本地部署大语言模型一直是开发者和技术爱好者关注的焦点。当你在 Apple Silicon Mac 上运行 27B 参数级别的模型时,内存瓶颈往往是最大的挑战。今天我们带来一期硬核实测:Mac Studio M4 Max(36GB 统一内存)搭配 omlx 推理框架和 dflash 内存优化技术,部署 Qwen3.6-27B-4bit(15.7GB)的完整性能报告。
测试的核心问题:dflash 这项基于内存分层的技术,究竟能带来多大的性能提升?在 36GB 内存限制下,是否能稳定运行 65536 tokens 的超长上下文?
测试环境
硬件配置
|------|--------------------------|
| 设备 | Mac Studio M4 Max |
| 统一内存 | 36 GB(32c GPU) |
| 芯片 | Apple Silicon M4 Max |
软件配置
|------|----------------------|
| 推理框架 | omlx |
| 内存优化 | dflash(对比测试项) |
| 测试模型 | Qwen3.6-27B-4bit |
| 模型大小 | 15.7 GB |
测试参数
生成长度:128 tokens(固定)
测试范围:pp1024 - pp65536(pp = Prompt Tokens)
批处理测试:2x / 4x / 8x batch,统一使用 pp1024 / tg128
核心性能对比
下面两张表展示了两种模式的完整测试数据。需要特别说明的是:不使用 dflash 的 pp65536 用例因内存溢出导致 omlx 服务停止,这是后续对比的重要背景。
无 dflash 模式
| 测试 | TTFT(ms) | TPOT | 生成速度 | 峰值内存 |
|---|---|---|---|---|
| pp1024/tg128 | 5,256 | 48.73 ms/tok | 20.7 tok/s | 15.88 GB |
| pp4096/tg128 | 20,370 | 50.16 ms/tok | 20.1 tok/s | 17.27 GB |
| pp8192/tg128 | 41,112 | 51.17 ms/tok | 19.7 tok/s | 18.30 GB |
| pp16384/tg128 | 84,726 | 54.79 ms/tok | 18.4 tok/s | 19.80 GB |
| pp32768/tg128 | 179,665 | 58.64 ms/tok | 17.2 tok/s | 22.80 GB |
| pp65536/tg128 | 内存溢出 - omlx 服务停止 |
有 dflash 模式
| 测试 | TTFT(ms) | TPOT | 生成速度 | 峰值内存 |
|---|---|---|---|---|
| pp1024/tg128 | 6,058 | 20.39 ms/tok | 49.4 tok/s | 19.45 GB |
| pp4096/tg128 | 20,632 | 12.11 ms/tok | 83.3 tok/s | 21.51 GB |
| pp8192/tg128 | 41,782 | 12.42 ms/tok | 81.1 tok/s | 22.74 GB |
| pp16384/tg128 | 88,563 | 12.91 ms/tok | 78.0 tok/s | 25.09 GB |
| pp32768/tg128 | 186,696 | 19.63 ms/tok | 51.3 tok/s | 29.48 GB |
| pp65536/tg128 | 428,234 | 21.70 ms/tok | 46.5 tok/s | 34.85 GB |
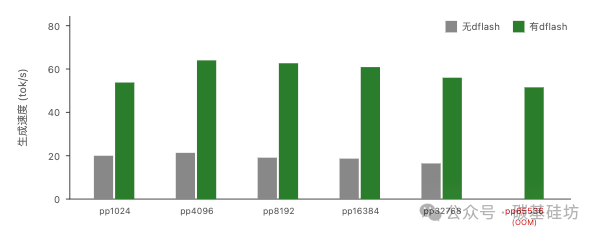
生成速度对比
深度分析
1. TPOT(逐字生成延迟)优化
在中等上下文长度(4096-16384 tokens)下,dflash 将 TPOT 从 50ms/tok 降低到 12ms/tok,提升幅度达到 2.4 倍。这意味着生成相同长度的回答,耗时减少超过一半,用户体验提升显著。
2. 生成速度全面提升
有 dflash 模式下,生成速度始终保持在 46-83 tok/s 区间,相比无 dflash 的 17-21 tok/s,平均提升约 3-4 倍。这一优势在长输出场景下尤为明显。
3. 超长上下文:从崩溃到正常运行
无 dflash 时,pp65536 直接导致内存溢出,omlx 服务崩溃。 启用 dflash 后,同样 65536 tokens 的输入不仅能正常运行,还能达到 46.5 tok/s 的生成速度,峰值内存控制在 34.85 GB(仍在 36GB 范围内)。这证明了 dflash 基于 SSD 扩展内存分层策略的有效性。
4. 吞吐量和延迟的权衡
在 pp4096 时达到最高吞吐量 190.5 tok/s(相比无 dflash 峰值 180.1 tok/s 提升 5.8%)。需要注意的是,dflash 在生成阶段更快,但预填充阶段(TTFT)略有增加,这是内存分层架构带来的正常权衡------热数据在内存,冷数据在 SSD,通过智能调度平衡性能和成本。
对话实测:翻译任务
我们使用同一个翻译任务来实测两种模式的实际表现。测试任务是将一段关于 oQ 量化系统的英文介绍翻译成中文,输入约 760 tokens,模型生成了约 5000 tokens 的详细翻译。
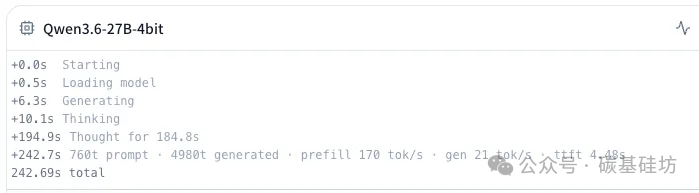
无 dflash 模式
|-------------|-------------|
| 输入长度 | 760 tokens |
| 生成数量 | 4980 tokens |
| Prefill 速度 | 170 tok/s |
| 生成速度 | 21 tok/s |
| 首字延迟 (TTFT) | 4.48s |
| 总耗时 | 242.69s |
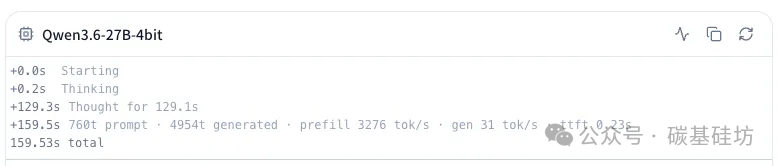
有 dflash 模式
|-------------|-------------|
| 输入长度 | 760 tokens |
| 生成数量 | 4954 tokens |
| Prefill 速度 | 3276 tok/s |
| 生成速度 | 31 tok/s |
| 首字延迟 (TTFT) | 0.23s |
| 总耗时 | 159.53s |
实测对比总结
-
生成速度提升: 21 tok/s → 31 tok/s,提升 47.6%
-
首字延迟降低: 4.48s → 0.23s,降低 94.9%
-
Prefill 速度提升: 170 tok/s → 3276 tok/s,提升 18.3 倍
-
总耗时降低: 242.69s → 159.53s,降低 34.3%
相关技术:oQ 量化系统
在测试中我们使用的 Qwen3.6-27B-4bit 模型采用了量化技术。oQ(optimized Quantization)是一种专为 Apple Silicon 设计的数据驱动混合精度量化系统,其核心特点包括:
-
通过校准测量每个层的实际量化敏感度,智能分配 bit
-
支持 oQ2-oQ8 多种量化级别
-
支持 VLM 视觉语言模型和 FP8 模型
-
支持 MiniMax M2.5、DeepSeek V3.2 等架构
量化让 27B 模型能够在 36GB 内存中运行,是本地部署大模型的关键技术之一。
连续批处理测试
批处理测试统一使用 pp1024 / tg128 配置,分别测试 2x、4x、8x 批处理规模。dflash 模式下各批处理规模均能稳定运行,有效避免了高并发下的内存压力问题。
结论
核心发现
-
dflash 将生成速度提升 3-4 倍 ,TPOT 优化达 2.4 倍
-
36GB 内存 + dflash 可以稳定运行 65536 tokens 超长上下文,纯内存方案无法做到
-
中等长度上下文(4K-16K)优化效果最显著
-
批处理场景下内存管理更稳定
使用建议
-
如果需要处理超长文档、多轮对话或 RAG 场景,强烈建议启用 dflash
-
日常短对话(4K 以内)两种模式都可用,但 dflash 体验更好
-
批量处理任务时 dflash 能提供更稳定的内存管理
-
dflash 会消耗少量 SSD 空间作为缓存,确保磁盘有足够余量