Java开发者转型AI工程化Week 3:从LangChain4j到AI Agent------让AI从"回答问题"进化到"完成任务"
作者: 一位正在转型的Java开发者
时间: 2026年4月
系列: Java开发者AI工程化转型记录(Week 3/3)
标签: LangChain4j, AI Agent, ReAct, Tool Calling, ChatMemory, 多工具编排
前言:Week 3的使命------从"调用模型"到"构建智能体"
Week 1让我建立了AI工程化的认知框架,跑通了Spring AI的基础集成。Week 2让我掌握了生产级能力------流式响应、Embedding/RAG、结构化输出、五层架构。而Week 3的核心命题是:如何让AI从被动回答问题的"工具",进化为主动完成任务的"智能体(Agent)" ?
这一周的探索围绕两个核心展开:LangChain4j (Java生态中最成熟的Agent框架)和AI Agent(大模型时代的全新编程范式)。如果说Spring AI是"如何优雅地调用模型",LangChain4j就是"如何让模型自主地行动"。
Day 1:LangChain4j初探------声明式编程的魅力
"接口即服务"的编程模型
LangChain4j最震撼我的设计是@AiService注解。在Spring AI中,调用AI需要手动构建PromptTemplate、管理ChatClient调用链:
ini
// Spring AI 方式(命令式)
PromptTemplate template = new PromptTemplate("请用{language}解释{concept}");
Prompt prompt = template.create(Map.of("language", "Java", "concept", "多态"));
String response = chatClient.prompt(prompt).call().content();而LangChain4j通过声明式编程将其简化为接口定义:
less
@AiService
public interface CodeAssistant {
@SystemMessage("你是一位资深Java架构师")
@UserMessage("请用{{language}}解释{{concept}}的概念")
String explainConcept(@V("language") String language,
@V("concept") String concept);
}
// 使用方式:像调用本地方法一样调用AI
String result = codeAssistant.explainConcept("Java", "多态");核心洞察 :这种"接口即服务"的设计,将AI调用从命令式编程 (告诉计算机怎么做)提升到了声明式编程(告诉计算机要什么结果)。这与Java 8 Stream API的演进方向完全一致------开发者关注"做什么",框架处理"怎么做"。
选型哲学:Spring AI vs LangChain4j
经过三天的对比实践,我形成了清晰的选型判断:
| 维度 | Spring AI | LangChain4j |
|---|---|---|
| 编程范式 | 命令式,细粒度控制 | 声明式,快速开发 |
| 核心优势 | 生态深度、Spring原生集成 | Agent能力、内置抽象丰富 |
| 适用场景 | 企业级项目、复杂Prompt工程 | 快速原型、对话系统、Agent应用 |
| 记忆管理 | 需手动实现 | ChatMemory内置 |
| 工具调用 | FunctionCallback |
@Tool注解更简洁 |
| RAG支持 | 基础向量存储 | ContentRetriever可插拔 |
我的结论 :两者并非互斥,而是互补 ------对话模块和Agent原型用LangChain4j(开发效率高),基础设施和监控治理用Spring AI(生态完善)。在同一项目中混用时,建议通过接口隔离明确边界,避免"双框架杂烩"。
Day 2:记忆与文档------Agent的"大脑"与"知识库"
ChatMemory:对话状态的语义管理
LangChain4j的ChatMemory提供了两种核心策略:
scss
// 策略1:滑动窗口(按消息数)
ChatMemory memory = MessageWindowChatMemory.builder()
.maxMessages(20) // 保留最近20条
.build();
// 策略2:Token窗口(按Token数,更精确)
ChatMemory memory = TokenWindowChatMemory.builder()
.maxTokens(1000, new OpenAiTokenizer()) // 保留最近1000 tokens
.build();关键设计 :通过ConcurrentHashMap<String, ChatMemory>实现多会话隔离,每个sessionId对应独立的记忆上下文。这是构建多用户聊天系统的核心基础设施。
深层感悟 :传统Web应用用Session/Redis管理用户状态,AI应用用ChatMemory管理对话状态------但后者更复杂,因为状态不仅是数据,更是 "上下文语义" 。MessageWindowChatMemory像Java的LinkedHashMap(LRU缓存),但缓存的不是对象,而是 "对话意图的连续性" 。
文档处理:RAG的预处理流水线
LangChain4j将文档处理标准化为四个阶段:

ini
// 加载PDF文档
Document document = FileSystemDocumentLoader.loadDocument("spring-ai-guide.pdf");
// 切分为TextSegment(每段500 tokens,重叠50 tokens)
DocumentSplitter splitter = DocumentSplitters.recursive(500, 50);
List<TextSegment> segments = splitter.split(document);
// 向量化并存储
EmbeddingStore<TextSegment> store = new InMemoryEmbeddingStore<>();
EmbeddingModel embeddingModel = new OpenAiEmbeddingModel();
for (TextSegment segment : segments) {
Embedding embedding = embeddingModel.embed(segment).content();
store.add(embedding, segment);
}这种"加载→分割→向量化→存储"的标准化流程,为后续RAG实现奠定了数据基础。重叠策略(50 tokens)尤其关键------它用冗余换质量,保留段落间的上下文连贯性。
Day 3:AI Agent基础概念------从"问答"到"行动"
Agent的本质:LLM + 工具 + 执行循环 + 记忆
Week 1和Week 2的AI应用都是被动式 的------用户问,AI答。Agent则是主动式 的:它具备自主决策能力,通过ReAct循环(Reasoning + Acting)持续与环境交互直到达成目标。
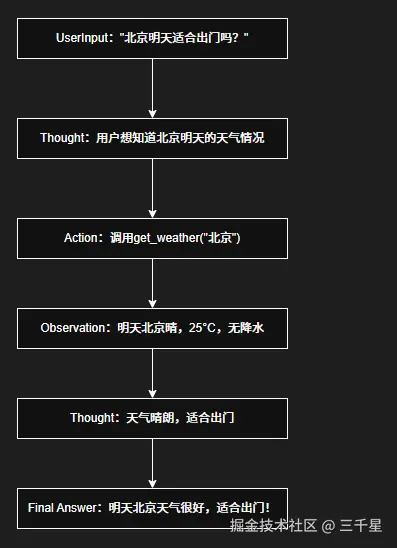
两种Agent模式:
- ReAct Agent(边想边做):适合简单交互,每步立即执行
- Plan-and-Execute Agent(先规划后执行):适合复杂任务分解,先生成完整计划再逐步执行
Tool Calling:Agent的"手脚"
@Tool注解让方法变为Agent可调用的工具:
less
public class WeatherTool {
@Tool("获取指定城市的实时天气信息")
public String getWeather(@P("城市名称,如北京、上海") String city) {
// 调用天气API
return weatherApi.getCurrent(city);
}
@Tool("发送邮件提醒")
public void sendEmail(@P("收件人邮箱") String to,
@P("邮件主题") String subject,
@P("邮件内容") String content) {
// 发送邮件
}
}AI会根据用户意图自主判断何时调用、调用哪个、传入什么参数。这种"感知→推理→行动→观察"的循环,让复杂任务自动分解为可执行的子任务序列。
工程挑战 :工具描述的清晰度直接决定Agent决策质量。@Tool("搜索")会让AI困惑,而@Tool("在数据库中执行SELECT查询,仅支持只读操作")能让AI confident地调用。AI时代的API设计需要"自解释性" ------不仅要让人看懂,更要让AI看懂。
Day 4:简单Agent开发------从单工具到多工具协作
AiServices.builder():Agent的装配工厂
LangChain4j通过链式配置将Agent的核心组件组装为可运行系统:
scss
CodeAssistant agent = AiServices.builder(CodeAssistant.class)
.chatLanguageModel(model) // 大脑:LLM
.chatMemory(memory) // 记忆:对话上下文
.tools(new WeatherTool(), // 手脚:可调用的工具
new CalculatorTool(),
new TimeTool())
.build();多工具协作的自动化
当用户问"北京天气如何?现在几点了?"时,Agent自动识别两个独立意图,分别调用get_weather和get_current_time,最后整合结果回复。这种意图识别→工具选择→结果整合的自动化,是Agent区别于简单Chat的核心能力。
调试洞察:通过日志观察Agent的Thought→Action→Observation循环,就像观察实习生的工作过程------你能看到它"思考"了什么、"尝试"了什么、"学到"了什么。这种可观测性对于调试Agent行为至关重要。
Day 5:多轮对话与记忆管理------让Agent"记得住"
Spring AI的双层记忆抽象
Week 5深入探索了Spring AI的记忆管理机制,其设计尤为精妙:
ChatMemory接口:负责策略逻辑(保留哪些消息、何时删除)ChatMemoryRepository接口:负责存储实现(内存/JDBC/Redis/向量库)
这种分离让滑动窗口 和摘要压缩两种策略可以复用同一套存储基础设施,也让存储介质切换无需改动策略代码。
混合策略:生产级记忆管理的最佳实践
纯滑动窗口简单高效但硬截断丢失早期信息,纯摘要压缩保留语义脉络但有额外LLM调用成本。推荐方案是 "三层记忆架构" :
| 层级 | 策略 | 容量 | 作用 |
|---|---|---|---|
| 近期记忆 | 滑动窗口(完整对话) | ~5K tokens | 保证当前对话流畅性 |
| 中期记忆 | 摘要压缩 | ~2K tokens | 保留远期语义脉络 |
| 长期记忆 | 关键锚定(结构化存储) | 无限制 | 用户身份、核心决策、偏好 |
这种分层可将Token消耗优化60-90% 。
Advisor模式:零侵入的记忆注入
MessageChatMemoryAdvisor实现了AOP式的记忆管理:
less
@RestController
public class ChatController {
@Autowired
private ChatClient chatClient;
@PostMapping("/chat")
public String chat(@RequestBody String message,
@RequestHeader("X-Conversation-Id") String sessionId) {
return chatClient.prompt()
.user(message)
.advisors(new MessageChatMemoryAdvisor(chatMemory, sessionId))
.call()
.content();
}
}对业务代码零侵入 :Controller只需设置会话ID,无需关心记忆管理的任何细节。这与Spring的声明式事务(@Transactional)理念一脉相承。
深层类比 :传统计算机用寄存器→L1/L2/L3缓存→内存→磁盘的分层架构平衡速度与容量,AI应用的记忆管理也需要类似的层次化设计------近期记忆像CPU缓存(速度快、容量小),中期记忆像内存(语义关联),长期记忆像磁盘(结构化持久)。摘要压缩的本质,是用计算(LLM调用)换空间(Token预算) 。
Day 6:复杂Agent场景------多工具编排与RAG融合
多工具编排的三层决策
复杂Agent需要AgentOrchestrator实现三层决策:
- 意图识别 (
analyzeIntent):通过关键词映射识别用户意图 - 工具选择 (
ToolMetadata匹配):通过工具描述和分类匹配可用工具 - 执行规划(依赖分析):决定串行/并行执行模式
scss
// 并行执行:独立任务同时处理
List<ToolResult> results = tools.stream()
.filter(tool -> tool.matches(intent))
.map(tool -> CompletableFuture.supplyAsync(() -> tool.execute(params)))
.map(CompletableFuture::join)
.collect(Collectors.toList());
// 串行执行:依赖任务按序处理
String resultA = toolA.execute(params);
String resultB = toolB.execute(resultA); // 依赖A的输出这种 "并行vs串行"决策与人类团队协作何其相似:独立任务并行(同时查天气和算费用),依赖任务串行(先检索再生成)。
Agent与RAG的融合:知识增强型自主系统
RAG为Agent提供结构化知识库访问能力,Agent为RAG提供意图理解和上下文组装能力:
less
public class RagQueryTool {
@Tool("从知识库中检索相关信息")
public String retrieve(@P("用户查询") String query) {
// 1. 判断是否需要检索
if (!needsRagRetrieval(query)) {
return "无需检索,直接回答";
}
// 2. 混合检索(向量+关键词+RRF融合)
List<Document> vectorResults = vectorStore.similaritySearch(query);
List<Document> keywordResults = fullTextSearch(query);
List<Document> fused = reciprocalRankFusion(vectorResults, keywordResults);
// 3. 重排序提升精度
List<Document> reranked = reranker.rerank(fused, query);
// 4. 组装上下文
return reranked.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n---\n"));
}
}混合检索策略 (向量+关键词+RRF融合+重排序)将检索精度从单一策略的70%提升到90%以上。
四级容错体系:生产级Agent的可靠性保障
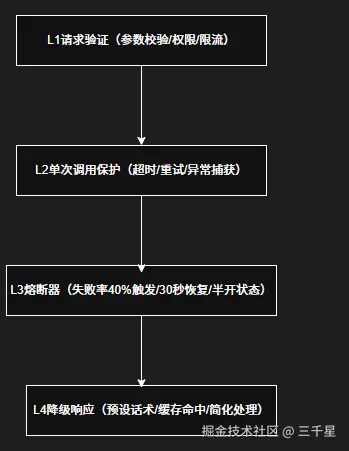
Resilience4j的CircuitBreaker+Retry+RateLimiter组合实现了这一体系,确保单点故障不会级联扩散。
Week 3复盘:三个核心突破
1. 从"框架使用者"到"框架选型者"
Week 1我只用Spring AI,Week 3我学会了根据场景选择工具:LangChain4j适合快速原型和Agent开发(声明式API效率高),Spring AI适合企业级基础设施(细粒度控制+生态完善)。框架选择是价值观的选择------追求简洁还是追求控制?没有标准答案,只有场景适配。
2. 从"调用API"到"设计自主系统"
Agent的ReAct循环让我理解了 "认知-行动"闭环 的价值。传统软件工程处理确定性逻辑(if-else),Agent工程处理概率性推理(LLM判断)。AgentOrchestrator本质上是一个"认知调度器",它在模拟人类项目经理的角色:分解任务、分配资源、监控进度、处理异常。
3. 从"无状态服务"到"语义状态管理"
ChatMemory的设计让我看到了AI应用状态管理的新形态。传统Session存储的是数据,AI记忆存储的是语义上下文。三层记忆架构(近期完整+中期摘要+长期锚定)不仅是技术方案,更是对人类记忆机制的工程化模拟。
待解决的深层问题
Week 3留下了几个值得持续探索的命题:
1. 多Agent协作的通信协议 当调度Agent→搜索Agent→汇总Agent协作时,如何设计Agent间通信契约(Inter-Agent Communication Contract)?如何避免上下文在多轮协作中无限膨胀?
2. Plan-and-Execute的动态重规划 复杂任务执行过程中环境可能变化(如天气突变),如何设计"计划重评估"节点?已执行步骤的副作用如何撤销或补偿?
3. 长期记忆的冲突检测 当长期记忆说"用户不吃辣",近期记忆说"用户点了麻辣火锅"时,如何设计"记忆融合器"进行冲突检测和一致性仲裁?