本文档记录了基于 Amazon MSK(Managed Streaming for Apache Kafka)和 Amazon Glue Schema Registry (GSR) 的完整测试实践。通过实际操作验证了 GSR 如何实现 Schema 的自动注册、版本管理及兼容性控制,确保上游数据结构的演进不会破坏下游系统的稳定性。
核心概念与理论
Schema 是数据结构的版本化规范(versioned specification),定义了数据记录的结构和格式,用于可靠的数据发布、消费或存储。类似于数据库的表结构定义(DDL),但用于流数据场景。
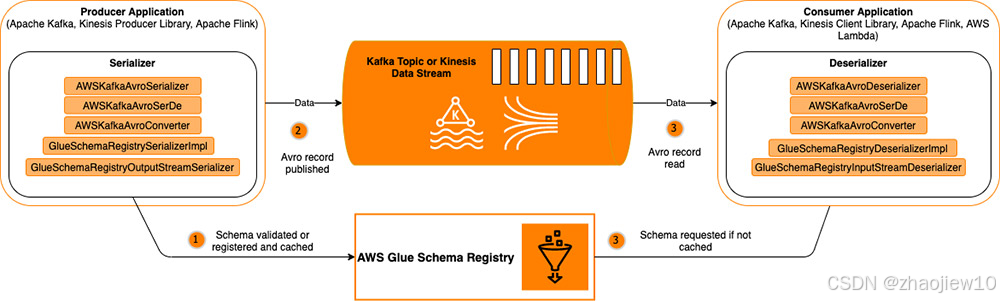
Glue Schema Registry (GSR) 是 AWS Glue 的无服务器功能,它使你能够在不额外收费的情况下,针对 Apache Avro 模式验证和可靠地演进流数据。主要解决的问题参考官方blog
With the Glue Schema Registry, you can eliminate defensive coding and cross-team coordination, improve data quality, reduce downstream application failures, and use a registry that is integrated across multiple AWS services. Each schema can be versioned within the guardrails of a compatibility mode, providing developers the flexibility to reliably evolve schemas. Additionally, the Glue Schema Registry can serialize data into a compressed format, helping you save on data transfer and storage costs.
序列化格式
Glue Schema Registry (GSR) 支持三种序列化格式:
| 格式 | 支持版本 | 说明 |
|---|---|---|
| AVRO | v1.11.4 | Apache Avro 二进制序列化格式 |
| JSON Schema | Draft-04/06/07 | 使用 Everit 库进行验证 |
| Protocol Buffers | proto2/proto3 | 不支持 extensions 和 groups |
三种格式的算则逻辑如下
- 选 AVRO:大数据/Kafka 生态、高吞吐、需要成熟的 schema 演进支持(Spark/Flink/Hive 原生支持 Avro)
- 选 JSON Schema:数据量不大、需要人类可读、快速原型验证、前后端交互场景
- 选 Protobuf:对性能和体积要求极高、已有 gRPC 微服务体系、跨语言调用多
| 维度 | AVRO | JSON Schema | Protobuf |
|---|---|---|---|
| 序列化大小 | 小(二进制) | 大(文本) | 最小(二进制) |
| 序列化速度 | 快 | 慢 | 最快 |
| 可读性 | 不可读 | 人类可读 | 不可读 |
| Schema 演进 | 原生支持,最成熟 | 支持 | 支持 |
| 生态兼容 | Kafka/Hadoop 生态首选 | Web/REST API 友好 | gRPC/微服务首选 |
| 学习成本 | 中等 | 低 | 较高(需写 .proto 文件) |
兼容性模式
当向注册中心提交 Schema 新版本时,兼容性规则决定是否接受该变更:
| 模式 | 含义 |
|---|---|
| NONE | 不做任何兼容性检查,任何变更都接受 |
| DISABLED | 完全禁止提交新版本 |
| BACKWARD | 新版本消费者能读取上一个版本的数据 |
| BACKWARD_ALL | 新版本消费者能读取所有历史版本的数据 |
| FORWARD | 上一个版本消费者能读取新版本的数据 |
| FORWARD_ALL | 所有历史版本消费者都能读取新版本的数据 |
| FULL | 同时满足 BACKWARD + FORWARD |
| FULL_ALL | 同时满足 BACKWARD_ALL + FORWARD_ALL |
假设当前 Schema V1 为:
{
"type": "record",
"name": "Person",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
}
]
}BACKWARD 模式示例
场景:新消费者(V2)读取旧数据(V1 格式)
-
V1 数据: {name:Alice,age:30}
-
允许的 V2 变更 --- 添加带 default 的字段:
V2 Schema: {name, age, income default:null}
V2 消费者读 V1 数据 → income 用 null 填充 → 正常工作
-
拒绝的 V2 变更 --- 添加不带 default 的必填字段:
V2 Schema: {name, age, income} (无 default)
V2 消费者读 V1 数据 → income 无值可填 → 报错
FORWARD 模式示例
场景:旧消费者(V1)读取新数据(V2 格式)
-
V1 Schema: {name, age, email default:unknown}
-
允许的 V2 变更 --- 删除带 default 的字段:
V2 Schema: {name, age} (删除 email)
V1 消费者读 V2 数据 → email 缺失,用 default unknown 填充 → 正常工作
-
拒绝的 V2 变更 --- 删除不带 default 的字段:
V2 Schema: {age, email} (删除 name,name 无 default)
V1 消费者读 V2 数据 → name 缺失且无 default → 报错
FULL 模式示例
同时满足 BACKWARD + FORWARD,即:
- 新增字段必须有 default(保证 BACKWARD)
- 删除字段在旧 schema 中必须有 default(保证 FORWARD)
场景
-
V1: {name, age, email default:unknown}
-
V2: {name, age, phone default:} --- 删除 email(有default) + 添加 phone(有default)
-
V2: {name, age, phone} --- 添加 phone 无 default,违反 BACKWARD
-
V2: {age, email} --- 删除 name 无 default,违反 FORWARD
*_ALL 变体
- BACKWARD 只检查与上一个版本的兼容性
- BACKWARD_ALL 检查与所有历史版本的兼容性
GSR 工作原理
总体架构图如下
注册 Schema
查询 Schema
Kafka Producer
(Java + GSR Serializer)
Amazon MSK
Topic: t1
Glue Streaming Job
(PySpark Consumer)
Glue Schema Registry
Registry: default-registry
Schema: t1
Version2: {name:string,age:int}
Version3: 新增income:number
生产者端(序列化 + 注册)
应用程序
(Producer)
GlueSchemaRegistryKafka
Serializer
Kafka
Broker
Glue Schema Registry
(注册/查询 Schema)
步骤 1:Schema 查找或注册
- 序列化器从数据对象中提取 Schema 定义(如 JsonDataWithSchema 中的 schema 字符串,或 GenericRecord 中的 Avro Schema)
- 先检查本地缓存是否已有该 Schema 的 Version ID
- 若缓存未命中,调用 glue:GetSchemaByDefinition 查询 GSR
- 若 Schema 不存在且开启了自动注册(SCHEMA_AUTO_REGISTRATION_SETTING=true),调用 glue:RegisterSchemaVersion 注册新版本
- 注册时 GSR 执行兼容性检查(根据 BACKWARD/FORWARD/FULL 等规则),不兼容则拒绝注册,返回 FAILURE 状态
- 注册成功后,GSR 返回 Schema Version ID(UUID),序列化器将其缓存(默认 24 小时)
步骤 2:数据验证
- 序列化器用 Schema 定义验证待发送的数据
- JSON 格式:使用 Everit 库校验 JSON 数据是否符合 JSON Schema 定义
- AVRO 格式:Avro 库自动校验 GenericRecord 是否符合 Schema 字段定义
- 验证失败则抛出 AWSSchemaRegistryException,数据不会发送到 Kafka
步骤 3:序列化 + 添加 Header + 投递
- 按数据格式序列化数据(JSON → UTF-8 字节,AVRO → 二进制编码)
- 可选压缩(ZLIB)
- 在序列化后的字节前面添加 18 字节 GSR Header
- 将完整的 payload(Header + 数据)作为 Kafka 消息的 value 发送
消息在 Kafka 中的存储格式
Kafka Message Value Layout:
Offset Length Field Description
0 1 Header Version 0x03
1 1 Compression Type 0=None, 5=ZLIB
2 16 Schema Version UUID 16 bytes
18 var Serialized Data PayloadGSR Header 结构(18 字节):
- Byte 0:Header Version(当前为 3)
- Byte 1:Compression 类型(0=无压缩,5=ZLIB)
- Bytes 2-17:Schema Version UUID(16 字节,标识该消息对应的 Schema 版本)
消费者端(反序列化 + 查询)
Kafka Broker
GlueSchemaRegistryKafka
Deserializer
应用程序
(Consumer)
Glue Schema Registry
(查询 Schema by Version ID)
步骤 4:解析 Header
- 反序列化器读取 payload 的前 18 字节
- 识别 Header Version(magic byte),确认这是 GSR 编码的消息
- 提取 Compression 类型和 Schema Version UUID
步骤 5:获取 Schema 定义
- 先检查本地缓存是否已有该 Version ID 对应的 Schema
- 若缓存未命中,调用 glue:GetSchemaVersion API,传入 Version ID
- GSR 返回完整的 Schema 定义(JSON Schema 字符串或 Avro Schema 字符串)
- 缓存该映射(默认 24 小时,最多 200 条)
步骤 6:反序列化数据
- 若消息有压缩,先解压(ZLIB)
- 用获取到的 Schema 定义反序列化 Bytes 18+ 的数据
- JSON 格式:返回 JsonDataWithSchema 对象(包含 schema + payload)
- AVRO 格式:返回 GenericRecord 或 SpecificRecord 对象
- 将反序列化后的对象交给应用程序处理
缓存机制
| 缓存位置 | 缓存内容 | 默认 TTL | 默认大小 |
|---|---|---|---|
| Producer | Schema Definition → Version ID | 24 小时 | 200 条 |
| Consumer | Version ID → Schema Definition | 24 小时 | 200 条 |
缓存减少了对 GSR API 的调用次数,提升吞吐量。可通过以下配置调整:
props.put(AWSSchemaRegistryConstants.CACHE_TIME_TO_LIVE_MILLIS, 86400000); // 24h
props.put(AWSSchemaRegistryConstants.CACHE_SIZE, 200);IAM 权限要求
生产者需要的权限:
glue:GetSchemaByDefinition--- 查找已有 Schemaglue:CreateSchema--- 创建新 Schema(自动注册时需要)glue:RegisterSchemaVersion--- 注册新版本glue:PutSchemaVersionMetadata--- 添加元数据
消费者需要的权限:
glue:GetSchemaVersion--- 根据 Version ID 获取 Schema 定义
测试环境配置
MSK 集群
集群名称: glueschema-test
集群 ARN: arn:aws-cn:kafka:cn-north-1:123456789012:cluster/glueschema-test/<cluster-uuid>
Kafka 版本: 3.5.1
Broker 数量: 2
实例类型: kafka.t3.small
存储: 10 GB EBS per broker
Bootstrap Servers (TLS):
b-1.<msk-cluster>.kafka.cn-north-1.amazonaws.com.cn:9094
b-2.<msk-cluster>.kafka.cn-north-1.amazonaws.com.cn:9094Kafka Topic
Topic 名称: t1
分区数: 1
副本因子: 2
创建命令:
kafka-topics.sh --create --topic t1 \
--bootstrap-server <bootstrap-servers>:9094 \
--partitions 1 --replication-factor 2 \
--command-config <(echo 'security.protocol=SSL')Glue Connection
json
{
"Name": "glueschema-msk-connection",
"ConnectionType": "KAFKA",
"ConnectionProperties": {
"KAFKA_BOOTSTRAP_SERVERS": "b-1.<msk-cluster>.kafka.cn-north-1.amazonaws.com.cn:9094,b-2.<msk-cluster>.kafka.cn-north-1.amazonaws.com.cn:9094",
"KAFKA_SSL_ENABLED": "true"
},
"PhysicalConnectionRequirements": {
"SubnetId": "subnet-0cccc3333private1a",
"SecurityGroupIdList": ["sg-0xxxxxxxxxxexample"],
"AvailabilityZone": "cn-north-1a"
}
}注意 :Glue Connection 的子网必须有 S3 VPC Endpoint 或 NAT Gateway,否则 Glue Job 启动时会报
VPC S3 endpoint validation failed错误。
IAM Role
角色名称: AWSGlueServiceRole-all
角色 ARN: arn:aws-cn:iam::123456789012:role/AWSGlueServiceRole-all
附加策略:
- AWSGlueServiceRole (AWS 托管)
- AmazonS3FullAccess (AWS 托管)
- AmazonKinesisFullAccess (AWS 托管)
- msk-gsr-access (自定义 inline policy)自定义 IAM Policy (msk-gsr-access)策略是必需的,因为 AWSGlueServiceRole 托管策略只包含 Glue 服务本身的权限,不包含访问 MSK 和 Schema Registry 所需的权限:
| 权限组 | 作用 | 为什么需要 |
|---|---|---|
| kafka-cluster:* | 连接 MSK 集群、读取 Topic 数据 | Glue Job 需要通过 IAM 认证连接 MSK 并消费消息 |
| kafka:Describe*/GetBootstrapBrokers | 获取 MSK 集群元数据 | Glue Connection 需要解析集群的 Bootstrap 地址 |
| glue:GetSchemaVersion/GetSchema/... | 读取 Schema Registry 中的 Schema | 反序列化器需要根据 Version ID 查询 Schema 定义 |
| ec2:CreateNetworkInterface/... | 管理 VPC 网络接口 | Glue Job 运行在 VPC 内,需要创建 ENI 连接到 MSK 所在子网 |
注意: 缺少 kafka-cluster 权限会导致连接超时;缺少 glue:GetSchemaVersion 会导致 AccessDeniedException;缺少 ec2 网络权限会导致 ENI 创建失败。
json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kafka-cluster:Connect",
"kafka-cluster:DescribeTopic",
"kafka-cluster:ReadData",
"kafka-cluster:DescribeGroup",
"kafka-cluster:AlterGroup"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": ["kafka:DescribeCluster", "kafka:GetBootstrapBrokers"],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"glue:GetSchemaVersion",
"glue:GetSchema",
"glue:ListSchemaVersions",
"glue:GetRegistry",
"glue:GetSchemaByDefinition"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"ec2:CreateNetworkInterface",
"ec2:DescribeNetworkInterfaces",
"ec2:DeleteNetworkInterface",
"ec2:DescribeVpcEndpoints",
"ec2:DescribeSubnets",
"ec2:DescribeSecurityGroups",
"ec2:DescribeRouteTables",
"ec2:DescribeVpcAttribute"
],
"Resource": "*"
}
]
}Glue Streaming Job
Job 名称: glueschema-kafka-consumer
Glue 版本: 4.0
Worker 类型: G.1X
Worker 数量: 2
脚本位置: s3://aws-glue-assets-123456789012-cn-north-1/scripts/glue-kafka-consumer.py
Connection: glueschema-msk-connection测试实践
项目依赖配置
pom.xml:
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>kafka-gsr-producer</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>software.amazon.glue</groupId>
<artifactId>schema-registry-serde</artifactId>
<version>1.1.5</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.11.4</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.5.1</version>
<executions>
<execution>
<phase>package</phase>
<goals><goal>shade</goal></goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.example.GsrProducer</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>JSON 格式:Producer 发送与 Schema 自动注册
验证 GSR 自动注册 JSON Schema,发送两个版本的数据到 topic t1。
GsrProducer.java:
java
package com.example;
import com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistryKafkaSerializer;
import com.amazonaws.services.schemaregistry.serializers.json.JsonDataWithSchema;
import com.amazonaws.services.schemaregistry.utils.AWSSchemaRegistryConstants;
import org.apache.kafka.clients.CommonClientConfigs;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.config.SslConfigs;
import org.apache.kafka.common.serialization.StringSerializer;
import software.amazon.awssdk.services.glue.model.DataFormat;
import software.amazon.awssdk.services.glue.model.Compatibility;
import java.util.Properties;
public class GsrProducer {
private static final String TOPIC = "t1";
private static final String REGION = "cn-north-1";
private static final String SCHEMA_V1 = "{\"$schema\":\"http://json-schema.org/draft-07/schema#\","
+ "\"type\":\"object\",\"properties\":{\"name\":{\"type\":\"string\"},\"age\":{\"type\":\"integer\"}},"
+ "\"required\":[\"name\",\"age\"]}";
private static final String SCHEMA_V2 = "{\"$schema\":\"http://json-schema.org/draft-07/schema#\","
+ "\"type\":\"object\",\"properties\":{\"name\":{\"type\":\"string\"},\"age\":{\"type\":\"integer\"},"
+ "\"income\":{\"type\":\"number\"}},\"required\":[\"name\",\"age\",\"income\"]}";
public static void main(String[] args) throws Exception {
String bootstrapServers = args[0];
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, GlueSchemaRegistryKafkaSerializer.class.getName());
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SSL");
props.put(SslConfigs.SSL_TRUSTSTORE_LOCATION_CONFIG, "/usr/lib/jvm/java-17-amazon-corretto.x86_64/lib/security/cacerts");
props.put(SslConfigs.SSL_TRUSTSTORE_PASSWORD_CONFIG, "changeit");
props.put(AWSSchemaRegistryConstants.AWS_REGION, REGION);
props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.JSON.name());
props.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, "true");
props.put(AWSSchemaRegistryConstants.COMPATIBILITY_SETTING, Compatibility.NONE.name());
props.put(AWSSchemaRegistryConstants.REGISTRY_NAME, "default-registry");
props.put(AWSSchemaRegistryConstants.SCHEMA_NAME, TOPIC);
try (KafkaProducer<String, JsonDataWithSchema> producer = new KafkaProducer<>(props)) {
JsonDataWithSchema v1 = JsonDataWithSchema.builder(SCHEMA_V1, "{\"name\":\"Alice\",\"age\":30}").build();
producer.send(new ProducerRecord<>(TOPIC, "key1", v1)).get();
System.out.println("V1 sent successfully");
}
try (KafkaProducer<String, JsonDataWithSchema> producer = new KafkaProducer<>(props)) {
JsonDataWithSchema v2 = JsonDataWithSchema.builder(SCHEMA_V2, "{\"name\":\"Bob\",\"age\":25,\"income\":50000.0}").build();
producer.send(new ProducerRecord<>(TOPIC, "key2", v2)).get();
System.out.println("V2 sent successfully");
}
}
}要点: 必须使用 JsonDataWithSchema 对象将 Schema 定义和数据绑定在一起,序列化器会用 Schema 验证数据后再发送。
⚠️ 注意: 如果直接发送 byte\[\] 而不是 JsonDataWithSchema 对象,会报错:
AWSSchemaRegistryException: JSON data validation against schema failed. Caused by: ValidationException: #: expected type: JSONArray, found: String序列化器无法从 byte\[\] 中提取 JSON Schema 定义,必须用 JsonDataWithSchema.builder(schema, data).build() 包装。
执行日志:
Sending V1: {"name":"Alice","age":30}
V1 sent successfully - Schema Version 1 registered
Sending V2: {"name":"Bob","age":25,"income":50000.0}
V2 sent successfully - Schema Version 2 registered
Done! Check Glue Schema Registry for schema versions.**Schema Registry 验证结果:**V2 到V3 的演进体现了字段增加(新增 income),由于兼容性设为 NONE,直接接受。
| 版本 | Version ID | Schema 定义 |
|---|---|---|
| V1 | 2f19deb7-2446-4e85-90d7-4193b5be0deb | {"type":"array","items":{"type":"integer"}} |
| V2 | 7ab9823d-65eb-4682-bb54-6f0ce7b0f732 | {"type":"object","properties":{"name":{"type":"string"},"age":{"type":"integer"}},"required":["name","age"]} |
| V3 | e2c1d04a-fde9-4b2b-8e5c-efabc0fb6fe0 | {"type":"object","properties":{"name":{"type":"string"},"age":{"type":"integer"},"income":{"type":"number"}},"required":["name","age","income"]} |
JSON 格式:Java Consumer(GSR 原生反序列化)
验证 GlueSchemaRegistryKafkaDeserializer 自动从消息 header 中提取 Schema Version ID → 查询 GSR → 反序列化。
GsrConsumer.java:
java
package com.example;
import com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryKafkaDeserializer;
import com.amazonaws.services.schemaregistry.serializers.json.JsonDataWithSchema;
import com.amazonaws.services.schemaregistry.utils.AWSSchemaRegistryConstants;
import org.apache.kafka.clients.CommonClientConfigs;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.config.SslConfigs;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class GsrConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, args[0]);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "gsr-consumer-test");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, GlueSchemaRegistryKafkaDeserializer.class.getName());
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SSL");
props.put(SslConfigs.SSL_TRUSTSTORE_LOCATION_CONFIG, "/usr/lib/jvm/java-17-amazon-corretto.x86_64/lib/security/cacerts");
props.put(SslConfigs.SSL_TRUSTSTORE_PASSWORD_CONFIG, "changeit");
props.put(AWSSchemaRegistryConstants.AWS_REGION, "cn-north-1");
try (KafkaConsumer<String, JsonDataWithSchema> consumer = new KafkaConsumer<>(props)) {
consumer.subscribe(Collections.singletonList("t1"));
int emptyPolls = 0;
while (emptyPolls < 3) {
ConsumerRecords<String, JsonDataWithSchema> records = consumer.poll(Duration.ofSeconds(5));
if (records.isEmpty()) { emptyPolls++; continue; }
emptyPolls = 0;
for (ConsumerRecord<String, JsonDataWithSchema> record : records) {
System.out.println("Key: " + record.key());
System.out.println("Schema: " + record.value().getSchema());
System.out.println("Payload: " + record.value().getPayload());
}
}
}
}
}要点: 消费者只需配置 GlueSchemaRegistryKafkaDeserializer 和 AWS_REGION,不需要预先知道 schema 定义。反序列化器自动从消息 header 中的 Version ID 查询 GSR。
执行日志:
Consuming from topic: t1
---
Key: key1
Schema: {"$schema":"http://json-schema.org/draft-07/schema#","type":"object","properties":{"name":{"type":"string"},"age":{"type":"integer"}},"required":["name","age"]}
Payload: {"name":"Alice","age":30}
Offset: 0
---
Key: key2
Schema: {"$schema":"http://json-schema.org/draft-07/schema#","type":"object","properties":{"name":{"type":"string"},"age":{"type":"integer"},"income":{"type":"number"}},"required":["name","age","income"]}
Payload: {"name":"Bob","age":25,"income":50000.0}
Offset: 1
Done - no more records.分析: 每条消息自带其对应版本的 schema。key1 返回 V2 schema(name+age),key2 返回 V3 schema(name+age+income)。消费者无需硬编码 schema,GSR 反序列化器全自动处理。
JSON 格式:Glue Streaming Job 消费(PySpark)
目标: 在 PySpark 环境中消费 GSR 编码的 Kafka 数据。
限制: Spark Structured Streaming 的 Kafka source 内部硬编码使用
ByteArrayDeserializer,不支持自定义 Kafka Deserializer。因此 PySpark 环境中无法直接使用GlueSchemaRegistryKafkaDeserializer,需要手动处理 GSR header。
python
import sys
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import col, from_json, expr
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
json_schema = StructType([
StructField("name", StringType(), True),
StructField("age", IntegerType(), True),
StructField("income", DoubleType(), True)
])
raw_df = spark.readStream.format("kafka") \
.option("kafka.bootstrap.servers", "<bootstrap-servers>:9094") \
.option("kafka.security.protocol", "SSL") \
.option("subscribe", "t1") \
.option("startingOffsets", "earliest").load()
# GSR header: 18 bytes (1 version + 1 compression + 16 UUID)
# Skip header, parse JSON
parsed_df = raw_df.select(
col("key").cast("string").alias("key"),
expr("substring(value, 19)").cast("string").alias("json_value"),
col("offset"), col("timestamp")
).withColumn("data", from_json(col("json_value"), json_schema)).select(
col("key"), col("data.name").alias("name"),
col("data.age").alias("age"), col("data.income").alias("income"),
col("offset"), col("timestamp")
)
query = parsed_df.writeStream.outputMode("append").format("json") \
.option("path", "s3://<bucket>/output/") \
.option("checkpointLocation", "s3://<bucket>/checkpoint/") \
.trigger(once=True).start()
query.awaitTermination()
job.commit()执行结果(S3 输出):
json
{"key":"key1","name":"Alice","age":30,"offset":0,"timestamp":"2026-05-11T14:11:12.899Z"}
{"key":"key2","name":"Bob","age":25,"income":50000.0,"offset":1,"timestamp":"2026-05-11T14:11:14.215Z"}Glue Job 运行详情:
json
{
"JobRunState": "SUCCEEDED",
"ExecutionTime": 79,
"WorkerType": "G.1X",
"NumberOfWorkers": 2,
"GlueVersion": "4.0"
}分析: V1 数据(Alice)没有 income 字段,解析为 null;V2 数据(Bob)完整包含所有字段。不同版本的数据共存于同一 Topic,消费者使用 superset schema 兼容读取。
⚠️ 注意事项(Glue Streaming Job 开发):
Glue Kafka Source 不兼容 GSR Header: Glue 封装的 create_data_frame.from_options(connection_type= kafka, classification=json) 会尝试将 value 当纯 JSON 解析,但 GSR 序列化的数据前 18 字节是 header,导致解析失败(产生 jsonjsonjson 临时列)。解决方案是使用 Spark 原生 spark.readStream.format(kafka) 读取原始二进制,手动 substring(value, 19) 跳过 header。
AVRO 格式
使用 AVRO 格式发送和消费数据,验证 Schema 自动注册。
AVRO 与 JSON 的关键差异
| 差异点 | JSON | AVRO |
|---|---|---|
| 数据对象 | JsonDataWithSchema |
GenericRecord |
| Schema 定义 | JSON Schema (Draft-07) | Avro Schema (.avsc) |
| Consumer 额外配置 | 无 | 需要 AVRO_RECORD_TYPE |
| 兼容性演进 | 无 default 概念,规则宽松 | 依赖 default 值,规则严格 |
| 序列化结果 | 文本(可读) | 二进制(不可读) |
Schema 定义:
json
// V1: name + age
{"type":"record","name":"Person","fields":[
{"name":"name","type":"string"},
{"name":"age","type":"int"}
]}
// V2 (BACKWARD 兼容): 添加带 default 的字段
{"type":"record","name":"Person","fields":[
{"name":"name","type":"string"},
{"name":"age","type":"int"},
{"name":"income","type":["null","double"],"default":null}
]}Producer 代码片段:
java
props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.AVRO.name());
props.put(AWSSchemaRegistryConstants.COMPATIBILITY_SETTING, Compatibility.NONE.name());
Schema schemaV1 = new Schema.Parser().parse(SCHEMA_V1);
GenericRecord record = new GenericData.Record(schemaV1);
record.put("name", "Alice");
record.put("age", 30);
producer.send(new ProducerRecord<>(topic, "key1", record)).get();Consumer 代码片段:
java
// AVRO 消费者需要额外指定 AVRO_RECORD_TYPE
props.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName());
KafkaConsumer<String, GenericRecord> consumer = new KafkaConsumer<>(props);执行日志:
[BASIC] Sending V1: {"name": "Alice", "age": 30}
[BASIC] V1 sent successfully
[BASIC] Sending V2: {"name": "Bob", "age": 25, "income": 50000.0}
[BASIC] V2 sent successfully
[BASIC] Done! Schema auto-registered with NONE compatibility.消费验证:
[CONSUME] Reading from topic: avro-t1
Key=key1 Value={"name": "Alice", "age": 30} Schema=Person
Key=key2 Value={"name": "Bob", "age": 25, "income": 50000.0} Schema=Person
[CONSUME] Done.**** AVRO 反序列化器自动根据消息中的 Schema Version ID 获取对应 schema,将二进制数据还原为 GenericRecord 对象。两条消息使用不同版本的 schema,消费者均能正确解析。
AVRO 格式:BACKWARD 兼容性校验
BACKWARD 兼容意味着新版本消费者能读取旧版本数据。新增字段必须有 default 值,否则新消费者读旧数据时无法填充该字段。
V1 数据: {name: "Alice", age: 30}
V2 消费者读取:
- income 有 default:null → {name: "Alice", age: 30, income: null}
- income 无 default → 无法构造完整记录 添加带 default 的字段允许创建
java
// V2: 新增 income 字段,有 default: null
private static final String SCHEMA_V2_BACKWARD = "{"
+ "\"type\":\"record\",\"name\":\"Person\",\"fields\":["
+ "{\"name\":\"name\",\"type\":\"string\"},"
+ "{\"name\":\"age\",\"type\":\"int\"},"
+ "{\"name\":\"income\",\"type\":[\"null\",\"double\"],\"default\":null}"
+ "]}";执行日志:
[BACKWARD-OK] Registering V1 schema...
[BACKWARD-OK] V1 registered successfully
[BACKWARD-OK] Sending V2 (add field with default) - should PASS...
[BACKWARD-OK] V2 PASSED! New field with default is BACKWARD compatible.添加不带 default 的字段拒绝创建
java
// V2: 新增 income 字段,无 default
private static final String SCHEMA_V2_NOT_BACKWARD = "{"
+ "\"type\":\"record\",\"name\":\"Person\",\"fields\":["
+ "{\"name\":\"name\",\"type\":\"string\"},"
+ "{\"name\":\"age\",\"type\":\"int\"},"
+ "{\"name\":\"income\",\"type\":\"double\"}"
+ "]}";执行日志:
[BACKWARD-FAIL] Registering V1 schema...
[BACKWARD-FAIL] V1 registered successfully
[BACKWARD-FAIL] Sending V2 (add field WITHOUT default) - should FAIL...
[BACKWARD-FAIL] REJECTED as expected! Error: AWSSchemaRegistryException: Schema evolution check failed.
schemaVersionId 68bd4a73-81a6-450e-b1a5-0b319abeb867 is in FAILURE status.GSR 在 schema 注册阶段就拦截了不兼容的变更,生产者无法将数据写入 Kafka,从源头防止数据污染。
AVRO 格式:FORWARD 兼容性校验
FORWARD 兼容意味着旧版本消费者能读取新版本数据。删除字段时,旧 schema 中该字段必须有 default 值,否则旧消费者读新数据时无法填充缺失字段。
V2 数据: {name: "Bob", age: 25} (删除了 email)
V1 消费者读取:
- email 有 default:"unknown" → {name: "Bob", age: 25, email: "unknown"}
V2 数据: {age: 25, email: "bob@test.com"} (删除了 name)
V1 消费者读取:
- name 无 default → 无法构造完整记录删除带 default 的字段 → 允许
java
// V1: name + age + email(default:"unknown")
private static final String SCHEMA_V1_WITH_EMAIL = "{"
+ "\"type\":\"record\",\"name\":\"PersonFwd\",\"fields\":["
+ "{\"name\":\"name\",\"type\":\"string\"},"
+ "{\"name\":\"age\",\"type\":\"int\"},"
+ "{\"name\":\"email\",\"type\":\"string\",\"default\":\"unknown\"}"
+ "]}";
// V2: 删除 email
private static final String SCHEMA_V2_FORWARD_OK = "{"
+ "\"type\":\"record\",\"name\":\"PersonFwd\",\"fields\":["
+ "{\"name\":\"name\",\"type\":\"string\"},"
+ "{\"name\":\"age\",\"type\":\"int\"}"
+ "]}";执行日志:
[FORWARD-OK] Registering V1 schema (name+age+email)...
[FORWARD-OK] V1 registered successfully
[FORWARD-OK] Sending V2 (remove email which has default) - should PASS...
[FORWARD-OK] V2 PASSED! Removing field with default is FORWARD compatible.删除不带 default 的字段 → 拒绝
java
// V2: 删除 name(V1 中 name 无 default)
private static final String SCHEMA_V2_FORWARD_FAIL = "{"
+ "\"type\":\"record\",\"name\":\"PersonFwd\",\"fields\":["
+ "{\"name\":\"age\",\"type\":\"int\"},"
+ "{\"name\":\"email\",\"type\":\"string\",\"default\":\"unknown\"}"
+ "]}";执行日志:
[FORWARD-FAIL] Registering V1 schema (name+age+email)...
[FORWARD-FAIL] V1 registered successfully
[FORWARD-FAIL] Sending V2 (remove name which has NO default) - should FAIL...
[FORWARD-FAIL] REJECTED as expected! Error: AWSSchemaRegistryException: Schema evolution check failed.
schemaVersionId 590e02a9-216c-4fb0-9a54-696409cf5e41 is in FAILURE status.FORWARD 模式保护了旧消费者不受新 schema 变更的影响。
兼容性校验总结
| 兼容性模式 | 允许的操作 | 拒绝的操作 | 保护对象 |
|---|---|---|---|
| BACKWARD | 添加带 default 的字段 | 添加不带 default 的字段 | 新消费者读旧数据 |
| FORWARD | 删除带 default 的字段 | 删除不带 default 的字段 | 旧消费者读新数据 |
| FULL | 两者都满足 | 两者都检查 | 双向兼容 |
AVRO 中 default 的作用:
| 场景 | default 的角色 |
|---|---|
| BACKWARD + 加字段 | 新消费者读旧数据时,用 default 填充缺失的新字段 |
| FORWARD + 删字段 | 旧消费者读新数据时,用 default 填充缺失的旧字段 |
| FULL | 所有新增/删除的字段都必须有 default |
这就是为什么 AVRO 的兼容性规则比 JSON Schema 更严格,AVRO 是强类型二进制格式,必须能构造出完整的记录对象,而 JSON 可以简单地忽略未知字段或返回 null。