一、引言
在流处理系统中,面对网络抖动、节点宕机等异常情况,系统对消息的处理通常有三种语义:
- At-Most-Once(最多一次): 尽力而为,消息哪怕丢了也不重发。延迟极低,但数据会丢失。
- At-Least-Once(至少一次): 保证消息绝对到达,如果发生故障就重发。数据不丢,但数据会重复。
- Exactly-Once(精确一次): 系统的终极目标,无论发生何种故障,每条数据对最终状态的改变都仅且只有一次。
Apache Flink 通过其独特的分布式快照(Checkpoint)机制实现了引擎内部的 exactly-once 语义,并通过两阶段提交协议(2PC)将这一保障扩展到端到端(end-to-end)层面。
| 层次 | 含义 | 依赖机制 |
|---|---|---|
| 引擎内部 exactly-once | Flink 状态在故障恢复后与无故障执行结果一致 | Checkpoint(分布式快照) |
| 端到端 exactly-once | 从 Source 读取到 Sink 写出,整条链路精确一次 | Checkpoint + Source 可重放 + Sink 事务/幂等 |
二、Flink 内部 Exactly-Once 机制原理
Flink 内部的 Exactly-Once 是通过基于 Chandy-Lamport 算法变体的Checkpoint 机制实现的,核心思想是:不暂停整个数据流的情况下,通过注入特殊标记(Barrier)来切分数据流,从而获取全局一致性快照。
Flink 会在数据流中周期性地插入一种特殊的标记,称为 Checkpoint Barrier。Barrier 将无限的数据流切分为一个个独立的批次,当一个算子(Operator)有多个输入流时,需要进行"屏障对齐"(Barrier Alignment)才能保证 Exactly-Once。
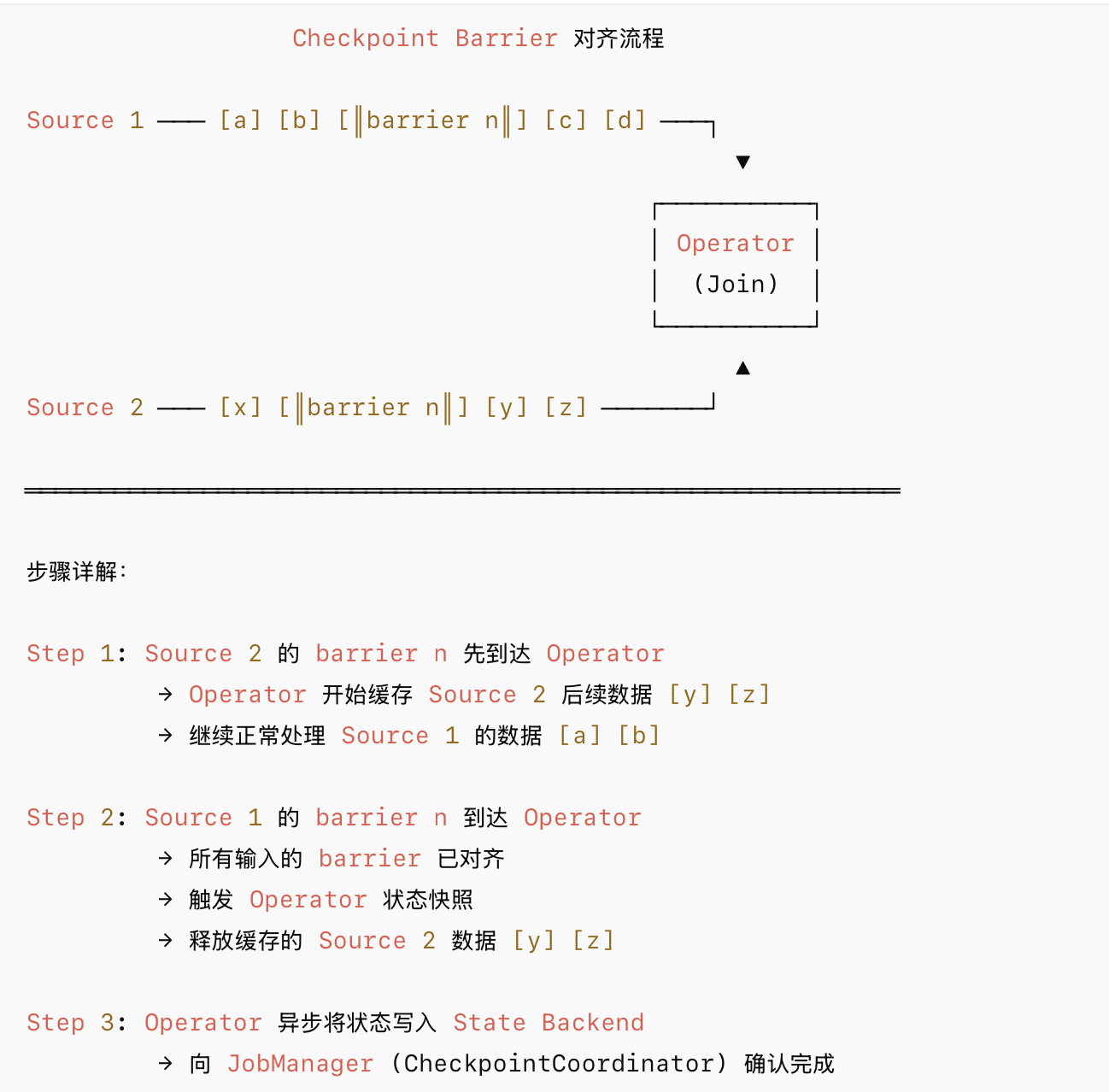
Barrier Alignment解决了一致性问题,但也带来了一个副作用:当某些输入通道存在反压或数据倾斜时,Barrier 对齐时间会变长,Checkpoint 延迟增加,甚至超时失败。
为了解决 Barrier Alignment 在反压场景下可能导致 Checkpoint 长时间无法完成的问题,Flink 引入了 Unaligned Checkpoint。

| 特性 | Aligned Checkpoint | Unaligned Checkpoint |
|---|---|---|
| 反压容忍度 | 低 | 高 |
| 快照大小 | 仅状态 | 状态 + in-flight 数据 |
| 恢复时间 | 较快 | 可能较慢(需恢复 in-flight 数据) |
| 适用场景 | 正常负载 | 严重反压 |
三、Flink 端到端 Exactly-Once 核心机制
Flink 内部的快照只能保证 Flink 自己不出错,但实际业务往往是 Kafka -> Flink -> Kafka/HBase。如果 Flink 处理完写到外部系统时崩溃,依然会导致数据不一致,这就引出了 端到端 Exactly-Once。
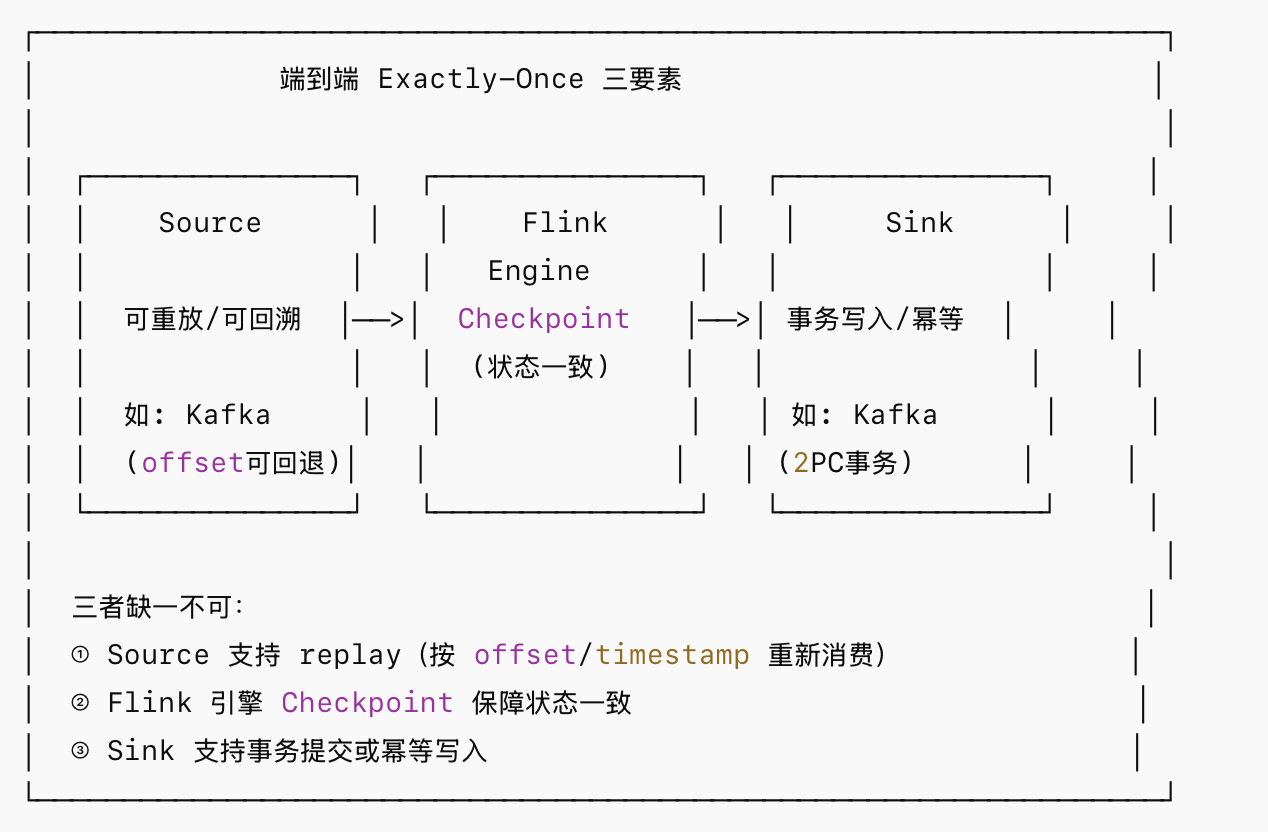
对于支持事务的外部系统,Flink 结合Checkpoint 机制通过 Two-Phase Commit(两阶段提交,简称 2PC)实现端到端 Exactly-Once,协作流程示意图如下:
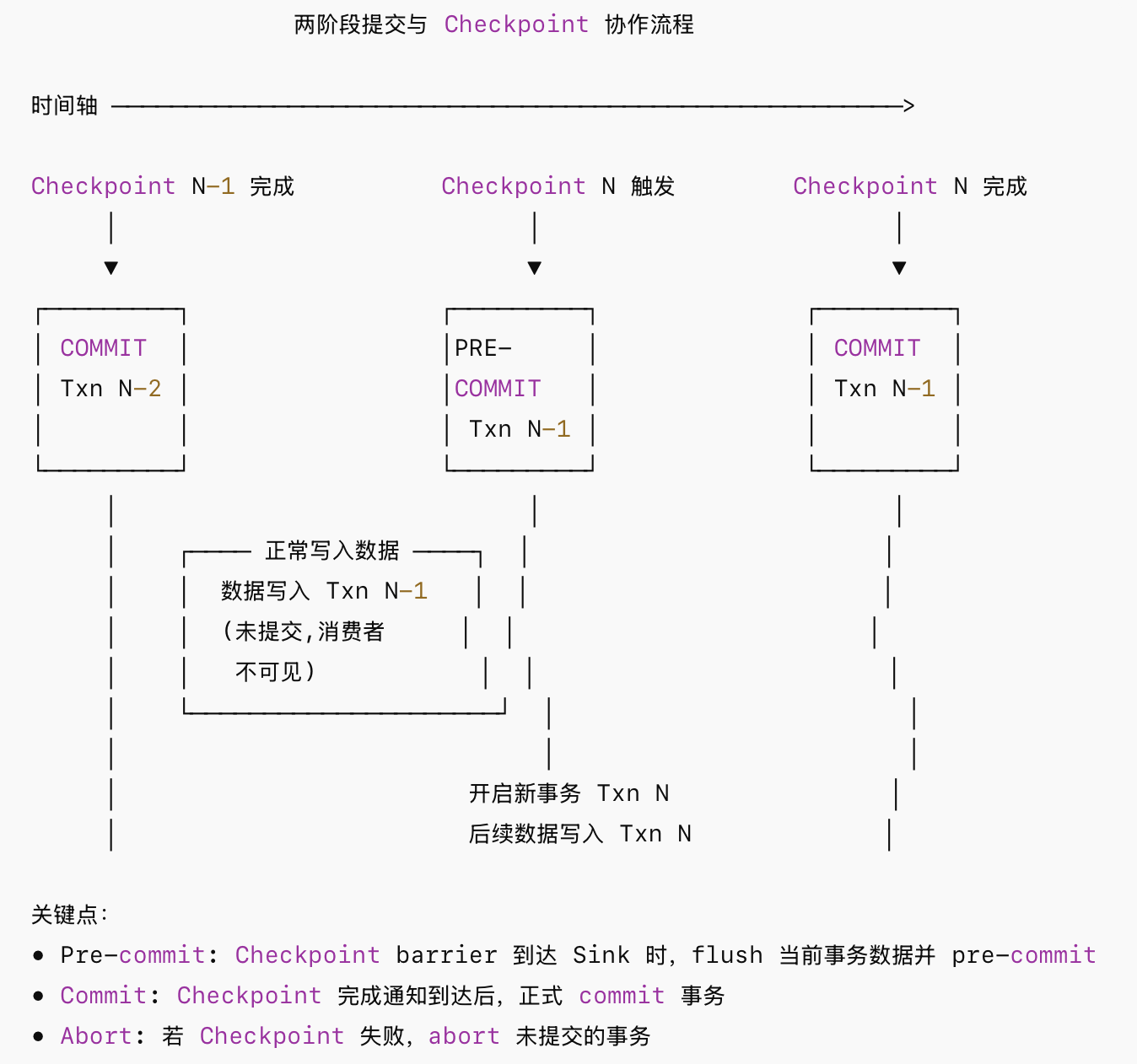
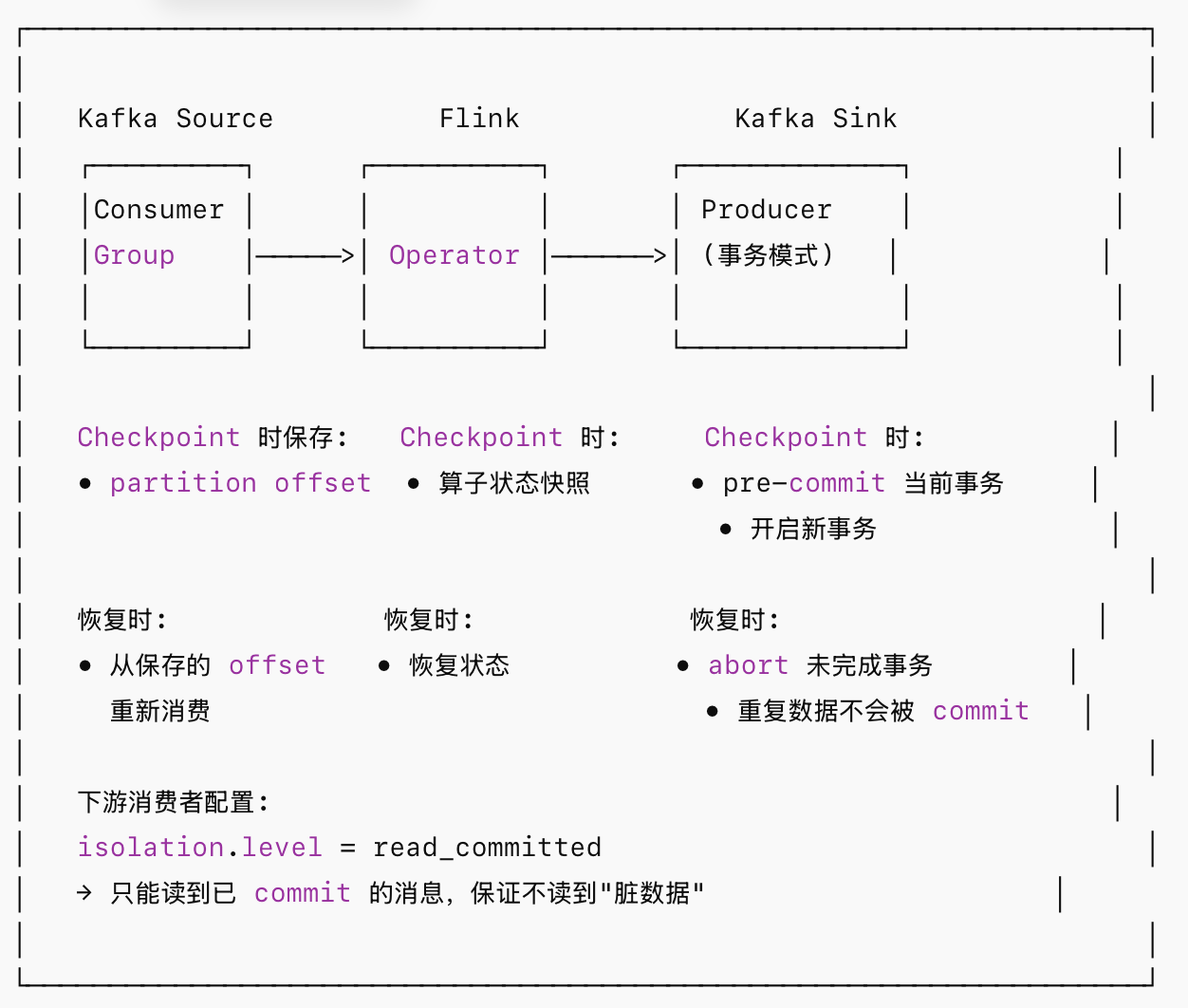
Flink-2pc典型代表是FlinkKafkaProducer,Kafka 端到端 Exactly-Once 详解如下:
对于不支持事务的 Sink(如 HBase、Elasticsearch、Redis),可通过幂等性实现 "效果上的 exactly-once":
幂等写入原理:
相同 Key 的重复写入 → 结果不变
例如:
• HBase: 相同 RowKey + Column 的 PUT 操作天然幂等
• Elasticsearch: 指定 document _id 的 index 操作天然幂等
• Redis: SET key value 天然幂等
注意:幂等写入无法保证"中间状态不可见"
→ 故障恢复期间,下游可能短暂看到部分结果
→ 适用于对短暂不一致可容忍的场景以下是常见不同Sink组件的Exactly-Once 能力对比:
| Sink 类型 | 是否容易实现端到端 Exactly-Once | 典型方式 | 注意事项 |
|---|---|---|---|
| Kafka Sink | 较容易 | Kafka Transaction + Checkpoint | 下游消费者需使用 read_committed |
| FileSink | 较容易 | Pending File 在 Checkpoint 完成后 Commit | 小文件、分区提交策略需治理 |
| JDBC Sink | 中等 | XA 事务或业务主键幂等 | 普通 JDBC 批量写通常是 At-Least-Once |
| Elasticsearch | 通常依赖幂等 | 指定 Document ID 覆盖写 | Append 型写入会重复 |
| Redis | 通常依赖幂等 | SET/HSET 等覆盖写 | INCR/LPUSH 等非幂等操作会重复 |
| HBase | 通常依赖幂等 | RowKey 覆盖写 | RowKey 设计决定一致性 |
| Iceberg/Hudi/Paimon | 较好 | Commit 协议 + Checkpoint | 需关注 Connector 版本与提交语义 |
| 自定义 HTTP Sink | 较难 | 幂等请求 ID / 外部事务表 | 未纳入 Checkpoint 的副作用不可自动保证 |
四、Exactly-Once优缺点分析
1.Flink 内部 Exactly-Once
| 维度 | 优点 | 缺点/代价 |
|---|---|---|
| 一致性 | 故障恢复后状态与无故障执行完全一致 | --- |
| 性能 | 异步快照,对正常处理影响小 | Barrier 对齐时缓存数据增加延迟 |
| 可用性 | 自动故障恢复,无需人工干预 | Checkpoint 失败可能导致 Job 失败 |
| 存储 | 增量 Checkpoint 减少写入量 | 大状态场景下存储成本高 |
| 复杂度 | 对用户透明,无需修改业务逻辑 | State Backend 调优有学习成本 |
2.端到端 Exactly-Once
| 维度 | 优点 | 缺点/代价 |
|---|---|---|
| 数据正确性 | 全链路精确一次,结果可信 | --- |
| 延迟 | --- | 事务提交延迟 = Checkpoint 间隔(数据对下游可见有延迟) |
| 吞吐 | --- | 事务开销降低吞吐(约 10-20%,视场景而定) |
| 运维 | --- | 需协调 Flink + Kafka 配置,复杂度上升 |
| 适用性 | --- | 要求 Sink 支持事务或幂等,Source 支持重放 |
3.Exactly-Once vs At-Least-Once
选择 Exactly-Once:
✓ 金融交易、计费、对账等对准确性要求极高的场景
✓ 下游无法容忍重复数据且无去重能力
✓ 状态计算结果直接面向用户展示
选择 At-Least-Once:
✓ 下游具备幂等能力(如 upsert 到数据库)
✓ 对延迟极度敏感(如实时推荐、监控告警)
✓ 可接受短暂重复,后续有去重/修正机制五、总结
Flink 的 exactly-once 语义建立在分布式快照算法之上,通过 Checkpoint Barrier 机制实现了引擎内部的状态一致性保障;在此基础上,结合 Source 端的可重放能力和 Sink 端的事务/幂等写入,Flink 实现了真正的端到端 exactly-once 语义。
然而,技术的本质是权衡,Exactly-Once 用牺牲部分延迟和系统开销的代价换取了绝对的准确;在我们日常技术选型中,最核心的是要结合实际的应用场景与需求去选择Exactly-Once 或者At-Least-Once路线,没有最好的,只有最合适的。