核心思想 :分布式不是"高大上"的代名词,而是迫不得已的无奈之举 ------当一台机器扛不住时,只能引入多台机器协作。业务永远比技术更重要,技术只是给业务提供支持。
一、先搞懂几个基本概念
| 概念 | 一句话解释 | 生活类比 |
|---|---|---|
| 应用/系统 | 为完成服务的一整套程序 | 一个团队完成一项任务 |
| 模块/组件 | 系统中职责清晰、内聚性强的部分 | 军队中的突击组、爆破组、掩护组 |
| 分布式 | 多个模块部署在不同服务器,通过网络配合 | 团队分散到多个城市远程协作办公 |
| 集群 | 多台服务器为同一个目标服务 | 大批炮兵集中形成炮兵打击集群 |
| 主(Master)/从(Slave) | 主承担核心写职责,从同步主的数据 | 班主任 vs 普通任课老师 |
| 中间件 | 不同应用之间的通信桥梁 | 饭店的采购部(连接厨房和菜市场) |
关键指标:
-
可用性:系统正常服务时长/总时长(如4个9 = 99.99%)
-
响应时长(RT):用户输入到系统响应的时间(越小越好)
-
吞吐量:单位时间成功处理的请求数
-
并发量:同一时刻支持的最高请求量
二、架构演进七步走(以一个电商网站为例)
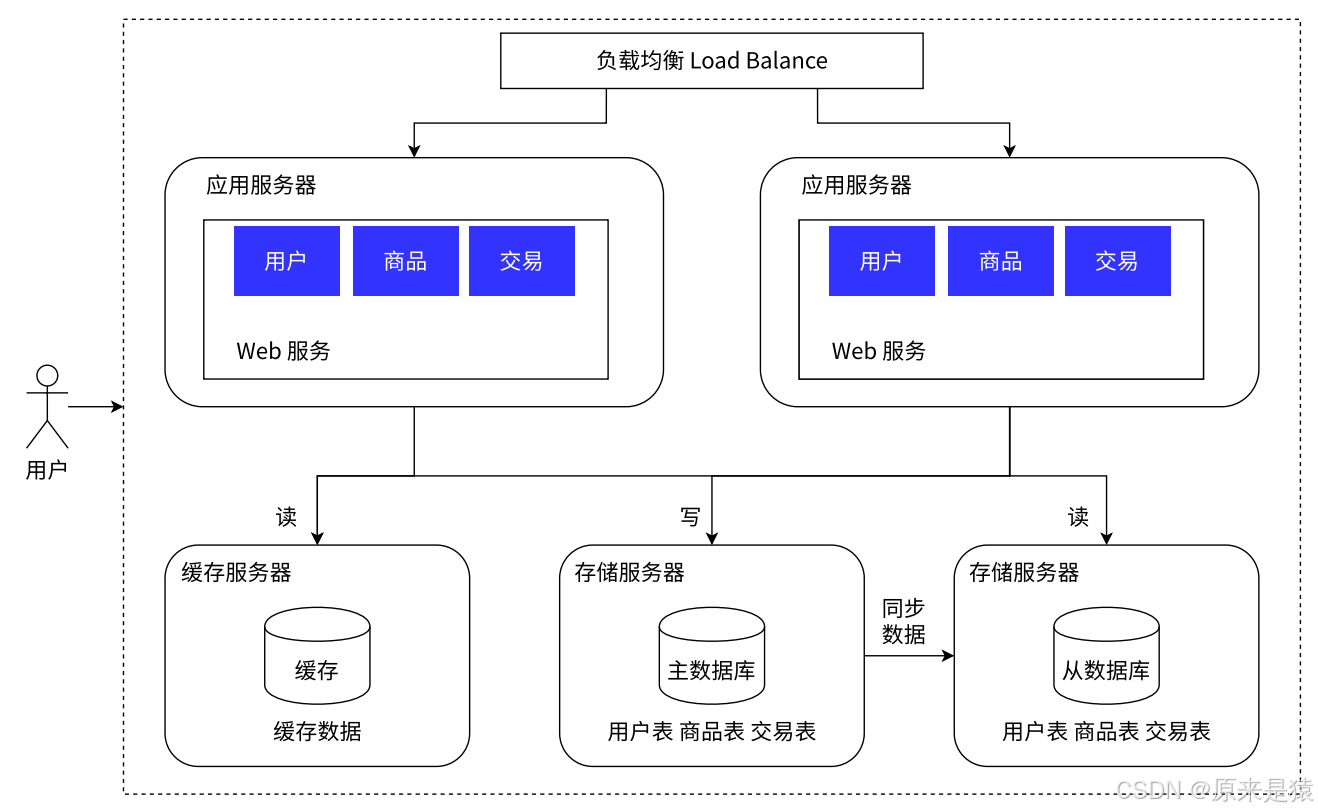
阶段1:单机架构
这台服务器上既运行着Web程序(处理用户请求),又安装了MySQL(存储数据)。
为什么可以这样?
-
用户量很少,一天可能就几十个人访问
-
开发速度快,团队小,改个东西很方便
-
成本低,租一台云服务器就够了
千万别瞧不起单机架构------绝大多数创业公司的产品,甚至很多成熟的小型系统,至今仍然跑在这种架构上。够用就好,没必要过度设计。
瓶颈在哪?
当用户量慢慢增长(比如从100人涨到1万人),问题就来了:
-
CPU不够用了:每次请求都要计算,请求多了CPU就100%
-
内存不够用了:每个请求都要占用内存,内存满了开始卡顿
-
磁盘不够用了:数据越来越多,读写变慢
-
带宽不够用了:网络传输成为瓶颈
任何一个硬件资源被撑爆,系统就会变慢甚至崩溃。
怎么办?两个选择
| 方案 | 做法 | 优点 | 缺点 |
|---|---|---|---|
| 垂直扩展 | 买更好的服务器(更强的CPU、更大的内存) | 不用改代码 | 贵!性能翻倍可能花4倍的钱,而且有上限 |
| 水平扩展 | 增加多台普通服务器,分担工作 | 成本低,扩展空间大 | 需要改架构,技术变复杂 |
阶段2:应用与数据分离
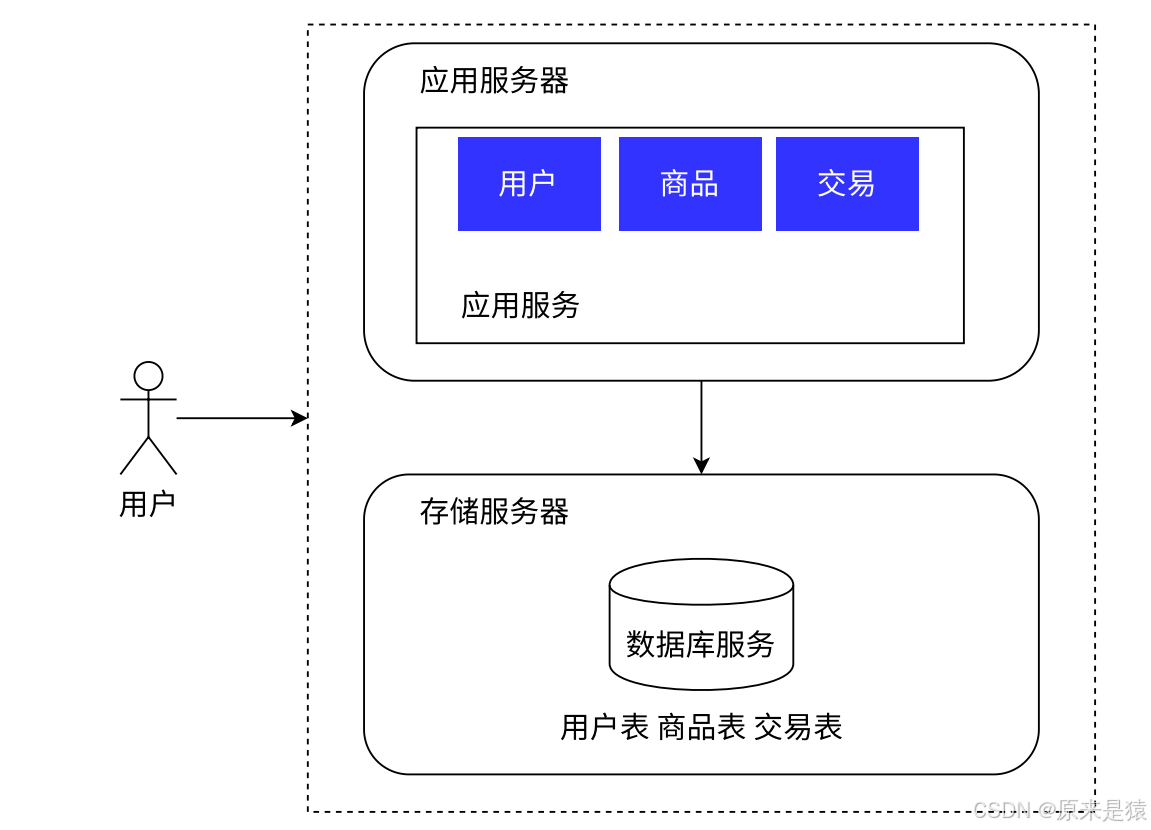
把应用服务器和数据库服务器拆开到两台不同的机器上:
为什么这样做?
-
应用服务器需要强劲的CPU和内存(跑业务逻辑)
-
数据库服务器需要大容量的高速磁盘(存数据、做查询)
分开之后,可以针对各自的需求配置硬件:应用服务器配高配CPU,数据库服务器配SSD固态硬盘。
效果如何?
成本没增加太多,但承载能力提升了一大截。不过这只是一个过渡方案,真正的挑战还在后面。
阶段3:应用服务集群 + 负载均衡
问题:
用户越来越多,单台应用服务器又扛不住了。
这就像一家饭店生意火爆,一个厨师炒菜炒到手抽筋也跟不上点单的速度。
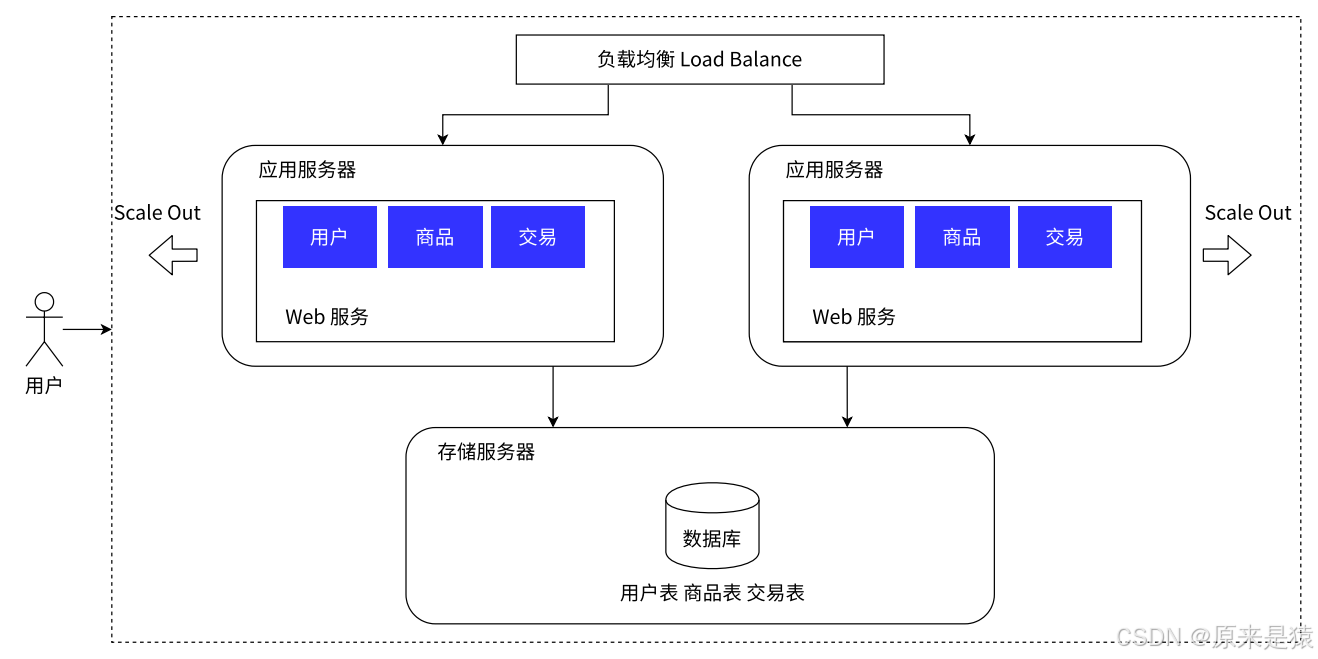
常见的分配算法
-
轮询:1号、2号、3号、1号、2号......公平分配
-
加权轮询:性能好的服务器多分一些任务
-
一致性哈希:同一个用户的请求始终分配给同一台服务器(比如VIP客户有专属客服)
相关软件
-
软件方案:Nginx、HAProxy、LVS
-
硬件方案:F5(很贵,但很强)
新问题
应用服务器的问题解决了,但所有的请求最终都要去数据库读写数据------数据库成了新的瓶颈。
负载均衡器就像公司领导 :负责接收所有请求,然后分发给下属(应用服务器)执行。它本身抗压能力远超应用服务器,但如果请求量连LB都扛不住了,就引入多个LB(多机房部署)。
💡 集群的好处:某台主机挂了,其他主机仍能服务,提高了可用性。
阶段4:读写分离 / 主从分离(数据库扛不住了)
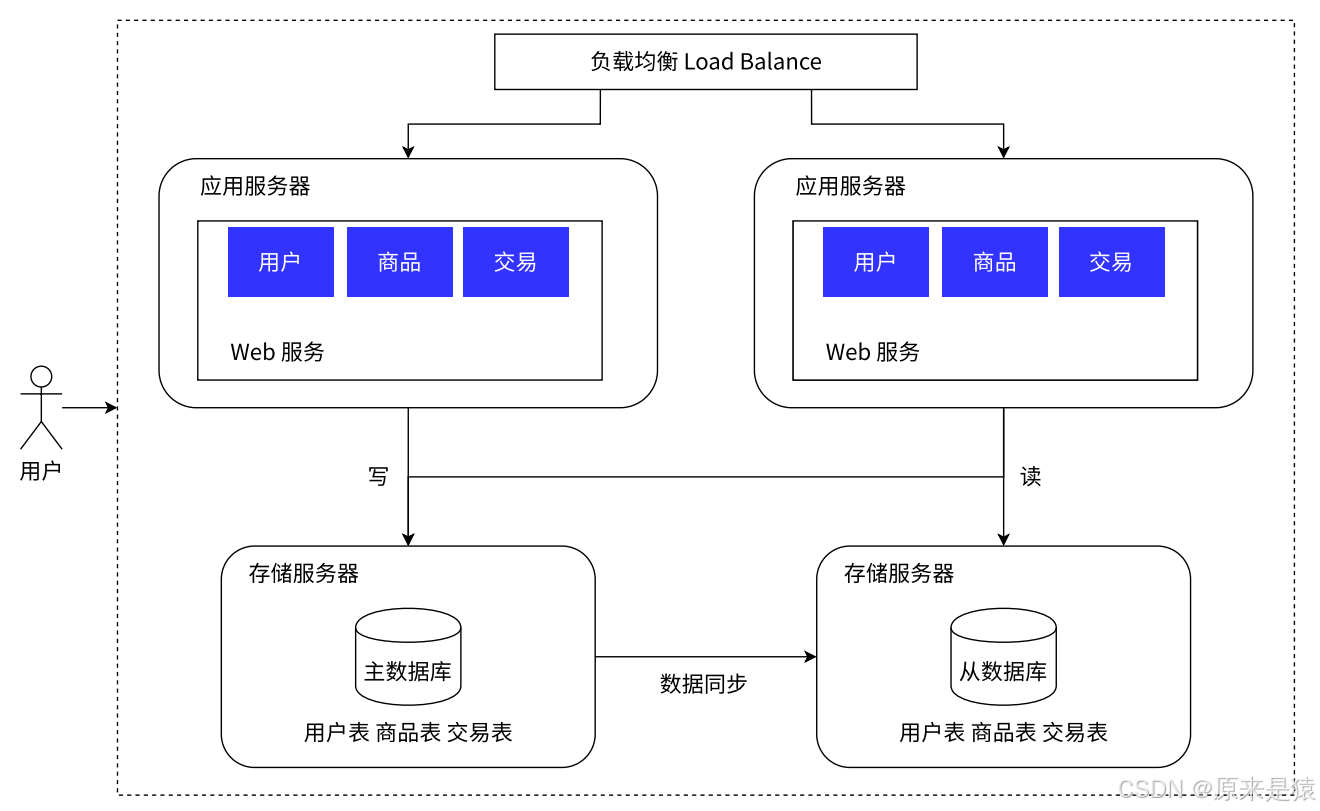
痛点 :应用服务器可以无限扩展,但数据库不行------数据分散后一致性无法保障(想象一下转账后一个库改了金额,另一个没改)!
解决方案:
-
一主多从:主库负责写,从库同步主库数据后负责读
-
实际场景中 读频率远高于写(100次读 vs 1次写),所以分散读压力效果显著
-
代价:主从同步需要时间,存在短暂的数据不一致窗口
相关软件:MyCat、TDDL、Amoeba、Cobar(数据库中间件自动分离读写请求)
阶段5:引入缓存 ------ 冷热分离架构
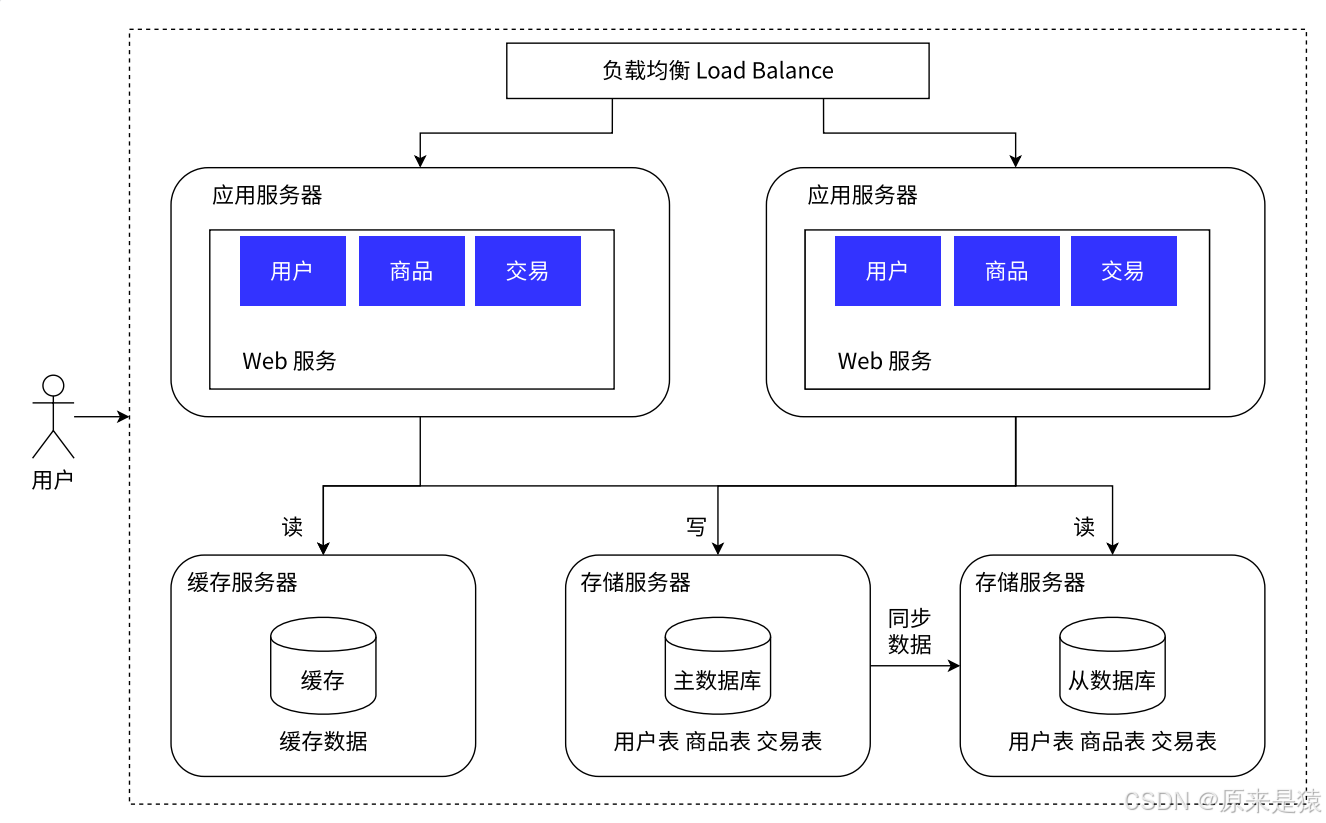
为什么快?
缓存(如Redis)是内存存储,访问速度是微秒级
数据库是磁盘存储,访问速度是毫秒级
差了几十倍甚至上百倍
为什么需要缓存?
数据库天然响应慢!把热点数据(20%的数据满足80%的访问)放到缓存里,访问速度提升数量级。
Redis的定位 :
Redis 是在分布式系统 中才能发挥威力的!**单机程序直接用变量存数据更快,**但进程间是隔离的,无法共享。Redis基于网络,可以把内存中的变量给其他进程、甚至其他主机使用。
缓存带来的问题 :
-
缓存一致性:数据库改了,缓存怎么同步更新?
-
缓存穿透/击穿/雪崩:大量请求直接打到数据库
-
热点数据集中失效:缓存同时过期,请求洪峰涌向数据库
⚠️ 引入缓存后系统复杂度大大提升,且涉及Redis和MySQL之间的数据同步问题。
阶段6:垂直分库(数据库也做业务拆分)
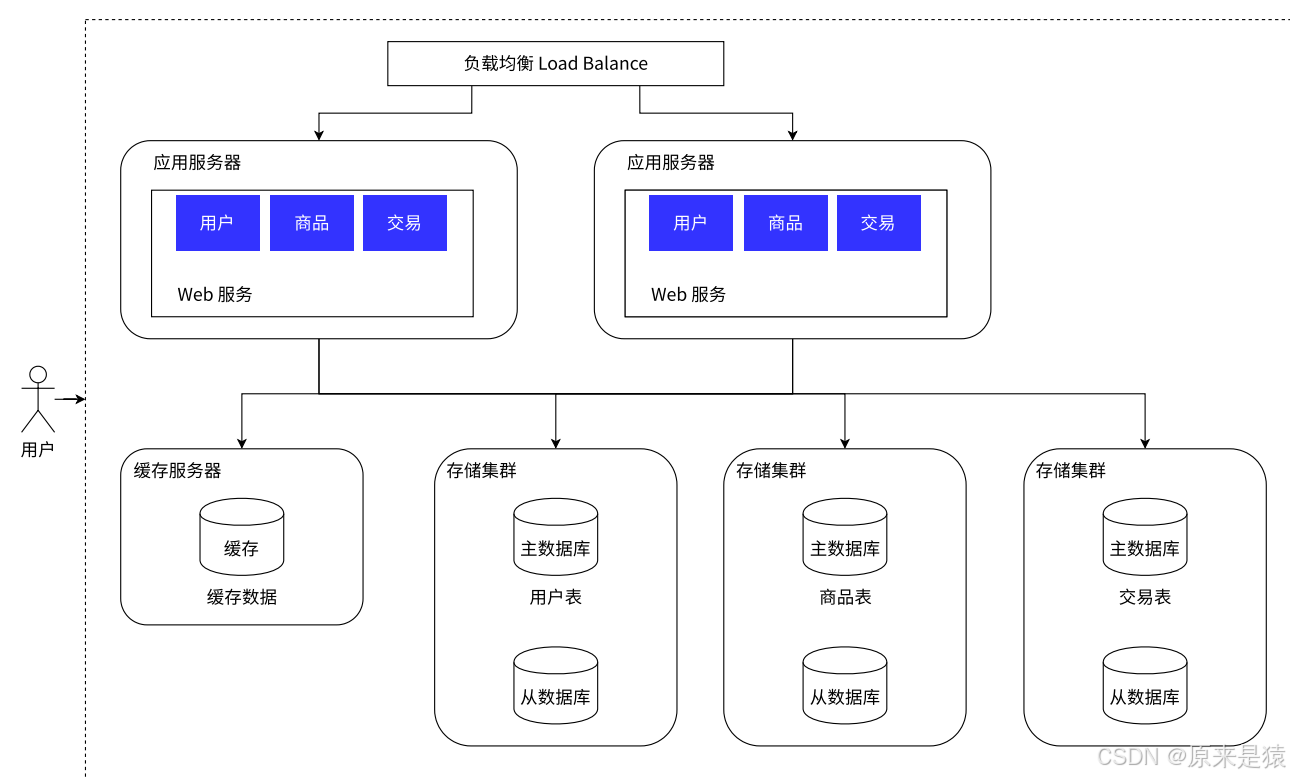
按业务拆分数据库 :用户数据、商品数据、交易数据分别存到不同的数据库集群
如果单表太大 :还可以继续分库分表(如按商品ID哈希、按小时建表)
💡 业务决定技术! 具体怎么分,必须结合实际业务场景。
阶段7:业务拆分 ------ 微服务架构
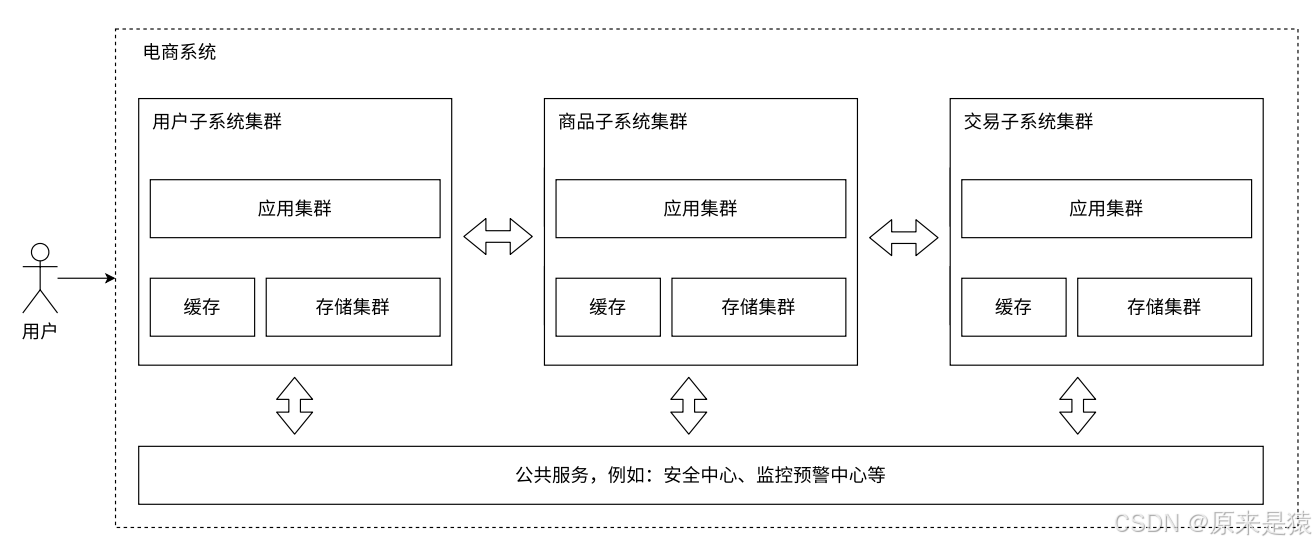
为什么拆微服务?
本质上是在解决**"人"的问题** !当应用服务器代码越来越复杂,需要更多人维护。人多了就要分组管理,按功能拆成微服务 = 按业务划分组织结构。
微服务的代价 :
-
性能下降:服务间通过网络通信(虽然万兆网卡已经比硬盘快了,但还是要花钱)
-
复杂度提高 :服务器更多,出问题的概率更大,需要更完善的监控和运维
-
可用性挑战:需要一系列手段保证系统整体可用
微服务的优势 :
-
解决了人的问题(团队分工明确)
-
功能复用更方便
-
不同服务可以独立部署、独立扩展
三、Redis 深度认识
3.1 Redis 到底是什么?
"The open source, in-memory data store used by millions of developers as a database , cache , streaming engine , and message broker."
| 角色 | 说明 |
|---|---|
| 数据库 | 内存存储,速度极快(但存储空间有限) |
| 缓存 | 最常用的场景,拦截热点读请求 |
| 消息中间件 | 初心就是做消息队列(生产者-消费者模型),但现在很少直接用,因为有更专业的MQ |
| 流引擎 | 处理实时数据流 |
3.2 Redis vs MySQL
| 对比项 | Redis | MySQL |
|---|---|---|
| 存储位置 | 内存 | 磁盘 |
| 速度 | 极快(纳秒级) | 较慢(毫秒级) |
| 容量 | 有限(受内存限制) | 很大(TB级) |
| 持久化 | 可配置,但本质内存型 | 天然持久化 |
| 适用场景 | 热点数据、缓存、临时数据 | 全量数据、事务性数据 |
又大又快的方案 :Redis + MySQL 结合使用 ------ MySQL存全量数据,Redis缓存热点数据。
⚠️ 单机程序中,直接用变量比Redis快!Redis的价值在于分布式环境下的跨进程/跨主机数据共享。

所谓的分布式系统,就是想办法引入更多的硬件资源!
但请记住:业务是更重要的,技术只是给业务提供支持的。 不要为了分布式而分布式。