set和map
- 1、set
- 2、使用set的基本方式
-
- 2.1、find()
- 2.2、erase()
- 2.3、count()
- [2.4、lower_bound() & upper_bound()](#2.4、lower_bound() & upper_bound())
- 3、multiset
- 4、map
- 5、使用map的基本方法
-
- [5.1、构造 & 析构](#5.1、构造 & 析构)
- [5.2、插入 & 删除](#5.2、插入 & 删除)
- 5.3、传入节点(pair)的方式
- 5.4、打印相关的零散知识点
- 5.5、重载\[\](难点)
- 5.6、at
- 6、multimap的简单提及
1、set
set的底层结构,其实是key搜索策略的二叉搜索树。
但是set相比普通的key搜索二叉搜索树,做了更近一步的调整:通过节点旋转,以达到建立平衡树的效果,使得遍历、查找等方法的时间复杂度接近O(logN)。
2、使用set的基本方式
使用set需包含头文件#include<set>。
set包含三个成员变量:
- key值
- 仿函数:确定比较的判断依据
- 空间配置器
set的构造函数 :
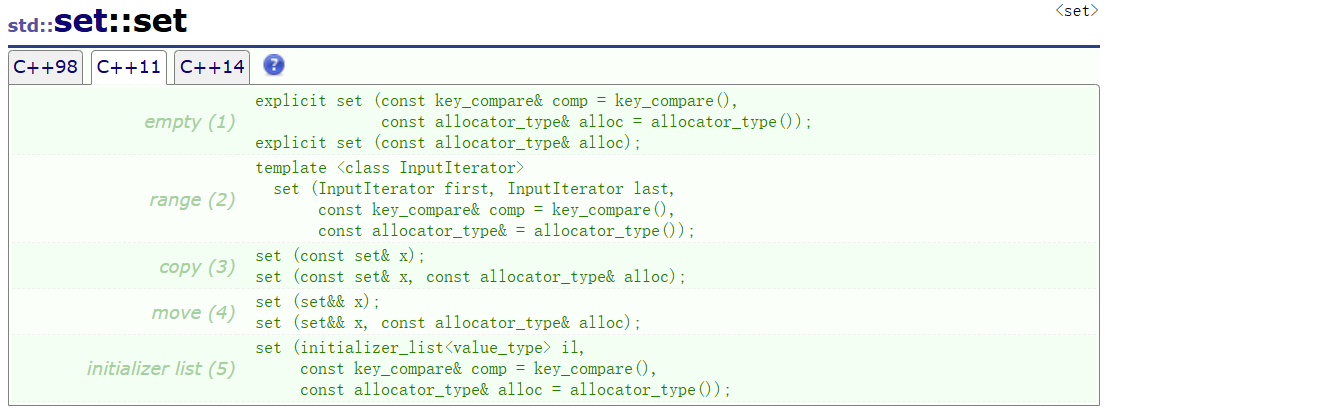
当前我们可以使用无参数构造、initializer_list构造、迭代器区间构造,和拷贝构造。
我们创建一个set,打印看看:
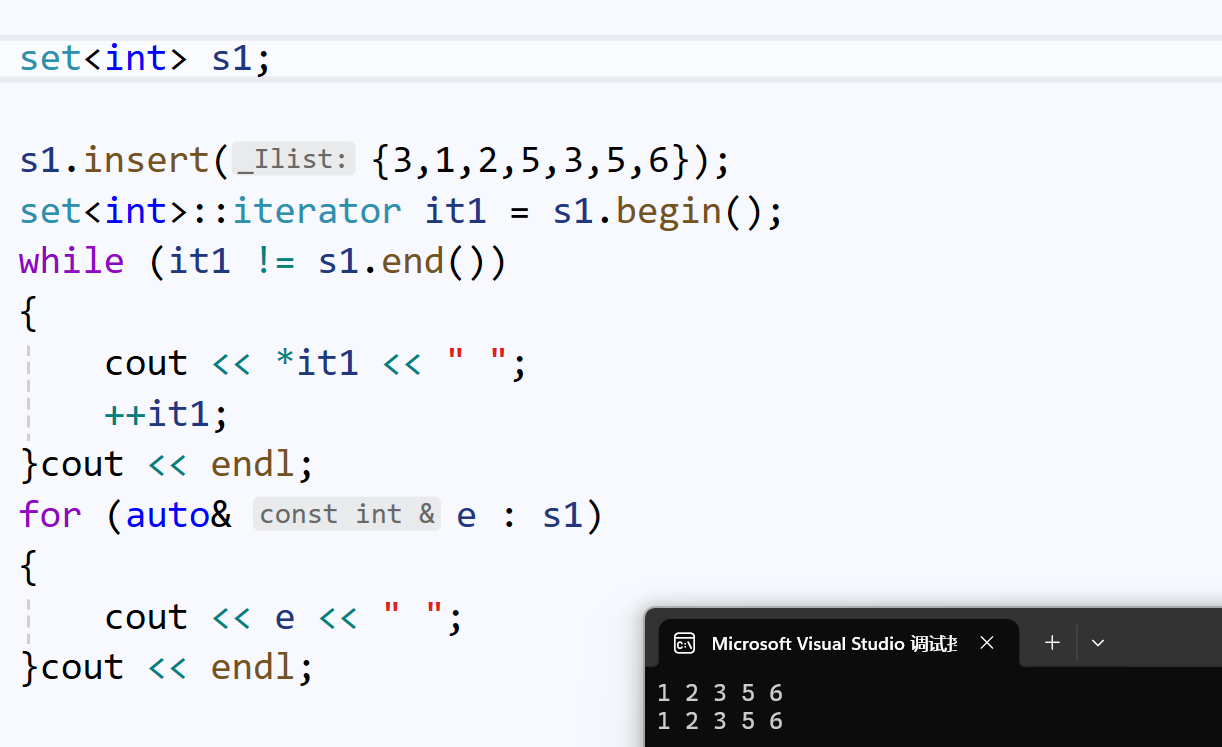
我们可以发现,遍历的结果是:去重+排序。这验证了set是不支持放入相同key值节点的。
2.1、find()
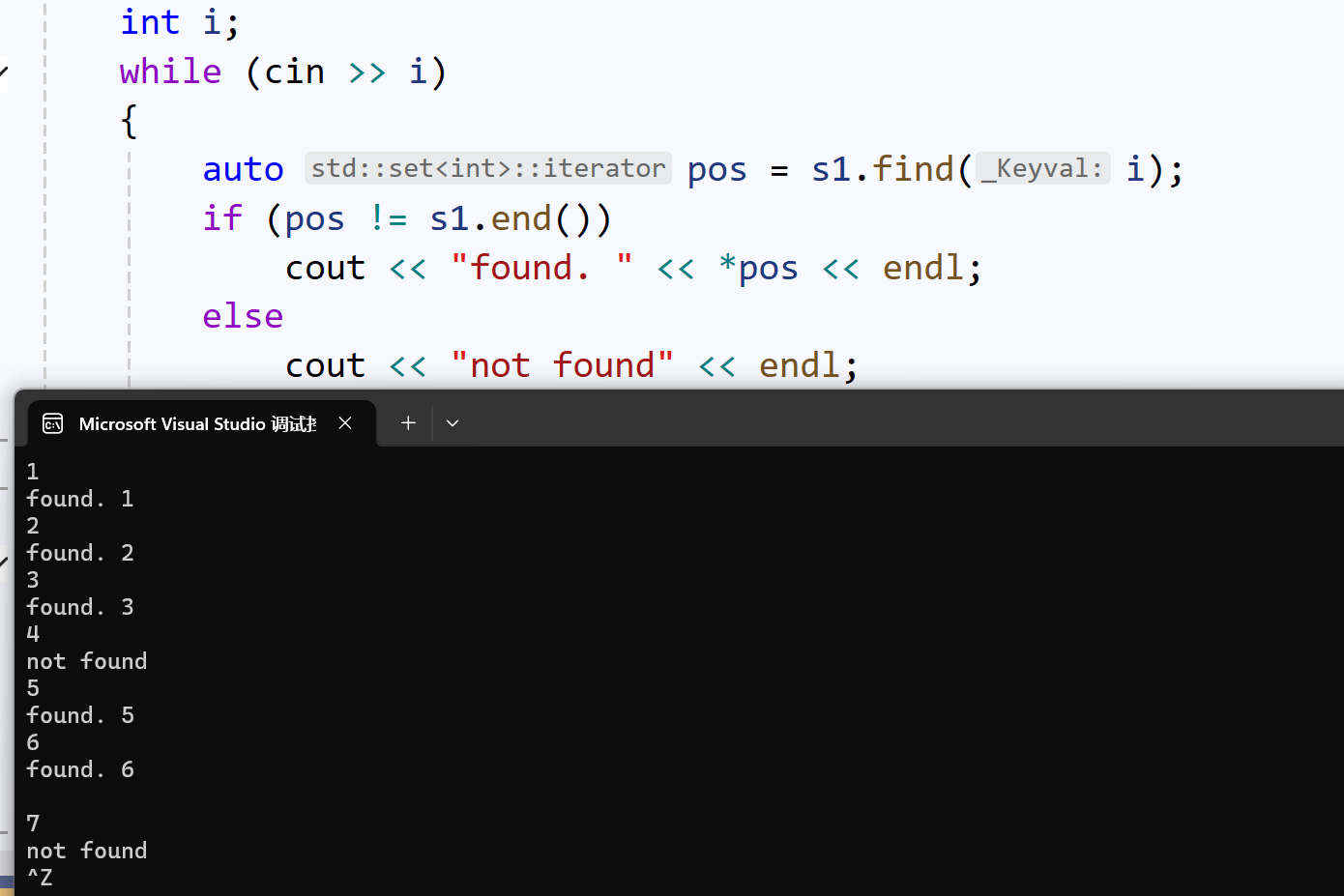
find(),接收要找的值,返回迭代器:
- 找到了,迭代器(保存的地址)指向要找值节点
- 没找到,迭代器指向end()(最后一个有效值的下一位)

2.2、erase()
set的erase()有三种:
- 删除迭代器所指的节点(此时迭代器会失效)
- 删除存储指定数的节点
- 删除一段迭代器区间

对于删除存储指定数的节点 的erase(),其返回值是删除节点的个数:

set将序列进行了去重,erase()返回的是1。
2.3、count()
count()返回的是指定值节点的个数。


2.4、lower_bound() & upper_bound()
bound:界限。
- lower_bound()返回的是存储大于等于指定值的值,的最近节点的位置(迭代器)
- upper_bound()返回的是存储大于指定值的值,的最近节点的位置(迭代器)


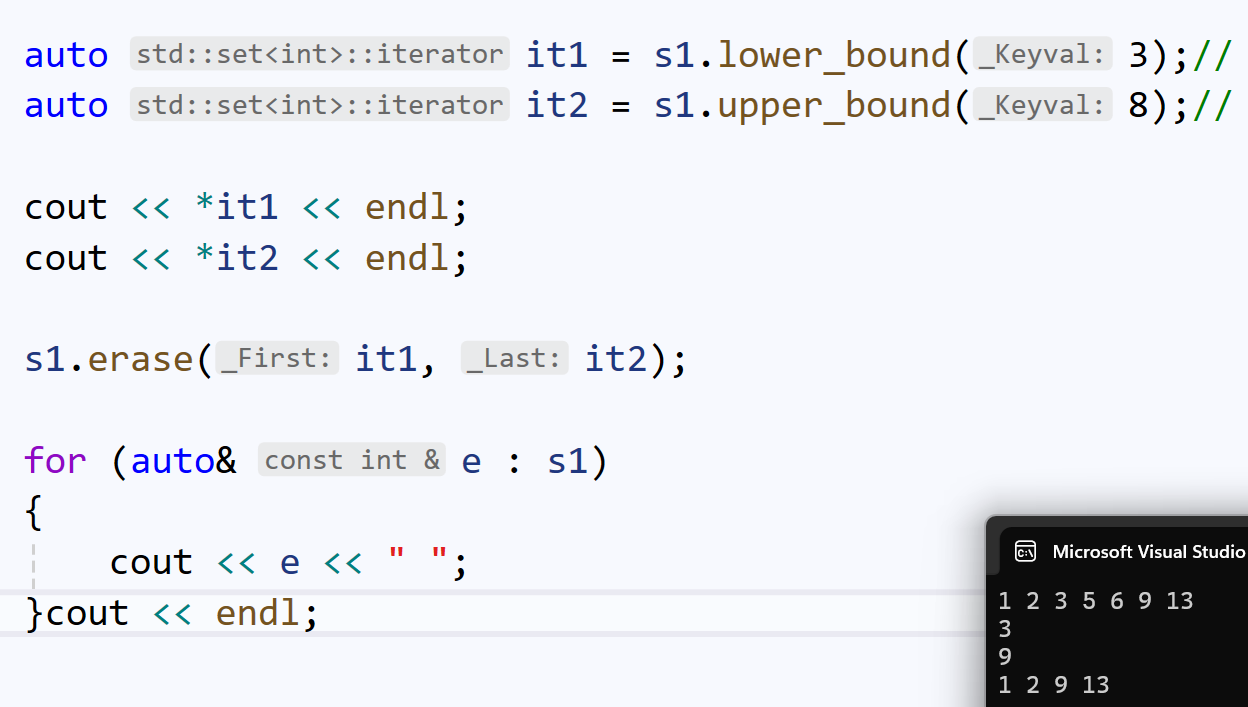
假设我们要在s1中,删除区间[3, 8]的所有数:
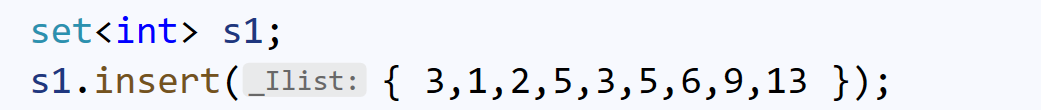
我们可能会想,先直接找到3, 8:
cpp
auto it1 = s1.find(3);
auto it2 = s1.find(8);如果s1里没有3, 8呢?
这时我们就可以利用lower_bound() & upper_bound():
cpp
// 中序遍历的序列为:1, 2, 3, 5, 6, 9, 13
auto it1 = s1.lower_bound(3);// 定位到大于等于3的最近值:3
auto it2 = s1.upper_bound(8);// 定位到大于8的最近值:9我们就可以对于这段左闭右开(左端首位有效,右段末位有效的下一个无效位)的区间进行erase()。
3、multiset
与set不同的是,multiset允许重复值的出现。
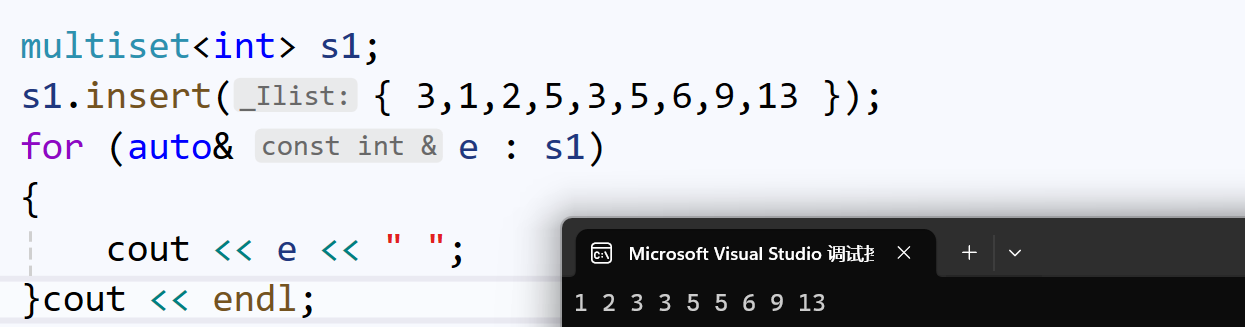
multiset与set,大部分接口的使用方式是几乎一样的。只有几个接口有一些不同之处。
3.1、multiset的find()
既然multiset可以放多个相同的值,那么find()找这个相同值,找的是哪一个呢?
答案是:中序序列的第一个。
我们可以稍微验证一下:
cpp
void test4()
{
multiset<int> s1 = { 3,3,1,2,5,3,5,6,9,13 };
for (auto& e : s1)
{
cout << e << " ";
}cout << endl;
multiset<int>::iterator it = s1.find(3);
cout << *it << endl;
while (it != s1.end())
{
cout << *it << " ";
++it;
}cout << endl;
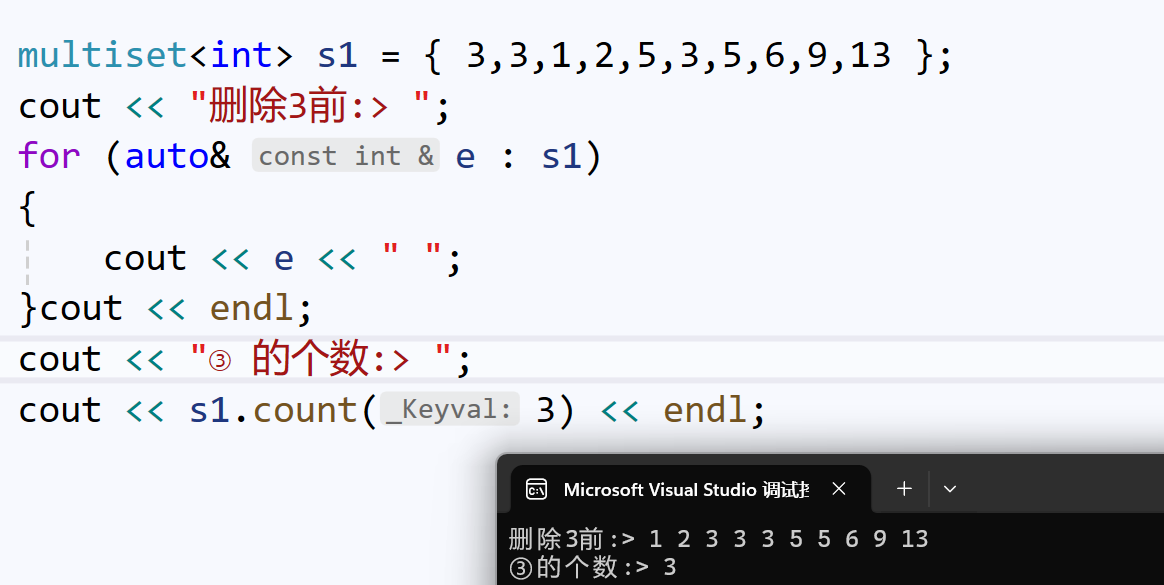
}上面代码给出的multiset序列,其中序遍历会有三个连续的3。
我们使用find()第一次找到3,并把此时3的位置赋值给迭代器it,然后使it遍历完剩下的序列,如果出现三个3,说明正确:

find()的逻辑,我们可以简单理解为:对此时multiset建起来的二叉搜索树进行中序遍历,找到了③不能停继续向左;直到某一个③的左子树再没有节点为③,那么这个节点③就是中序第一个③,find()就返回这个③的位置。(如果没有③就返回multiset的end()(左闭右开))
3.2、multiset的erase()
multiset的erase()将会删除所有的指定值:
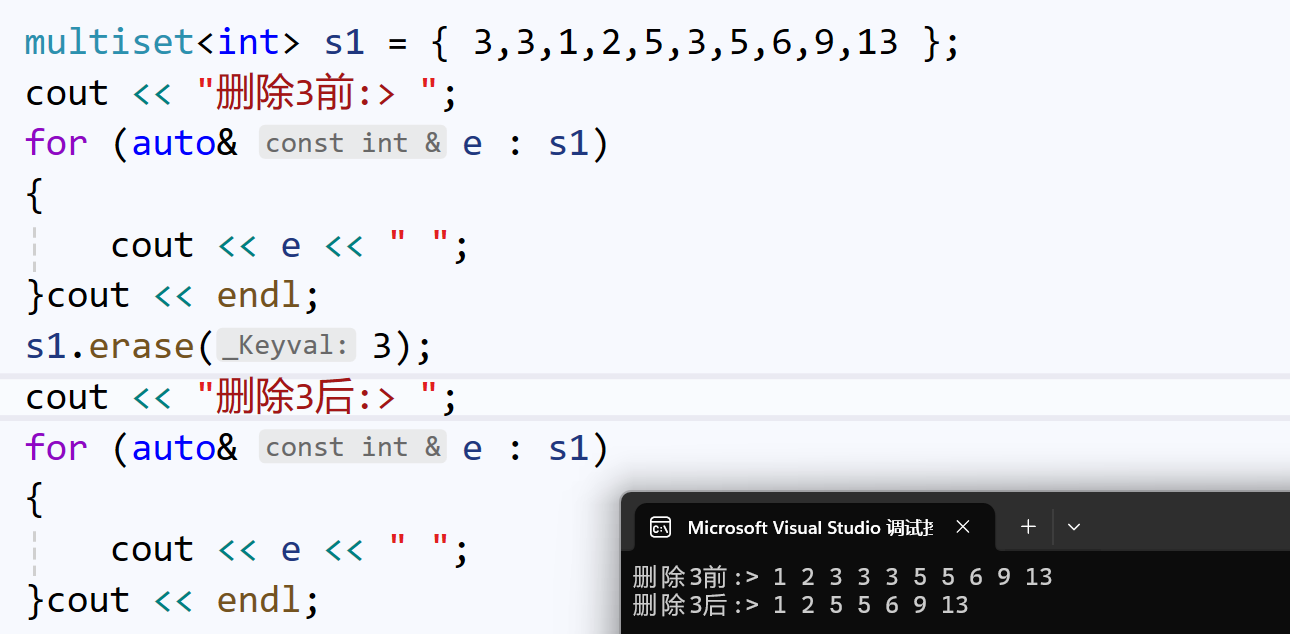
C++98标准中,erase()有一个返回类型为size_t的重载:

这个重载,返回的是被删除节点的个数:
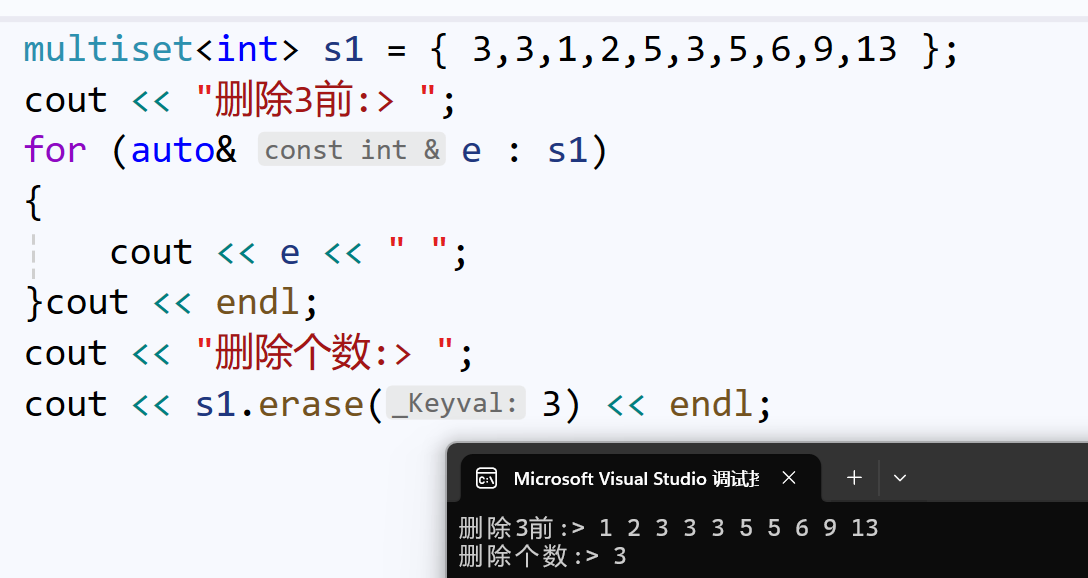
那么也就意味者,multiset的**count()**可以计算指定值对应节点的个数,不再只是0或1,就有价值了:
3.3、multiset的equal_range
首先我们要知道,equal_range()返回的是一段包含所有相同指定值的迭代器区间。

这里我们看到,equal_range()的返回类型是pair<iterator, iterator>。
我们再看pair:

pair有两个成员:T1类型first、T2类型second。
那么我们就可以猜测:equal_range()将指向第一次出现的指定值节点位置 的迭代器传给pair的first,而将指向最后一次出现的指定值节点位置的下一个位置的迭代器传给pair的second。
假设我们有序列:3,3,1,2,5,3,5,6,9,13,排成中序(升序)是1,2,3,3,3,5,5,6,9,13,向equal_range()输入3:
- 首先识别出multiset的迭代器类型,实例化出一个pair类
- pair类的first为multiset的迭代器类型,指向第一个3;second为multiset的迭代器类型,指向5
cpp
void test6()
{
multiset<int> s1 = { 3,3,1,2,5,3,5,6,9,13 };
cout << "删除前: ";
for (auto& e : s1)
{
cout << e << " ";
}cout << endl;
auto pair = s1.equal_range(3);
cout << "first: " << *pair.first << endl;
cout << "second: " << *pair.second << endl;
s1.erase(pair.first, pair.second);
cout << "删除后: ";
for (auto& e : s1)
{
cout << e << " ";
}cout << endl;
}
4、map
set对应key搜索策略,那么map对应key-value搜索策略。

我们可以看到,map与set,其实只相差一点:map比set多了一个mapped_type,就是key-value策略里的value。
但是,map的底层可不是单独存了一个key,一个value:
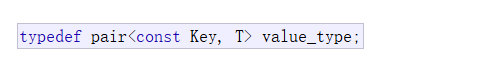
map的数据key, value,是存放在一个pair类对象里的:
- pair的first对应key
- pair的second对应value
我们发现,Key类型被const修饰,意味着参与比较,以确定在map哪个地方的key值是不期望被直接修改的;而value值可以被修改。
5、使用map的基本方法
5.1、构造 & 析构
map的构造,有默认构造、拷贝构造、迭代器区间构造、initializer_list构造等等:
map和set的深拷贝,在数据量很多的情况下,代价比较大,应谨慎使用。
析构也可能是一种遍历析构的方法,目前我们不需要管。
5.2、插入 & 删除
插入:
首先我们要明白,我们插入map的每一个数据(节点),都是一个pair< const K, T >的对象,并不只是key值。
其次,map的插入函数,也有常见的几个重载:
- 简单插入一个pair
- 在迭代器position处插入一个pair
- 插入一段迭代器区间
- 插入initializer_list对象
删除:

常见的几个重载:
- 删除指定位置(迭代器)的节点
- 删除所有存指定key值的节点,并返回删除了多少个节点
- 删除一段迭代器区间
5.3、传入节点(pair)的方式
比如,我们想实现一个简单的中英互译词典:
cpp
void test1()
{
// 实现一个中英词典
map<string, string> dict;
}我们可以放入一个pair<string, string>类对象:
cpp
void test1()
{
// 实现一个中英词典
map<string, string> dict;
pair<string, string> kv1("dictionary", "词典");// 放入一个对象
dict.insert(kv1);
}也可以放入一个pair<string, string>类型的匿名对象:
cpp
void test1()
{
// 实现一个中英词典
map<string, string> dict;
pair<string, string> kv1("dictionary", "词典");
dict.insert(kv1);
dict.insert(pair<string, string>("map", "映射"));// 放入匿名对象
}我们还可以放入一个make_pair类对象。
cpp
void test1()
{
// 实现一个中英词典
map<string, string> dict;
pair<string, string> kv1("dictionary", "词典");
dict.insert(kv1);
dict.insert(pair<string, string>("map", "映射"));
dict.insert(make_pair("left", "左"));// 放入make_pair对象
}我们来稍微了解一下make_pair:

make_pair接收传入的x, y,推导出x的类型T1和y的类型T2;然后返回一个pair<T1, T2>类对象,这个对象的first是x,second是y。
我们向make_pair直接传入"left", "左",make_pair就会返回一个pair<const char*, const char*>类型的对象。
而我们在上面简单的中英词典中,dict接收的pair,是pair<string, string>类型的。而代码能正常运行,意味着当前make_pair返回的pair<const char*, const char*>类对象,就会转换成pair<string, string>类的对象。(可以类比为const char* 对象转化为了string类对象)
上面的所有放法,都是C++11之前的放法。
C++11之后,支持多参数隐式类型转换:
cpp
void test1()
{
// 实现一个中英词典
map<string, string> dict;
pair<string, string> kv1("dictionary", "词典");
dict.insert(kv1);
dict.insert(pair<string, string>("map", "映射"));
dict.insert(make_pair("left", "左"));
dict.insert({"right", "右"});// 多参数隐式类型转换
// 两个const char*,最终转换成一个pair<string, string>
}当然,我们还可以将多参数隐式类型转换,与initializer_list插入结合:
cpp
void test1()
{
// 实现一个中英词典
map<string, string> dict;
pair<string, string> kv1("dictionary", "词典");
dict.insert(kv1);
dict.insert(pair<string, string>("map", "映射"));
dict.insert(make_pair("left", "左"));
dict.insert({"right", "右"});
dict.insert({{"insert", "插入"}, {"sort", "排序"}, {"string", "字符串"}});
}5.4、打印相关的零散知识点
当前pair<string, string>是不支持直接打印的:

我们只能打印pair<string, string>的first和second:
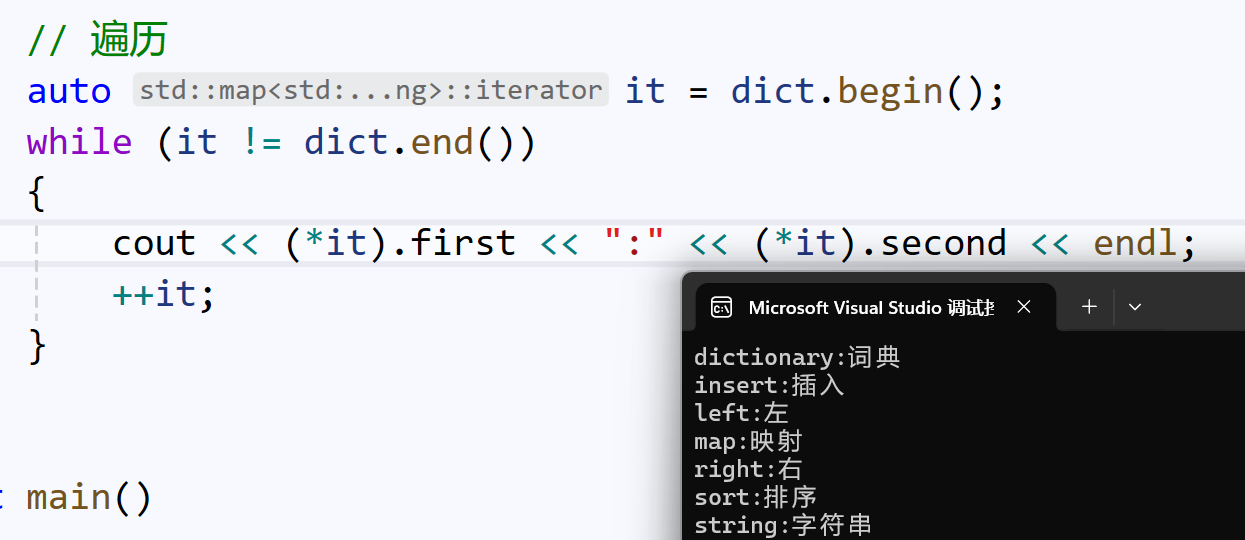
我们还可以使用之前学过的重载-> 。
it->first其实转换成了it.operator->()->first。operator->返回的是迭代器指向的节点的地址,再由这个节点地址,通过结构体成员访问操作符->,访问到first, second:
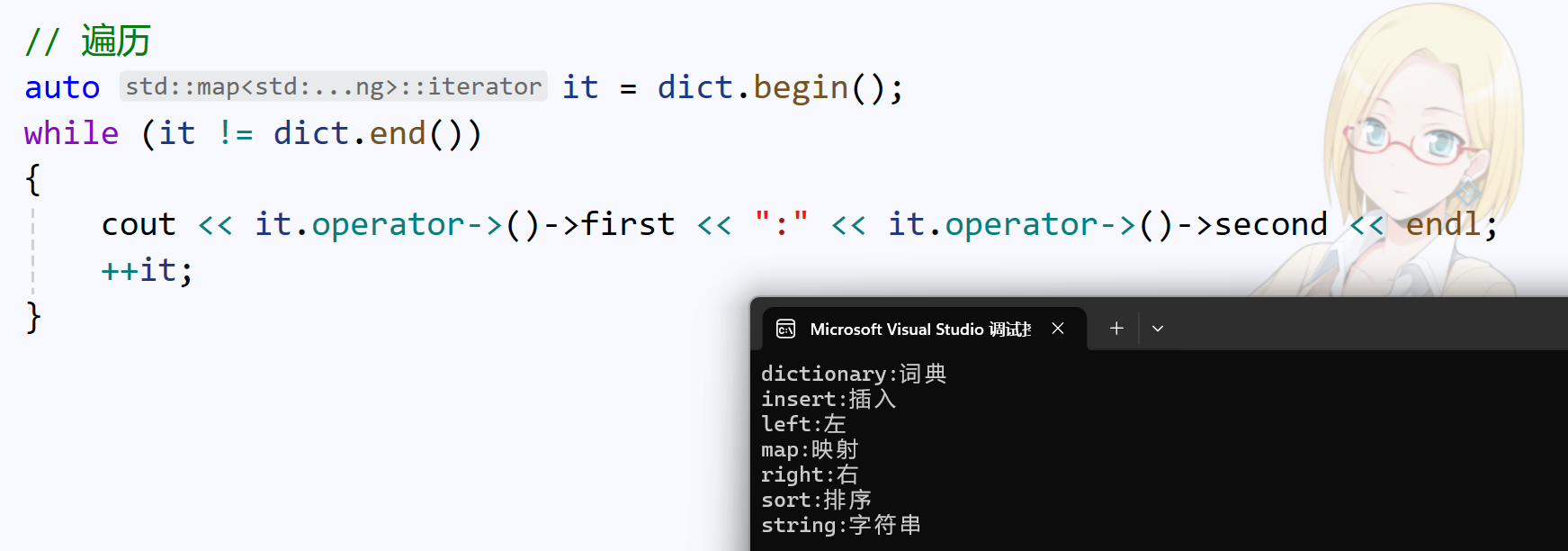
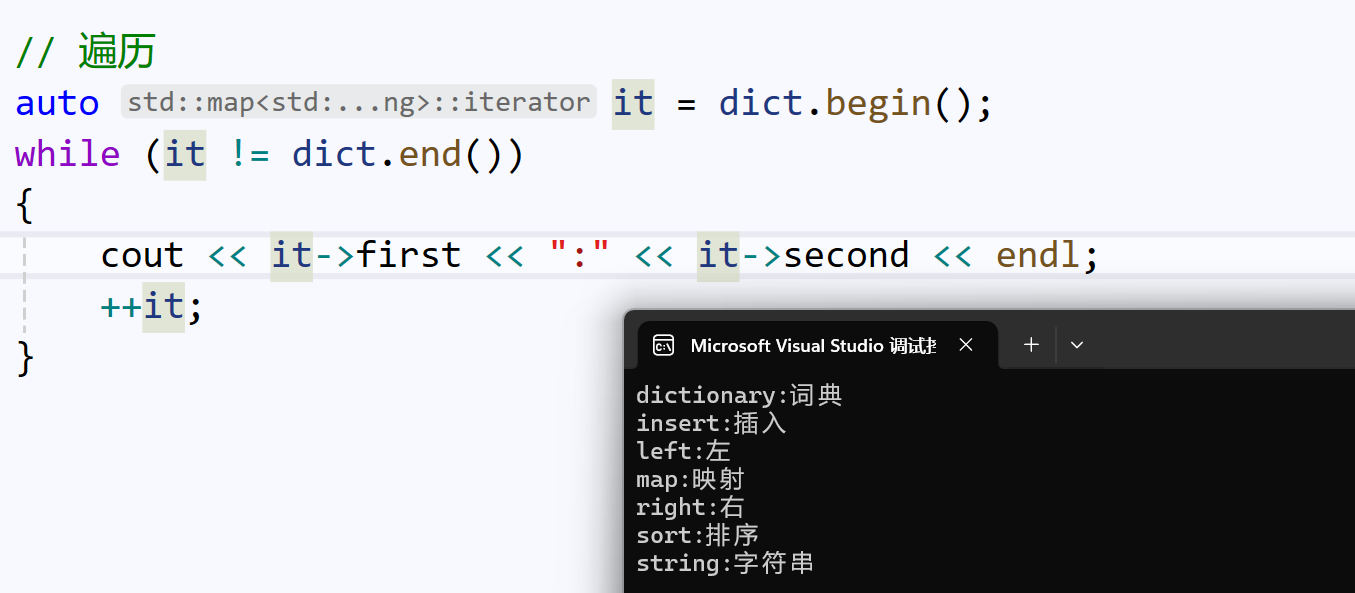
重载->是访问map成员的重要方式。
map支持迭代器,所以我们可以使用范围for:
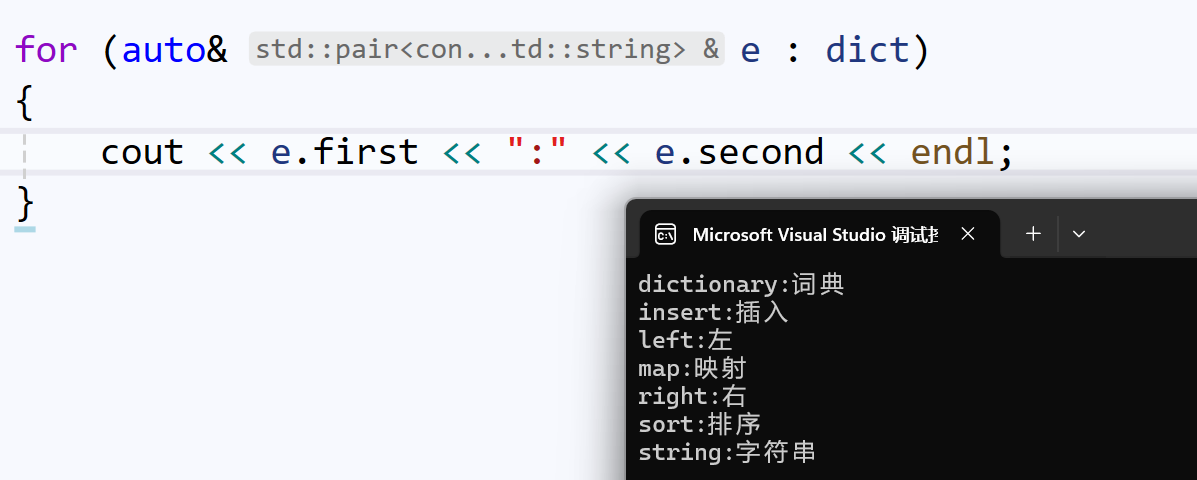
C++17有一种更便捷的语法,结构化绑定:
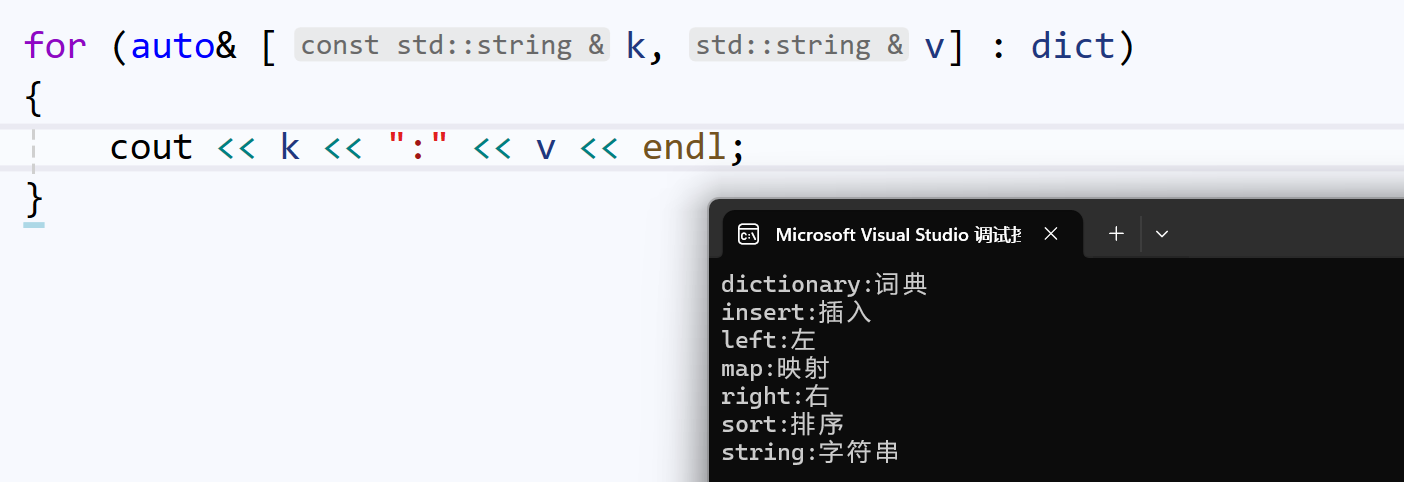
我们可以初步理解为:
- k绑定了dict中,每一个pair<string, string>类对象的成员first
- v绑定了每一个pair<string, string>类对象的成员second
既能用传值,又能用传引用的地方,一定优先传引用!!!!!!!!!!
5.5、重载\[\](难点)
我们在学习数据结构vector的时候就了解过,重载\[\]实现的一般是下标的随机访问,适合底层存储空间连续的结构。
但是map的底层存储空间是不连续的,这意味着map的重载\[\]的作用可能不一样。实际上,map的重载\[\]实现了多重功能。
我们看一段map的简单使用场景,即统计单词出现的次数:
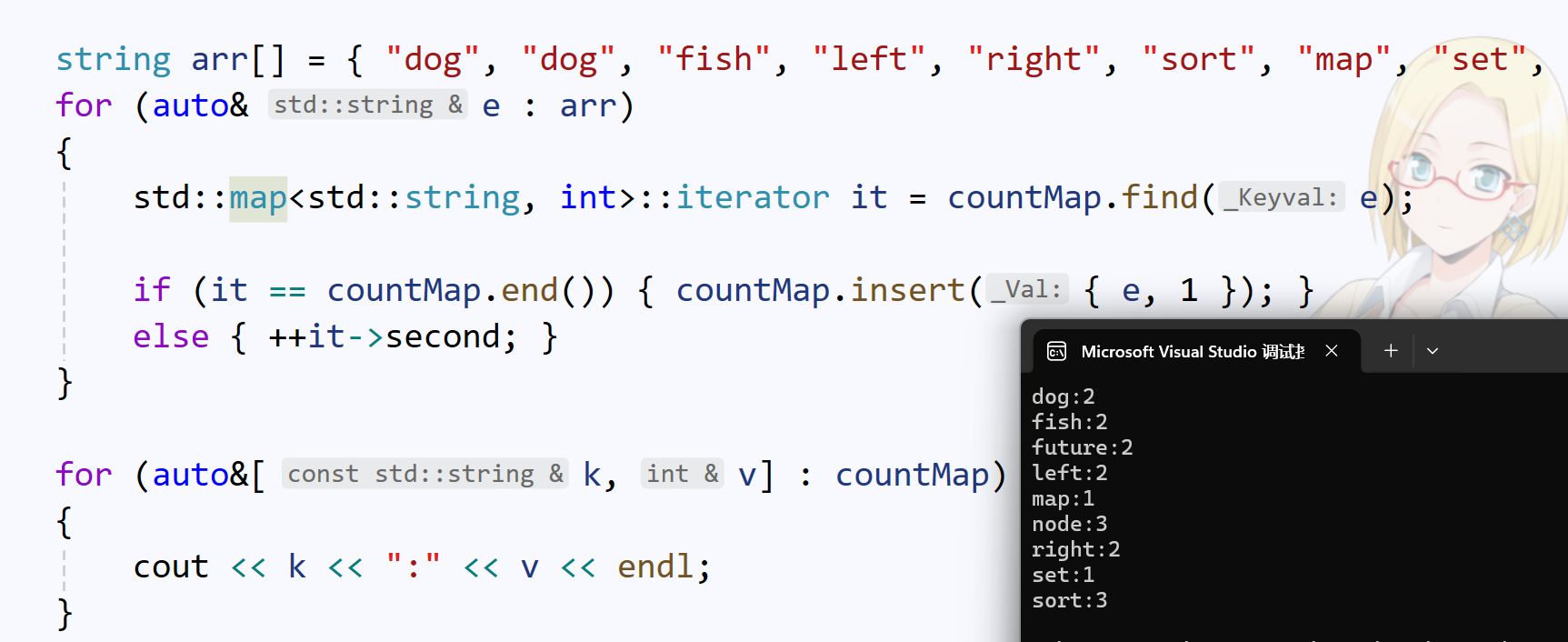
我们写了一堆东西:
- 遍历文本,定义迭代器寻找每个单词是否出现在文章中
- 如果未出现,即it走到
countMap.end(),就插入这个单词,和出现次数:1 - 如果出现,++出现次数
- 如果未出现,即it走到
但是,我们使用重载\[\],仅仅用了一句代码:
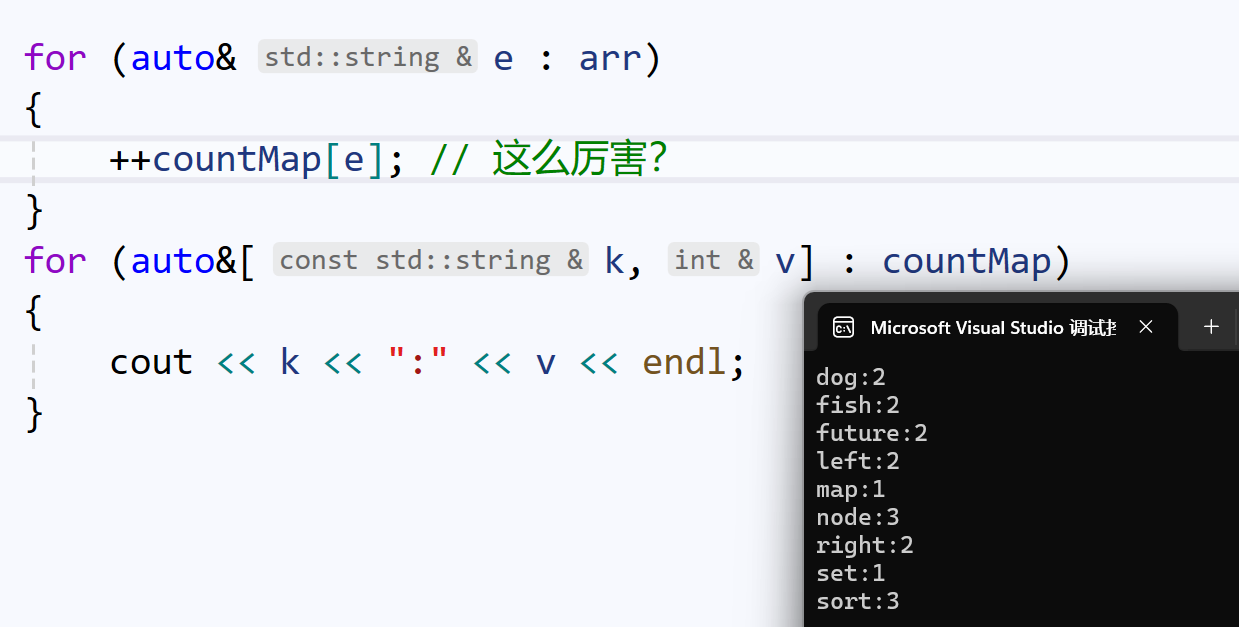
就完成了上面3句代码的工作。
根据之前的学习,我们能理解:如果单词是在countMap里存在的,我们可以猜测,通过在重载\[\]输入单词,就可以返回出现次数,此时我们进行++修改出现次数。
但如果单词没有出现在countMap里呢?我们就必须好好深入理解map的重载\[\]。
5.5.1、重载\[\]的理解
C++官方文档给了一句代码,以描述map重载\[\]的功能:
cpp
(*((this->insert(make_pair(k,mapped_type()))).first)).second在map类域中,重载\[\]不管三七二十一,直接进行insert()插入操作:
- 插入的是一个make_pair返回的pair对象
- make_pair自动识别了key值类型与value值类型,返回的是
pair<key_type, mapped_type>对象 - pair<key_type, mapped_type>对象的存储:
- first:传入重载\[\]的key值的对象
- second:是一个mapped_type()匿名对象,编译器可能初始化成0
- make_pair自动识别了key值类型与value值类型,返回的是
由于map不支持插入相同key值的pair,所以insert()插入操作可能成功,也可能失败。但insert()都会返回另一个pair对象:

我们假设这个由insert返回的pair为:pair_for_insert。
insert()插入操作,可能成功,也可能失败:
- 插入成功,pair_for_insert 存储:
- first:指向被插入的这个pair节点的迭代器
- second:true
- 插入失败,说明map对象中已有存储相同key值的pair节点,pair_for_insert 存储:
- first:指向已经存在的相同key值pair节点的迭代器
- second:false
那么,再访问这个pair_for_insert的first,我们就找到了指向相同key值pair节点的迭代器,这个迭代器指向的pair节点,可能是新插入map对象的,也可能是已经存在于map对象中的。
我们再解引用这个迭代器,拿到这个map对象中的pair节点;访问second,就访问到了key值对应的value值。
5.5.2、重载\[\]的使用
看到这,我们就能理解,其实重载\[\]完成了两个操作,查找 和插入:
- 如果存对应key值的pair节点不存在(重载\[\]方法查找不到),重载\[\]就插入一个存key值的pair节点,这个pair节点的value值默认被初始化,然后返回这个value值
- 如果存对应key值的pair节点存在,重载\[\]就查找到这个pair节点,返回其存储的value值
那么重载\[\]就有4个作用:
插入:

插入+修改:
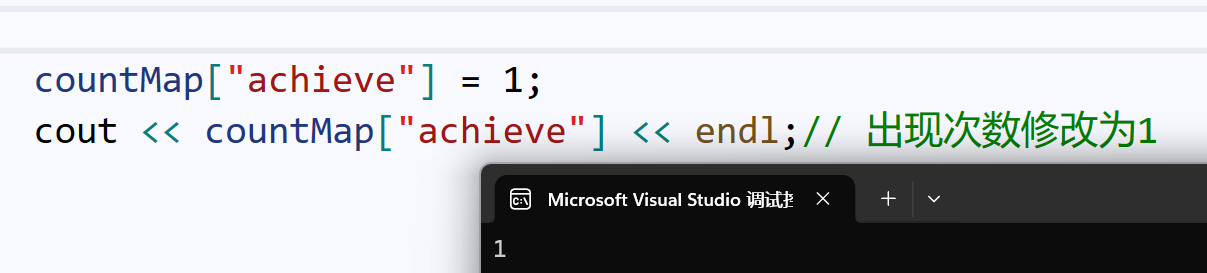
修改:

查找:

5.6、at
由于我们还未接触到"异常",所以我们对于at只做简单了解。
相比重载\[\],at的作用,就是纯粹的查找+修改:
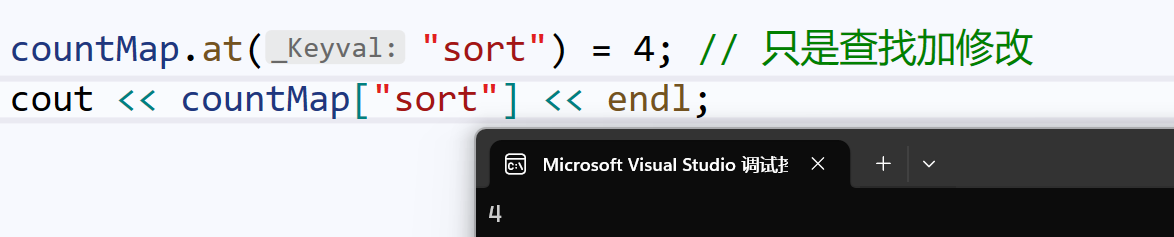
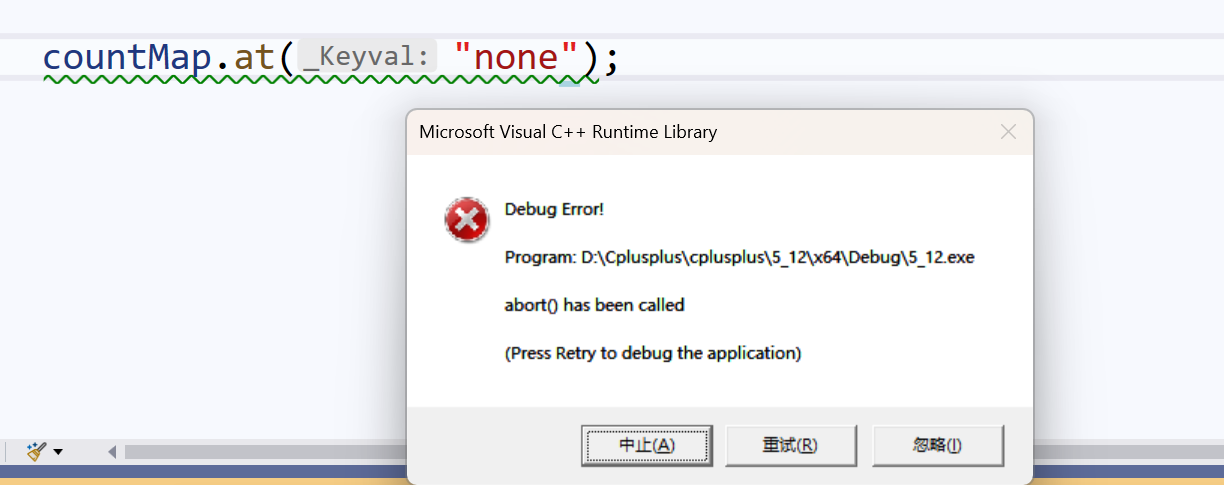
但是,如果使用at查找从未出现的单词,会抛异常:
6、multimap的简单提及
multimap支持插入多个相同key值,意味着multimap的插入操作永远成功。
也意味着,multimap树中可以有多个存相同key值的pair节点,这些pair节点的value可以相同,也可以不同。
但是,multimap不支持重载\[\]。可能的原因是:multimap只能找到中序第一个相同key所在的pair节点,接下来的相同key的pair节点就找不到了。