RNN介绍
| 对比维度 | 普通前馈神经网络(基础 NN) | 卷积神经网络(CNN) | 循环神经网络(RNN) |
|---|---|---|---|
| 核心概念 | 最基础神经网络,由输入层、全连接隐藏层、输出层组成;层间全连接,只处理相互独立无关联的数据,无记忆、无自动特征提取能力。 | 以卷积运算为核心的网络,新增卷积层、池化层;依靠局部连接、权值共享自动提取空间特征,专门处理图像类网格结构数据。 | 具有记忆循环结构的神经网络,隐藏层会保存上一时刻状态;能记忆前文时序信息,专门处理有先后顺序的序列数据。 |
| 核心结构 | 全连接层堆叠,信号单向传递 | 卷积层 + 池化层 + 全连接层,局部连接、权值共享 | 隐藏层内部带循环反馈,时刻之间状态传递 |
| 数据流向 | 输入→隐藏→输出,单向无循环 | 输入→卷积→池化→全连接→输出,单向 | 按时序循环:当前输入 + 上一时刻隐藏状态 共同计算 |
| 核心能力 | 简单非线性拟合,做基础数据分类回归 | 自动提取图像边缘、纹理、空间特征 | 记忆历史信息,捕捉前后时序依赖关系 |
| 适用数据 | 表格数据、独立样本、一维向量 | 图像、视频、二维网格数据 | 文本、语音、时间序列、连续时序数据 |
| 关键特点 | 全连接、无记忆、参数量大、易过拟合 | 局部连接、参数少、特征自动提取、专注空间信息 | 有记忆、能上下文关联、可处理变长序列 |
专门处理有先后顺序、前后有关系的序列数据,自带记忆功能,能记住前面的信息,用来影响后面的判断。
主要用途
自然语言处理
分词、翻译、聊天机器人、情感分析、文本生成。
语音处理
语音转文字、语音识别、语音合成。
时间序列预测
股票走势、气温预测、销量预测、数据趋势预判。
连续时序数据
只要是按时间排队、前后有关联的数据,都能用 RNN。
一句话总结
普通神经网络认单独数据,CNN 认图片图像,
RNN 专门认有先后顺序、需要记前面内容的时序 / 文本数据。
自然语言处理概述
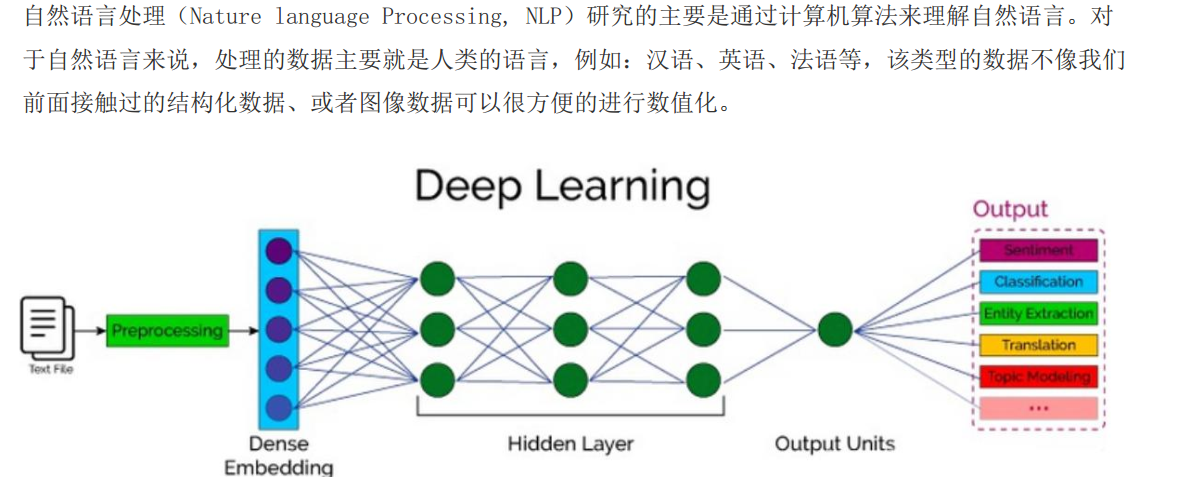
词嵌入式
把文本里的每个词,转换成低维稠密向量,作为 RNN 的输入,同时还能捕捉词和词之间的语义相似性。
三个关键作用
- 输入表示:把文字这种没法直接给 RNN 处理的符号,变成机器能计算的数字向量。
- 降低维度:不用稀疏的 one-hot 向量,而是用低维向量表示词,减少计算量。
- 捕捉语义 :语义相近的词,对应的向量也会很接近(比如
cat和mat的向量,会比cat和on更相似)
词嵌入层的工作流程
- 初始化词向量矩阵 :先根据词汇表的词数,构建一个词向量矩阵。比如有 100 个词,每个词用 4 维向量表示,矩阵就是
100×4的大小。每个词对应矩阵里的一行向量。 - 文本转索引:输入的句子先分词,每个词在词汇表里都有唯一的索引,把词转换成对应的索引数字。
- 索引查表得向量 :用每个词的索引,去词向量矩阵里 "查表",找到对应的向量。比如
cat的索引是 0,就取矩阵的第 0 行向量。 - 向量输入 RNN:这些查出来的词向量,作为 RNN 的输入,让 RNN 处理序列信息。
num_embeddings:词汇表里一共有多少个词(词的数量)。embedding_dim:每个词要转换成多少维的向量(比如 4 维、128 维)。
词嵌入(文本→向量)是 RAG 系统的 "匹配基础"。它的作用是把「用户问题」和「知识库文本」都转换成向量,让系统能通过向量相似度,快速找到和问题最相关的文档片段。
| 环节 | 词嵌入的角色 | RAG 匹配的作用 |
|---|---|---|
| 文本处理 | 把自然语言转成机器能算的向量 | 让语义相似的文本有可量化的 "距离" |
| 相似度匹配 | 提供向量空间中的位置信息 | 不用逐字比对,快速召回相关文档 |
| 大模型输入 | 统一问题和知识库的向量表示 | 保证匹配结果的语义一致性 |
词嵌入层使用
 接下来,我们将会学习如何将词转换为词向量,其步骤如下:
接下来,我们将会学习如何将词转换为词向量,其步骤如下:
- 先将语料进行分词,构建词与索引的映射,我们可以把这个映射叫做词表,词表中每个词都对应了一
个唯一的索引
- 然后使用 nn.Embedding 构建词嵌入矩阵,词索引对应的向量即为该词对应的数值化后的向量表示。
例如,我们的文本数据为:
"北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途

RNN网络原理
RNN 循环神经网络:带循环、有记忆 ,通过隐藏状态 h 存储历史序列信息,把前一时刻的记忆带到当前时刻,专门处理时序 / 序列数据(文本、语音、时间序列)。
每一瞬间 RNN 只干三件事:
- 带着上一秒的记忆 \(h_{t-1}\)
- 接收现在的新输入 \(x_t\)
- 两件东西合在一起:
- 刷新出新记忆 \(h_t\)(留给下一秒用)
- 给出当前的预测输出 \(y_t\)
循环往复,一直往下走。
比如读句子:我今天去公园
- 读到「我」:脑子记一下:主角是我
- 读到「今天」:脑子更新记忆:我 + 时间今天
- 读到「去」:再更新:我 今天 要去
- 读到「公园」:最后完整理解意思
RNN 的 h 就是你读句子时脑子里一直累计的上下文印象,每读一个字,就更新一次印象,同时理解当前字。
- 记东西:把前面的信息存下来,不丢
- 懂上下文:不是孤立看单个输入,结合前后理解
- 串起顺序:不管句子长短,都能一步步顺着顺序处理
记性短 !句子一长,最早的信息就慢慢忘了 ,记不住太远的内容,所以后来出了 LSTM、GRU,就是帮 RNN 加长记忆力的。
PyTorch RNN层的使用
RNN = torch.nn.RNN(input_size,hidden_size,num_layers)
参数意义是:
-
input_size:输入数据的维度,一般设为词向量的维度;
-
hidden_size:隐藏层h的维度,也是当前层神经元的输出维度;
-
num_layers: 隐藏层h的层数,默认为1. 将RNN实例化就可以将数据送入进行处理



在 PyTorch 的 RNN 里,hn 就是 初始隐藏状态,也就是你之前理解的那个「初始记忆」。
文本生成
导入工具包
导入周杰伦数据集
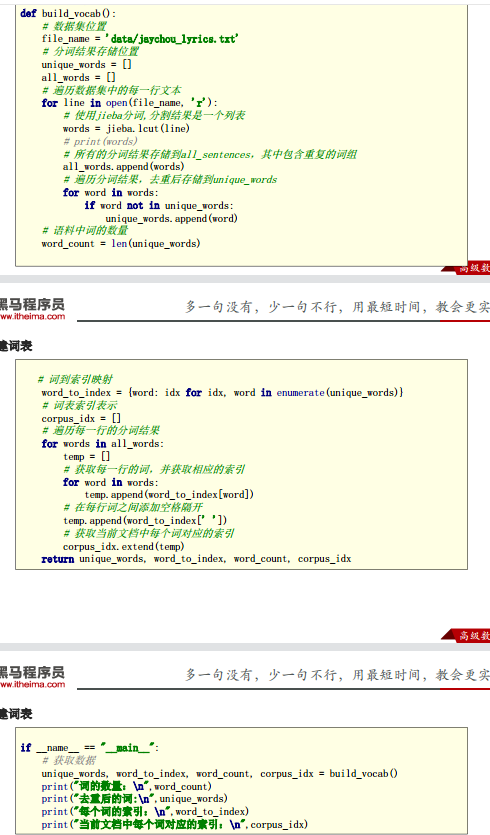
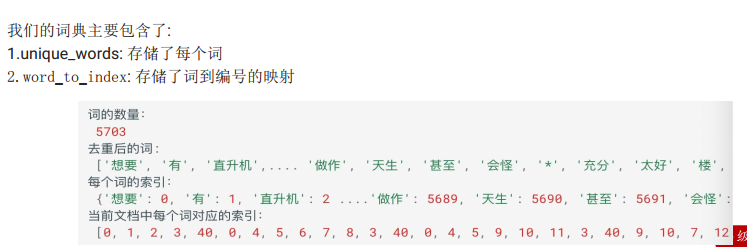
构建此表

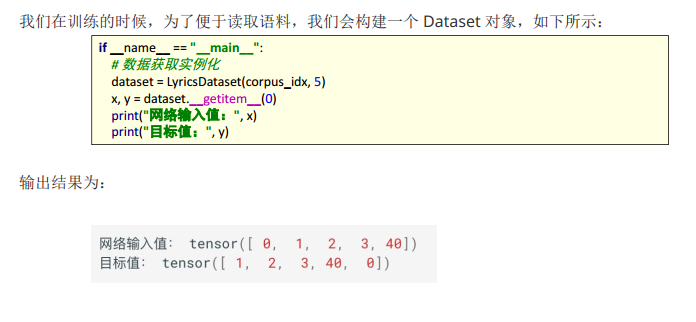
接下来, 我们对周杰伦歌词的数据进行处理构建词表,具体实现如下所示:
整体流程是:
l 获取文本数据
l 分词,并进行去重
构建词表
构建数据集对象
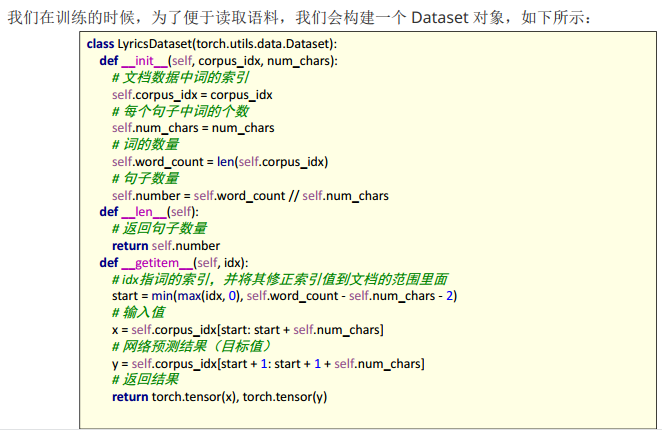
我们用于实现《歌词生成》的网络模型,主要包含了三个层:
-
词嵌入层: 用于将语料转换为词向量
-
循环网络层: 提取句子语义
-
全连接层: 输出对词典中每个词的预测概率
构建网络模型

构建训练函数
训练函数主要负责编写数据迭代、送入网络、计算损失、反向
传播、更新参数,其流程基本较为固定。
由于我们要实现文本生成,文本生成本质上,输入一串文本,预测下一个文本,也属于分类问题,所以,我们使用多
分类交叉熵损失函数。优化方法我们学习过 SGB、AdaGrad、Adam 等,在这里我们选择学习率、梯度自适应的 Adam
算法作为我们的优化方法。
训练完成之后,我们使用 torch.save 方法将模型持久化存储
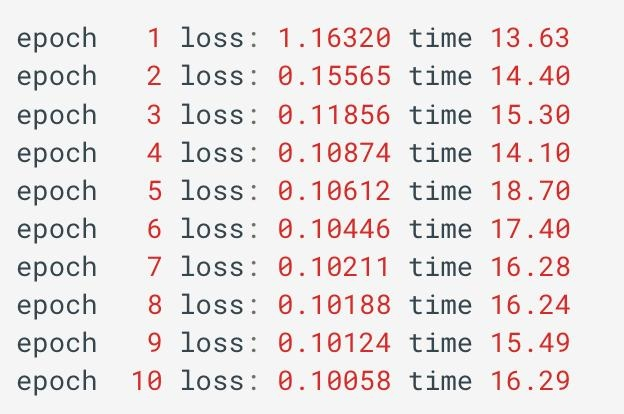
模型训练
def train():
构建词典
index_to_word, word_to_index, word_count, corpus_idx = build_vocab()
数据集
lyrics = LyricsDataset(corpus_idx, 32)
初始化模型
model = TextGenerator(word_count)
损失函数
criterion = nn.CrossEntropyLoss()
优化方法
optimizer = optim.Adam(model.parameters(), lr=1e-3)
训练轮数
epoch = 10
for epoch_idx in range(epoch):
数据加载器
lyrics_dataloader = DataLoader(lyrics, shuffle=True, batch_size=1)
训练时间
start = time.time()
iter_num = 0 # 迭代次数
训练损失
total_loss = 0.0
遍历数据集
for x, y in lyrics_dataloader:
隐藏状态的初始化
hidden = model.init_hidden(bs=1)
模型计算
output, hidden = model(x, hidden)
计算损失
y:batch,seq_len->seq_len,batch->seq_len\*batch
y = torch.transpose(y, 0, 1).contiguous().view(-1)
loss = criterion(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
iter_num += 1 # 迭代次数加1
total_loss += loss.item()
打印训练信息
print('epoch %3s loss: %.5f time %.2f' % (epoch_idx + 1, total_loss / iter_num, time.time() - start))
模型存储
torch.save(model.state_dict(), 'data/lyrics_model_%d.pth' % epoch)
if name == "main":
train()
构建预测函数
从磁盘加载训练好的模型,进行预测。预测函数,输入第一个指定的词,我们将该词输入网路,预测出下一个词,再
将预测的出的词再次送入网络,预测出下一个词,以此类推,知道预测出我们指定长度的内容。
def predict(start_word, sentence_length):
# 构建词典
index_to_word, word_to_index, word_count, _ = build_vocab()
# 构建模型
model = TextGenerator(word_count)
# 加载参数
model.load_state_dict(torch.load('data/lyrics_model_10.pth'))
# 隐藏状态
hidden = model.init_hidden()
# 将起始词转换为索引
word_idx = word_to_index[start_word]
# 产生的词的索引存放位置
generate_sentence = [word_idx]
# 遍历到句子长度,获取每一个词
for _ in range(sentence_length):
# 模型预测
output, hidden = model(torch.tensor([[word_idx]]), hidden)
# 获取预测结果
word_idx = torch.argmax(output)
generate_sentence.append(word_idx)
# 根据产生的索引获取对应的词,并进行打印
for idx in generate_sentence:
print(index_to_word[idx], end='')
if __name__ == "__main__":
# 调用预测函数
predict('分手', 50)输出结果:
分手的话像语言暴力
我已无能为力再提起 决定中断熟悉
然后在这里 不限日期
然后将过去 慢慢温习
让我爱上你 那场悲剧
是你完美演出的一场戏
总结
-
构建词汇表
-
构建数据对象
-
编写网络模型
-
编写训练函数
-
编写预测函数