Nanobot 源码深入解析:ReAct 循环的核心实现
这篇文章讲 Nanobot 的 AgentRunner 类------4000 行框架代码里真正驱动 Agent 思考和行动的部分。
代码来自 HKUDS/nanobot(GitHub 37K Stars),以下片段有精简,完整实现请看原仓库。
1. 背景
Nanobot 是一个约 4000 行代码的极简 Agent 框架,由香港大学 HKUDS 实验室开源。
它的设计哲学很直接:不替 LLM 做规划,只给 LLM 提供循环结构。框架不写任务流、不做状态机,把规划决策权完全交给 LLM,把框架自身复杂度压到最低。
本篇聚焦 nanobot/agent/runner.py 中的 AgentRunner 类。每条用户消息进来,AgentLoop 都会创建一个新的 AgentRunner 实例,由它完成完整的推理+行动循环,最终返回响应。
2. ReAct 原型图------从概念到代码的映射
循环结构
ReAct(Reasoning + Acting)的核心就一张图:
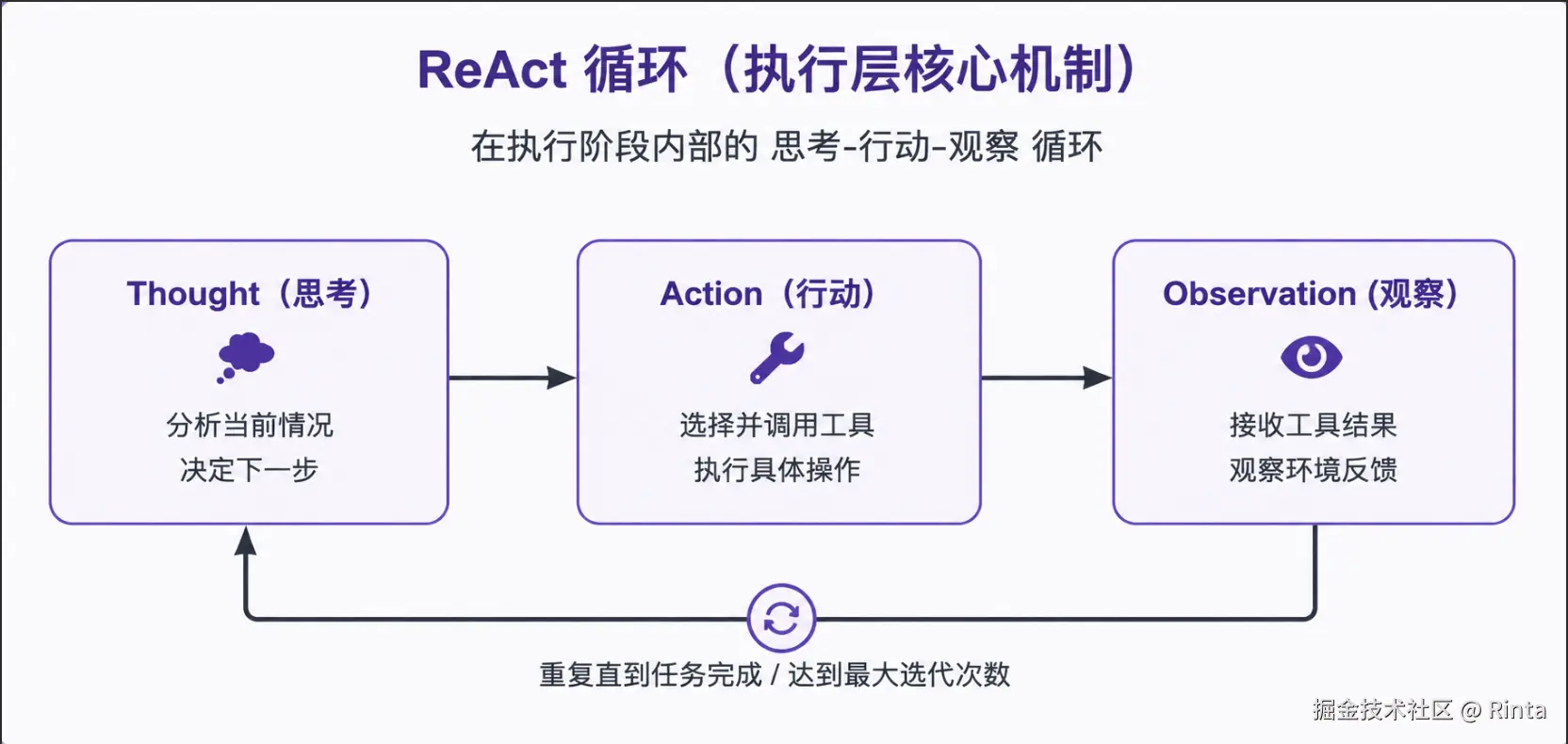
循环直到 LLM 不再调用工具------这意味着它认为任务完成了,输出最终回答。
单次调用 vs ReAct 循环
用 LLM API 最基础的写法是这样的:
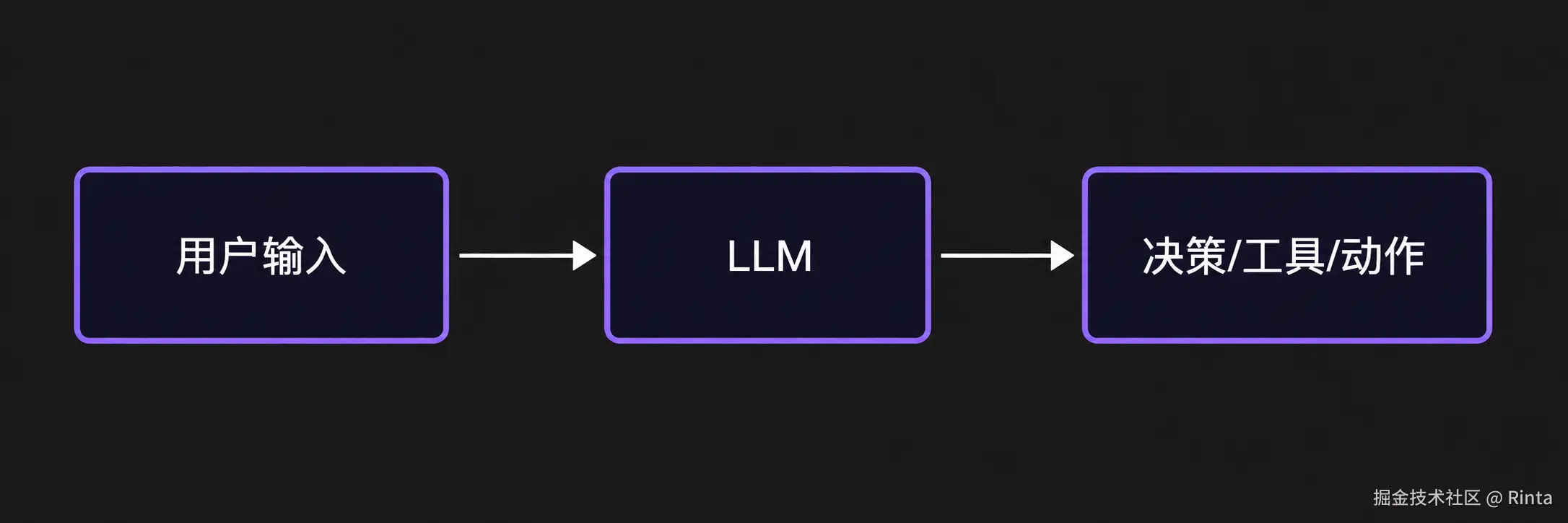
一次调用,一次回答,完成。没有工具,没有反馈,LLM 的输出就是终点。
ReAct 的区别在于:LLM 的输出是下一步行动的指令,而不是终点。
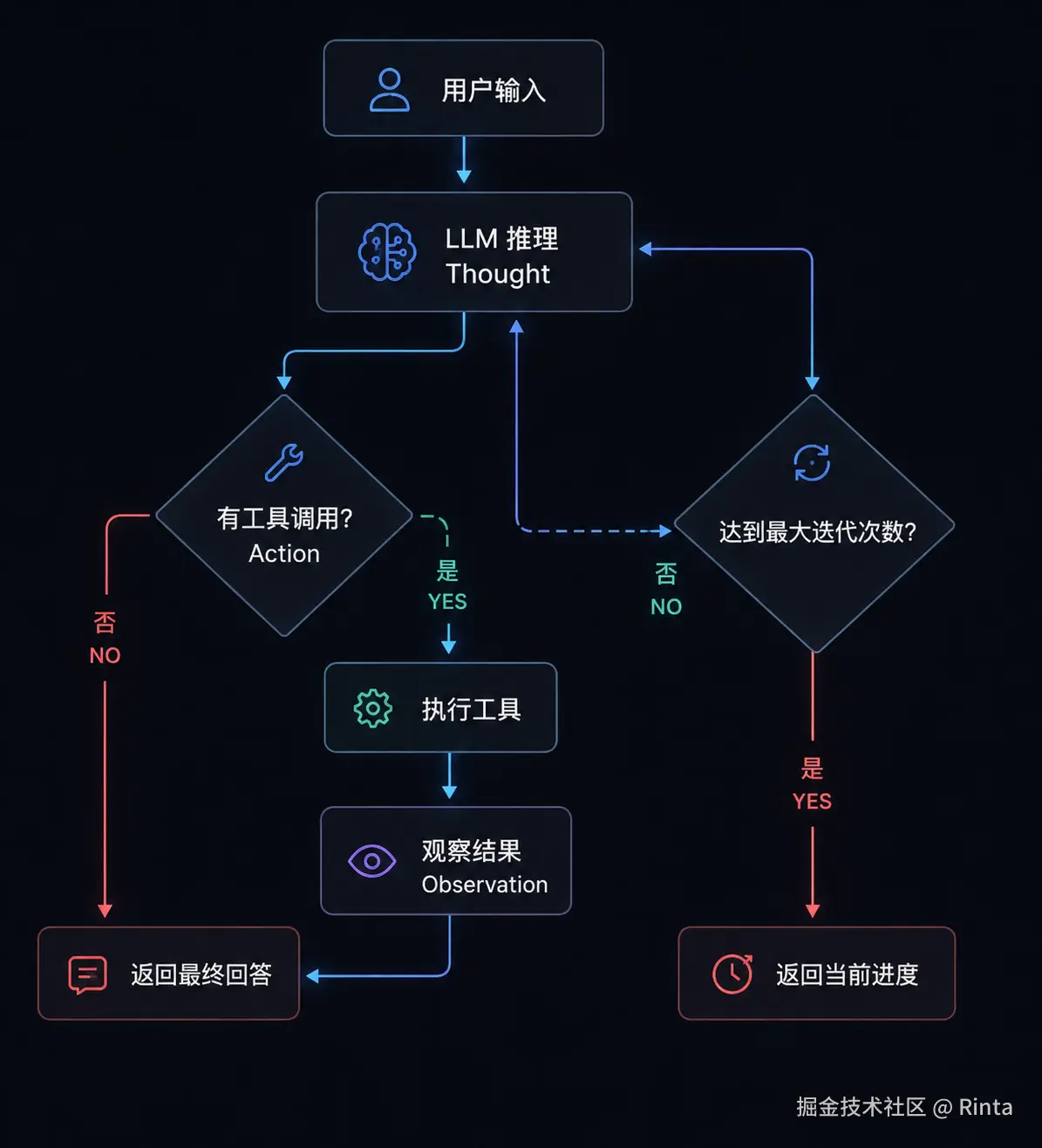
messages 列表是循环的载体。每一轮 LLM 的回复和工具结果都追加进去,LLM 下一轮看到的是完整上下文,而不是从头开始。
3. AgentRunner.run() 核心架构和执行
初始化:两件事
进入循环之前,run() 做两件事:
ReAct 循环前:
ini
async def run(self, user_message: str, session_id: str) -> str:
# 构建发给 LLM 的消息列表(含历史对话、长期记忆、当前输入)
messages = self.context_builder.build_messages(
user_message=user_message,
session_id=session_id,
)
# 获取所有注册工具的 JSON Schema(LLM 用这个决定调哪个工具)
tools = self.tool_registry.get_tool_schemas()
final_response = ""
tool_calls_history = []build_messages() 拿上下文,get_tool_schemas() 拿工具列表。工具列表以 JSON Schema 格式提供给 LLM,LLM 通过 Function Calling 机制返回它想调的工具名和上下文参数。
核心方法:Context_builder.build_messages 的内部逻辑:
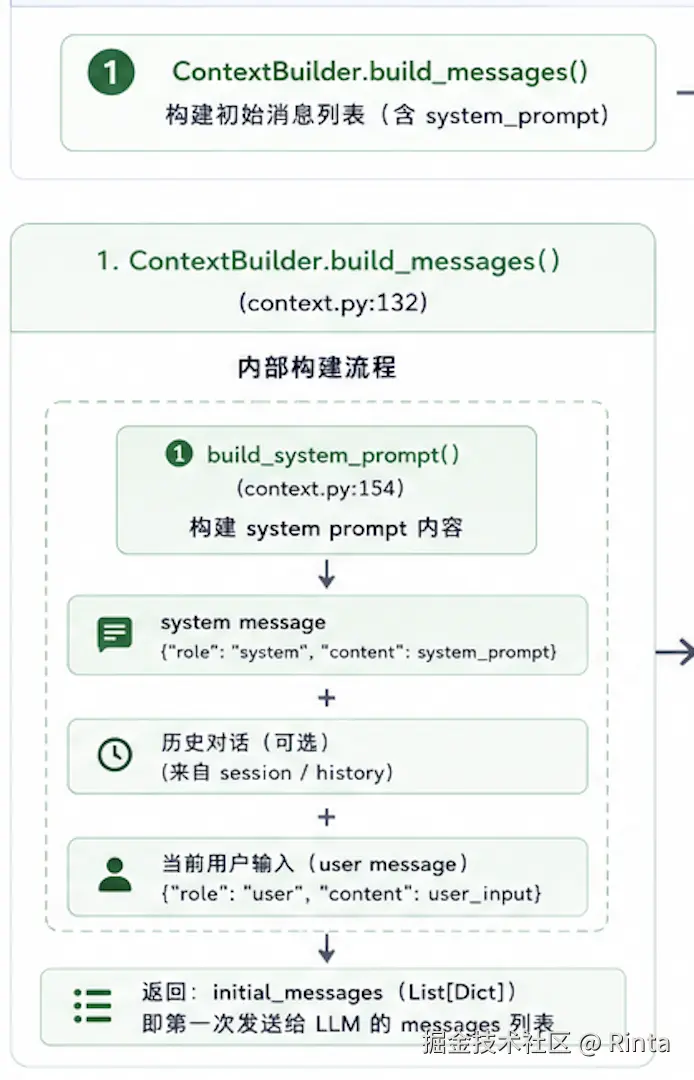 ContextBuilder.build_prompt作用: 构建ReAct循环中LLM所需要的完整上下文参数。 首先先调用build_system_prompt()方法来构建system prompt,包含有Identity + Bootstrap + Memory + Skills,这样system prompt就构建完成。
ContextBuilder.build_prompt作用: 构建ReAct循环中LLM所需要的完整上下文参数。 首先先调用build_system_prompt()方法来构建system prompt,包含有Identity + Bootstrap + Memory + Skills,这样system prompt就构建完成。
接着返回message列表,消息结构由下面这个组成:
css
消息结构:
[system_prompt] + [session history...] + [user_message]组成session history表示的是最近的一次对话的上下文窗口(类似我们用Agent一次上下文窗口对话的记忆)
ReAct 循环核心
核心代码:
python
async def run(self, user_message: str, session_id: str) -> str:
"""执行完整的 ReAct 循环,返回最终响应。"""
# 3. ReAct 循环
for iteration in range(self.max_iterations):
# --- Lifecycle Hook: before_iteration ---
await self._before_iteration(iteration, messages)
# --- 调用 LLM ---
response = await self.provider.chat_with_retry(
messages=messages,
tools=tools if tools else None,
)#返回是否需工具调用
# --- 检查是否有工具调用 ---
if not response.tool_calls:
# 没有工具调用 = LLM 认为任务完成
final_response = response.content
break
# --- 有工具调用 ---
# 将 assistant 的响应加入消息列表
messages.append({
"role": "assistant",
"content": response.content,
"tool_calls": response.tool_calls,
})
# --- Lifecycle Hook: before_execute_tools ---
await self._before_execute_tools(response.tool_calls)
# --- 逐一执行工具调用 ---(工具调用函数在下面)
for tool_call in response.tool_calls:
#返回具体工具参数结果
result = await self._execute_tool(tool_call)
# 截断过长的工具结果
if len(result) > _TOOL_RESULT_MAX_CHARS:
result = result[:_TOOL_RESULT_MAX_CHARS] + "\n...(truncated)"
# 将工具结果加入消息列表+更新messages
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result,
})
tool_calls_history.append(tool_call)
# --- Lifecycle Hook: after_iteration ---
await self._after_iteration(iteration, messages)
else:
# 达到最大迭代次数仍未完成
final_response = "I've reached the maximum number of iterations. Here's what I've done so far..."
return final_response核心架构图(简化示意图):
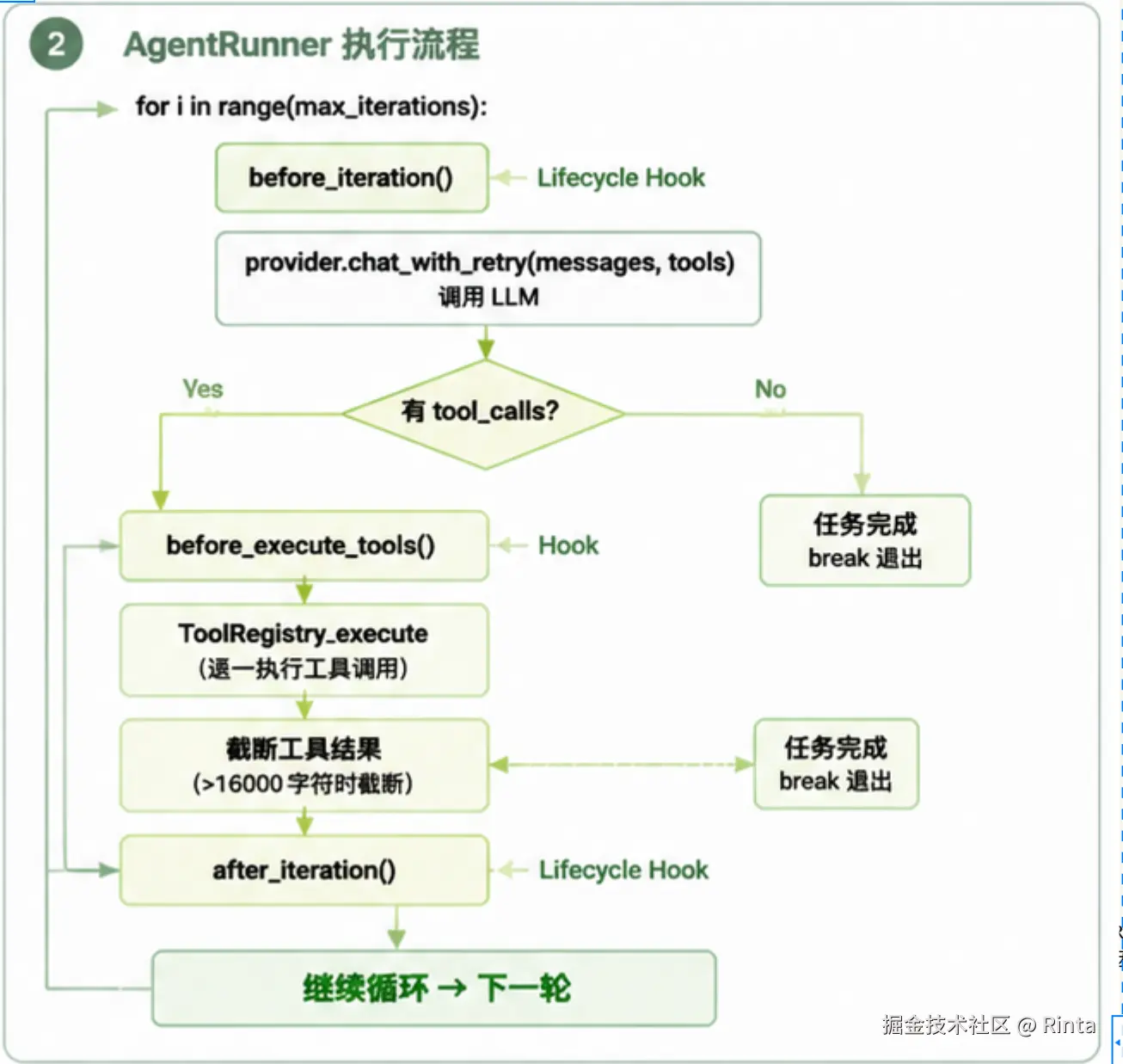 (这里ToolRegister_execute()需要修改成_execute_tool())
(这里ToolRegister_execute()需要修改成_execute_tool())
主要逻辑讲解:
每一轮循环,都是一次完整的 Thought → Action → Observation:
Thought:首先LLM读入完整的 messages(含历史、记忆、当前输入,即完整上下文参数)和tools(可用工具列表),分析当前情况,决定下一步是否使用工具
python
response = await self.provider.chat_with_retry(
messages=messages, # 完整上下文:历史 + 记忆 + 当前输入 + 上一轮
tools=tools,
)Action:接着检查是否有工具调用,没有工具调用,返回最后的responses.反之继续执行
python
if not response.tool_calls:
break # Thought 认为任务完成,退出循环
result = await self._execute_tool(tool_call) # Thought 决定调工具,执行Observation:接收工具执行的结果append到 messages,这会成为下一轮 LLM 的输入
python
if len(result) > _TOOL_RESULT_MAX_CHARS:
result = result[:_TOOL_RESULT_MAX_CHARS] + "\n...(truncated)" # 截断
messages.append({
"role": "tool",
"content": result, # 工具结果写入 messages
})核心方法分析:
几个 Lifecycle Hooks:
before_iteration
- 作用:每轮开始时同步当前 iteration
- 当前 _LoopHook 里主要做状态更新,不做业务推理
before_execute_tools
- 作用:
- 发进度提示给前端/UI
- 记录工具调用日志
- 给工具设置 channel/chat_id/message_id/session_key 这些上下文
after_iteration
- 作用:
- 上报 tool finish 事件
- 记录 token usage
- 做一轮结束时的收尾工作
finalize_content
- 作用:把模型原始输出再过一层处理
- 当前主要是 strip_think,把 thinking/reasoning 内容剥掉再给用户
工具结果截断
截断代码
ini
# nanobot/agent/runner.py L250(模块级常量定义)
_TOOL_RESULT_MAX_CHARS = 16000
# nanobot/agent/runner.py L334--336(循环内使用)
if len(result) > _TOOL_RESULT_MAX_CHARS:
result = result[:_TOOL_RESULT_MAX_CHARS] + "\n...(truncated)"这是AgentRunner 有一个重要的优化------_TOOL_RESULT_MAX_CHARS = 16000。当工具返回的结果超过 16000 个字符时,会被截断。
为什么是 16000 字符
三个原因:
- 上下文窗口有限:过长的工具结果会挤压历史消息和 system prompt 的空间
- Lost in the Middle 问题:LLM 处理超长文本时,中间部分的信息容易被忽略,导致处理效果下降
- Token 成本:截断可以有效控制成本
16000 字符是一个经验值------足以包含大多数工具返回的有用信息,同时不会过度占用上下文。
存在的问题:
硬截断简单稳定,但它同时也有一个隐含假设:前面的内容比后面更重要。
这个假设在许多情况是不成立的:
- 代码运行报错:关键 stack trace 通常在最后几行,不在开头
- 流式日志输出:最终状态、最新事件在末尾
- 某些工具的返回格式:数据按时间升序排列,最新的在后面
改进:
我马上想到处理就是:重新调用LLM压缩或者使用RAG,但是这同时会引入一定的复杂度,不符合Nanobot轻量的原则。具体对比图如下:
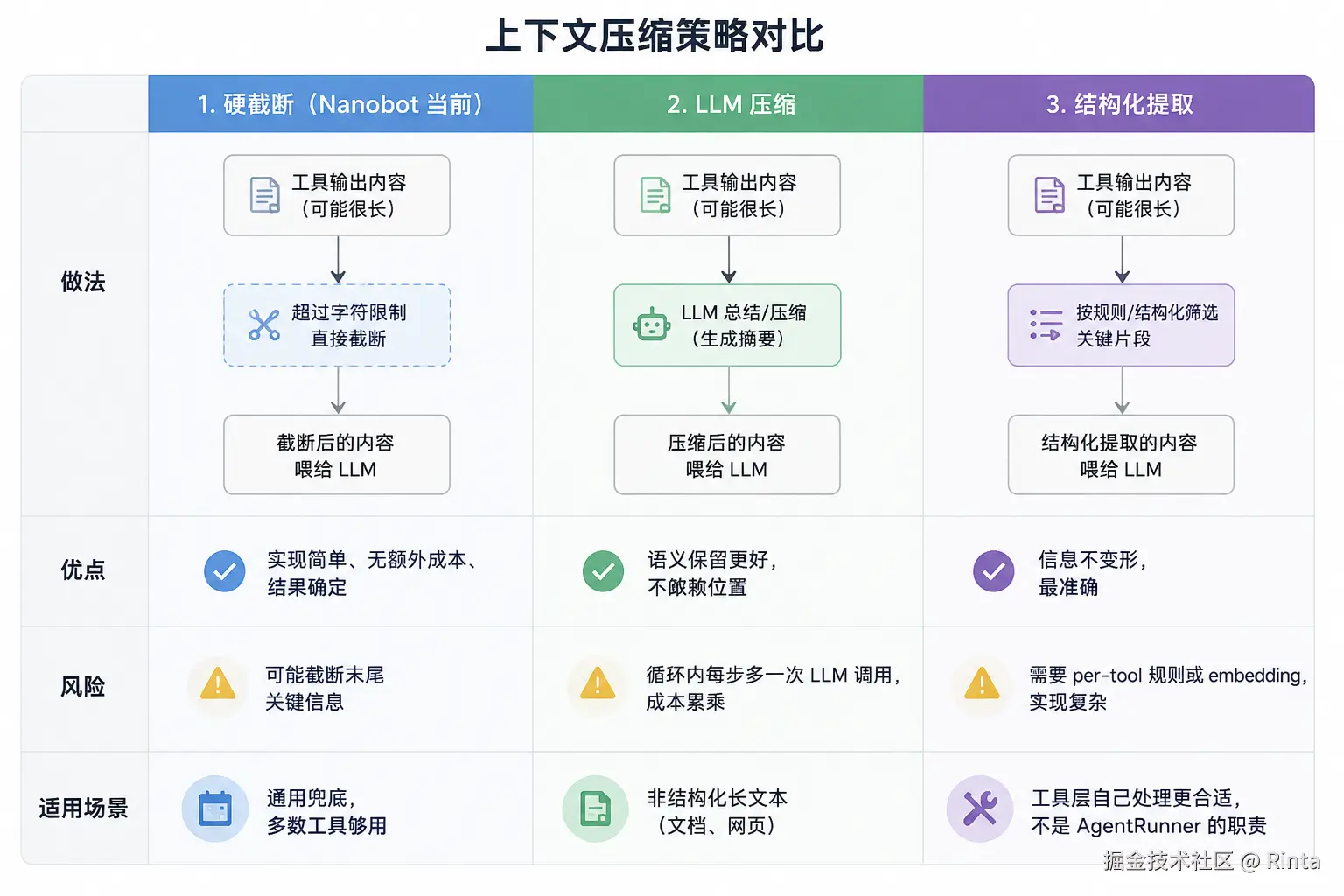
这本质是三种不同的信息控制策略:截断以简单性优先,压缩以语义完整优先,RAG以相关性和准确性优先。Nanobot 选硬截断,也是在实现复杂度和通用稳定性之间做了一个偏向简单的取舍。
最后我权衡了一个小小的方案,不需要 LLM 但又可以解决硬截断问题:首尾截断(保留前 N 字符 + 后 M 字符,中间用省略号连接)
ini
# 首尾截断示意(改进方向,非 Nanobot 当前实现)
HEAD = 12000
TAIL = 3000
if len(result) > HEAD + TAIL:
result = result[:HEAD] + "\n...(truncated)...\n" + result[-TAIL:]三行代码,零额外成本,同时避免了硬截断。
4. 总结
AgentRunner.run() 的核心是一个 for 循环,循环体内嵌了 2个设计细节:
- 工具结果截断:16000 字符硬截断,简单稳定,权衡点在于能否接受末尾信息丢失
- Lifecycle Hooks:三个钩子嵌在固定位置,扩展点预留好,主逻辑不动
LLM 自主规划不需要人工编写任务流。框架只负责:给上下文、给工具列表、跑循环、把结果喂回去。剩下的,交给 LLM。
5.核心 Takeaway
- ReAct 循环的本质:反复问 LLM "下一步做什么",直到它不再调工具为止
- 16000 字符截断:简单优先,隐含假设是"前面比后面重要",权衡点在能否接受末尾信息丢失
- 框架哲学:Nanobot 把规划决策权交给 LLM,框架只提供循环结构