本文对应项目版本:
v0.0.12
在一个 AI 应用刚开始做聊天功能时,textarea 往往已经够用了。
用户输入一段自然语言,前端把它发给后端,后端拿到消息数组,模型开始生成回答。这个链路简单、直接,也足够支撑最早期的问答场景。
但当项目里慢慢出现 Skill(任务能力层)、Tool(可执行工具)、Resource(可读取上下文)、Prompt(可注入模型的提示模板)、MCP 能力(通过 MCP 接入的外部能力)之后,我开始遇到一个更具体的问题:用户输入不再只是一段自然语言。
它开始同时表达三件事:
- 这一轮我想做什么
- 这一轮我要引用哪个上下文
- 这一轮真正的自然语言问题是什么
普通 textarea 能承载第三件事,却很难稳定承载前两件事。
这也是 AI Mind 在 v0.0.12 里升级输入层的原因。
先简单介绍一下项目背景。AI Mind 是一个按版本持续演进的 AI Native Runtime Skeleton(AI 原生运行时骨架),不是一次性做完的 AI 产品。它从本地聊天闭环开始,逐步长出结构化流式协议、工具调用、多工具运行时、Skill 运行时、MCP 接入、能力表面,以及后续会开始推进的 Agent / 数据层能力。
到本版本之前,项目里已经有了 reader-skill(阅读类 Skill,负责承接文档读取、项目上下文和 MCP 能力消费)、utility-skill(工具类 Skill,负责计算、时间、单位换算等稳定工具任务)、本地 / 远程 MCP Tool、Resource、Prompt,以及前端的执行事实展示。
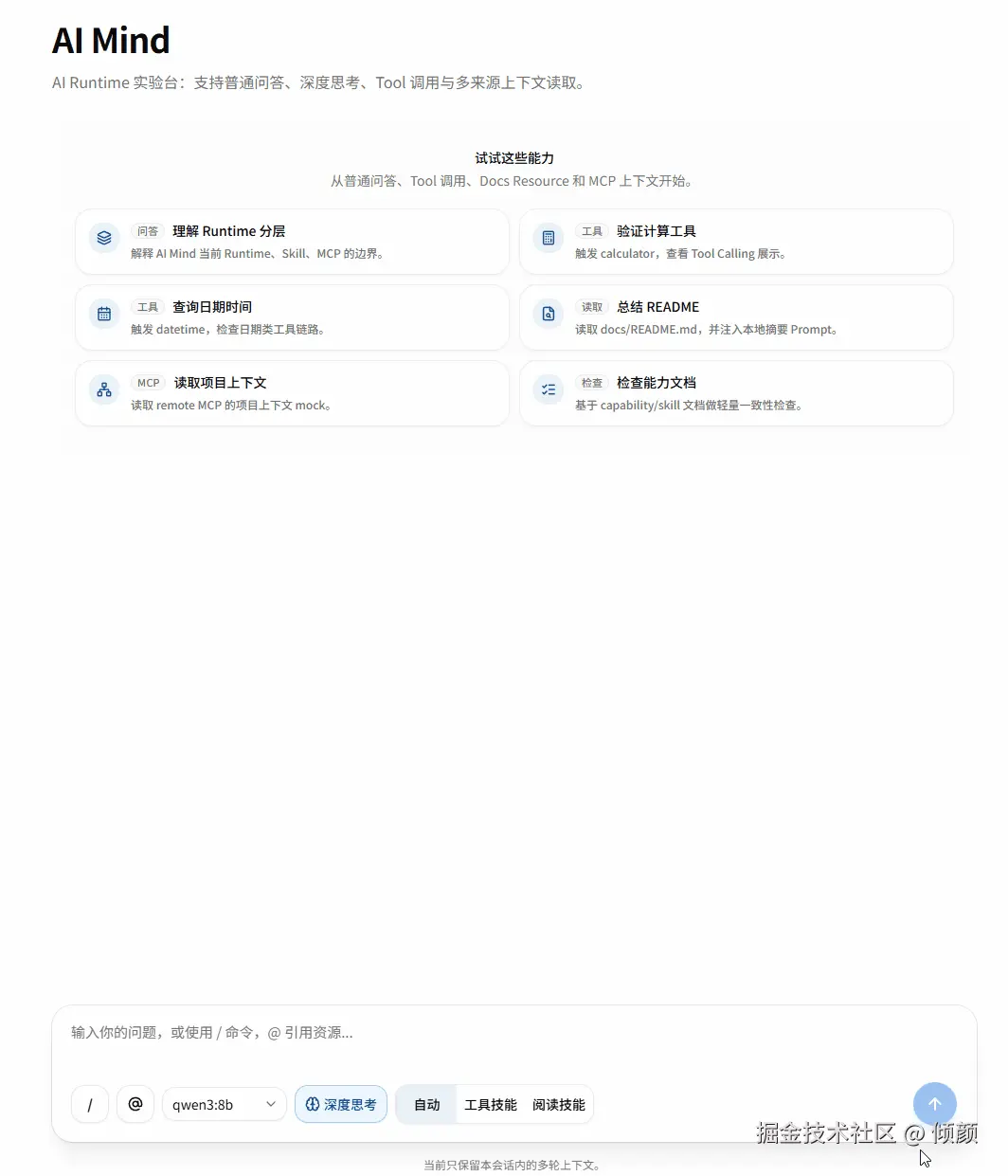
为了让第一次读到这篇文章的读者更容易跟上,这里先轻量对齐几个概念:
/command表达"我想做什么",例如选择"总结文档"。@resource表达"我想引用什么",例如显式引用docs://README.md。- 命令标签 / 资源标签(Command Chip / Resource Chip)是在输入框里可见、可删除的结构化标签。
- 结构化请求(ComposerPayload)是发送给后端的稳定输入结构,包含自然语言、命令意图和资源引用。
- Skill 是运行时最终命中的内部承接模块,例如
reader-skill承接阅读和文档类任务,utility-skill承接计算、时间等工具类任务。
这几个概念之间的关系也要先讲清楚:用户通过 /command 和 @resource 表达输入侧的能力倾向,但不是直接指定 Skill,也不是直接执行 Tool。真正由哪个 Skill 承接、是否读取资源、是否绑定工具,仍然由运行时根据上下文做最终判断。
所以这一版我没有直接进入 Agent,也没有把输入框做成复杂的富文本编辑器,而是先补了一个更基础的输入层:Composer V1。
如果把这次升级压成一句话:
这版不是把
textarea换成 Tiptap,而是让一次 AI 请求从"一段字符串"变成"自然语言 + 任务意图 + 上下文引用"的结构化输入。
普通 textarea 和 Composer V1 的差异大概是这样:
text
普通 textarea:
用户只能输入自然语言
Composer V1:
自然语言 + /命令 + @资源1. 为什么我不再满足于 textarea
在早期聊天场景里,输入框的职责很单纯:收集用户自然语言。
比如:
text
帮我总结一下这个项目。这个问题本身已经包含了任务目标,但它没有明确说明"总结哪个上下文"。如果系统里只有一段固定上下文,问题不大;但当项目开始支持 Resource(可读取上下文)、Prompt(提示模板)、MCP 服务(外部能力服务)和 Skill 路由之后,靠自然语言猜上下文会越来越不稳。
用户可能想表达的是:
text
[总结文档] @docs://README.md 这份文档的核心结构是什么?这里面其实有三层信息:
[总结文档]是任务意图@docs://README.md是上下文引用这份文档的核心结构是什么?才是自然语言问题
如果这些都塞进一段字符串里,后端只能继续靠解析文本或者靠模型自己猜。
这在工程上会带来几个问题:
- 前端不知道这轮输入到底携带了哪些结构化语义。
- 后端不知道用户引用的资源是明确选择的,还是自然语言里随口提到的。
- 运行时很难区分"用户想总结文档"和"用户只是问到 summary 这个词"。
- 下一阶段开始进入 Agent 时,输入层仍然是一团不稳定的文本。
所以 Composer V1 解决的不是"输入框更好看"这个问题,而是让输入层先有能力表达结构。
2. 为什么选择 Tiptap,但不把它当富文本编辑器用
这次我选择 Tiptap,不是因为想做一个 Markdown 编辑器。
恰好相反,我在这个版本里刻意避免把输入框做成富文本产品形态。
Tiptap 在这里是增强输入框,不是富文本编辑器。
AI Composer(AI 输入层)的职责不是排版文章,而是表达本轮 AI 请求的输入语义。它需要的是这些能力:
- 在光标位置插入一个整体可选中的标签
- 用
/触发命令菜单 - 用
@触发资源菜单 - 删除标签时同步清空对应结构化信息
- 发送时从编辑器文档树里提取结构化请求
- 输入
#、-、**bold**时保持普通文本,不自动变成富文本结构
如果继续用 textarea,最麻烦的不是输入文本,而是"输入框里有一块不是普通文本、但又要像内容一样存在"的标签。
Tiptap 的价值在这里就很明确:它能让我把命令标签(Command Chip)和资源标签(Resource Chip)做成内联原子节点(inline atom node)。也就是说,它们在编辑器里像一个整体对象一样存在,可以被光标跳过、选中、删除,同时又能在发送时被序列化成稳定的结构化信息。
本版实际代码里,composer-editor.tsx(Tiptap 输入层,负责编辑器初始化、Enter 行为、/ 与 @ 菜单触发)使用了 Tiptap,但关闭了大部分富文本能力。StarterKit 只是被裁剪后的基础输入能力,不承担 Markdown 富文本编辑器角色。
从实现流程看,它大概分成 6 步:
text
初始化 Tiptap 编辑器
-> 关闭大部分富文本能力,只保留基础输入
-> 注册 commandChip / resourceChip 两类内联节点
-> 用 Suggestion 监听 / 和 @
-> 选择菜单项后插入内联标签
-> 发送时序列化成 plainText / command / references这里最关键的不是"用了 Tiptap",而是把编辑器能力拆成了两层:前端输入体验由 Tiptap 承接,前后端协议仍然由结构化请求承接。这样后端不用理解 Tiptap 的文档树,也不会被某个前端编辑器绑定死。
所以这版我一直把它当"增强版输入框"来用:它能插入标签、处理光标和菜单、生成结构化请求,但不负责把用户输入渲染成富文本文章。
这也是我给自己设的边界:
- 不做工具栏
- 不做图片粘贴
- 不做表格
- 不做标题、列表、加粗的自动格式化
- 不做 Markdown 双向转换
- 不让后端依赖 Tiptap 原始 JSON
一句话总结:
我用的是 Tiptap 的编辑器基础能力,不是它的富文本产品形态。
3. Composer V1 的最小形态:文本、命令标签、资源标签
Composer V1 的输入模型很小,只保留三块:
text
plainText:用户自然语言
命令标签(Command Chip):用户想做什么
资源标签(Resource Chip):用户引用什么上下文本版没有做复杂选择器,也没有做完整命令执行系统。
我给它收了几个明确边界:
- 只允许一个命令标签
- 只允许一个资源标签
- 选择新的命令会替换旧命令
- 选择新的资源会替换旧资源
- 删除标签后同步清空结构化信息
- 不做搜索
- 不做文件树
- 不做完整资源选择器(Resource Picker)
- 不做 Skill / Tool / Prompt 菜单
最终前后端约定的结构是 ComposerPayload(Composer 发送给后端的结构化请求):
ts
export type ChatComposerCommandName = 'check' | 'summary' | 'tasklist'
export interface ChatComposerCommand {
label: string
name: ChatComposerCommandName
}
export interface ChatComposerReference {
id: string
label: string
serverId?: string
source: 'local' | 'remote'
type: 'resource'
uri: string
}
export interface ChatComposerPayload {
command?: ChatComposerCommand
plainText: string
references?: ChatComposerReference[]
}这里有一个小细节:虽然本版 UI 只允许一个资源标签,但结构化请求里仍然使用 references 数组。
这不是为了提前做多资源选择,而是为了让接口语义更自然。v0.0.12 只写入 0 或 1 个资源引用,后续如果真的进入受控多引用,不需要再把单数结构改成数组结构。
它也不会替代原来的消息数组。ComposerPayload 在本版里只是结构化提示信息,让运行时更清楚这一轮输入里有哪些意图和引用。
Composer V1 先解决"结构化表达",不解决"所有资源都能浏览和选择"。
4. / 命令菜单:Command 是意图,不是执行按钮
/ 命令菜单是这版最容易被误解的地方。
很多产品里的 slash command(斜杠命令)像一个"立即执行按钮":选了某个命令,就马上触发对应动作。但我在这一版没有这么做。
Composer V1 里的 Command 只是任务意图标签。
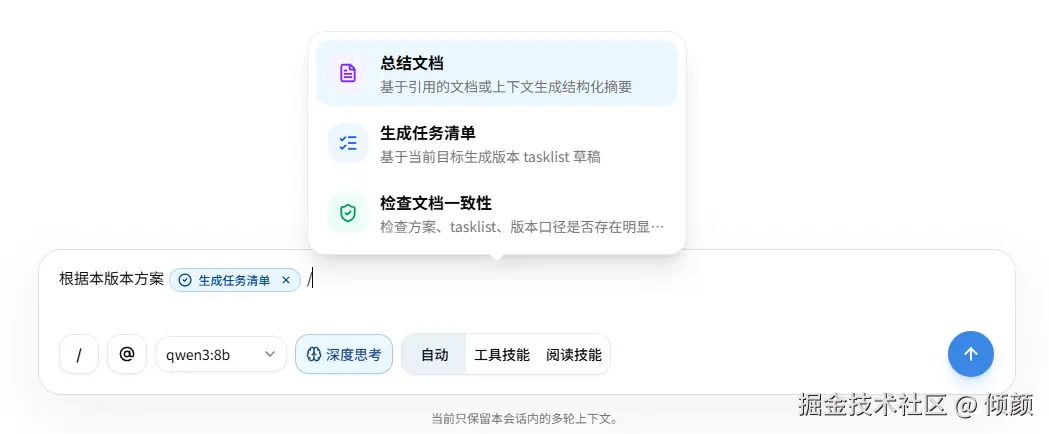
第一版固定 3 个命令:
/summary:总结文档/tasklist:生成任务清单/check:检查文档一致性
选择命令之后,输入框里会插入一个命令标签。但它不会立即调用 Prompt,也不会立即调用 Tool。
比如用户输入:
text
[生成任务清单] 帮我整理一下 v0.0.12 后续工作这里的 [生成任务清单] 只告诉后端:本轮用户更偏向"任务清单"场景。它不是一个远程 Prompt 的执行按钮。
这个边界很重要。
因为一旦把命令做成执行入口,输入层就会开始承担工作流(workflow,多步骤编排)的职责:选命令、找资源、调 Prompt、调 Tool、处理结果。这样看起来很快,但会让 Composer 提前变成一个小型 Agent。
本版我只让命令进入结构化请求,真正消费由后端运行时(Runtime)决定,而且消费范围非常窄。
5. @ 资源菜单:让上下文引用变成显式结构
@ 菜单解决的是另一个问题:用户到底引用了什么上下文?
过去用户可能会写:
text
帮我看看 README。这个问题对人来说能懂,但对运行时不够稳定。
它到底是根目录 README.md?还是 docs 里的 README.md?是本地文档?还是远程 MCP 资源?模型能不能读?读哪个服务?这些都不能靠一句自然语言长期稳定地猜。
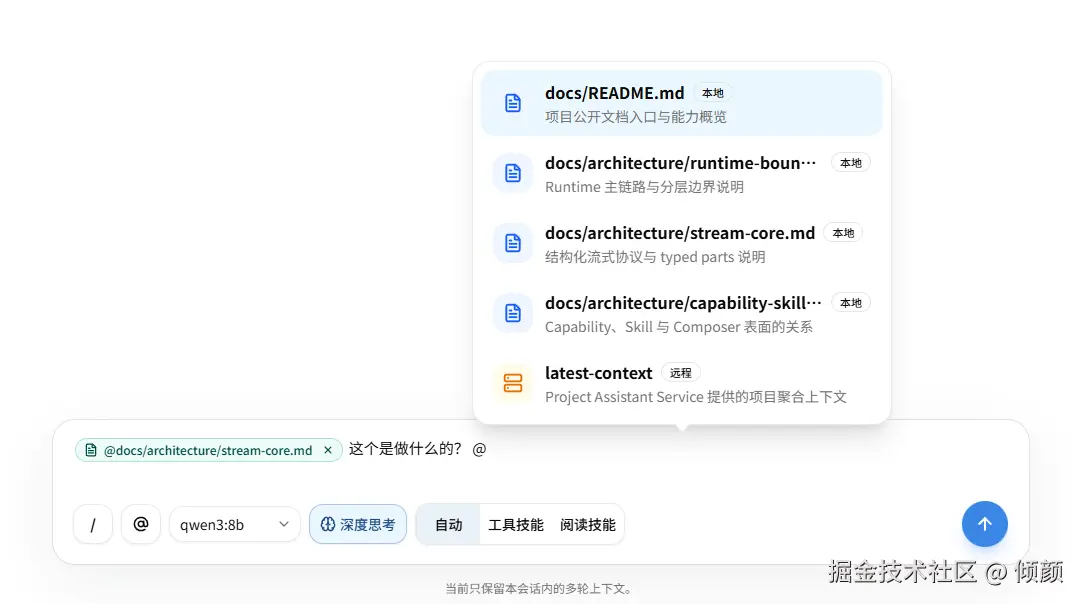
所以本版把本地文档 Resource(可读取上下文)收敛成 docs://...:
text
@docs://README.md
@docs://architecture/runtime-boundary.md
@docs://architecture/stream-core.md
@docs://architecture/capability-skill-surface.md同时保留一个远程资源:
text
@project://latest-context这背后对应了一个更大的边界收口:本地 Resource 不再是"项目任意文件读取",而是只允许读取 docs/**/*.md 里的项目知识文档,并统一使用 docs://... 这样的资源地址。
这部分不是本文主线,只需要理解成 @resource 的安全背景:用户可以显式引用项目文档,但不会把源码目录、配置文件和任意本地文件都暴露给模型。
资源标签的意义不是"前端提前读取资源",而是把"本轮显式引用了哪个资源"写进结构化请求。真正读取资源的动作仍然由运行时完成。
6. 内联标签:让结构化输入成为消息内容的一部分
最终在输入框里,我希望用户看到的是:
text
[总结文档] @docs://README.md 帮我总结核心结构也就是命令、资源和自然语言共同构成本轮输入。
所以实现里,composer-chip-nodes.ts(命令 / 资源内联节点定义,负责把标签注册成 Tiptap inline atom node)把两类标签都放进了编辑器文档树:
ts
export const COMMAND_CHIP_NODE_NAME = 'commandChip'
export const RESOURCE_CHIP_NODE_NAME = 'resourceChip'
export const CommandChipNode = Node.create({
name: COMMAND_CHIP_NODE_NAME,
group: 'inline',
inline: true,
atom: true,
selectable: true,
addNodeView() {
return ReactNodeViewRenderer(InlineComposerChipNodeView)
},
})
export const ResourceChipNode = Node.create({
name: RESOURCE_CHIP_NODE_NAME,
group: 'inline',
inline: true,
atom: true,
selectable: true,
addNodeView() {
return ReactNodeViewRenderer(InlineComposerChipNodeView)
},
})这里的关键是 inline + atom + selectable。
它让标签既是输入内容的一部分,又不会被拆成普通文本。用户可以选中它、删除它,序列化时也能准确识别它。
发送后的用户消息气泡也会保留这层语义。项目里用 displaySegments(消息展示片段,用来还原文字、命令标签和资源标签的位置)记录本轮用户消息的可读展示结构,避免发送之后只能看到一段被压平的 plain text。
这部分不是为了炫 UI,而是为了让结构化输入真正成为消息内容的一部分。
7. 结构化请求:不要把 Tiptap JSON 直接丢给后端
用了 Tiptap 之后,很自然会出现一个诱惑:既然编辑器有 JSON,那直接把 editor.getJSON() 发给后端不就好了?
我没有这么做。
原因很简单:Tiptap JSON 是前端编辑器实现细节,不应该成为 AI 运行时的输入协议。
后端真正需要的只有三件事:
plainText:用户自然语言command:本轮任务意图references:本轮显式引用的上下文资源
所以项目里专门有 composer-serialization.ts(Composer 序列化层,负责从 Tiptap 文档树提取 plainText、command、references 和 displaySegments)来做这件事。
核心逻辑是:标签不进入 plainText,而是进入结构化信息。
ts
function getInlineTextFromContent(content: JSONContent[] | undefined): string {
return (content ?? [])
.map(node => {
if (node.type === 'text') {
return node.text ?? ''
}
if (node.type === 'hardBreak') {
return '\n'
}
if (node.type === COMMAND_CHIP_NODE_NAME || node.type === RESOURCE_CHIP_NODE_NAME) {
return ''
}
return getInlineTextFromContent(node.content)
})
.join('')
}
export function serializeComposerPayload(editor: Editor): ComposerPayload {
const editorJSON = editor.getJSON()
const metadata = extractComposerMetadata(editorJSON)
return {
plainText: getPlainTextFromContent(editorJSON),
...(metadata.command ? { command: metadata.command } : {}),
...(metadata.references.length > 0 ? { references: metadata.references } : {}),
}
}这段代码解决的问题很明确:输入框里看到的 chip,不应该被混进用户自然语言。
比如:
text
[总结文档] @docs://README.md 帮我总结核心结构发送给后端时应该变成:
ts
{
plainText: '帮我总结核心结构',
command: { name: 'summary', label: '总结文档' },
references: [
{
type: 'resource',
id: 'docs-readme',
label: 'docs/README.md',
source: 'local',
uri: 'docs://README.md'
}
]
}而不是把 [总结文档] @docs://README.md 一起塞进 plainText。
这里还有一个很小但很真实的兼容点:如果用户只选择了标签,没有输入自然语言,旧的消息链路仍然需要一段非空文本。
所以 composer-submission.ts(Composer 提交兼容层,负责判断"只有标签、没有文字"的输入是否有效,并生成兼容文本)会在这种情况下用可读标签生成一段兼容文本。这样既不破坏旧消息结构,也不丢掉 Composer 的结构化语义。
8. Composer 运行时:只做很窄的消费闭环
有了结构化请求之后,下一步很容易做重。
比如:
text
/tasklist -> 自动调用 tasklist-draft Prompt
/check -> 自动调用 check_doc_consistency Tool
/summary -> 自动选择某个 Resource 再总结这些听起来都合理,但它们已经开始接近工作流。
本版我没有这么做。
composer-context.ts(Composer 运行时消费层,负责把命令意图和资源引用转成受控上下文注入)只做了几条固定、很窄的逻辑:
ts
export function resolveComposerContextInvocation(request: ChatRequest): ComposerContextInvocation | null {
const command = request.composer?.command
const commandName = command?.name
const reference = getPrimaryComposerReference(request)
const userGoal = getLastUserMessageText(request)
if (commandName === 'summary' && isDocsResourceReference(reference)) {
return {
kind: 'docs-summary',
reference,
userGoal,
}
}
if (isDocsResourceReference(reference)) {
return {
command,
kind: 'docs-resource',
reference,
userGoal,
}
}
if (isLatestContextReference(reference)) {
return {
command,
kind: 'remote-resource',
reference,
userGoal,
}
}
if (command) {
return {
command,
kind: 'command-hint',
userGoal,
}
}
return null
}这段逻辑体现了本版的边界。不同输入形态在本版里的行为大概是这样:
| 输入形态 | 本版行为 |
|---|---|
/summary + @docs://... |
读取 docs resource,并使用 local-file-summary 生成文档摘要上下文 |
@docs://... |
读取 docs resource,作为本轮回答上下文 |
@project://latest-context |
读取远程 context,作为本轮回答上下文 |
/tasklist |
只作为任务清单意图提示,不自动调用远程 Prompt |
/check |
只作为一致性检查意图提示,不自动调用远程 Tool |
也就是说,/summary + @docs://... 是本版唯一的自动摘要闭环,但不是唯一的 Composer 消费路径。
这个差异很关键。
如果我把 /tasklist 和 /check 也做成立即执行,就会从 Composer V1 滑向命令执行系统(Command Execution System)。那不是本版目标。
Composer V1 不是工作流 V1。它只是先让用户输入变得结构化,让运行时在少量固定场景里安全消费这些结构。
9. 几个让输入框从"演示可用"变成"日常可用"的细节
这次看起来是在做输入框,但真正花时间的地方并不只是 UI。
Enter 和 Shift + Enter
聊天输入里,Enter 通常表示发送,Shift + Enter 表示换行。
但到了 Tiptap 里,Enter 同时可能被编辑器、Suggestion 菜单和输入法占用。最终实现里,菜单打开时 Enter 交给菜单选择项;菜单未打开、且不是组合输入状态时,Enter 才会触发发送。
中文输入法 composition
中文输入法期间,用户按 Enter 很可能只是确认候选词。
所以发送逻辑必须检查 event.isComposing 和 view.composing。如果不做这一步,中文用户很容易在打字过程中误发送。
这是一个非常小的判断,但它直接决定输入框能不能日常使用。
Markdown 字符保持纯文本
AI 输入框不是 Markdown 编辑器。
所以本版明确要求:
text
# 标题
- item
**bold**这些输入都保持普通文本,不自动变标题、列表或加粗。
前端回答仍然可以渲染 Markdown,但用户输入框不承担文章排版职责。
/ 和 @ 菜单不能撑开输入框
/ 和 @ 菜单用的是 Tiptap Suggestion + ReactRenderer + tippy。可以简单理解为:Tiptap 负责识别触发字符,React 负责渲染菜单,tippy 负责把菜单浮在光标附近。
它必须是浮层,而不是普通 DOM 流里的列表。不然菜单一打开,底部输入框高度就会被撑开,消息列表也会跟着抖动。
触发字符也要收窄
/ 不是任何时候都应该触发命令菜单。
比如路径、URL、普通文本里都可能出现 /。所以实现里会检查触发字符前面是否为空或空白,避免把普通路径误识别成命令。
@ 的规则也类似,只是为了适配中文输入,它允许前一个字符是中文字符。
这些细节不复杂,但如果没有它们,输入框会很"演示可用",但不太像日常可用。
10. 用户看不到的另一半:工具运行时也要回到能力驱动
上面这些都是用户能看到的输入层变化。
但本版本还有一个用户不太感知、对运行时却很重要的变化:Tool Runtime(工具运行时)不再从 allowedTools 绑定工具,而是从 capabilitySelectors 解析本轮可用工具。
旧方式里,Skill 上会有一组 allowedTools。它简单直接,但到了 v0.0.11 之后,项目已经有了 Capability Surface(能力表面,用来统一描述 Tool / Resource / Prompt)。如果继续保留 allowedTools,Skill 里一套工具声明、能力模型里又一套选择规则,后续会越来越难解释。
本版迁移后的链路是:
text
SkillDefinition.capabilitySelectors
-> 能力目录(Capability Catalog)
-> 解析 tool 类型能力
-> 生成本轮可用工具表
-> 映射成模型可见工具
-> 绑定给模型
-> 进入工具运行时对应实现放在 tool-binding.ts(能力驱动的工具绑定层,负责根据 Skill 选择范围解析本轮可用工具表)里。
关键点不是"换了一个字段名",而是把工具绑定收回到同一条能力链路里:
- 只有
capabilityType === 'tool'的能力能进入模型工具绑定。 - Resource / Prompt 不会被错误塞进工具运行时。
- 普通聊天没有命中 Skill 时,不默认暴露所有工具。
- 同一轮出现工具名冲突时直接失败收口,不自动改名。
这一层收口之后,模型绑定、工具调用校验、工具执行和前端展示都消费同一份"本轮可用工具表"。这对后续 Agent 很重要,因为 Agent 不应该面对一组散落在 Skill、工具注册表、MCP 适配器里的工具来源。
11. 远程 MCP Tool 标准化:不要让 check_doc_consistency 变成特殊分支
v0.0.11 已经接入了远程 MCP 服务:project-assistant-service(远程 MCP mock 服务,当前用于验证远程 Resource / Prompt / Tool 最小闭环)。
其中有一个远程 Tool:
text
check_doc_consistency它可以用来检查文档口径一致性。
如果只是为了跑通一个演示,最容易的做法是写死:
ts
if (toolName === 'check_doc_consistency') {
// special logic
}但这会让远程 Tool 永远停留在特殊分支里。
本版把它改成标准工具运行时可消费对象:
text
远程 MCP tools/list
-> RemoteMcpToolAdapter
-> ChatToolDefinition
-> 工具运行时
-> mcpClientManager.callTool(...)实现放在 remote-mcp-tool-adapter.ts(远程 MCP Tool 适配层,负责把 tools/list 返回的工具信息转成项目内部标准 ChatToolDefinition)里。
这部分的核心只有一个:check_doc_consistency 只是第一个样本,不应该成为写死分支。它应该通过 RemoteMcpToolAdapter 进入标准 Tool Runtime,再由 capabilitySelectors 决定本轮是否暴露给模型。
这样一来,远程 MCP Tool 和本地工具走同一条工具运行时,Resource / Prompt 也不会被错误混进工具绑定。这部分用户不一定直接感知,但它让输入层、能力层和执行层开始对齐。
12. 这版刻意没有做什么
这次升级很容易继续往下扩,但我刻意收住了。
本版不做:
- Agent
- 工作流
- 动态规划器
- RAG / chunking / indexing
- 完整资源选择器(Resource Picker)
- 多资源选择
- 文件树浏览
- Markdown 富文本编辑器
/tasklist自动调用远程 Prompt/check自动调用远程 Tool- 工具市场
- 多服务发现
- Prompt / Resource tool 化
这些不是不重要,而是不应该在 Composer V1 里一起做。
输入层刚开始结构化时,最重要的是边界稳定。如果这一版同时把输入、资源选择、命令执行、工具规划和 Agent 都揉在一起,短期看起来功能更多,长期反而很难继续演进。
所以我更愿意先把这三个问题讲清楚:
- 用户输入如何表达意图和上下文?
- 运行时何时消费这些结构化信息?
- Tool 绑定如何回到能力驱动?
13. 一个小插曲:正在思考的动效优化
除了 Composer 主线,这版还有一个很小的前端细节:正在思考 的文字动效。
这个点不是核心架构,但它会明显影响用户对"系统正在工作"的感知。一开始我是在 GPT 的界面里看到这个效果,第一反应是:这个"正在思考"的扫光反馈还挺酷。后面豆包也更新了类似特效,我就更想把这个细节也补到 AI Mind 里。
所以本版本除了输入层升级,我也顺手实现了一个类似的"正在思考"文字动效。它不是为了堆炫技,而是让等待过程不那么干,尤其是在深度思考开启、模型还没吐出正文时,界面能给用户一个更自然的状态反馈。
代码上我没有做复杂动画组件,只保留一个很小的 ThinkingText:
tsx
export function ThinkingText({ text = '正在思考', className }: ThinkingTextProps) {
return (
<span data-slot="thinking-text" className={cn(styles.thinkingText, className)}>
{text}
</span>
)
}真正的动效放在 CSS 里,用文字背景渐变做一个从右到左的扫光:
css
.thinkingText {
color: var(--thinking-text-base);
background-image: linear-gradient(
100deg,
var(--thinking-text-base) 0%,
var(--thinking-text-base) 42%,
var(--thinking-text-sheen) 50%,
var(--thinking-text-base) 58%,
var(--thinking-text-base) 100%
);
background-size: 260% 100%;
background-clip: text;
-webkit-text-fill-color: transparent;
animation: thinking-text-shimmer 1.8s ease-in-out infinite;
}这块我比较在意两点:
- 它只是"系统正在思考"的轻提示,不抢回答内容的注意力。
- 它支持
prefers-reduced-motion,用户关闭动画偏好时会退回普通文字。

这个小插曲和 Composer 的主线其实是同一件事的两面:输入层让用户更清楚地表达"我要什么",反馈层让用户更清楚地感知"系统正在做什么"。
14. 这版真正改变了什么
如果只看 UI,这版像是把 textarea 换成了 Tiptap 输入框。
但从运行时角度看,它改的是三条更底层的链路。
第一,输入层变了。
用户输入不再只是自然语言字符串,而是可以携带命令标签和资源标签。输入框开始表达"我要做什么"和"我要引用什么"。
第二,请求结构变了。
前后端不再把所有东西都塞进 text,而是把自然语言、任务意图、资源引用拆成 plainText / command / references。Tiptap JSON 留在前端,运行时只消费稳定的结构化请求。
第三,工具绑定变了。
工具运行时不再依赖旧的 allowedTools 双轨声明,而是通过 capabilitySelectors -> 能力目录 -> 本轮可用工具表 解析本轮可用工具。远程 MCP Tool 也进入了标准工具运行时。
对我来说,v0.0.12 的意义不是"做了一个更漂亮的输入框",而是让 AI 应用的输入层第一次具备了结构化语义。
它为下一阶段开始进入受控单 Agent 留下了更稳的前提:
text
textarea
-> 结构化请求
-> 能力驱动的运行时
-> 受控单 Agent Preview项目地址:
如果这个系列对大家有帮助,可以顺手点个 Star 支持一下。下一阶段我会开始推进受控单 Agent Preview:不是一上来做完全自由规划,而是在这版结构化输入、受控资源引用和能力驱动工具绑定的基础上,让 Agent 先在明确边界里跑起来。