文章目录
- [react native(学习笔记第四课) 英语打卡微应用(3)-图片转化成语音文件](#react native(学习笔记第四课) 英语打卡微应用(3)-图片转化成语音文件)
-
-
- [1. 文字到语音的转换`AI` (`Text To Speech TTS` )](#1. 文字到语音的转换
AI(Text To Speech TTS)) - [1.1 `AI`的采用选择](#1.1
AI的采用选择) - [1.2 全体代码](#1.2 全体代码)
- [1.2.1 主要`TTS`的类](#1.2.1 主要
TTS的类) - [1.2.2 `pytest`进行提前测试](#1.2.2
pytest进行提前测试) - [1.2.3 最后进行结合到`backend`的真正代码中](#1.2.3 最后进行结合到
backend的真正代码中) - [1.2.4 修改的代码汇总](#1.2.4 修改的代码汇总)
- [1. 文字到语音的转换`AI` (`Text To Speech TTS` )](#1. 文字到语音的转换
- [2. 构建基础`TTS`类](#2. 构建基础
TTS类) - [3. 创建`pytest`代码并执行](#3. 创建
pytest代码并执行) -
- [3.1 创建`pytest`代码](#3.1 创建
pytest代码) - [3.2 执行`pytest`代码](#3.2 执行
pytest代码)
- [3.1 创建`pytest`代码](#3.1 创建
- [4. 在`backend`中调用`TTS`类进行语音生成](#4. 在
backend中调用TTS类进行语音生成) -
- [4.1 修改`backend`中的代码](#4.1 修改
backend中的代码) - [4.2 执行手机应用进行测试](#4.2 执行手机应用进行测试)
- [4.1 修改`backend`中的代码](#4.1 修改
- [5. 接下来的工作](#5. 接下来的工作)
-
react native(学习笔记第四课) 英语打卡微应用(3)-图片转化成语音文件
- 文字到语音的转换
AI(Text To Speech TTS) - 构建基础
TTS类 - 创建
pytest代码 - 在
backend中调用TTS类进行语音生成 - 接下来的工作
1. 文字到语音的转换AI (Text To Speech TTS )
TTS是Text To Speech的缩写,即"从文本到语音",是人机对话的一部分,让机器能够说话。TTS技术对文本文件进行实时转换,转换时间之短可以秒计算,速度非常快。
1.1 AI的采用选择
因为上一个阶段使用了智谱AI,进行了图片到文字的OCR抽取,为了保持LLM的单一选择,是程序更加简单。继续选择使用智谱AI。
看到智谱AI的平台上,提供了TTS的AI服务,正好可以使用。这里可以充值10元,可以使用好长时间,在测试阶段还是没有问题的。
在下面这里可以查看API的使用方法。

文本转语音API
1.2 全体代码
介绍一下在这个阶段的主要改修和做成的代码。
1.2.1 主要TTS的类
主要功能:
- 接受
HumanMessage或者纯文本的文本输入。 - 调用智谱
AI的glm-tts,进行文本到语音的输出。 - 将结果保存到
wav文件中。
1.2.2 pytest进行提前测试
主要功能:
- 从
sample文本文件中,提取文本。 - 在
pytest代码中,调用TTS类。
1.2.3 最后进行结合到backend的真正代码中
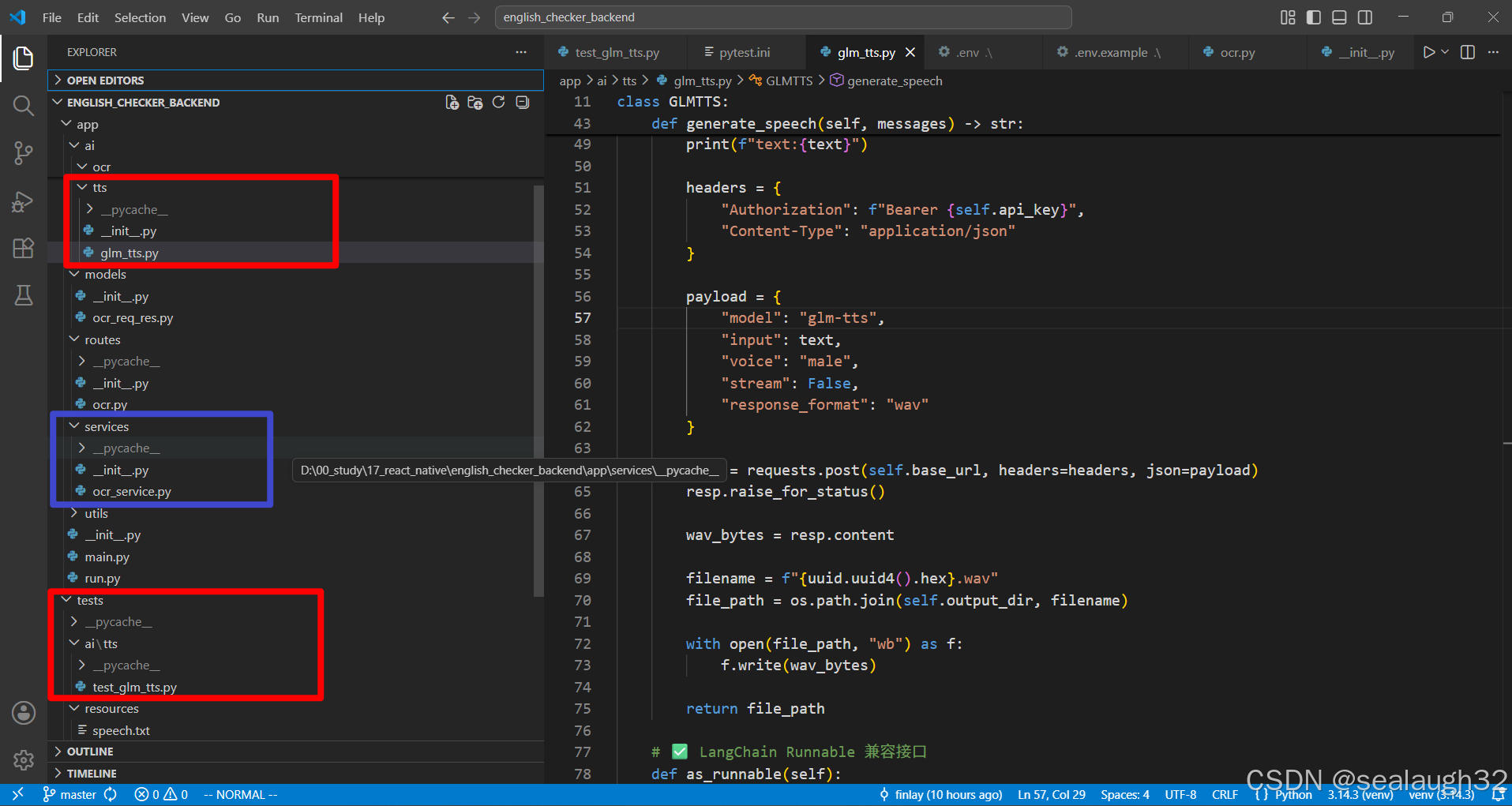
1.2.4 修改的代码汇总
红色的地方是做成的代码部分,蓝色部分是backend的代码进行调用TTS类的地方。
2. 构建基础TTS类
这里很简单,就是使用通常的request类进行https的请求,进行TTS转换。
python
import os
import uuid
import requests
import wave
import io
from dotenv import load_dotenv
from langchain_core.runnables import RunnableLambda
load_dotenv()
class GLMTTS:
def __init__(self):
self.api_key = os.getenv("ZHIPU_AI_API_KEY")
self.base_url = os.getenv(
"GLM_TTS_BASE_URL",
"https://open.bigmodel.cn/api/paas/v4/audio/speech"
)
self.output_dir = os.getenv("TTS_OUTPUT_DIR", "./tts_output")
# speech max length
self.speech_max_length = int(os.getenv("SPEECH_MAX_LENGTH",999))
os.makedirs(self.output_dir, exist_ok=True)
def _extract_text(self, messages) -> str:
"""从 LangChain message 结构中提取纯文本"""
from langchain_core.messages import HumanMessage
if not isinstance(messages, list):
return str(messages)
texts = []
for m in messages:
if isinstance(m, HumanMessage):
texts.append(m.content)
elif isinstance(m, tuple) and m[0] == "human":
texts.append(m[1])
else:
texts.append(str(m))
# if length is over max length, the cut into max length
texts = texts[:self.speech_max_length]
return "\n".join(texts).strip()
def generate_speech(self, messages) -> str:
"""
输入: LangChain message / 文本
输出: 保存后的 WAV 文件路径
"""
text = self._extract_text(messages)
print(f"text:{text}")
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
payload = {
"model": "glm-tts",
"input": text,
"voice": "male",
"stream": False,
"response_format": "wav"
}
resp = requests.post(self.base_url, headers=headers, json=payload)
resp.raise_for_status()
wav_bytes = resp.content
filename = f"{uuid.uuid4().hex}.wav"
file_path = os.path.join(self.output_dir, filename)
with open(file_path, "wb") as f:
f.write(wav_bytes)
return file_path
# ✅ LangChain Runnable 兼容接口
def as_runnable(self):
return RunnableLambda(self.generate_speech)注意,这里通过dotenv定义了SPEECH_MAX_LENGTH为999,之后暂时将超过999文字的截取到999文字内。因为通过测试看出智谱AI的glm-tts这里,如果超过1000文字,就会出错,所以暂时先这样对应了一下。以后,将考虑将文章进行每1000的分割调用。
3. 创建pytest代码并执行
3.1 创建pytest代码
这里如果直接和backend的代码,那么调式起来还需要手机react native应用的启动,进行图片的扫描与AI的ocr解析,在这之前,使用pytest进行类似于单体测试。
注意,这里规范pytest的路径:
- 和正式代码的根目录
\app的同级,建立目录\tests \tests的子路径也是测试的目标代码同样建立,\tests\ai\tts- 创建
pytest的文件test_glm_test.py
python
# tests/test_glm_tts.py
import sys
from pathlib import Path
from app.ai.tts.glm_tts import GLMTTS
def test_glm_tts_001():
with open("tests\\resources\\speech.txt", "r", encoding="utf-8") as f:
lines = f.readlines()
content = "".join(lines)
content = content[:999]
print(f"len:{len(content)}")
tts = GLMTTS()
wav_path = tts.generate_speech(content)
assert (len(wav_path) > 0)这里,需要注意两点:
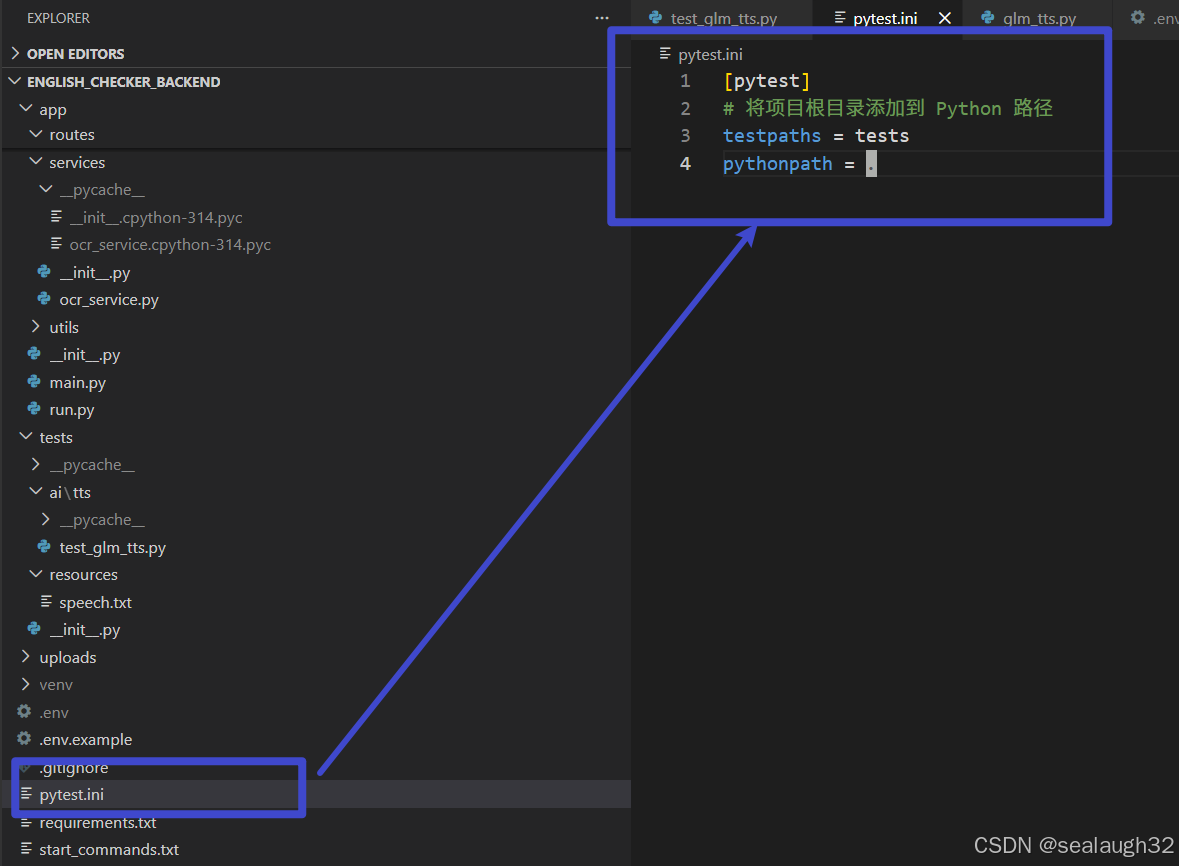
- 需要设定
pytest.ini文件,让root path设定到app和tests的父目录,以便pytest的测试代码能够找到app下的backend测试类(制品代码)。 - 另外在这里准备好测试的文本文件,
tests/resources/speech.txt,在pytest中使用这个文本文件。
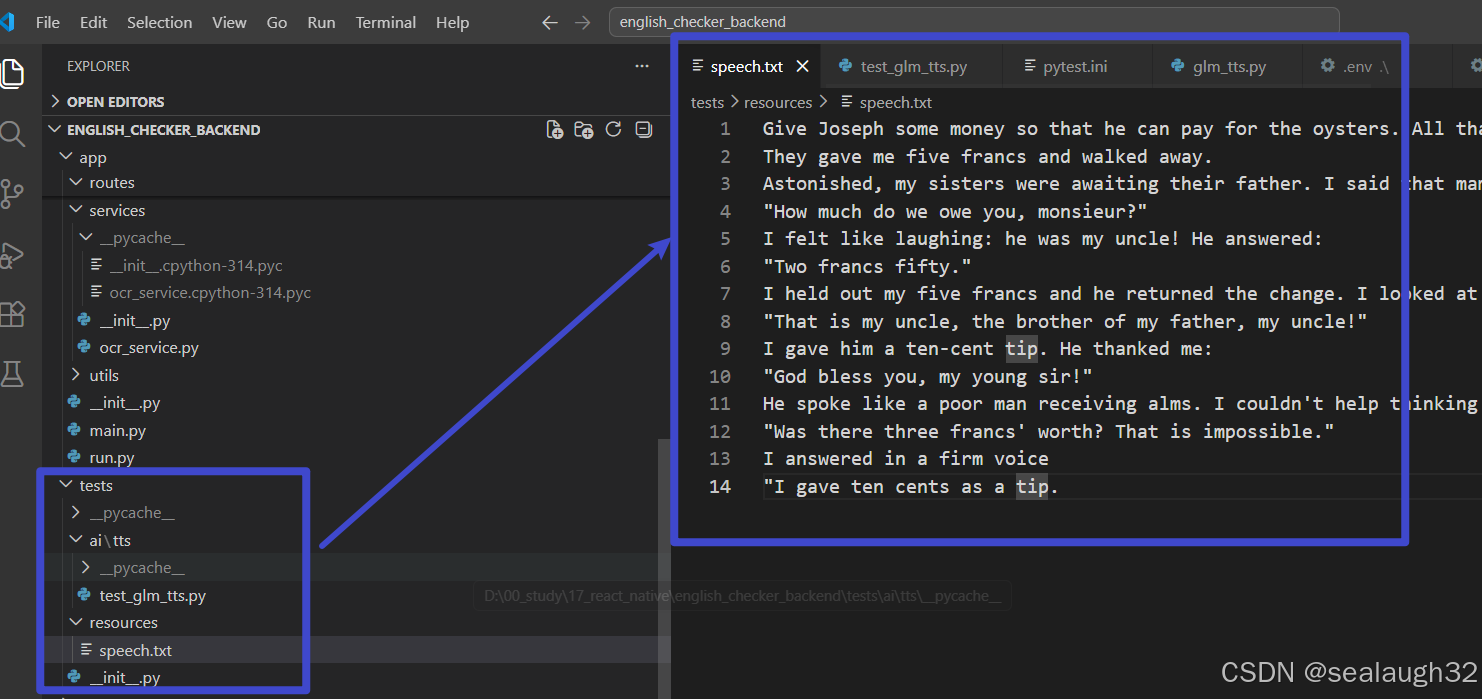
3.2 执行pytest代码
这里,因为需要执行pytest,实现安装pytest。
shell
pip install pytest之后,可以将venv里面上安装的python包提出到requirements.txt中,那么执行下面命令。
shell
pip freeze > requirements.txt接下来执行pytest的代码。
shell
pytest .\tests\ai\tts\test_glm_tts.py
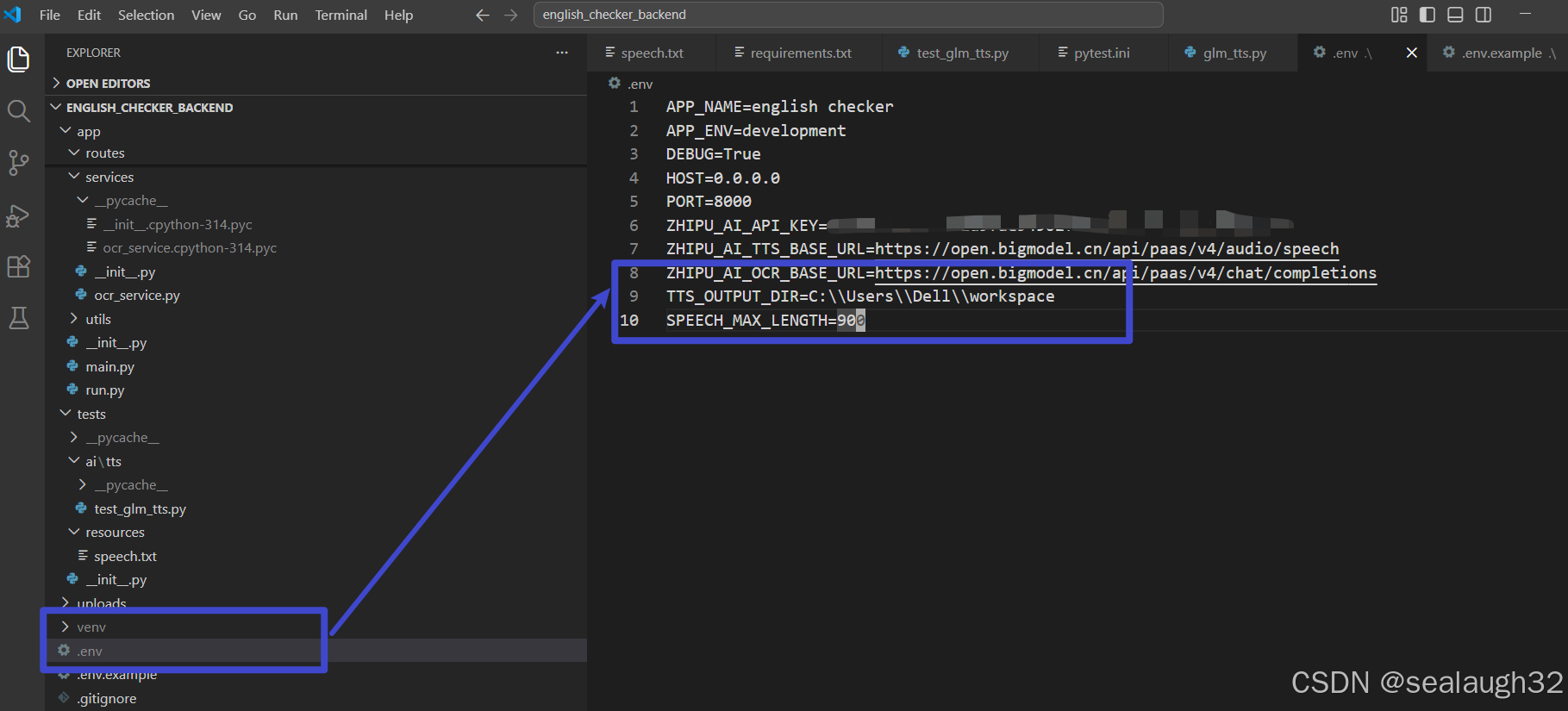
之后,进行结果的检查。注意,这里将dotenv里面定义了wav文件的输出路径。
检查输出路径,可以看到已经生成了文件(文件名字是UUID)。
可以听听转换成的语音文件。
4. 在backend中调用TTS类进行语音生成
4.1 修改backend中的代码
python
from langchain_core.messages import HumanMessage
from app.ai.tts import GLMTTS
class OCRService:
async def extract_text(self, base64_url) -> str:
"""
从图片字节数据中提取文字
"""
try:
# 在线程池中运行CPU密集型的OCR任务
# 这样可以避免阻塞FastAPI的异步事件循环
loop = asyncio.get_event_loop()
# 执行OCR
analyzer = create_image_analyzer()
result = analyzer(base64_url)
# 将执行结果送给AI,转换成wav文件
messages = [
HumanMessage(content=result),
]
tts = GLMTTS()
wav_path = tts.generate_speech(messages)
print("生成音频路径:", wav_path)
return result
except Exception as e:
logger.error(f"文字提取失败: {str(e)}", exc_info=True) # exc_info=True 会记录完整的堆栈跟踪
raise Exception(f"OCR处理失败: {str(e)}")
4.2 执行手机应用进行测试
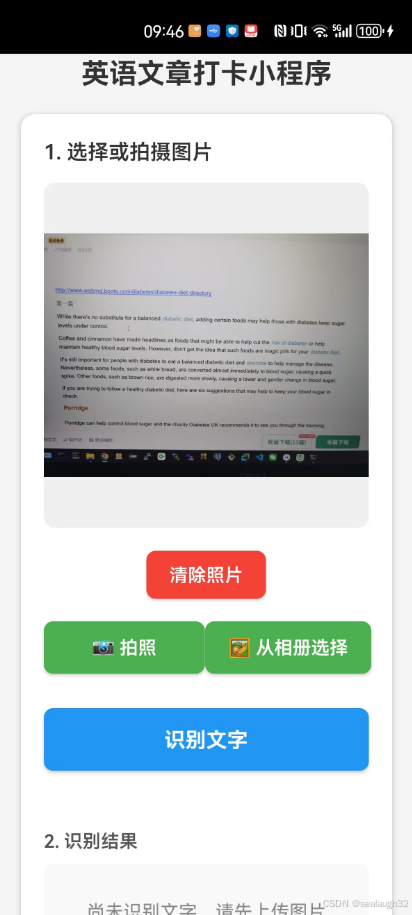
这时候,点击识别文字的按钮,就会看到,经过了一会的处理,backend的本地路径(dotenv定义)TTS_OUTPUT_DIR=C:\\Users\\Dell\\workspace上会出现生成的语音文件。
到此,实现了下面功能:
- 手机的
react native的应用进行拍照 - 传递到
backend backend调用大模型实现- 图片到文本文件的
ocr抽取 - 文本到语音的转换
- 图片到文本文件的
5. 接下来的工作
- 将文本以及生成的
wav的bytes进行数据库的保存 - 之后实现
react native手机应用上,对数据库里面的数据进行list表示。