大家好,欢迎来到小撒的私房菜,我是小撒。
不知道你最近有没有跟我一样的感受:现在 AI 圈造新词的速度,简直快得离谱。比如,这篇文章我将来分享AI最近出圈的新词:Harness Engineering(本来早就该跟大家分享的,奈何一直没时间)。
我将以如下脉络展开,捋清这个新范式的来龙去脉:它因何诞生、要解决什么问题,为什么它会成为 2026 年 AI 工程赛道的核心竞争力。
本文脉络
一、开篇案例:一个真实踩坑故事,引出"为什么光靠 Prompt 不够" 二、三代演变:Prompt Engineering → Context Engineering → Harness Engineering 的演进逻辑 三、第一代 Prompt Engineering:什么是它、最佳实践、以及它的天花板在哪里 四、第二代 Context Engineering:信息管理的升级,以及它同样无法解决的问题 五、Harness Engineering 是什么:核心定义与三大组件(约束前馈 / 反馈回路 / 质量门控) 六、一个类比:让你秒懂 Harness 与纯 Prompt 的本质区别 七、为什么偏偏 2026 年火:模型能力 + 任务复杂度 + 工程成熟度三重因素 八、三件套上手指南:AGENTS.md / Hooks / 质量门控,普通开发者立刻能用 九、最佳实践:PRE 模式与实战经验 十、结尾:回到开头我朋友的问题
朋友的 AI 项目,差点出了大事
上个月,一个做技术负责人的朋友找我吃饭,整个人状态不太对。
他们公司年初引入了 AI Coding Agent,跑了两个月效果不错,老板也满意。然后有一天安全团队找上门来------扫描发现,最近一批 AI 生成的代码里,有接口没做权限校验,有地方在日志里打印了用户 ID,还有一处直接拼接了 SQL。三个问题,没有一个是运行报错的,测试也全过了,就这么悄悄进了代码库。
他第一反应是去改 Prompt,加了一大段安全要求。跑了一周,好了一些。再过一周,又出现类似问题。再改 Prompt......就这么反复,他说自己最近两个月光在调 Prompt,感觉在跟 AI 玩打地鼠。
我问他:你们有没有在 CI 里接安全检查?有没有一个规则文件让 Agent 每次启动都能读到?
他愣了一下:没有,我以为告诉它就行了。
这就是现在很多团队遇到的问题的缩影:Agent 能跑,但跑不稳。单次表现不错,整体不可靠。 问题不在模型,在模型外面那一层。而那一层,现在有个专有名词了:Harness。
三代概念的演变:我们一直在解决同一个问题
在说 Harness Engineering 之前,先用一分钟搞清楚它从哪里来。
AI 工程方法论走到今天,大概经历了三个阶段:

三代其实在解决同一个问题:如何让 AI 的输出稳定符合预期。
但要真正理解为什么需要 Harness Engineering,先得搞清楚前两代做了什么、又在哪里碰了壁。
第一代:Prompt Engineering------从「把话说清楚」开始
什么是 Prompt Engineering
如果你 2023 年用过 ChatGPT,大概经历过这个过程:
写了一句话,AI 给了个不太对的答案。重新措辞,加了几句说明,再试------好了一点,但还是差点意思。继续改,继续试。这个循环,就是最朴素的 Prompt Engineering。
严肃地说:Prompt Engineering 是通过精心设计指令,引导 AI 给出更符合预期输出的工程实践。作用范围是单次交互,核心逻辑是------你能给 AI 多少有效信息,它就能给你多少有效输出。
一个真正管用的 Prompt,通常由六个要素组成:

Prompt Engineering 的最佳实践
掌握几个技巧,输出质量能明显提升:
让 AI 先思考再回答(Chain of Thought)
不要直接问"这个 bug 怎么修",而是说"先分析所有可能的原因,再逐步排查,最后给出修复方案"。显式的推理步骤能有效减少 AI 跳步犯错。
用例子代替描述(Few-shot)
"我想要结构清晰的注释风格"------这句话对每个人意味着不同的东西。直接给两个示例,# 验证用户权限,失败抛出 403,AI 会比读描述更快对齐你的预期。举例子比描述有效 10 倍。
角色设定锁定知识框架
"你是一个有十年经验的 FastAPI 工程师,熟悉异步编程"------这不是客套,它引导 AI 调用特定领域的知识储备,而不是给出万金油式的通用回答。
约束写具体,不要只说"注意"
"注意安全"太模糊。"禁止在日志里打印用户 ID,所有数据库查询必须用参数化查询"才是具体的。约束越精确,AI 的遵守率越高。
这些技巧在 2023 年确实很有效,也催生了"Prompt 工程师"这个短暂的职业泡沫。但问题很快就来了。
Prompt Engineering 的局限性
局限一:跨会话遗忘。
你在第一个会话里调好了 Prompt,AI 表现不错。开了新会话,所有约定归零。你的规范、你的偏好、你的技术栈------AI 一概不知。要保持一致,你得每次手动复制粘贴那段 Prompt,不现实。
局限二:软约束,靠「理解」,不可靠。
即使在同一会话里,Prompt 也只是"说了一遍"。AI 理解了,大多数时候会遵守,但没有被强制执行。时间一长,指令在长上下文里被稀释,AI 开始犯回之前的错误。改 Prompt,暂时好了,另一个问题又冒出来------这就是"打地鼠"。
局限三:只管单次交互,撑不住长任务。
Prompt Engineering 的假设是"一次对话解决一个问题"。但现实中,AI Coding Agent 要跑几十步、修改十几个文件。一个 Prompt 撑不住这么长的任务链。

第二代:Context Engineering------从「给够信息」到「管好信息」
什么是 Context Engineering
2024 年,随着模型的上下文窗口从 4k、8k 扩展到 128k 甚至更长,工程师们开始换一个思路:
既然 AI 能看到的信息变多了,与其纠结"怎么说",不如认真想"让 AI 看到什么"。
Context Engineering 的核心:精心管理 AI 在生成回答时能访问的全部信息。
"上下文"不只是你打的那几行字。AI 在回答时能"看到"的全部内容,是一个复杂的组合:
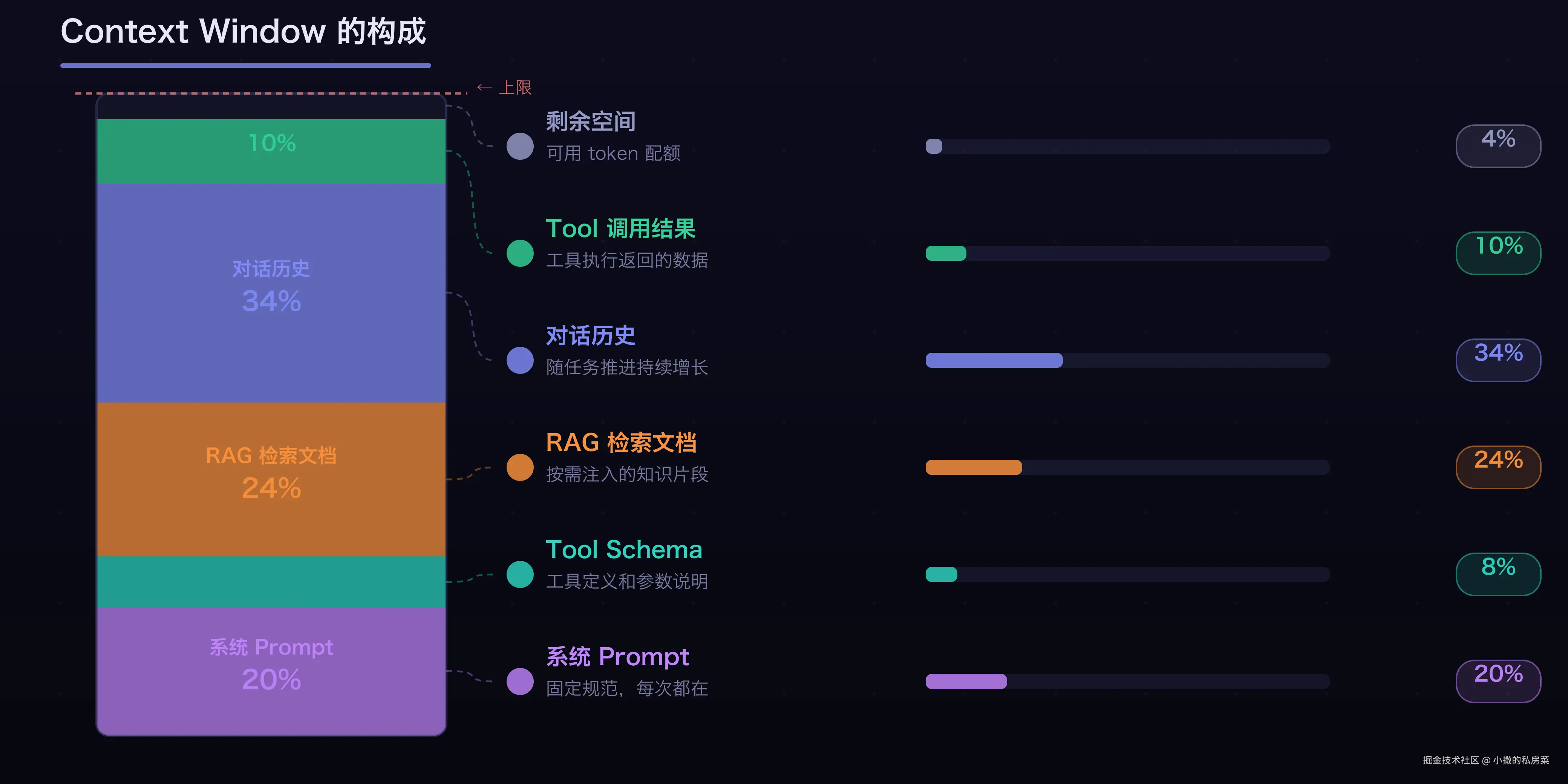
Context Engineering 的最佳实践
RAG(检索增强生成)------知识不放 Prompt 里,放数据库里
把产品文档、代码库、历史案例存进向量数据库,每次 AI 需要时检索最相关的片段注入上下文。这样既避免超出 token 限制,也能让 AI 基于实际资料作答,而不是凭"感觉"编造。
一个典型的使用场景:你让 AI 帮你修一个复杂模块,RAG 自动把相关的接口文档、历史 PR 的改动说明、相似 bug 的修复记录一并注入------AI 能做到的事就完全不同了。
对话历史的滚动压缩
不要把整段历史都保留。当对话超过一定长度,把早期内容压缩成摘要,只保留最近几轮的完整记录。既维持了连续性,又不让 token 费用失控。
结构化上下文,分层放置
系统级规范放最前面,当前任务描述放中间,具体参考资料放后面。AI 读上下文的注意力不是均匀分布的------开头和结尾被记住的概率远高于中间(这个现象有专门的论文研究,叫"Lost in the Middle")。
Context Engineering 把 AI 的有效工作范围从"单次对话"扩展到了"跨多轮的复杂任务",这是真正的进步。
Context Engineering 的局限性
但有一个问题,它解决不了:AI 看到了规则,不等于 AI 会执行规则。
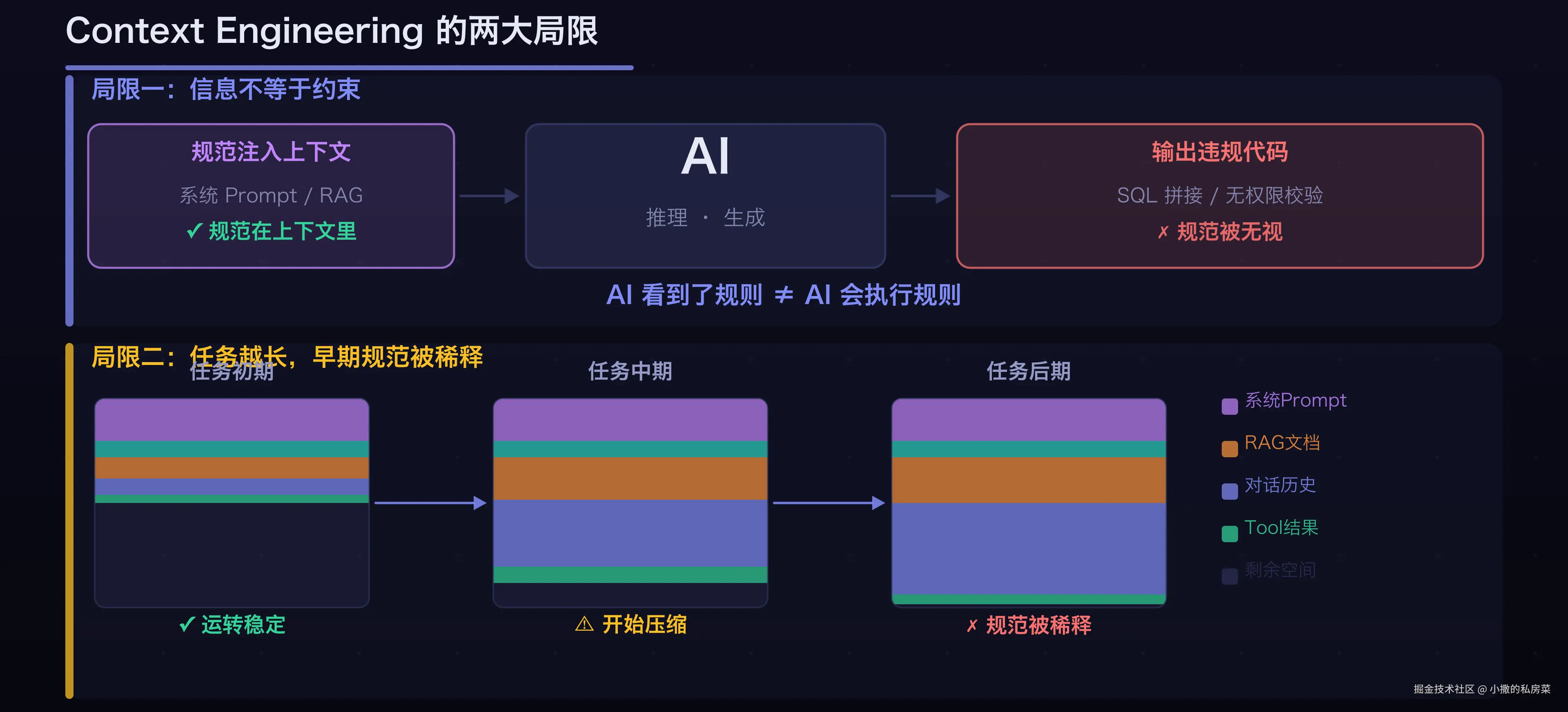
我朋友的团队把规范写进了系统 Prompt,把 RAG 接好了,上下文管理也做得不错。但那三个安全漏洞,是在上下文一切正常的情况下出现的------AI 看到了"不要拼接 SQL"的规范,但它就是生成了拼接 SQL 的代码。
Context Engineering 的本质是信息层面的工程 ------给 AI 更好的信息。但没有在行为层面加装护栏。
随着任务越来越长,还有另一个问题:早期注入的规范会被后来涌入的大量上下文"稀释",AI 在任务后期对早期约束的遵守程度会明显下降。这不是靠精心设计 Prompt 能解决的,它是上下文机制的结构性问题。
这就是为什么需要 Harness Engineering------不是再给 AI 更多信息,而是在行为层面加上结构性的硬约束。
Harness Engineering 到底是什么
2026 年 2 月,OpenAI 工程师 Ryan Lopopolo 发了一篇文章,描述他们的内部 Agent 基础设施。几天后,Terraform 和 Ghostty 的作者 Mitchell Hashimoto 把这篇文章的核心提炼成了一个公式:
Agent = Model + Harness
Model 是 AI 模型本身,负责推理和生成。 Harness 是包裹在模型外面的一切------规则文件、约束层、反馈回路、权限管控、Safety 护栏......
Harness Engineering 就是构建这个外层系统的工程实践。
Harness 的完整结构
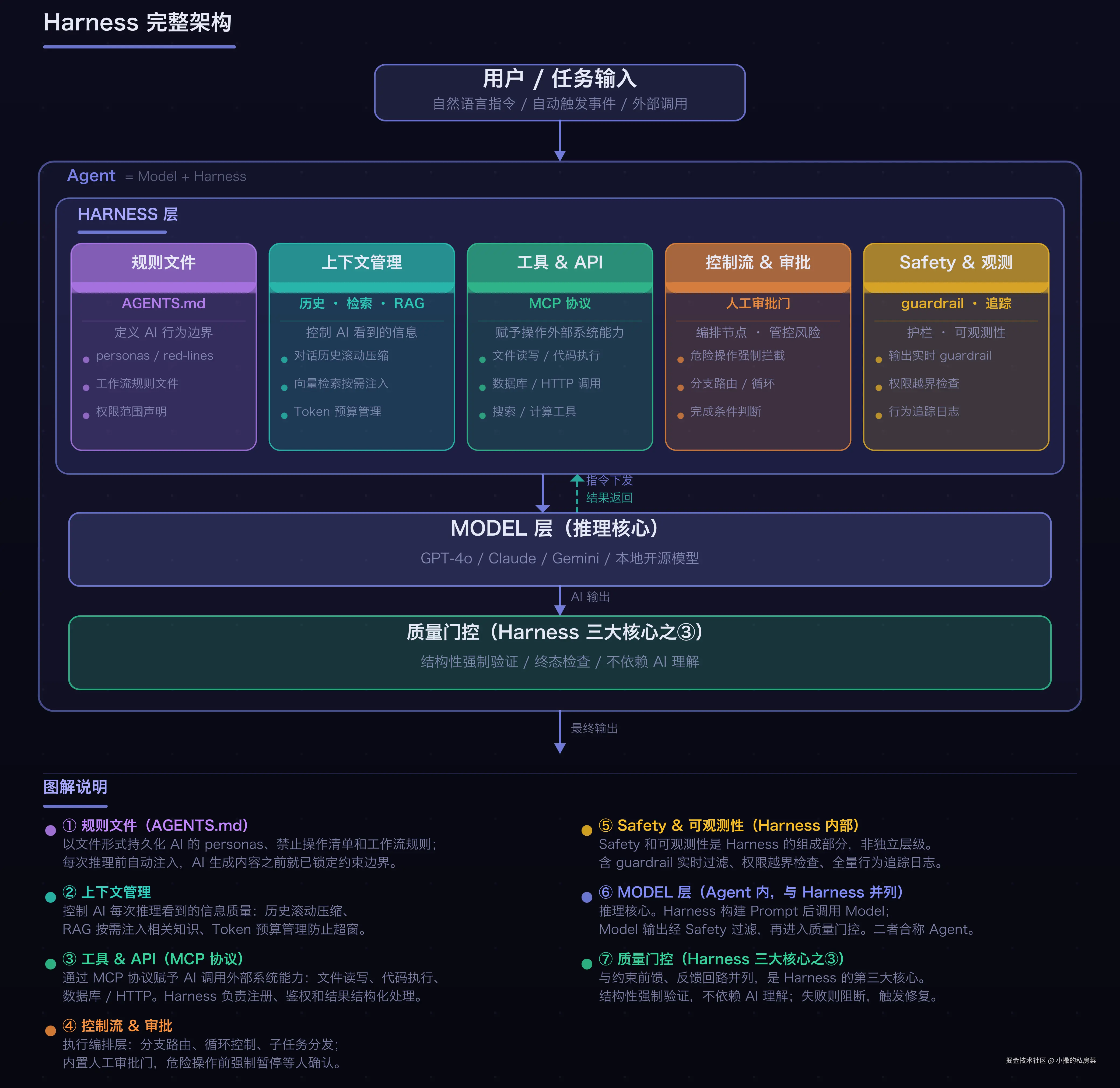
Harness 的作用不是让 AI 更聪明,而是让它更可靠。不管 AI 有没有"理解"规范,结构上的约束都会生效。这就是为什么我朋友反复调 Prompt 却始终不稳定的根本原因------他在靠 AI 的记忆,不是靠系统的结构。
Harness 的三个关键组件
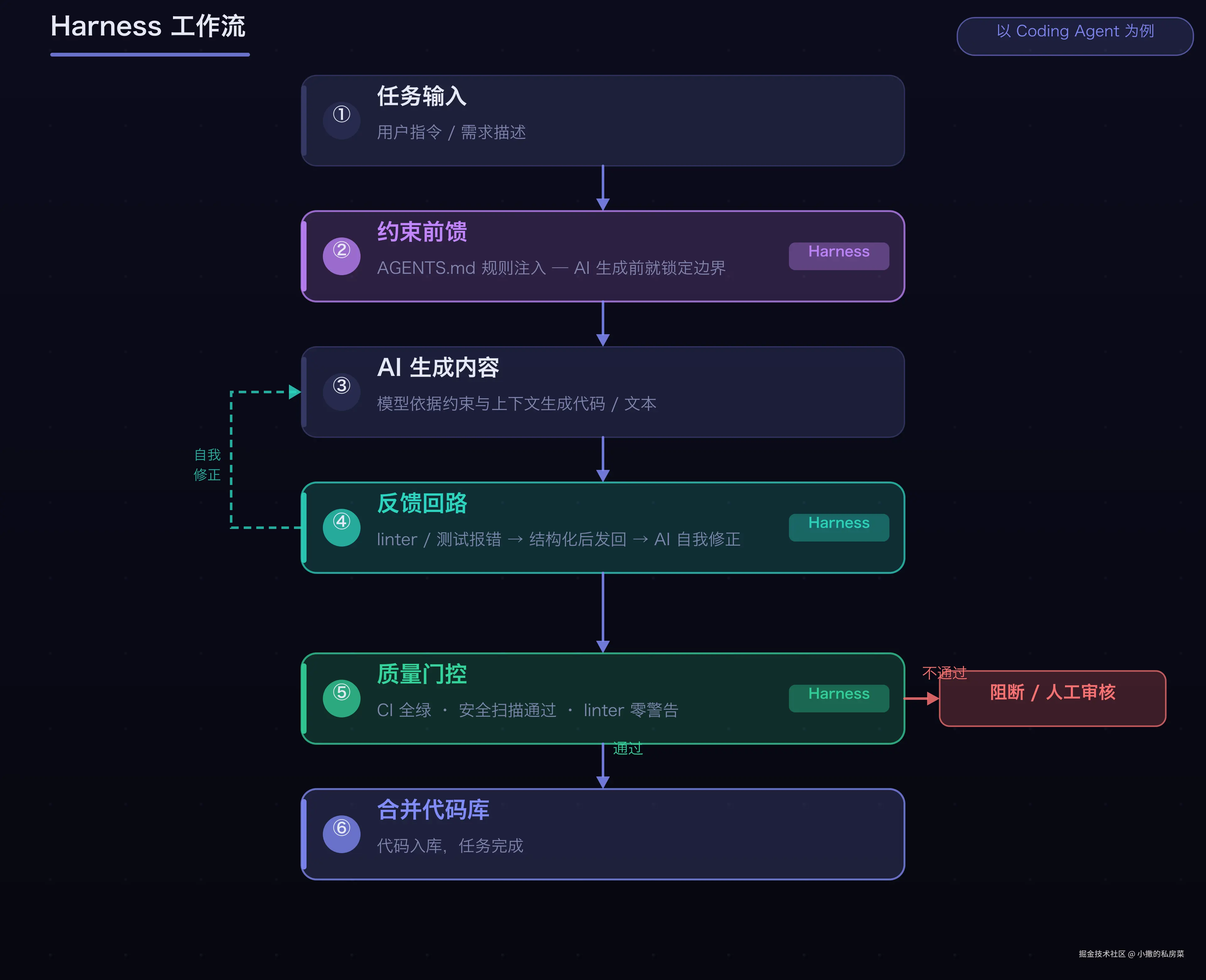
Harness 层里有很多东西,但核心可以归为三类(本文以 Coding Agent 为例,其他类型见下方对比图):
① 约束前馈(Constraint Harness) 在 AI 生成之前,缩小它的解空间。规则文件就是典型------让 AI 一开始就不进入错误区域,而不是生成完再来纠错。
② 反馈回路(Feedback Loop) AI 的输出不符合要求时,把错误信息结构化地反馈给它,让它能自我修正。把 linter 报错直接发给 AI 让它改,比你用自然语言描述"哪里有问题"要精准得多。
③ 质量门控(Quality Gate) 最终的输出要过一道硬性检查,不管 AI 说什么。CI 里的安全扫描就是典型的质量门控------不通过就是不通过,不依赖 AI 的"理解"。
其他类型的 Agent 同样适用
上述三大核心不只适用于 Coding Agent。无论是客服机器人、内容创作、研究分析,还是金融合规 Agent,都可以从同样三个维度构建 Harness------约束前馈限定行为边界,反馈回路驱动自我修正,质量门控强制终态验证。具体工具不同,结构相同:

一个让你秒懂的类比
招聘的时候,你会写一份 JD,告诉候选人岗位职责。这是 Prompt Engineering------你在精心设计你的"提问"。
入职之后,你给新员工提供背景资料、项目文档、现有代码库。这是 Context Engineering------你在给 AI 补充信息。
但是,一个人能不能在公司里稳定输出,真正依赖的是公司的制度:代码 review 流程、安全扫描、部署审批、团队规范......这套制度让他即使某天状态不好,也不会出大问题。这是 Harness Engineering。
Mitchell Hashimoto 的核心理念是:
每次 AI 犯了错,不是只修 Prompt,而是要把这个错误变成结构上不可能再发生的约束。
朋友的 AI 写了不安全的代码,他去改 Prompt,本质上是靠 AI 的"记忆"。而接入安全扫描到 CI,是靠系统的结构------这才是 Harness Engineering 的思路。
为什么偏偏在 2026 年火起来
这个概念其实不新鲜,工程师一直在做类似的事情,只是以前没有统一的名字。
2026 年突然有人开始认真对待,是因为几件事撞在了一起:
模型能力到了临界点。 GPT-4o、Claude、Gemini 都已经能真正跑长任务的 Coding Agent 了,不是玩具,是生产工具。Agent 真的在大规模跑,harness 的问题才真的浮出来。
大量团队踩坑之后开始反思。 统计数字很扎心:88% 的企业 AI Agent 项目上不了生产,65% 的失败原因不是模型不行,是 harness 层的问题------上下文管理混乱、没有约束机制、没有反馈回路。
有人给这件事起了名字。 Mitchell Hashimoto 那个公式 Agent = Model + Harness 一出来,大家发现这正是自己一直想说但说不清楚的东西,于是迅速传播开了。
普通开发者能立刻上手的三件套
概念讲完了。不需要大厂背景,个人开发者或小团队今天就能上手------三件事,做完立刻有效。
第一件:写一个 AGENTS.md
原理 :AI 工具(Claude Code、Cursor、Copilot)每次运行,会自动读项目根目录的 AGENTS.md 或 CLAUDE.md。把规范写进去,它每次都遵守------不需要你在每个 Prompt 里重复说。
这是约束前馈。
第一步,创建文件:在项目根目录执行以下命令(Windows 用户直接在编辑器里新建同名文件):
bash
touch AGENTS.md第二步,填入内容,把下面的模板复制进去,改成自己的技术栈:
markdown
# AGENTS.md
## 代码规范
- Python 文件遵循 PEP8,格式化用 black
- 函数命名 snake_case,类命名 PascalCase
- 所有公共函数必须有类型注解
## 安全红线(必须遵守,不得违反)
- 禁止在日志里打印用户 ID、手机号、密码等敏感信息
- 数据库查询必须用参数化查询,禁止字符串拼接 SQL
- 所有 API 接口必须有权限校验
## 架构约束
- 数据库操作只能写在 repository 层
- 不引入新的第三方依赖,除非在 PR 里说明原因
## 不确定时的处理方式
- 涉及安全实现:先列方案让我确认,不要直接写
- 需要改动超过 3 个文件:先制定计划,确认后再执行
## 技术栈
- 语言:Python 3.11 / FastAPI / PostgreSQL效果对比:
没有 AGENTS.md:
你说 → AI 写了没有权限校验的接口
你说加权限 → AI 加了,下次又忘
有了 AGENTS.md:
你说 → AI 每次都直接写带权限校验的版本
(因为每次启动都读到了规范,不靠记忆)第二件:Linter 接进 CI,做成硬门控
原理:Prompt 是软约束,CI 是硬约束。代码不通过检查,合不了主干,这是结构上的限制,和 AI 有没有"记住"规范无关。
CI 拦截本身是质量门控 ------输出端的硬检查,与 AI 是否理解规范无关;而把报错结构化地传回给 AI 驱动修正,是反馈回路。两个机制时序上相连,逻辑角色不同,本节两件事都会做到。
具体操作(Python 项目,5 分钟完成):
第一步,安装工具:
bash
pip install ruff bandit pre-commit第二步,在项目根目录新建 .pre-commit-config.yaml:
yaml
repos:
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.4.0
hooks:
- id: ruff # 代码规范检查
- id: ruff-format # 自动格式化
- repo: https://github.com/PyCQA/bandit
rev: 1.7.8
hooks:
- id: bandit # 安全漏洞扫描
args: ["-r", ".", "-ll"]第三步,激活:
bash
pre-commit install之后每次 git commit,检查自动运行。AI 写的代码有安全问题,commit 直接被拦住,错误信息打出来。
关键一步:把报错反馈给 AI(这就是反馈回路)
不要自己手动改,直接把报错复制给 AI:
sql
你:你刚才写的代码,pre-commit 检查报了这个:
bandit B608: Possible SQL injection via string-based query
在 user_repository.py 第 42 行
请修复。
AI:(读取错误信息,定位问题,改成参数化查询)比你说"那个 SQL 有安全问题"精准十倍。
如果你用的是 Claude Code,有一个补充说明
Claude Code 内置了 Hooks 机制 :在 ~/.claude/settings.json 里配置后,每次 AI 编辑文件,会自动触发 ruff、mypy 等检查,报错直接反馈给 AI 修正。这是会话内的轻量级反馈回路,不用额外安装 pre-commit。
但它替代不了 CI 质量门控,两者作用层不同:
| Claude Code Hooks | CI(pre-commit / GitHub Actions) | |
|---|---|---|
| 作用范围 | 当前会话内 | 所有人、所有提交 |
| 能否绕过 | 可关闭或忽略 | 不通过则无法合并 |
| 执行环境 | 本地,依赖本地配置 | 独立环境,结果可信 |
| 适合场景 | 个人项目、快速迭代 | 多人协作、生产部署 |
实用建议:个人项目先把 Claude Code Hooks 配好,作为日常反馈回路,够用;一旦涉及多人协作或代码进生产,CI 是必须做的硬门控,两者不互斥,可以同时用。
第三件:复杂任务强制走 Plan → Review → Execute
原理 :涉及多个文件、有架构影响的任务,先让 AI 出方案,你确认了再执行。把人工判断放在执行之前,而不是收拾残局的时候。本质上是人工审批门的体现------在高风险节点把约束前置,让问题在计划阶段暴露,而不是执行完再返工。
流程图:
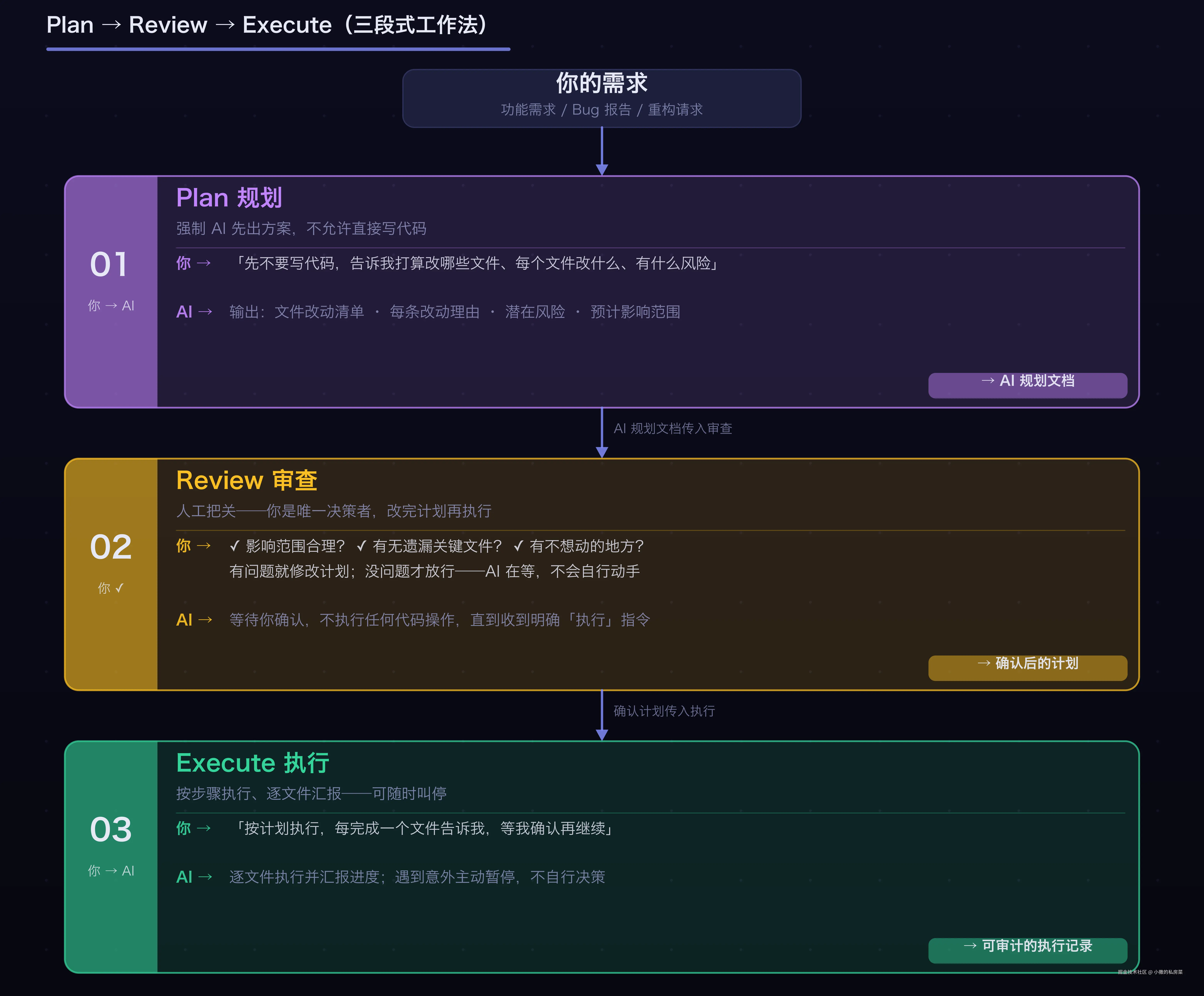
一个真实的对话示范:
python
❌ 不推荐:
你:"帮我把用户模块的同步改成异步"
→ AI 改了 8 个文件,你要一个个 review,
发现问题又要重来
✅ 推荐(PRE 模式):
你:"我想把用户模块的同步调用改成异步。
先不要改代码,告诉我需要改哪些文件、
每个文件大概改什么、有什么需要注意的。"
AI:需要修改 4 个文件:
1. user_service.py - get_user() 改为 async def
2. user_controller.py - 改为 async 路由处理器
3. tests/test_user.py - 改用 pytest-asyncio
⚠️ 注意:auth_service.py 也调用了 get_user(),
需要同步修改,否则会有兼容性问题
你:"好,auth_service.py 先不动,
你先改前 3 个,每改完一个告诉我。"这个模式表面上多了一步,实际上省时间:在计划阶段发现问题,比执行完再发现便宜得多。
最佳实践
理解了三件套,再给一些从实际踩坑中总结出来的原则:
原则一:规则写进文件,不要只存在 Prompt 里
AGENTS.md 是持久化的,Prompt 是一次性的。只要你更新了 AGENTS.md,Agent 下次启动就会遵守新规范------不需要你每次都重新说。
原则二:每次 AI 犯错,问自己"怎么让这个错误结构上不可能再发生"
这是 Mitchell Hashimoto 的原话。不要只想"这次怎么修",要想"下次怎么防"。能接进 CI 的就接进 CI,能写进规则文件的就写进规则文件,而不是靠 Prompt 里多加一句话。
原则三:硬约束优于软约束

越靠左越可靠,越靠右越容易失效。能用工具强制执行的,就不要靠 AI 的"理解"。
原则四:人工审批门放在正确的位置
不是每一步都需要你确认,那样效率太低。审批门适合放在:
- 不可逆的操作前(删数据、修改权限)
- 影响多个文件的重构前
- 不确定性高的技术决策前
其他的让 Agent 自己跑,不要变成 AI 的手动执行器。
原则五:把 Harness 当基础设施来建,不是当补丁
AGENTS.md 要随着项目演进定期更新,CI 检查要随着规范变化调整。这不是一次性的工作,是需要持续维护的基础设施------就像你不会写完 CI 配置就永远不管它一样。
回到开头那个朋友
后来我帮他做了两件事:在 AGENTS.md 里加了专门的安全规范章节,然后把 bandit 接入了他们的 CI,安全等级 MEDIUM 以上的问题直接卡住合并。
一周后他发消息,说安全团队那边没有新的问题了,他自己也不用再花时间盯着 AI 生成的代码逐行检查安全问题了。
他说了一句话我觉得挺准的:
"之前我以为管好 AI 就是把话说清楚,现在才明白,管好 AI 其实是把系统搭好。"
这大概就是 Prompt Engineering 和 Harness Engineering 最本质的区别。
模型会越来越强,但能让 Agent 在生产环境里稳定跑起来的,永远是那一层外壳------Harness。
如果你现在正在用 AI Coding Agent,不妨先从写一个 AGENTS.md 开始------10 分钟,立刻有效。
如果本教程对你有所帮助,留下一个免费的三连吧 ♥️!