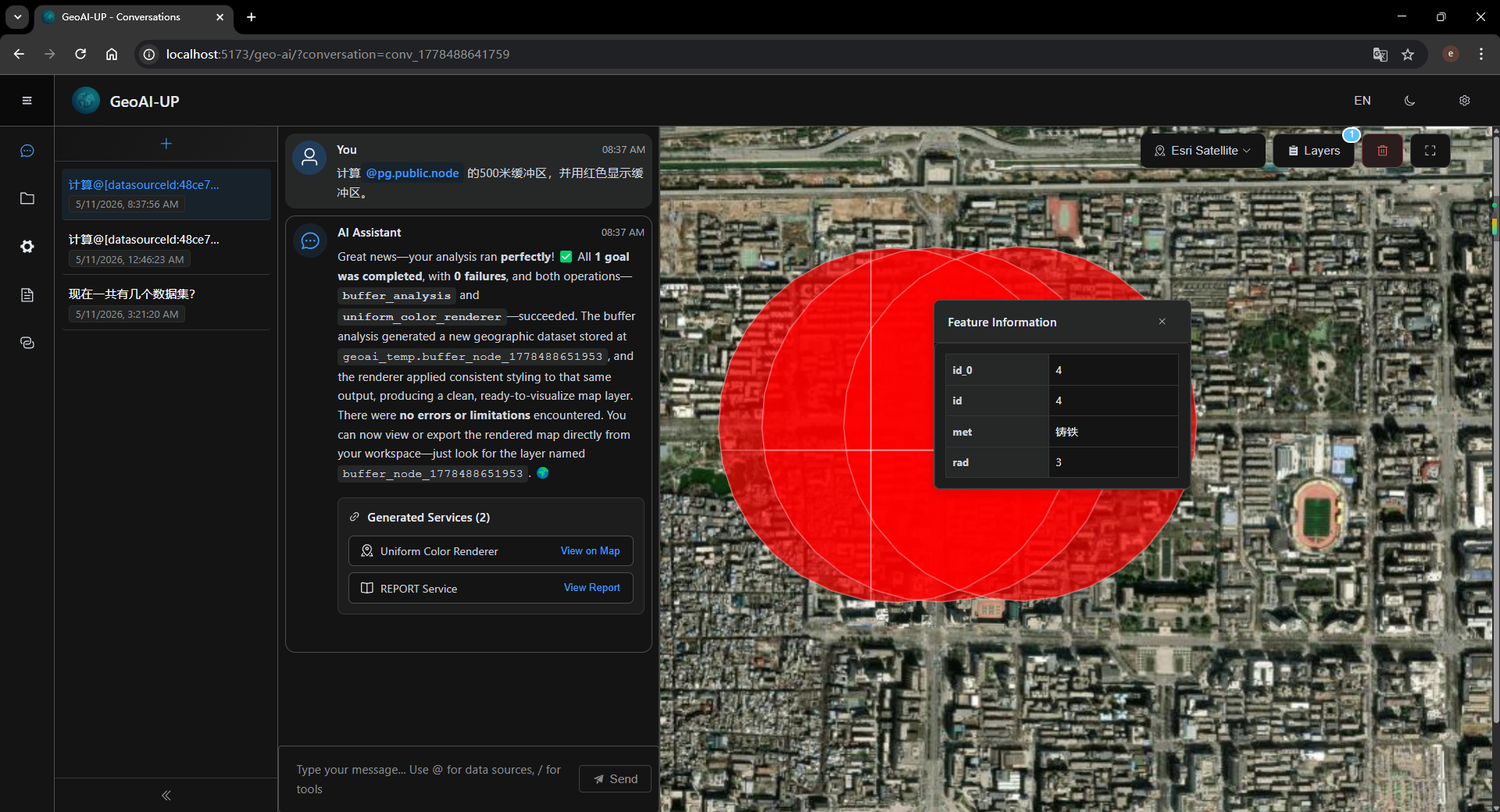
如何让GIS(地理信息系统)变得更智能、更易用?
传统的GIS软件(如ArcGIS、QGIS)虽然功能强大,但学习成本高,普通用户往往需要几个月才能掌握基本操作。而随着大语言模型(LLM)的发展,我开始思考:能否用自然语言来驱动GIS分析?经过一段时间的研究和实践,我启动了一个名为 GeoAI-UP 的开源项目,目标是实现真正的"说人话做空间分析"。
传统GIS的痛点
传统GIS工具存在几个明显痛点:
- 学习曲线陡峭:用户需要掌握大量专业术语和操作流程,如空间分析、坐标系统、投影变换等
- 操作复杂:完成一个简单的缓冲区分析需要多个步骤,从数据加载到参数设置再到结果可视化
- 门槛高:非专业人士很难上手,限制了GIS技术在更多场景的应用
- 重复劳动:相同类型的分析需要重复操作,缺乏智能化和自动化
AI Agent 驱动的新思路
我的想法是构建一个AI Agent,它能够:
- 理解用户的自然语言输入
- 自动识别分析目标和意图
- 规划执行步骤
- 调用相应的GIS工具
- 返回可视化结果
这不仅仅是简单的命令翻译,而是让AI具备"思考"能力,能够根据上下文和数据特点做出智能决策。
核心技术架构
1. 意图识别层(Goal Splitter)
这是整个系统的第一步,负责将用户输入拆解为可执行的分析目标。例如,当用户说"分析城市中心区域的人口密度分布"时,系统需要识别出:
- 数据源:人口数据、城市边界数据
- 分析类型:密度分析、空间统计
- 可视化需求:热力图、分级显示
在代码层面,GoalSplitterAgent 通过以下方式实现:
- 语义化数据源分析 :系统会先扫描已注册的数据源,提取其字段结构和业务含义。例如,一个名为
cities.shp的文件会被分析出包含name(城市名)、population(人口)等字段。 - 算子能力匹配:获取当前系统支持的所有空间算子(如缓冲区、叠加、统计等),并将它们的描述发送给 LLM。
- 结构化目标拆解:利用 Zod 库定义严格的输出 Schema,强制 LLM 返回标准化的 JSON 格式,确保后续程序能准确解析。
typescript
// GoalSplitterAgent.ts 中的核心逻辑
const goalSchema = z.object({
id: z.string().describe('Unique identifier for the goal'),
description: z.string().describe('Detailed description of what to accomplish in natural language'),
priority: z.number().min(1).max(10).describe('Priority level (1-10)')
});
// 调用 LLM 进行意图识别
const goals = await chain.invoke({
userInput: state.userInput,
availableExecutors: operatorsForLLM, // 传入所有可用算子的描述
availableDataSources: dataSourcesForLLM // 传入数据源的语义化描述
}) as AnalysisGoal[];这种设计避免了传统规则匹配的僵化,让 AI 能够根据数据的实际内容(比如有没有"人口"字段)来动态调整分析目标。
2. 任务规划层(Task Planner)
在识别出分析目标后,Task Planner 负责生成具体的执行计划。这部分是整个 AI Agent 的核心,它不仅要选择工具,还要处理复杂的依赖关系。
TaskPlannerAgent 的设计包含了几个关键环节:
- 基于能力的初步过滤:为了减少 LLM 的上下文压力,系统会先根据目标关键词(如"距离"、"范围")初步筛选出相关的 GIS 算子。
- 智能算子选择:LLM 会根据数据特征和目标需求,从候选列表中选出最合适的算子组合,并确定参数。
- 依赖图构建:分析步骤间的输入输出关系,构建有向无环图(DAG),为后续的并行执行做准备。
- 终端节点约束验证:确保可视化或报告生成的算子始终位于执行链的最后,防止逻辑错误。
typescript
// TaskPlannerAgent.ts 中的执行步骤定义
const stepSchema = z.object({
stepId: z.string(),
operatorId: z.string().describe('ID of the spatial operator to execute'),
parameters: z.record(z.any()).describe('Parameters to pass to the operator'),
dependsOn: z.array(z.string()).nullable().default([]).describe('Step IDs that must complete first')
});3. 统一的空间算子架构(SpatialOperator)
为了让 AI 能够更准确地理解和调用 GIS 功能,项目摒弃了传统的插件模式,转而采用基于 Zod Schema 的 SpatialOperator 抽象。每个算子都明确定义了输入输出规范:
typescript
// SpatialOperator.ts 基类定义
export abstract class SpatialOperator {
abstract readonly operatorId: string;
abstract readonly name: string;
abstract readonly description: string; // 供 LLM 理解的详细描述
abstract readonly inputSchema: z.ZodObject<any>; // 输入参数校验
abstract readonly outputSchema: z.ZodObject<any>; // 输出结果校验
abstract readonly returnType: 'spatial' | 'analytical' | 'textual'; // 返回值类型分类
// 统一的执行入口:校验 -> 执行 -> 再校验
async execute(params: unknown, context: OperatorContext): Promise<OperatorResult> {
const validatedParams = this.inputSchema.parse(params);
const result = await this.executeCore(validatedParams, context);
return { success: true, data: this.outputSchema.parse(result) };
}
}以 BufferOperator 为例,它不仅执行缓冲区计算,还会自动将结果持久化并注册为新的虚拟数据源,方便后续步骤引用:
typescript
// BufferOperator.ts 核心逻辑
protected async executeCore(params, context) {
// 1. 从数据库获取原始数据源信息
const dataSource = dataSourceRepo.getById(params.dataSourceId);
// 2. 调用底层数据访问门面执行空间运算
const result = await dataAccess.buffer(dataSource.type, dataSource.reference, params.distance);
// 3. 持久化结果并返回 NativeData 结构
const persistedResult = await resultPersistence.persistResult(result, 'buffer', dataSource);
return {
id: persistedResult.id,
type: persistedResult.type,
reference: persistedResult.reference,
metadata: persistedResult.metadata // 包含坐标系、样式等关键信息
};
}4. 编排引擎与状态管理(LangGraph)
整个工作流由 GeoAIGraph 驱动,它基于 LangGraph 构建了一个状态机。这个状态机确保了从意图识别到最终总结的每一步都能有序执行,并且支持中间结果的增量推送。
typescript
// GeoAIGraph.ts 工作流定义
const workflow = new StateGraph(GeoAIStateAnnotation)
.addNode('memoryLoader', loadConversationHistory) // 加载历史对话
.addNode('goalSplitter', splitGoals) // 意图识别
.addNode('taskPlanner', planTasks) // 任务规划
.addNode('pluginExecutor', executeWithParallel) // 并行/串行执行
.addNode('reportDecision', decideReport) // 决定是否生成报告
.addNode('summaryGenerator', generateSummary); // 生成自然语言总结
// 定义执行路径
workflow.addEdge(START, 'memoryLoader');
workflow.addEdge('goalSplitter', 'taskPlanner');
workflow.addEdge('taskPlanner', 'pluginExecutor');
// ...5. 动态 MVT 发布服务
对于大规模空间数据的可视化,项目采用了动态 MVT(Mapbox Vector Tiles)发布技术。MVTOnDemandPublisher 实现了按需生成矢量瓦片的能力:
- 单例缓存机制:使用单例模式管理全局瓦片索引,避免重复加载大数据集。
- LRU 淘汰策略:内置内存缓存,默认保留最近使用的 10,000 个瓦片,平衡性能与内存占用。
- 多源适配 :对 GeoJSON 使用
geojson-vt进行内存切片,对 PostGIS 则直接调用ST_AsMVT()数据库函数,实现极致的查询效率。
typescript
// MVTOnDemandPublisher.ts 缓存逻辑
async getTile(tilesetId: string, z: number, x: number, y: number): Promise<Buffer | null> {
const cacheKey = `${tilesetId}/${z}/${x}/${y}`;
// 1. 检查内存缓存
const cached = this.tileCache.get(cacheKey);
if (cached) return cached;
// 2. 按需生成(根据数据源类型路由)
let tileBuffer = metadata.sourceType === 'postgis'
? await this.getPostGISTile(...)
: this.getGeoJSONTile(...);
// 3. 写入缓存
if (tileBuffer) this.tileCache.set(cacheKey, tileBuffer);
return tileBuffer;
}自然语言对话的数据流时序
为了更直观地展示用户输入如何转化为空间分析结果,我们可以通过以下时序图来理解整个数据流转过程:
可视化服务 (MVT/WMS) 数据库/文件系统 大语言模型 (LLM) LangGraph 工作流 后端 API (Express) 前端 (Vue3) 用户 (User) 可视化服务 (MVT/WMS) 数据库/文件系统 大语言模型 (LLM) LangGraph 工作流 后端 API (Express) 前端 (Vue3) 用户 (User) 阶段 1: 意图识别与规划 阶段 2: 并行/串行执行 loop 遍历执行步骤 阶段 3: 动态发布与总结 输入自然语言指令 发送 SSE 请求 初始化状态 (State) 加载历史对话 & 数据源元数据 返回上下文信息 调用 GoalSplitter (拆解目标) 返回结构化目标列表 调用 TaskPlanner (生成执行计划) 返回算子序列及依赖关系 读取原始空间数据 返回 FeatureCollection / SQL 连接 执行空间算子 (如 Buffer, Overlay) 持久化中间结果 (NativeData) 返回新数据源 ID 注册 MVT/WMS 瓦片服务 返回服务 URL 调用 SummaryGenerator (生成总结) 返回自然语言分析报告 推送最终状态与增量结果 实时流式返回 Token & 图层信息 渲染地图并展示对话总结
这个流程的核心在于 LangGraph 的状态机管理 。它确保了即使面对复杂的跨步骤引用(例如:"先找出人口密集区,再计算这些区域的平均房价"),系统也能准确地通过 dataSourceId 在步骤间传递数据。
实际应用场景
理论上这个系统可以处理很多复杂的GIS分析任务:
场景1:城市规划分析
用户输入:"找出市中心5公里范围内人口超过10万的区域"
系统自动执行:
- 加载人口统计数据
- 确定市中心位置
- 执行缓冲区分析
- 过滤人口条件
- 生成可视化结果
场景2:商业选址
用户输入:"分析新店址周边的竞争情况和客流潜力"
系统自动:
- 加载商业设施数据
- 获取交通网络信息
- 执行可达性分析
- 生成综合评估报告
场景3:环境监测
用户输入:"监测河流污染扩散趋势"
系统自动:
- 加载水质监测点数据
- 分析时空变化模式
- 预测扩散路径
- 生成预警信息
技术挑战与解决方案
在开发过程中遇到不少技术挑战:
- 意图理解准确性:GIS领域术语多样,需要大量样本来训练LLM的理解能力
- 数据格式兼容性:不同来源的空间数据格式差异很大,需要统一的抽象层
- 性能优化:大规模空间数据处理需要高效的算法和缓存策略
- 错误恢复:当某个步骤失败时,需要智能的回退和重试机制
项目现状与未来展望
目前 GeoAI-UP 项目还在持续开发中,很多功能仍在完善阶段。虽然已经有了一些核心功能的实现,但离理想的"智能GIS助手"还有不小差距。
已完成的部分:
- 基础的意图识别和任务规划框架
- 多种数据源的支持
- 动态MVT瓦片发布
- 可视化界面
待完善的功能:
- 更丰富的空间分析算子
- 更智能的任务规划算法
- 更好的错误处理和用户反馈
- 更完善的插件生态
总结
用AI Agent重构传统GIS是一个很有挑战性的尝试。虽然目前还有很多技术难题需要解决,但我相信随着大语言模型能力的不断提升和GIS技术的持续发展,真正的"说人话做空间分析"一定会成为现实。GeoAI-UP 项目将持续探索这一方向,也希望有更多的开发者和GIS从业者一起参与进来。
注意:本文所述项目为持续开发中,文中提到的许多功能是愿景,实际实现可能还存在一些限制和不足。项目正在积极开发中,欢迎关注和贡献。
欢迎有兴趣的朋友一起加入GeoAI-UP!