1 事务为何重要?
1.1 从银行转账看事务的ACID
想象一个简单的银行转账场景:小明从自己账户向小红账户转账100元,数据库需要两个操作:
sql
-- 操作1:从小明账户扣除100元
UPDATE accounts SET balance = balance - 100 WHERE user_id = '小明';
-- 操作2:向小红账户增加100元
UPDATE accounts SET balance = balance + 100 WHERE user_id = '小红';如果这两个操作不能保证原子性,会发生什么?加入操作1成功操作2失败,那么小明将无缘无故失去100元。这就是事务要解决的核心问题
事务必须满足ACID特性:
- A:原子性。转账两个操作要么全部成功,要么全部失败,不能只执行一半。
- C:一致性。转账前后,系统总金额保持不变(小明+小红的余额总和不变)。
- I:隔离性。转账过程中,其他用户查询这两个账户时,不应该看到"小明已扣款但小红未到账"的中间状态。
- D:持久性。一旦转账成功,即使数据库服务器立即断电,重启后转账结果也必须保持。
事务是关系型数据库的基石,它保证了即使在复杂并发和异常情况下,数据依然可靠、准确。
1.2 单机时代:MySQL的辉煌与局限
MySQL自1995年诞生以来,凭借其开源、易用、高性能的特点,成为互联网时代最流行的关系型数据库之一。其InnoDB存储引擎提供了完整的事务支持,满足了绝大多数应用的需求。
在单机架构下,MySQL通过精巧的设计实现了高效的事务:
- 通过缓冲池减少磁盘IO
- 通过行级锁实现高并发
- 通过Redolog/Undolog日志保证数据安全
- 通过MVCC机制提供非阻塞读
然而随着互联网的高速发展,单机MySQL逐渐也面临挑战:
- 容量瓶颈:单机存储有限,无法存储海量数据
- 性能瓶颈:单CPU/内存/磁盘IO存在上限
- 可用性低:单点故障导致服务完全中断
- 扩展困难:垂直扩展成本高且有限
面对这些问题,业界最初采用分库分表的方案,但这又带来了新的复杂性:跨库事务难以保证、跨表查询复杂、数据迁移困难等。
1.3 云原生时代:分布式数据库崛起
随着云计算和微服务架构的普及,催生了新一代的分布式数据库。这类数据库从设计之初就面向分布式环境,具有水平扩展、高可用、强一致性的特点。TiDB是云原生分布式数据库的代表之一,它采用计算与存储分离的架构(详细可以看这篇博客):纸上得来终觉浅?从 0 到 1 实现分布式 KV 后,我才读懂了 TiDB 的设计-CSDN博客
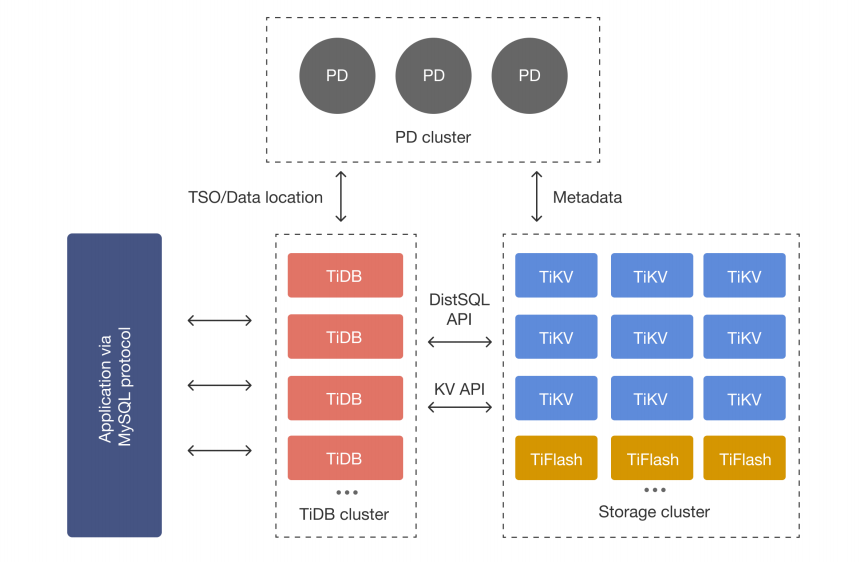
TiDB的核心理念就是"让分布式数据库用起来像单机数据库一样简单",它兼容MySQL协议,使得迁移成本大大降低。但是更重要的是,它解决了分布式核心下的难题:如何保证数据一致性、如何实现跨节点事务、如何自动扩容缩容等。
1.4 本文导读:我们探究什么?
本文将深入探讨事务在单机与分布式环境下的实现:
- 深入理解InnoDB,理解单机事务如何通过精巧设计实现ACID
- 剖析TiDB的Percolator模型,掌握分布式事务如何协调多个节点
- 对比两种实现,理解各自的使用场景和取舍
- 探究技术演进,从单机到分布式的设计哲学变换
无论你是数据库开发者、系统架构师,还是对数据库原理感兴趣的工程师,相信这篇文章都能帮助你建立完整的事务知识体系。
接下来,让我们从最熟悉的MySQL开始,看看单机事务是如何实现的。
2 单机事务的经典实现------以Mysql InnoDB为例
2.1 核心架构
在单机数据库中,所有组件都在同一台服务器的掌控之下,这种"**集中式"**架构带来了极大的简化。让我们看看MySQL InnoDB的核心组件如何协同工作:
- 缓冲池:缓存磁盘的数据页,避免每次读取都访问磁盘。当事务修改数据时,实际上修改的是缓冲池中的页,Innodb会通过检查点机制定期将脏页刷回磁盘
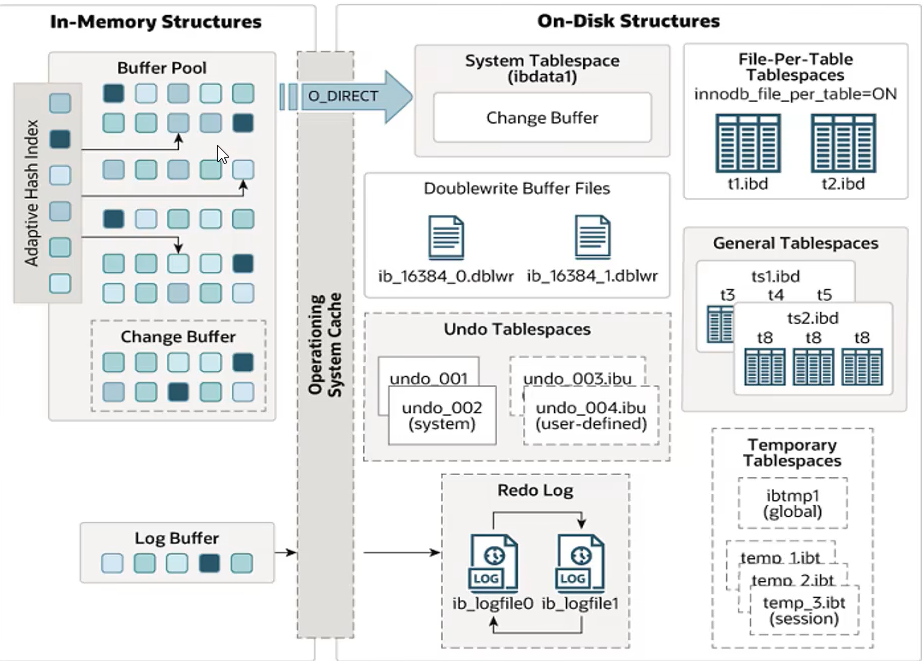
- 锁机制:管理所有的行级锁。在内存中,Innodb为每个被锁定的行维护一个锁结构,包含事务ID、锁类型等信息。当多个事务竞争同一行时,锁系统负责协调

- 日志系统:是崩溃恢复的保障。Redo Log记录了对数据的物理修改,用于重做;Undo Log记录了修改前的数据镜像,用于回滚和MVCC。
这种集中式架构的优势显而易见,所有组件共享内存,通讯成本低;锁管理和事务协调都在本地完成,没有网络开销。但是这也注定了它扩展边界------单机硬件性能上限。
2.2 MVCC:多版本并发控制魔法
2.2.1 版本号从何而来?------事务ID的生成
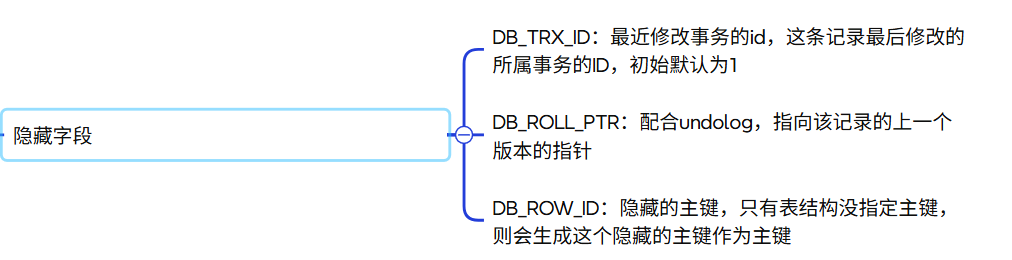
在InnoDB中,每个事务都有一个唯一的事务ID(TRX_ID),这是一个自增的64位整数。当事务首次执行写操作时,InnoDB会为它分配一个TRX_ID(隐藏字段)。
cpp
// 简化的TRX_ID分配
uint64_t assign_trx_id() {
static std::atomic<uint64_t> next_trx_id(1);
return next_trx_id.fetch_add(1, std::memory_order_relaxed);
}
这个事务ID有两个重要作用:标识事务的开始顺序,以及作为数据版本的标签。
2.2.2 Undo Log:构建数据的时光机

Undo Log是MVCC的基石。当一行数据被修改时,InnoDB会保存修改前的值到Undo Log中,形成一个版本链。让我们看一个具体例子:
假设有一行用户余额数据,初始值为100元,经过三个事务修改:
sql
-- 事务1 (TRX_ID=100): 余额增加50元
UPDATE accounts SET balance = 150 WHERE user_id = 1;
-- 事务2 (TRX_ID=200): 余额减少30元
UPDATE accounts SET balance = 120 WHERE user_id = 1;
-- 事务3 (TRX_ID=300): 余额增加80元
UPDATE accounts SET balance = 200 WHERE user_id = 1;那么对应生成的Undolog版本链如下所示:
sql
当前版本: 200 (TRX_ID=300)
↑
Undo指针指向: 120 (TRX_ID=200)
↑
Undo指针指向: 150 (TRX_ID=100)
↑
Undo指针指向: 100 (初始值)2.2.3 ReadView:定义"我能看到什么"
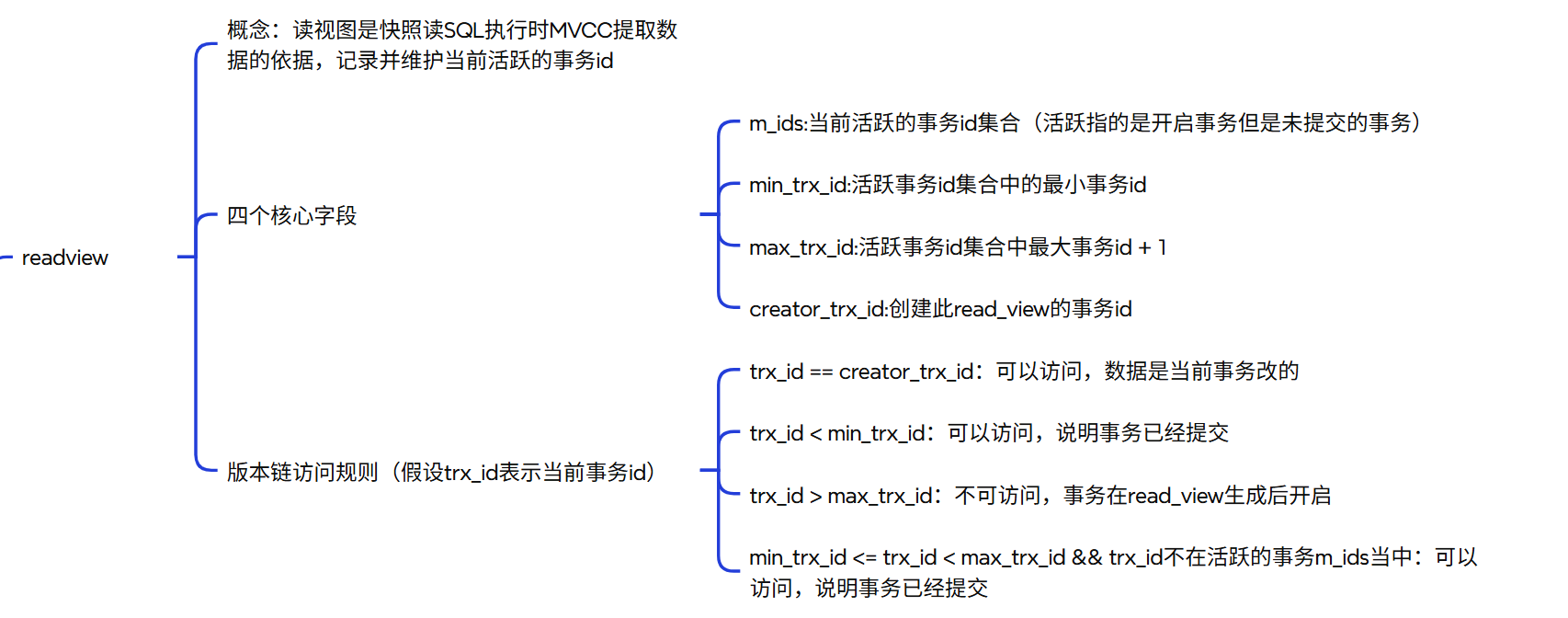
- 当前读:读到的是最新的数据记录,读取时还要保证其他并发事务不能修改当前记录,会对读取记录加锁。如:select ... lock in share mode(共享锁),select ... for update、update、delete(排他锁)
- 快照读:简单的select(不加锁)就是快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读
cpp
struct ReadView {
// 活跃事务列表:当前未提交的事务ID集合
std::set<trx_id_t> active_trx_ids;
// 最小活跃事务ID
trx_id_t min_trx_id;
// 下一个将要分配的事务ID
trx_id_t next_trx_id;
};可见性判断很简单:
- 如果版本TRX_ID < min_trx_id,说明在事务开始前已经提交,可见
- 如果版本TRX_ID > (next_trx_id)max_trx_id,说明在事务开始后才开始,不可见
- 如果TRX_ID在活跃事务列表中,说明还未提交,不可见
- 否则,可见
2.3 锁机制:并发的守护者
MVCC机制主要解决读冲突问题,但是写冲突还需要锁来解决
2.3.1 行锁、间隙锁、Next-Key Lock
假设有一个用户表:
sql
CREATE TABLE users (
id INT PRIMARY KEY,
age INT,
INDEX idx_age (age)
);
INSERT INTO users VALUES (1, 20), (2, 25), (3, 30), (5, 35), (7, 40);- 记录锁 :锁住具体的行,如
SELECT * FROM users WHERE id = 3 FOR UPDATE - 间隙锁 :锁住一个区间但不包括记录,如
SELECT * FROM users WHERE age = 28 FOR UPDATE会锁住(25, 30)这个区间 - Next-Key Lock :记录锁+间隙锁,如
SELECT * FROM users WHERE age = 30 FOR UPDATE会锁住(25, 30]这个区间
2.3.2 两阶段锁协议(2PL)
Innodb严格遵守两阶段锁协议:
- 增长阶段:事务可以获取锁,但不能释放锁
- 缩减阶段:事务可以释放锁,但不能获取新锁
这意味着,即使一个行锁在事务后期不再被需要,也必须等到事务结束时才释放。这是为了保证可串行化调度
2.3.3 死锁检测与处理
考虑两个事务互相等待的场景:
sql
-- 事务1
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1; -- 获取id=1的锁
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2; -- 等待id=2的锁
-- 事务2
BEGIN;
UPDATE accounts SET balance = balance - 50 WHERE user_id = 2; -- 获取id=2的锁
UPDATE accounts SET balance = balance + 50 WHERE user_id = 1; -- 等待id=1的锁此时发送死锁。InnoDB的死锁检测机制会定期扫描锁等待图,发现环后选择回滚代价较小的事务(通常是修改行数较少的事务)
2.4 崩溃恢复:永不丢失
2.4.1 Redo Log:重做的艺术
Redo Log记录的是物理日志,格式如下:
sql
[LSN: 1001] [PageID: 0x0012] [Offset: 64] [Old: 0x00] [New: 0xFF]这表示"在日志序列号1001,将第0x0012页的第64字节从0x00改为0xFF"。
为什么使用物理日志?
因为物理日志恢复速度快,只需重放即可。而逻辑日志(如"UPDATE accounts SET balance=200")需要重新解析执行,且可能因索引变化而失败
2.4.2 Binlog与两阶段提交
为了保证Redo Log和Binlog的一致性,MySQL使用两阶段提交:
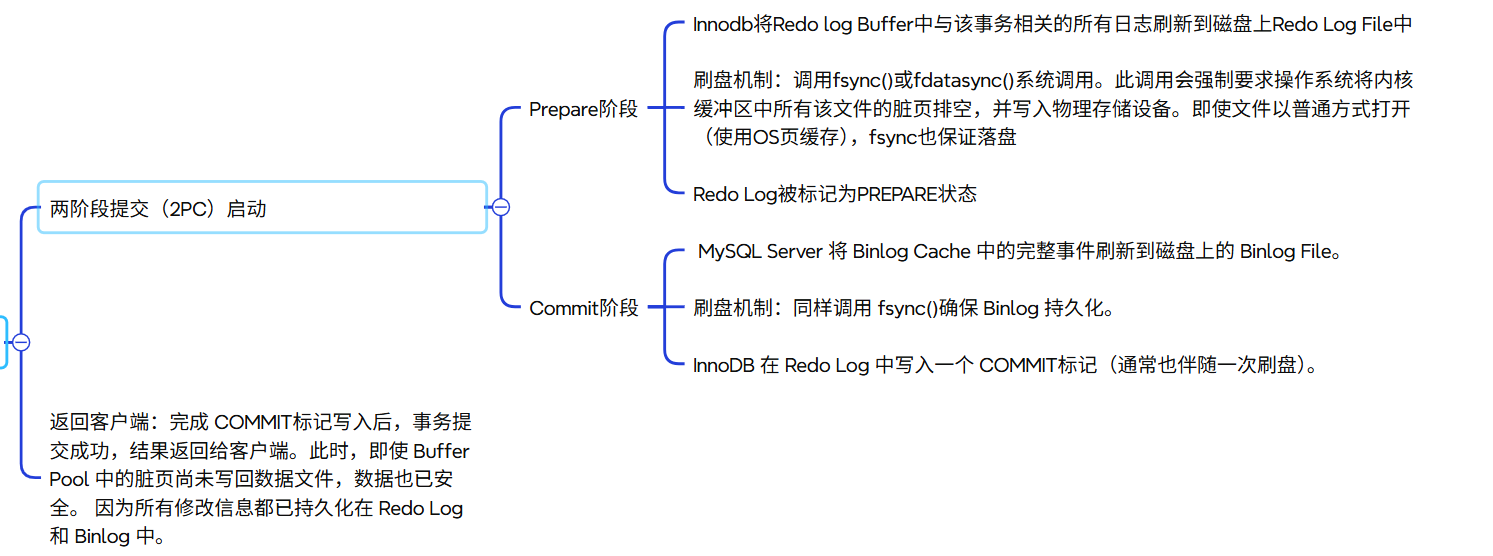
- 准备阶段:Innodb将事务写入RedoLog,标记为PREPARE状态
- 提交阶段:Server将事务写入Binlog,然后Innodb将RedoLog标记为COMMIT
如果崩溃发生在阶段1,事务会回滚;如果发生在阶段2,重启后会检查Binlog,已记录的事务会重做。
2.4.3 崩溃后的自动恢复流程
cpp
void crash_recovery() {
// 阶段1:前滚(Redo)
redo_from_checkpoint();
// 阶段2:回滚(Undo)
rollback_uncommitted_trxs();
// 清理
purge_old_undo_logs();
}2.5 单机事务的局限
尽管InnoDB的设计十分精巧,但单机架构的本质局限无法回避:
| 局限 | 表现 | 影响 |
|---|---|---|
| 扩展性 | 只能垂直扩展(更强CPU/更大内存/更快磁盘) | 成本指数增长,存在物理上限 |
| 可用性 | 主从复制有延迟,故障切换丢数据 | RPO>0,不满足金融级要求 |
| 容灾 | 同城灾备复杂,异地多活几乎不可能 | 灾难恢复能力有限 |
| 架构 | 计算存储耦合,资源无法独立扩展 | 存储或计算单方面瓶颈影响整体 |
这些局限在数据量不大、并发不高的场景下不明显,但随着互联网应用的发展,单机数据库越来越力不从心。这直接推动了分布式数据库的发展。
在下一章,我们将看到TiDB如何通过全新的架构设计,解决这些挑战。
3 迈向分布式 ------ TiDB的架构革新
3.1 TiDB整体架构
当我们从单机数据库走向分布式数据库,最大的变化是从"集中控制"变为"协同工作"。TiDB采用典型的分布式架构,将计算、存储、调度三大功能分离,每个部分都可以独立扩展。
// TiDB的简化架构示意
type TiDBCluster struct {
// 计算层 - 无状态,负责SQL解析、优化、执行
TiDBServers []*TiDBServer // 可水平扩展
// 调度层 - 轻量级,负责元信息管理和时间戳分配
PD *PlacementDriver // 通常3-5个节点实现高可用
// 存储层 - 有状态,负责数据存储和分布式事务
TiKVStores []*TiKVStore // 可水平扩展,数据自动分片
}计算层:TiDB Server
- 无状态设计:每个TiDB节点不存储数据,可以任意增加和减少
- SQL网关:接收MySQL协议连接,解析SQL,生成执行
- 分布式执行器:将查询计划拆分成多个任务,下发到存储层并行执行
- 事务协调者:协调分布式事务的两阶段提交
存储层:TiKV
- 分布式Key-Value存储:数据以Region为单位分片存储
- Raft共识协议:每个Region在3-5个副本间通过Raft保持一致性
- MVCC+Percolator:基于Google Perocolator模型实现分布式事务
- 协处理器:在存储层进行计算,减少网络传输
调度层:PD(Placement Driver)
- 集群大脑:管理元数据,监控节点状态
- 时间戳分配器:提供全局单调递增的时间戳(TSO)
- 负载均衡调度:自动迁移Region,平衡集群负载
- 故障检测与恢复:自动处理节点故障,保证高可用
3.2 数据如何分片:Region与Raft Group
TiDB将数据划分为连续的key区间,每个区间称为一个Region,默认大小约96MB-144MB
整个Key空间:
┌─────────────────────────────────────────────────────────────┐
│ [a, b) │ [b, d) │ [d, g) │ [g, m) │ [m, z) │ ... │
│ Region1 │ Region2 │ Region3 │ Region4 │ Region5 │ │
└─────────────────────────────────────────────────────────────┘
↑ ↑ ↑ ↑ ↑
副本组 副本组 副本组 副本组 副本组
(Raft) (Raft) (Raft) (Raft) (Raft)Region特点:
- 每个Region在物理上是一个Raft Group,有3-5个副本
- Region是数据迁移和负载均衡的最小单位
- 随着数据增加,Region会自动分裂
- 副本可以分布在不同的机架、机房,实现容灾
3.3 分布式事务四大挑战
在单机数据库中,事务的ACID特性可以通过集中控制来实现。但在分布式环境中,数据分散在不同的节点中上,这带来了前所未有的挑战:
挑战1:时钟同步
在单机中,我们可以用单调递增的计数器作为版本号。但是在分布式系统中,各个节点的本地时钟都存在误差,无法保证全局有序。
TiDB解决方案:通过PD提供全局单调递增的时间戳(TSO),所有节点的时间都向"中央时间"对齐
挑战2:原子提交
单机中,原子提交可以通过本地日志(undolog,redolog)实现。但分布式事务设计多个节点,如何确保所有节点要么全部提交,要么全部回滚
**TiDB的解决方案:**采用Percolator模型的两阶段提交协议,通过Primary Key决定事务最终状态
挑战3:故障处理
在单机中,故障恢复相对简单。但在分布式系统中,任何节点都可能在任何时刻故障,且故障检测需要时间。
TiDB的解决方案:
- 通过Raft保证数据多副本一致
- 通过Lease机制检测节点故障
- 通过Primary Key状态决定未完成事务的最终结果
挑战4:性能开销
分布式事务涉及多次网络通信,延迟远高于本地内存访问。
TiDB的解决方案:
- 异步提交:减少客户端等待时间
- 1PC优化:单Region事务跳过2PC
- 批量处理:合并小请求,减少RPC数量
3.4 MySQL集群是否是一种分布式架构
**MySQL原生的集群方案通常不被认为是真正的分布式架构,而是一种高可用或读写分离架构。** 但通过中间件实现的"分库分表"可以构建分布式系统。
3.4.1 MySQL主从复制(Replication)------ 非分布式
这是最常见的MySQL集群方式
- 工作原理:主节点(Master)处理所有写请求,并将数据变更以binlog形式同步给其他从节点
- 为什么不是分布式 :所有节点存储完全相同的数据全集 ,没有数据分片。写能力无法扩展(单点写入),存储容量受单节点限制。它的主要目标是读写分离 和高可用,而非分布式扩展。
3.4.2 MySQL NDB Cluster ------ 是分布式,但有局限
这是MySQL官方提供的真正分布式内存数据库集群
- 工作原理:数据自动分片(Partition)存储在多个数据节点。应用通过SQL节点(mysqld进程)访问,SQL节点是无状态的。管理节点负载配置
- 分布式特性:支持数据节点的ACID事务,写能力可水平扩展
- 局限:传统上基于内存,对磁盘支持不如InnoDB成熟;对复杂SQL(如多表JOIN)的支持和优化不如传统的InnoDB引擎。它更像一个专用的分布式键值存储附加了SQL接口。
3.4.3 MySQL Group Replication / InnoDB Cluster ------ 高可用集群,非分布式
这是MySQL 5.7/8.0后推出的现代高可用方案。
- 工作原理:基于Paxos协议实现多主或单主同步复制。所有节点存储全量数据,通过组通信保证数据强一致。
- 为什么不是分布式 :核心目标是高可用和自动故障切换。虽然写请求可以在多个主节点上发起(多主模式),但本质上它们都在竞争修改同一份完整的数据,容易冲突,且存储容量和写性能仍受单节点限制。
3.4.4 分库分表 + 中间件 ------ 应用层实现的分布式
这是业界应对海量数据的常见方案,在应用层构建了分布式系统。
- 工作原理 :使用MyCAT、ShardingSphere等中间件,将一张大表的数据按规则(如用户ID取模)拆分到后端多个独立的MySQL实例中。
- 分布式特性:具备了数据分片、写扩展、存储扩展的能力。
- 巨大缺点 :对应用不透明 ,跨分片查询(JOIN、排序、聚合)极其复杂且性能低下;跨分片事务难以实现,通常无法保证强一致性,或者性能代价极高。运维复杂度(数据迁移、扩容)也很大。
4 分布式事务的经典方案------TiDB的Percolator模型详解
4.1 Percolator模型设计哲学
Percolator的核心思想可以用一句话来总结:将事务状态编码到数据本身,而非集中存储
在传统的两阶段提交(2PC)中,需要一个中心化的协调者(Coordinator)来记录事务状态。这个协调者成为单点瓶颈和故障点。Percolator通过巧妙的设计,将事务状态分散存储在参与事务的数据行中。
关键洞察:
- 事务状态分散化:不再需要中心化的事务管理器
- Primary Key决定事务的命运:选择其中一个key作为事务状态"代言人"
- 客户端作为协调者:事务的发起者协调整个提交过程
- 时间戳作为全局时钟:保证整个集群的事件有序
4.2 全局时钟:分布式世界的时间法则
在分布式系统中,如何确定事件先后顺序?Percolator的答案是:引入一个全局单调递增的时间戳
TSO (Timestamp Oracle) 的工作原理
cpp
// 简化的TSO服务实现
type TSO struct {
mu sync.Mutex
lastTS int64
leaseTime time.Time
}
// 获取时间戳
func (t *TSO) GetTimestamp() (int64, error) {
t.mu.Lock()
defer t.mu.Unlock()
now := time.Now()
if now.After(t.leaseTime) {
// 续租逻辑
t.leaseTime = now.Add(10 * time.Second)
}
t.lastTS++
return t.lastTS, nil
}TSO特点:
- 全局唯一且单调递增
- 高可用部署
- 批量分配时间戳,减少网络请求
- 物理时钟+逻辑时钟结合,保证性能
4.3 两阶段提交的分布式实现
让我们深入Percolator的两阶段提交流程。我们将通过一个具体的转账例子来说明。
场景设定
假设有两个银行账户:
- 账户A:余额100元,存储在Region1
- 账户B:余额50元,存储在Region2
转账事务:从A向B转账20元,使A余额变为80,B余额变为70。
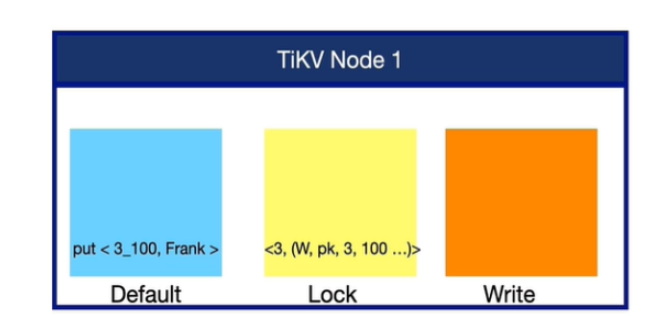
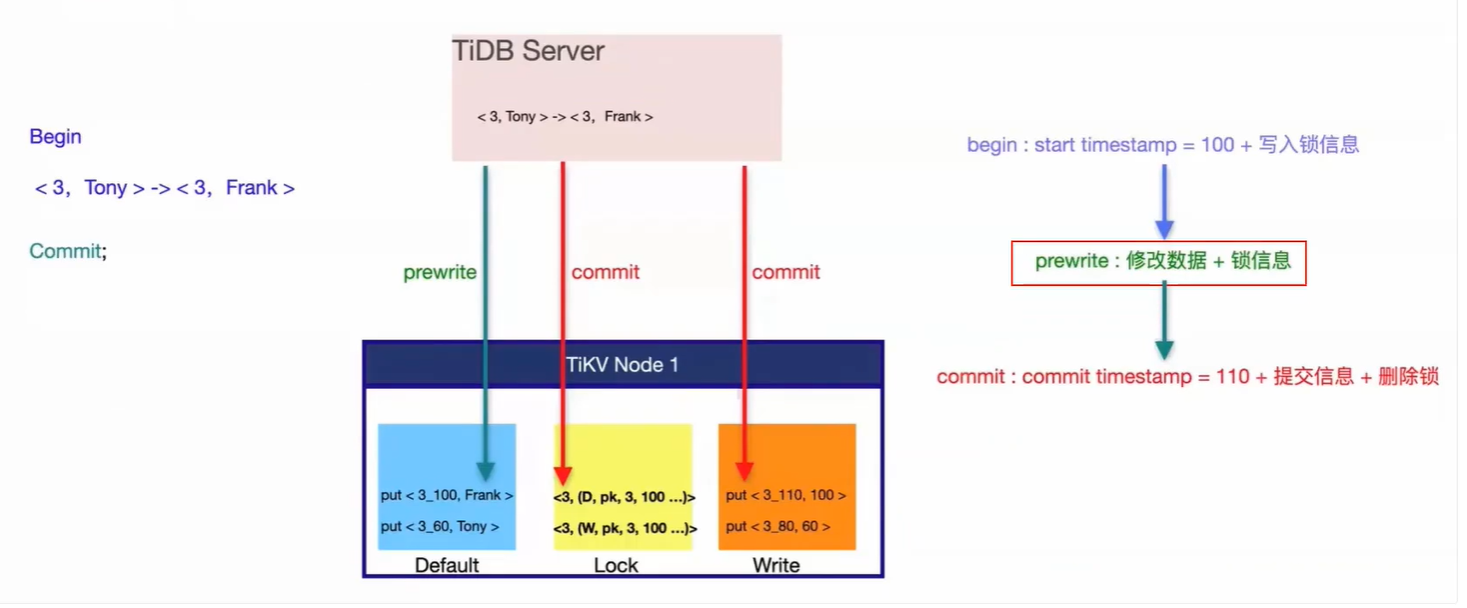
第一阶段:客户端准备
Go
// 客户端开始事务
tx := &Transaction{
startTS: TSO.GetTimestamp(), // 假设得到 start_ts = 100
writes: map[string][]byte{
"account_A": []byte("80"),
"account_B": []byte("70"),
},
}
// 随机选择Primary Key
tx.primary = "account_A"第二阶段:Prewrite(预写)
Prewrite阶段的目标是:锁定所有要修改的key,并写入新数据。
- 对Primary Key (account_A)的操作:
sql
-- 在Region1上执行
BEGIN TRANSACTION WITH start_ts = 100
-- 1. 检查冲突:account_A是否被其他事务锁定?
-- 2. 写入锁到Lock CF
INSERT INTO LockCF (key, value)
VALUES ('account_A', 'lock_info: {primary: account_A, start_ts: 100}')
-- 3. 写入数据到Data CF
INSERT INTO DataCF (key, value)
VALUES ('account_A_100', '80') -- 格式: key_start_ts- 对Secondary Key (account_B)的操作:
sql
-- 在Region2上执行
BEGIN TRANSACTION WITH start_ts = 100
-- 1. 检查冲突:account_B是否被其他事务锁定?
-- 2. 写入锁到Lock CF
INSERT INTO LockCF (key, value)
VALUES ('account_B', 'lock_info: {primary: account_A, start_ts: 100}')
-- 3. 写入数据到Data CF
INSERT INTO DataCF (key, value)
VALUES ('account_B_100', '70')注意:Secondary key的锁中记录了primary key的信息,这是故障恢复的关键
Prewrite成功条件:
- 所有key都没有被其他事务锁定
- 所有key的已提交版本都早于start_ts(防止写倾斜)
第三阶段:Commite(提交)
如果Prewrite全部成功,客户端获取commit_ts(假设为101),然后提交。
- 首先提交Primary key:
sql
-- 在Region1上执行
-- 1. 检查Primary Key的锁是否仍然存在(防止过期)
-- 2. 写入提交记录到Write CF
INSERT INTO WriteCF (key, value)
VALUES ('account_A_101', '100') -- 格式: key_commit_ts, 指向start_ts=100的数据
-- 3. 删除Lock CF中的锁
DELETE FROM LockCF WHERE key = 'account_A'关键点:一旦Primary key提交记录写入成功,事务在外部看来就已经提交了。即使此时客户端崩溃,事务的结果也确定了
- 然后提交Secondary keys:
sql
-- 在Region2上执行
-- 1. 检查Secondary Key的锁是否仍然存在
-- 2. 写入提交记录到Write CF
INSERT INTO WriteCF (key, value)
VALUES ('account_B_101', '100')
-- 3. 删除Lock CF中的锁
DELETE FROM LockCF WHERE key = 'account_B'Secondary keys的提交可以异步进行,即使客户端在提交完Primary后崩溃,其他事务或后台线程会帮助完成Secondary keys的提交。
4.4 读操作与快照隔离
读操作如何看到一致性快照?这依赖于MVCC和时间戳机制。
Go
// 读操作的简化流程
func Read(key []byte, startTS int64) ([]byte, error) {
// 1. 检查key是否被锁住
lock := GetLock(key)
if lock != nil && lock.startTS < startTS {
// 被较早的事务锁住,等待或abort
return WaitOrAbort(lock)
}
// 2. 查找Write CF,找到commit_ts <= startTS的最大commit_ts
commitTS := FindLatestWriteCF(key, startTS)
if commitTS == 0 {
return nil, errors.New("key not found")
}
// 3. 从Write CF获取start_ts
startTSOfData := GetStartTSFromWriteCF(key, commitTS)
// 4. 从Data CF读取数据
return GetDataCF(key, startTSOfData)
}示例,假设在时间戳120时读取account_A:
- 查找WriteCF中key为account_A,commit_ts < 120的最大commit_ts
- 找到account_A_101 -> 100(表示在101提交的数据,其start_ts是100)
- 从Data CF读取account_A_100,得到数据为80
这就是快照隔离:每个事务看到的是事务开始时的数据快照,无论其他事务如何并发修改
4.5 故障恢复:系统自愈能力
Percolator的精妙之处在于其优雅的故障处理机制。由于没有中心化的事务管理器,故障恢复是通过数据本身完成的。
场景一:客户端在Prewrite阶段崩溃
Go
事务T1: start_ts=100
Prewrite:
- account_A: 已写入锁和数据 ✓
- account_B: 已写入锁和数据 ✓
Commit: 客户端在提交前崩溃 ❌恢复过程:
- 事务T2尝试修改account_A,发现锁
- 事务T2检测锁的start_ts = 100,判断事务是否过期(通过比较当前时间与start_ts)
- 如果过期,T2执行回滚:清理锁和对应数据版本
- 如果未过期,T2等待锁释放(避免活锁)
场景二:客户端在Commit Primary后崩溃
Go
事务T1: start_ts=100, commit_ts=101
Prewrite: 全部成功 ✓
Commit:
- account_A: 提交成功 ✓
- account_B: 客户端在提交前崩溃 ❌恢复过程:
- 事务T2尝试读取account_B,发现锁
- T2查看锁信息:{primary: account_A, start_ts: 100}
- T3查询account_A的状态:
- 检查Write CF中account_A在100之后是否有提交记录
- 找到account_A_101 -> 100,说明事务已提交
- T2帮助提交account_B:写入Write记录,清理锁
- T2继续自己的操作
场景三:客户端在Commit Secondary时崩溃
Go
事务T1: start_ts=100, commit_ts=101
Prewrite: 全部成功 ✓
Commit:
- account_A: 提交成功 ✓
- account_B: 写入Write记录后,清理锁前崩溃 ❌恢复过程:
- 事务T2尝试读取account_B,发送锁
- 检测Write CF,发现account_B_101已存在
- 因此事务已提交,直接清理锁
- 读取account_B_100的数据
这种设计使得Percolator模型具有自我修复的能力:未完成的事务最终会被其他事务清理,系统总能达到一致性状态
4.6 TiDB的优化实现
在实际的TiDB中,Percolator模型有一些重要优化:
优化一:异步提交
Go
// 传统Percolator
func Commit() error {
commitTS := TSO.GetTimestamp()
CommitPrimary() // 同步
CommitSecondaries() // 同步
return nil
}
// 异步提交优化
func AsyncCommit() error {
commitTS := TSO.GetTimestamp()
CommitPrimary() // 同步
go CommitSecondaries() // 异步,不阻塞客户端
return nil
}优点:客户端无需等待所有Secondary keys提交完成,降低延迟。
优化二:1PC(One-Phase Commit)
如果事务只涉及单个Region,可以跳过复杂的2PC流程:
Go
func OnePCCommit() error {
// 单Region事务,直接写入数据
// 无需Prewrite阶段
WriteDataAndCommitInOnePhase()
return nil
}优点:减少一次RPC往返,提升性能。
优化三:批量提交
将多个key的Prewrite或Commit请求批量发送:
Go
func BatchPrewrite(keys []string) error {
// 将keys按Region分组
groups := GroupByRegion(keys)
// 并行发送到不同Region
for _, group := range groups {
go SendBatchPrewrite(group)
}
return WaitAll()
}优点:减少网络请求数量,提升吞吐量。
4.7 与单机事务的对比总结
| 特性 | MySQL InnoDB (单机) | TiDB Percolator (分布式) |
|---|---|---|
| 原子性 | Redo/Undo Log | 两阶段提交 + Primary Key |
| 一致性 | 约束检查 + 日志 | 全局时间戳 + Raft |
| 隔离性 | MVCC + 锁 | 全局快照隔离 |
| 持久性 | WAL | Raft复制 + WAL |
| 锁管理 | 内存锁表 | 分散在数据中 |
| 时钟 | 本地计数器 | 全局TSO |
| 扩展性 | 垂直扩展 | 水平扩展 |
| 故障恢复 | Redo/Undo回放 | 基于Primary Key的状态检查 |