导读
本文系统阐述了构建App稳定性分析Agent的必要性、核心设计与实现路径。传统的手动排查流程效率低下、严重依赖专家,而本方案通过将工具链自动化与AI智能分析相结合,构建了一个统一的Agent框架。该框架以可扩展的Tool(原子能力)和Workflow(场景策略)为核心,当前已成功落地闪退(Crash)自动分析场景,能够实现从崩溃日志解析、地址符号化、代码上下文提取到AI推理和修复建议的一站式处理。
更重要的是,通过引入向量数据库驱动的RAG知识库,系统能将处理经验沉淀下来,实现越用越智能的"数据飞轮"效应。
01 背景:为什么我们需要 App 稳定性分析 Agent
App 稳定性是用户体验的底线。一次闪退可能意味着一次用户流失,一个高频 crash 可能直接拖垮产品口碑。然而,在实际研发中,稳定性治理的排查效率远低于问题爆发的速度。
我们在日常的稳定性治理中持续面对这些痛点:
问题类型多 闪退(Crash)、ANR、卡顿、内存泄漏、OOM......每类问题的分析方法、工具链、经验知识都不同,缺少统一入口。
排查链路长 一次典型的 native crash 排查至少需要经历:日志收集 → 符号化 → 堆栈分析 → 代码定位 → 上下文还原 → 根因判断 → 修复验证。链路中任何一环出问题都会阻塞后续环节。
跨团队协作成本高 日志在平台侧、符号表在构建系统、源码在代码仓库、经验在专家脑中。证据分散,信息传递依赖人工对齐,耗时且容易遗漏。
关键瓶颈依赖专家经验 地址符号化工具配置繁琐,多线程归因需要深入理解线程模型,根因判断高度依赖对业务代码的熟悉程度。新人上手慢,老手产能被锁定在低级重复劳动上。
传统流程的典型链路如下图所示------节点越多、角色越多、信息传递越长,排查效率越低:
css
┌──────────────────────────────────────────────────────────────────────────┐
│ 传统 App 稳定性排查流程 │
├──────────────────────────────────────────────────────────────────────────┤
│ │
│ [监控平台] ──→ [值班同学] ──→ [手动下载日志] │
│ │ │
│ ▼ │
│ [手动配置符号化工具] │
│ addr2line / atos │
│ │ │
│ ▼ │
│ [肉眼分析堆栈帧] │
│ 区分系统帧 / 业务帧 │
│ │ │
│ ▼ │
│ [手动查找源代码] │
│ 对照行号逐文件翻阅 │
│ │ │
│ ▼ │
│ [凭经验推断根因] ←── 需要资深专家 │
│ │ │
│ ▼ │
│ [编写修复代码] │
│ │ │
│ ▼ │
│ [提交 & 验证] │
│ │
│ 平均耗时:数小时 ~ 数天 瓶颈:专家经验 + 手动操作 │
└──────────────────────────────────────────────────────────────────────────┘面对这些问题,我们的思路是:构建一个统一的 App 稳定性分析 Agent,用 AI + 工具链自动完成"证据采集 → 推理分析 → 结论输出"全流程,把专家经验沉淀为可复用的系统能力。
02 解决方案:构建统一的稳定性分析 Agent
我们提出的核心方案是:以统一的 Agent 作为稳定性分析入口,串联"证据采集、推理分析、结论输出"全流程。
核心设计思路
平台能力与场景能力解耦:先沉淀通用分析底座(日志解析、地址符号化、代码提取、LLM 推理),再按问题类型(Crash、ANR、卡顿等)扩展场景化分析策略。这样,底层工具链可复用,上层策略可替换。
多壳架构(Multi-Shell):Core 负责通用分析能力,CLI / Daemon / IDE Plugin 提供一致化入口与交互形态,满足不同使用场景。
总体架构
scss
┌─────────────────────────────────────────────────────────────────┐
│ 应用接入层(Entry Points) │
│ │
│ ┌─────────┐ ┌──────────────┐ ┌──────────┐ ┌────────┐ │
│ │ CLI │ │ HTTP Daemon │ │ Python │ │ VSCode │ │
│ │ 命令行 │ │ (SSE 流式) │ │ API │ │ Plugin │ │
│ └────┬────┘ └──────┬───────┘ └────┬─────┘ └───┬────┘ │
│ └────────────────┼────────────────┼───────────────┘ │
│ │ │ │
├─────────────────────────┼────────────────┼────────────────────────┤
│ ▼ ▼ │
│ ┌─────────────────────────────────┐ │
│ │ Tool + Workflow 编排引擎 │ │
│ │ (tool_system: Registry + │ │
│ │ ConfigDrivenExecutor) │ │
│ └───────────────┬─────────────────┘ │
│ │ │
├──────────────────────────────┼────────────────────────────────────┤
│ ▼ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────────┐ │
│ │ Crash Log │ │ Address │ │ Code Content │ │
│ │ Parser │ │ Symbolizer │ │ Provider │ │
│ │ (日志解析) │ │ (地址符号化) │ │ (代码上下文提取) │ │
│ └──────────────┘ └──────────────┘ └──────────────────┘ │
│ │ │
├──────────────────────────────┼────────────────────────────────────┤
│ ▼ │
│ ┌───────────────────────────────┐ │
│ │ AI Agent 推理层 │ │
│ │ ┌─────────┐ ┌────────────┐ │ │
│ │ │ RAG │ │ LLM │ │ │
│ │ │ Rules + │ │ Direct / │ │ │
│ │ │ Vectors │ │ LangChain /│ │ │
│ │ │ │ │ LangGraph │ │ │
│ │ └─────────┘ └────────────┘ │ │
│ └───────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘当前聚焦:CLI 优先
在多壳架构中,我们当前优先打磨 CLI(命令行) 作为核心入口,并参照了Claude的交互方式。CLI 的优势在于:
-
无环境依赖:不需要启动 IDE 或 Daemon 服务,一条命令即可触发完整分析链路。
-
脚本化集成:天然适合 CI/CD 流水线、自动化测试、批量分析等场景。
-
调试友好:每步产出独立的 JSON 文件,便于排查工具链各环节的中间状态。
-
交互优先体验 :对标 Claude CLI,可在终端向导内完成配置、分析与 AI 修复建议闭环;同时保留
--parse-only等参数模式用于自动化与高级场景。
Daemon 和 VSCode Plugin 均基于 CLI 的 Core 能力构建,CLI 稳定后上层自然受益。
为什么必须引入向量数据库:把分析能力做成"数据飞轮"
很多团队会把 AI 崩溃分析做成"一次性问答工具":日志进来,模型回答,任务结束。短期看可用,长期看会遇到同一个问题------每次都从零开始。
我们引入向量数据库(与规则库、元数据层配合)的核心目的,是把稳定性分析从"单次推理"升级为"持续进化系统",形成可复用的数据飞轮:
-
采集(Capture):每次分析沉淀结构化证据(崩溃特征、调用链片段、修复策略、采纳/拒绝反馈)。
-
检索(Retrieve):新问题到来时,先命中规则高置信路径,再做向量相似检索,快速复用历史经验。
-
反馈(Feedback):研发对建议的采用/拒绝会回写 Pattern 反馈,持续修正策略质量。
-
治理(Governance):通过衰减与 GC 机制清理低质量模式,保持知识库"新鲜且可信"。
-
收益(Compounding):同类问题越处理越快、建议命中率越高、新人上手门槛越低。
这也是 Stability Analysis Agent 与"只会对话的工具"本质差异:它不仅给答案,还会把答案背后的经验沉淀成组织资产。
03 首个场景:App 闪退(Crash)分析能力
当前 Agent 已具备完整的 App 闪退(Crash)自动分析能力,围绕该场景开发了专属的 Tool 和 Workflow。选择先做闪退场景的原因:
-
价值高:闪退是影响用户体验最直接的稳定性问题,排查优先级最高。
-
数据结构化:崩溃日志有明确的格式规范(Apple crash report、Android tombstone 等),便于自动化解析。
闪退分析链路
vbnet
输入 输出
│ │
┌────────────────────────▼───────────────────────────────▼────────────────┐
│ │
│ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────────┐ │
│ │ Step 1 │ │ Step 2 │ │ Step 3 │ │
│ │ crash_log_ │───▶│ add2line_ │───▶│ code_content_ │ │
│ │ parser │ │ resolver │ │ provider │ │
│ │ │ │ │ │ │ │
│ │ 输入: │ │ 输入: │ │ 输入: │ │
│ │ 原始崩溃日志 │ │ 解析结果JSON │ │ 符号化结果JSON │ │
│ │ │ │ + 符号文件目录 │ │ + 源码根目录 │ │
│ │ 输出: │ │ 输出: │ │ 输出: │ │
│ │ 结构化解析结果 │ │ 函数名+文件+行号 │ │ 崩溃函数体 │ │
│ │ (线程/帧/信号) │ │ 已符号化堆栈 │ │ + 调用链代码 │ │
│ │ │ │ │ │ + 崩溃图谱 │ │
│ └─────────────────┘ └─────────────────┘ └──────────┬──────────┘ │
│ │ │
│ ┌──────────────────────┘ │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────────────┐ │
│ │ Step 4: RAG 知识检索(可选) │ │
│ │ ┌──────────┐ ┌──────────────┐ ┌────────────────────────┐ │ │
│ │ │ Layer 1 │ │ Layer 2 │ │ Layer 3 │ │ │
│ │ │ Rules │ │ Patterns │ │ Metadata │ │ │
│ │ │ (SQLite) │ │ (ChromaDB) │ │ (SQLite) │ │ │
│ │ │ 精确匹配 │ │ 语义相似检索 │ │ 证据/策略/指导块 │ │ │
│ │ └──────────┘ └──────────────┘ └────────────────────────┘ │ │
│ └──────────────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────────────┐ │
│ │ Step 5: LLM 推理分析(可选) │ │
│ │ 综合所有上下文 → 生成根因分析 + 修复建议 │ │
│ │ 支持 Direct / LangChain / LangGraph 三种引擎 │ │
│ └──────────────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────────────┐ │
│ │ Step 6: 自动修复源码(可选) │ │
│ │ AI 生成修复方案 → 函数级精确替换 → 备份原始文件 │ │
│ │ Git 管理下可直接生成 Patch │ │
│ └──────────────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────┐ │
│ │ 最终产出 │ │
│ │ 修复后的源码文件 │ │
│ │ + 分析报告 (JSON/MD) │ │
│ │ + 原始源码备份 │ │
│ └──────────────────────────┘ │
│ │
└──────────────────────────────────────────────────────────────────────────┘链路编排代码
Workflow 是链路编排的核心单元。
以下是 BaseCrashAnalysisWorkflow.solve() 的关键实现:
python
# workflows/crash_analysis_workflow.py
class BaseCrashAnalysisWorkflow(BaseWorkflow):
def solve(self, problem: Dict[str, Any], context: WorkflowContext) -> Dict[str, Any]:
crash_log = problem.get("crash_log", "")
library_dir = problem.get("library_dir")
code_roots = problem.get("code_roots", [])
# Step 1: 解析崩溃日志
parse_result = context.execute_tool("crash_log_parser", {
"log_content": crash_log
})
# Step 2: 符号化地址(addr2line / atos)
resolved = context.execute_tool("add2line_resolver", {
"crash_json": json.dumps(parse_result),
"library_dir": library_dir
})
# Step 3: 提取代码上下文(崩溃函数体 + 调用链)
code_context = context.execute_tool("code_content_provider", {
"resolved_stack": json.dumps(resolved),
"code_roots": code_roots
})
# Step 4 (可选): RAG 知识库检索
rag_result = self._collect_memory_context(
problem, parse_result, resolved, code_context
)
# Step 5 (可选): LLM 推理分析
if context.llm:
prompt = self._build_analysis_prompt(
parse_result, resolved, code_context, rag_result
)
analysis = context.call_llm(prompt)
return {
"status": "success",
"parse_result": parse_result,
"resolved_stack": resolved,
"code_context": code_context,
"analysis": analysis
}每一步的输入输出都是结构化 JSON,便于追踪、调试和复用。
04 Demo:一次真实 App 闪退的自动分析过程
项目在根目录examples/crash_cases文件夹下内置了多组 Demo 崩溃样例,覆盖常见崩溃类型包括多线程,开箱即可运行:
-
demo_basic:11 种典型崩溃------空指针、悬空指针、数组越界、除零、错误类型转换、栈溢出、主动 abort、SIGBUS、SIGILL、double free、空函数指针调用。
-
demo_multithread:多线程数据竞争导致的崩溃场景。
每个 Demo 都包含完整的崩溃源码、预生成的崩溃日志和符号文件。下面以最经典的 空指针崩溃(NullPtr_SIGSEGV) 为例,展示从崩溃代码到自动修复的完整流程。
4.1 崩溃代码
这是 my_lib.cpp 中导致崩溃的函数------一个典型的空指针写操作:
c
// examples/crash_cases/demo_basic/code_dir/common/src/my_lib.cpp
void crash_nullptr() {
std::cout << "触发空指针崩溃..." << std::endl;
int* p = nullptr;
*p = 42; // 第 187 行:对空指针执行写操作 → SIGSEGV
}4.2 崩溃日志
程序崩溃后生成如下日志(已简化):
makefile
=== 崩溃报告 ===
时间: 2026-04-08_10-43-08
崩溃类型: NullPtr_SIGSEGV
崩溃地址: 0x100546ffc
=== 堆栈跟踪 ===
#0 0x100546ffc libmylib.dylib _Z13crash_nullptrv + 56
#1 0x10054665c libmylib.dylib _Z14signal_handleriP9__siginfoPv + 496
#2 0x18d1b2de4 libsystem_platform.dylib _sigtramp + 56
#3 0x100546ff0 libmylib.dylib _Z13crash_nullptrv + 44
#4 0x100519d30 crash_test main + 656人眼看到的是 _Z13crash_nullptrv(C++ mangled name)和原始地址 0x100546ffc------既不知道对应哪个源文件,也不知道具体哪一行。
4.3 运行分析
项目已在 GitHub 发布 Release 产物,提供预编译的 CLI 二进制文件 StabilityAnalyzer,无需 Python 环境即可运行。同时也已发布到 PyPI,Python 用户可通过 pip install 一键安装。下面以 PyPI 安装方式为例,演示如何在终端通过交互向导完成完整分析(详细安装方式见第 9 章):
Release 产物:
PyPI:
bash
# 安装
pip install stability-analysis-agent
# 一条命令进入交互引导(首屏主菜单;进入配置流程时自动检测并引导)
sa-agent具体如图:

Agent 自动完成日志解析、地址符号化(0x100546ffc → my_lib.cpp:187)、代码上下文提取、RAG 知识检索、LLM 推理分析,并直接将修复代码写回源文件。
4.4 标准大页(HugePage)修复结果
Agent 自动将 crash_nullptr() 修复为:
c
void crash_nullptr() {
std::cout << "触发空指针崩溃..." << std::endl;
int* p = nullptr;
if (p == nullptr) {
std::cerr << "检测到空指针,跳过写操作" << std::endl;
return;
}
*p = 42;
}修复前的源码自动备份到 cli_reports/<timestamp>/original_sources/ 目录。如果源码由 Git 管理,还可以直接生成 Patch:
bash
git diff # 查看 Agent 做了什么修改
git diff > fix_nullptr_crash.patch # 生成 Patch 文件从一段看不懂的崩溃日志,到源码自动修复,只需一条命令。
05 为什么不直接使用 AI 编程工具或开发一个 Skill,而是做 Agent
两个最常见的疑问:直接把日志粘贴给 AI 编程工具(Cursor / Copilot / Claude Code)不行吗? 以及 为 AI 编程工具开发一个专用 Skill 就够了,为什么要单独做 Agent?
对比一:Agent vs 直接使用 AI 编程工具
把崩溃日志粘贴给 AI 编程工具,本质上是将原始文本丢给 LLM 做单次推理。这在稳定性分析场景下存在根本性问题:
-
无法执行工具链操作 :日志中的原始地址(如
0x100546ffc)对 LLM 就是一串十六进制数字,它无法运行addr2line/atos符号化,也无法在你的代码仓库中定位源文件------给出的"分析"注定是缺乏精确定位的猜测。 -
日志噪音淹没关键信息:真实崩溃日志包含数十个线程、数百个堆栈帧,80%+ 是系统库帧。直接粘贴给 LLM,大量 token 浪费在无关帧上,有价值的 App 帧反而被淹没。
-
无多步编排能力:LLM 的单轮对话无法做到"先解析、再符号化、再提取代码、再推理"的多步骤逻辑,而 Agent 天然支持多轮推理与步骤编排。
┌────────────────────────────────┐ ┌─────────────────────────────────────┐ │ AI 编程工具 │ │ Stability Analysis Agent │ ├────────────────────────────────┤ ├─────────────────────────────────────┤ │ │ │ │ │ 崩溃日志(原文粘贴) │ │ 崩溃日志 │ │ │ │ │ │ │ │ ▼ │ │ ▼ │ │ ┌──────────┐ │ │ ┌──────────┐ │ │ │ LLM │ 一次调用 │ │ │ Parser │ 结构化解析 │ │ │ "猜" │ │ │ └────┬─────┘ │ │ └────┬─────┘ │ │ ▼ │ │ │ │ │ ┌──────────┐ │ │ ▼ │ │ │ addr2line│ 精确符号化 │ │ "可能是空指针" │ │ └────┬─────┘ │ │ 没有行号 │ │ ▼ │ │ 没有代码 │ │ ┌──────────┐ │ │ 没有证据链 │ │ │ Code Ctx │ 提取源码 │ │ 下次问同样问题 │ │ └────┬─────┘ │ │ 可能给不同答案 │ │ ▼ │ │ │ │ ┌──────────┐ │ │ │ │ │ LLM │ 带完整上下文推理 │ │ │ │ └────┬─────┘ │ │ │ │ ▼ │ │ │ │ 精准定位 + 修复代码 + 证据链 │ │ │ │ │ └────────────────────────────────┘ └─────────────────────────────────────┘
对比二:Agent vs 为 AI 编程工具开发一个 Skill
AI 编程工具(如 Claude Code)支持开发 Skill------本质是一组预设的 prompt 模板和指令集 ,指导 LLM 按特定流程调用工具完成任务。理论上可以写一个"崩溃分析 Skill",让 LLM 依次调用 addr2line、读取源码、输出分析结论。但这种方式的局限在于:
-
无持久化知识积累:Skill 每次调用都是一个新会话,不知道你的团队上周刚修过同样的空指针模式,也不知道某个模块历史上的高频崩溃点。Agent 通过 RAG 知识库(规则表 + 向量数据库)跨会话持续积累分析经验,同类问题越分析越准。
-
工具链不可控:Skill 依赖 LLM 自行决定如何调用工具,prompt 稍有变化就可能跳过关键步骤(如符号化)或输出格式不一致。Agent 有确定性的工具链流程,每步产出结构化 JSON,不依赖 LLM "理解"该怎么调工具。
-
无结构化中间产物:Skill 的执行过程是 LLM 对话流,中间状态难以持久化和复用。Agent 的每步产出(解析结果、符号化结果、代码上下文)都是独立的 JSON 文件,可追溯、可调试、可供下游消费。
-
扩展依赖 prompt 工程:Skill 新增能力需要精心调整 prompt 并祈祷 LLM 正确执行。Agent 的 Tool + Workflow 注册机制让新能力即插即用,行为确定性高。
-
缺少飞轮治理机制:Skill 很难原生支持"反馈回写→模式淘汰→质量提升"的闭环。Agent 在向量库层提供反馈记录、置信衰减与治理机制,支持知识持续净化。
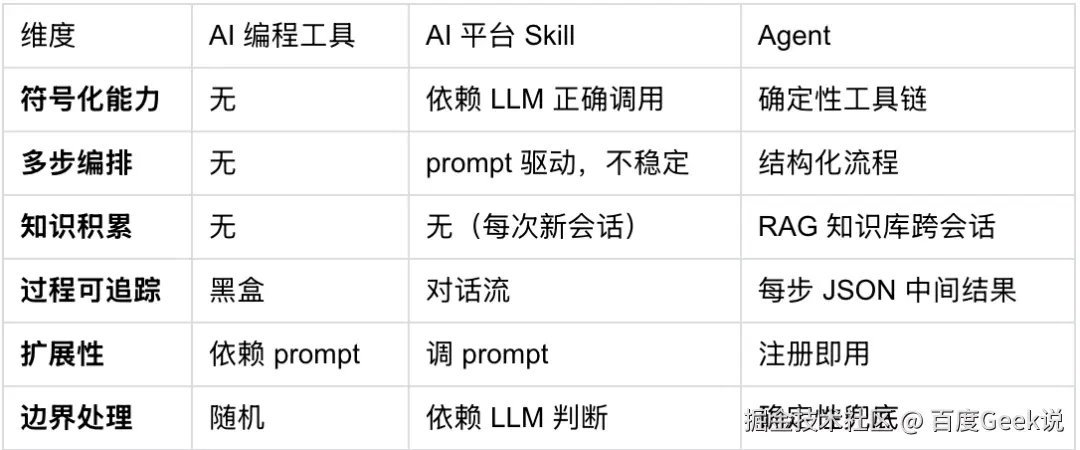
简单说:AI 编程工具缺少工具链和上下文,AI 平台 Skill 缺少知识积累和确定性保障------Agent 同时具备两者的优势。
进一步说:Agent 的价值不只在"这一次分析得准",更在"下一次会更快更准"。这正是向量数据库驱动的数据飞轮意义。
06 可扩展架构:如何通过 Tool + Workflow 覆盖更多稳定性问题
整个系统的可扩展性建立在 Tool + Workflow 分层组合 的架构设计上。
Tool 与 Workflow 的分工
-
Tool (原子能力):负责证据采集与处理,每个 Tool 实现
BaseTool接口,定义execute(input_data) -> output_data。当前已实现:crash_log_parser(日志解析)、add2line_resolver(地址符号化)、code_content_provider(代码上下文提取)。 -
Workflow (场景策略):面向具体问题类型,编排一组 Tool 并添加领域逻辑,实现
BaseWorkflow接口,定义solve(problem, context) -> result。当前继承体系:BaseCrashAnalysisWorkflow→GenericCrashAnalyzeWorkflow/iOSCrashAnalyzeWorkflow/AndroidCrashAnalyzeWorkflow。
底层 Tool 可复用(如 crash_log_parser 同时服务于 Crash 和 ANR),上层 Workflow 可替换(不同问题类型独立实现分析策略)。
注册系统与扩展
注册中心支持三级优先级(BUILTIN=100 < EXTENSION=200 < CUSTOM=300),高优先级自动覆盖低优先级。新增一个 Tool 只需三步:
ruby
# 1. 实现 BaseTool
class MyCustomTool(BaseTool):
def definition(self) -> ToolDefinition:
return ToolDefinition(name="my_tool", description="...", ...)
def execute(self, input_data):
return {"result": "..."}
# 2. 注册(高优先级可覆盖内置实现)
registry.register("my_tool", MyCustomTool(), priority=Priority.EXTENSION)
# 3. 在 Workflow 中使用
result = context.execute_tool("my_tool", {"query": "..."})还可以通过 CLI 参数 --plugin-module 动态加载第三方扩展模块,无需修改开源代码(高级 / 其它使用方式):
css
sa-agent --crash-log <log> --library-dir <lib> --code-root <code> \
--plugin-module my_company.custom_parser插件模块只需实现 register_all(registry) 接口即可。
07 下一步路线图:从闪退走向 ANR / 卡顿 / 内存治理
闪退(Crash)分析链路是第一个成熟落地的场景,但 App 稳定性远不止闪退。我们的目标是在统一框架下,逐步覆盖所有高频稳定性问题。
演进路线
bash
┌──────────────────────────────────────────────────────────────────────────┐
│ 演进路线图 │
├──────────────────────────────────────────────────────────────────────────┤
│ │
│ Phase 1(已完成) │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ ★ App 闪退(Crash)自动分析 │ │
│ │ - 多平台日志解析(iOS/Android/macOS/Linux) │ │
│ │ - 地址符号化(addr2line / atos) │ │
│ │ - 代码上下文提取 + 崩溃图谱 │ │
│ │ - RAG 知识库 + LLM 推理 │ │
│ │ - CLI + Daemon + Python API │ │
│ └───────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ Phase 2(规划中) │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ → ANR 分析 │ │
│ │ - 新增 ANR 日志解析 Tool │ │
│ │ - 新增 ANR 分析 Workflow(主线程阻塞归因) │ │
│ │ - 复用:addr2line + code_content_provider + RAG │ │
│ ├───────────────────────────────────────────────────────┤ │
│ │ → 卡顿分析 │ │
│ │ - 新增 Trace 解析 Tool │ │
│ │ - 新增卡顿分析 Workflow(慢函数 / 锁竞争归因) │ │
│ │ - 复用:code_content_provider + RAG │ │
│ └───────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ Phase 3(远期) │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ → 内存治理(OOM / 内存泄漏) │ │
│ │ - 新增 Memory Profiler Tool │ │
│ │ - 新增内存分析 Workflow │ │
│ ├───────────────────────────────────────────────────────┤ │
│ │ → 多维度聚合分析 │ │
│ │ - 跨问题类型关联分析 │ │
│ │ - 智能分派(自动判断问题类型 → 自动选择 Workflow) │ │
│ └───────────────────────────────────────────────────────┘ │
│ │
└──────────────────────────────────────────────────────────────────────────┘实现方式
沿用统一的 Tool + Workflow 框架:
-
新场景 = 新 Tool + 新 Workflow:每个问题类型增量补齐专属的 Tool(证据采集)和 Workflow(分析策略)。
-
底座复用:地址符号化、代码提取、RAG 知识库、LLM 推理引擎等通用能力无需重复开发。
-
配置驱动 :通过
SystemConfig启用/禁用 Tool 和 Workflow,灵活组合。
在工程收益上,这意味着:新场景不是"从零重做一套分析系统",而是在同一数据飞轮上新增证据类型与策略节点,复用已沉淀的模式与反馈体系。
08 工程化落地中的挑战与踩坑经验
从"Demo 能跑通"到"工程化可落地"之间,有大量工程细节。
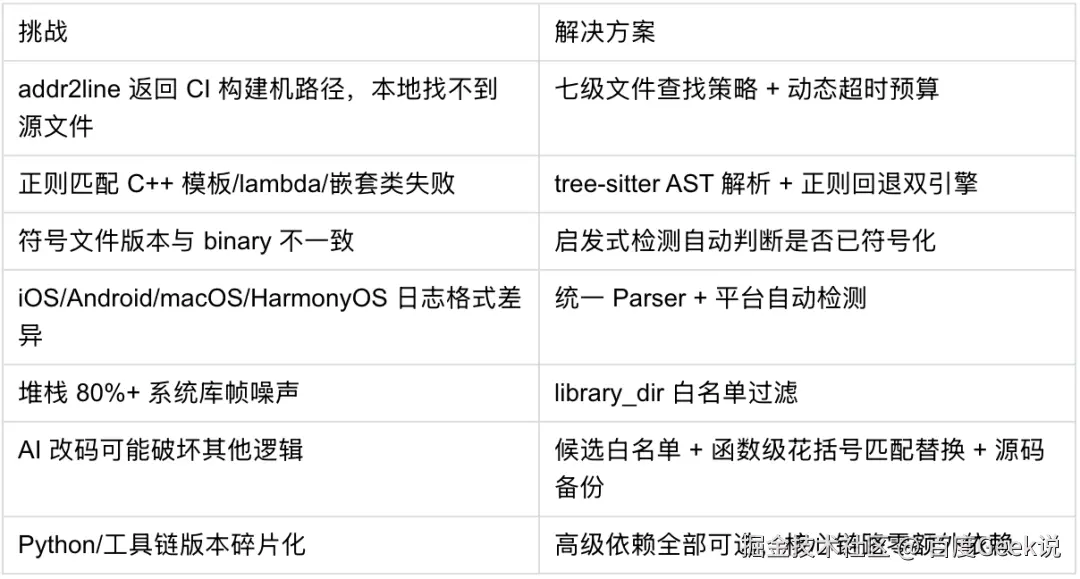
重点展开两个最有工程难度的挑战。
源码文件的智能定位
addr2line 返回的是编译时路径(CI 构建机绝对路径),与本地目录结构完全不同。我们设计了七级递进查找策略:直接命中 → 工程根目录名锚点(CI 路径中含与 code-root 同名目录段,取后缀拼接)→ 尾部路径逐级拼接(从文件名向上逐级尝试,O(级数)次 stat)→ 父目录+文件名 glob 匹配 → 预建索引查找 → 受限 Fallback(仅 src/lib/common 等常见子目录浅层搜索)。多候选时通过路径相似度评分选择最佳结果,全局引入动态超时预算确保大仓库不卡死。
函数体精确提取
C++ 语法复杂(模板、lambda、嵌套类、跨行签名),我们采用 tree-sitter AST 为主、正则为回退 的双引擎。tree-sitter 将源码解析为 AST,精准定位 function_definition 节点,仅在签名区匹配函数名(避免误识别),选最小 span(最内层函数);还用于 lambda 检测和调用链验证。tree-sitter 不可用时自动切换到正则引擎(支持多行签名合并、花括号深度匹配)。通过 --code-parser-backend tree-sitter|regex 切换。
所有高级依赖(tree-sitter、RAG、LangGraph)均为可选导入,缺失时自动回退。pip install stability-analysis-agent 一键安装即可运行核心工具链;安装后直接运行 sa-agent 进入交互主菜单,可按引导完成大模型与符号化工具配置(首屏不做阻塞式环境扫描,进入配置流程时会自动检测并提示)。任何可选依赖缺失都不会阻断核心链路。 自 v1.2.2 起,还可通过 cli.api 在 Python 中嵌入同一套能力(见第 9 章),便于与内部平台或定制 CLI 集成。
09 结语:Stability Analysis Agent 已开源,欢迎共建
Stability Analysis Agent 是由百度地图开发平台 推出并已开源的 App 稳定性分析 Agent。项目已在团队内部推广使用,持续沉淀历史崩溃模式和排查经验,帮助缩短 Crash 排查时间、降低新人上手门槛。
我们更看重的是"长期复利":通过向量数据库驱动的数据飞轮,把一次次线上故障处置转化为可检索、可治理、可继承的稳定性知识资产,让系统越用越聪明、团队越用越省力。
项目定位是 App 稳定性分析的统一 Agent 框架------闪退(Crash)是当前首个成熟场景,ANR、卡顿、内存等场景正在演进中。

快速上手
项目已发布到 PyPI,可一键安装并在终端通过交互向导完成配置与分析。
shell
# 安装(中国大陆可加 -i https://pypi.tuna.tsinghua.edu.cn/simple)
pip install stability-analysis-agent
# 启动交互向导
sa-agent在终端菜单中选择 快速开始分析(推荐),然后按提示输入 Demo 路径:
-
examples/crash_cases/demo_basic/logs/mac/NullPtr_SIGSEGV_2026-04-08_10-43-08.crash -
examples/crash_cases/demo_basic/lib/mac -
examples/crash_cases/demo_basic/code_dir
向导会先输出执行计划,然后自动执行。AI 模式下会完成解析、符号化、代码上下文提取与 LLM 推理,并可将修复建议回写源码(含备份)。交互体验参照 Claude CLI:支持上下键菜单、分组化"更多选项"、可返回路径和关键步骤确认面板。
自 v1.2.2 起,项目也提供 cli.api 可编程接口,便于企业包装器或自动化脚本在 Python 进程内调用同一套分析链路。
欢迎试用 Demo、提交 Issue、贡献 Tool / Workflow,一起完善 App 稳定性分析 Agent 体系。
若本文或项目对你有启发,欢迎在 GitHub 仓库(github.com/baidu-maps/... 页面右上角点亮 Star。 这既是对维护者的认可,也能让更多人看到这套实践,并方便你关注后续 Release。