论文题目:Compositional Caching for Training-free Open-vocabulary Attribute Detection(用于免训练开放词汇表属性检测的组合缓存)
会议:CVPR2025
摘要:属性检测对于许多计算机视觉任务至关重要,因为它使系统能够描述颜色、纹理和材料等属性。目前的方法通常依赖于费力的注释过程,而这些过程本身是有限的:对象可以以任意的细节级别(例如,颜色与颜色阴影)来描述,当注释者没有得到仔细的指导时,会导致模棱两可。此外,它们在预定义的一组属性内运行,降低了对不可预见的下游应用程序的可伸缩性和适应性。我们提出了组合缓存(COMCA),这是一种无需训练的开放词汇表属性检测方法,克服了这些限制。COMCA只需要目标属性和对象的列表作为输入,通过利用网络规模的数据库和大型语言模型来确定属性与对象的兼容性,使用它们来填充图像的辅助缓存。为了说明属性的组成性质,缓存图像接收可变属性标签。这些在推理时基于输入图像和缓存图像之间的相似性被聚集,完善了对潜在的视觉语言模型(VLM)的预测。重要的是,我们的方法是与模型无关的,与各种VLM兼容。在公共数据集上的实验表明,COMCA的性能明显优于零镜头和基于缓存的基线,与最近的基于训练的方法相竞争,证明了精心设计的免训练方法可以成功地解决开放词汇属性检测问题。
项目地址:https://comca-attributes.github.io
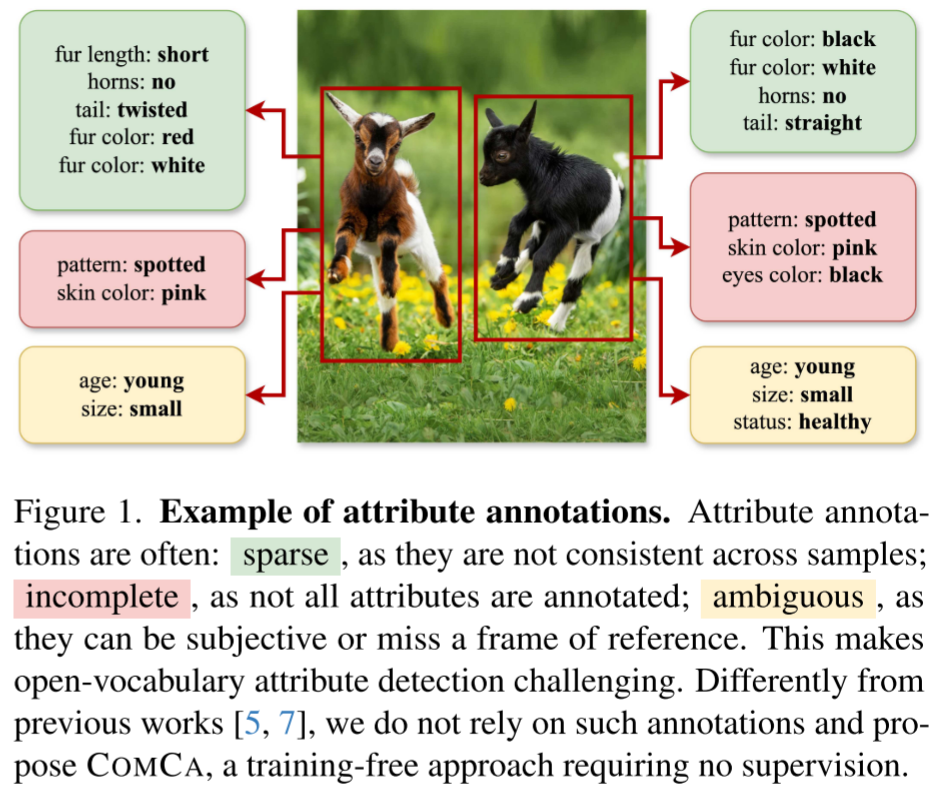
COMCA - 无需训练的开放词汇属性检测新范式
引言:属性检测的困境
想象一下,你正在开发一个智能购物助手,用户希望找到"一件红色 的短袖 、棉质 T恤"。这个看似简单的需求背后,隐藏着计算机视觉中的一个复杂问题------属性检测。
传统的属性检测方法依赖于大量的人工标注数据。但这种方法有个致命缺陷:标注既昂贵 又主观。对于同一只山羊,有人可能标注为"棕色",另一人可能说是"红棕色"。更糟糕的是,这些模型只能识别训练时见过的属性,无法适应新的需求。
今天,我们要介绍的这篇CVPR 2025论文提出了一个优雅的解决方案------COMCA (Compositional Caching),一个完全无需训练的开放词汇属性检测方法。
核心洞察:组合的力量
COMCA的设计基于对现实世界的两个简单而深刻的观察:
观察1:并非所有属性都适用于所有对象
- 你可以说一只狗是"湿的",但很少说一个塑料瓶是"湿的"
- "长角"适用于山羊,但不适用于猫
观察2:每个对象同时具有多个属性
- 一只山羊不仅有颜色,还有大小、年龄、毛发纹理等
- 忽略这种多属性性质会导致错误关联
这两个观察似乎显而易见,但现有的缓存方法却忽视了它们。COMCA正是通过系统性地利用这些组合原则,实现了突破性的性能。
技术架构:三步走策略
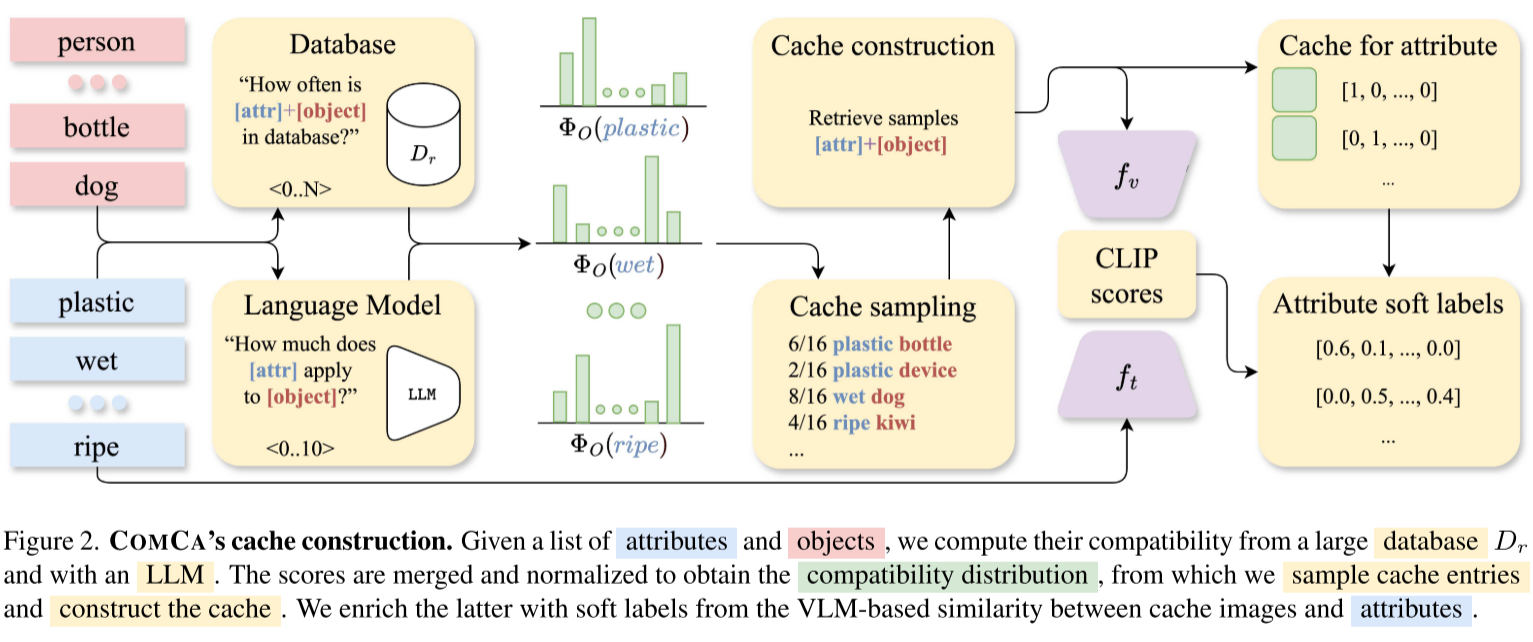
第一步:智能缓存构建
COMCA不是盲目地为每个属性存储随机图像,而是智能地选择最相关的对象-属性组合。
如何判断哪些组合是合理的?
COMCA使用了双管齐下的策略:
-
数据驱动:从大规模图像-文本数据库(如CC12M,1200万图像对)中统计属性和对象的共现频率
- 例如:"塑料 + 瓶子"的共现频率高,而"湿 + 瓶子"的共现频率低
-
知识驱动:查询大语言模型(GPT-3.5)评估属性-对象组合的合理性
- 弥补数据中的偏见(例如,人们很少在标题中描述"干燥的狗",尽管这是常态)
这两个分数相乘后归一化,得到一个兼容性分布。然后,COMCA从这个分布中采样对象,为每个属性检索K个相关图像。
优势 :这种方法将缓存大小从 |属性| × |对象| × K 降低到仅 |属性| × K,同时保证了缓存的质量。
第二步:软标签赋能
传统缓存方法为每个图像分配一个硬标签(one-hot向量)。例如,为"大型汽车"检索的图像只会被标记为"大"。
但这有个问题:这辆车可能也是"蓝色"的、"现代"的、"轿车"类型的。硬标签忽略了这些信息。
COMCA的解决方案:软标签
对于缓存中的每张图像,COMCA计算它与所有目标属性的相似度(使用VLM的图像和文本编码器)。这些相似度分数经过归一化后,成为软标签。
归一化的魔法:
- 问题:VLM的图像-文本相似度存在"模态间隙",分数范围狭窄
- 解决:使用整个缓存的统计信息(均值和标准差)进行Z-score归一化,然后应用softmax
这样,每个缓存图像都能为多个属性贡献分数,而不是仅限于采样时的那个属性。
第三步:推理时融合
在推理阶段,COMCA结合了两个信号:
- VLM的零样本预测:直接比较输入图像与属性文本
- 缓存的贡献:计算输入图像与缓存中所有图像的相似度,用软标签加权
最终预测 = λ × 缓存分数 + VLM分数
这种融合策略让COMCA既能利用VLM的强大泛化能力,又能通过缓存提供特定任务的锚点。
实验结果
数据集
- OVAD:117个属性,80个类别,14,300个实例
- VAW:620个属性,2,260个类别,更稀疏的标注
主要发现
1. 显著优于零样本和缓存基线
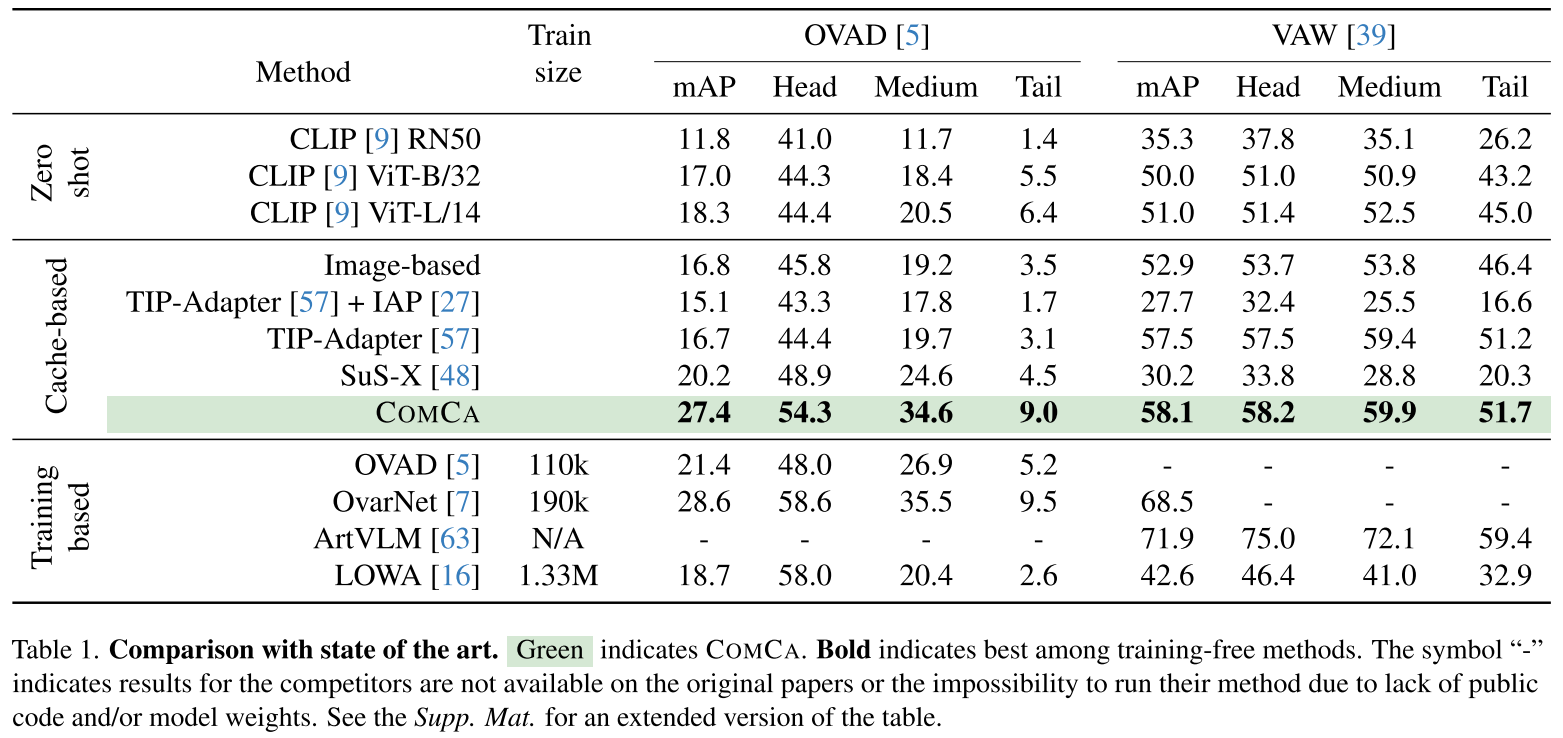
| 方法 | OVAD mAP | VAW mAP |
|---|---|---|
| CLIP ViT-B/32 | 17.0 | 50.0 |
| TIP-Adapter | 16.7 | 57.5 |
| SuS-X | 20.2 | 30.2 |
| COMCA | 27.4 | 58.1 |
COMCA提升:
- vs CLIP:+10.4 (OVAD), +8.1 (VAW)
- vs TIP-Adapter:+10.7 (OVAD), +0.6 (VAW)
- vs SuS-X:+7.2 (OVAD), +27.9 (VAW)
2. 与训练基础方法竞争,甚至超越
- OVAD数据集:COMCA (27.4) 接近OvarNet (28.6,使用19万训练样本)
- VAW数据集:COMCA超越LOWA (42.6,使用133万训练样本),达到58.1 mAP
3. 跨数据集泛化能力卓越
当训练基础的OVAD方法在不同数据集间迁移时,性能从21.4 mAP骤降至16.0 mAP(训练于COCO,测试于VAW)。而COMCA始终保持竞争力,因为它不依赖特定训练集。
4. 模型无关性:适用于多种VLM
在8种不同的VLM架构上测试(CLIP、SigLIP、CoCa、BLIP、X-VLM),COMCA一致性地带来性能提升:
- 平均提升:OVAD +8.9 mAP,VAW +7.0 mAP
- 最高提升:CoCa ViT-L/14上+11.5 mAP
5. Box-free设置的实用性
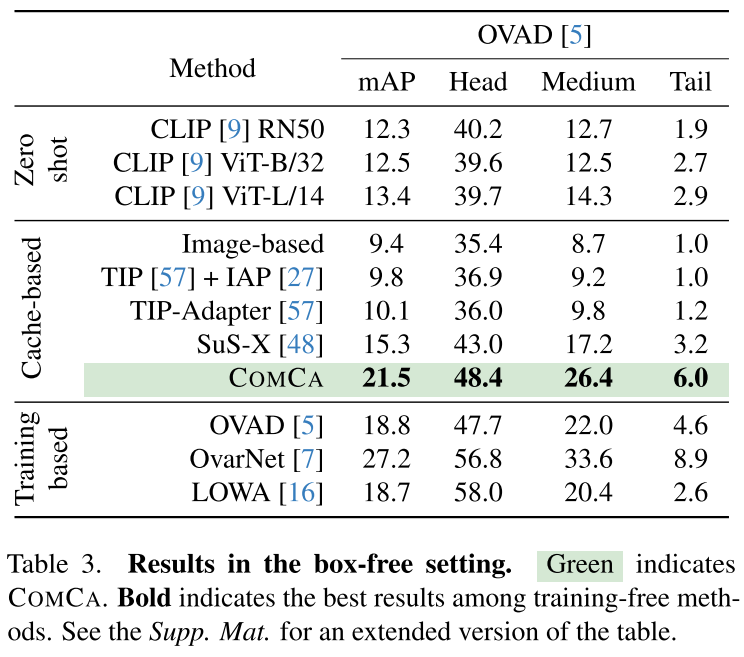
使用YOLOv11M自动检测对象(而非给定边界框),COMCA仍然表现出色:
- 超越CLIP ViT-B/32:+9.0 mAP
- 超越训练基础的OVAD和LOWA
消融研究的关键发现
-
兼容性估计至关重要
- 随机采样:16.7 mAP
- 暴力枚举所有组合:10.6 mAP(过多噪声)
- 仅数据库分数:18.6 mAP
- 仅LLM分数:21.1 mAP
- 融合策略(COMCA) :26.4 mAP
-
软标签的一致性增益
- 在所有兼容性估计策略上,软标签都带来+3.8至+5.4 mAP的提升
-
缓存大小的稳定性
- K=16样本/属性时性能稳定
- VAW在K=1时已表现良好(因属性数量多,缓存已足够代表性)
定性分析:看得见的改进
论文展示了几个定性案例:
- 斑马:CLIP错误地预测为"反光的",COMCA正确识别为"条纹的"
- 棒球运动员:CLIP错误地标记为"巨大的",COMCA正确识别尺寸
- 山羊:训练基础的OVAD因训练集偏见对两个对象预测相同属性,COMCA避免了这个问题
这些案例表明,COMCA的缓存机制提供了更可靠的视觉参考锚点。
方法的优势与局限
优势
- 完全无需训练:零标注数据,零训练时间,零GPU成本
- 不受数据集偏见影响:跨数据集泛化能力强
- 模型无关:可插拔到任何VLM上
- 可扩展:缓存大小与属性数量线性相关
- 易于适应新领域:只需更新属性和对象列表
局限
- 依赖检索质量:缓存质量受限于检索数据库
- LLM成本:兼容性估计需要查询LLM(虽然只需一次)
- 需要对象和属性列表:假设这些是已知的
- 边界框依赖(在box-given设置):虽然也支持box-free
未来方向
论文在结论中提到了几个有趣的未来研究方向:
- 完全开放的设置:不需要预先指定对象或属性列表
- 领域适应:针对特定领域(如航空图像、医学图像)优化缓存构建
- 生成式缓存:更深入地探索使用生成模型(而非检索)构建缓存
- 动态缓存更新:根据推理时的反馈调整缓存
实践建议
如果你想在自己的项目中使用COMCA,这里是一些建议:
- 开始简单:使用论文的默认配置(K=16,λ=1.17,α=0.6)
- 选择合适的VLM:更大的模型(如ViT-L/14)通常表现更好
- 准备好LLM访问:兼容性估计需要GPT-3.5或类似模型
- 考虑数据库选择:CC12M是个好起点,但特定领域可能需要定制数据库
- 评估box-free性能:如果你的应用没有对象检测器,先测试box-given设置的潜力
结论:训练自由的未来
COMCA代表了属性检测研究的一个重要里程碑。它证明了精心设计的训练自由方法可以与昂贵的训练基础方法竞争,甚至在某些方面超越它们。
更重要的是,COMCA体现了一个更广泛的趋势:通过组合 和检索,而不是大规模训练,来构建智能系统。这种范式在资源受限的环境、需要快速适应新任务的场景,以及对模型可解释性有高要求的应用中,具有独特的优势。
随着VLM和LLM的不断进步,像COMCA这样的训练自由方法将变得越来越强大。我们可能正在见证一个新时代的开端------在这个时代,智能不再等于大规模训练,而等于巧妙的组合与检索。