本章目标:从根本理解为什么 LLM 没有记忆、掌握 8 种记忆实现方案(从简单到复杂),每种方案配有完整可运行代码和选型建议,能够为生产级 Agent 选择合适的记忆后端。
前期回顾
一、LLM 为什么天生没有记忆?
这是初学者最常见的困惑:"为什么昨天告诉了 AI 我的名字,今天它又不记得了?"
原因 :LLM 是无状态函数 。每次 API 调用都是独立的,就像调用 sin(x) 函数,它不会"记住"上次你传过什么参数。
python
# LLM 的无状态性
llm.invoke("我叫张三") # → "您好,张三!"
llm.invoke("我叫什么?") # → "我不知道您的名字" ← 完全独立的两次调用!解决方案 :在每次调用时,把历史对话记录一并传入,让 LLM 能"看到"过去说了什么。
python
# 有记忆的对话:把历史消息都传进去
messages = [
{"role": "user", "content": "我叫张三"},
{"role": "assistant", "content": "您好,张三!"},
{"role": "user", "content": "我叫什么?"}, # 有了历史,模型能回答了
]
llm.invoke(messages) # → "你叫张三"记忆系统的本质就是:如何管理这份历史消息。
二、8 种记忆方案全景对比
| 方案 | 持久化 | 多会话 | 外部服务 | 适用场景 |
|---|---|---|---|---|
| 手动消息历史 | ❌(进程内) | 手动管理 | 不需要 | 学习、简单原型 |
| 滑动窗口 | ❌(进程内) | 手动管理 | 不需要 | 控制 Token 成本 |
| LangGraph MemorySaver | ❌(进程内) | ✅ thread_id | 不需要 | 多会话 Agent |
| SQLite SqliteSaver | ✅(文件) | ✅ thread_id | 不需要 | 单机持久化 |
| 摘要记忆 | 可扩展 | 可扩展 | 可选 | 长对话压缩 |
| 文件记忆(JSON) | ✅(文件) | ✅ | 不需要 | 零依赖原型 |
| Redis 记忆 | ✅ | ✅ | Redis 服务 | 高并发低延迟 |
| MongoDB 记忆 | ✅ | ✅ | MongoDB 服务 | 结构灵活 |
| PostgreSQL 记忆 | ✅ | ✅ | PostgreSQL 服务 | 企业级事务 |
三、方案一:手动消息历史(最基础)
代码文件:lessons/10_memory/01_conversation_memory.py
python
import os
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(
model="qwen-plus",
temperature=0.7,
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# ── 核心:维护一个消息历史列表 ────────────────────────────────
history = [
# system 消息通常放在最前面,定义 AI 的行为
SystemMessage(content="你是一个贴心的生活助手。记住用户告诉你的所有个人信息。")
]
def chat(user_input: str) -> str:
"""一次对话:追加用户消息、调用 LLM、追加 AI 回复。"""
# 1. 追加用户消息
history.append(HumanMessage(content=user_input))
# 2. 将完整历史传给 LLM(这就是"记忆"的实现原理)
response = llm.invoke(history)
# 3. 追加 AI 回复
history.append(AIMessage(content=response.content))
return response.content
# 测试多轮对话
print(chat("我叫李明,今年28岁,住在北京。"))
print(chat("我喜欢跑步,每周跑3次。"))
print(chat("我叫什么名字?住哪里?")) # AI 应该能回答
print(f"\n当前对话长度:{len(history)} 条消息")
print(f"预计 Token 消耗:{sum(len(m.content) for m in history) // 4} 个(近似)")滑动窗口变体(控制 Token 消耗)
python
WINDOW_SIZE = 6 # 最近 3 轮对话(6 条消息)
def chat_windowed(user_input: str) -> str:
"""滑动窗口对话:只保留最近 N 条消息。"""
history.append(HumanMessage(content=user_input))
# 始终保留 system 消息,其余只取最近 WINDOW_SIZE 条
system_msgs = [m for m in history if isinstance(m, SystemMessage)]
recent_msgs = [m for m in history if not isinstance(m, SystemMessage)][-WINDOW_SIZE:]
window = system_msgs + recent_msgs
response = llm.invoke(window)
history.append(AIMessage(content=response.content))
return response.content优缺点分析:
- ✅ 零依赖,最简单
- ❌ 历史无限增长,对话越长 Token 消耗越大
- ❌ 程序重启后记忆消失
- ❌ 多会话需要手动维护多个 history 列表
四、方案二:LangGraph MemorySaver(推荐入门)
代码文件:lessons/10_memory/02_langgraph_memory.py
python
import os
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import MemorySaver
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(
model="qwen-plus",
temperature=0.7,
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
@tool
def get_current_time() -> str:
"""获取当前北京时间。"""
from datetime import datetime, timezone, timedelta
return datetime.now(timezone(timedelta(hours=8))).strftime("%Y-%m-%d %H:%M")
# ── 创建带记忆的 Agent ────────────────────────────────────────
memory = MemorySaver() # 内存检查点(进程内,重启后消失)
agent = create_react_agent(
llm,
tools=[get_current_time],
checkpointer=memory, # ← 关键:绑定记忆检查点
state_modifier="""你是有记忆的助手。
请记住用户告诉你的所有信息,在后续对话中主动应用这些信息。
用中文回答。""",
)
# ── 关键:thread_id 区分不同会话 ─────────────────────────────
config_alice = {"configurable": {"thread_id": "alice_001"}}
config_bob = {"configurable": {"thread_id": "bob_001"}}
def ask(question: str, config: dict) -> str:
"""向 Agent 提问。"""
result = agent.invoke(
{"messages": [HumanMessage(content=question)]},
config=config,
)
return result["messages"][-1].content
# ── 测试多会话隔离 ────────────────────────────────────────────
print("=== Alice 的会话 ===")
print(ask("我叫Alice,我是一名产品经理,在上海工作。", config_alice))
print(ask("我的工作是做什么的?", config_alice))
print("\n=== Bob 的会话(与 Alice 隔离)===")
print(ask("我叫Bob,我是工程师,在北京工作。", config_bob))
print(ask("我在哪里工作?", config_bob))
print("\n=== 回到 Alice 的会话(Alice 的记忆不受 Bob 影响)===")
print(ask("回顾一下我的职业信息。", config_alice))
# ── 查看会话状态 ──────────────────────────────────────────────
state = agent.get_state(config_alice)
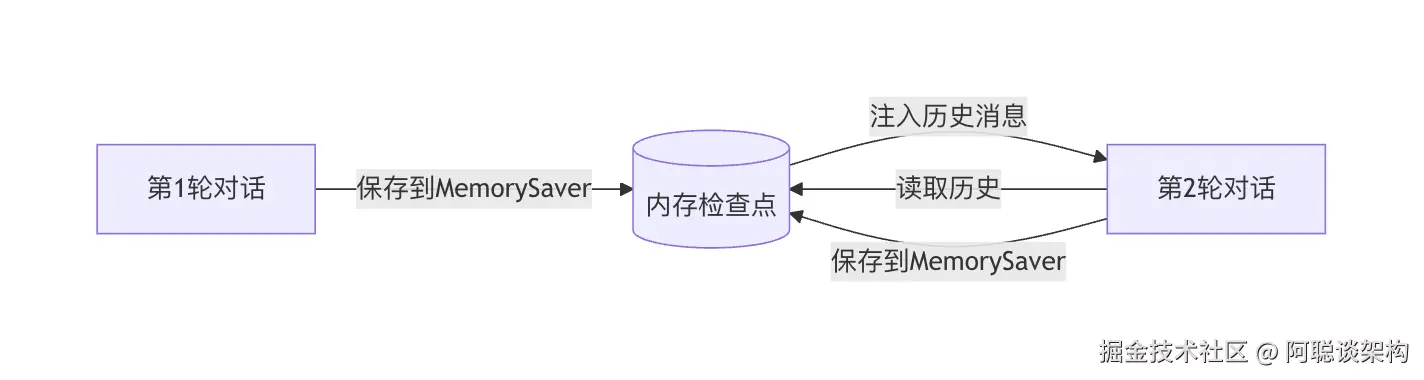
print(f"\nAlice 会话消息数:{len(state.values.get('messages', []))}")MemorySaver 的工作原理:
五、方案三:SQLite 持久化(跨进程重启)
代码文件:10_memory/03_persistent_memory.py
bash
# 安装依赖
uv sync --extra memory
python
import os
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.sqlite import SqliteSaver
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(
model="qwen-plus",
temperature=0.7,
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
DB_PATH = "agent_memory.db" # 使用固定路径,才能跨进程持久化
def create_agent_with_sqlite():
"""创建使用 SQLite 记忆的 Agent。"""
checkpointer = SqliteSaver.from_conn_string(DB_PATH)
return create_react_agent(
llm,
tools=[],
checkpointer=checkpointer,
state_modifier="你是持久记忆助手,即使程序重启,你也记得之前的对话。",
), checkpointer
# ── 第一次运行(建立记忆)────────────────────────────────────
print("=== 第一次运行 ===")
agent, checkpointer = create_agent_with_sqlite()
config = {"configurable": {"thread_id": "user_persistent_001"}}
# 注意:SqliteSaver 支持上下文管理器,也支持直接使用
result = agent.invoke(
{"messages": [HumanMessage(content="我叫赵六,我最喜欢的颜色是蓝色。")]},
config=config,
)
print(result["messages"][-1].content)
# ── 模拟程序重启(重新创建 Agent,但使用同一个 DB 文件)────
print("\n=== 模拟程序重启后 ===")
agent2, checkpointer2 = create_agent_with_sqlite() # 新实例,但同一个 DB
result2 = agent2.invoke(
{"messages": [HumanMessage(content="我最喜欢什么颜色?我叫什么名字?")]},
config=config, # 同一个 thread_id
)
print(result2["messages"][-1].content)
# AI 应该能回答"蓝色"和"赵六",即使是"重启后"的新实例SqliteSaver vs MemorySaver 的唯一区别:
python
# MemorySaver(进程内,重启消失)
checkpointer = MemorySaver()
# SqliteSaver(文件持久化,重启后恢复)
checkpointer = SqliteSaver.from_conn_string("memory.db")
# API 完全一样,只是 checkpointer= 参数不同!
agent = create_react_agent(llm, tools, checkpointer=checkpointer)六、方案四:摘要记忆(长对话 Token 优化)
代码文件:lessons/10_memory/04_summary_memory.py
当对话很长时(50+ 轮),完整历史可能消耗几千个 Token。摘要记忆将旧消息压缩为文字摘要:
python
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_core.messages import RemoveMessage, HumanMessage, AIMessage, SystemMessage
class SummaryState(TypedDict):
messages: Annotated[list, add_messages] # 当前消息窗口
summary: str # 历史摘要
SUMMARY_THRESHOLD = 6 # 超过 6 条消息时触发摘要
KEEP_RECENT = 4 # 摘要后保留最近 4 条
def chat_node(state: SummaryState) -> dict:
"""主对话节点:将摘要注入系统提示,然后调用 LLM。"""
messages = state["messages"]
summary = state.get("summary", "")
# 如果有历史摘要,将其注入到系统提示中
if summary:
context = [SystemMessage(content=f"对话历史摘要:{summary}\n\n基于以上历史和当前对话回答用户。")]
full_messages = context + messages
else:
full_messages = messages
response = llm.invoke(full_messages)
return {"messages": [response]}
def should_summarize(state: SummaryState) -> str:
"""判断是否需要摘要:消息数超过阈值时触发。"""
if len(state["messages"]) > SUMMARY_THRESHOLD:
return "summarize"
return END
def summarize_node(state: SummaryState) -> dict:
"""摘要节点:压缩旧消息,只保留最近几条。"""
messages = state["messages"]
old_messages = messages[:-KEEP_RECENT] # 要压缩的旧消息
recent_messages = messages[-KEEP_RECENT:] # 保留的最近消息
existing_summary = state.get("summary", "")
# 用 LLM 生成摘要
summary_prompt = f"{"之前的摘要:" + existing_summary + '\n\n' if existing_summary else ''}"
summary_prompt += "以下对话内容需要压缩成摘要(保留所有关键信息):\n"
summary_prompt += "\n".join(
f"{'用户' if isinstance(m, HumanMessage) else 'AI'}:{m.content}"
for m in old_messages
if isinstance(m, (HumanMessage, AIMessage))
)
new_summary = llm.invoke([HumanMessage(content=summary_prompt)]).content
# 使用 RemoveMessage 删除旧消息(LangGraph 的特殊消息类型)
deletes = [RemoveMessage(id=m.id) for m in old_messages]
print(f"[摘要] 压缩了 {len(old_messages)} 条旧消息")
print(f"[摘要] 新摘要:{new_summary[:100]}...")
return {"summary": new_summary, "messages": deletes}
# 构建摘要记忆图
builder = StateGraph(SummaryState)
builder.add_node("chat", chat_node)
builder.add_node("summarize", summarize_node)
builder.add_edge(START, "chat")
builder.add_conditional_edges("chat", should_summarize, {"summarize": "summarize", END: END})
builder.add_edge("summarize", END)
summary_graph = builder.compile()
# 测试
test_messages = [
"我叫王芳,今年35岁,是北京的一名教师。",
"我教数学,已经教了10年了。",
"我有两个孩子,大的8岁,小的5岁。",
"我最近在备考教师资格证高级别考试。",
"我丈夫是程序员,我们住在朝阳区。",
"今天天气真好,我想出去跑步。",
"我叫什么,做什么工作?", # 这里应该触发摘要,但 AI 仍能从摘要中回答
]
state = {"messages": [], "summary": ""}
for msg_text in test_messages:
print(f"\n用户:{msg_text}")
state = summary_graph.invoke(
{"messages": state["messages"] + [HumanMessage(content=msg_text)],
"summary": state.get("summary", "")}
)
print(f"AI:{state['messages'][-1].content}")
print(f" [当前消息数: {len(state['messages'])}, 有摘要: {bool(state.get('summary'))}]")七、方案五~八:外部服务记忆后端
文件记忆(JSON)
代码文件:lessons/10_memory/05_file_memory.py
python
import json
import os
from pathlib import Path
from datetime import datetime
MEMORY_FILE = "/tmp/agent_memory.json"
class FileMemoryBackend:
"""基于 JSON 文件的记忆后端。"""
def __init__(self, file_path: str = MEMORY_FILE):
self.file_path = Path(file_path)
self._data = self._load()
def _load(self) -> dict:
if self.file_path.exists():
return json.loads(self.file_path.read_text(encoding="utf-8"))
return {}
def _save(self):
self.file_path.write_text(json.dumps(self._data, ensure_ascii=False, indent=2), encoding="utf-8")
def save_message(self, thread_id: str, role: str, content: str):
"""保存一条消息到指定会话。"""
if thread_id not in self._data:
self._data[thread_id] = {"messages": [], "created_at": datetime.now().isoformat()}
self._data[thread_id]["messages"].append({
"role": role,
"content": content,
"timestamp": datetime.now().isoformat()
})
self._save()
def get_messages(self, thread_id: str, last_n: int = 20) -> list:
"""获取指定会话的最近 N 条消息。"""
messages = self._data.get(thread_id, {}).get("messages", [])
return messages[-last_n:]
def list_sessions(self) -> list:
"""列出所有会话 ID。"""
return list(self._data.keys())
# 使用示例
memory = FileMemoryBackend()
def chat_with_file_memory(thread_id: str, user_input: str) -> str:
# 保存用户消息
memory.save_message(thread_id, "user", user_input)
# 构建消息历史
raw_messages = memory.get_messages(thread_id, last_n=10)
from langchain_core.messages import HumanMessage, AIMessage
messages = []
for msg in raw_messages:
if msg["role"] == "user":
messages.append(HumanMessage(content=msg["content"]))
else:
messages.append(AIMessage(content=msg["content"]))
# 调用 LLM
response = llm.invoke(messages)
# 保存 AI 回复
memory.save_message(thread_id, "assistant", response.content)
return response.contentRedis 记忆
代码文件:lessons/10_memory/06_redis_memory.py
bash
uv sync --extra memory-redis
export REDIS_URL=redis://localhost:6379/0
python
import os
import json
from datetime import datetime
try:
import redis
except ImportError:
print("❌ 请安装 Redis:uv sync --extra memory-redis")
exit(1)
REDIS_URL = os.getenv("REDIS_URL", "redis://localhost:6379/0")
class RedisMemoryBackend:
"""基于 Redis 的记忆后端。"""
def __init__(self, url: str, ttl_seconds: int = 86400):
self.client = redis.from_url(url, socket_connect_timeout=5, decode_responses=True)
self.ttl = ttl_seconds # 对话记录的过期时间(默认 24 小时)
# 测试连接
try:
self.client.ping()
print("✅ Redis 连接成功")
except redis.ConnectionError as e:
raise ConnectionError(f"Redis 连接失败:{e}")
def save_message(self, thread_id: str, role: str, content: str):
"""将消息保存到 Redis List。"""
key = f"memory:{thread_id}:messages"
message = json.dumps({
"role": role,
"content": content,
"timestamp": datetime.now().isoformat()
}, ensure_ascii=False)
self.client.rpush(key, message) # 追加到列表末尾
self.client.expire(key, self.ttl) # 设置过期时间(TTL)
def get_messages(self, thread_id: str, last_n: int = 20) -> list:
"""获取最近 N 条消息。"""
key = f"memory:{thread_id}:messages"
# lrange(-last_n, -1) 获取最后 last_n 条
raw = self.client.lrange(key, -last_n, -1)
return [json.loads(m) for m in raw]
def clear_session(self, thread_id: str):
"""清空指定会话的记忆。"""
self.client.delete(f"memory:{thread_id}:messages")MongoDB 记忆
代码文件:lessons/10_memory/07_mongodb_memory.py
bash
uv sync --extra memory-mongodb
export MONGODB_URI=mongodb://localhost:27017
python
try:
from pymongo import MongoClient
from pymongo.errors import ConnectionFailure
except ImportError:
print("❌ 请安装 pymongo:uv sync --extra memory-mongodb")
exit(1)
MONGODB_URI = os.getenv("MONGODB_URI", "mongodb://localhost:27017")
class MongoMemoryBackend:
"""基于 MongoDB 的记忆后端。"""
def __init__(self, uri: str, db_name: str = "agent_memory"):
self.client = MongoClient(uri, serverSelectionTimeoutMS=5000)
# 测试连接
self.client.admin.command("ping")
self.db = self.client[db_name]
self.sessions = self.db["sessions"]
# 创建索引
self.sessions.create_index([("thread_id", 1), ("timestamp", 1)])
print("✅ MongoDB 连接成功")
def save_message(self, thread_id: str, role: str, content: str):
"""保存一条消息。"""
self.sessions.insert_one({
"thread_id": thread_id,
"role": role,
"content": content,
"timestamp": datetime.now(),
})
def get_messages(self, thread_id: str, last_n: int = 20) -> list:
"""获取最近 N 条消息。"""
cursor = (
self.sessions
.find({"thread_id": thread_id}, {"_id": 0})
.sort("timestamp", -1)
.limit(last_n)
)
return list(reversed(list(cursor))) # 倒序还原成时间正序PostgreSQL 记忆
代码文件:lessons/10_memory/08_postgresql_memory.py
bash
uv sync --extra memory-postgres
export POSTGRES_DSN=postgresql://postgres:postgres@localhost:5432/postgres
python
try:
import psycopg
except ImportError:
print("❌ 请安装 psycopg:uv sync --extra memory-postgres")
exit(1)
POSTGRES_DSN = os.getenv("POSTGRES_DSN", "postgresql://postgres:postgres@localhost:5432/postgres")
class PostgresMemoryBackend:
"""基于 PostgreSQL 的记忆后端。"""
def __init__(self, dsn: str):
self.dsn = dsn
self._init_db()
print("✅ PostgreSQL 连接成功")
def _init_db(self):
"""初始化数据库表(如果不存在则创建)。"""
with psycopg.connect(self.dsn) as conn:
conn.execute("""
CREATE TABLE IF NOT EXISTS agent_messages (
id SERIAL PRIMARY KEY,
thread_id TEXT NOT NULL,
role TEXT NOT NULL,
content TEXT NOT NULL,
created_at TIMESTAMP DEFAULT NOW()
)
""")
conn.execute("""
CREATE INDEX IF NOT EXISTS idx_thread_time
ON agent_messages (thread_id, created_at)
""")
def save_message(self, thread_id: str, role: str, content: str):
"""保存消息(使用参数化查询防止 SQL 注入)。"""
with psycopg.connect(self.dsn) as conn:
conn.execute(
"INSERT INTO agent_messages (thread_id, role, content) VALUES (%s, %s, %s)",
(thread_id, role, content) # 参数化,安全
)
def get_messages(self, thread_id: str, last_n: int = 20) -> list:
"""获取最近 N 条消息。"""
with psycopg.connect(self.dsn) as conn:
rows = conn.execute(
"""SELECT role, content, created_at
FROM agent_messages
WHERE thread_id = %s
ORDER BY created_at DESC
LIMIT %s""",
(thread_id, last_n)
).fetchall()
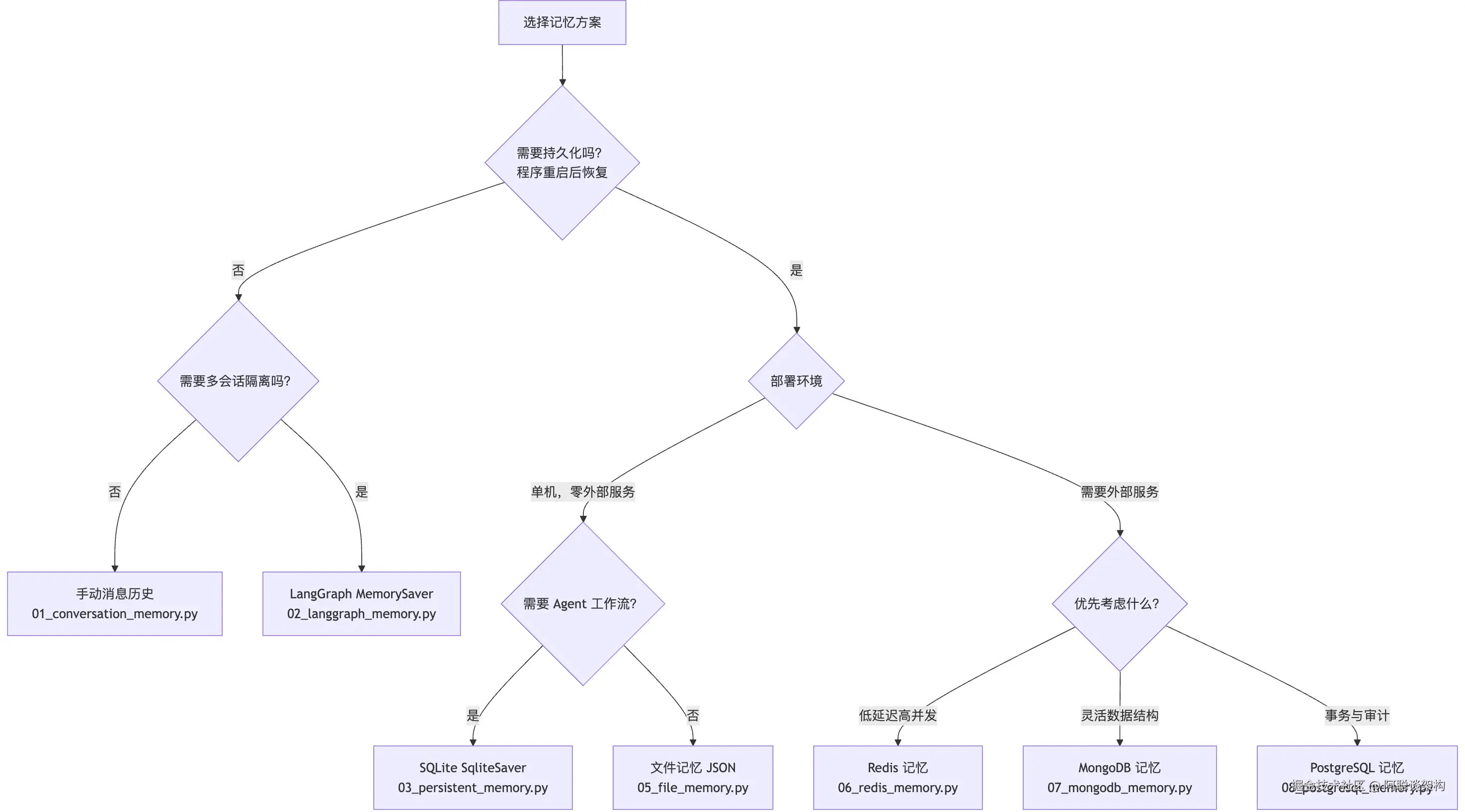
return [{"role": r[0], "content": r[1], "timestamp": str(r[2])} for r in reversed(rows)]八、选型决策树
九、长对话 Token 成本控制建议
| 对话轮数 | 推荐策略 |
|---|---|
| < 10 轮 | 完整历史,无需优化 |
| 10-50 轮 | 滑动窗口(保留最近 10-20 条) |
| > 50 轮 | 摘要记忆(LLM 自动压缩旧消息) |
| 生产级 | Redis/PostgreSQL + 摘要记忆组合 |
🎉 恭喜完成10章学习! 你现在掌握了从基础 LLM 调用到生产级 Agent 记忆系统的完整知识体系。下一步建议:选择一个你真实需要解决的业务问题,用本课程学到的技术构建一个完整的 AI 应用。
AI入门开发系列文章合集
作者:阿聪谈架构公众号:阿聪谈架构 (分享后端架构 / AI / Java 技术文章)
相关代码关注公众号:【阿聪谈架构】 回复:AI专栏代码