****论文题目:****Accurate and Interpretable Log-Based Fault Diagnosis Using Large Language Models(基于大语言模型的准确可解释日志故障诊断)
****期刊:****IEEE TRANSACTIONS ON SERVICES COMPUTING
****摘要:****基于日志的故障诊断是保证系统可靠性和弹性的关键。然而,现有的方法只提供故障诊断结果而不提供解释,这降低了其可信度。大型语言模型(大型语言模型)具有广泛的预训练知识,并在日志分析中显示出潜力,但由于专业能力和特定领域的见解有限,它们不能直接应用于基于日志的故障诊断。此外,大型语言模型课程在上下文长度上有限制,而且内容太多样化,无法选择合适的课程。为了解决这些问题,本文提出了LogInsight,这是一个使用大型语言模型实现准确和可解释的基于日志的故障诊断的框架。我们对一个中等规模的开源大型语言模型进行微调,以整合领域专业知识并利用其解释能力。此外,我们设计了一个面向故障的日志摘要(FOLS)模块,从日志序列中提取重要信息,减轻了大型语言模型的上下文长度限制。对两个公共数据集和实际生产数据集的广泛评估表明,LogInsight在性能和可解释性方面都优于最先进的方法。
LogInsight:用大语言模型实现准确且可解释的日志故障诊断
一、背景与问题:为什么日志故障诊断这么难?
在现代大规模在线服务系统中,故障一旦发生,会迅速波及相互依赖的服务,影响数以百万计的用户,造成巨大的经济损失。当系统出现故障时,运维(O&M)工程师需要分析系统产生的海量日志,完成故障分类(Fault Triage),即判断故障属于哪种类型,并将其分派给对应的团队处置。
然而,这个过程面临三大挑战:
- 日志量巨大:大型系统一次故障可能产生成百上千条日志,人工逐一排查既耗时又容易出错。
- 现有自动化方法缺乏可解释性:已有的机器学习和深度学习方法(如 LogCluster、Cloud19、LogKG)虽然能给出诊断结果,却无法提供任何解释------工程师不知道"为什么系统认为是这种故障",难以建立信任感,也无法据此快速制定处置方案。
- 大语言模型(LLM)直接应用的局限 :LLM 拥有丰富的预训练知识,在 NLP 任务上表现出色,但直接用于日志故障诊断会面临两个核心障碍:
- 缺乏领域专业知识:通用 LLM 没有针对故障诊断场景的专项训练,直接应用效果差。
- 上下文长度限制:故障诊断往往需要分析大量日志,而 LLM 的输入 token 有限,无法一次性处理全部日志。

【配图 1】:论文 Fig. 1------传统故障诊断 vs. 可解释故障诊断的对比示意图(只输出结果 vs. 输出结果+解释理由)
二、LogInsight 的核心创新
针对上述问题,论文提出了 LogInsight 框架,其核心创新体现在以下三点:
创新点 1:面向故障的日志摘要模块(FOLS)
为解决"上下文长度限制"问题,论文设计了 Fault-Oriented Log Summary(FOLS) 模块。
故障期间的日志往往包含大量冗余和噪声,而真正有价值的诊断线索是稀疏的。FOLS 通过两步操作提炼出关键信息:
Step 1:基于聚类的内容聚合(Clustering-Based Content Aggregation)
- 使用 Jaccard 距离 度量日志内容之间的语法相似性:
- 使用 DBSCAN 密度聚类算法对日志条目进行聚类(无需预先指定类别数,能处理任意形状的簇)。
- 每个簇只保留质心(到簇内所有点平均距离最小的那条日志),从而大幅去除冗余。
Step 2:基于 TF-IDF 的内容排名(TF-IDF-Based Content Ranking)
- 对每条日志内容计算 TF-IDF 分数:
,其中 IDF 的分母使用"包含该 token 的故障数量",使得在多种故障中频繁出现的通用词语权重降低,突出与特定故障相关的独特词语。
- 按分数降序排列,过滤掉低于阈值的日志,再按时间顺序重新排列,得到最终的故障摘要(Fault Summary)。
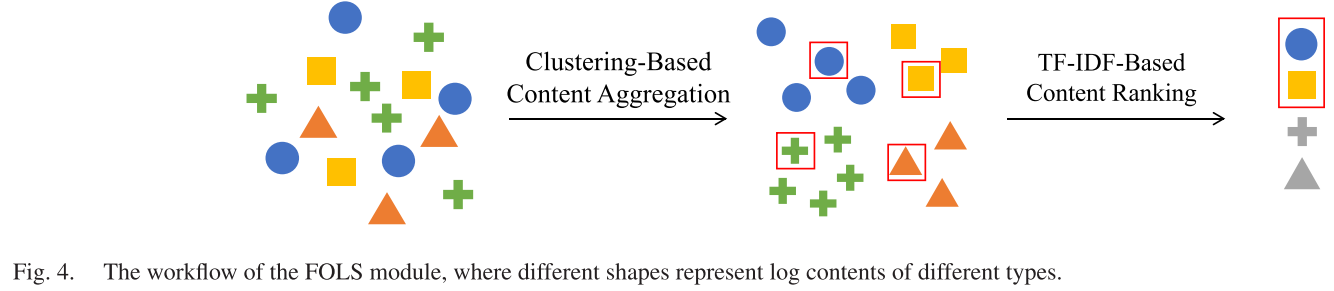
【配图 2】:论文 Fig. 4------FOLS 模块的工作流程图(不同形状代表不同类型的日志内容,展示聚类和排名两步操作)
创新点 2:知识注入(Knowledge Injection)
为解决"领域专业知识缺乏"问题,论文构建了专属的指令数据集 LFDInstruction。
具体流程:
- 运维专家收集各类故障的日志数据。
- 用 FOLS 模块生成每个故障的简洁摘要,作为模型输入。
- 利用 GPT-4 自动生成初版故障分析与解释(包含故障类型和判断理由),作为模型输出。
- 专家人工审核,修正 GPT-4 生成内容中的不准确之处。

【配图 3】:论文 Fig. 5------LFDInstruction 数据集中单条数据的结构示意(Instruction + Input Data → Fault Type + Explanation)
这种"自动生成 + 人工验证"的策略,既降低了标注成本,又保证了数据质量。实验中,两名工程师约一小时可完成 50 条数据的审核,且这是一次性的训练前工作,不需要持续投入。
创新点 3:监督微调(Supervised Fine-Tuning with LoRA)
将 LFDInstruction 数据集用于对开源 LLM 进行参数高效微调(PEFT),采用 LoRA(Low-Rank Adaptation) 方法:
- Rank = 8,Alpha = 32,Dropout = 0.05
- 学习率
- 基座模型:经过对比评估,选择 Mistral-7B(约 70 亿参数)
微调目标:最小化模型预测输出与真实诊断之间的误差:
三、系统整体框架
LogInsight 由四个主要模块组成:
| 阶段 | 模块 | 功能 |
|---|---|---|
| 离线 | 日志预处理 | 用正则表达式提取日志 Content 字段,组成日志内容序列 |
| 离线 | FOLS | 聚类 + TF-IDF 排名,生成故障摘要 |
| 离线 | 知识注入 | GPT-4 生成解释 → 专家验证 → 构建 LFDInstruction |
| 离线 | 监督微调 | 用 LFDInstruction 对 LLM 进行 LoRA 微调 |
| 在线 | 推理 | 输入新故障日志 → FOLS 摘要 → 微调 LLM → 输出类型 + 解释 |
值得注意的是,LogInsight 无需日志解析(Log Parsing),直接利用 LLM 理解原始日志内容,这比先解析成模板再分析的传统流程更为简洁,也避免了解析错误对下游任务的影响。
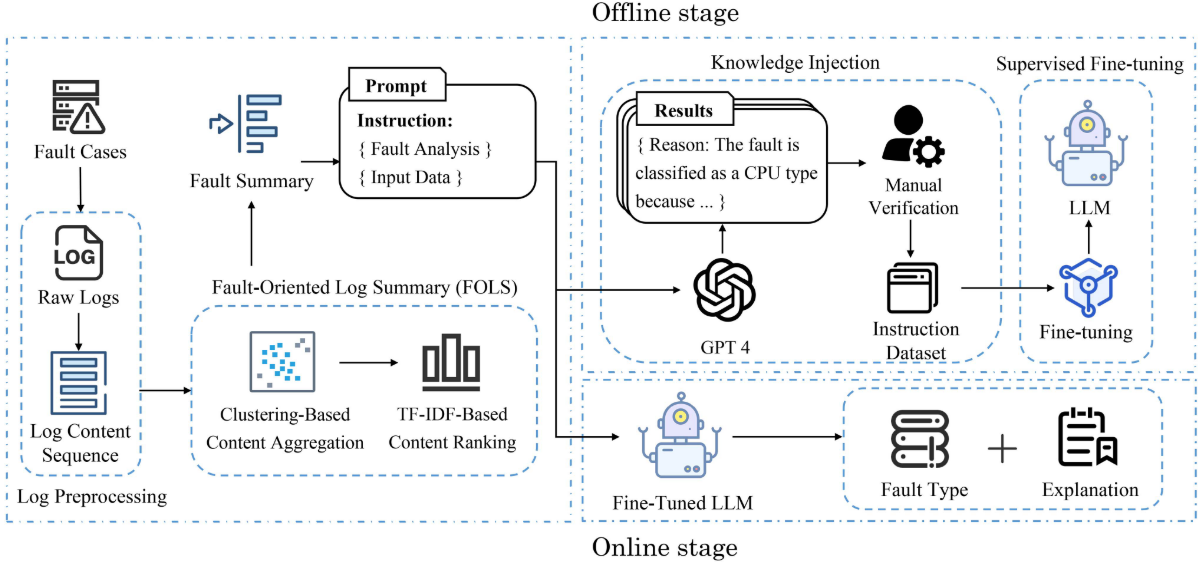
【配图 4】:论文 Fig. 2------LogInsight 整体框架图(离线阶段 + 在线阶段)
四、实验设置
数据集
论文在三个真实数据集上进行了评估:
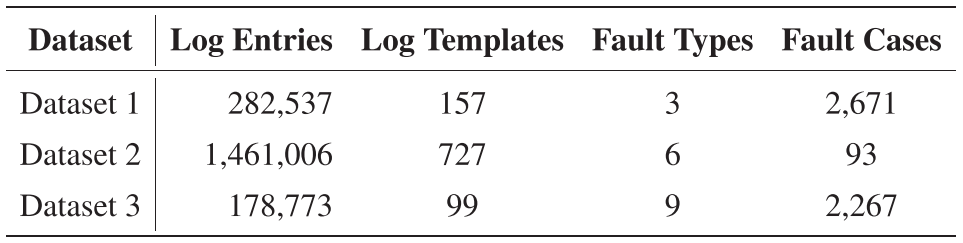
【配表 1】:论文 Table I------三个数据集的详细信息(故障数量、日志条目数、故障类型数等)
- Dataset 1 (公开):真实业务环境中的服务器日志,共 2,671 条故障案例,3 种故障类型(CPU Caterr、Memory Constraint Error、Hardware Error)。取故障发生前 12 小时的日志。
- Dataset 2 (公开,来自 OpenStack):93 条故障案例,1,461,006 条日志条目,6 种故障类型(AMQP Server Unreachable、MySQL Lost Connection 等)。
- Dataset 3 (生产数据集,来自中国移动 CMCC):322 台交换机的网络设备日志,178,773 条日志条目,9 种故障类型(Power Supply Fault、Fan Fault、Port Flapping Fault 等),跨度一年。
每个数据集随机选取 50 条故障案例构建 LFDInstruction 用于微调,其余用于测试。
基线方法
- LogCluster(无监督):TF-IDF 向量 + 层次聚类
- Cloud19(有监督):word2vec 嵌入 + 分类
- LogKG(有监督):知识图谱 + OPTICS 聚类
- GPT-4(零样本):使用相同 prompt,不经微调直接推理
评估指标
使用多分类标准指标:Micro F1、Macro F1、Weighted F1。
五、实验结果与分析
RQ1:故障诊断效果

【配表 2】:论文 Table III------LogInsight 与各基线方法在三个数据集上的性能对比
LogInsight 在所有数据集、所有指标上均超越所有基线方法:
- Weighted F1 分别为 0.883、0.997、0.997 ,相较最优基线方法提升了 36.9%、12.8%、7.3%。
- Dataset 1 的提升最显著,因为该数据集故障模式复杂,传统方法难以应对。
- 基线方法普遍存在 Macro F1 远低于 Micro/Weighted F1 的问题,说明它们对类别不均衡数据处理能力弱;而 LogInsight 三项指标保持高度一致,体现了对不同数据分布的稳健适应性。
- LogInsight 显著优于直接使用 GPT-4,充分验证了领域微调的必要性。
RQ2:在线部署效率
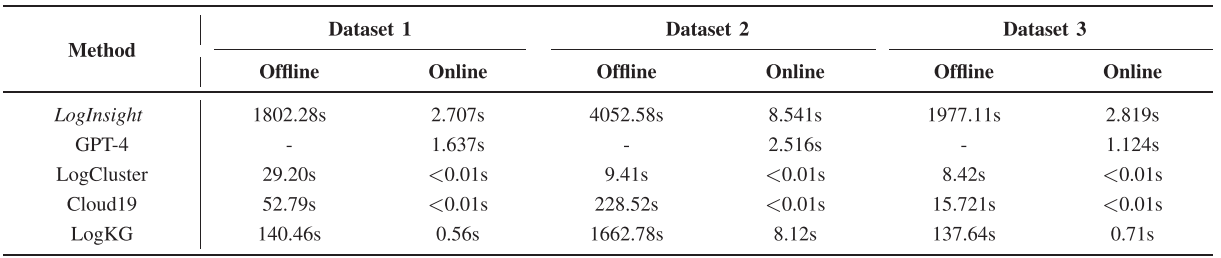
【配表 3】:论文 Table IV------LogInsight 与基线方法的效率对比(离线 + 在线时间)
LogInsight 在三个数据集上的平均在线诊断时间分别为 2.7 秒、8.5 秒、2.8 秒,完全满足实时在线部署的延迟要求。虽然 LLM 的推理开销天然高于传统方法,但这一时间代价在实际运维场景中是可以接受的。
RQ3:FOLS 模块消融实验
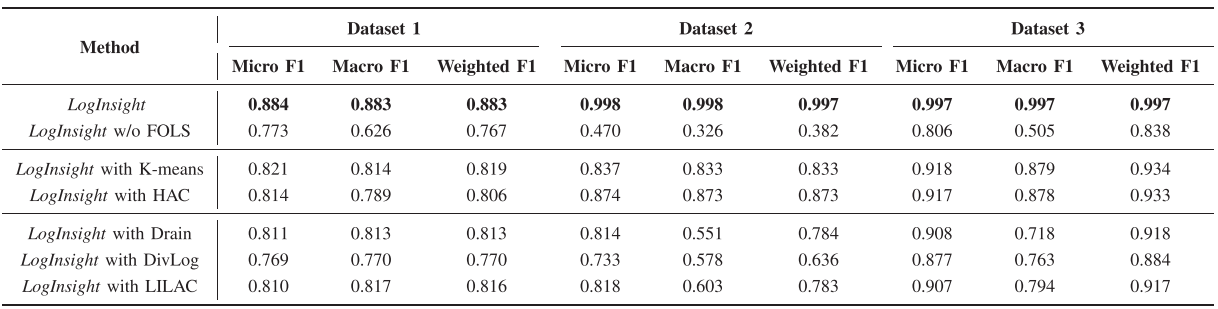
【配表 4】:论文 Table V------FOLS 模块消融实验结果
移除 FOLS 模块后,性能显著下降:Weighted F1 在三个数据集上分别从 0.883/0.997/0.997 降至 0.767/0.382/0.838。下降的原因有两个:
- 原始日志含有大量冗余和噪声,信息熵低;
- token 长度限制导致日志被截断,关键信息丢失。
此外,实验对比了用 K-means、HAC 等聚类算法和 Drain、DivLog、LILAC 等日志解析方法替换 DBSCAN 的效果。结论是:聚类方法整体优于日志解析方法------解析方法引入的解析错误(尤其是用占位符"*"替代变量)会误导 LLM 的分析,损害诊断性能。
RQ4:可解释性评估
为评估解释质量,来自 CMCC 的运维专家对 Dataset 3 中随机抽取的 200 条故障案例进行人工打分(Likert 1-5 分量表),从两个维度评估:
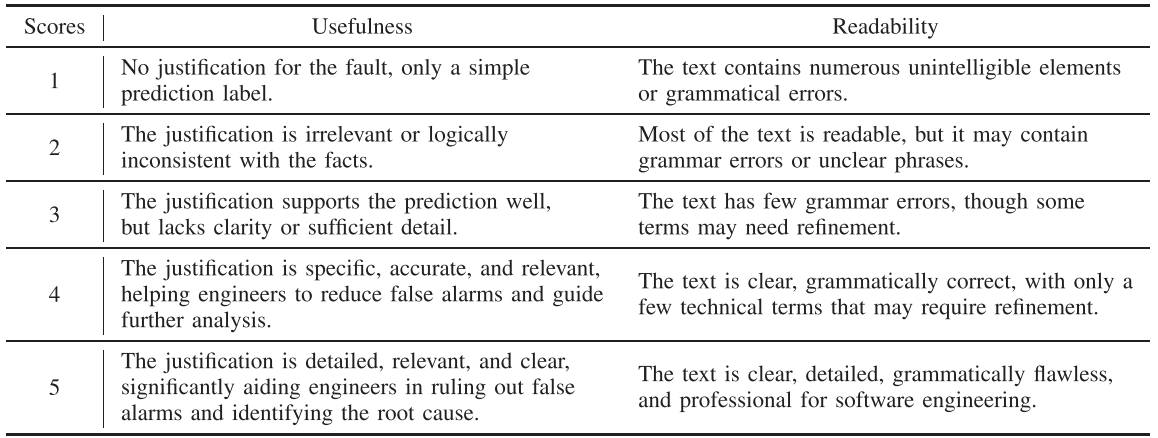
【配表 5】 :论文 Table VI------可解释性评估标准(1-5 分的判断准则)
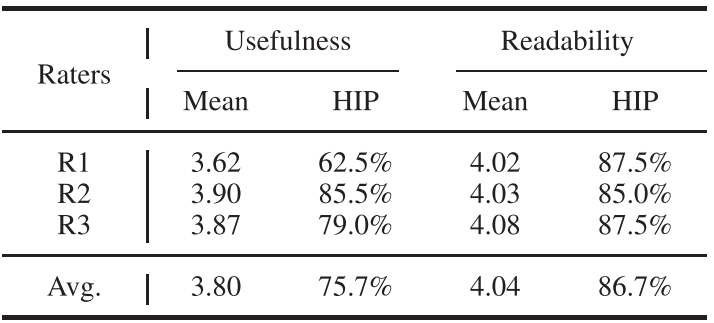
【配表 6】:论文 Table VII------专家打分结果汇总
- 实用性(Usefulness) :平均分 3.80 分 ,高解释性比例(≥4分)达 75.7%,说明大多数解释能有效支撑工程师的诊断决策。
- 可读性(Readability) :平均分 4.04 分 ,高解释性比例达 86.7%,说明生成的解释语法正确、语义清晰、专业规范。

【配图 5】:论文 Fig. 8------两个典型故障案例的诊断示例(Port Flapping Fault 和 Power Supply Fault 的完整输入摘要与输出解释)
RQ5:与不同 LLM 的兼容性
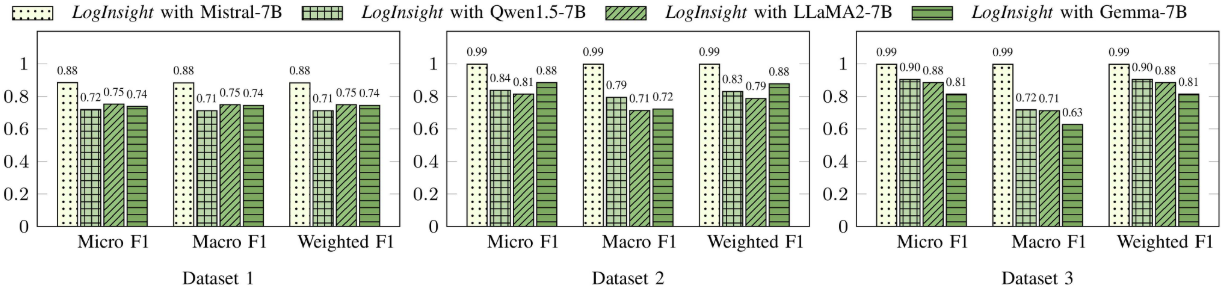
【配图 6】:论文 Fig. 7------LogInsight 在 Mistral-7B、Qwen1.5-7B-Chat、LLaMA2-7B、Gemma-7B 四种基座模型上的性能对比图
LogInsight 在 Mistral-7B 上性能最优,但搭配其他三种模型时同样能取得相近的效果,体现了框架对不同 LLM 架构的良好适配性。
六、案例研究
论文随机选取两个故障案例,直观展示了 LogInsight 的完整工作流程:
案例 1:端口抖动故障(Port Flapping Fault)
- 故障前 10 分钟共收集到 796 条日志。
- 经 FOLS 聚类聚合后压缩至 29 条不同日志,再经 TF-IDF 排名过滤掉 11 条,最终得到 18 条关键日志(包含"Port Down"、"LACP"等关键词)。
- LogInsight 正确诊断出故障根因:LOS(信号丢失)告警引发的端口 Down 事件,以及 LACP 和 Smartgroup 状态变化。
案例 2:电源故障(Power Supply Fault)
- 收集到 365 条日志 ,经 FOLS 处理后生成包含 23 条关键日志的故障摘要。
- LogInsight 准确识别故障类型,输出描述了电源异常和电压不规律问题,为工程师提供了详细可操作的信息。
七、讨论:局限性与未来方向
尽管 LogInsight 取得了优异的成绩,论文也坦诚地指出了两个现实局限:
1. 相似日志模式下的误分类
在 Dataset 3 中,"端口故障(Port Failure)"和"LACP 抖动(LACP Flapping)"往往产生高度相似的日志模式,因为端口故障本身可能引发 LACP 不稳定,导致两类故障的日志特征重叠,模型难以区分。未来可引入系统性能指标或调用链等多模态数据来提供更丰富的上下文信息。
2. 对未知故障类型的识别能力不足
当前方案通过 Prompt 枚举已知故障类型,并指示模型将未知故障标记为"unknown type",但实验发现模型仍倾向于将未知故障错误归类为已知类型之一。未来可探索引入外部知识库或自监督学习策略,降低对预定义类型的依赖,增强对新兴故障的适应能力。
八、与其他方法的深度对比:为什么微调优于 Prompt 和 RAG?

【配表 7】:论文 Table IX------微调方法 vs. Prompt 方法 vs. RAG 方法的性能对比
论文专门对比了三种 LLM 使用策略:
- Prompt-based:直接在基础 LLM 上使用设计好的 Prompt,不做微调。
- RAG-based:使用 SentenceTransformer + 余弦相似度检索 Top-5 历史案例作为 in-context 示例。
- Fine-tuned LogInsight:使用 LFDInstruction 进行 LoRA 微调。
结论明确:微调方法大幅领先。未微调的 LLM(无论是否加 RAG)经常无法遵循指令、生成无关或格式混乱的内容,在专业故障诊断任务上可靠性差。微调使 LLM 将领域知识内化,能够稳定地输出结构化、准确的诊断结果。
九、总结
LogInsight 的价值可以归纳为一句话:它是第一个同时解决"诊断准确性"和"结果可解释性"的 LLM 日志故障诊断框架。
| 维度 | LogInsight 的方案 |
|---|---|
| 领域知识缺失 | 构建 LFDInstruction,LoRA 微调注入领域知识 |
| 上下文长度限制 | FOLS 模块(聚类 + TF-IDF)压缩日志,保留关键信息 |
| 可解释性缺失 | 微调 LLM 同时输出故障类型和解释理由 |
| 工程可行性 | 平均诊断时间 ≤8.5 秒,50 条数据即可完成有效微调 |
对于从事 AIOps、日志分析、智能运维的从业者和研究者而言,LogInsight 提供了一个将 LLM 落地到生产运维场景的清晰范本,其 FOLS 模块的设计思路(用聚类+排名代替解析来压缩日志)尤其具有借鉴价值。