作者:周弘懿(锦琛)
背景
很多团队并不缺向量数据库,缺的是一条能真正跑通的落地路径。第一次接入 Milvus 时,开实例、配网络、建 Collection、导数据、做检索验证、跑多模态样例往往分散在不同角色手里,结果每个人都完成了一段,但"能连上、能导入、能搜索、能演示"的端到端闭环迟迟没有形成。
alibabacloud-milvus-manage 要解决的就是这个问题。它不是把底层命令换一种写法,而是把实例管理、访问打通、数据建模、导入验证、混合检索和多模态演示收敛成一条自然语言任务路径:你说清目标,它把关键动作串起来,并返回可验证的结果。
这篇文章基于真实操作示例,保留原始命令与截图,展示如何更高效地完成以下事情:
-
创建 Alibaba Cloud Milvus 实例
-
查看实例状态并补齐公网访问
-
管理 Collection 并快速验证数据
-
导入文本数据,执行标量、向量和 Hybrid 搜索
-
建立全文检索 + 语义检索的混合检索链路
-
完成图片、视频等多模态数据入库与跨模态搜索
alibabacloud-milvus-manage 实战
假设你是一位在做知识库问答和多媒体搜索的应用工程师,希望在一周内跑通一套可演示、可复用的检索系统。你的目标通常很明确:
-
创建一个 Milvus 2.6 实例
-
打通本机访问链路
-
导入文章数据并验证标量、向量和 Hybrid 搜索
-
顺手证明这套链路也支持图片和视频
传统做法里,你往往需要来回切换云控制台、API 文档、pymilvus 脚本和 embedding 处理代码,再自己设计测试 query 验证结果。用 alibabacloud-milvus-manage,可以把这些动作收敛成一条更清晰的实战路径。
建议按下图所示的 4 个阶段推进,从基础设施、访问链路,到数据验证、检索与多模态能力,逐步完成验证。 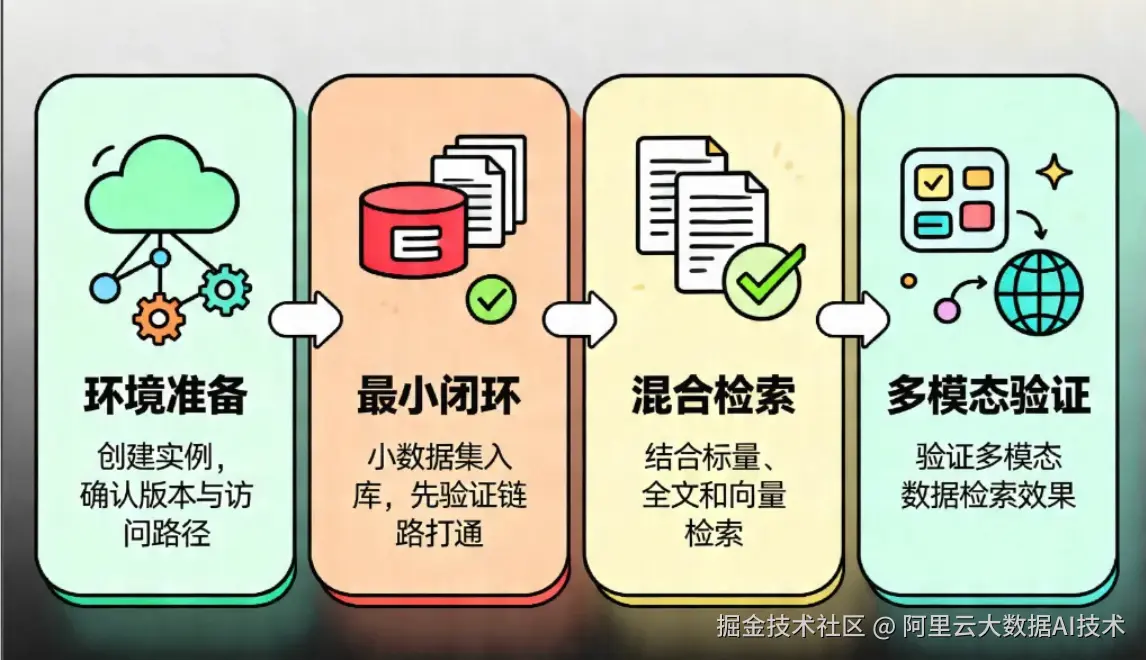
下面的 8 个示例保留了原始输入和截图,并在每一步补充"为什么这一步重要",便于从 0 到 1 介绍这条完整落地路径。
前置步骤:安装 SKILL 运行环境
可以从以下三个地址获取最新版本的 alibabacloud-milvus-manage:
下面以 OpenClaw、Claude Code、Codex 为例说明安装方式:
集群管理场景
1. 创建集群
先把实例创建出来,后面的连通、入库和搜索验证才能继续做。这里建议一开始就把版本、地域和密码策略定清楚,后面排查问题会更省事。
示例输入:
text
/alibabacloud-milvus-manage 在杭州j可用区创建一个2.6版本的milvus实例,密码使用Test123456@123
实践建议:
-
在需求早期就固定 Milvus 版本,减少后续兼容性波动
-
实例名、地域、网络策略最好和业务环境保持一致
-
演示环境可以追求快速可用,生产环境则应单独补充密码与权限规范
2. 查看创建情况
实例创建完成,不代表已经可以使用。这里最好马上确认状态,尽早发现创建失败、状态未完成或配置不一致等问题。
示例输入:
text
/alibabacloud-milvus-manage 查看创建情况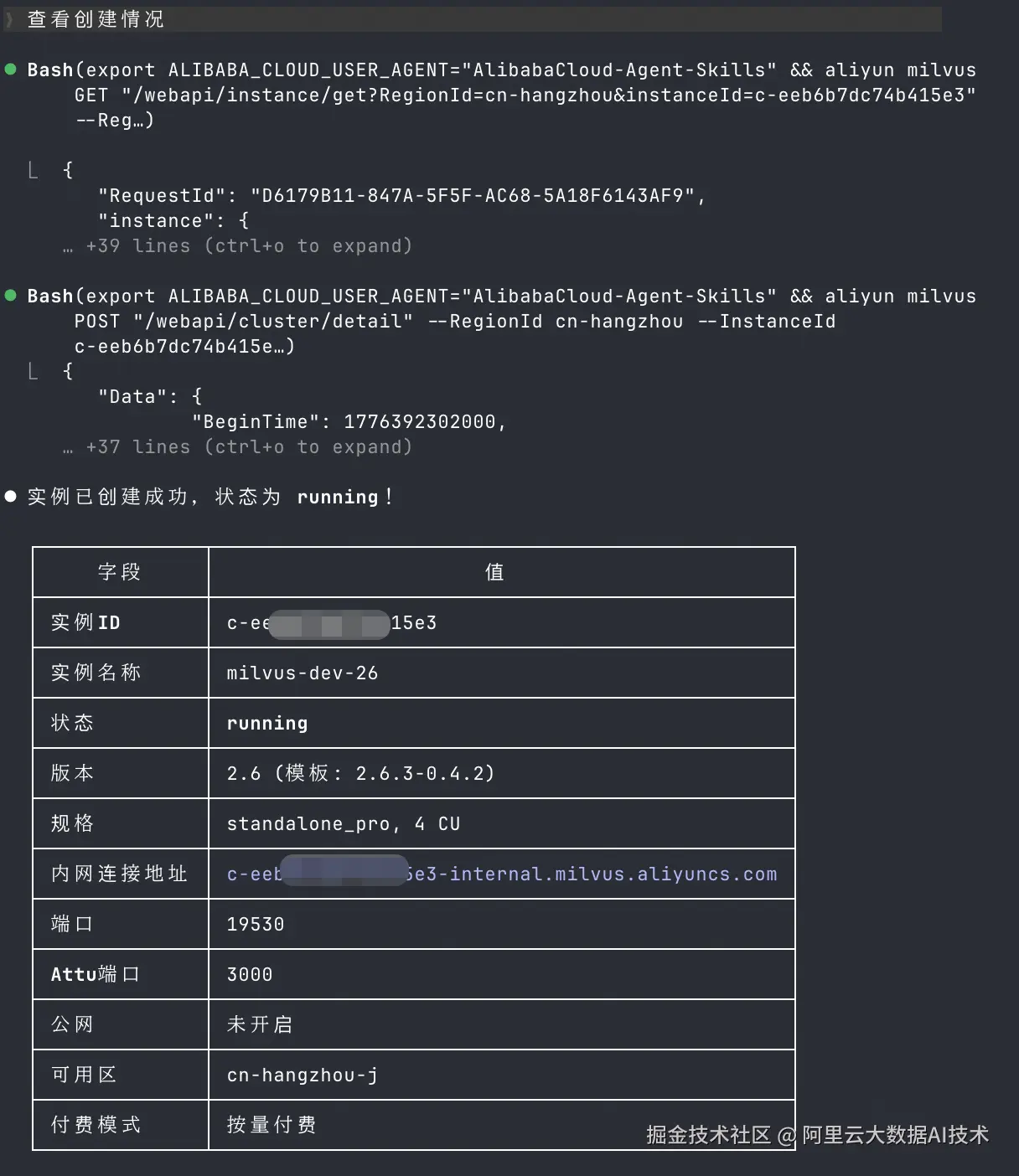
实践建议:
-
建完实例后,先确认状态,再继续后续操作
-
把"查看状态"当成标准步骤,不要靠猜测判断是否可用
3. 添加公网访问
这一步是把"实例已经创建"变成"本地真的能连上"。很多 PoC 卡住,不是 Milvus 本身有问题,而是访问链路没有打通。
示例输入:
text
/alibabacloud-milvus-manage 给集群开启公网访问,添加本机ip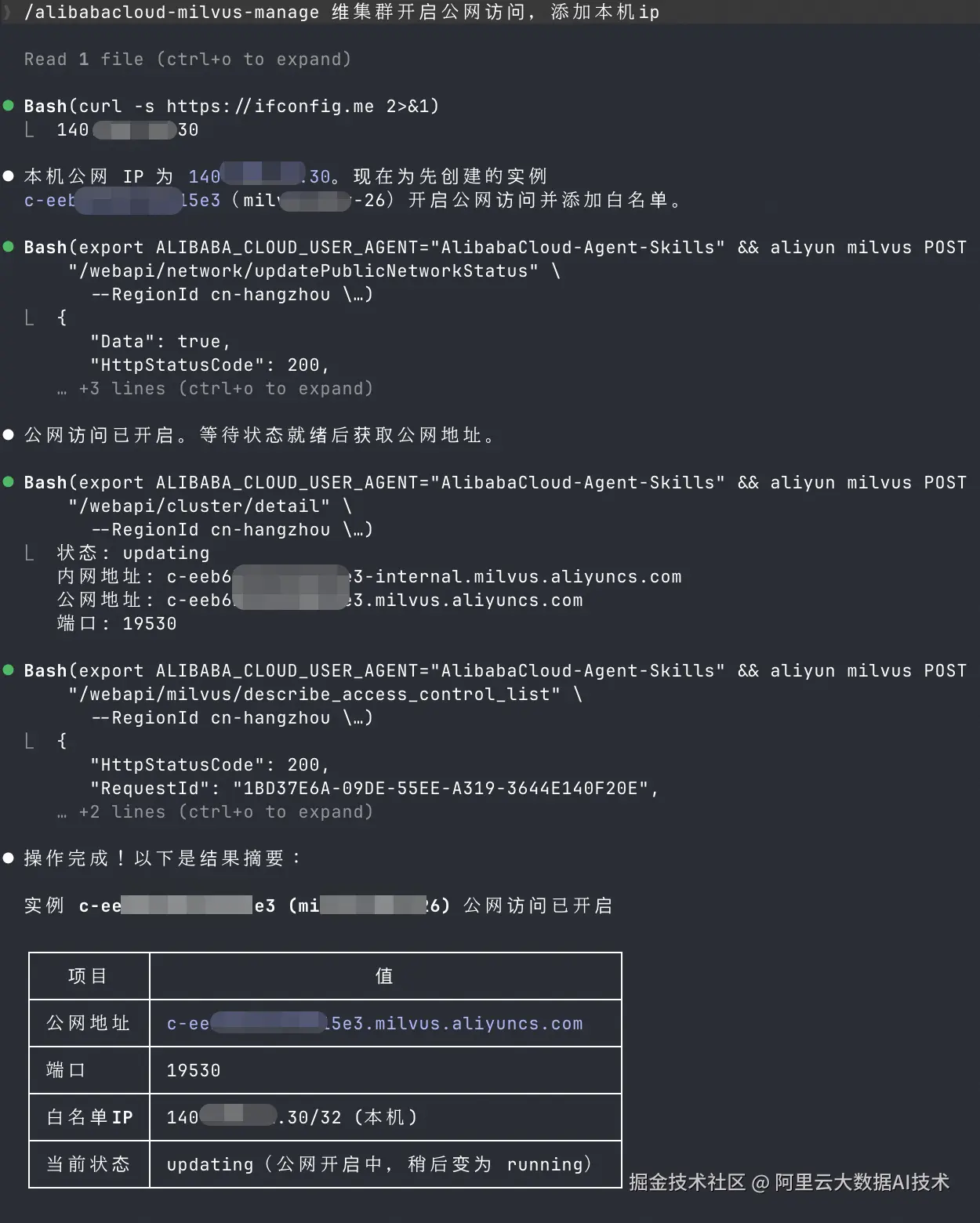
实践建议:
-
演示或开发环境可以先开公网访问,快速完成验证
-
一旦进入团队共享或生产阶段,应尽快切回更严格的网络策略
-
"把本机 IP 加入白名单"是最常见也最容易被遗漏的一步
4. 管理并查询 Collection 列表
在导入新数据之前,先看一下 Collection 列表,再抽样查看每个 Collection 的少量数据,是个很实用的检查动作。这样可以快速确认实例已经连通、表结构已经建好、数据也能正常读出来。
示例输入:
text
/alibabacloud-milvus-manage 查询所有collection,每个展示3条数据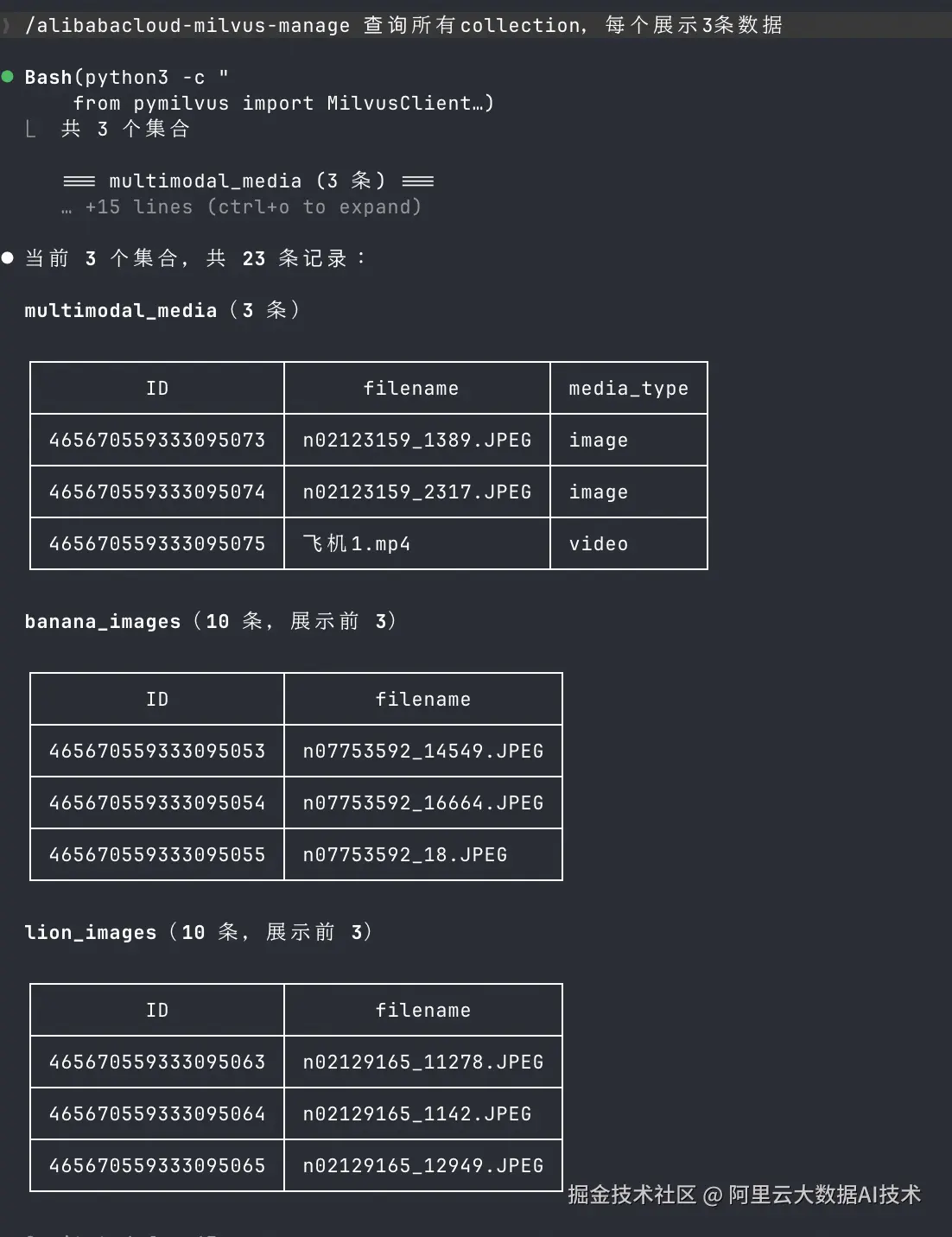
实践建议:
-
"先列出 Collection,再抽样看 3 条数据"是很好的日常巡检方式
-
不要等到搜索结果异常时,才回头检查数据是否真的入库
业务验证场景
文本入库,并验证标量、向量与 Hybrid 搜索
这是最常见的一类业务场景:先把已有文本数据导入 Milvus,再把标量、向量和 Hybrid 搜索都跑一遍,确认整条链路可用。对很多团队来说,用现成的 embedding 数据先把检索跑通,会比一开始就处理复杂数据流程更直接。
示例输入:
text
/alibabacloud-milvus-manage 我有一个 /Users/zhy/Documents/dataset/articles.jsonl
文件,每行包含 title、content、embedding 字段,帮我导入到 article_db collection
里,如果没有的话创建它。导入完后,根据文件中内容随机构造一下标量搜索和向量搜索功能进行测试
导入的数据如下图:可以自行使用ai模拟一些数据 
实践建议:
-
如果你的数据里已经有 embedding,优先直接导入,最快验证链路
-
导入后不要只看"是否成功",一定要补上搜索测试
-
标量搜索、向量搜索都先跑通,再去做更复杂的业务组合
为文本字段同时建立全文检索和 embedding,并验证混合搜索
这一段更接近真实业务。很多场景不会只靠单一路径检索,用户查询里通常既有关键词,也有语义意图,还可能带着时间、标签、类别等过滤条件。把 BM25 和 embedding 放在同一条检索链路里,会更贴近生产环境。
示例输入:
text
/alibabacloud-milvus-manage 我要在 Milvus 里做中文全文检索,需要建一个新的表,需要 title
和 content 两个文本字段,用 BM25 做全文检索,再加一个 text-embedding-v3 做语义搜索,维度
1024。创建好后插入 /Users/zhy/Documents/dataset/articles_raw.jsonl 文件中所有数据数据,然后
分别用文件中的内容向量搜索,标量搜索,全文、embedding的混合搜,全文、标量、向量的混合搜
导入的数据如下图:可以自行使用ai模拟一些数据 
这一段为什么值得重点看:
-
它证明了 SKILL 不只会"建库入库",还能完成完整的检索设计
-
它覆盖了全文、向量、标量以及三者混合的真实检索形态
-
它特别适合知识库、内容平台、客服问答、资讯搜索等典型场景
实践建议:
-
对中文内容检索,全文检索和语义检索建议一起规划
-
不要把"向量搜索"误认为是检索系统的全部
-
生产中最有价值的往往是混合搜索,而不是单一路径的 topK
图片入库并搜索
文本链路跑通后,下一步通常就是验证图片检索。这个示例说明,同样的操作方式不只适用于文本,也适用于图片数据。
图片可到thoth.inrialpes.fr/~jegou/data...地址下载,下载后将目录替换下问题中的描述。
示例输入:
text
/alibabacloud-milvus-manage 把 /Users/zhy/Documents/dataset/qwen-vl/train/banana
目录的图片全部入库,最后用"黄色香蕉"搜索试试
实践建议:
-
从小目录开始做图片入库,先验证准确性,再考虑规模扩张
-
用自然语言描述图片内容做搜索,是最容易让业务方直观看到价值的演示方式
图片、视频联合入库与跨模态搜索
这一段适合放在后面做能力展示。它说明这套 SKILL 不只支持单一模态,也可以把图片和视频一起纳入同一个可检索空间。
图片可到thoth.inrialpes.fr/~jegou/data...地址下载,下载后将目录替换下问题中的描述。
示例输入:
text
/alibabacloud-milvus-manage 先把
/Users/zhy/Documents/dataset/qwen-vl/train/tiger_cat目录下选2个文件 以及
/Users/zhy/Documents/dataset/飞机1.mp4 这三个文件入库,然后用
/Users/zhy/Documents/dataset/qwen-vl/train/tiger_cat下任意一个文件
搜索相似的产品图片,返回前 3 个。再用这个目录这个下面的图片搜索 搜索相似视频
实践建议:
-
多模态检索演示一开始不用追求大规模,先把样例跑通
-
先做少量图片和视频联合入库,更容易验证跨模态结果是否符合预期
-
这类能力适合商品搜索、内容审核、媒资管理、视频理解等场景
结语
通过alibabacloud-milvus-manage,把之前繁重的流程化的操作通过自然语言来解决,把向量检索稳定地放进业务流程里。
alibabacloud-milvus-manage 提供的是一条更短的落地路径:从实例到数据,从索引到检索,从验证到复用。它让团队可以先用小数据集跑通闭环,再逐步扩展到知识库、搜索、推荐和多媒体检索等场景。