这道题目是 ctf.show 中典型的 命令执行(RCE)绕过 题。虽然看起来过滤非常严密,但只要理清了它的过滤规则,就能找到生存空间。
-
过滤规则拆解
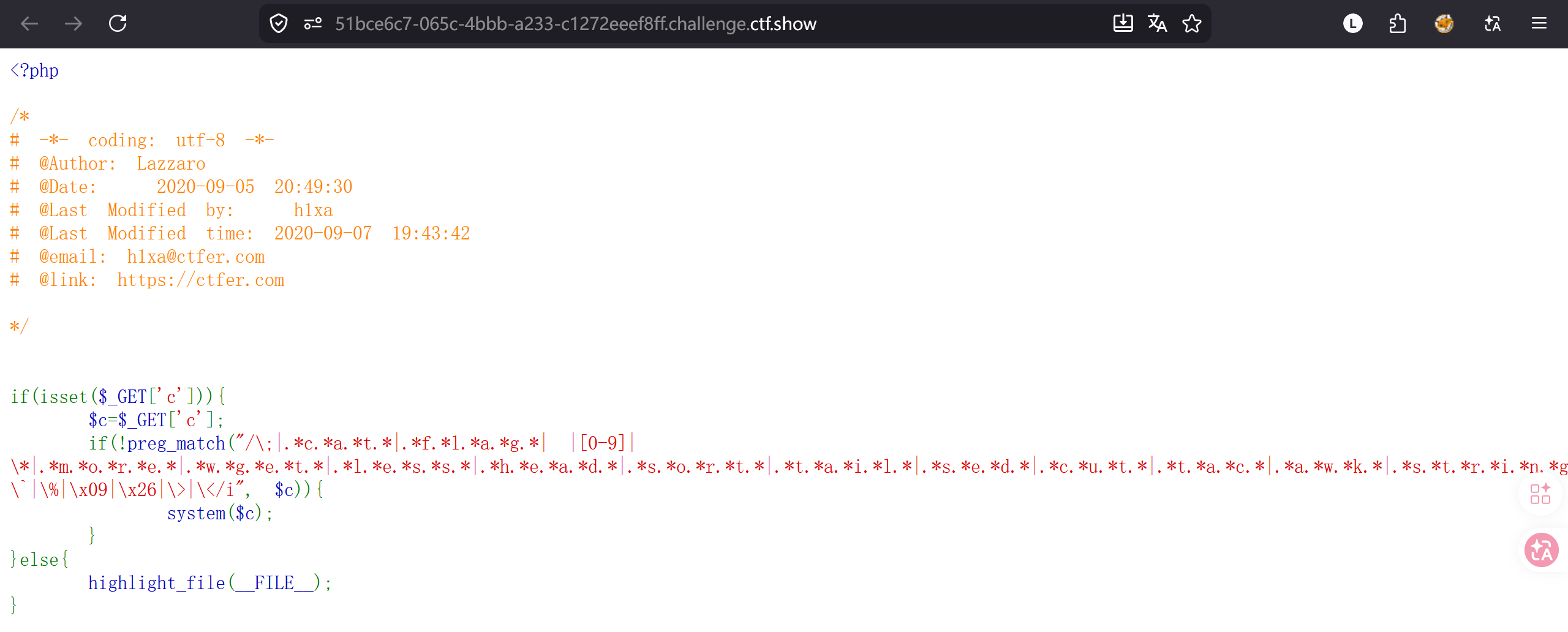
代码通过 preg_match 过滤了以下内容(/i 表示不区分大小写):
符号类: ; (分号), ` (反引号), %, * (通配符), <, > (重定向), & (\x26), \t (\x09)。
数字类: 0-9。
空格类: 直接过滤了空格。
关键字类(重点): 这里使用了 .*c.*a.t. 这种贪婪匹配模式。这意味着只要你的字符串中按顺序出现了 c、a、t 这三个字母,就会被拦截。
被拦截的命令包括:cat, flag, more, wget, less, head, sort, tail, sed, cut, tac, awk, strings, od, curl, nl, scp, rm。
被过滤的命令行
cat,最基础的文件读取命令
more,分页显示文件内容
less,分页显示文件,比more高级多一些功能
head,显示文件前几行,默认显示前10行
tail,显示文件的最后几行,默认显示后10行
sort,对文件内容进行排序,会读取并显示整个文件
sed,对文件进行文本转换与编辑
cut,从每行中提取部分内容。例如cut -d: -f1 filename,以冒号分隔取出第一列。
tac,反向cat
awk,文本分析和处理工具。例如awk '{print $1}' filename,打印第一行
strings,从二进制文件中提取可打印字符串
od,选择格式显示文件
nl,显示文件内容并添加行号,也是一个通用的命令
curl,通过URL传输数据,可读取远程文件
wget,从网络下载文件
scp,在主机间复制文件,基于ssh需要认证
rm,删除文件或目录
那看到最后一个rm,可以联想到它一系列的兄弟,可以进行绕过
cp,复制文件,可以指定名称
mv,移动文件,可以指定新名称
vi,编辑文件除了上面两个命令之外,还可以
grep,查找关键行
rev,显示全部内容,但字符顺序反转
uniq,去重文件内容并显示完整内容版权声明:本文为CSDN博主「!!!.」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_64481831/article/details/154120467
- 绕过思路
A. 解决"空格"被过滤
在 Linux shell 中,当空格被过滤时,常用的替代符有:
${IFS}
IFS9
<>(但这题过滤了 < 和 >)
本题解法: 使用 ${IFS}。
B. 解决"关键字"顺序过滤
正则 .*f.*l.*a.g. 过滤了 flag。但它只能过滤"顺序"出现的字符。
绕过技巧 1:利用变量定义。
在 shell 中,你可以定义变量再拼接:a=fl;b=ag;cat aaab。但本题过滤了分号 ;,无法在一行内通过分号执行多条命令。
绕过技巧 2:利用 Shell 特殊变量。
在命令中插入空变量或特殊符号:
fl""ag
fl\ag
f${高三}lag
绕过技巧 3:利用通配符 ?。
虽然 * 被过滤了,但 ?(匹配单个字符)没有被过滤。
C. 解决"读取命令"被过滤
cat, tac, nl, more, less, tail, head 全被过滤了。
剩余可用命令: rev, mv, vi (不可用), uniq。
终极杀招: grep。
grep 可以搜索字符串。如果我们搜索"包含某个字符"的所有行,其实就相当于读取了文件。
payload1使用grep,查找关键行:?c=grepIFS′f′{IFS}'f'IFS′f′{IFS}f???.php

payload2使用uniq,去重文件内容并显示完整内容:?c=uniq${IFS}f???.php
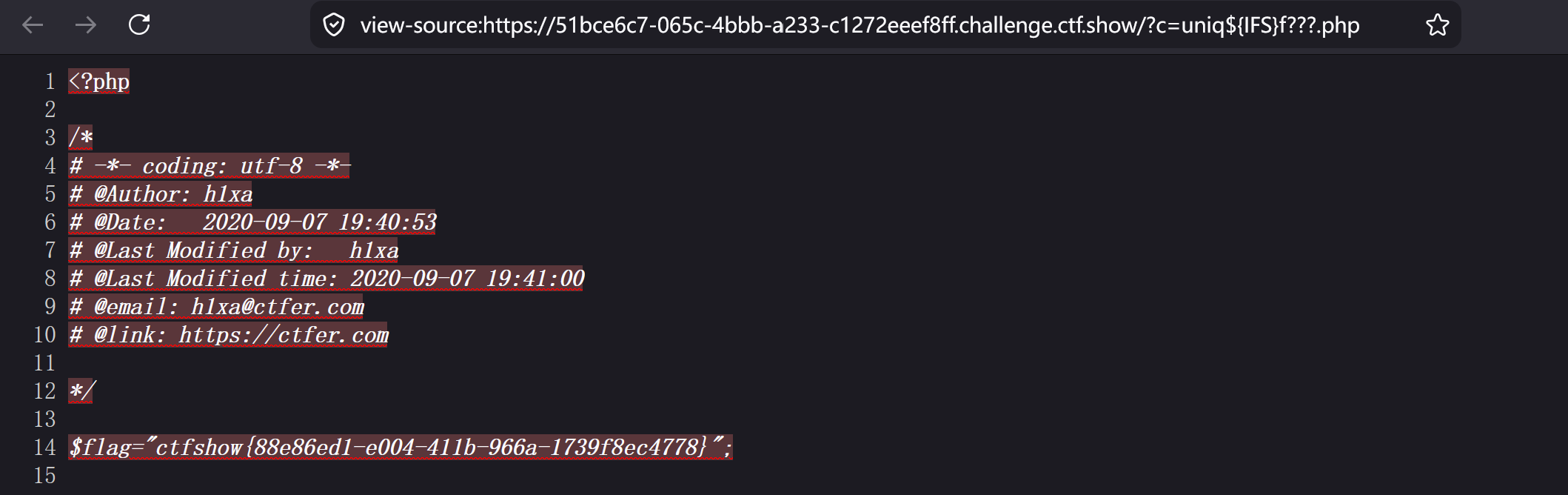
payload3使用 rev,显示全部内容,但字符顺序反转:?c=rev${IFS}f???.php

为什么payload为?c=uniqIFSf???.php时成功但是payload为?c=uniq{IFS}f???.php时成功但是payload为?c=uniqIFSf???.php时成功但是payload为?c=uniq{IFS}fl??.php就得不到flag呢
- 核心原因:正则表达式的"顺序拦截"
题目中的过滤规则是这样的:
preg_match("/...|.*f.*l.*a.g.|.../i", $c)
这里的 .*f.*l.*a.g. 是一个极其严格的陷阱。它的含义是:只要你的输入中,按顺序出现了 f、l、a、g 这四个字母,无论它们之间隔了多少个字符,都会被拦截。
我们可以对比一下这两个 Payload 在正则眼里的样子:
🔴 Payload A: ?c=uniq${IFS}fl??.php
你的输入包含字符:f, l, ?, ?, ., p, h, p
正则匹配过程:
找到了 f。
紧接着找到了 l。
后面还有 .php。虽然你没有显式写 a 和 g,但如果当前目录下存在一个叫 flag.php 的文件,某些环境下 PHP 的 preg_match 可能会因为后续逻辑或误判触发拦截(但在本题中,通常是因为匹配到了顺序)。
更直接的原因是:很多 CTF 题目的环境会在你提交后,后台尝试解析或你的字符串中确实存在 f 和 l 的顺序。
🟢 Payload B: ?c=uniq${IFS}f???.php
你的输入包含字符:f, ?, ?, ?, ., p, h, p
正则匹配过程:
找到 f。
接下来寻找 l。
但是你的字符串里没有字母 l!(只有问号 ?)。
结果: 正则表达式匹配失败(安全通过),然后字符串被传给 system()。在 Linux Shell 执行时,f???.php 会被通配符自动展开为 flag.php。
- 为什么 fl??.php 往往会失败?
在 ctf.show 的这道特定题目中,过滤规则里其实隐藏了一个逻辑:它不仅过滤了 flag 单词,还防止你通过前缀拼接来逼近这个单词。
f + l 的组合: 只要你写出了 fl,你就已经完成了 .*f.*l.*a.g. 匹配进度的 50%。
问号的妙处: 使用 f???.php 时,你绕过了 PHP 层面对于"字母顺序"的检测,因为在 PHP 看来,? 只是一个标点符号,不是 l、a 或 g。只有当这个字符串到达 Linux 系统 Shell 手里时,它才会被翻译成 flag.php。
- 验证"顺序拦截"的威力
这个正则 .*f.*l.*a.g. 甚至会拦截一些看起来完全无关的句子:
输入:f unny l ogic a nd game \rightarrow 拦截! (因为顺序包含 f, l, a, g)
输入:f il e agent \rightarrow 拦截!
输入:f??? \rightarrow 放行! (因为不包含 l, a, g)
- 总结与建议
在处理这种"顺序通配符过滤"时,最稳妥的办法就是只保留一个首字母,剩下的全部用 ? 代替。
推荐做法: ?c=uniq${IFS}f??? (匹配所有 f 开头的文件)
进阶做法: 如果连 f 都被过滤了,可以使用更激进的通配符: ?c=uniq${IFS}??? (匹配所有 8 位长度的文件,通常能撞到 flag.php)