一、引言
在 Flink 实时计算的世界里,流处理的本质可以概括为公式:实时流处理 = 业务逻辑 + 状态(State)。无论是窗口聚合、双流 Join 还是复杂的 CEP 模式匹配,都离不开状态管理。Flink 提供了两种基本的状态类型:Keyed State(键控状态) 和 Operator State(算子状态),本文将深入浅出地剖析这两者的底层机制、重分配策略,并给出实战中的最佳实践。

二、Keyed State(键控状态):基于 Key 的数据记忆
Keyed State 是与特定 Key 绑定的状态,只能在KeyedStream上下文中使用(即keyBy()之后)。每个 Key 拥有独立的状态实例,不同 Key 之间状态完全隔离。
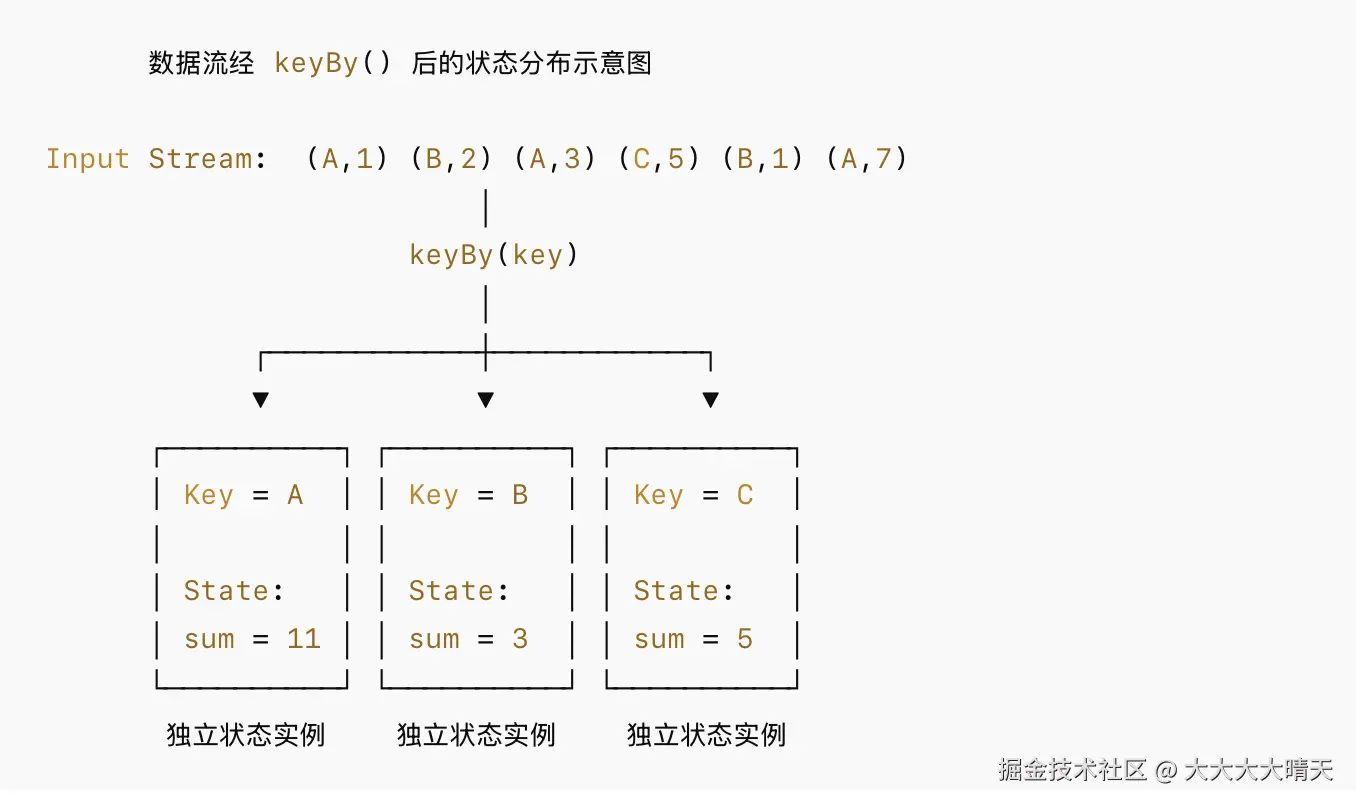
Keyed State支持以下数据结构:
| 状态类型 | 存储结构 | 典型场景 | 访问方式 |
|---|---|---|---|
| ValueState | 单值 | 最新状态跟踪、上次事件记录 | value() / update(v) |
| ListState | 列表 | 事件序列收集、窗口缓存 | add(v) / get() / clear() |
| MapState<UK, UV> | Map | 多维度指标统计、分组计数 | put(k,v) / get(k) / entries() |
| ReducingState | 单值(自动聚合) | 持续求和、求最值 | add(v) → 自动 reduce |
| AggregatingState<IN,OUT> | 单值(自动聚合) | 求平均值等复杂聚合 | add(v) → 自动 aggregate |
Keyed State 通过State Descriptor声明,在open()方法中通过RuntimeContext获取,示例如下:
scala
public class WordCountFunction extends KeyedProcessFunction<String, String, Tuple2<String, Long>> {
// 声明状态句柄
private transient ValueState<Long> countState;
@Override
public void open(OpenContext openContext) throws Exception {
// 通过 StateDescriptor 注册状态
ValueStateDescriptor<Long> descriptor =
new ValueStateDescriptor<>("word-count", Long.class, 0L);
// ① 可选:配置 State TTL(状态过期清理)
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Duration.ofHours(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(
StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
descriptor.enableTimeToLive(ttlConfig);
// ② 通过 RuntimeContext 获取状态实例
countState = getRuntimeContext().getState(descriptor);
}
@Override
public void processElement(String value,
Context ctx,
Collector<Tuple2<String, Long>> out) throws Exception {
Long currentCount = countState.value(); // 读取当前 Key 的状态
currentCount += 1;
countState.update(currentCount); // 更新当前 Key 的状态
out.collect(Tuple2.of(value, currentCount));
}
}在底层,Flink 并不会为每一个单独的 Key 维护一个独立的状态结构(那样元数据开销太大了),而是引入了 Key Group(键组) 的概念。Key Group 是 Flink 分发 Keyed State 的最小单元。
当作业的并发度发生改变(扩容或缩容)时,Keyed State 的重新分配是基于 Key Group 进行的。
- 分配公式:
KeyGroupId = MathUtils.murmurHash(key.hashCode()) % maxParallelism。 - 在扩缩容时,Flink 会将一个个完整的 Key Group 重新均匀分配给新的 Task 实例。
三、Operator State(算子状态):基于 Task 实例的全局记忆
Operator State(也称 Non-Keyed State)与算子的并行实例绑定,每个并行子任务(subtask)维护一份独立的状态,与数据的 Key 无关。一个 Task 实例处理的所有数据,共享同一个 Operator State。
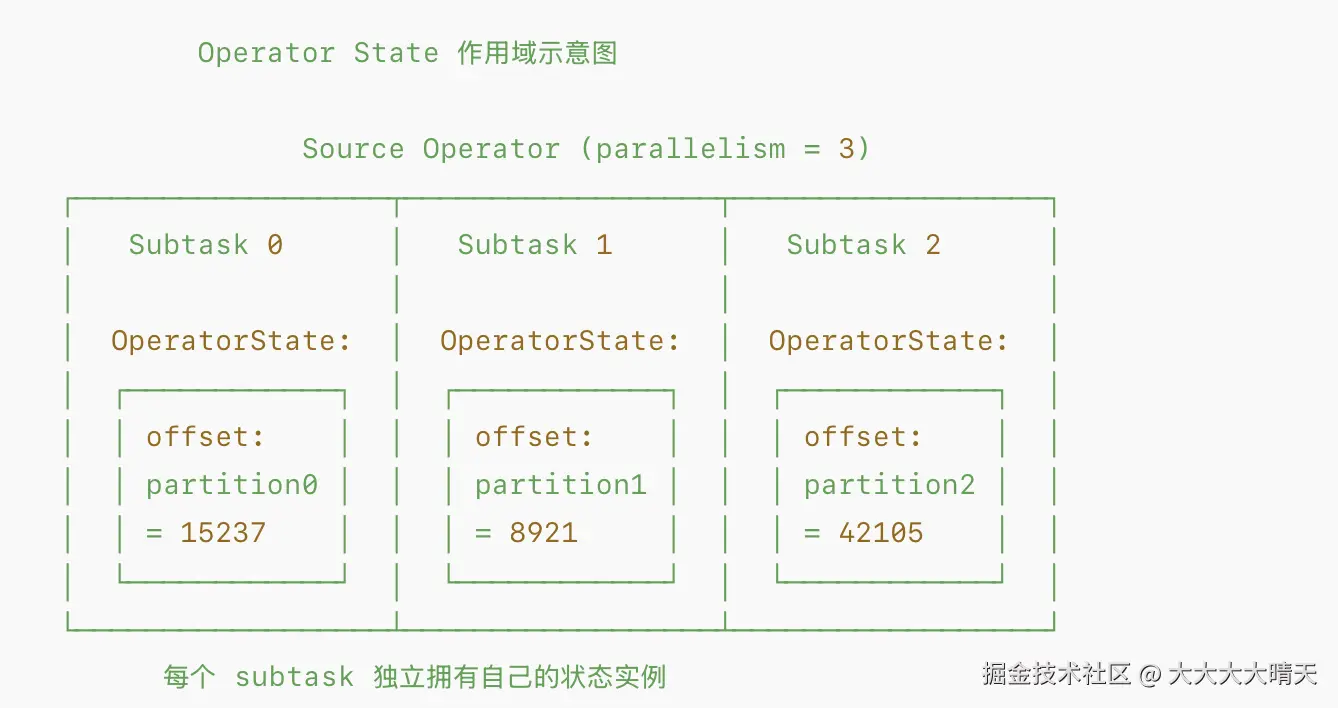
Operator State支持以下数据结构:
| 状态类型 | 重分配模式 | 典型场景 |
|---|---|---|
| ListState | Even-split(均匀拆分) | Kafka offset 管理、缓冲区 |
| UnionListState | Union(联合广播) | 需要全量恢复的元数据 |
| BroadcastState<K,V> | Broadcast(广播) | 动态规则、配置下发 |
Operator State 通过实现CheckpointedFunction接口来使用,在日常Flink应用开发中基本很少使用。
由于没有 Key 的概念,扩缩容时 Operator State 的分配策略分为以下几种:
- Even-split (ListState):轮询平均分配。例如,缩容前 Task A 有状态 1,2,Task B 有状态 3,4。扩容到 4 个并发后,状态会被打散,变成新 Task 1 拿 1,Task 2 拿 2,以此类推。
- Union (UnionListState):全量广播。扩缩容后,每一个新 Task 都会获得所有老 Task 状态的完整集合。然后由用户自己的逻辑去决定哪些数据归新 Task 处理,哪些丢弃。
- BroadcastState:每一个 Task 都保持相同的状态,扩容时新 Task 直接从旧 Task 拷贝一份全量状态即可。
四、Keyed State vs Operator State 核心对比
| 对比维度 | Keyed State | Operator State |
|---|---|---|
| 作用域 | 每个 Key 一个状态实例 | 每个算子并行实例一个状态 |
| 前提条件 | 必须在 keyBy() 之后使用 | 任意算子均可使用 |
| 访问方式 | 通过 RuntimeContext 在 open() 中获取 | 实现 CheckpointedFunction 接口 |
| State Descriptor 注册位置 | open() 方法 | initializeState() 方法 |
| 支持类型 | Value / List / Map / Reducing / Aggregating | List / UnionList / Broadcast |
| State TTL | ✅ 支持 | ❌ 不支持 |
| State Backend 影响 | 受 StateBackend 选择影响(堆内/RocksDB) | 始终存储在堆内存(Java Heap) |
| 重分配策略 | 基于 Key Group 自动重分配 | Even-split / Union / Broadcast |
| 典型使用者 | 业务开发者(常用) | Connector/Source/Sink 开发者 |
五、最佳实践与避坑指南
1.合理设置 maxParallelism
scss
env.setMaxParallelism(128); // 默认值即可满足多数场景
// 或在算子级别设置
stream.keyBy(...).process(...).setMaxParallelism(256);- maxParallelism 一旦设定后不可更改(否则无法从 Savepoint 恢复)
- 建议设为 2 的幂次方(如 128、256),有利于 Key Group 均匀分布
- parallelism 不能超过 maxParallelism
2.为 Keyed State 配置 State TTL
对于无限增长的 Key 空间(如 userId),必须配置 TTL 防止状态膨胀:
scss
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Duration.ofDays(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupFullSnapshot() // 全量 snapshot 时清理
.cleanupIncrementally(10, true) // 增量清理(RocksDB 推荐)
.cleanupInRocksdbCompactFilter(1000) // RocksDB Compaction 时清理
.build();3.大状态场景选择 RocksDB
arduino
// flink-conf.yaml 或代码中配置
env.setStateBackend(new EmbeddedRocksDBStateBackend(true)); // true = 增量 Checkpoint4.Operator State 保持轻量
- Operator State 存储在 Java 堆内存中,过大会导致 OOM
- 避免在 Operator State 中存储大量数据
- 如果需要大状态管理,考虑改用
keyBy()+ Keyed State
5.慎用 UnionListState
除非你非常明确扩缩容后需要所有 Task 拿到全局状态做重新路由(像 Kafka Source 那样),否则在普通业务逻辑中请使用ListState。UnionListState在高并发、大状态下扩容会导致极其恐怖的内存暴涨。
6.为算子设置唯一 UID
scss
stream
.keyBy(...)
.process(new MyProcessFunction())
.uid("my-process-function") // ← 必须设置!
.name("My Process Function");uid()是 Savepoint 恢复时匹配状态的唯一标识- 不设置时 Flink 会自动生成,但拓扑变更后可能无法匹配
- 建议制定 UID 命名规范