论 → 生成报告 → 记录发现 → 推荐下一步行动适用场景:
- 研究项目
- 详细竞争分析
- 学术研究
- R&D部门
- 药物发现(特别酷的应用)
核心价值:
- 创新赋能:
智能体可决定哪些方向值得探索 - 发现哪些主题和角度值得深入
缺点:
- 时间敏感性强
- 资源消耗极大
- 需要筛选海量文档,快速判断相关/不相关
tips
-
复杂度权衡:很多模式看似强大,实则复杂度高、成本大,不要为了炫技而堆架构
-
常见陷阱:
- 多智能体通信容易陷入无限循环
- 过度反思会拖慢速度
- 上下文爆炸导致成本飙升
- 链式过长产生幻觉
-
最佳实践:
- 根据具体工作流程选择合适模式
- 从简单开始逐步复杂化
- 设置最大重试次数避免无限循环
- 预留人工介入机制处理边缘情况
-
实际落地建议:
- 90%的情况下不需要使用高级推理技术
- 3-5步的链式结构已足够验证
- 企业级部署才需要完整的监控和容错系统