所有内容在同一目录下
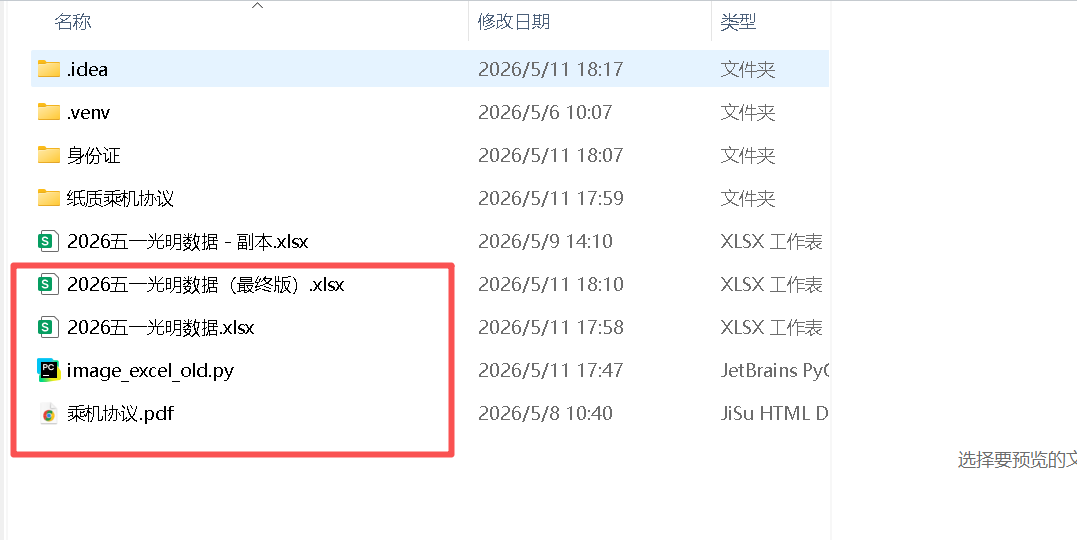
转换前:
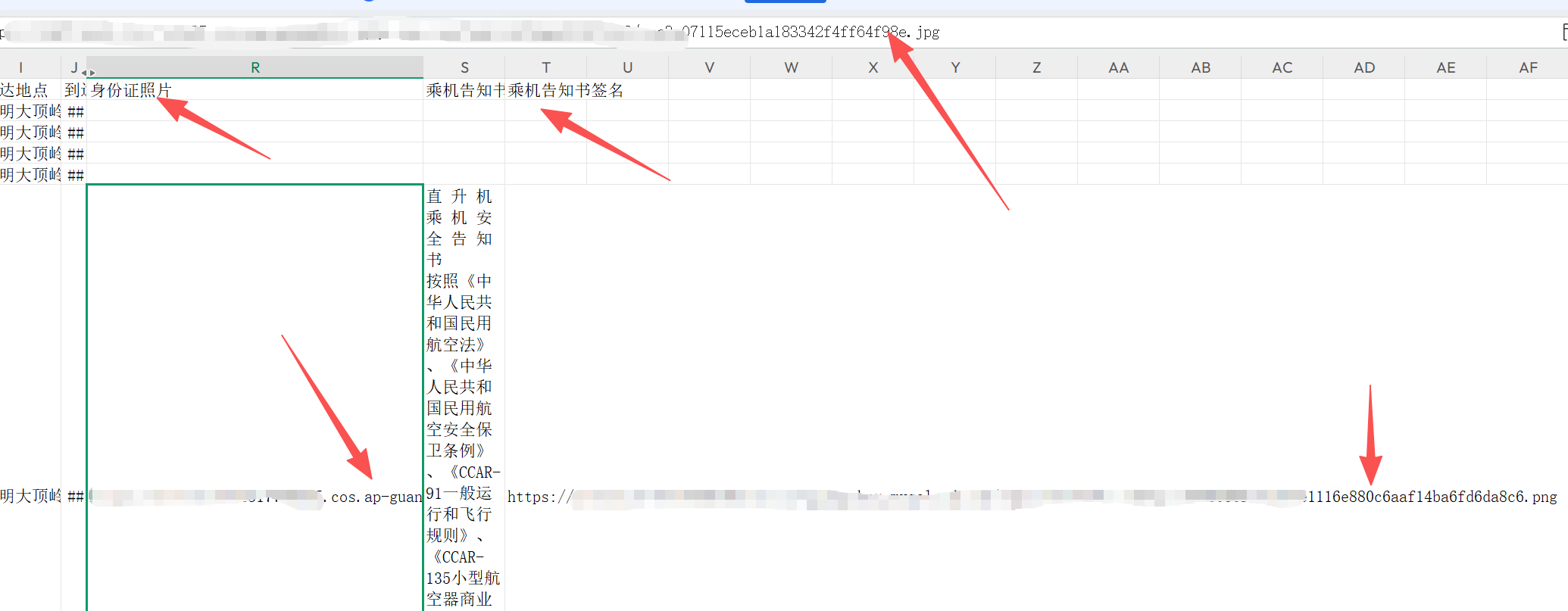
转换后:

链接转图片:image_excel_old.py代码
import pandas as pd
from openpyxl import Workbook
from openpyxl.drawing.image import Image
from openpyxl.styles import Alignment
from io import BytesIO
import os
import logging
from PIL import Image as PILImage
from PIL import ImageDraw, ImageFont
from PIL import ImageOps
import fitz # PyMuPDF 用于读取PDF
import requests
import re
try:
from qcloud_cos import CosConfig, CosS3Client # provided by cos-python-sdk-v5
except Exception: # pragma: no cover
CosConfig = None
CosS3Client = None
# ------------------- 配置 -------------------
logging.basicConfig(level=logging.INFO)
# 生产跑批场景下通常需要 COS 私钥才能拉取图片。
# 优先从环境变量读取(推荐),否则回退到历史默认值以保证脚本可直接运行。
# TENCENT_COS_SECRETID(腾讯COS访问ID)
secret_id = os.getenv("COS_SECRET_ID", "").strip() or "AKIDRp8b6cvKbmq3GKGJQSGpJkL4"
# TENCENT_COS_SECRETKEY(腾讯COS访问密钥)
secret_key = os.getenv("COS_SECRET_KEY", "").strip() or "Z1PKApSwHTn5FJSkDWmoeXH6vx"
region = "ap-guangzhou"
cos_client = None
if CosConfig and CosS3Client and secret_id and secret_key:
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key, Token=None, Scheme="https")
cos_client = CosS3Client(config)
CSV_FILE = "2026五一光明数据.xlsx"
PDF_FILE = "乘机协议.pdf" # 同级目录PDF
SAVE_EXCEL = "2026五一光明数据(最终版).xlsx"
COL_ID = "身份证照片"
COL_NOTICE = "乘机告知书"
COL_SIGN = "乘机告知书签名"
COL_PHONE = "电话"
COL_ID_NO = "身份证号码"
COL_FLIGHT_DATE = "实际起飞日期"
# PDF 渲染倍率(越大越清晰,但文件更大)
PDF_RENDER_SCALE = 4.0
PDF_COORD_BASE_SCALE = 1.6
# 身份证竖图转横图旋转方向(90 或 -90)。默认 -90,修复"正反不对"问题。
ID_ROTATE_DEG = -90
# 个别上传图片的相机方向和 EXIF 不一致,需要在通用方向处理后再修正。
# key 支持 URL 片段;value 是 PIL rotate 的角度,正数为逆时针。
ID_ROTATE_OVERRIDES = {
"cac3a07115eceb1a183342f4ff64f98e": 90,
}
SIGN_WIDTH = 180 # 签名大小
SIGN_HEIGHT = 60
CELL_PADDING = 5
# 输出版式参考「光明10月第二轮398 - 副本.xlsx」
# Excel 行高单位是 point;身份证显示高度 333px 约等于 250pt。
# 加一点余量,避免图片在 Excel/WPS 中贴边或被行边界压住。
REFERENCE_ROW_HEIGHT = 260
ID_DISPLAY_SIZE = (405, 290)
AGREEMENT_DISPLAY_SIZE = (268, 290)
REFERENCE_COLUMN_WIDTHS = {
"A": 13.0,
"B": 13.0,
"C": 16.6272727272727,
"D": 27.8727272727273,
"E": 18.2545454545455,
"F": 14.4545454545455,
"G": 9.0,
"H": 9.0,
"I": 9.0,
"J": 9.0,
"K": 9.0,
"L": 9.0,
"M": 9.0,
"N": 38.2545454545455,
"O": 9.0,
"P": 9.0,
"Q": 9.0,
"R": 58.5909090909091,
"S": 39.0636363636364,
}
# 协议页是渲染成图片后再贴图/写字,以下坐标基于 1.6x 渲染的 (953, 1348) 页面。
# 实际渲染倍率可调,使用时会自动换算到当前 PDF_RENDER_SCALE。
# 如模板PDF有调整,可微调这几个常量
AGREEMENT_SIGN_POS = (210, 895) # "签字"横线起始位置(名字/签名)
AGREEMENT_IDNO_POS = (563, 930) # "身份证号码"横线起始位置
AGREEMENT_PHONE_POS = (240, 996) # "联系电话"横线起始位置
AGREEMENT_DATE_Y_POS = (492, 996) # "日期-年"
AGREEMENT_DATE_M_POS = (590, 996) # "日期-月"
AGREEMENT_DATE_D_POS = (675, 996) # "日期-日"
AGREEMENT_TEXT_COLOR = (0, 0, 0)
AGREEMENT_TEXT_SIZE = int(os.getenv("AGREEMENT_TEXT_SIZE", "20"))
AGREEMENT_FONT_PATH = os.getenv("AGREEMENT_FONT_PATH", "").strip()
FONT_CANDIDATES = (
AGREEMENT_FONT_PATH,
# Windows
os.path.join(os.environ.get("WINDIR", r"C:\Windows"), "Fonts", "msyh.ttc"),
os.path.join(os.environ.get("WINDIR", r"C:\Windows"), "Fonts", "msyhbd.ttc"),
os.path.join(os.environ.get("WINDIR", r"C:\Windows"), "Fonts", "simhei.ttf"),
os.path.join(os.environ.get("WINDIR", r"C:\Windows"), "Fonts", "simsun.ttc"),
os.path.join(os.environ.get("WINDIR", r"C:\Windows"), "Fonts", "arialuni.ttf"),
# macOS
"/System/Library/Fonts/PingFang.ttc",
"/System/Library/Fonts/Supplemental/Arial Unicode.ttf",
"/System/Library/Fonts/Supplemental/Songti.ttc",
# Linux / common PIL fallback
"/usr/share/fonts/truetype/wqy/wqy-microhei.ttc",
"/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc",
"/usr/share/fonts/truetype/dejavu/DejaVuSans.ttf",
"DejaVuSans.ttf",
)
# ------------------- 工具函数 -------------------
def parse_cos_url(url):
try:
bucket = url.split("https://")[-1].split(".cos.")[0]
key = url.split(".cos.")[1].split("/", 1)[1]
return bucket, key
except:
return None, None
def download_img(url):
if not url:
return None
url = str(url).strip()
if not url:
return None
# WPS/Excel 图片占位公式:=DISPIMG("ID_xxx",1)
# 这种不是可直接下载的 URL,这里直接返回 None(上层会跳过并保留原值/清空逻辑)
if url.startswith("=DISPIMG(") or "DISPIMG(" in url:
return None
# 优先用 COS SDK(如果配置了密钥)
if "cos.ap-guangzhou.myqcloud.com" in url and cos_client:
bucket, key = parse_cos_url(url)
if not bucket or not key:
return None
try:
resp = cos_client.get_object(Bucket=bucket, Key=key)
data = b"".join(chunk for chunk in resp["Body"])
return data if len(data) > 0 else None
except Exception:
return None
# 兜底:直接 HTTP 拉取(适用于公网可读/带签名的URL)
try:
r = requests.get(url, timeout=15)
if r.status_code != 200:
return None
return r.content if r.content else None
except Exception:
return None
def pdf_page_to_image(pdf_path, page_idx=0):
"""读取PDF第一页转图片"""
doc = fitz.open(pdf_path)
page = doc[page_idx]
mat = fitz.Matrix(PDF_RENDER_SCALE, PDF_RENDER_SCALE) # 高清
pix = page.get_pixmap(matrix=mat)
img = PILImage.open(BytesIO(pix.tobytes("png"))).convert("RGB")
doc.close()
return img
def _get_font(size: int) -> ImageFont.ImageFont:
# Windows 下如果回退到 PIL 默认位图字体,字号会明显偏小。
# 因此优先使用系统可缩放字体;必要时可用 AGREEMENT_FONT_PATH 显式指定。
for p in FONT_CANDIDATES:
if not p:
continue
try:
return ImageFont.truetype(p, size=size)
except Exception:
continue
logging.warning("No scalable font found; falling back to PIL default font. Set AGREEMENT_FONT_PATH if text is too small.")
return ImageFont.load_default()
def _pdf_scaled_pos(pos: tuple[int, int]) -> tuple[int, int]:
factor = PDF_RENDER_SCALE / PDF_COORD_BASE_SCALE
return int(round(pos[0] * factor)), int(round(pos[1] * factor))
def _pdf_scaled_size(size: int) -> int:
return max(1, int(round(size * PDF_RENDER_SCALE / PDF_COORD_BASE_SCALE)))
def _format_cell_value(v) -> str:
if v is None or (isinstance(v, float) and pd.isna(v)):
return ""
# pandas NA / string NA
try:
if v is pd.NA or pd.isna(v):
return ""
except Exception:
pass
try:
import datetime as _dt
if isinstance(v, (pd.Timestamp, _dt.datetime, _dt.date)):
return v.strftime("%Y-%m-%d")
except Exception:
pass
return str(v).strip()
def _to_excel_cell_value(v):
"""openpyxl 不支持 pandas.NA,统一转成 None 或普通类型"""
try:
if v is pd.NA or pd.isna(v):
return None
except Exception:
pass
return v
def _save_image_for_excel(im: PILImage.Image, *, fmt: str = "PNG", quality: int = 90) -> BytesIO:
out = BytesIO()
save_kwargs = {"optimize": True}
if fmt.upper() in {"JPEG", "JPG"}:
im = im.convert("RGB")
save_kwargs["quality"] = quality
im.save(out, fmt, **save_kwargs)
out.seek(0)
return out
def _normalize_id_image(im: PILImage.Image, source_url: str) -> PILImage.Image:
im = ImageOps.exif_transpose(im).convert("RGB")
if im.height > im.width:
im = im.rotate(ID_ROTATE_DEG, expand=True)
for key, deg in ID_ROTATE_OVERRIDES.items():
if key in source_url:
im = im.rotate(deg, expand=True)
break
return im
def _add_sized_image(ws, img_data: BytesIO, row_idx: int, col_idx: int, size: tuple[int, int]):
img = Image(img_data)
img.width, img.height = size
ws.add_image(img, ws.cell(row_idx, col_idx).coordinate)
ws.cell(row_idx, col_idx, value="")
def _apply_reference_layout(ws, headers: list[str]):
for letter, width in REFERENCE_COLUMN_WIDTHS.items():
ws.column_dimensions[letter].width = width
ws.sheet_view.zoomScale = 100
ws.sheet_view.zoomScaleNormal = 100
ws.auto_filter.ref = ws.dimensions
for row in ws.iter_rows(min_row=1, max_row=ws.max_row, max_col=len(headers)):
for cell in row:
cell.alignment = Alignment(vertical="center", wrap_text=cell.column_letter == "N")
def merge_pdf_with_sign(pdf_img, sign_img_data, *, phone: str, id_no: str, flight_date: str):
"""把签名贴到协议页横线,并把电话/身份证号/日期写到对应横线上"""
try:
draw = ImageDraw.Draw(pdf_img)
font = _get_font(_pdf_scaled_size(AGREEMENT_TEXT_SIZE))
if id_no:
draw.text(_pdf_scaled_pos(AGREEMENT_IDNO_POS), id_no, fill=AGREEMENT_TEXT_COLOR, font=font)
if phone:
draw.text(_pdf_scaled_pos(AGREEMENT_PHONE_POS), phone, fill=AGREEMENT_TEXT_COLOR, font=font)
if flight_date:
# 期望格式:YYYY-MM-DD / YYYY/MM/DD / YYYY.MM.DD
m = re.match(r"^\s*(\d{4})\D+(\d{1,2})\D+(\d{1,2})\s*$", str(flight_date))
if m:
y = m.group(1)
mo = str(int(m.group(2))).zfill(2)
d = str(int(m.group(3))).zfill(2)
else:
# fallback: 尽量保底把整串写到"年"位置
y, mo, d = str(flight_date).strip(), "", ""
draw.text(_pdf_scaled_pos(AGREEMENT_DATE_Y_POS), y, fill=AGREEMENT_TEXT_COLOR, font=font)
if mo:
draw.text(_pdf_scaled_pos(AGREEMENT_DATE_M_POS), mo, fill=AGREEMENT_TEXT_COLOR, font=font)
if d:
draw.text(_pdf_scaled_pos(AGREEMENT_DATE_D_POS), d, fill=AGREEMENT_TEXT_COLOR, font=font)
if sign_img_data:
sign_img = PILImage.open(BytesIO(sign_img_data)).convert("RGBA")
sign_img.thumbnail((_pdf_scaled_size(SIGN_WIDTH), _pdf_scaled_size(SIGN_HEIGHT)))
# ===================== 签名定位到签字横线 =====================
pdf_img.paste(sign_img, _pdf_scaled_pos(AGREEMENT_SIGN_POS), mask=sign_img)
out = BytesIO()
pdf_img.save(out, format="PNG", optimize=True)
out.seek(0)
return out
except Exception as e:
logging.exception("merge_pdf_with_sign failed: %s", e)
return None
# ------------------- 生成Excel -------------------
def generate():
df = pd.read_excel(CSV_FILE, dtype={COL_PHONE: "string", COL_ID_NO: "string"})
pdf_img = pdf_page_to_image(PDF_FILE) # 预加载PDF
wb = Workbook()
ws = wb.active
ws.title = "乘机数据"
# 参考表只有「乘机告知书」一列承载协议页,不再保留单独的签名图片列。
headers = [h for h in df.columns.tolist() if h != COL_SIGN]
# 写表头
for c, h in enumerate(headers, 1):
ws.cell(row=1, column=c, value=h)
success = 0
for row_idx, (_, row) in enumerate(df.iterrows(), 2):
# 写入所有数据
for c, h in enumerate(headers, 1):
ws.cell(row=row_idx, column=c, value=_to_excel_cell_value(row[h]))
max_h = 0
# ========== 1. 身份证照片 ==========
c_id = headers.index(COL_ID) + 1
url_id = str(row.get(COL_ID, "")).strip()
data_id = download_img(url_id)
if data_id:
with PILImage.open(BytesIO(data_id)) as im:
im = _normalize_id_image(im, url_id)
# 只缩小 Excel 里的显示尺寸,不缩小源图像像素,保证放大查看仍清晰。
out = _save_image_for_excel(im, fmt="PNG")
_add_sized_image(ws, out, row_idx, c_id, ID_DISPLAY_SIZE)
max_h = max(max_h, REFERENCE_ROW_HEIGHT)
# ========== 2. 乘机协议第一页插入到「乘机告知书」列(有签名才生成) ==========
c_notice = headers.index(COL_NOTICE) + 1
url_sign = str(row.get(COL_SIGN, "")).strip()
data_sign = download_img(url_sign)
phone = _format_cell_value(row.get(COL_PHONE, ""))
id_no = _format_cell_value(row.get(COL_ID_NO, ""))
flight_date = _format_cell_value(row.get(COL_FLIGHT_DATE, ""))
# 有签名才生成协议页,否则不生成(但身份证照片仍然会处理)
if data_sign:
merged_img = merge_pdf_with_sign(
pdf_img.copy(),
data_sign,
phone=phone,
id_no=id_no,
flight_date=flight_date,
)
else:
merged_img = None
if merged_img:
_add_sized_image(ws, merged_img, row_idx, c_notice, AGREEMENT_DISPLAY_SIZE)
max_h = max(max_h, REFERENCE_ROW_HEIGHT)
# 行高
if max_h > 0:
ws.row_dimensions[row_idx].height = REFERENCE_ROW_HEIGHT
success += 1
_apply_reference_layout(ws, headers)
wb.save(SAVE_EXCEL)
print(f"✅ 完成!成功处理 {success} 行,文件:{os.path.abspath(SAVE_EXCEL)}")
if __name__ == "__main__":
generate()没有链接的导入本地的图片与pdf进行填充**:image_excel_old.py代码**
tips:身份证文件夹与纸质乘机协议中的命名与excel里的姓名保持一致
import pandas as pd
from openpyxl import Workbook
from openpyxl.drawing.image import Image
from openpyxl.styles import Alignment
from io import BytesIO
import os
import logging
from PIL import Image as PILImage
from PIL import ImageDraw, ImageFont
from PIL import ImageOps
import fitz # PyMuPDF 用于读取PDF
import requests
import re
import glob
try:
from qcloud_cos import CosConfig, CosS3Client # provided by cos-python-sdk-v5
except Exception:
CosConfig = None
CosS3Client = None
# ------------------- 配置 -------------------
logging.basicConfig(level=logging.INFO)
# 优先从环境变量读取(推荐),否则回退到历史默认值以保证脚本可直接运行。
# TENCENT_COS_SECRETID(腾讯COS访问ID)
secret_id = os.getenv("COS_SECRET_ID", "").strip() or "AKIDRp8b6cvKbmq3GKGJQSGpJkL4"
# TENCENT_COS_SECRETKEY(腾讯COS访问密钥)
secret_key = os.getenv("COS_SECRET_KEY", "").strip() or "Z1PKApSwHTn5FJSkDWmoeXH6vx"
region = "ap-guangzhou"
cos_client = None
if CosConfig and CosS3Client and secret_id and secret_key:
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key, Token=None, Scheme="https")
cos_client = CosS3Client(config)
CSV_FILE = "2026五一光明数据.xlsx"
PDF_FILE = "乘机协议.pdf"
SAVE_EXCEL = "2026五一光明数据(最终版).xlsx"
# 本地文件夹
ID_CARD_DIR = "身份证"
PAPER_AGREEMENT_DIR = "纸质乘机协议"
ID_EXTS = ["*.jpg", "*.jpeg", "*.png", "*.bmp"]
PDF_EXT = "*.pdf"
COL_ID = "身份证照片"
COL_NOTICE = "乘机告知书"
COL_SIGN = "乘机告知书签名"
COL_PHONE = "电话"
COL_ID_NO = "身份证号码"
COL_FLIGHT_DATE = "实际起飞日期"
COL_NAME = "姓名"
PDF_RENDER_SCALE = 4.0
PDF_COORD_BASE_SCALE = 1.6
ID_ROTATE_DEG = -90
ID_ROTATE_OVERRIDES = {"cac3a07115eceb1a183342f4ff64f98e": 90}
SIGN_WIDTH = 180
SIGN_HEIGHT = 60
REFERENCE_ROW_HEIGHT = 260
ID_DISPLAY_SIZE = (405, 290)
AGREEMENT_DISPLAY_SIZE = (268, 290)
REFERENCE_COLUMN_WIDTHS = {
"A": 13.0, "B": 13.0, "C": 16.627, "D": 27.873, "E": 18.255, "F": 14.455,
"G": 9.0, "H": 9.0, "I": 9.0, "J": 9.0, "K": 9.0, "L": 9.0, "M": 9.0,
"N": 38.255, "O": 9.0, "P": 9.0, "Q": 9.0, "R": 58.591, "S": 39.064,
}
AGREEMENT_SIGN_POS = (210, 895)
AGREEMENT_IDNO_POS = (563, 930)
AGREEMENT_PHONE_POS = (240, 996)
AGREEMENT_DATE_Y_POS = (492, 996)
AGREEMENT_DATE_M_POS = (590, 996)
AGREEMENT_DATE_D_POS = (675, 996)
AGREEMENT_TEXT_COLOR = (0, 0, 0)
AGREEMENT_TEXT_SIZE = 20
AGREEMENT_FONT_PATH = os.getenv("AGREEMENT_FONT_PATH", "").strip()
FONT_CANDIDATES = (
AGREEMENT_FONT_PATH,
os.path.join(os.environ.get("WINDIR", r"C:\Windows"), "Fonts", "msyh.ttc"),
"/System/Library/Fonts/PingFang.ttc",
"/usr/share/fonts/truetype/wqy/wqy-microhei.ttc",
"DejaVuSans.ttf",
)
# 本地文件缓存
id_file_map = {}
pdf_file_map = {}
# ------------------- 工具函数 -------------------
def parse_cos_url(url):
try:
bucket = url.split("https://")[-1].split(".cos.")[0]
key = url.split(".cos.")[1].split("/", 1)[1]
return bucket, key
except:
return None, None
def download_img(url):
if not url or str(url).strip() == "" or "=DISPIMG(" in str(url):
return None
url = str(url).strip()
if "cos.ap-guangzhou.myqcloud.com" in url and cos_client:
bucket, key = parse_cos_url(url)
if bucket and key:
try:
resp = cos_client.get_object(Bucket=bucket, Key=key)
return b"".join(chunk for chunk in resp["Body"])
except:
pass
try:
r = requests.get(url, timeout=15)
return r.content if r.status_code == 200 and r.content else None
except:
return None
def pdf_page_to_image(pdf_path, page_idx=0):
try:
doc = fitz.open(pdf_path)
page = doc[page_idx]
mat = fitz.Matrix(PDF_RENDER_SCALE, PDF_RENDER_SCALE)
pix = page.get_pixmap(matrix=mat)
img = PILImage.open(BytesIO(pix.tobytes("png"))).convert("RGB")
doc.close()
return img
except:
return None
def _get_font(size: int) -> ImageFont.ImageFont:
for p in FONT_CANDIDATES:
if p:
try:
return ImageFont.truetype(p, size=size)
except:
continue
logging.warning("使用默认字体,可能显示异常")
return ImageFont.load_default()
def _pdf_scaled_pos(pos: tuple[int, int]) -> tuple[int, int]:
f = PDF_RENDER_SCALE / PDF_COORD_BASE_SCALE
return int(round(pos[0] * f)), int(round(pos[1] * f))
def _pdf_scaled_size(size: int) -> int:
return max(1, int(round(size * PDF_RENDER_SCALE / PDF_COORD_BASE_SCALE)))
def _format_cell_value(v) -> str:
if pd.isna(v) or v is None:
return ""
try:
if isinstance(v, (pd.Timestamp, object)):
return str(v).strip()
except:
pass
return str(v).strip()
def _to_excel_cell_value(v):
return None if pd.isna(v) else v
def _save_image_for_excel(im: PILImage.Image, fmt="PNG") -> BytesIO:
out = BytesIO()
if fmt == "JPEG":
im = im.convert("RGB")
im.save(out, fmt, optimize=True)
out.seek(0)
return out
def _normalize_id_image(im: PILImage.Image, source_url="") -> PILImage.Image:
im = ImageOps.exif_transpose(im).convert("RGB")
if im.height > im.width:
im = im.rotate(ID_ROTATE_DEG, expand=True)
for k, d in ID_ROTATE_OVERRIDES.items():
if k in str(source_url):
im = im.rotate(d, expand=True)
return im
def _add_sized_image(ws, img_data: BytesIO, row_idx: int, col_idx: int, size: tuple[int, int]):
if not img_data:
return
try:
img = Image(img_data)
img.width, img.height = size
ws.add_image(img, ws.cell(row_idx, col_idx).coordinate)
ws.cell(row_idx, col_idx, value="")
except Exception as e:
logging.warning(f"插入图片失败: {e}")
def _apply_reference_layout(ws, headers):
for k, w in REFERENCE_COLUMN_WIDTHS.items():
ws.column_dimensions[k].width = w
for row in ws.iter_rows(min_row=1, max_row=ws.max_row, max_col=len(headers)):
for cell in row:
cell.alignment = Alignment(vertical="center", wrap_text=(cell.column_letter == "N"))
def merge_pdf_with_sign(pdf_img, sign_img_data, phone, id_no, flight_date):
try:
img = pdf_img.copy()
draw = ImageDraw.Draw(img)
font = _get_font(_pdf_scaled_size(AGREEMENT_TEXT_SIZE))
if id_no:
draw.text(_pdf_scaled_pos(AGREEMENT_IDNO_POS), id_no, fill=AGREEMENT_TEXT_COLOR, font=font)
if phone:
draw.text(_pdf_scaled_pos(AGREEMENT_PHONE_POS), phone, fill=AGREEMENT_TEXT_COLOR, font=font)
# ========== 修复:日期解析加强,确保有签名就一定写入年月日 ==========
if flight_date:
date_str = str(flight_date).strip()
# 匹配所有常见日期格式:2025-05-01 | 2025/05/01 | 2025.05.01 | 2025年5月1日
match = re.search(r'(\d{4})\D*(\d{1,2})\D*(\d{1,2})', date_str)
if match:
y = match.group(1)
m = str(int(match.group(2))).zfill(2)
d = str(int(match.group(3))).zfill(2)
draw.text(_pdf_scaled_pos(AGREEMENT_DATE_Y_POS), y, font=font, fill=AGREEMENT_TEXT_COLOR)
draw.text(_pdf_scaled_pos(AGREEMENT_DATE_M_POS), m, font=font, fill=AGREEMENT_TEXT_COLOR)
draw.text(_pdf_scaled_pos(AGREEMENT_DATE_D_POS), d, font=font, fill=AGREEMENT_TEXT_COLOR)
if sign_img_data:
sign = PILImage.open(BytesIO(sign_img_data)).convert("RGBA")
sign.thumbnail((_pdf_scaled_size(SIGN_WIDTH), _pdf_scaled_size(SIGN_HEIGHT)))
img.paste(sign, _pdf_scaled_pos(AGREEMENT_SIGN_POS), mask=sign)
return _save_image_for_excel(img)
except Exception as e:
logging.warning(f"协议合成失败:{e}")
return None
# ------------------- 本地文件加载函数(优化版) -------------------
def init_local_files():
global id_file_map, pdf_file_map
id_file_map.clear()
pdf_file_map.clear()
# 加载身份证图片
if os.path.exists(ID_CARD_DIR):
for ext in ID_EXTS:
paths = glob.glob(os.path.join(ID_CARD_DIR, ext)) + glob.glob(os.path.join(ID_CARD_DIR, ext.upper()))
for p in paths:
name = os.path.splitext(os.path.basename(p))[0].strip()
id_file_map[name] = p
# 加载纸质协议PDF
if os.path.exists(PAPER_AGREEMENT_DIR):
paths = glob.glob(os.path.join(PAPER_AGREEMENT_DIR, PDF_EXT)) + glob.glob(os.path.join(PAPER_AGREEMENT_DIR, PDF_EXT.upper()))
for p in paths:
name = os.path.splitext(os.path.basename(p))[0].strip()
pdf_file_map[name] = p
logging.info(f"本地身份证:{len(id_file_map)} 张")
logging.info(f"本地纸质协议:{len(pdf_file_map)} 份")
def get_local_id_image_bytes(name):
if not name:
return None
path = id_file_map.get(name.strip())
if not path or not os.path.exists(path):
return None
try:
with open(path, "rb") as f:
return f.read()
except:
return None
def get_local_pdf_image_bytes(name):
if not name:
return None
path = pdf_file_map.get(name.strip())
if not path or not os.path.exists(path):
return None
img = pdf_page_to_image(path)
if not img:
return None
return _save_image_for_excel(img)
# ------------------- 主生成逻辑 -------------------
def generate():
init_local_files()
df = pd.read_excel(CSV_FILE, dtype={COL_PHONE: "string", COL_ID_NO: "string"})
pdf_template = pdf_page_to_image(PDF_FILE) if os.path.exists(PDF_FILE) else None
wb = Workbook()
ws = wb.active
ws.title = "乘机数据"
headers = [h for h in df.columns if h != COL_SIGN]
# 写入表头
for c, h in enumerate(headers, 1):
ws.cell(row=1, column=c, value=h)
success = 0
for row_idx, (_, row) in enumerate(df.iterrows(), start=2):
# 写入数据
for c, h in enumerate(headers, 1):
ws.cell(row=row_idx, column=c, value=_to_excel_cell_value(row[h]))
max_h = 0
name = _format_cell_value(row.get(COL_NAME))
# ========== 1. 身份证:URL优先 → 本地图片兜底 ==========
c_id = headers.index(COL_ID) + 1
id_url = row.get(COL_ID, "")
id_bytes = download_img(id_url) or get_local_id_image_bytes(name)
if id_bytes:
with PILImage.open(BytesIO(id_bytes)) as im:
im_norm = _normalize_id_image(im, str(id_url))
img_out = _save_image_for_excel(im_norm)
_add_sized_image(ws, img_out, row_idx, c_id, ID_DISPLAY_SIZE)
max_h = REFERENCE_ROW_HEIGHT
# ========== 2. 乘机告知书:电子签名 → 本地PDF ==========
c_notice = headers.index(COL_NOTICE) + 1
sign_bytes = download_img(row.get(COL_SIGN, ""))
final_img = None
# 有签名 + 有PDF模板 → 合成带签名、带信息的协议
if sign_bytes and pdf_template:
final_img = merge_pdf_with_sign(
pdf_template, sign_bytes,
_format_cell_value(row.get(COL_PHONE)),
_format_cell_value(row.get(COL_ID_NO)),
_format_cell_value(row.get(COL_FLIGHT_DATE))
)
# 无电子签名 → 用本地纸质PDF
if not final_img and name:
final_img = get_local_pdf_image_bytes(name)
if final_img:
_add_sized_image(ws, final_img, row_idx, c_notice, AGREEMENT_DISPLAY_SIZE)
max_h = REFERENCE_ROW_HEIGHT
if max_h > 0:
ws.row_dimensions[row_idx].height = max_h
success += 1
_apply_reference_layout(ws, headers)
wb.save(SAVE_EXCEL)
print(f"\n✅ 生成完成!成功处理 {success} 行")
print(f"📁 文件路径:{os.path.abspath(SAVE_EXCEL)}")
if __name__ == "__main__":
generate()