文献来源:Dipannyta Nandi a,b, Manjarini Mallik a,c , Chandreyee Chowdhury a ,∗,Designing a flask-shaped autoencoder-based dataset distillation framework for Indoor Localization,Engineering Applications of Artificial Intelligence,2026
一段话简要总结
本文针对WiFi 指纹室内定位 在边缘计算、网络不稳定、数据集冗余与类别不平衡 场景下的痛点,提出非对称烧瓶形自编码器(FSA) 数据集蒸馏框架,融合k-Disagreeing Neighbor(kDN)实例硬度评分 实现样本压缩与关键特征保留,在火车站数据集(RSD) 与UJIIndoorLoc、SODIndoorLoc 两大基准数据集上验证,蒸馏后数据集体积减少 36% 、DNN 训练时间缩短 45.98% ,所有数据集定位准确率超 95%,兼顾轻量化与高精度,适配边缘端实时定位部署。
摘要
Indoor localization has become a crucial part ofurban planning( 城市规划**)** and governance applications as complex indoor and semi-indoor public infrastructures are deprived of Global Navigation Satellite System(GNSS) signals.
由于复杂的室内及半室内公共基础设施无法接收全球导航卫星系统(GNSS)信号,室内定位已成为城市规划与治理应用中的重要组成部分。
Due to wide availability of already existing WiFi infrastructures, machine learning-based localization utilizing WiFi signal fingerprints provide ubiquitous location-based services in such areas.
鉴于现有无线网络基础设施已广泛普及,依托WiFi信号指纹的机器学习定位技术,可在这类区域提供无处不在的基于位置的服务。
However, existing works have assumed sufficient availability of cloud services over an unobstructed Internet connection.
然而,现有研究均假设可通过畅通的互联网连接获得充足的云服务。
Interestingly, in a crowded railway station, intermittent(间歇的) internet connection is the reality.
有意思的是,在人流密集的火车站,网络连接断断续续才是实际现状。
Hence, this assumption needs to be lifted by enabling edge learning so that real life location-based services could be provided in public indoor spaces.
因此,需要通过启用边缘学习来打破这一假设,从而能够在公共室内场所提供现实生活中的基于位置的服务。
Consequently, for lightweight training of the classifiers, a novel data compression mechanism has been devised that captures the data patterns in a more compact representation.
因此,为实现分类器的轻量化训练,本文设计了一种新型数据压缩机制,能够以更精简的表征形式捕捉数据特征模式。
Thus, our first contribution is to design an asymmetric Flask-shaped Autoencoder model that takes both signal fingerprints and their instance hardness scores to come up with a distilled data representation, mitigating class imbalance.
因此,本文的首个研究贡献是设计一种非对称瓶状自编码器模型,该模型同时输入信号指纹及其实例难度分数,生成精简的数据表征,从而缓解类别不平衡问题。
Instance hardness as k-Disagreeing Neighborsignifies boundary instances for characterizing inter-class separability in the distilled dataset.
基于k近邻差异度的实例难度可表征蒸馏数据集中用于刻画类间可分性的边界实例。
Applicability of the proposed approach is assessed by collecting data from a crowded railway station utilizing their publicly available WiFi infrastructure.
该所提方法的适用性通过在人流密集的火车站利用其公开可用的无线网络设施采集数据进行评估。
The proposed work is implemented on our collected Railway Station Dataset and two other benchmark datasets. This resulted in more than 95% accuracy on all three datasets indicating generalizability. For Railway Station Dataset, the distilled dataset size decreased by 36% resulting in 45% less training time for Deep Neural Network classifier.
本文所提研究工作在自建的火车站数据集以及另外两个基准数据集上完成实验部署。实验结果显示,该方法在三个数据集上的准确率均超过95%,具备良好的泛化能力。针对火车站数据集,蒸馏后的数据集规模缩减36%,同时使深度神经网络分类器的训练时间减少45%。
1.前言
Indoor Localization aids in determining the position of an individual or object inside the premises of a building where signals from Global Navigation Satellite System are significantly weak or unrecognizable.
室内定位技术可在全球导航卫星系统信号严重衰弱或无法识别的建筑物内部,实现对人员或物体位置的精准判定。
Navigating through large indoor spaces such as airports, shopping malls and huge office buildings with the help of built-in sensors of smartphones is a pressing research challenge that is crucial for many location-based services such as, crowd mitigation, safety and surveillance, and so on Deshmukh et al. (2025).
借助智能手机内置传感器,在机场、购物中心、大型写字楼等广阔室内空间中实现路径导航,已成为一项亟待攻克的研究难题,同时对人流疏导、安全监控等各类位置服务领域具有至关重要的应用价值(Deshmukh et al. (2025))。
The increase in demand for localization systems direct us towards edge intelligence that is efficient at operating under limited computational and storage resources, optimizing performance in dynamic indoor environments.
定位系统市场需求的持续增长,推动行业向边缘智能方向发展;边缘智能能够在算力与存储资源受限的条件下高效运行,并可在动态室内环境中实现性能优化。
Within the broad-spectrum of indoor localization, WiFi-based fingerprinting has emerged to be a prominent method for developing an Indoor Localization System (ILS) where public indoor spaces have a ready-to-use WiFi infrastructure, eliminating(消除) the need for additional
hardware installation.
在室内定位的广泛研究领域中,基于WiFi指纹的定位方法已成为构建室内定位系统(ILS)的主流方式。公共室内场景普遍具备现成可用的WiFi基础设施,无需额外安装硬件设备。
This technique identifies distinct locations by an individual set of vectors, each containing location-specific Received Signal Strength Indicator (RSSI) values collected from nearby fixed Access Points (APs). Each RSSI vector represents a fingerprint for that particular location.
该方法通过独有的向量集合区分不同位置,每个向量包含从周边固定接入点(AP)采集的、具有位置特异性的接收信号强度指示(RSSI)数值,每一组RSSI向量均可作为对应位置的指纹特征。
These location-specific fingerprints often vary due to changes in crowd density, device configurations, and ambient conditions, leading to a complex and non-linear relationship within
the RSSI-feature space.
人群密度、设备配置以及环境状态的变化,往往会导致这类位置专属指纹特征发生波动,进而使RSSI特征空间内形成复杂的非线性关联。
Machine learning and deep learning classifiers are used by researchers to model these complex non-linear relation-ships (Nabati and Ghorashi, 2023).
研究人员常借助机器学习与深度学习分类器,对这类复杂非线性关系进行建模((Nabati and Ghorashi, 2023)。
In the process, variability due to crowd density and device-level inconsistencies introduce noise during sample collection whereas dense sampling and repeated measurements lead to a rise in the redundancy of samples in the dataset. To ensure reliable predictive performance during location classification, models require sufficient representative instances per class i.e, location point.
在数据采集过程中,人群密度波动与设备个体差异会引入采样噪声,而密集采样、重复测量又会造成数据集样本冗余度大幅增加。为保障位置分类任务具备可靠的预测效果,模型需要为每一类(即每个定位点位)配备充足且具有代表性的样本实例。
Moreover, these challenges get amplified under limited memory and computation environments. Generative Adversarial Networks are capable of producing sufficient representative instances per class (Mallik et al., 2025) for indoor environments. However, they employ an additional generative model which add to computational expensiveness.
此外,在内存与计算资源受限的环境下,上述各类难题会进一步加剧。生成对抗网络能够为室内场景的每一类生成足量代表性样本(Mallik et al., 2025),但该网络需要额外搭载生成模型,会显著增加计算开销。
Among feasible solutions, one such potential solution is dataset distillation (Wang et al., 2018). The main objective of this work is to investigate the process of WiFi fingerprinting in resource-constrained environments by leveraging dataset distillation and evaluating the impact of the same on the performance of various classifiers.
在各类可行的优化方案中,数据集蒸馏技术是极具潜力的解决途径之一(Wang et al., 2018)。本文的核心研究目标为:在资源受限环境下,结合数据集蒸馏技术探究WiFi指纹定位的实现流程,并评估该技术对各类分类器性能产生的实际影响。
在基于RSSI的室内定位领域,先前的研究提出了收集、扩充和定期更新ILS数据集以处理动态影响因素的技术(Park等人,2024;Ezzati Khatab等人,2021;Alitaleshi等人,2023)。重复的数据收集和维护逐渐扩大了数据集的维度,因为检测到的一些AP具有不同的上下文,不够稳定,无法在每个数据收集阶段检测到。
因此,为了改进定位过程,Panja等人(2024a)和Kargar-Barzi等人(2024)(文献3.4)提出了从特征空间的角度进行降维的方法。然而,对处理问题的另一个维度,即实例空间的机制的关注有限。当数据集具有每个位置点的样本的倾斜分布时,情况变得更加棘手,这导致由于少数类的表示不足而导致对多数类的偏见,这是定位数据集中注意到的常见现象。此外,对具有成本效益的边缘级别训练的需求对于确保此类本地化系统在任何城市基础设施中取得商业成功至关重要。这是分析实例空间维度的另一个动机。这一差距突显了对数据效率方法的需求,如数据集蒸馏、压缩(Li和Liu,2025)、异常值去除(Abdullah等人,2023)或实例选择(Panja等人,2023)。这样的技术旨在将数据集过滤成原始数据集的紧凑但具有代表性的子集,而不损害定位精度。
尽管存在一些方法来从指纹数据集中识别和移除噪声数据实例(Kim和Lee,2023;Chen等人,2025),并使用元启发式算法执行实例选择(Panja等人,2024b),但它们仅专注于从原始数据集中识别真实样本的子集。然而,在现有的定位工作中,通过提取本质特征表示来将定位数据集提取为高维而紧凑的知识表示是不存在的。有趣的是,对于边缘级别的近乎实时的定位性能,拥有轻量级的平衡定位方法是非常重要的。
2018年,研究人员首次引入了数据集蒸馏的概念(Wang等人,2018年)。其想法是将代表数据集的相对较大的实例集压缩为较小的形式,而不是改变模型。该方法可能不会保持原始数据的分布,但获得了与原始数据集相似的学习效率。在最近的研究中,数据集蒸馏被用于不同的领域,包括计算机视觉(Li等人,2025)、自然语言处理(Sucholutsky和Schonlau,2021)和联合学习(Song等人,2023)。受数据集精馏在这些领域取得成功的启发,我们试图将这一概念与ILS相结合,并通过一个特定于任务的自动编码器提出了一种新的数据集精馏策略。该精馏策略保留了未被表示的位置点中的区分实例,并过滤了看似重要的位置点中的冗余,从而缓解了类的不平衡。此外,它加快了培训过程,使部署实时边缘设备的本地化模型的任务变得更简单,并确保此类模型在动态环境中的健壮性。
自动编码器广泛用于特征压缩或降维(Panja等人,2024a,核心参考文献之一 )。它通过将输入数据映射到包含数据中关键模式的低维潜在空间(瓶颈层)来压缩要素,同时丢弃相关性较低的信息。然后,解码器根据该压缩表示重建原始输入。在本文中,我们从不同的角度利用了这一概念,提出了一种映射策略,用于实例压缩,或数据集蒸馏,目的是降低类之间的相似性,并在遇到类不平衡的情况下突出类内关系。所提出的自动编码器模型是不对称的,即编码器和解码器的体系结构不是彼此的镜像(Gao等人,2025,核心参考文献之二),所得到的模型具有烧瓶状的形状。所提出的烧瓶形自动编码器(FSA)接收经过预处理的WiFi指纹室内定位数据集作为输入,并得到该数据集的精炼版本。这项工作的新颖性在于设计了烧瓶形自动编码器模型,以及它对数据集蒸馏的操作方式。
图1示出了所提出的方法的总体工作流程。最初,从目标区域收集WiFi指纹并存储以创建原始室内定位数据集。以捕获实例硬度的方式对该数据集进行进一步的预处理。在下一阶段,所提出的非对称FlaskShape自动编码器被用来产生精炼表示,这些精炼表示被编译以形成原始数据集的精炼版本。这被分类器用于位置预测。
图1
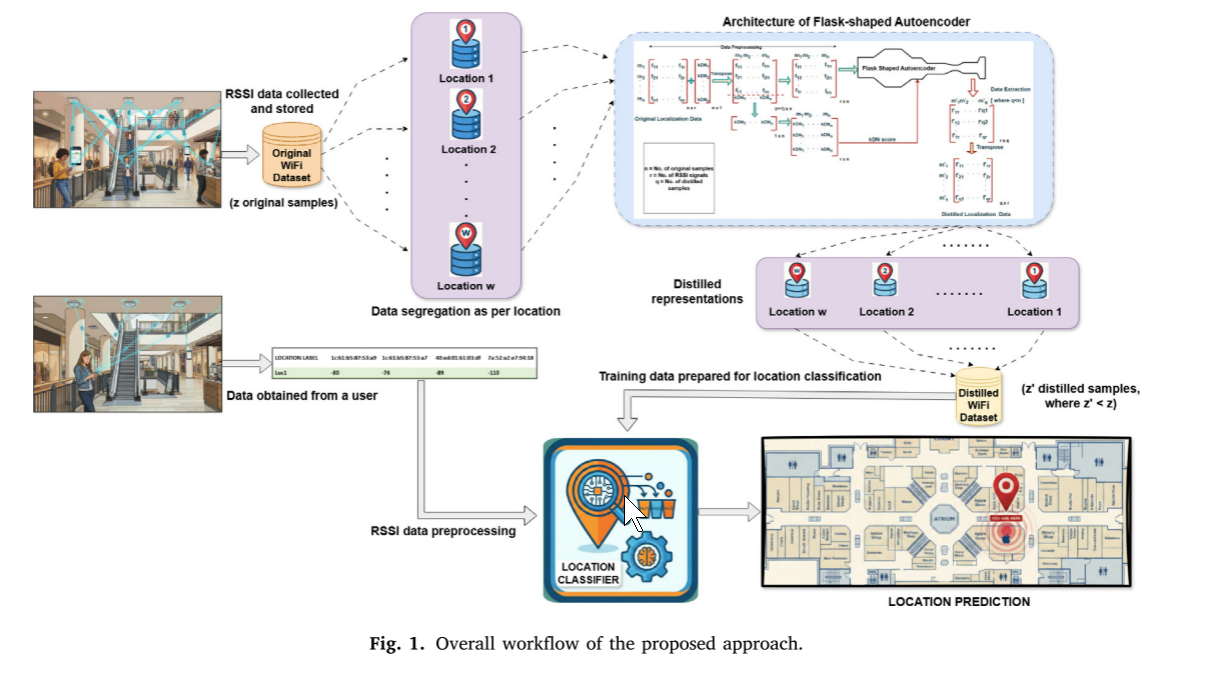
整篇论文的总流程图 ,用一句话说:从原始 WiFi 信号采集 → 数据预处理 → 烧瓶形自编码器蒸馏 → 得到精简数据集 → 定位分类的完整 pipeline。
图 1 展示了:用烧瓶形自编码器把 "大、冗余、不平衡" 的原始 WiFi 定位数据,变成 "小、精、高效" 的蒸馏数据,最终实现轻量、高精度室内定位。
图 1 的每一步逐段解释
我按从左到右的顺序讲,完全对应论文逻辑:
- 原始数据采集(最左侧)
-
从目标室内区域 (火车站、商场、办公楼)采集WiFi 指纹数据
-
数据内容:每个位置的RSSI 信号强度 + 对应的位置标签
-
得到:原始室内定位数据集
- 数据预处理(Data preprocessing)
-
按位置(Location ID) 把数据分组
-
计算每个样本的 kDN(k-Disagreeing Neighbor)实例硬度分数
-
目的:标记难分类的边界样本,缓解类别不平衡
- Flask-Shaped Autoencoder(FSA 核心模块)
-
输入:转置后的 WiFi 指纹 + kDN 分数
-
作用:数据集蒸馏(Dataset Distillation)
-
输出:蒸馏后的紧凑数据表示(Distilled representations)
- 构建蒸馏数据集
-
把所有位置的蒸馏结果合并
-
得到:体积更小、信息更浓缩的蒸馏数据集
- 位置分类与预测
-
用分类器(RF/ANN/DNN/SVM)训练蒸馏数据
-
在线阶段输入新的 WiFi 信号 → 输出定位结果
提出的方法在三个不同的场景中进行了实验。首先,我们采集了该市某火车站的WiFi指纹数据。在这样的公共场所,AP的部署是出于通信(而不是本地化)的需要,一些用户密度较高的地方(如售票柜台、站台等)。有多个AP,一些地方,如厕所和跑道边区域,有几个AP,甚至根本没有AP。在AP分布不均匀的区域进行实验,反映了该方法在公共场所的有效性。
为了指导数据集处理,区分分数k-不一致邻居(KDN)(Smith等人,2014,核心参考文献之三)提供了一种原则性的方法来解决类别失衡问题,因为它识别了较少代表的实例,否则可能被误认为异常值。它识别可能导致类成员资格模糊的相邻类(参考点)的边界指纹,减少对多数类的偏差,从而支持稳健的决策边界。我们还在另外两个基准数据集上对我们提出的方法进行了评估,从实验分析中得出了普遍的结论。
这项工作的主要贡献如下。
·提出了一种对室内定位数据集进行数据集精馏的算法,并在存在类不平衡的情况下对其进行处理。
·设计了一种非对称自动编码器模型,称为烧瓶形自动编码器(FSA)。特征解压缩和实例硬度的概念已经被用来捕获数据的压缩但有意义的表示。
·我们在收集的火车站数据集(RSD)和另外两个包含WiFi指纹数据的基准数据集上进行了实验和深入研究。
本文共分六个部分。第二节介绍了许多使用自动编码器进行室内定位和进行实例选择的作者的贡献。第三节详细解释了所提出的方法。第四节给出了在三个数据集上应用所提出的方法所获得的实验结果。第五节讨论了我们研究的主要发现,并指出了其局限性。第6节提供了这项研究的结论。
2.相关工作
在这一部分中,我们讨论了最近的文献,这些文献强调了自动编码器在解决室内定位领域的几个关键研究挑战方面的效用,以及用于数据简化和现代定位系统的实例选择的一些方法。
Park等人。(2024)介绍了一种适用于室内车辆导航的数据采集技术,该技术使用从多个信标获得的信号。他们指出,通过定义有向图,有限数量的信标就足以进行高分辨率定位,并着手减少良好估计所需的训练信标数量。此外,他们提出了一种基于图形的技术,涉及自动编码器,提高了成本效益,并在不降低估计精度的情况下将高分辨率数据转换为低分辨率形式。
在Ezzati Khatab(2021)等人的一项研究中,由于环境的动态性质,有必要更新WiFi指纹定位数据库。然而,手动收集和更新数据所需的人力使这一过程既复杂又耗时。他们制定了一种室内定位方法,采用自动编码器进行高层特征提取,然后逐渐添加标记和未标记的众包数据来更新指纹数据库。
由于障碍物的反射和折射等多种因素导致信号中存在噪声,影响了位置估计。
Kim和Lee(2023)增加了噪声,反映了随着终端和信标之间距离的增加信噪比的增加,以训练去噪自动编码器。因此,来自解码器的重建数据代表了有助于提高定位性能的去噪蓝牙低能量(BLE)样本。这种方法声称对BLE信号有效,但在基于WiFi的接收信号强度数据集上可能更难实现。
Alitaleshi等人(2023,文献5.11)提出了一种解决训练数据短缺的方法,并使定位方法对噪声数据具有较强的鲁棒性。他们设计了一个框架,在这个框架中,使用极端学习机和自动编码器来提取关键特征。这些提取的特征被用来训练二维卷积神经网络(CNN)(Mizutani,1994)进行位置估计。为了提高定位性能的稳健性,提出了一种在训练数据中引入噪声的数据增强方法。然而,向WiFi定位数据库添加噪声不能被认为是处理样本不足的绝对方法。
Panja等人的工作(2024a)针对基于WiFi指纹的室内定位中的高维问题,提出了一种降维方法。它是室内定位过程中降低实时响应的一个促成因素。他们制定了一种编码过程,该编码过程采用了卷积自动编码器上的双通道训练流水线,其中指纹数据集及其对应的实例硬度分数已作为输入提供给每个通道。
Kargar-Barzi等人(2024年,文献3.4)提出了一项基于自动编码器的研究,在该研究中,他们将以一维向量形式存在的每个定位数据样本转换为带填充的𝑛×𝑛矩阵。这个2D数据样本类似于灰度图像张量。2D数据样本被认为是卷积自动编码器的输入,其中编码器部分首先具有卷积层,然后是池。编码部分之后是一个瓶颈层。解码器具有互补的卷积层,其前面是上采样层。分类任务主要集中在建筑物精度和楼层精度上。
Qian等人(2021)介绍了一种基于WiFi的混合室内定位技术,该技术分为两个部分。首先,他们结合了CNN、RNN(Tsoi和Back,1997)和混合密度预测下一个位置的功能作为一种有监督的学习技术。其次,他们还构造了一个基于变分自动编码器的半监督学习来获取原始输入的潜在分布,以提高定位性能。
Wei等人的研究成果(2024)提供了一种关于射频识别(RFID)的室内定位机构。在整合了高斯卡尔曼滤波作为预处理策略后,他们对RFID数据样本训练了一个基于自动编码器的门控递归单元。这使得定位精度与传统方法相比有了相当大的提高。然而,干扰和信号穿透墙壁增加了使用射频信号进行准确定位的难度,因此作为独立解决方案是不切实际的。研究人员强调了任务特定的非对称自动编码器在不同领域提供的范围,以及非对称自动编码器的一般实现。Gao等人(2025)设计了一种非对称自动编码器,它通过在具有不同编解码层的自动编码器的帮助下执行加速度计数据的特征压缩来建立数据维度的降低与下行带宽之间的关联。Gilbert等人(2024)的另一项研究旨在通过开发一种在解码器中具有比声称与对称自动编码器相比具有较小重建误差的编码器更多层的自动编码器来提高性能。
Panja等人(2024b)的一项值得注意的研究旨在解决在WiFi指纹识别过程中降低计算成本的挑战。该策略专注于通过二进制粒子群优化(Cervante等人,2012)选择实例的子集,从而提高定位算法的可持续性。Panja等人(2023)陈述的关于人类活动识别领域的另一项相关工作使用遗传算法(Holland,1992)和k-不一致邻居(Smith等人,2014)进行元组选择,以保留传感器数据集中的信息实例子集,减少计算开销。虽然这些技术在实例级选择中是有效的,但其对现有数据的剪枝而不是近似整个数据集的学习能力的依赖性造成了数据分布的不完全表示的可能性。
此外,为了应对室内环境的动态性质随着物理布局的变化而带来的挑战,Lombardo等人(2024)提出了一种基于机器学习的数字孪生体系结构,该体系结构利用基于长期短期记忆模型的编解码器进行轨迹重建。它还整合了持续的学习并生成合成数据,以跟上动态环境,因此能够不断复制物理属性并产生网络物理知识。Yang等人(2025)重点研究了使用同时定位和测绘的复杂室内环境的路径规划效率低下的问题。他们设计了一种室内地图分割预处理算法,通过识别和分割不规则形状的复杂室内地图,从路径规划过程中排除了不必要的搜索空间,从而减少了计算开销。
上面讨论的现有工作说明了使用自动编码器使用不同的技术来执行基于室内定位的任务的不同方法。一些研究,Ezzati Khatab等人(2021)描述了自动编码器在数据增强中的作用,而一些人(Panja等人,2024a)使用自动编码器来降低数据集的维度。同样,一些工作(Kim和Lee,2023)开发了一种去噪自动编码器来降低指纹数据集的噪声,以提高室内定位的有效性。因此,现有的研究从多个角度强调了自动编码器在捕获和利用特征空间中的基本模式方面的重要性。
此外,现代定位系统已经转向基于生成性数据的策略(Lombardo等人,2024)和结构优化方法(Yang等人,2025)。关于实例选择的早期研究(Panja等人,2024b,2023)仍然受到原始数据的限制,但通过从原始实例集推导出一组紧凑的信息丰富的实例,为进一步扩展这一想法开辟了一条途径。这使得我们设计了一种基于自动编码器的定位算法,该算法能够解决类不平衡、实例冗余等问题,并能够处理开放空间中AP的稀疏分布。因此,我们为不同的目的提出了基于自动编码器的方法--数据集提取,如下所示。
3.提出的方法
在这一部分中,提出了一种新的ILS数据集提取方法,该方法采用一个基于非对称自动编码器的框架来获取提取的数据。为了奠定基础,我们首先概述自动编码器的基本组件。具有单个隐藏层𝑦、输入𝑥和具有编码器̂𝑥和解码器𝐸𝑛(𝑥的重构输入𝐷𝑒(𝑦的自动编码器的一般结构可以通过等式来定义。(1)和(2)。

| 公式 | 含义解释 |
|---|---|
| y=En(x) | 编码器(Encoder):将高维输入 x 映射为低维隐向量 y |
| x^=De(y) | 解码器(Decoder):从低维隐向量 y 中重构出原始输入的近似 x^ |
| f(x)=De(En(x)) | 自编码器整体:编码器 + 解码器的串联结构 |
| x∈Rn | 输入 x 是 n 维向量(原始数据维度) |
| En(x):Rn→Re,e<n | 编码器把 n 维数据压缩到 e 维(瓶颈层,e 是隐空间维度,小于原始维度 n) |
| De(y):Re→Rv,v=n | 解码器把 e 维隐向量恢复为 n 维输出,维度与输入一致 |
| f(x)≈x^ | 训练目标:让重构结果 x^ 尽可能接近原始输入 x,实现 "无监督特征学习" |