MySQL 作为主流关系型数据库,CRUD(增 Create、查 Retrieve、改 Update、删 Delete) 是数据库操作的核心根基,也是后端开发、数据处理的必备技能。本文全程理论 + 实战实验结合,所有 SQL 代码可直接复制执行,带你从零吃透 MySQL 基本查询与增删改查,新手也能快速上手。
1:学习前置
所有实验基于学生表students和成绩单exam_result开战
1:创建学生表
sql
-- 学生表:ID自增、学号唯一、姓名非空、QQ号可选
CREATE TABLE students (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT COMMENT '学生ID(主键自增)',
sn INT NOT NULL UNIQUE COMMENT '学号(唯一约束)',
name VARCHAR(20) NOT NULL COMMENT '学生姓名',
qq VARCHAR(20) COMMENT 'QQ号码'
);2:创建成绩单exam_result
sql
-- 成绩表:存储语数外三科成绩
CREATE TABLE exam_result (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT COMMENT '成绩记录ID',
name VARCHAR(20) NOT NULL COMMENT '学生姓名',
chinese FLOAT DEFAULT 0.0 COMMENT '语文成绩',
math FLOAT DEFAULT 0.0 COMMENT '数学成绩',
english FLOAT DEFAULT 0.0 COMMENT '英语成绩'
);2:create插入数据
插入数据是向表中添加记录,核心语法:
INSERT INTO 表名 (列名1,列名2) VALUES (值1,值2);
1:单行数据+全列插入
sql
-- 插入2条学生记录
INSERT INTO students VALUES (100, 1000, '唐三藏', NULL);
INSERT INTO students VALUES (101, 10001, '孙悟空', '111');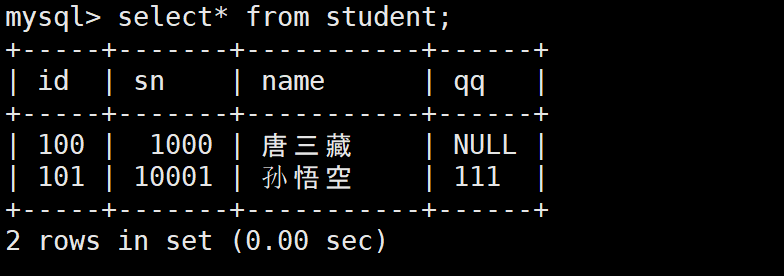
2:多行数据+指定列插入
sql
-- 批量插入2条学生数据,仅填id、学号、姓名
INSERT INTO students (id, sn, name) VALUES
(102, 20001, '曹孟德'),
(103, 20002, '孙仲谋');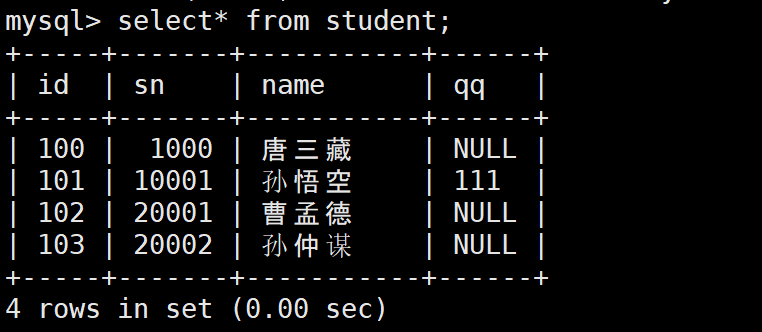
3:插入否则更新
主键 / 唯一键冲突时,自动更新数据避免插入失败。
sql
-- 主键100已存在,触发更新
INSERT INTO students (id, sn, name) VALUES (100, 10010, '唐大师')
ON DUPLICATE KEY UPDATE sn = 10010, name = '唐大师';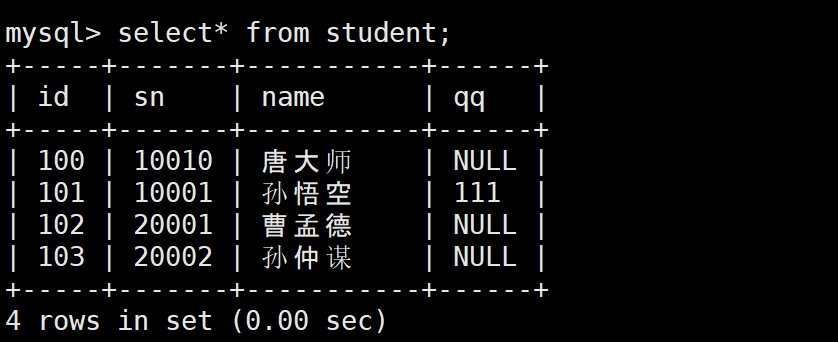
4:插入替换
冲突则删除旧数据再插入,无冲突直接新增。
sql
REPLACE INTO students (sn, name) VALUES (20001, '曹阿瞒');3:retrieve数据查询
查询是 MySQL最核心操作,语法:
SELECT DISTINCT 列 FROM 表 WHERE条件 ORDER BY排序 LIMIT分页;
1:基础查询实验
先插入成绩然后查询
sql
-- 插入7条成绩数据
INSERT INTO exam_result (name, chinese, math, english) VALUES
('唐三藏', 67, 98, 56),
('孙悟空', 87, 78, 77),
('猪悟能', 88, 98, 90),
('曹孟德', 82, 84, 67),
('刘玄德', 55, 85, 45),
('孙权', 70, 73, 78),
('宋公明', 75, 65, 30);1:全列查询(不推荐生产使用)
sql
SELECT * FROM exam_result;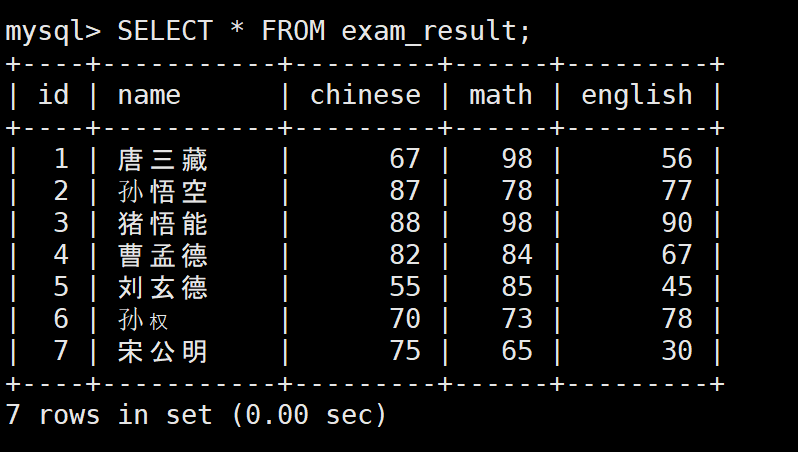
2:指定列+表达式查询
sql
-- 查询ID、姓名,计算总分
SELECT id, name, chinese + math + english AS 总分 FROM exam_result;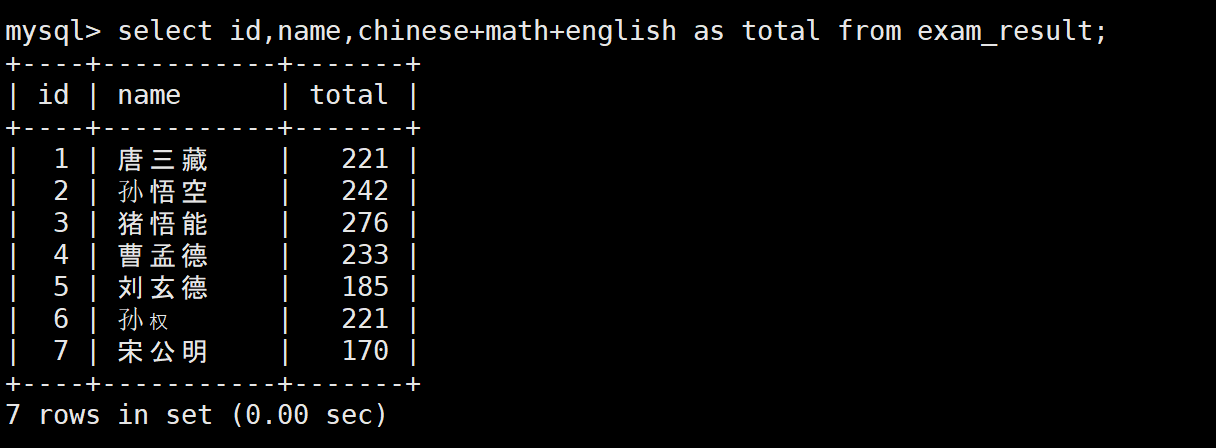
3:结果去重(DISTINCT)
sql
-- 数学成绩去重查询
SELECT DISTINCT math FROM exam_result;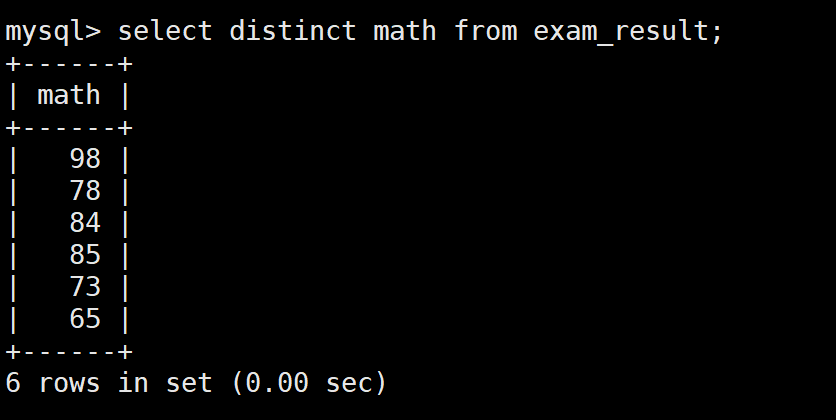
2:WHERE条件筛选实验
1:英语不及格的学生
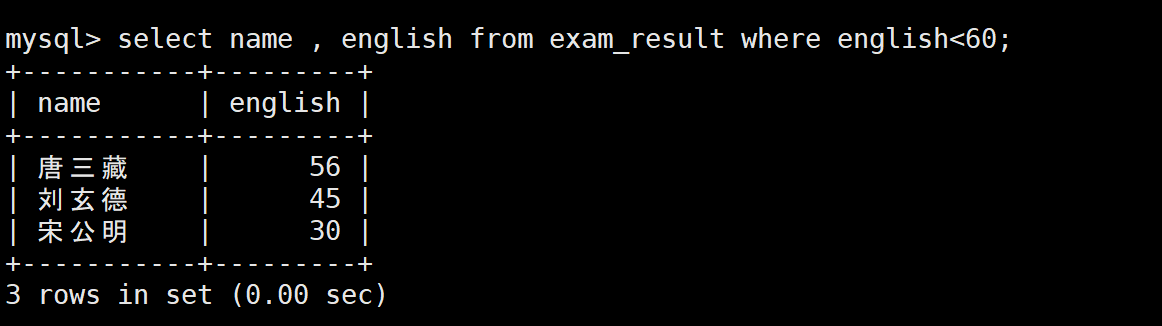
2:语文80-90的学生
sql
-- BETWEEN 包含区间两端值
SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90;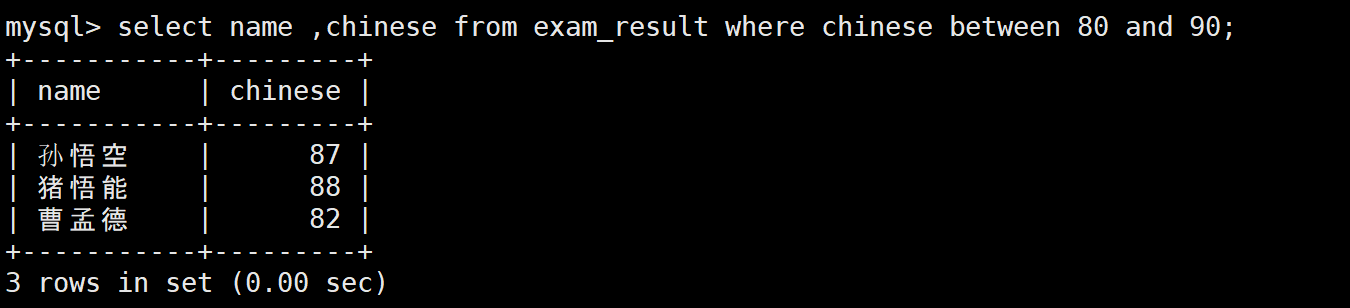
3:模糊查询(姓孙的学生)
sql
-- %:匹配任意字符;_:匹配单个字符
SELECT name FROM exam_result WHERE name LIKE '孙%';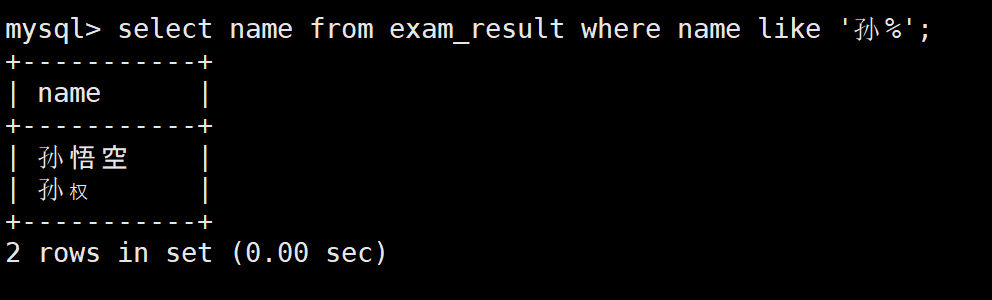
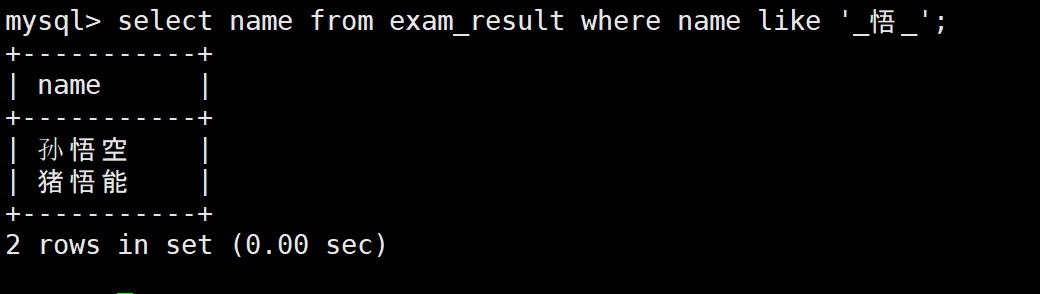
也可以这样模糊查询
3:排序+分页查询
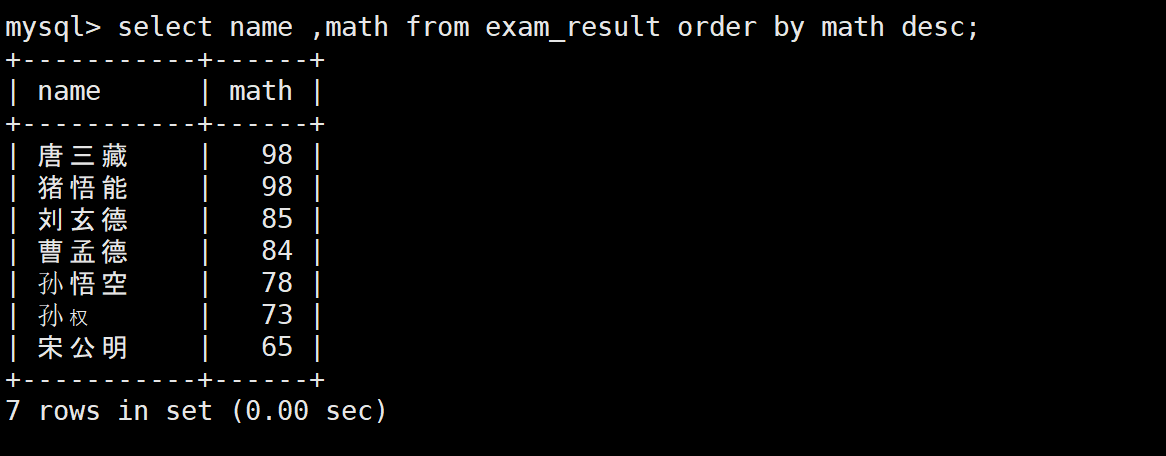
1:按照数学成绩降序排序
sql
SELECT name, math FROM exam_result ORDER BY math DESC;注意:NULL视为最小值,升序排在最前,降序排在最后。
2:分页查询(第一页,每页三条)
sql
-- LIMIT 条数 OFFSET 起始下标(从0开始)
SELECT id, name, math FROM exam_result ORDER BY id LIMIT 3 OFFSET 0;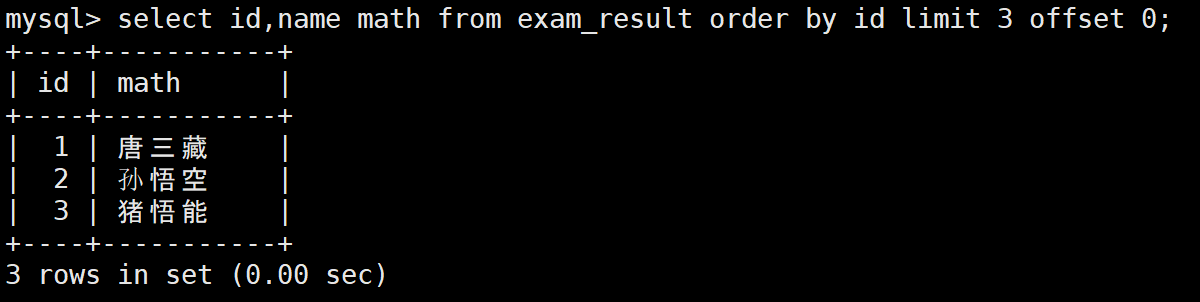
4:update数据更新
核心语法
UPDATE 表 SET 列=值 WHERE 条件;
无 WHERE 条件会更新全表,生产环境严禁滥用!
1:单字段更新
sql
-- 把孙悟空的数学成绩改为80分
UPDATE exam_result SET math = 80 WHERE name = '孙悟空';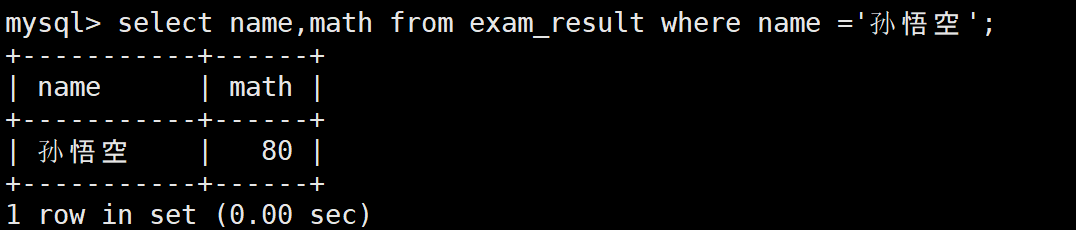
2:多字段批量更新
sql
-- 曹孟德:数学60分、语文70分
UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';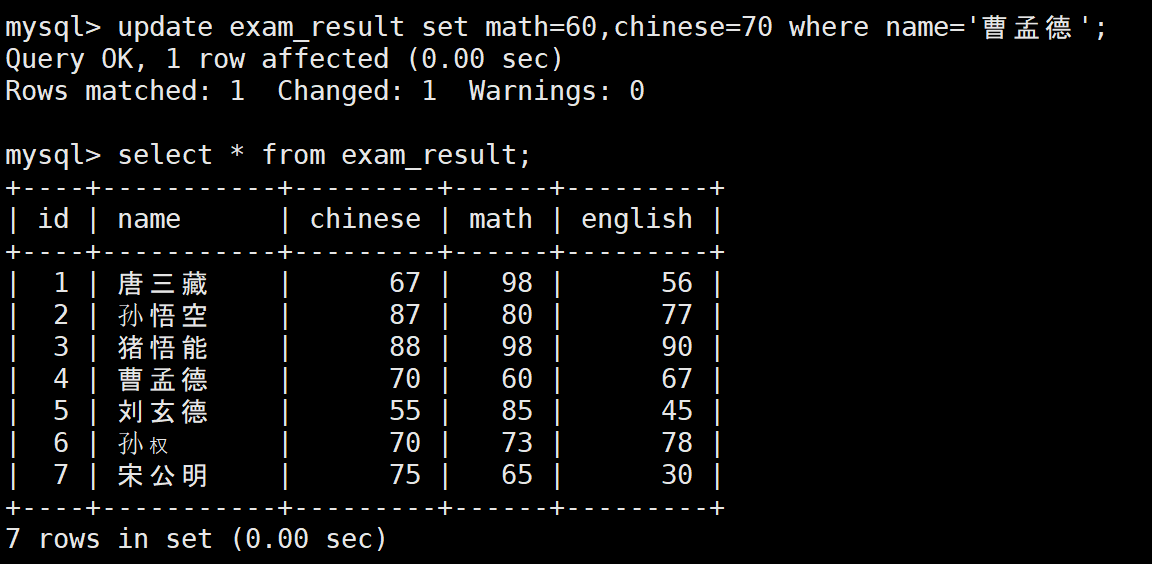
3:表达式更新(在原值上修改)
sql
-- 总分倒数前三的学生,数学成绩+30
UPDATE exam_result SET math = math + 30
ORDER BY chinese + math + english LIMIT 3;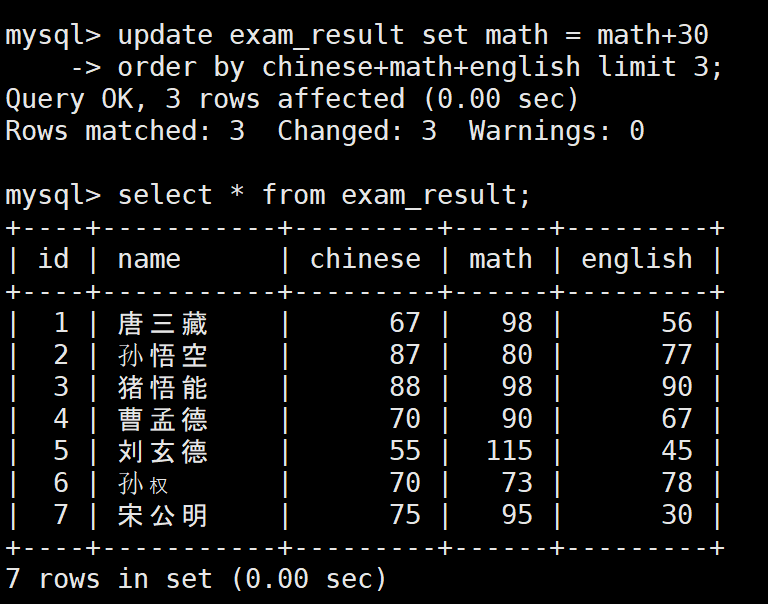
5:delete数据删除
核心语法
DELETE FROM 表 WHERE 条件;
1:删除单条数据
sql
-- 删除孙悟空的成绩记录
DELETE FROM exam_result WHERE name = '孙悟空';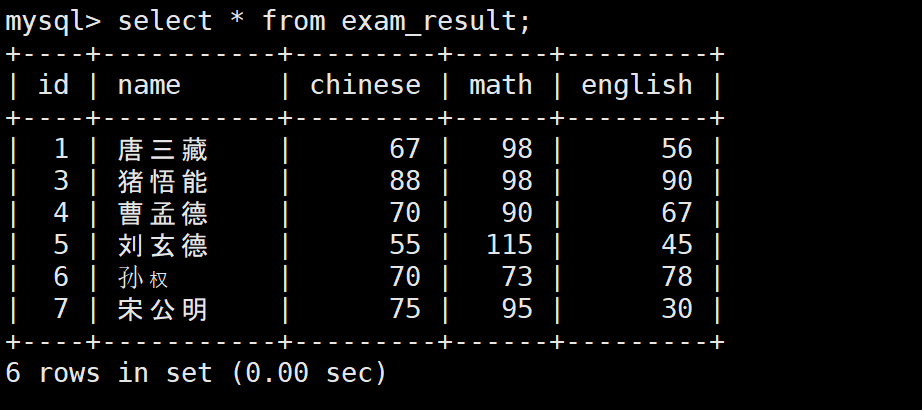
2:全表删除和截断表
DELETE 全表(保留自增 ID)
sql
DELETE FROM students;TRUNCATE截断表(重置自增ID,速度更快)
sql
TRUNCATE students;| 操作 | 能否删指定行 | 自增 ID | 事务回滚 |
|---|---|---|---|
| DELETE | 能 | 保留 | 支持 |
| TRUNCATE | 不能(全表) | 重置 | 不支持 |
6:高级查询:聚合函数+分组
1:聚合函数实验
sql
-- 统计学生总人数
SELECT COUNT(*) FROM students;
-- 数学成绩总分
SELECT SUM(math) FROM exam_result;
-- 英语最高分
SELECT MAX(english) FROM exam_result;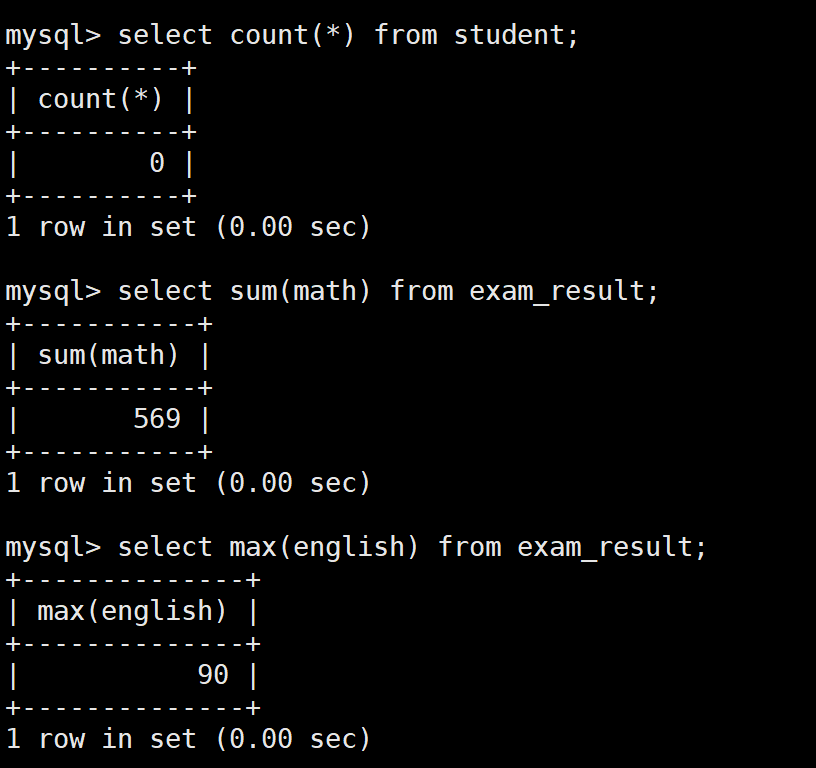
2:GROUP BY分组+HAVING筛选
1:实验准备
创建员工表
sql
-- 1. 创建员工表 emp
CREATE TABLE emp (
emp_id INT PRIMARY KEY AUTO_INCREMENT COMMENT '员工编号',
emp_name VARCHAR(20) NOT NULL COMMENT '员工姓名',
dept VARCHAR(20) NOT NULL COMMENT '所属部门',
job VARCHAR(20) NOT NULL COMMENT '岗位',
sal INT NOT NULL COMMENT '工资'
);
-- 2. 插入测试数据
INSERT INTO emp (emp_name, dept, job, sal) VALUES
('孙悟空', '研发部', '开发', 9000),
('猪八戒', '研发部', '测试', 7000),
('唐三藏', '产品部', '产品经理', 12000),
('沙和尚', '研发部', '开发', 8500),
('白龙马', '产品部', '产品专员', 6000),
('曹孟德', '运营部', '运营主管', 10000),
('刘皇叔', '运营部', '运营专员', 5000);
2:单字段分组->按部门统计
需求:统计每个部门的员工人数、平均工资、最高工资、最低工资
sql
-- 单字段分组:按 dept 分组
SELECT
dept AS '部门',
COUNT(emp_id) AS '员工人数',
AVG(sal) AS '平均工资',
MAX(sal) AS '最高工资',
MIN(sal) AS '最低工资'
FROM emp
GROUP BY dept;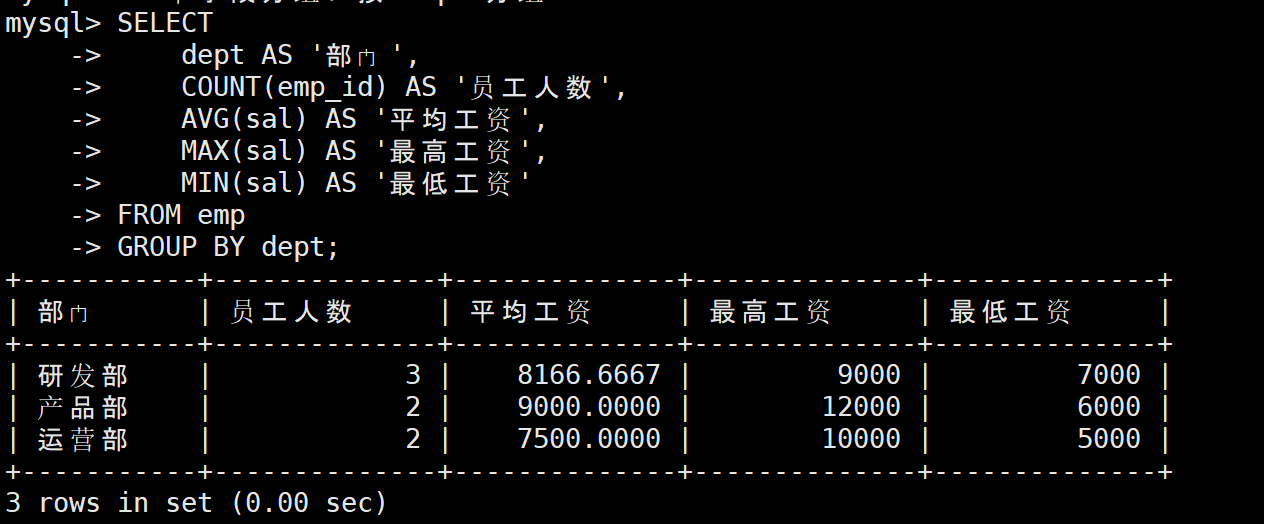
2:多字段分组->按部门+岗位分组
sql
-- 多字段分组:先按部门分,再按岗位分
SELECT
dept AS '部门',
job AS '岗位',
COUNT(emp_id) AS '人数',
AVG(sal) AS '岗位平均工资'
FROM emp
GROUP BY dept, job;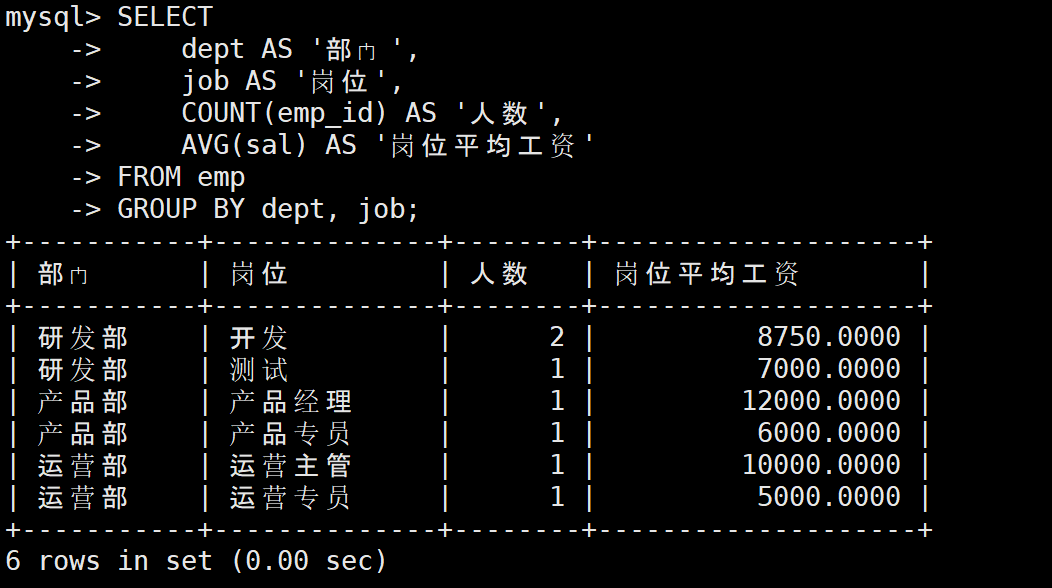
3:GROUP BY +HAVING ->过滤分组结果
HAVING 专门过滤分组后的结果 ,WHERE 过滤分组前的原始数据,二者不能混用。
需求:筛选出平均工资 ≥ 8000 的部门
sql
-- 先分组统计,再用 HAVING 过滤分组结果
SELECT
dept AS '部门',
AVG(sal) AS '平均工资'
FROM emp
GROUP BY dept
HAVING AVG(sal) >= 8000;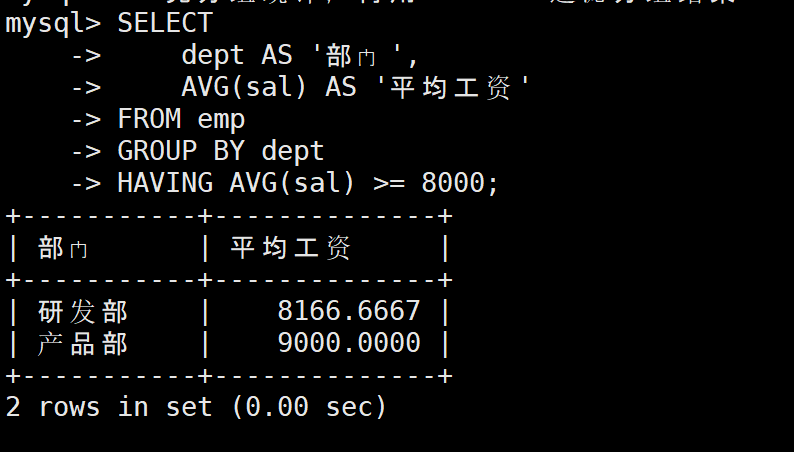
4:GROUP BY + ORDER BY ->分组后排序
需求:按部门统计总工资,结果按总工资降序排列
sql
SELECT
dept AS '部门',
SUM(sal) AS '部门总工资'
FROM emp
GROUP BY dept
ORDER BY SUM(sal) DESC;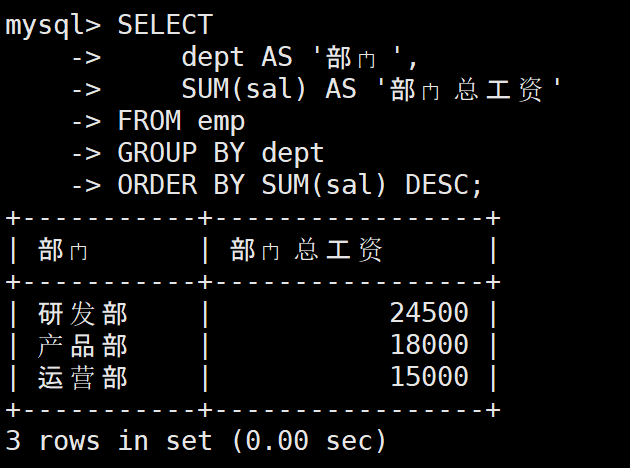
7:核心知识点总结
- SQL 关键字执行顺序
from → on → join → where → group by → having → select → distinct → order by → limit - CRUD 核心原则
- 增:指定列插入更安全,冲突用
ON DUPLICATE/REPLACE - 查:少用
*,善用WHERE/LIMIT优化性能 - 改 / 删:必须加 WHERE 条件,避免全表操作
- 增:指定列插入更安全,冲突用
- 查询技巧 :去重
DISTINCT、排序ORDER BY、分页LIMIT、模糊LIKE是日常高频用法