一、开篇:为什么还要写一个专用推理引擎?
现在本地大模型生态已经很热闹了。
你想跑 GGUF,可以用 llama.cpp;你想做服务化推理,可以用 vLLM;你想快速管理本地模型,可以用 Ollama;你想搭 API,可以再套 FastAPI、Nginx、Agent 客户端。
那么问题来了:
为什么还要单独写一个推理引擎?
antirez/ds4 给出的答案很明确:它不是想做"又一个通用框架",而是想把 DeepSeek V4 Flash 这个具体模型,在本地高内存 Mac 机器上做成一个完整闭环。
它关心的不是"支持多少模型",而是:
- 这个模型的 GGUF 权重如何被正确加载?
- 这个模型的量化布局如何保持质量?
- 这个模型的 Attention、MoE、HC 等结构如何落到 Metal 图上?
- 长上下文 Agent 反复提交 Prompt 时,如何避免重复 prefill?
- 本地服务如何同时兼容 OpenAI 和 Anthropic API?
- 代码 Agent 如何直接使用这个本地模型?
这就是 ds4.c 的价值:从一个模型出发,做一条专用推理链路。
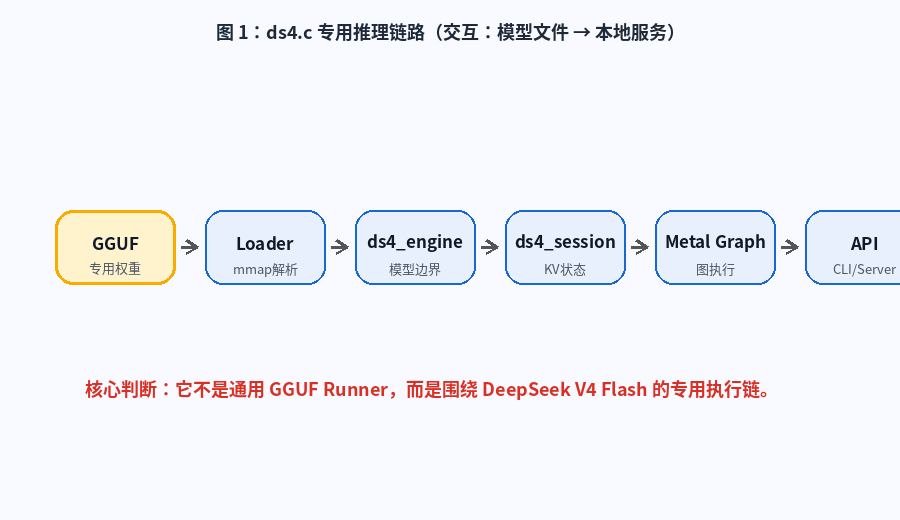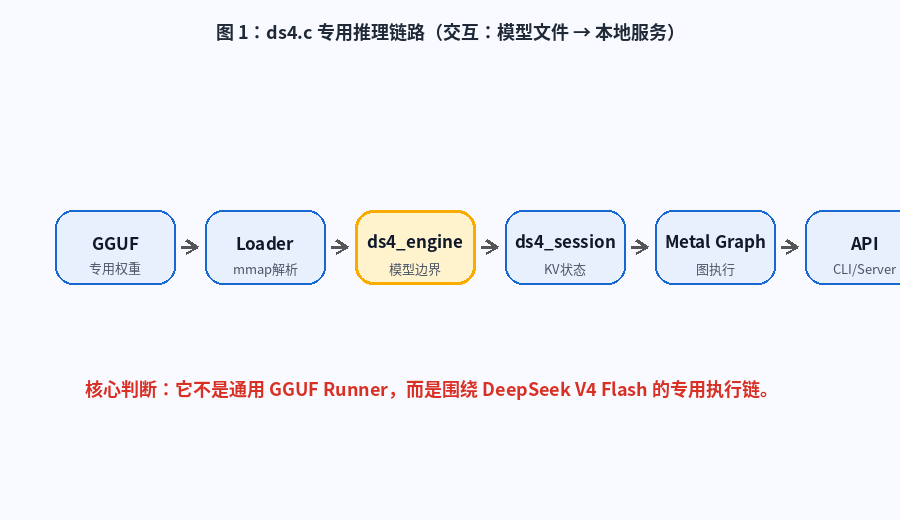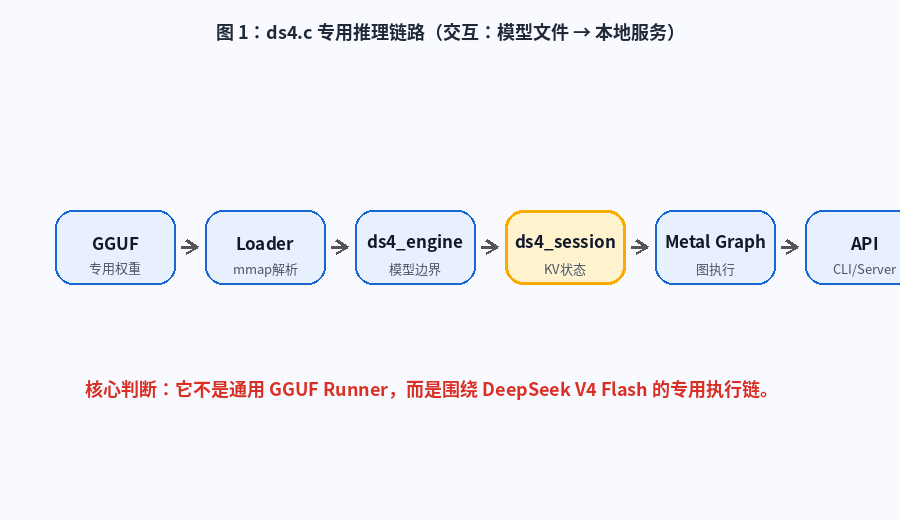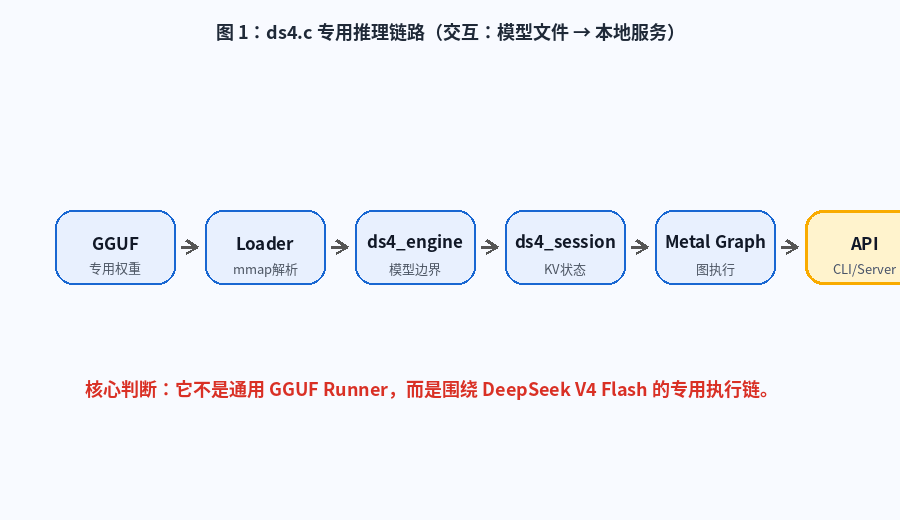
图 1:ds4.c 专用推理链路。动画展示从 DeepSeek V4 Flash GGUF 到 Loader、Engine、Session、Metal Graph,再到 CLI / Server 的完整路径。
二、项目定位:ds4.c 到底是什么?
ds4.c 是一个小型原生推理引擎,目标模型是 DeepSeek V4 Flash。
它有几个非常重要的限定:
- 不是通用 GGUF Runner
- 不是 llama.cpp 的一层包装
- 不是通用推理框架
- 主要执行路径是 Metal
- 只适配项目指定的 DeepSeek V4 Flash GGUF 权重
这几个"不是什么"非常重要,因为很多人看到 GGUF、Metal、本地 API,就会自然把它归类成 llama.cpp 的同类项目。但 ds4.c 的设计出发点完全不同。
它不是为了支持更多模型,而是为了让一个特定模型拥有更高的本地完成度。
2.1 用一句话概括
text
ds4.c = DeepSeek V4 Flash 专用 GGUF 加载器
+ Metal Graph 推理执行器
+ KV Session 管理器
+ Disk KV Cache
+ OpenAI / Anthropic 兼容本地服务2.2 它解决的核心问题
| 问题 | ds4.c 的回答 |
|---|---|
| 模型太大 | 使用专门制作的 q2 / q4 GGUF |
| 长上下文太贵 | 内存 KV + Disk KV Cache 复用前缀 |
| 本地模型不好接 Agent | 提供 OpenAI / Anthropic 兼容接口 |
| 通用框架无法深度贴合 | 固定 DeepSeek V4 Flash 结构做专用执行 |
| Prompt 反复 prefill 浪费 | session prefix 对齐,只处理新增 token |
三、设计哲学:不做通用框架,而做单模型闭环
通用框架的优势是覆盖面。覆盖面越广,越适合生态扩张;但覆盖面越广,每个模型的特殊结构就越难被极致优化。
ds4.c 选择了反方向:
text
通用框架:一个引擎支持很多模型
ds4.c:一个引擎深度服务一个模型这和数据库里的"通用执行引擎"和"专用算子优化"很像。
通用执行引擎可以覆盖各种 SQL;但如果你知道某个业务查询每天跑几千万次,就可能会为它做特化索引、物化视图、预计算、缓存路径。
ds4.c 对 DeepSeek V4 Flash 做的事情也类似:
- 模型形状固定
- 张量布局固定
- 量化策略固定
- Prompt 格式固定
- KV 状态格式固定
- API 返回格式针对 Agent 场景优化
它牺牲了"随便换模型"的能力,换来了"围绕一个模型把链路做完整"的可能。
四、整体架构:从 GGUF 到本地 API
从工程结构看,ds4.c 可以分成六层。
| 层级 | 主要职责 | 关键词 |
|---|---|---|
| 模型层 | DeepSeek V4 Flash 专用 GGUF | q2 / q4 / MTP |
| 加载层 | 解析 GGUF metadata 和 tensor directory | mmap |
| 引擎层 | 管理模型、tokenizer、固定结构 | ds4_engine |
| 会话层 | 管理 KV、logits、prefix 复用 | ds4_session |
| 执行层 | Metal Graph 执行 Attention / MoE / HC | Metal |
| 接口层 | CLI、OpenAI API、Anthropic API | ds4-server |
如果用流程表示:
text
用户请求
↓
Prompt 渲染
↓
Tokenize
↓
ds4_session 检查 prefix
↓
命中内存 KV / 磁盘 KV / 重新 prefill
↓
Metal Graph 执行
↓
采样生成 token
↓
SSE / JSON / CLI 输出这条链路看起来不复杂,但难点在于它把"推理过程"和"服务过程"绑在了一起。
普通 Server 可能只是把模型调用包成 HTTP API。ds4-server 更进一步:它把请求解析、Prompt 渲染、KV 复用、磁盘 checkpoint、流式输出、工具调用兼容都放进了同一条设计线上。
五、模型权重与非对称量化策略
ds4.c 不是拿任意 DeepSeek GGUF 都能跑。它只支持项目提供的专用 GGUF 文件。
项目给出了主要两类主模型:
bash
./download_model.sh q2 # 128GB RAM 机器
./download_model.sh q4 # 256GB+ RAM 机器还可以下载可选 MTP 组件:
bash
./download_model.sh mtp5.1 q2 与 q4 的差异
| 类型 | 大致定位 | 适合机器 | 特点 |
|---|---|---|---|
| q2 | 2-bit routed experts | 128GB RAM | 更省内存,重点服务个人高内存 Mac |
| q4 | 4-bit routed experts | 256GB+ RAM | 质量和资源开销更高 |
| mtp | speculative decoding 组件 | q2 / q4 都可选 | 目前更多是实验性小幅加速 |
5.2 为什么不是全模型统一量化?
这个项目的量化思路很有意思:不是把所有张量一刀切压低,而是重点处理模型空间占用最大的部分。
简单理解:
- routed MoE experts 占据主要模型空间
- 所以重点量化 routed experts
- 共享专家、投影、路由等关键组件尽量保留质量
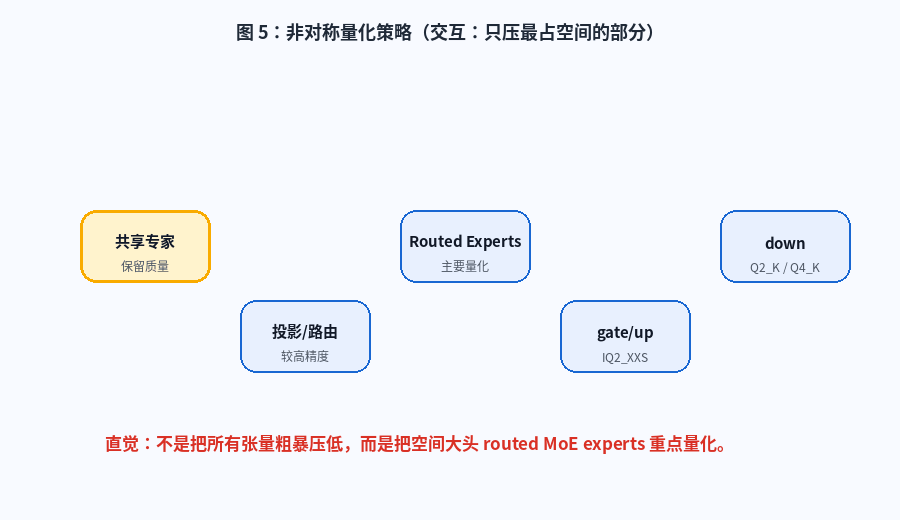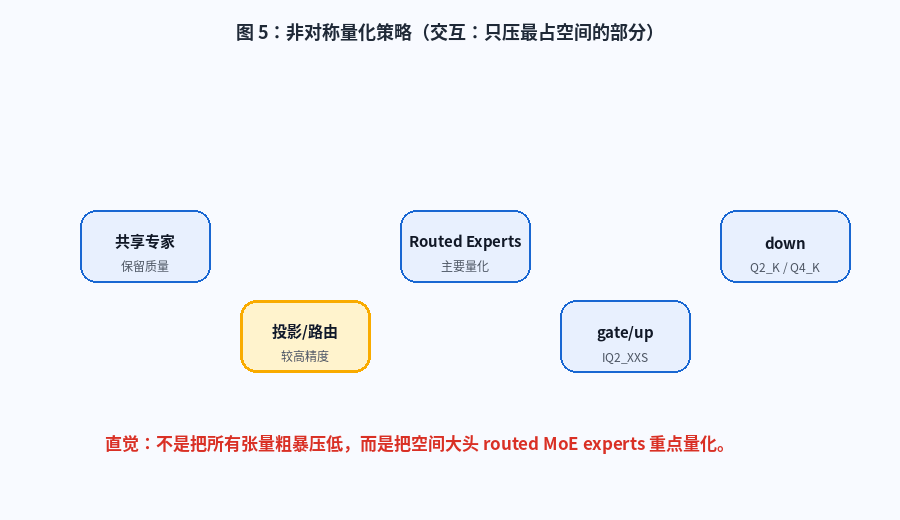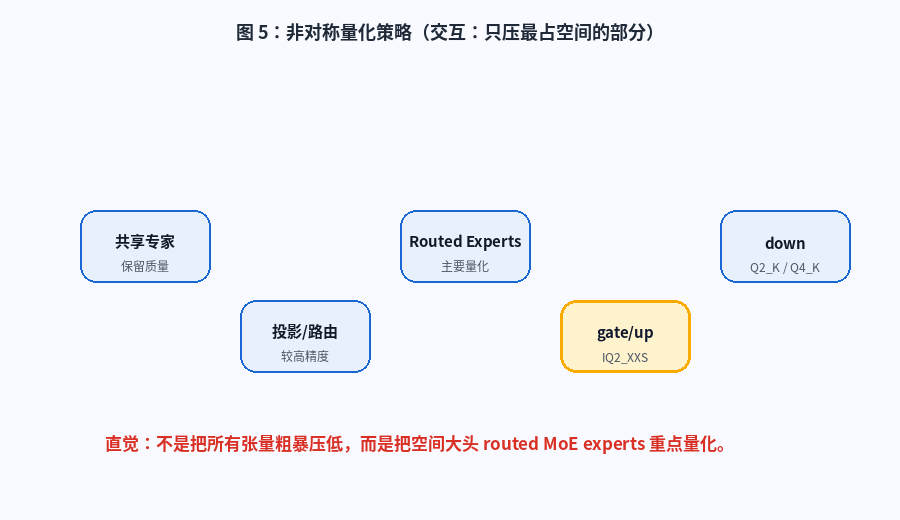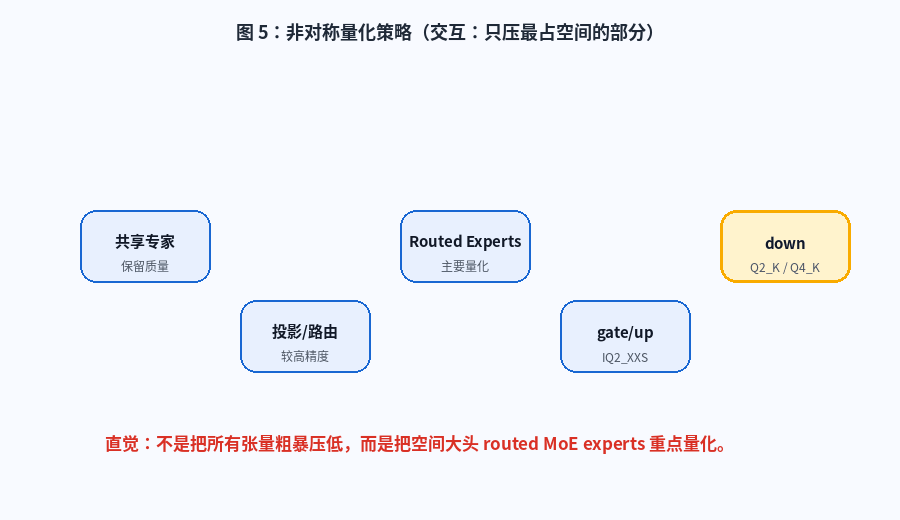
图 5:非对称量化策略。动画展示共享专家、投影/路由、routed experts、gate/up、down 等组件在量化策略中的不同位置。
这是一种非常工程化的取舍:
text
不是哪里都省,
而是只在最值得省的地方省。对大模型本地部署来说,这种"结构感知量化"比普通的"全局低比特压缩"更值得研究。
六、Metal Graph:真正的执行核心
ds4.c 的快路径是 Metal。
它把 DeepSeek V4 Flash 的核心计算拆成一组 Metal tensor 与 kernel,包括:
- Token embedding
- Q / KV projection
- RoPE
- Attention
- KV Compression
- Router
- Routed MoE
- Shared expert
- Hyper-Connection
- Output head
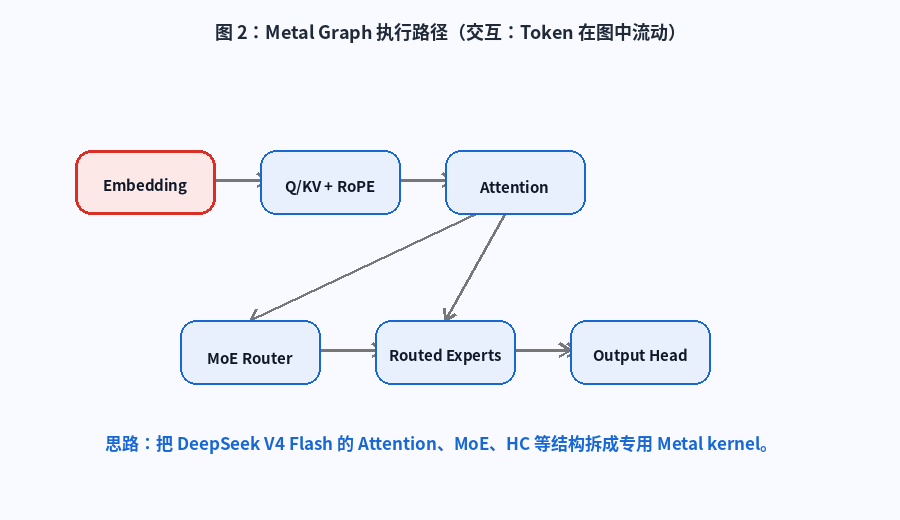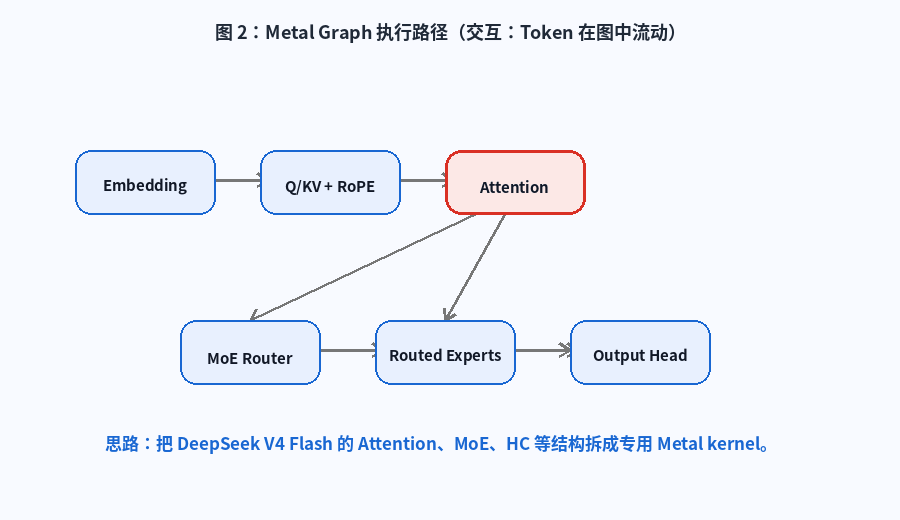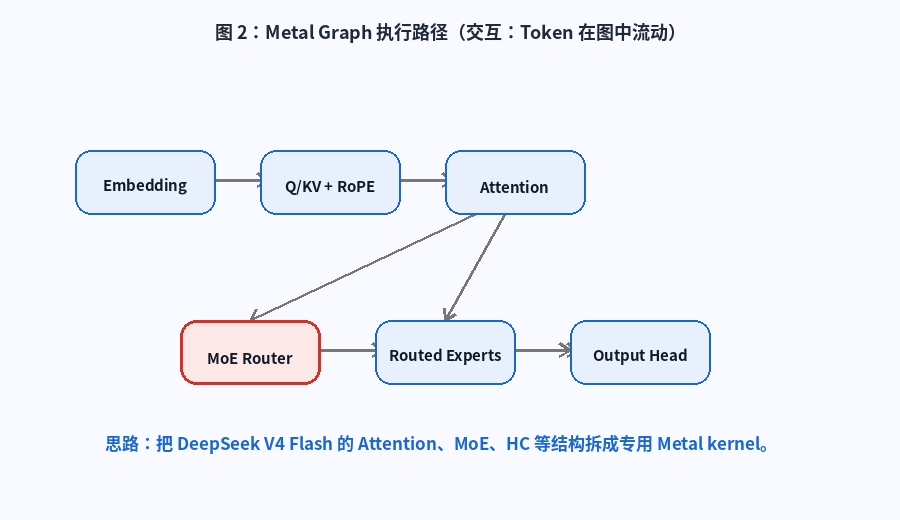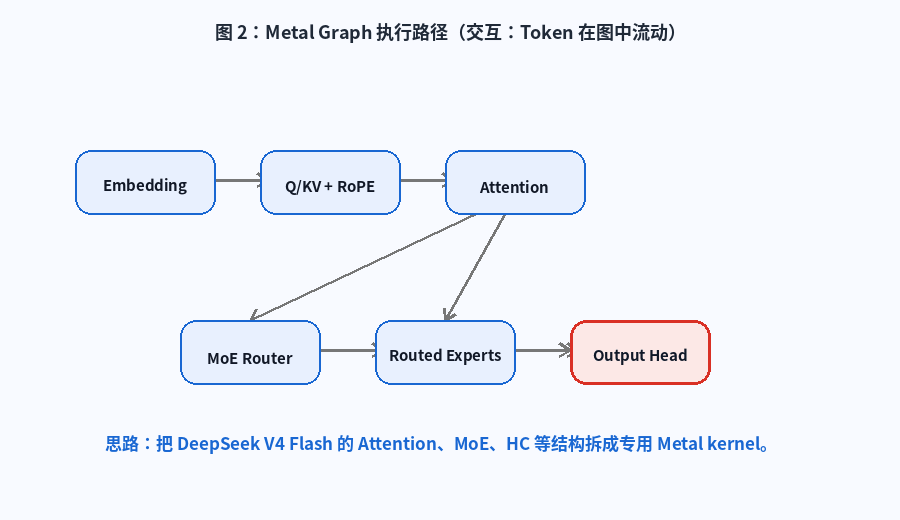
图 2:Metal Graph 执行路径。动画展示 token 从 Embedding 进入 Q/KV、Attention、MoE Router、Routed Experts,再进入 Output Head 的大致流动。
6.1 为什么是 Metal?
因为项目目标是高内存 Apple Silicon 机器:
- MacBook Pro M3 Max 128GB
- Mac Studio M3 Ultra 512GB
- 类似统一内存架构的本地设备
在这种设备上,Metal 是主要 GPU 计算入口。ds4.c 针对 Metal 做深度执行路径,就能避开通用框架的一部分抽象成本。
6.2 CPU 路径是什么?
项目中也有 CPU 相关路径,但它不是生产推理目标。CPU 路径更像是:
- correctness check
- debug reference
- 对照验证
所以不要把它理解成"CPU 也能高性能跑"。
七、ds4_engine 与 ds4_session:模型和会话的边界
这个项目的边界设计很清楚:
text
ds4_engine = 已加载模型
ds4_session = 一条可变推理时间线7.1 ds4_engine
ds4_engine 可以理解为模型实例,它负责:
- 打开 GGUF 文件
- 绑定权重
- 维护 tokenizer
- 暴露模型能力
- 创建 session
- 提供推理所需的公共函数
7.2 ds4_session
ds4_session 是更有意思的部分。它保存当前对话的推理状态:
- live KV cache
- 当前 token prefix
- logits
- context position
- session payload 保存/恢复能力
为什么需要 session?
因为 API 客户端通常是无状态的。客户端每次请求都会发完整消息数组,服务端必须判断:
text
这次请求是不是上次请求的延长版本?
如果是,只处理新增 token。
如果不是,能不能从磁盘 checkpoint 恢复?
如果都不行,才重新 prefill。这就是 ds4_session_sync() 这类设计的价值。
八、Disk KV Cache:把长上下文前缀存到磁盘
这是 ds4.c 最值得单独拿出来研究的设计。
传统直觉里,KV Cache 应该放在内存或显存里。但在长上下文本地推理场景中,如果模型本身支持压缩 KV,而设备又有足够快的 SSD,那么磁盘就不再只是"冷存储",而可以变成 KV 状态的二级缓存。
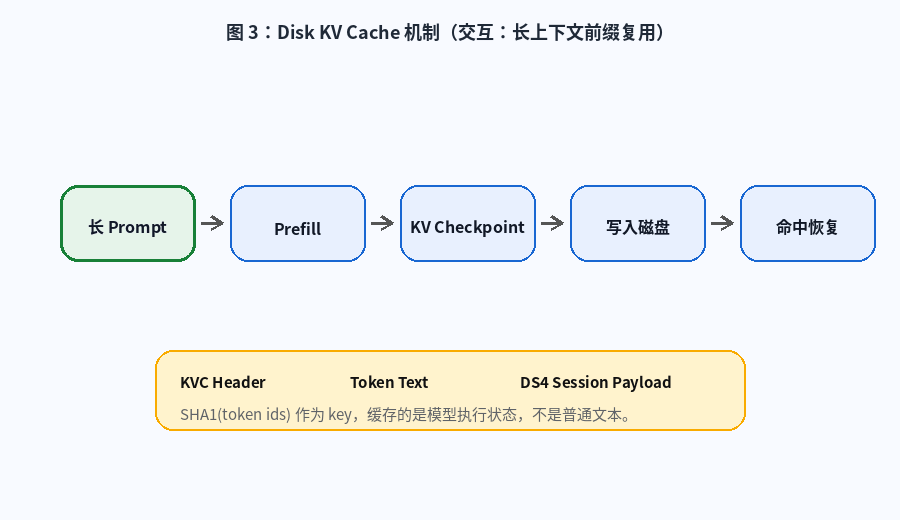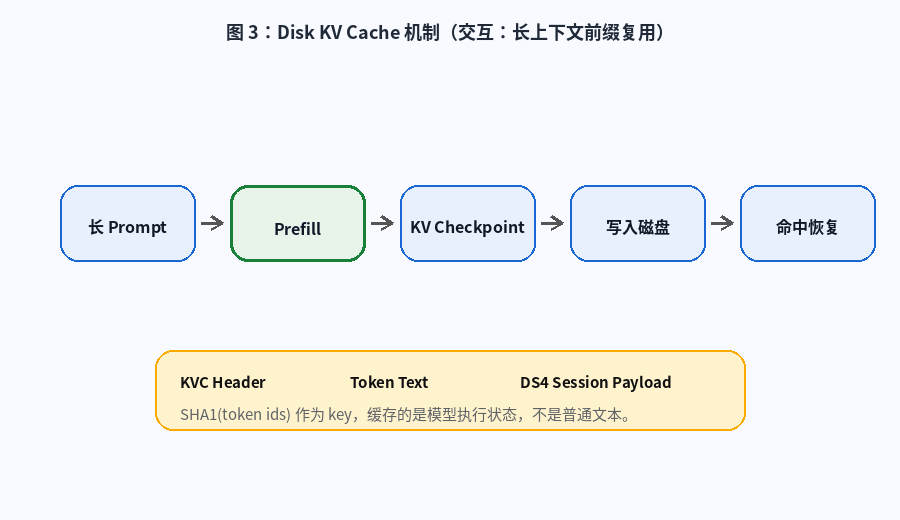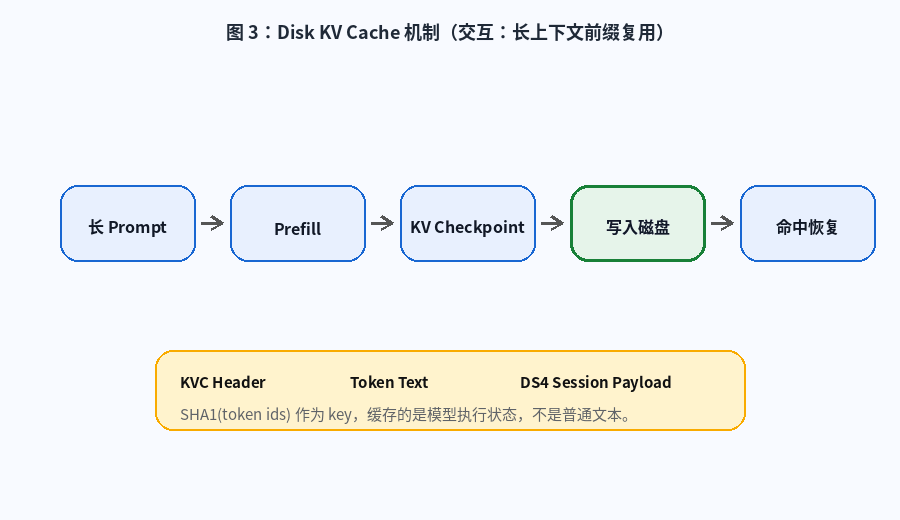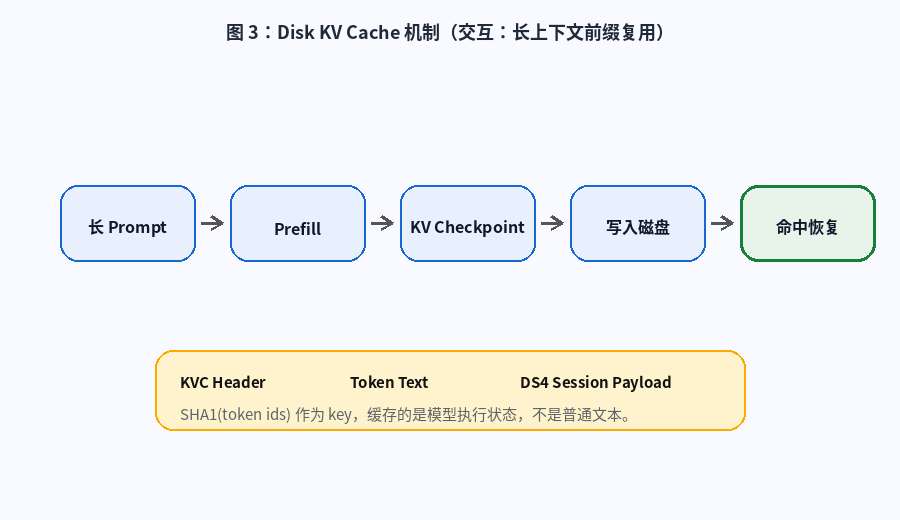
图 3:Disk KV Cache 机制。动画展示长 Prompt 经过 prefill 后生成 KV checkpoint,写入磁盘,后续请求命中相同前缀后恢复继续生成。
8.1 为什么 Agent 特别需要 Disk KV Cache?
代码 Agent 经常这样工作:
- 第一次请求带上系统提示词、项目文件、工具定义、历史上下文
- 模型生成一次回复
- 用户或工具追加一点新内容
- 客户端再次发送完整上下文
- 模型再处理一遍巨大前缀
如果没有 prefix 复用,每次请求都要重复处理前面几万甚至几十万 token。
假设:
- 初始上下文:100000 tokens
- 本轮新增内容:2000 tokens
重复计算比例近似为:
$$
\text{重复比例}
\frac{100000}{100000 + 2000}
\approx 98.04%
$$
这意味着,如果不能复用前缀,绝大多数计算都花在"已经处理过的内容"上。
8.2 Disk KV Cache 缓存的是什么?
它缓存的不是普通文本,而是模型执行状态。
大体结构如下:
text
KVC fixed header
↓
rendered token text
↓
DS4 session payload
↓
optional tool-id map section其中 session payload 包括:
- checkpoint token IDs
- 下一 token logits
- raw sliding-window KV rows
- compressed KV rows
- indexer compressed rows
- compressor frontier tensors
这已经非常接近"把推理现场保存下来"。
8.3 缓存 key 为什么用 token ids?
因为模型真正看到的不是字符串,而是 token 序列。
同样一段文本,可能因为拼接边界、特殊 token、工具调用格式不同,导致 token 序列不同。用 token IDs 作为 key,更贴近模型执行真实状态。
可以理解为:
text
文本相同 ≠ token 序列一定相同
token 序列相同 ≈ 模型输入前缀相同所以 ds4.c 使用 token IDs 的 SHA1 作为缓存 key,是合理的工程选择。
九、CLI 使用:不是 Demo,而是有状态交互入口
ds4.c 提供 ds4 命令行程序。
单次执行:
bash
./ds4 -p "Explain Redis streams in one paragraph."交互模式:
bash
./ds4
ds4>常见参数:
bash
./ds4 \
--ctx 32768 \
--nothink \
-p "用一段话解释 Redis Stream"9.1 常用交互命令
| 命令 | 作用 |
|---|---|
/help |
查看帮助 |
/think |
开启普通 thinking |
/think-max |
开启 Think Max,受上下文大小限制 |
/nothink |
直接回答 |
/ctx N |
修改上下文大小 |
/read FILE |
从文件读取 Prompt |
/quit |
退出 |
图 6:CLI / Server / Agent 工作流。动画展示从 CLI 本地交互,到 Server API,再到代码 Agent 接入的完整使用路径。
9.2 CLI 的关键不是输入输出
CLI 最大价值不是"能打字问模型",而是:
text
交互式 CLI 也维护 rendered chat transcript 和 live Metal KV checkpoint。也就是说,多轮对话不是每次从零开始,而是延续同一个 session。
十、Server 使用:OpenAI / Anthropic 双协议兼容
服务端启动命令:
bash
./ds4-server \
--ctx 100000 \
--kv-disk-dir /tmp/ds4-kv \
--kv-disk-space-mb 8192支持的接口包括:
text
GET /v1/models
GET /v1/models/deepseek-v4-flash
POST /v1/chat/completions
POST /v1/completions
POST /v1/messages10.1 OpenAI 风格请求
bash
curl http://127.0.0.1:8000/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{"role": "user", "content": "List three Redis design principles."}
],
"stream": true
}'10.2 Anthropic 风格请求
Anthropic 风格主要服务 /v1/messages,适合 Claude Code 一类客户端。
这类兼容非常实用,因为本地模型要进入真实开发工作流,不能只输出纯文本,还要处理:
- system prompt
- messages
- tools
- tool_choice
- stop_sequences
- streaming
- thinking controls
- usage 信息
- 工具调用块
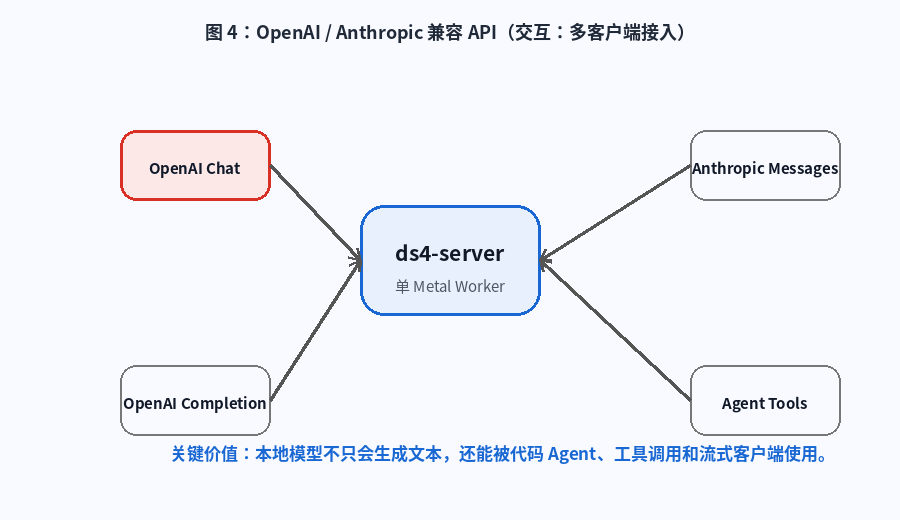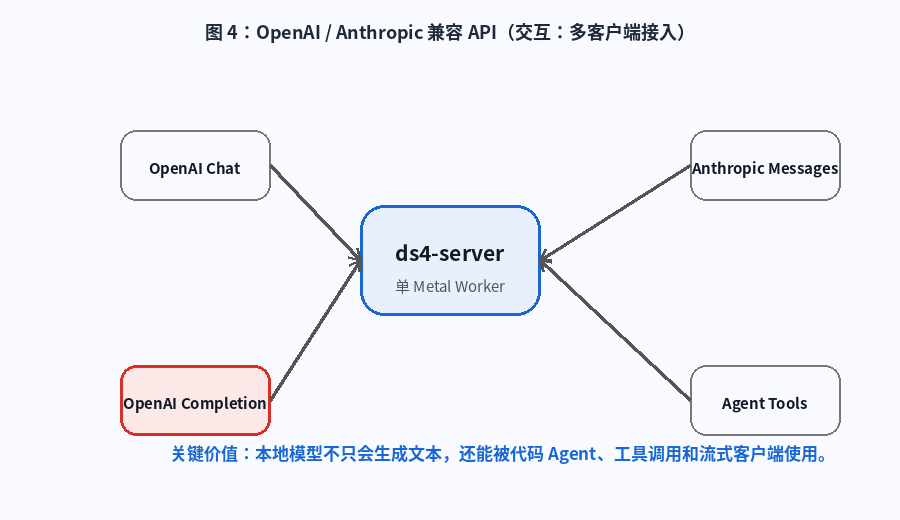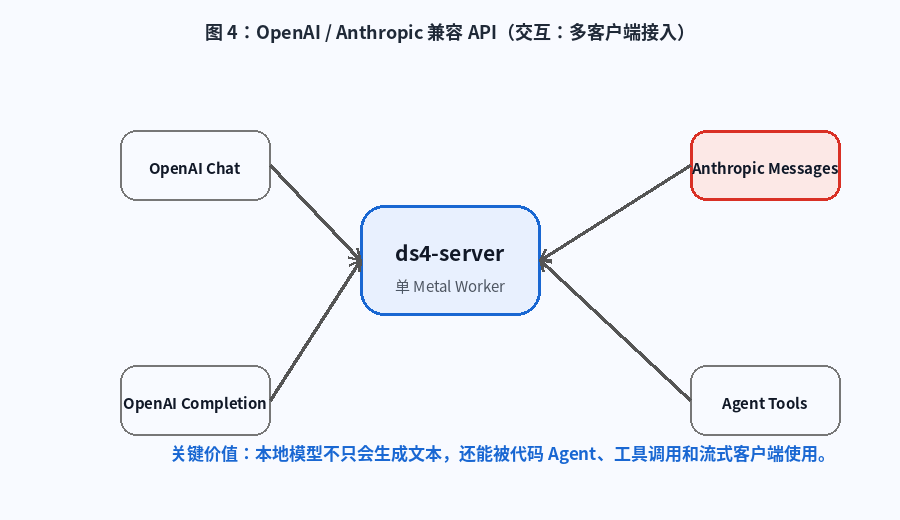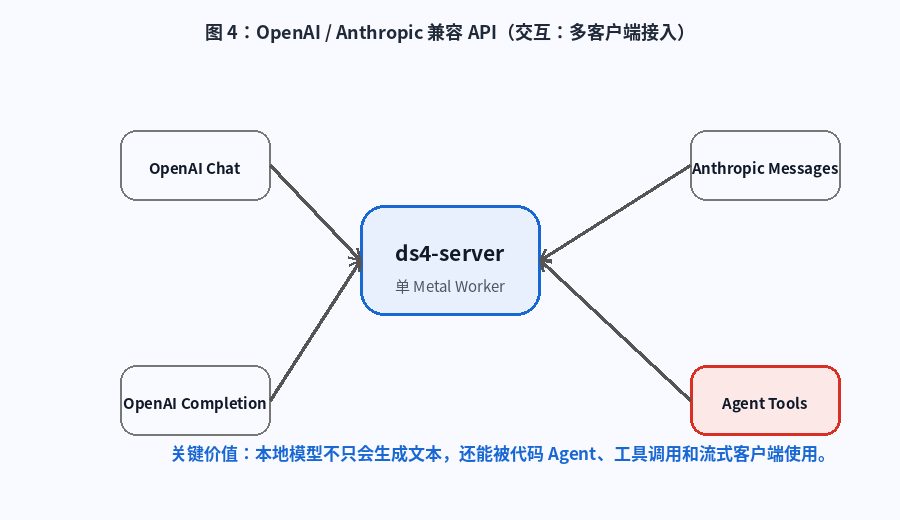
图 4:OpenAI / Anthropic 兼容 API。动画展示 OpenAI Chat、Completion、Anthropic Messages、Agent Tools 等不同客户端进入 ds4-server。
10.3 并发模型
这里要注意:ds4-server 当前并不是 vLLM 那种高并发批处理服务。
它的推理本身会通过一个 Metal worker 串行化,原因是:
text
一个 worker 持有 live ds4_session 和 KV 状态,
这样 session 复用、磁盘 checkpoint 和后续 batching 决策都集中在一个地方。这对本地 Agent 非常合理,但对高并发 API 服务不是最佳模型。
十一、Agent 接入:本地模型如何进入代码工作流
ds4-server 的一个重要目标是服务本地代码 Agent。
典型链路如下:
text
代码 Agent
↓
OpenAI / Anthropic 兼容请求
↓
ds4-server
↓
渲染 Prompt + 工具 schema
↓
DeepSeek V4 Flash 本地推理
↓
流式返回 reasoning / text / tool_use11.1 为什么 Agent 场景更复杂?
普通聊天只需要:
text
输入文本 → 输出文本Agent 场景还需要:
text
输入消息
+ 系统提示词
+ 工具定义
+ 工具调用历史
+ 文件上下文
+ 长对话历史
↓
模型输出
+ 思考内容
+ 最终文本
+ 工具调用
+ 流式增量这也是 ds4.c 为什么要重视 API glue、tool schema、DSML 工具格式、Disk KV Cache 的原因。
11.2 本地 Agent 的关键矛盾
本地 Agent 通常有两个矛盾:
- 上下文越来越长
- 每轮新增内容其实很少
Disk KV Cache 正好解决这个矛盾。
如果每轮只新增几百到几千 token,那么命中前缀后,只处理新增 token 就能明显降低等待时间。
十二、和 llama.cpp、vLLM、Ollama 的定位对比
ds4.c 不能简单说"比谁好",因为它的定位不同。

图 7:ds4.c 的定位。动画对比 llama.cpp、vLLM、Ollama 与 ds4.c 的目标差异。
| 项目 | 主要定位 | 后端特点 | 适合场景 |
|---|---|---|---|
| llama.cpp | 通用 GGUF 本地推理 | CPU / CUDA / Metal / Vulkan 等 | 多模型、跨平台 |
| vLLM | 高吞吐服务端推理 | CUDA 为主 | GPU 集群、API 服务 |
| Ollama | 本地模型管理与调用体验 | 封装底层推理引擎 | 快速体验和模型分发 |
| ds4.c | DeepSeek V4 Flash 专用引擎 | Metal 为主 | 高内存 Mac 本地长上下文推理 |
12.1 如果你想多模型通用
选 llama.cpp / Ollama 更自然。
12.2 如果你想服务端高吞吐
选 vLLM 更自然。
12.3 如果你想研究专用模型本地链路
ds4.c 很值得看。
它更像是一个问题的答案:
如果我只关心一个模型,能不能把这个模型在本地机器上做成完整产品?
十三、性能与资源:128GB 内存机器能跑什么?
根据项目说明,q2 面向 128GB RAM 机器,q4 面向 256GB+ RAM 机器。
这里最值得注意的不是单次 token/s,而是资源结构:
| 资源项 | 影响 |
|---|---|
| 模型权重 | 决定能否装进内存 |
| 上下文窗口 | 决定 KV / indexer / buffer 开销 |
| Disk KV Cache | 决定长上下文重复请求能否复用 |
| Metal 后端 | 决定 Apple Silicon 上执行效率 |
| q2 / q4 | 决定质量、速度、内存的取舍 |
13.1 不要盲目开 1M 上下文
DeepSeek V4 Flash 支持非常长的上下文,但本地运行时不能只看模型上限。
更合理的做法是:
text
根据机器内存、模型量化大小、KV Cache 开销、Agent 实际需求,
选择 100K ~ 300K 这类更现实的上下文。尤其是 128GB RAM 机器,如果 q2 权重本身已经占用较多空间,再盲目拉满上下文,反而容易让系统压力变大。
十四、工程陷阱:哪些地方不能误解?
14.1 误解一:它是通用 GGUF Runner
不是。
它只支持指定 DeepSeek V4 Flash GGUF。随便拿其他 GGUF,大概率不具备它期待的 tensor layout、metadata、量化组合和 MTP 状态。
14.2 误解二:它可以替代 vLLM
不能直接替代。
vLLM 面向 CUDA 服务端高吞吐;ds4.c 当前主要面向 Metal 和本地高内存 Mac。两者不是同一赛道。
14.3 误解三:Disk KV Cache 等于普通文本缓存
不是。
普通文本缓存缓存的是"输入输出结果"。Disk KV Cache 缓存的是"模型已经计算出的中间状态"。
区别非常大:
| 类型 | 缓存对象 | 适用场景 |
|---|---|---|
| 文本缓存 | prompt → response | 完全相同问题 |
| Embedding 缓存 | text → vector | 检索系统 |
| KV Cache | token prefix → 模型状态 | 长上下文连续推理 |
14.4 误解四:CPU 路径可以生产使用
不要这么理解。
CPU 路径主要是 reference/debug/correctness check,不是正常高性能推理目标。
14.5 误解五:MTP 一定显著加速
项目里也提到当前 MTP/speculative path 仍偏实验性,不应该假设它能立刻带来明显生成速度提升。
十五、适合谁研究,谁不适合直接部署?
15.1 非常适合研究的人
如果你关注下面这些方向,ds4.c 值得仔细读:
- Apple Silicon 上大模型推理优化
- Metal kernel 组织方式
- GGUF 专用加载器
- MoE 模型本地执行
- 长上下文 KV Cache
- Agent 本地服务化
- OpenAI / Anthropic API 兼容层
- 单模型专用引擎设计
15.2 不太适合直接部署的人
如果你的主要环境是:
- A100 / H100 / 4090D
- CUDA
- Linux GPU 服务器
- vLLM 服务集群
- 多模型统一管理
- 高并发 API 网关
那么它目前不适合作为主力生产推理框架。
你可以研究它的思想,但不建议直接把它当作 vLLM 替代品。
15.3 对企业 AI 架构的启发
即使不直接部署,它仍然有三点很值得借鉴:
- 专用模型可以有专用运行时
- 长上下文服务必须重视前缀复用
- 本地模型要服务 Agent,协议兼容是基础设施,不是附属功能
十六、结语:本地推理的新方向不是只有通用化
过去我们习惯了一个方向:
text
做一个通用框架,支持越来越多模型。这是正确的,也是生态建设必须走的路。
但 ds4.c 提醒我们,还有另一条路:
text
围绕一个足够重要的模型,做一条足够完整的专用推理链路。这条路不会替代通用框架,但会补上通用框架不容易做到极致的部分。
尤其在长上下文、本地 Agent、Mac 高内存设备、单模型深度优化这些场景下,ds4.c 的设计非常有启发:
- 它不追求"大而全"
- 它接受"窄"
- 它把"窄"变成"深"
- 它把模型、缓存、接口、Agent 工作流连成了一条线
所以,ds4.c 最值得学习的不是某个具体命令,而是它背后的工程判断:
当一个模型足够重要时,为它单独打造一套运行时,也许是合理的。
参考资料
- antirez/ds4:https://github.com/antirez/ds4
- antirez/deepseek-v4-gguf:https://huggingface.co/antirez/deepseek-v4-gguf
- llama.cpp:https://github.com/ggml-org/llama.cpp
- GGUF / GGML 相关生态:https://github.com/ggml-org
- OpenAI Chat Completions API 兼容格式
- Anthropic Messages API 兼容格式