第八章:选择性关注------注意力机制的诞生
!info
上一章,我们看到了 Seq2Seq 架构的辉煌与困境。它用两个 LSTM 串联,让机器第一次能够端到端地学习翻译------不需要任何语言学规则,只需要喂给它足够多的平行语料,它就能自己摸索出翻译的方法。Sutskever 等人在 WMT'14 英法翻译任务上超越了精心调优十余年的统计机器翻译系统,这个消息震动了整个 NLP 社区。
然而,在这场胜利的背后,一个结构性的缺陷正在悄悄放大。Seq2Seq 要求编码器把整个输入句子压缩成一个固定大小的向量------这个向量,是编码器和解码器之间唯一的信息通道。句子短的时候问题不大;但当句子变长,这个通道就开始拥堵,翻译质量随句子长度急剧下滑。
本章的起点,就是这个信息瓶颈。而打破它的,是一个看似朴素却影响深远的想法:与其把所有信息压进一个向量,不如让解码器在需要时自己去查找。
!question
Seq2Seq 的信息瓶颈是一个结构性问题,它能在不抛弃 RNN 的前提下被修复吗?注意力机制是怎么做到这一点的?
8.1、蒙特利尔,2014 年的夏天
8.1.1 三个人,一间实验室,一个日渐清晰的裂缝
2014 年的夏天,加拿大蒙特利尔,蒙特利尔大学(Université de Montréal)。
这座城市的夏天短促而炎热,但在大学主楼里的 LISA(Laboratoire d'Informatique des Systèmes Adaptatifs,自适应系统计算机科学实验室)里,研究者们几乎感觉不到季节。实验室由约书亚·本吉奥领导,是当时全球最活跃的深度学习研究中心之一。那一年,深度学习刚刚走出 AlexNet 之后的兴奋期,开始认真面对一个新的战场:语言。
实验室里有一名来自德国的访问学生,叫德米特里·巴赫达瑙(Dzmitry Bahdanau),来自雅各布斯大学不来梅(Jacobs University Bremen)。他最初加入本吉奥研究组时,并没有机器翻译的背景------他研究的是回声状态网络(Echo State Network),一种不太主流的循环神经网络变体。但他有一种工程师式的直觉:如果一个系统的某个地方让你感到别扭,那个别扭的地方很可能就是问题所在。
和他一起工作的,是赵京铉(Kyunghyun Cho,1985-,GRU 提出者之一,后任纽约大学教授)。赵京铉当时刚刚完成一件重要的事:在本吉奥的指导下,他提出了我们上一章讲到的编码器-解码器(Encoder-Decoder)架构,并在这个框架下引入了 GRU(门控循环单元)。2014 年 6 月,他们的论文刚刚提交,整个实验室都处于一种紧张的等待与评估之中------这个架构能真正解决机器翻译的问题吗?
巴赫达瑙开始在这个框架上做实验。他很快就注意到了一件让他困扰的事。
8.1.2 令人不安的曲线
在实验室的显示器前,巴赫达瑙盯着一张折线图,已经看了将近半个小时。
图上有两条曲线:横轴是测试句子的长度,纵轴是翻译质量的 BLEU 分数。在句子较短的区域,曲线平稳;但当句子超过二十个词,一条曲线开始下滑,越来越陡------像一个人走路越来越快,突然脚步踉跄,开始摔跤。
他调整了模型的参数,重新训练,曲线还是那样。他换了不同的初始化方式,还是那样。他加大了数据量,稍微好了一点,但那个拐点依然清晰地存在:长句子,翻译质量就是会崩溃。
问题不难定位------他知道。源头在于这个架构的一个核心设计:编码器把整个输入句子"压缩"进最后一步的隐状态,然后这一个向量,作为解码器的全部信息来源。当句子变长了,这个向量根本装不下所有的内容。
但他当时还不知道,如何解决这个问题。他甚至不确定这是否是一个"可以"被解决的问题------也许这就是这类架构的天花板?
让我们用一个具体例子来感受这个"装不下"究竟有多真实。
8.1.3 翻译一首诗的困境
想象你要翻译这样一个法语句子:
"L'accord sur la zone économique européenne a été signé en août 1992."
("关于欧洲经济区的协议于 1992 年 8 月签署。")
这是一个 13 个词的句子,不算太长。对于 Seq2Seq 来说,编码器要把这 13 个词的所有信息------主语"L'accord"(协议)、介词短语"sur la zone économique européenne"(关于欧洲经济区)、谓语"a été signé"(已被签署)、时间状语"en août 1992"(在 1992 年 8 月)------全部压进最终的隐状态向量里。这个向量,是编码器交给解码器的全部遗产。
然后解码器从这个向量出发,一词一词地生成英文。当它从最开始生成 "The" 时,手里只有这个压缩向量;生成"agreement"时,还是这个向量;生成"on"、"the"、"European"、"Economic"、"Area"、"was"、"signed"、"in"、"August"、"1992"......每一步,它都要从同一个固定的向量里提取当下需要的信息。
对 13 个词的句子来说,这勉强够用。但现在把句子变长。2014 年的机器翻译任务里,有大量这样的句子------来自新闻、法律文书、技术文档。一个常见的欧盟议会发言,可能长达 40、50 个词,甚至更长:
"The Commission considers that the proposed directive on data retention, if adopted in its current form, would not only fail to achieve its stated objectives but would also impose disproportionate and unjustified burdens on telecommunications service providers and on citizens' fundamental rights to privacy."(欧盟委员会认为,目前形式的数据留存指令提案若获通过,不仅无法实现其既定目标,还将对电信服务提供商及公民隐私基本权利施加不成比例且不合理的负担。)
这是 52 个词。编码器要把"欧盟委员会的立场"、"拟议指令的主题"、"失败的理由"、"电信服务商的负担"、"基本人权"......全部压进同一个固定大小的向量。
更麻烦的是:编码器在处理这个句子时,并不知道解码器之后具体会翻译哪个词。当解码器需要翻译 "telecommunications service providers"(电信服务商)的时候,它需要访问的信息,在原句的第 42 到 49 个词的位置------而这些信息,在被压进那个固定向量的过程中,已经被淡化、稀释,混杂在其他所有内容里,模糊不清了。
用一个贴近生活的类比来说:这就好像你要参加一场口译工作,但规则是你只能在听完全部原文之后,把它整理成一张名片大小的纸条,然后仅凭这张纸条进行翻译。名片是固定大小的,无论原文是 5 句话还是 50 句话。你在听的过程中,只能不断地做取舍、压缩、合并------最后那张名片上,有很多东西已经面目全非了。
8.1.4 一个在当时显得"越界"的问题
巴赫达瑙是一个直接的人。他不太在意研究圈子里的"常规做法",也不太在乎自己是一个没有多少 NLP 背景的访问学生。当他意识到信息瓶颈是一个架构层面的问题后,他自然地问了一个问题:
为什么解码器只能依赖最终的那一个压缩向量?为什么不能让它在翻译每个词的时候,都回头去看看编码器在处理每个源词时留下的中间状态?
这个问题,从今天的角度看,几乎像是废话------当然应该这么做。但在 2014 年,它之所以没有被更早提出,有一个重要的原因:当时的整个研究范式,都是围绕"压缩"这个思路构建的。
Seq2Seq 的设计哲学是:让神经网络自己学会如何把一个句子的"意思"浓缩成一个向量表示。这个思路有很强的理论吸引力------如果网络够聪明,它应该能学会抓住最重要的东西。Sutskever 等人的结果也证明,在短句上,这个压缩确实有效。
问题在于,在"压缩"这个框架里,信息的损失是不可见的------你只能看到最终的翻译输出,却看不见哪些信息在压缩过程中消失了。巴赫达瑙的洞察,是把问题从"如何压缩"转向了"如何不压缩"------不是让网络学会更好地压缩,而是从根本上改变信息的流动方式。
巴赫达瑙把这个想法告诉了赵京铉和本吉奥。本吉奥的反应是典型的导师式的谨慎:想法有意思,但需要验证------理论上说得通,不代表实践中有效。赵京铉则更直接,他很快就看到了这个思路的可行性。三个人开始合作,在接下来的几个月里,把这个想法从一个直觉,变成了一个完整的机制。
这三人的组合,本身就很有意思。本吉奥是资深的深度学习奠基人,他在 NLP 和表示学习上有深厚的理论积累,能为这个想法提供数学框架上的支撑;赵京铉是机器翻译方向上的新锐,对 Seq2Seq 的设计细节了如指掌;而巴赫达瑙,这个没有太多 NLP 背景的访问学生,带来的是工程师式的直觉和对"这个地方就是不对劲"的执着。
有时候,一个领域最重要的突破,恰恰来自一个不被既有范式束缚的人。他不知道"应该怎么做",所以他问了一个在行内人看来"有点奇怪"的问题------然后发现这个问题的答案,改变了整个领域。
2014 年 9 月 1 日,三人在 arXiv 发布了论文的预印本。这比 Sutskever 等人的 Seq2Seq 论文的 arXiv 版本(2014 年 9 月 10 日)还早了九天------两篇定义这个时代的论文,几乎在同一周出现在世界面前。
8.2、信息瓶颈:一个无法靠"修补"解决的问题
8.2.1 固定大小向量的物理限制
在理解巴赫达瑙的解决方案之前,我们需要更深入地理解这个问题------为什么它是结构性的,而不是可以通过调参或者换更大模型来解决的?
Seq2Seq 的编码器在处理输入序列时,会在每个时间步 ttt 生成一个隐状态 hth_tht。当它处理完最后一个词之后,最终的隐状态 hTh_ThT 成为"上下文向量"(context vector),传递给解码器。
这里有一个根本性的矛盾:
- 输入的信息量随句子长度线性增长:100 个词的句子,理论上包含的信息远多于 10 个词的句子
- 上下文向量的容量是固定的:无论是 256 维、512 维还是 1024 维,这个向量的大小在模型设计时就已确定,不随输入长度变化
这不是"把向量维度调大就能解决"的问题。把向量从 512 维调到 2048 维,确实能存储更多信息,但问题的本质没有变------它依然是一个固定容量的容器,面对可以无限增长的输入。更大的向量能支撑更长的句子,但总有一个长度会让它再次崩溃。
更深层的矛盾,来自 LSTM 的工作机制。LSTM 通过门控机制决定"记住什么、忘掉什么"。遗忘门会在每个时间步主动清除部分信息,输入门决定新信息写入多少。这些决策,发生在编码阶段------也就是说,LSTM 在决定"要不要保留这条信息"的时候,它根本不知道解码器之后具体会需要什么。
这就引出了一个结构性的困境:编码器做的是通用摘要,解码器需要的是按需查阅。
打个比方:这就像一个律师在开庭前必须把整份案卷背熟,然后把所有内容压缩成一张 A4 纸带进法庭------不允许翻原件。这张纸的大小是固定的。无论案件涉及三份证据还是三百份证据,他都只有那一张 A4 纸。他当然会努力把最重要的内容写上去,但什么是"最重要的"?庭审开始前,他并不知道对方律师会聚焦在哪个细节上。他只能猜测,做一个"通用摘要"。而当对方突然追问某个他认为次要的细节时,那张纸上就什么都没有了。
8.2.2 "遗忘"不是坏事,是设计缺陷在这里暴露
LSTM 的遗忘门,在第六章里是一个被赞美的设计:它让网络能够主动管理自己的记忆,只保留相关的信息。但在 Seq2Seq 的场景里,这个"主动遗忘"变成了一个隐患。
考虑这样一个句子:
"虽然委员会承认这一政策在短期内会带来一定的经济代价,但它认为从长远来看,这些代价是值得的。"
当编码器处理完"代价"的时候,离句子开头的"虽然委员会承认"已经过去了十多个时间步。在这十多步里,LSTM 的遗忘门已经进行了十多次"是否保留"的决策。句子开头的信息,经过层层过滤,往往已经变得非常微弱。
而这个句子的翻译,恰恰需要维持"虽然......但"这个转折结构。如果"虽然"的信息在生成"但"对应的英文翻译时已经淡出,翻译就会出错------模型可能会错误地把整个句子当成一个肯定判断,而非一个让步+肯定的复合结构。
这不是 LSTM 不够好。这是 LSTM + 固定上下文向量的组合,在面对结构复杂的长句时,必然会遇到的天花板。
8.2.3 失败的翻译长什么样?
理解信息瓶颈最直接的方式,是看一看它造成的真实错误。
在 Bahdanau 等人的实验中,他们测试了带注意力和不带注意力的模型在相同长句上的翻译输出。不带注意力的模型(RNNenc-dec)在长句上的典型错误有这几种类型:
词义混淆:源句子开头的关键名词,在句子中段之后开始变得模糊。模型可能会把"欧洲经济区"翻译成一个语义相近但不精确的短语,因为这个短语在编码过程中已经被稀释进了上下文向量。
成分缺失:一个复合句里的某个从句,在翻译输出中消失了。模型"记得"主句,却忘了某个关键的时间状语或条件子句。
词序错误:尤其在英法、英德这类词序有所不同的语言对上,长句的后半部分词序往往会出现紊乱------因为解码器对源句子的记忆在这个阶段已经严重退化,只能凭目标语言自身的语言模式"猜"词序。
带注意力的模型(RNNsearch)在同样的句子上,这些问题大多消失了。模型在翻译每个目标词时,可以精确地"回头"定位源句子中的对应位置,就像翻译员翻着原稿一样。
这种对比,是对注意力机制价值最有力的说明------不是 BLEU 分数上的零点几,而是翻译结果从"读得出来但明显有错",变成了"接近正常人类翻译"。
8.2.4 为什么没有早点发现这个问题?
这里有一个很自然的问题:Seq2Seq 发表于 2014 年 9 月,而 Bahdanau 等人的注意力论文几乎同时(也是 2014 年 9 月)提交到 arXiv。这意味着,在 Seq2Seq 正式发表之前,注意力机制就已经在开发中了。
这不是说 Sutskever 等人"不知道"信息瓶颈的问题。他们在论文里提到了这个限制。但他们当时有一个合理的假设:对于大多数翻译句子(平均长度 20-30 词),当前的 LSTM 容量足够;而且,更深的 LSTM、更大的隐状态维度,可以缓解这个问题。
这是科学研究中很常见的一种思维模式:先证明方法论的可行性,再优化细节。Seq2Seq 的贡献,是证明了"端到端神经机器翻译"这条路是可行的。信息瓶颈,是下一步要解决的问题。
巴赫达瑙的贡献,是没有接受"缓解"这个答案,而是问了"能不能彻底解决"。而他能提出这个问题,部分原因也在于他是一个"局外人":他没有深陷 RNN 研究的范式惯性里,没有对"编码成向量"这个设计有情感上的执着。他只是看着那条不断下滑的翻译质量曲线,觉得这件事不对劲,然后问了一个最朴素的问题。
8.3、关键洞察:按需提取,而非压缩储存
8.3.1 人类翻译员从不依赖记忆
让我们从一个简单的观察出发。
一个职业口译员在工作时,脑子里发生的事情大概是这样的:当她听到对方说"The Commission considers...",她的注意力立刻锁定在"Commission"------这是主语,整句话的主体,接下来的一切都围绕它展开。当她开始说出"委员会认为"的时候,她并不是在从脑海中调取一个"整句话的压缩摘要",而是在实时地处理------听到什么,就翻译什么,同时把已经听到的内容保持在短期意识中。
换成书面翻译的场景:一个笔译员翻译一篇长文时,她的桌上摆着原文。翻译第三段的时候,她随时可以翻回第一段看看某个术语的原文;翻译某个代词的时候,她往前扫几行,确认指代的主语。她不需要把原文全部记住,因为原文就在那里,随时可以查阅。
这是一个极其自然的工作方式,以至于我们从不去想它。但它隐含了一个重要的操作原则:信息应该在被需要的时候被提取,而不是在处理开始之前被全部压缩成摘要。
换一个更贴近职场的类比:想象你正在做一个需要频繁查阅数据的分析报告。你不会在开始写报告之前,先把所有数据记在脑子里,然后凭记忆写完整篇。你会打开电脑,写一段,然后打开数据文件查一个数字,关上,再写一段,再查。数据文件始终在那里;你按需访问,每次只取你当下需要的那部分。这,正是注意力机制的工作方式。
把这个原则应用到 Seq2Seq 上,答案几乎是自明的:编码器处理每个词时产生的中间隐状态,不应该被丢弃,而应该全部保留下来,让解码器在翻译每个目标词时能够按需查阅最相关的那些。
8.3.2 为什么这个"显然"的想法没有更早出现
但等等------这个想法听起来如此显然,为什么不是从 Seq2Seq 一开始就这样设计?
这里有一个深层的认知惯性在起作用。
深度学习的核心信念之一,是"让网络自己学习表示"。Seq2Seq 的设计者们相信:如果给网络足够的参数和足够的训练数据,它应该能学会如何把一个句子的语义"精华"压缩进一个向量,然后解码器再从这个精华中重建目标语言。这是一个很有哲学吸引力的想法------端到端,无需人工干预,一切由数据驱动。
在这个框架里,固定上下文向量不是一个 bug,而是一个 feature------它是"网络学习到的语义空间"的载体。如果模型表现不够好,直觉上的回应是"让它学得更好",而不是"改变架构"。
巴赫达瑙打破的,正是这个认知框架。他不相信"更好的压缩"能解决问题,因为他看到了数据:无论怎样调整模型,长句翻译的质量终归是有这样的一个顶点,超过了这个长度翻译质量就会下滑。他把这个现象归因于架构本身,而不是训练方式。
这是一种工程师式的思维:不要假设模型"应该能学会"某件事,而是看它实际上学没学会,如果没有,就改掉那个阻碍它学会的结构性障碍。
8.3.3 查阅机制:打破压缩范式
巴赫达瑙的具体想法,是让解码器在每一步解码时,都能"看到"编码器在每个时间步产生的隐状态------不只是最后一个,而是全部。
但"看到全部"不能等于"不加区分地混用全部"。不同的解码步骤需要的信息不同:翻译句子主语的时候,需要关注源句子的主语;翻译时间状语的时候,需要关注时间表达;翻译动词的时候,需要关注谓语部分。
这就引出了一个关键问题:如何让解码器"聪明地"选择每一步应该重点参考哪些编码器状态?
硬性选择(直接选一个最相关的位置)会破坏可微分性,无法端到端训练。平均混合(把所有编码器状态等权重相加)会丢失"不同步骤需要不同信息"这个关键特性。
巴赫达瑙的解决方案是:用一个可学习的评分函数,让网络自己学会为每个编码器位置分配权重,然后对所有位置做加权求和。 这个评分函数,和整个翻译模型一起,从翻译数据中联合学习。
这就是注意力机制(Attention Mechanism)的核心思想。
8.3.4 范式转变:从"存储"到"检索"
如果往更深处看,注意力机制代表的,是信息处理方式的一次根本性转变------而不只是一个技术技巧。
传统的 Seq2Seq 模型,本质上是一种存储-回放的信息处理模式:先把所有信息编码存入一个向量,再从这个向量里解码。这个模式的极限,就是上下文向量的容量上限。
注意力机制引入的,是检索的概念:不是把信息提前压缩存好,而是在需要的时候,带着当前的查询条件,去原始信息库里动态检索最相关的内容。信息库(编码器的所有隐状态)始终完整地保存在那里,每次检索的结果随查询条件而变化。
这个"存储 vs 检索"的对立,在计算机科学里其实有很长的历史。数据库领域早就知道:对于大型、多样化的数据,按需查询(SQL查询)比预先计算好所有摘要要灵活得多。注意力机制,可以看作是把这个计算机科学里的朴素智慧,引入到了神经网络的信息处理流程中。
这个转变的意义,在 2014 年还没有人完全意识到。大家当时只看到了"翻译长句不再崩溃"这个实际好处。但回头看,这个"从存储到检索"的范式转变,是后来 Self-Attention、Transformer、乃至整个大语言模型时代里"用注意力处理一切"这个思路的哲学根基。
8.4、注意力机制的工作原理
8.4.1 三步走:评分、归一化、加权求和
让我们把这个注意力机制拆解成三个具体步骤,其中每一步都有其清晰的物理含义。
第一步:计算注意力分数(Attention Score)
解码器在第 iii 步时,处于某个当前状态 si−1s_{i-1}si−1(前一步的解码器隐状态)。注意力机制为源序列中的每个位置 jjj 计算一个分数 eije_{ij}eij,表示"第 iii 步解码时,应该对源序列第 jjj 个位置给予多大关注"。
巴赫达瑙使用了一个小型神经网络(称为"对齐模型",alignment model)来计算这个分数:
eij=va⊤tanh(Wasi−1+Uahj)e_{ij} = v_a^{\top} \tanh(W_a s_{i-1} + U_a h_j)eij=va⊤tanh(Wasi−1+Uahj)
其中:
- si−1s_{i-1}si−1 是解码器当前的隐状态("我现在在生成什么")
- hjh_jhj 是编码器在位置 jjj 的隐状态("源序列的第 jjj 个位置是什么")
- WaW_aWa、UaU_aUa、vav_ava 是对齐模型的可学习参数------它们和整个翻译模型一起从翻译数据中学习,不是人工设计的
这个公式所做的事情,通俗的解释是,把解码器当前状态和某个编码器状态"各自转换一下再合并",经过一个非线性激活,最后压缩成一个标量分数。这个分数越高,表示这一步翻译越应该"关注"这个特定的编码器位置。
这里有一个值得特别说明的细节:分数的计算同时用到了解码器状态和编码器状态。 这意味着,同样一个编码器位置,对于不同的解码步骤,可能有完全不同的重要性。翻译"委员会"时,编码器里的"Commission"位置得分最高;翻译"认为"时,"considers"位置得分最高。注意力是上下文相关的------这是它最关键的特性。
还有一件更微妙的事值得强调:对齐模型(评分函数 vav_ava、WaW_aWa、UaU_aUa)的参数,没有独立的监督信号 ------没有人告诉它"翻译 'agreement' 时应该注意 'accord'"。它学到这些,完全是因为整个翻译系统在做翻译任务时,发现这样分配注意力能让翻译错误更少。梯度从翻译损失反向传播,穿过解码器,穿过加权求和,一直传到对齐模型的参数------对齐模型就在这个过程中,学到了"哪个源位置对于当前翻译步骤最相关"。
这是一种意义深远的"涌现":对齐知识,从纯粹的翻译误差最小化中自动涌现。没有人标注过哪个英文词应该对应哪个法文词,但网络在学翻译的过程中,自己发现了这种对齐模式。
第二步:Softmax 归一化
对所有位置的分数做 Softmax,得到注意力权重 αij\alpha_{ij}αij:
αij=exp(eij)∑k=1Texp(eik)\alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{k=1}^{T} \exp(e_{ik})}αij=∑k=1Texp(eik)exp(eij)
归一化之后,αij\alpha_{ij}αij 对所有 jjj 求和等于 1,且每个值在 0,10, 10,1 之间。这些权重可以理解为一个概率分布:解码的第 iii 步,把注意力按照这个分布"分配"到源序列的各个位置。
Softmax 这里做了一件微妙的事:它把原始分数压缩成了"相对重要性"。就算某个位置的绝对分数很低,它还是会分到一个大于零的权重。没有任何位置被完全忽略------只是权重有大有小。
第三步:加权求和,得到动态上下文向量
ci=∑j=1Tαijhjc_i = \sum_{j=1}^{T} \alpha_{ij} h_jci=j=1∑Tαijhj
用注意力权重对编码器隐状态做加权求和,得到这一步专属的上下文向量 cic_ici。注意,这个向量随每一步解码而动态变化------翻译不同的词时,它聚焦在源序列的不同位置。这就是它被称为"动态上下文向量"的原因:相比 Seq2Seq 里那个贯穿始终的"固定上下文向量",这个向量是活的。
最后,解码器把这个动态上下文向量 cic_ici、当前的解码器状态 si−1s_{i-1}si−1、以及上一步生成的词三者结合起来,生成当前时间步的输出。
📊 图 7.2:注意力机制的计算流程
图示说明:左侧为编码器(纵向排列的隐状态 h1h_1h1 到 hTh_ThT),右侧为解码器(第 iii 步的状态 si−1s_{i-1}si−1)。从 si−1s_{i-1}si−1 出发,用虚线连接到每个 hjh_jhj,计算分数 eije_{ij}eij,经 Softmax 得权重 αij\alpha_{ij}αij(用连线粗细表示权重大小),最终加权求和得到 cic_ici。cic_ici 与 si−1s_{i-1}si−1 合并后输入解码器生成第 iii 个输出词。
8.4.2 "软"注意力:为什么是加权而不是选择
注意这里的一个设计细节:注意力权重 αij\alpha_{ij}αij 是连续的、可微的实数,而不是 0/1 的离散选择。
"硬"注意力(Hard Attention)会是这样的设计:每一步解码,它会直接选择一个编码器位置,只使用这个特定位置的隐状态------就像真正的"把注意力集中在某一点"。这在直觉上更像人类的"目光聚焦"------每次只看一个地方。
但"软"注意力(Soft Attention)的设计更有工程价值,理由在于可微分性。
深度学习的训练依赖反向传播:误差从输出层往回传,每一步计算梯度,更新参数。这个过程要求所有运算都是可微的------梯度要能流过去。加权求和是可微的,softmax 是可微的,评分函数里的 tanh 是可微的------整个注意力机制都是可微的。这意味着,对齐模型的参数 WaW_aWa、UaU_aUa、vav_ava 可以和翻译模型一起,用同一个翻译损失函数训练,不需要任何额外的监督信号。
如果使用硬注意力,"选择哪个位置"这个离散决策本身是不可微的------你无法对"选了第 5 个位置而不是第 4 个"这个离散动作求导。训练时就需要用强化学习中的 REINFORCE 算法来估计梯度,这个方法方差高、收敛慢、实现复杂。
软注意力绕开了这个难题:它不做"选择",而是做"分配"------把注意力像拨号旋钮一样连续地分配给每个位置。这个连续分配是完全可微的,可以无缝地嵌入到标准的反向传播训练里。
实际上,软注意力的权重分布,在大多数情况下会自然地接近"硬注意力"的效果:最相关位置的权重会非常高(接近 1),其余位置的权重很低(接近 0)。它只是在计算上做了"平滑",避免了离散选择带来的不可微性问题。
8.4.3 对齐矩阵:神经网络在"想什么"
巴赫达瑙等人在论文中展示了一个令人印象深刻的可视化:它把整个翻译过程的注意力权重 αij\alpha_{ij}αij 画成一个矩阵------横轴是目标语言位置(英文输出词),纵轴是源语言位置(法文输入词),颜色深浅表示注意力权重的大小。
这张图,是深度学习历史上最有名的可视化之一。
它揭示的事情,在 2014 年让很多研究者感到震惊:模型在没有任何语言学标注、没有任何人工对齐规则的情况下,自发地学到了单词之间的语义对应关系。
以英法翻译为例,对齐矩阵里可以清楚地看到:
- "The" 对应法语的 "L'"(冠词对应冠词)
- "agreement" 对应 "accord"
- "European Economic Area" 对应 "zone économique européenne"------而且对应关系是部分错序的,因为法语的形容词通常在名词之后("zone économique" 而非 "économique zone"),矩阵里出现了一些非对角线的高权重块,正好反映了这种词序差异
- "was signed" 对应 "a été signé"------英语被动式和法语被动式的对应
这些对应关系,没有人告诉模型。没有对齐标注,没有语言学规则,只有翻译数据和反向传播。模型自己学到了这些,因为只有学到这些,它才能翻译对。
注意力矩阵的意义不只是"看着好看"。它提供了前所未有的可解释性:我们第一次能够直观地看见神经网络在"思考"什么。在此之前,深度学习模型几乎是纯黑盒------给它输入,它给你输出,中间发生了什么,没人能看见。现在,至少在翻译这件事上,我们可以说:模型在生成第 kkk 个输出词的时候,重点参考了源句子的第 j1j_1j1、j2j_2j2、j3j_3j3 个位置。
这个可解释性有实际价值:当翻译结果不准确的时候,研究者可以检查注意力矩阵,看看模型的"注意力"是否对准了错误的位置------这比盲目调参要有效得多。

图 8.1:注意力对齐矩阵可视化。这是一个矩阵热图,横轴为英文输出词序列,纵轴为法文输入词序列。颜色越深(白色)表示注意力权重越高。对角线区域颜色普遍较深(表示大多数词对的词序相近),部分区域出现非对角线高权重块(反映法英词序差异,如形容词-名词顺序的倒置)。来源:Bahdanau et al.,2015,图 3。
8.4.4 Query、Key、Value 的前身
对于熟悉后期发展起来的 Transformer 架构的读者,一定不会陌生三个无处不在的概念:Query(查询) 、Key(键) 、Value(值)。理解了 Bahdanau 注意力,这三个概念其实已经呼之欲出了------只是当时还没有被这样命名。
让我们用一个图书馆的类比来理解。
想象一下,如果你去图书馆查资料。你的心里会有一个具体的问题(Query)------"我想找关于欧洲经济区协议历史的资料"。图书馆里每本书都有自己的标签或摘要(Key)------"欧盟贸易政策"、"1990 年代国际协定"、"经济区域化理论"......你可以把自己的问题和每本书的标签做匹配,计算相关度,然后选出最相关的几本书,读取它们的内容(Value)。
这里的关键点有,Key 是用来匹配的,Value 是实际要读取的内容。一本书的摘要(Key)和这本书的内容(Value)可以是完全不同的两件事------摘要是为了帮助你判断"要不要读它",内容才是你真正需要的东西。
在 Bahdanau 注意力里:
- Query = 解码器当前的隐状态 si−1s_{i-1}si−1("我现在要生成什么词,需要什么信息")
- Key = 编码器每个位置的隐状态 hjh_jhj(与 Query 做评分,决定关注程度)
- Value = 编码器每个位置的隐状态 hjh_jhj(被加权求和,提供实际内容)
等等------Key 和 Value 是同一个东西(都是 hjh_jhj)?
是的,在原始 Bahdanau 设计中,同一个编码器隐状态既充当"索引标签",也充当"实际内容"。这是一种简化:我们假设"这个位置有什么"和"这个位置是什么"是同一件事。
到了 Transformer,这两个角色被显式地拆分成两个独立的向量------通过学习到的线性变换,同一个编码器状态可以被投影成不同的 Key 向量和 Value 向量。这个分离带来了更强的表达能力:模型可以以不同的方式表达"我能被怎么检索到"和"我包含什么内容"。
但这个 Q/K/V 的框架,本质上是对 Bahdanau 注意力的一次泛化和形式化,而不是从零发明的新概念。理解了这里,Transformer 的注意力机制就不再神秘------它只是把这个结构推得更彻底了。
(选读)深入解释 :Bahdanau 注意力的分数函数是"加性"的(additive attention):用一个小神经网络计算分数 eij=va⊤tanh(Wasi−1+Uahj)e_{ij} = v_a^{\top} \tanh(W_a s_{i-1} + U_a h_j)eij=va⊤tanh(Wasi−1+Uahj)。2015 年,Luong 等人提出了"乘性"注意力(multiplicative attention):用矩阵乘法计算分数 eij=si−1⊤Wahje_{ij} = s_{i-1}^{\top} W_a h_jeij=si−1⊤Wahj,以及最简化的点积版本 eij=si−1⊤hje_{ij} = s_{i-1}^{\top} h_jeij=si−1⊤hj。加性注意力的参数更多,表达能力更强,但计算速度慢;点积注意力计算简单,在 GPU 上效率更高,后来成为 Transformer 的默认选择(加上了一个缩放因子,变成 Scaled Dot-Product Attention)。两种注意力的核心思想完全相同,区别只在于分数函数的参数化方式。
8.5、注意力机制的性能表现
8.5.1 WMT 基准:神经网络第一次真正追上统计方法
2015 年,巴赫达瑙等人的论文正式在 ICLR(国际学习表征会议)发表。论文的实验结果,清晰地证明了注意力机制的价值。
在解读结果之前,先简单解释一下衡量翻译质量的指标:BLEU 分数(Bilingual Evaluation Understudy)。它的核心思路是:把机器翻译的输出和人工参考译文做 n-gram 匹配,计算重叠程度,输出一个 0-100 之间的分数(实际中很少超过 40)。BLEU 分数的绝对值并不那么容易解读,但相对比较很有意义------从 26 到 28,大约对应翻译质量从"勉强可读"到"通顺流畅"的差距,在工业应用上是明显的质量提升。
在 WMT'14 英法翻译任务上,巴赫达瑙等人比较了两种配置:
- RNNenc-dec:标准 Seq2Seq(即 Cho 等人的编码器-解码器架构),无注意力
- RNNsearch:相同架构加上注意力机制,包含 RNNsearch-30(在长度 ≤30 的句子上训练)和 RNNsearch-50(长度 ≤50)
结果令人印象深刻:RNNsearch-50 达到了 28.45 BLEU 分,与当时最好的基于短语的统计机器翻译系统(Moses,26.30 BLEU)相当,甚至稍有超越------而 Moses 是一个融合了大量语言学先验知识、精心调优多年的复杂系统,背后有整整一代 NLP 研究者十余年的努力。
更重要的是我们在图 7.6 展示的那条曲线:在长句(30 词以上)上,不带注意力的 RNNenc-dec 质量急剧下滑,而 RNNsearch 几乎保持水平。这意味着,信息瓶颈不只是被"缓解"了,而是真正被解决了------对于翻译质量随句子长度退化这个问题,注意力机制给出了一个结构性的答案。
这组数据在 NLP 社区引发了一定的震动。不是因为数字有多惊人(毕竟只是勉强追平了统计系统),而是因为它证明了:一个没有任何语言学先验的端到端神经系统,只要解决了信息瓶颈,就可以在质量上与精心设计的专家系统旗鼓相当。这是一个关于方法论的信号:神经方法的上限,远不止于此。
还有一件事值得记住:比较的对象------Moses------不是一个随便搭起来的基线。Moses 是当时最成熟的开源机器翻译工具包,背后有 Johns Hopkins、爱丁堡大学等多所顶尖机构多年的研究积累,支持了大量商业翻译系统。一个用更简洁架构、端到端训练的神经网络,在没有任何人工语言学特征的情况下追平了它------这件事,在 NLP 圈里的含义,不亚于 2012 年 AlexNet 在图像领域对传统方法的超越。
8.5.2 论文的起伏命运:一开始并不顺利
值得一提的是,这篇论文本身的命运,颇具戏剧性。
2014 年 9 月,巴赫达瑙等人把论文发到了 arXiv(arXiv:1409.0473)。同年,他们将论文投稿到 ICLR 2015。ICLR 的审稿是开放的------任何人都可以看到审稿意见,也可以参与讨论。几位审稿人对论文给出了"积极"或"有保留的积极"评价,论文最终获得发表------但并非作为会议的 Oral(口头报告),而是 Poster(海报展示)。
换言之,在最初的学术评审里,这篇论文被认为"有意思,但影响范围有限"------它被放进了海报展示的队列中,却并没有被放在大会的重点讲台上。
但在接下来的几年里,它的引用量开始以令人吃惊的速度攀升。2015 年,注意力机制被迅速采纳进各种 NLP 系统;2016 年,Google 的 Neural Machine Translation(GNMT)系统在生产中大规模部署,注意力机制是其核心组件;2017 年,Transformer 更是将注意力机制发挥到极致。
到今天,这篇论文的引用量超过了四万次。一篇最初被 ICLR 评为"海报"的论文,成为深度学习历史上被引用最多的论文之一。
这个故事有一个微妙的寓意:一篇工作的重要性往往不在发表时就能被充分的认识到。价值的评判,有时需要时间。
事后,Bahdanau 曾被问起当时提交 ICLR 时的感受。他说,他们对论文的影响力其实并没有那么笃定------他们知道这个方法是有效的,实验数据摆在那里,但究竟会引发多大的关注,他们自己也不清楚。那篇论文在他看来,更像是一个"解决了一个具体工程问题"的工作,而不是"提出了一个颠覆性范式"的工作。
这也许正是科研最真实的样子:当事者往往是在解决一个具体的、当下的问题,而回望历史的人才会把它归纳成"范式转变"。巴赫达瑙想解决的,只是"长句翻译质量崩溃"这个让他寝食难安的具体毛病。他没想到,解决这个毛病的方法,会成为接下来十年 AI 历史的基础构件之一。
8.5.3 Google 的大规模验证
如果说 Bahdanau 的论文是在学术上证明了注意力的价值,那么 2016 年 Google 的行动,是在工业规模上给出了最有力的背书。
2016 年 9 月,Google 宣布将 Google 翻译全面切换到神经机器翻译(Google Neural Machine Translation,GNMT) 系统。这是一个里程碑式的事件------毕竟,Google 翻译每天处理超过 1400 亿个字符,是世界上规模最大的翻译系统之一。在这个系统的核心,就是带注意力机制的深度 LSTM。
Google 在论文中报告了令人印象深刻的数字:相比之前使用的基于短语的统计翻译系统,GNMT 在英汉翻译上的错误率降低了 87%,在英法翻译上降低了 60%。更重要的是,Google 做了一个人工评估:让翻译专家对比 GNMT 的输出和人工翻译,在多个语言对上,GNMT 的翻译已经被认为接近人类水平------"与专业翻译员的差距,已经缩小到了只剩三分之一"。
这不只是数字。这是一个你每天打开手机就能感受到的变化:当你试着把一封英语邮件翻译成中文,或者在旅行时用 Google 翻译和当地人沟通------2016 年之后,翻译质量产生了肉眼可见的质的飞跃。
这是注意力机制从实验室到现实世界的第一次大规模着陆。
8.5.4 图像描述:注意力的第一次"出圈"
注意力机制的影响,很快就超出了机器翻译领域。
2015 年,来自多伦多大学的凯尔文·徐(Kelvin Xu)等人发表了论文《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》,把注意力机制引入了图像描述(Image Captioning)任务------给一张图片生成一句文字描述。
他们的模型结构是:先用卷积神经网络(CNN)把图片编码成一个特征图(feature map),这个特征图的不同区域对应图片的不同空间位置;然后用一个带注意力的 LSTM 解码器生成文字,每生成一个词,注意力机制就"聚焦"到特征图的某个区域上。
生成 "bird" 时,注意力落在图片中鸟的位置;生成 "tree" 时,落在树的位置;生成 "sky" 时,落在天空区域;生成 "sitting" 时,注意力分散在鸟和树枝的交界处,因为这个词描述的是鸟和环境的关系。
论文中的可视化极具感染力:把注意力权重叠加到原图上,用高亮区域显示模型在生成每个词时"看"的是哪里。对于"The bird is sitting on a branch"这句话,模型的"视线"会随着句子生成而在图片上移动------读到"bird"时看鸟,读到"branch"时看树枝,读到"sitting"时两者都有一点。
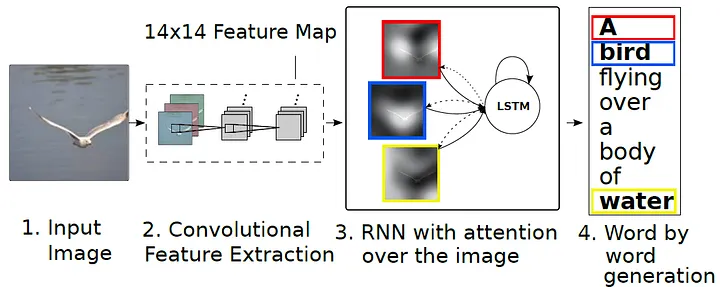
图 8.2:Show, Attend and Tell 论文中展示的图/词对齐示意图
这个可视化在当时在社交媒体上广泛传播,甚至登上了科技新闻------不是因为技术数字有多惊人,而是因为它让普通人第一次看到了一种关于"AI 在看什么"的直观证据。
《Show, Attend and Tell》让更广泛的研究者意识到:注意力不是 NLP 专属的技巧,而是一种通用的机制,可以在任何"需要有选择性地聚焦于输入的某个部分"的任务中使用。从这里开始,注意力机制的应用范围迅速扩展到图像描述、语音识别、阅读理解、问答系统......
8.5.5 Luong 注意力:2015 年的工程化整理
2015 年,斯坦福大学的 Minh-Thang Luong 、Hieu Pham 和克里斯托弗·曼宁(Christopher D. Manning,斯坦福 NLP 组负责人)发表了《Effective Approaches to Attention-based Neural Machine Translation》(arXiv:1508.04025)。
这篇论文的贡献,不是提出新的注意力原理,而是对 Bahdanau 注意力做了系统性的工程化整理和改进,把各种可能的设计选项都实现出来并做了对比实验------就像一篇"注意力的消融研究"。
全局注意力 vs 局部注意力 :Bahdanau 注意力每次都关注全部编码器状态(全局注意力)。Luong 提出了局部注意力(local attention)------每次只关注源序列的一个固定窗口,而不是全部。这减少了计算量,尤其适合非常长的序列,且实验结果显示在很多任务上质量并没有因此下降。
简化的分数函数:相比 Bahdanau 的加性注意力,Luong 提出了更简洁的乘性版本:
- 点积注意力 (dot):eij=si⊤hje_{ij} = s_i^{\top} h_jeij=si⊤hj
- 通用注意力 (general):eij=si⊤Wahje_{ij} = s_i^{\top} W_a h_jeij=si⊤Wahj
- 拼接注意力(concat,即 Bahdanau 的原版)
实验结果显示,三种方式在质量上差异不大,但点积注意力计算最快,最容易在 GPU 上高效实现。这个点积注意力,后来被直接引入了 Transformer------加上一个缩放因子 1dk\frac{1}{\sqrt{d_k}}dk 1,变成了 Transformer 的 Scaled Dot-Product Attention。
Luong 等人的最终结果:在 WMT'14 英德翻译上,他们的最佳模型达到了 25.9 BLEU,比当时最好的系统高出 5.0 个 BLEU 点。
到 2015 年底,注意力机制已经成为 NLP 序列模型的"标准配件":几乎每一个参加机器翻译比赛的团队,都会默认在模型里加上注意力。它从一个新想法,变成了一个约定俗成的 baseline------这是一个新技术走向成熟的标志。
8.6、注意力的边界:补丁还是蓝图?
8.6.1 注意力解决了什么
到 2015 年底,注意力机制的价值已经被广泛认可。总结起来,它做到了四件事:
第一,彻底解决了信息瓶颈。这是最直接的贡献。固定大小上下文向量的限制被绕过------不是靠增大容量,而是靠改变信息流动的逻辑。翻译长句时的质量下滑,从"随长度指数衰减"变成了"基本水平"。这是一个质的变化,而不只是量的改进。
第二,赋予了模型可解释性。注意力权重的可视化,让研究者第一次能够窥见神经网络的"思考过程"。这种透明度在深度学习时代极为罕见,也催生了整个"可解释性 AI"研究方向的早期工作。
第三,高度灵活,可跨领域复用。注意力机制本身对"被注意的对象"没有任何限制------可以是编码器状态、图片特征、音频帧、甚至是序列自身的其他位置(Self-Attention 的雏形)。这种通用性,让它迅速从机器翻译渗透到图像描述、语音识别、阅读理解等几乎所有序列建模任务。
第四,端到端可训练,对齐知识从数据中自动习得。没有对齐标注,没有语言学规则,模型自己学到了词语之间的对应关系。这是深度学习"数据驱动"哲学的又一次胜利。
8.6.2 注意力没有解决什么
然而,2015 年的注意力机制还只是 RNN 的一个"增强模块"。它解决了信息瓶颈,却没有触及 RNN 的另一个根本瓶颈:顺序计算的枷锁。
RNN 的本质决定了它必须按时间步顺序计算:hth_tht 依赖 ht−1h_{t-1}ht−1,ht−1h_{t-1}ht−1 依赖 ht−2h_{t-2}ht−2......这个依赖链在时间轴上是无法打破的。无论你有多少 GPU 核,处理一个 100 步的序列,编码器就是要顺序走 100 步。
这在 2012 年以前的硬件条件下,几乎是不可避免的。但 GPU 时代到来之后,这个限制开始变得越来越让人难以接受。CNN 之所以能被大规模并行加速,是因为不同空间位置的卷积可以同时计算。RNN 天然地无法从这种并行性中获益。
一个直观的对比:在图像任务上,如果你有 4 块 GPU,训练速度接近 4 倍;在 RNN 的序列任务上,有 4 块 GPU,在时间轴上的计算你还是只能一步一步走,提速有限。这对于需要处理成千上万样本的工业级模型来说,是一个严重的效率瓶颈。
更麻烦的是,随着 NLP 任务的规模越来越大,需要处理的序列也越来越长。1000 个词的文档、10000 个字符的代码------对于 RNN 来说,这意味着 1000 步、10000 步的顺序计算。即使有 LSTM 和注意力,这个顺序依赖就是无法并行。
8.6.3 另一个被忽视的问题:O(n2)O(n^2)O(n2) 的代价
注意力机制自己,也带来了一个计算代价,当时被很多人忽视:其复杂度是 O(n2)O(n^2)O(n2),其中 nnn 是源序列长度。
这是怎么来的?在每个解码步骤,注意力机制需要把当前解码器状态和所有 nnn 个编码器状态都计算一次分数------nnn 次计算。解码 mmm 个输出词,就需要 n×mn \times mn×m 次。如果是 Self-Attention(序列和自身的注意力),需要 n×nn \times nn×n 次------序列里每个位置都要和其他所有位置计算一次分数。
在 2014-2015 年的翻译任务中,句子长度通常在 20-50 词,O(n2)O(n^2)O(n2) 的代价可以接受。但如果序列长度变成 1000 词呢?n2n^2n2 就是 100 万次计算。变成 10000 词?1 亿次。随着序列长度增长,计算量是平方级增长------这是一个非常陡峭的曲线。
这意味着,注意力机制在处理非常长的序列时,有自己的效率上限。这个问题在 2015 年还不紧迫,但随着 NLP 任务逐渐从"翻译短句"扩展到"理解长文档",它会越来越重要。
8.6.4 一颗种子,以及一个当时看不见的问题
2015 年,一个小小的想法开始在少数研究者的头脑里萌芽,虽然还没有人把它写成论文。
既然注意力机制允许序列中的任意两个位置直接"交流"------解码器的某个位置可以直接查阅编码器的任意位置,绕过中间的所有时间步------那么,有没有可能让一个序列内部的位置也这样相互交流?
换言之:注意力不只是编码器和解码器之间的桥梁,它还可以用于序列内部自身------每个词同时关注这个序列里所有其他词,直接建立任意位置之间的联系。
这就是 Self-Attention 的雏形想法。
如果 Self-Attention 可行,那么处理序列就不再需要 RNN 的逐步传递了------序列里的每个词,在一步操作里,就能直接获取整个序列的所有信息。这意味着:全程并行。
在 2015 年,这还只是一个模糊的直觉,没有完整的架构,没有实验验证,甚至没有被系统地讨论过。这个想法真正成熟,是在两年之后,由 Google Brain 的八个工程师写成了那篇会改变整个 AI 领域的论文。
但那是下一章的故事了。
8.6.5 对实践者的意义
从实践层面看,注意力机制在 2015 年之后对 NLP 工程师的影响是极其直接的。
在注意力出现之前,如果要做机器翻译,通常模型在长句子上的表现是不可靠的------虽然这些可以通过调整超参数、增加层数来努力提高,但研究者内心知道,超过某个长度,质量就是会下滑。如果产品用户主要写短消息,这也许没什么问题;但如果产品用例包括文章翻译、文档处理,这就是一个无法绕过的瓶颈。
注意力出现之后,这个"心理上的瓶颈"消失了。实践者不再需要担心句子长度------模型可以在翻译任何词时"精确找到"它对应的源词位置。长句和短句,变成了同样可以处理的任务。
更重要的是,注意力机制的实现并不复杂。一旦理解了三步计算(评分、归一化、加权求和),用几十行代码就可以把它接入到已有的 LSTM 模型里。2015 年下半年,GitHub 上出现了大量加入了注意力机制的开源翻译实现,各种框架(早期的 Theano、Torch,后来的 TensorFlow)里都有了注意力的标准模块。它从一个研究想法,变成了工程师工具箱里的标准组件,速度之快,在 NLP 历史上是罕见的。
这种快速普及,本质上是因为注意力机制是在不破坏已有架构的前提下的改进------实践者不需要重新设计整个模型,只需要在 Seq2Seq 的解码器里加上这个查询机制。对工程师来说,这意味着它可以被快速集成到现有系统里,而风险极低。
如果说 Seq2Seq 打开了神经机器翻译的大门,那么注意力机制让这扇门真正变得实用------不只是"能翻译",而是"翻译得足够好,足以在生产环境中替换规则系统"。2016 年 Google 翻译的全面切换,是这个实用性的最终证明。
8.7、知识自检
读完本章,你应该能做到:
- 用三句话向非技术朋友解释"信息瓶颈"问题,说清楚为什么固定大小的上下文向量会在长句翻译中出现问题
- 描述 Bahdanau 注意力的三步计算流程:计算分数(对齐模型)→ Softmax 归一化 → 加权求和得到动态上下文向量
- 解释"软注意力"和"硬注意力"的区别,以及为什么软注意力更容易端到端训练(可微分性)
- 说出注意力对齐矩阵能告诉我们什么,以及为什么它提供了深度学习中罕见的可解释性
- 指出注意力机制解决了 Seq2Seq 的哪些问题(信息瓶颈、可解释性),以及它自己的局限(RNN 顺序计算瓶颈不变、O(n2)O(n^2)O(n2) 复杂度)
- 解释 Query、Key、Value 在 Bahdanau 注意力中分别对应什么,以及 Transformer 里 Key 和 Value 为什么被拆分成了两个独立向量
8.8、常见误解
❌ "注意力机制模拟了人类大脑的注意力"
✅ 实际上:注意力机制是一个数学运算------对所有位置计算加权平均,灵感来自人类翻译时"回头查阅原文"的行为,但和神经生物学意义上的大脑注意力没有直接关系。大脑注意力是选择性的、离散的;机制里的"软注意力"是连续的、对所有位置都有权重的。把两者混为一谈,会导致对机制的错误理解。
❌ "注意力权重表示模型对某个词'理解'了多少"✅ 实际上:注意力权重只表示在当前解码步骤中,哪些编码器位置对输出的贡献更大。高注意力权重不等于"更好地理解了这个词"------同一个源词,在翻译不同目标词时,其注意力权重可能截然不同。此外,研究表明注意力权重并不总是可靠的可解释性工具,它们有时并不与人类直觉的"重要性"对应。
❌ "Transformer 的注意力和 Bahdanau 注意力是完全不同的东西"✅ 实际上:Transformer 的 Scaled Dot-Product Attention 是 Bahdanau 注意力的直接后继,核心操作完全相同(计算分数、Softmax、加权求和)。主要差别是:①分数函数从加性(神经网络)变成了缩放点积;②显式引入了 Q/K/V 的分离;③引入了 Multi-Head(多头并行);④从"编码器-解码器之间的注意力"扩展到了"序列内部的 Self-Attention"。
❌ "注意力机制让模型能记住更长的序列"✅ 实际上:注意力不是增强了记忆,而是改变了信息的访问方式。在 RNN+Attention 框架下,RNN 的记忆容量没有本质变化------LSTM 对长序列的依赖衰减问题依然存在。注意力解决的是解码器访问信息的方式,而不是编码器的记忆能力。
❌ "2015 年带注意力的 Seq2Seq 就是 Transformer"✅ 实际上:2014-2015 年的注意力机制是搭在 RNN 上的,RNN 仍然负责序列的逐步处理,注意力只是解码器的查询机制,整个系统还是顺序计算的。Transformer(2017年)的革命在于完全去掉了 RNN,用 Self-Attention 替代了循环结构,使整个序列处理可以全程并行------这是本质上不同的架构飞跃,不是"注意力的升级版"。
本章关键词
| 词汇 | 简明定义 |
|---|---|
| 注意力机制(Attention Mechanism) | 让解码器在每步生成时动态查询所有编码器隐状态,通过可学习的加权求和替代固定上下文向量 |
| 对齐模型(Alignment Model) | 注意力中用于计算源位置与当前解码步骤相关度分数的可学习评分函数 |
| 注意力权重(Attention Weights) | 对所有编码器位置的分数做 Softmax 后得到的归一化权重分布,决定每个位置的贡献比例 |
| 软注意力(Soft Attention) | 对所有位置分配连续权重的注意力形式,可微分,可端到端训练,是目前主流 |
| 硬注意力(Hard Attention) | 每步只选择一个位置的注意力形式,不可微,需用强化学习(REINFORCE)训练,较少使用 |
| 动态上下文向量(Dynamic Context Vector) | 注意力机制中每步解码时根据当前状态动态计算的上下文向量,区别于 Seq2Seq 的固定上下文向量 |
| 对齐矩阵(Alignment Matrix) | 将翻译过程的全部注意力权重可视化为热图矩阵,揭示源词与目标词之间的对应关系 |
| 加性注意力(Additive Attention) | Bahdanau 提出的注意力分数函数,用小神经网络计算分数,参数量较多,也称 Concat Attention |
| 乘性注意力(Multiplicative Attention) | Luong 提出的注意力分数函数,用矩阵乘法或点积计算,计算效率更高,是 Transformer 的前身 |
| Query / Key / Value(Q/K/V) | 注意力的三角色:Query 是查询状态,Key 用于相关度匹配,Value 提供实际内容;Bahdanau 注意力中 Key=Value,Transformer 中两者分离 |
| 信息瓶颈(Information Bottleneck) | Seq2Seq 的结构性限制:整个输入被压缩为固定大小向量,长句信息必然丢失 |
| Self-Attention(自注意力) | 注意力机制的一种扩展形式,序列中每个位置直接关注同一序列的所有其他位置,是 Transformer 的核心组件 |
延伸阅读
- 必读 :Bahdanau, D., Cho, K., & Bengio, Y. (2015). Neural Machine Translation by Jointly Learning to Align and Translate. ICLR 2015.(首发于 arXiv:1409.0473,2014 年 9 月)------注意力机制的原始论文,第 3 节对机制的描述极为清晰,图 3 的对齐矩阵可视化是必看内容。
- 必读 :Luong, M.-T., Pham, H., & Manning, C. D. (2015). Effective Approaches to Attention-based Neural Machine Translation. EMNLP 2015.(arXiv:1508.04025)------对各种注意力变体的系统性比较,理解 Bahdanau 到 Transformer 演化的关键连接。
- 推荐 :Xu, K., et al. (2015). Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. ICML 2015.------将注意力扩展到图像,最直观的注意力可视化案例,也是"注意力跨模态应用"的起点。
- 推荐 :Wu, Y., et al. (2016). Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv:1609.08144.------Google GNMT 论文,注意力机制工业规模部署的第一手资料,详细描述了翻译质量提升的量化数据。
- 推荐 :Bahdanau, D. (2025). The True Origin of Attention, from Its Author. Turing Post.------作者本人的回顾文章,讲述注意力机制诞生背后的故事,是理解这段历史最直接的第一手材料。
!tip
下一章预告:注意力机制让 Seq2Seq 能够跨越信息瓶颈------但 RNN 的顺序计算依赖,仍然让整个系统无法充分利用现代 GPU 的并行能力。2017 年,Google Brain 的八位工程师做了一个激进的决定:把 RNN 彻底扔掉,只用注意力。他们把论文标题起成了一句宣言------《Attention Is All You Need》。